基于C-F模型的中文地址行政区划辨识方法
2018-07-19李晓林周华兵
李晓林,张 懿+,周华兵,李 霖
(1.武汉工程大学 计算机科学与工程学院,湖北 武汉 430205;2.武汉工程大学 智能机器人湖北省重点实验室,湖北 武汉 430205;3.武汉大学 资源与环境科学学院,湖北 武汉 430079)
0 引 言
随着城市现代化建设的发展,城市命名方式不断变化,故急需更新和完善现有地理位置信息库。而伴随着人们出行、交流等对互联网的不断依赖,使互联网中积累了大量蕴含地理位置信息的中文地址,故可通过提取其中的有用信息来获取人们普遍使用的地理位置信息表示方式。但由于人们网络交流的随意性,导致互联网中大部分中文地址表达方式纷繁复杂、形式各异[1]。且中国地域广阔,地理位置信息的杂乱与不规范,同时具有极强的区域特色,往往会增加辨识的难度或引发辨识的歧义。
中文词语之间无明显的分割符号,相同词在不同语境中存在不同含义[2]。对于一条地址字符串,如果省略区划特征字,其中可能包含多个行政区划信息,如“江苏鼓楼广场”,其中“江苏”匹配行政区划“江苏省”,“鼓楼”匹配“江苏省南京市鼓楼区”和“江苏省徐州市鼓楼区”;又如“湖北省洪山”,其中“洪山”匹配“湖北省武汉市洪山区”和“湖北省随州市洪山镇”。类似行政区划匹配结果的多样性与歧义性对地址信息的准确辨识均产生影响。
为了更好地构建地理位置信息库,就需首先解决地理文本信息中的中文地址行政区划信息提取问题。
1 相关工作
针对中文地址识别国内已有大量研究,特别是对行政区划特征完整且无歧义的中文地址的识别已达到较好的效果。目前主要采用的方法可分为3个方面:基于特征词的地址分词算法、基于机器学习模型的地址识别以及基于自然语言理解的地址要素识别。
文献[3]采用特征词匹配的思想,提出了一种前后缀与特征词相结合的地名地址识别提取方法。首先利用HMM训练进行分词,接着通过地名地址前后缀词库进行候选地名切分与预提取,最后根据特征词进行匹配过滤,实现对地名地址的准确提取[3]。该算法具有较高的运行效率,但分词结果的正确率十分依赖于地址信息中是否存在特征字,当特征字缺失时,会严重影响分词的准确率。目前较为熟知的机器学习模型主要有隐马尔科夫模型(HMM)、最大熵模型(MEMM)和条件随机场(CRF)模型等,其中CRF模型具有特征选择灵活和拟合程度较好的优点[4]。文献[5]利用条件随机场模型,根据中文地址行政区划的表达特点,结合判别式概率模型和四词位标注法,首先对观测序列进行标注以对目标序列建模,通过构建语料训练集和特征模板,得到行政区划的表达模型[5]。虽然该方法的识别准确率能够到达近90%,但需要对语料进行人工标注,工作量太大,同时模型训练的效果过于依赖所选取语料的规范性。基于机器学习的方法可以通过对中文语义进行标注,有效获取语句结构中的语义信息,但存在设计复杂、条件要求过强等缺陷[6]。文献[7]和文献[8]在自然语言理解的基础上对中文地址进行识别。