基于深度哈希的肺结节图像检索方法
2018-07-19宋云霞唐笑先
宋云霞,强 彦+,唐笑先
(1.太原理工大学 计算机科学与技术学院,山西 太原 030024;2.山西省人民医院 CT室,山西 太原 030012)
0 引 言
肺癌是当今死亡率最高的恶性肿瘤[1],主要原因是肺部疾病种类繁多且其影像显示上复杂多样,导致其难以诊断。此外,肺部疾病在影像学上存在同病异影和异病同影的现象[2],也为肺部疾病的诊断带来了困难。由于医学图像检索可以达到减轻医生工作负担以及另一方面增加诊断准确性的双重优势,因此,近年来大量学者在肺部影像检索上进行了相关研究并取得了一定的成果[3]。
图像哈希方法是一种快速的图像检索方法[4],不仅有效降低了相似度计算时间,同时也大大降低了存储量,在解决大规模计算机视觉问题中受到重视。但是由于图像哈希在检索精度方面很大程度上依赖于对数据库图像提取到的特征是否充分高效,通过传统的特征描述算子如:SIFT[5]、HOG[6]、Gist[7]、LBP[8]、HSV[9]等手工所提取到的图像特征或其融合特征已经不适于当前大数据时代下的高精度需求了。
鉴于深度学习在特征提取方面的优势,本文首先利用卷积神经网络将图像特征进行充分提取,然后通过改进的有监督哈希对高维特征进行降维并且学习哈希函数,进行哈希编码,最后再借鉴由粗到精的检索思想[10],提出一种图像检索方法。
1 提取图像深度特征
对肺结节CT图像的检索的精确度取决于对结节图像的特征能否进行充分有效的提取,能否最大限度地表征结节图像中所包含的信息。然而目前手工提取的特征已经不能满足检索的高精准度需求。随着大数据时代的到来,含更多隐含层的深度卷积神经网络(convolutional neural networks,CNNs)因具有更复杂的网络结构[11],相比于传统学习方法具有更为强大的特征学习和表达能力。本文将采取CNNs的网络结构对肺结节图像进行特征提取。本文所采用的数据库为全球最大的肺部影像数据库LIDC,北京理工大学与权威医师合作创建的LISS数据库,以及合作医院所提供的肺部CT数据集。