基于改进的Cifar-10深度学习模型的金钱豹个体识别研究
2018-07-23赵婷婷周哲峰李东喜
赵婷婷,周哲峰,李东喜,刘 松,李 明
(1.太原理工大学 a.数学学院,b.大数据学院,太原 030024;2.山西沃成生态环境研究所,太原 030012;3.中国科学院大学 网络空间安全学院,北京 100049;4.中国科学院信息工程研究所 物联网信息安全技术北京市重点实验室,北京 100093)
金钱豹是世界上分布最广的野生猫科动物之一。长期的过度猎捕、栖息地的破坏、种群过小且相互隔离等因素导致了金钱豹在亚洲的种群数量显著减少。历史上,除干旱戈壁沙漠和海拔大于4 000 m的西部山区外,豹的分布遍及中国。金钱豹在我国有3个亚种,长江以南的为华南豹,长江以北的为华北豹,分布在吉林和黑龙江的为东北豹[1]。近年的调查研究结果表明,金钱豹在中国急剧减少。现存金钱豹种群小且分散,主要存在于相互独立的自然保护区中,使得它们面临着较高的局部地区灭绝的风险。金钱豹的保护工作引起了国家和社会越来越多的重视,并开展了大量的研究。金钱豹的个体识别,为分析国内金钱豹的资源现状和保护提供了科学依据。
目前,主要使用红外相机技术对金钱豹个体进行调查与检测研究。山西沃成生态环境研究所通过在自然保护区中布设大量的红外触发相机,对金钱豹进行长时间连续的监测调查,获得了大量金钱豹相关影像数据。通过处理金钱豹相关影像数据,根据影像数据中金钱豹自身的可识别特征——局部花纹来区分个体,从而估算调查区域内金钱豹的种群数量。
当前主要是通过人工目视比对图片中金钱豹花纹的差异性来区分金钱豹个体。随着金钱豹影像数据的增多,人工目视比对方法效率会降低。但在图片识别领域,深度学习方法对于区分图片差异有着显著的优势。基于此,本文将以提升金钱豹个体识别的准确率为目标,研究基于深度学习的具有普适性的金钱豹个体识别方法。
1 研究现状
金钱豹个体识别指根据金钱豹个体之间的差异区分金钱豹个体。金钱豹个体识别是对金钱豹进行有效保护的基础。随着金钱豹的种群数量显著减少,对金钱豹个体识别的研究也逐渐增多起来。
对金钱豹的个体识别,可以借鉴各类虎豹的个体识别方法。已有部分研究主要关注于通过虎豹的生物特征差异进行识别。2000年,MILLS et al[2]通过从稀有或难以捕获的物种的粪便和毛发中提取DNA进行个体识别。2007年,KERLEY et al[3]使用专门训练的犬通过粪便的气味进行东北虎的个体识别。2010年,RIORDAN[4]通过提取虎和雪豹的脚印形状进行个体识别。DNA分析法可以识别到准确的个体,但是花费较高,并且在野外采集毛发、粪便样本也较为困难。通过脚印形状进行个体识别花费较少,并且脚印采集较为简单,但是只能在冬季进行,不利于全年的持续监测。利用犬粪便气味进行个体识别则需要对犬进行专门的训练,并且在金钱豹所在的自然保护区也比较难遇到金钱豹粪便,不适于长时间对金钱豹进行监测。
近年来红外照相技术在物种监测中被广泛应用,通过红外触发相机可以获得大量的金钱豹的形体特征[5-7]。通过金钱豹的形体特征进行个体识别成为流行。在金钱豹的形体特征中,金钱豹体侧花纹更为明显。2006年,STEPHENS et al[8]提出虎豹的体侧中部、后肢外侧等部位条纹与斑点具有很大的个体差异性,非常适合进行个体识别。HIBY利用动物个体体侧花纹来进行个体识别,从而精确得出检测到的虎豹个体数量[9]。在当前的通过体侧花纹识别金钱豹的方法中,主要是通过人工目视比对进行个体识别。人工目视比对对于少量金钱豹体侧花纹图片识别准确度较高,而随着红外相机拍摄到的金钱豹的图片数量增多,则需要更多的人力来进行识别标定。
在图片识别领域,深度学习取得的成绩非常显著。在人脸识别测试集LFW中,经典的人脸识别算法EIGENFACE[10]仅能达到60%的识别率,非深度学习识别算法的最优识别率为96.33%[11],而深度学习可以达到99.47%的高识别率[12]。