文献[7]通过建立空间关系地址模型和地址库逻辑模型以解决中文地址抽象问题和地址信息空间知识表达问题,依据中文分词和语义推理原理,在结合自然语言理解方法和地址匹配方法的基础上,建立基于自然语言理解的中文地址识别算法;文献[8]从人类理解地址的角度出发,通过互联网中蕴含的地名信息建立一个地址知识库,从而对地址进行解析、更新等操作。虽然文献[7]和文献[8]的实验结果准确率较高,但文献[7]仅对河南省濮阳市人口库1000条居民地址数据进行测试,测试数据集太小且区域性太强,缺乏足够的说服力,文献[8]主要针对电力系统业务部门中的地址数据进行识别,同样缺乏通用性。
上述方法均可以解决行政区划完整且无歧义的中文地址识别问题,但针对网络中出现的杂乱无章且行政区划存在模糊、缺失的地址的识别则存在如下问题:①建立了标准地址库以匹配标准地址中的行政区划,但对于无特征信息标签,且会产生歧义的非标准化地址,将产生错误的匹配结果。如“南京江宁芙阁路兰州拉面馆”,其中“兰州拉面馆”会错误匹配为“兰州市”;②仅依据地名词典进行特征字直接匹配的方法,大多没有考虑地址的语义信息,导致查找结果多样,查找的准确性较低,无法较准确的获取地址中包涵的行政区划;③地址标准化工作较为繁重,或字符串匹配次数较多,或算法迭代次数多,导致程序计算量太大,系统运行速度慢;④仅依靠行政区划完善的地址数据作为训练样本,虽对类似结构的地址文本具有较好的识别率,但对行政区划模糊或缺失的地址信息的识别效果较差,识别方法具有一定的局限性。
为解决上述不确定性问题,本文事先建立一个有限的、轻量级的1-3级标准基址库[9]。在此基础上提出一种基于可信度模型的行政区划可信度计算方法,利用可信度方法的概念与模型对地址行政区划的可信度进行推理计算,从而得到更准确的中文地址行政区划。
2 可信度计算方法
可信度方法是一种基本的不确定性推理方法,又称C-F模型,具体含义请参考文献[10]。结合此模型,将行政区划作为证据,其对应匹配的行政区划结果作为结论,并对多个匹配结论的可信度进行不确定性推理,选择可信度最高的区划结论作为地址的行政区划信息。
2.1 名词解释
(1)初始信度(initial credibility,IR)表示地址字符串对应行政区划结论集中的各区划结论作为地址字符串准确定位信息的初始信任程度。
(2)传递因子(transfer factor,TF)表示地址字符串中各行政区划匹配结论间信度相互传递的系数,即0 (3)传递信度(transfer credibility,TR)表示地址字符串中各行政区划结论所包含地理信息的关系程度。可表示为 传递信度=初始信度×传递因子 (4)移动窗口最大匹配算法(maximum moving window match,MMWM)通过动态调整匹配窗口的大小,截取地址字符串的子串并与标准行政区划字典进行匹配,从而得到其中包含的行政区划结论集。算法详细步骤请参考文献[11]。 将地址字符串包含的行政区划作为不确定性推理的证据,区划匹配的地址结果作为不确定性推理的结论;辨识方法总体流程如图1所示。 图1 中文地址行政区划信息提取流程 具体计算方法与步骤如下: (1)利用行政区划字典和移动窗口最大匹配算法,匹配得到地址字符串所包含的可能行政区划结论集。 (2)对一个待查询地址字符串,当其中行政区划作为推理证据时,依据其位置因子(factor position,FP)与匹配模式系数Mode(i),计算该证据行政区划的初始信度。 首先根据行政区划表,对待查询地址字符串进行分词,得到若干个行政区划字符串。 (1) 同时,证据行政区划初始信度如式(2)所示 (2) 式中:Mode(i)为第i个行政区划字符串的系数,如果是完全匹配模式,如地址字符串“湖北省武汉市”匹配行政区划“湖北省”、“武汉市”,则Mode(i)=0.9,此处不设Mode(i)=1.0的原因在于,完全匹配的行政区划中可能包含命名实体,匹配模式会误将其识别为地址行政区划,例如:“武汉市江夏区兰州拉面馆”中的“兰州”即为命名实体;如果是部分匹配模式,如地址字符串“湖北武汉”匹配行政区划“湖北省”、“武汉市”等,则必须保证其匹配模式系数小于完全匹配时的系数,故Mode(i)=0.7;同理,如果是简称匹配模式,则Mode(i)=0.5。 (3)对于一个地址字符串,当其包含多个行政区划证据时,行政区划结论集中的匹配结论会对应多个不同的地理位置信息。但从语义的角度考虑,不同区划匹配结论间仍存在一定的位置关系,即会将自身区划证据初始信度传递到相关匹配区划结论中,以相互支持各区划证据。 传递因子主要由两个不同地址匹配地址结论中的相同区划个数S(i,j)和区划位置级差因子FPL(i,j)确定,且传递因子与区划级差相关因子(factor position level relation,FPLR)密切相关,故需先得出FPLR(i,j),如式(3)所示 FPLR(i,j)=FPL(i,j)+S(i,j) (3) 假设有区划证据“南京”和“鼓楼”,证据“南京”匹配区划结论为A1:“江苏省南京市”,“鼓楼”匹配区划结论为A2:“江苏省南京市鼓楼区”和A3:“江苏省徐州市鼓楼区”,由此可得S(A1,A2)=2,S(A1,A3)=1。 对于包含完整行政区划的地址,其区划行政级别变化趋势往往与位置值的变化趋势保持一致,如当Pos(1)=“省”,Pos(2)=“市”; 而在存在行政区划模糊或缺失的地址中,FPL(i,j)的变化趋势较为复杂多变,但本文主要针对省、市和区三级行政区划,即Lev(i)∈{1,2,3}。 通过对大量实际地址中出现的行政区划的级别与位置进行分析,可得区划级差相关因子具体表示形式,如式(4)所示 (4) 由式(4)可知,FPL(i,j)≤1且0≤S(i,j)≤3, 同时为满足0≤TF≤1, 故令传递因子TF(i,j)如式(5)所示 (5) (4)对于某一地址字符串,将其中行政区划作为证据,根据位置因子和匹配区划级别,得到其对应行政区划结论的初始信度。