本文首次将深度学习方法应用到金钱豹花纹特征识别研究中,试图得到一种金钱豹个体识别的普适方法。
2 深度卷积神经网络
卷积神经网络是一种特殊的前馈神经网络,是受生物学上感受野的机制而提出的,已成为当前语音分析和图像识别领域的研究热点。卷积神经网络通过使用卷积层代替部分全连接层以及添加子采样层,获得了3种结构上的特性:局部连接,权重共享以及空间或时间上的次采样。这些特性使得卷积神经网络具有一定程度上的平移、缩放和扭曲不变性[13]。
深度神经网络可以从原始输入数据中自动发现需要检测的特征,进行特征学习。通过堆叠多个隐藏层,深度神经网络能够逐层学习到更加抽象复杂的特征,其中每一层学习到的特征表达都是前一层学习到的简单特征表达的组合。比如对于图像分类任务,图像往往以像素矩阵的形式作为原始输入,第一层可以通过比较相邻像素之间的亮度识别边缘。给定第一个隐藏层对边缘的描述,第二个隐藏层可以检测角和轮廓,这些角和轮廓可以被看作是边缘的集合。给定第二个隐藏层对角和轮廓的描述,第三个隐藏层可以通过查找角和轮廓的特定集合来检测特定对象的整个部分。以此类推,之后的每一个隐藏层都是对前一个隐藏层检测到的特征组合的描述。最后,所得到的描述可以用于识别图像中存在的对象。对于深度学习而言,这些特征和隐藏层并不需要通过人工设计,它们都可以通过通用的学习过程得到。
对于金钱豹花纹而言,可能会由于光线、拍摄角度以及金钱豹的行动等因素造成花纹亮度及其形状的变化,但是花纹间的结构是不变的。深度卷积神经网络可以自主进行特征学习,检测出花纹结构,且对多种变形具有不变性。本文首次使用深度卷积神经网络来实现金钱豹的个体识别。结果表明,该方法具有很好的预测准确性。
2.1 卷积
卷积神经网络得名于使用卷积层代替部分全连接层,即在部分隐藏层使用卷积运算代替矩阵相乘。应用于图像识别领域,指输出图像中的每个像素都是由输入图像对应位置的小区域的像素通过加权平均得到的,相应的权值矩阵就称作卷积核。卷积的结果经激活函数后输出该层的特征图。卷积层可以看作是对输入图像进行“抽象”的操作,经过几次处理之后,能够提取出图像的“特征值”。一般地,卷积层的计算形式为:
(1)
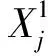
2.2 ReLU激活函数
在神经网络中,激活函数的作用是通过加入非线性因素,从而解决线性模型不能解决的问题。
ReLU激活函数(The Rectified Linear Unit)是目前使用最多的激活函数,其表达式为:f(x)=max(0,x),函数关系图如图1所示。
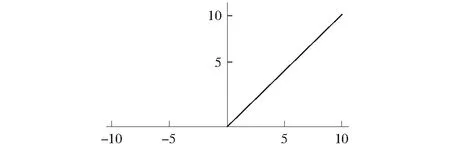
图1 ReLU激活函数Fig.1 Plot of the ReLU activation function
相比传统的Sigmoid和tanh函数,ReLU激活函数的有效性体现在2个方面:a) 减轻梯度消失的问题;b) 加快训练速度。KRIZHEVSKY et al[14]指出,使用ReLU激活函数的深度卷积神经网络训练速度比同样情况下使用tanh函数的训练速度快几倍。
2.3 池化
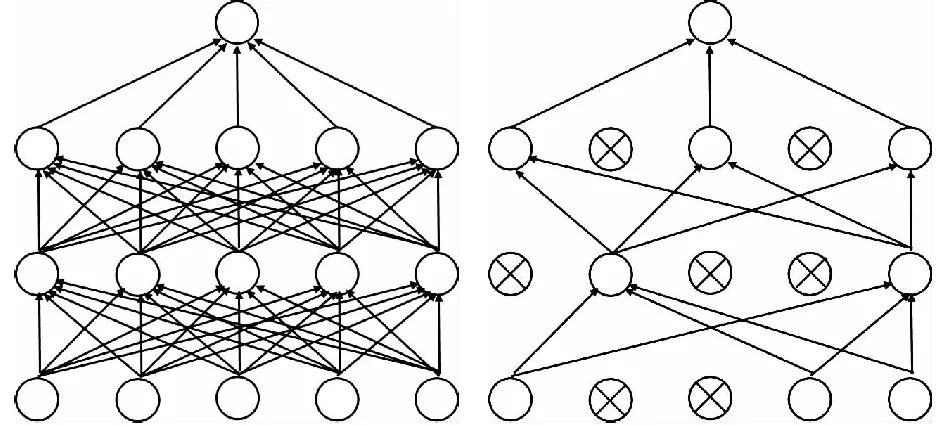
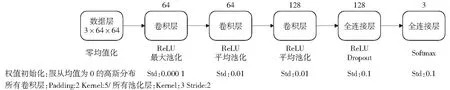
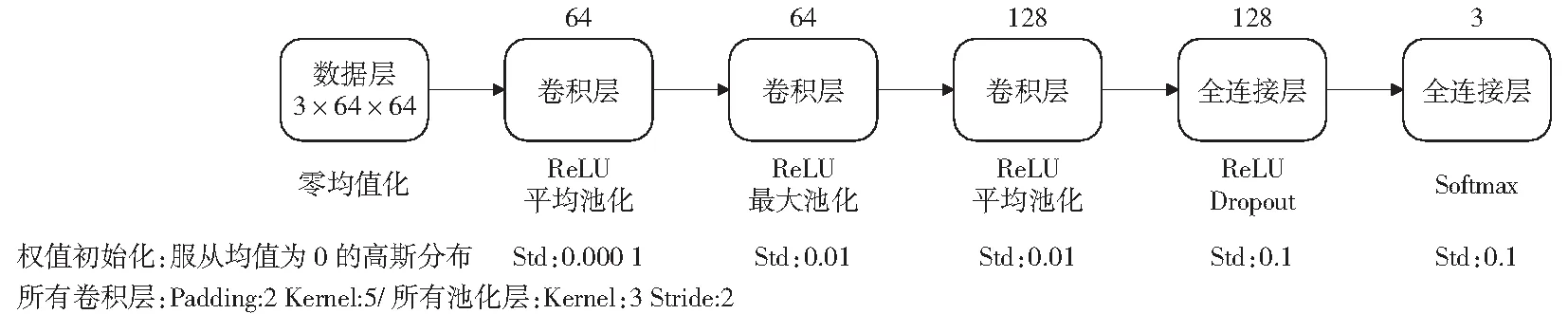
卷积神经网络中的池化层归纳了同一个核特征图中相邻神经元组的输出,对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。常见的池化操作为平均池化(Ave)和最大池化(Max).通常,由邻接池化单元归纳的邻域并不重叠。确切地说,一个池化层可以被看作是包含了每间隔stride个像素的池化单元的栅格组成,每一个都归纳了以池化单元为中心大小为sizeX×sizeX的邻域,这里stride即为步长,sizeX指定池化层核的大小。如果令stride=sizeX,将会得到非重叠池化。若令stride 本文模型使用了3个池化层,共有8种池化方式的组合,最终通过实验选取相对于实验数据最合适的池化组合。 Cifar-10是由KRIZHEVSKY和SUTSKEVER收集的一个用于普适物体识别的数据集。Cifar-10由60 000张像素的RGB彩色图片构成,共10个分类。其中50 000张用于训练,10 000张用于测试。Cifar-10快速简易模型是基于该数据集推出的一个深度卷积神经网络结构,理论上这个网络容量可以把验证集错误率降到25%左右。 本文模型参考了Cifar-10快速简易模型。结构方面,该模型包含5个学习层(3个卷积层和2个全连接层)。每一个卷积层后面都添加了池化层,其中,第一个卷积层之后采用最大池化,第二、三个卷积层之后采用平均池化。激活函数均使用ReLU函数,除最后一个全连接层使用了Softmax函数。参数方面,该模型初始化每一层的权重,服从均值为0,标准差分别为0.000 1,0.01,0.01,0.1,0.1的高斯分布。初始化第二个卷积层以及第一个全连接隐层的偏置项为常数1.这种初始化通过向 ReLUs提供正的输入来加速学习的早期阶段。初始化其余层的神经元偏置项为常数0.对于每一个卷积层的输入,对其向外扩充两个像素点,以使得卷积运算之后的特征图大小不变。对于每一个卷积层,为防止损失太多信息,步长设置为1,卷积核的大小设置为5×5.对于每一个池化层,设置步长为2,核的大小为3×3.在输入层,模型通过对原始数据减去像素均值以提高精度。 对于深度神经网络而言,需要学习的参数较多,容易出现过拟合现象。本文使用的金钱豹数据相对于模型需要学习的参数来说较少,很容易发生过拟合。因此,本文选取一种非常有效的方法——“Dropout”防止训练得到的模型过拟合。 “Dropout”的思想是在每一轮训练过程中,将每一个隐藏神经元以固定的概率p“丢弃”。 这些以这种方式被“丢弃”的神经元的输出被设置为0,它们既不会参加前向传递,也不会参与反向传播。而那些以概率(1-p)被保留下来的神经元构成了一个新的“瘦”的神经网络。这样对于每一次输入,神经网络都会学习到一个不同的结构。因此,使用“Dropout”之后,可以将一个大网络看做是多个小网络的组合。最后通过对多个模型的输出取平均来得到最终结果。这种方式相当于综合考虑多种不同模型的预测结果,可以有效降低测试误差,提高预测的准确度,而且能够有效地防止过拟合,显著降低泛化误差。需要指出的是,如果神经元在训练期间以概率(1-p)保留,那么该神经元的输出权重在测试期间要乘以(1-p).这确保了对于任何隐藏神经元的输出的期望(在已知训练期间被“丢弃”的神经元的分布下)与测试时的实际输出相同[15]。本文模型在第一个全连接层使用了“Dropout”,Nitish Srivastava等指出,使用“Dropout”时,在简单情形下,使用验证集选择p值或直接设置p=0.5,可使通用网络模型近似最优[15]。本文设置p=0.5,即每一个神经元有50%的概率被“丢弃”。 图2 标准神经网络(左)与应用“Dropout”之后的神经网络(右)Fig.2 A standard neural net with 2 hidden layers (Left) and an example of a thinned net produced by applying dropout to the network (Right) Cifar-10 快速简易模型的3个池化层分别为Max-Ave-Ave.为了更好地拟合实验数据,本文对池化层的组合方式进行了调整,最优组合方式通过实验确定。 最终改进模型结构如图3,图4所示。 