虽然不同行政区划匹配出各自对应行政区划结论,但结论之间存在一定的地理位置关系。故需利用不确定性的信度传递概念,对各证据的初始信度进行转移,由式(2)和式(5)可知 (6) 依据式(7)得出各行政区划结论间的传递信度后,以此计算各行政区划传递信度的总和,并作为各行政区划信度的更新值,记为Credibility(j),如式(7)所示 (7) 最后,选取行政区划结论集中可信度最大的行政区划结论作为地址字符串的地理定位区划方式,如式(8)所示 (8) 本文方法主要针对中文地址行政区划信息的辨识与提取,为了充分体现本文方法在解决地址行政区划模糊、缺失和歧义等问题上的优势,需对实验进行一定设计,并在此基础上对实验结果进行分析。 为验证本文方法的有效性,需准备一个结构规范,内容较为完整的行政区划字典,作为信息匹配的依据。实验设计的主要内容包括:测试语料预处理和实验组合方式。 (1)测试语料预处理 利用网络爬虫算法从互联中获取25万条地址数据。然而,这些地址大多包含冗余的信息,其中“路”特征词等低级区划信息会对实验结果的准确性产生较大干扰,如“上海路”、“南京路”和“武汉大道”等会匹配得到“上海市”、“南京市”和“武汉市”等干扰信息。为了排除此干扰,体现本文方法在针对行政区划信息辨识上的优越性,本文实验对于中文地址的预处理方式为省略低级区划,只保留三级行政区划等有效信息。 (2)实验组合方式 在所选取的测试语料中,有些地址信息十分完整与确切,如“湖北省武汉市”,此时可通过完全匹配的方式获取其中行政区划信息“湖北省”和“武汉市”;但也存在行政区划特征字缺失的情况,如“安徽合肥”,此时只能依靠部分匹配的方式,“安徽”部分匹配“安徽省”,“合肥”部分匹配“合肥市”。 为了能够更加完整的获取地址行政区划信息,并体现本文方法能够有效解决行政区划特征字缺失、歧义等问题,实验采用完全匹配查询、完全匹配查询+部分匹配查询两种方式;并将原始语料与经过预处理的语料分别与两种匹配方式进行组合实验。 通过可信度计算方法获取可信度最大的区划结果作为地址字符串的地理定位信息。4种实验组合方式的具体实验结果见表1。 表1 可信度计算实验结果 本文通过设计计算方法,对地址行政区划信息进行辨识,4种实验方式的时耗相差不大且均可被接受,故重点讨论各组合实验方法的正确率。 (1)若匹配方式不变 均选择完全区划匹配查询时,会将原始地址集字符串中所有以行政区划命名的路街等信息过滤掉,同时也会忽略地址中省略特征词的字符串,故是否对数据进行预处理,对行政区划元素选择的正确率没有影响。 均选择完全+部分区划匹配查询,对原始数据而言,由于完全+部分匹配查询是对关键字进行匹配查询,会匹配得到产生干扰的行政区划,比如“南京路”将匹配成“南京市”,对结果的选择造成影响;而对于经过预处理的测试语料,已排除了上述干扰,并综合考虑了完全匹配、部分匹配及行政区划层次结构等因素,故结论具有较大的可确定性,且识别正确率高于单纯地选择最大行政区划的结果。 (2)若测试地址集不变 对于原始数据而言,因未对其作任何的预处理工作,其中包含较多冗余且易产生歧义的信息,故当采用完全+部分匹配方式时,会将部分命名实体或街道名等错误地识别为行政区划信息,给计算方法提供了错误信息,干扰了地址区划信息的识别,故导致识别准确率较低。 对于经过预处理,省略了低级区划信息的地址而言,排除了“路”特征字产生的干扰后,其所产生的歧义信息大多是由行政区划的模糊、缺失和不确定性导致了。当采用完全+部分匹配规则时,可以获取更多的行政区划信息,即增强了信息间的约束,并通过本文提出的计算方法,能够正确地识别出其实际指定的行政区划信息。 故在对测试语料进行预处理的基础上,采用完全+部分匹配方法能够更好地说明本文计算方法在针对解决行政区划信息模糊、缺失等问题上的优势。 通过对具体实验结果观察分析发现,在完善区划匹配词典的基础上,对于较为规范的地址有非常高的识别正确率,同时针对行政区划不完整且存在地址要素残缺的非规范地址,本文提出的证据可信度计算方法,能够较好地识别一般方法无法确定或识别错误的地址字符串中蕴含的地址区划信息。比如地址“中山东港新区金广东海岸滨城”,其中包含多个相互间存在冲突或关联的行政区划结论,见表2。 表2 地址行政区划结论 显然一般的地址匹配算法或要素解析规则是无法确定该地址的行政区划。究其原因在于,或地址中出现多个地址要素,或将命名实体错误的识别为地址要素。当多个地址要素代表的行政区划结论存在较大歧义时,无法确定其准确的信息。本文提出的可信度计算方法,通过公式计算的方法,选取地址中可信度较大地址要素代表的行政区划结论作为地址行政区划信息。通过本文的计算方法可以正确地确定地址“中山东港新区金广东海岸滨城”,指定的是“辽宁省大连市中山区”,且与实际情况相符。 本文计算方法虽然可以解析大部分规则或不规则的中文地址,但对于少量特殊的地址字符串,识别结果与地址实际位置信息依然存在偏差。针对原始地址语料识别失败的结果主要分为以下两种情况: (1)实际情况中存在单字行政区划,其将对地址字符串中行政区划信息的提取产生严重干扰。如地址:“江南区沙井大道”,其中“江南区”匹配行政区划“广西壮族自治区南宁市江南区”。但由于匹配词典中存在单字行政区划“南区”,无论正向匹配算法还是反向匹配算法[9],均会将“江南区”识别为“南区”,匹配行政区划“广东省中山市南区”等;同时由于地址字符串中无其它地理定位信息,导致无法准确获取该地址的地理位置信息。具体计算结果见表3。 表3 区划可信度计算结果二 (2)由于实验地址数据形式各异,其中存在大量非标准地址,如:“合肥市明光”。当对原始地址进行完全匹配时,得到行政区划“安徽省合肥市”;当对原始数据进行完全+部分匹配时,得到行政区划“安徽省滁州市明光区”。通过计算得到两种行政区划匹配结果的可信度,具体计算结果见表4。 表4 区划可信度计算结果三 由表4可知,本文计算方法将得到错误的行政区划识别结果。