图3 金钱豹左侧中部数据最优模型整体结构Fig.3 Overall structure of the optimal model about leopard left middle data 图4 金钱豹右侧中部数据最优模型整体结构Fig.4 Overall structure of the optimal model about leopard right middle data 本文模型改进主要是加倍了神经元的个数以学习到更多的特征结构,添加了“Dropout”层来防止模型过拟合,并对池化层的组合方式进行了适当地调整。可以发现左侧中部数据的最优模型池化层的组合方式与Cifar-10快速简易模型是相同的。而右侧中部数据的最优模型的第一个和第二个池化层都进行了改变。说明没有哪一种模型是最好的,我们需要通过针对实验数据对模型进行灵活改动,以训练得到针对实验数据的最佳模型。 本文使用的金钱豹数据来源于山西沃成生态环境研究所2010-2016年数据。 目前通过人眼目视识别的豹子有80只左右,但对于不同豹子所获得的影像数据数量不等。选取了其中影像数据量较多的3只豹子进行识别分类,使用体侧中部数据训练与验证模型,可观察到金钱豹体侧中部的影像数据量如表1所示。 表1 可观察到金钱豹体侧中部的影像数据量Table 1 Amount of images that can be observed leopard body-side middle 对于金钱豹影像数据,首先使用Adobe Premiere Pro CC工具将视频以每秒24帧的方式导出图片,然后对导出的图片进行高效选择:对于可以直观明显地观测到体侧中部花纹的图片,按其连续动作进行保存,对于图片质量稍差的图片,从中选取几帧典型动作(花纹较明显)进行保存。这里的质量稍差指的是由于光线、角度以及金钱豹的行动造成的体侧中部部分过亮或过暗、花纹不够直观明显以及扭曲过于严重。接下来将筛选得到的图片与直接获取得到的质量较好的金钱豹图片导入Adobe Photoshop CS6进行裁剪,获得体侧中部图像。在利用卷积神经网络进行图像识别时,对于输入层(图像层),通常把数据归一化成2的次方的长宽像素值。通过观察待裁剪图片的像素大小,本文将图片统一裁剪为64×64像素大小。最后进一步筛选适用于模型训练与验证的图片。统计数量如表2所示。 表2 适用于模型训练与验证的图片数量Table 2 Number of pictures applicable for model training and verification 图5展示了通过预处理得到的用于模型训练的3只金钱豹的左侧中部花纹数据的部分样本数据。 图5 用于模型训练的3只金钱豹左侧中部花纹对比图Fig.5 Contrast chart of three leopard left-side middle pattern which used model training 4.3.1 数据集的构建 每次实验,从各类样本中随机选取90张图片作为训练集,剩余样本构成验证集。对于两侧数据,分别随机选取3组互不相容的训练集与验证集。其中训练集图片在裁剪时以体侧中部花纹为中心,截取体侧中部。验证集图片简单截取体侧中部,尽量使体侧中部居中,未刻意寻找中心花纹。参与模型的数据分布如表3. 表3 参与模型训练与验证的数据分布Table 3 Data distribution used model training and verification 4.3.2 参数配置 SRIVASTAVA et al[15]指出,使用“Dropout”时,0.95~0.99之间的动量值相对更好。不仅可以显著加快学习速度,还可以有效降低噪音,所以本文中动量值设置为0.95. 本次实验使用随机梯度下降法训练模型,最大迭代次数为1 000,基础学习率为0.000 01,权重衰减参数为0.004. 权重衰减项可以控制神经网络的正则化项,一定程度上防止模型过拟合[14]。权重w的更新规则是 (2) wi+1=wi+vi+1. (3) 4.3.3 实验平台 平台方面,本文选取在Linux ubuntu16.04.2系统上搭建Caffe框架,进行模型训练。 Caffe(convolutional architecture for fast feature embedding)是由在Google工作的贾扬清博士及其团队一同研制的一款用来计算卷积神经网络的深度学习开源框架。其优势主要体现在高效的运行速度上。Caffe可以通过文本文件的更改来实现网络结构的调整,从而避免了通过繁琐的编码进行网络优化。Caffe支持CPU和GPU运算的转换,同时实现了多GPU的并行运算,从而可以最大程度地提高计算效率。Caffe是基于BSD2-Clause协议的C++/CUDA架构,支持终端指令、Python和MATLAB等接口[16]。 本次试验使用3组数据的平均准确率来衡量模型预测结果的准确度,使用准确率的标准差来衡量模型的稳定性,使用平均损失来衡量模型预测正确的可能性的大小。 准确率a和损失bloss的计算公式分别为: (4) 图6 使用金钱豹左右两侧体侧中部数据建立模型,在验证集上得到的平均准确率、准确率标准差与平均损失Fig.6 Using Leopard left and right body-sides middle pattern to build the model, the average accuracy, the standard deviation of accuracy and the average loss on validation set (5) 从图6可以看出,对于金钱豹左侧中部数据,池化层组合方式为MAX-AVE-AVE的模型平均预测准确率较高且更稳定,平均损失也基本稳定在最低值;对于金钱豹右侧中部数据,池化层组合方式为AVE-MAX-AVE的模型的平均预测准确率较好且相对更稳定,平均损失也基本始终保持在最低值。 综合考虑平均准确率、准确率标准差、平均损失3种评价指标,对于左侧中部数据,本文模型选取池化层为MAX-AVE-AVE的组合方式,对于右侧中部数据,本文模型选取池化层为AVE-MAX-AVE的组合方式。其训练结果如表4所示。 表4 训练结果随迭代次数的变化Table 4 Training results vary with the number of iterations 通过观察实验结果,可以发现本文模型的预测准确率高达99.3%以上,且损失较低,说明模型以很高的概率预测到了正确类别。而且对于左右两侧中部数据,本文通过实验的方式选取了不同的池化组合。在实际训练模型时,我们需要根据实验数据适当的调整模型结构,以训练得到相对于实验数据的最优模型。 本文基于山西沃成生态环境研究所通过红外相机采集的大量金钱豹影像数据,首次将深度学习方法应用到金钱豹个体识别研究中,通过适当改进的Cifar-10深度学习模型,借助Caffe深度学习框架进行模型训练,得到较优的金钱豹个体识别深度学习模型。最终得到的深度学习模型可以达到99.3%的识别准确率,能够有效识别金钱豹个体。之后可以依据此方法分析金钱豹生存现状,为金钱豹栖息地的保护提供理论基础。 本文根据已有数据构建了丰富的图像数据库,之后拍摄到的新的金钱豹图像可与当前图像库中的豹纹图片进行比对,实现个体识别,扩充数据库。且随着获取到的图像资料的增加,可以根据金钱豹的头部、尾部、体侧花纹分别构建模型,然后将其集成为一个系统,以便之后可以进行推广使用。3 基于Cifar-10卷积神经网络的改进模型
3.1 整体结构
3.2 引入Dropout防止过拟合
3.3 池化方式组合优化
3.4 改进模型整体结构
4 实验
4.1 数据描述

4.2 数据预处理


4.3 实验验证与讨论



5 结果分析
5.1 性能指标

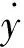
5.2 结果分析

6 总结与展望