识别错误的主要原因在于,地址信息的识别产生歧义且该地址中并无其它区划信息以支撑相关结果。 本文计算方法主要解决“省市区”三级行政区划的信息提取,故若地址中包含路街等位置信息时,则可以将其忽略,即对语料进行预处理,以提高地址行政区划匹配精确度。由表1实验结果可知,当对测试地址语料中的“路”特征字进行预处理后,实验准确率有了显著提高,当采用完全与部分区划匹配方式时准确率达到94.81%。由此可见,当地址行政区划信息充足时,本文方法在解决地址行政区划信息模糊、缺失和歧义等问题是十分有效的。 通过分析中文地址解析方法在各种算法中的应用,将本文方法与基于特征字匹配方法、基于条件随机场方法和基于自然语言理解的地址识别方法进行对比实验。为了使实验方法根据说服力,将上述方法分别对本文经过预处理的地址数据测试集进行实验,具体识别结果对比见表5。 表5 识别结果比较表 采用基于特征字匹配方法的分词结果正确性通常取决于地址信息中是否有特征字符,若地址中没有出现能够区分“省市区”信息的特征字符,就会影响分词的正确性,故对于本文从互联网中获取的杂乱无章且存在行政区划缺失的地址,该方法无法识别,导致识别准确率很低。采用基于条件随机场算法,利用地址要素标注集进行人工标注,可以识别地址语料蕴含的位置信息,但识别性能一般,且需要耗费大量的精力对语料进行标注,方法的效率不高。目前采用的基于自然语言理解的方法具有较大的局限性,模型对训练语料依赖较强,针对互联网中大量杂乱无章的地址识别效果较差。本文提出的可信度计算方法,不仅效率高,同时可以通过有效的计算消除地址字符串之间存在的歧义,并完善地址行政区划信息。 互联网中地址文本错综复杂、杂乱无章,难以通过一种方式有效解决所有形式地址的地理位置信息提取问题。本文提出一种基于可信度模型的行政区划可信度计算方法,能够灵活处理不同结构地址的行政区划信息。利用移动窗口最大匹配算法对地址字符串进行行政区划匹配[12],在顾及中文地址语义的前提下,根据中文地址的表达特点,建立行政区划匹配规则和可信度计算方法,能够有效地处理引发歧义的行政区划信息,提高了中文地址行政区划解析的正确率和时效性。 在未来的工作中,可在此研究的基础上,进一步增加行政区划级别识别的级数,通过处理结构更为复杂的地址获取更为完善的地理位置信息。2.2 区划可信度计算方法
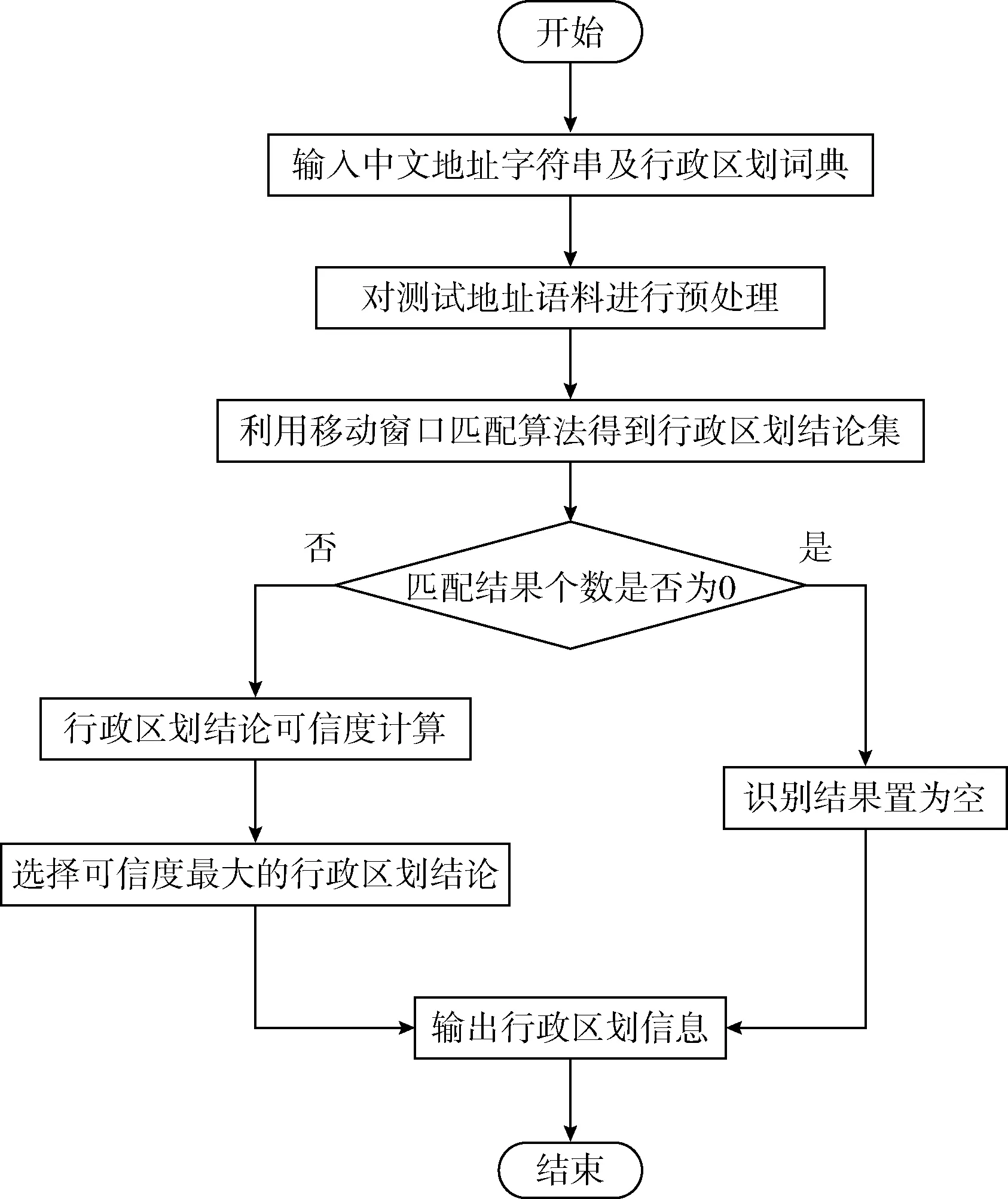
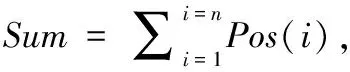
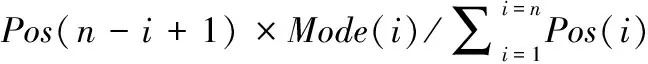
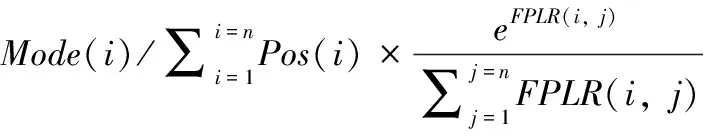
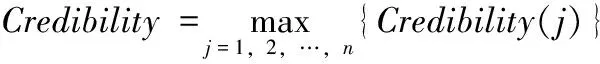
3 实验设计与分析
3.1 实验设计
3.2 实验结果与分析




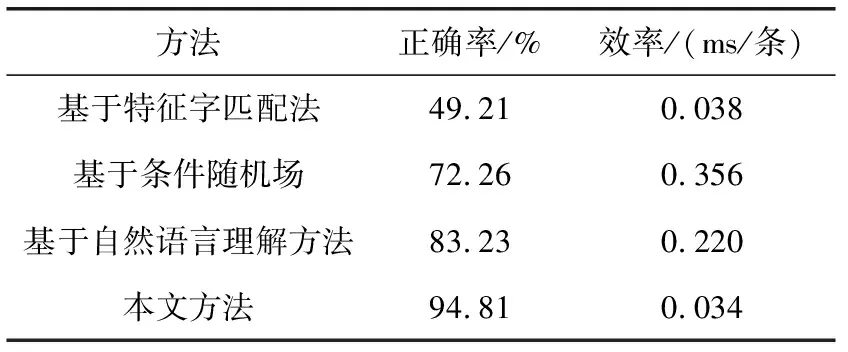
3.3 对比实验
4 结束语