通过对结节图像减去图像均值进行预处理并将其输入到网络中,对9种肺结节征象类型包括GGO(磨玻璃)、Spiculation(毛刺征)、Lobulation(分叶征)、Cavity&Vacuolus(空泡)、Calcification(钙化)、Pleural Dragging(胸膜牵拉)、Bronchial Mucus Plugs(支气管黏液栓)、Obstructive pneumonia(阻塞性肺炎)、Air bronchogram(支气管充气征)进行分类,不断训练网络直到稳定最优为止,将全连接层的特征提取出来用于本文下一步的图像检索阶段。图1为9种征象类型的肺结节图像,图2为CNNs的网络架构,表1中给出了CNNs架构中设置的具体参数。

图1 9种征象类型的结节图像
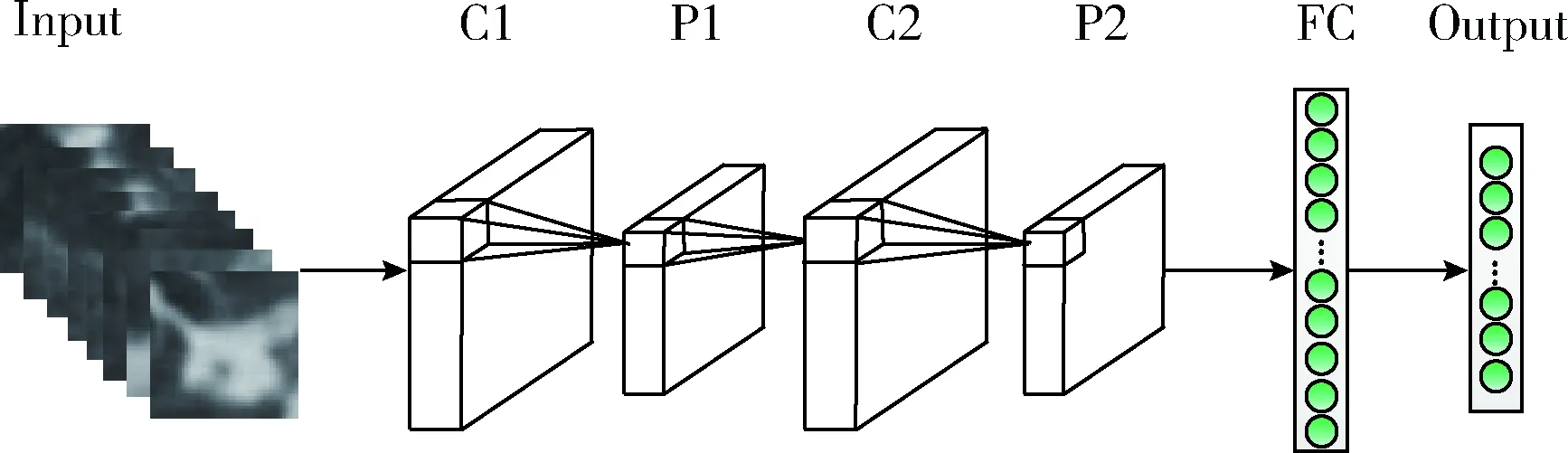
图2 CNNs网络架构
2 稀疏有监督哈希
2.1 PCA稀疏降维
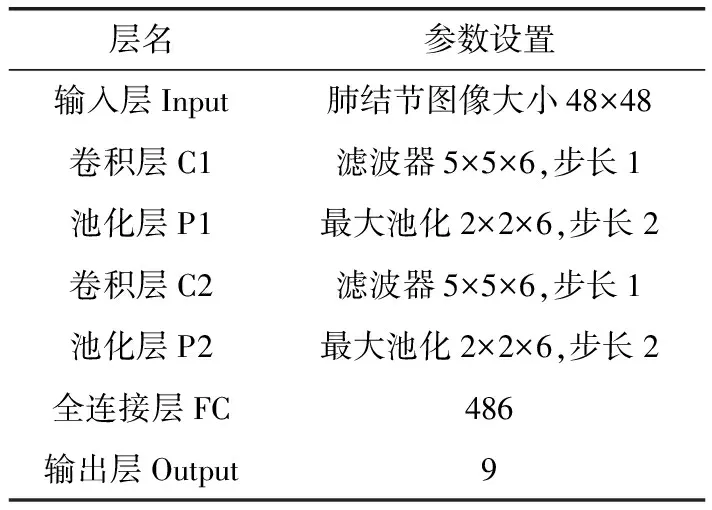
表1 CNNs框架中的参数设置
前面的部分中CNNs对结节图像的特征进行了充分的提取,但是提取到的特征维度太高,并且其中存在特征冗余的情况,会直接影响后续哈希函数的构建以及检索的精度及速率。针对此问题,本文采用主成分分析算法(principal components analysis,PCA),具体算法如下:
PCA算法:
输入: CNNs提取到的肺结节图像特征矩阵X
输出: 降维后的特征矩阵Y
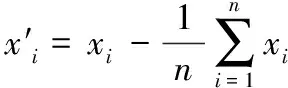

步骤3 对C进行奇异值分解计算其特征值λi和特征向量ei
步骤4 构建特征子空间, 将特征值降序排列, 将前k个特征值对应的特征向量结合构建特征子空间Ω=(e1,e2,…,ek)
步骤5 得到降维后的特征矩阵:Y=ΩX′
2.2 KSH_PCA
利用哈希函数将2.1节所提取到的肺结节的主要语义特征映射为二值哈希码。为保存肺结节图像在线性子空间中的相似性,哈希函数的设计尤为关键,其一般形式如式(1)所示,若哈希码的长度为r,则须设计r个哈希函数,即H={h1,h2,…,hr}
(1)
式中:w为系数向量,需要学习。b表示偏差,为产生均衡的哈希码,通常将b赋值为样本集中全部图像特征的期望值,由于在2.1节中对图像特征已经进行了零均值化操作,所以将b赋为0,之后用PCA降维后的特征yi代替式(1)中的xi,将其简化为如下的式(2)
(2)
然后借鉴KSH(supervised hashing with kernels)方法的思想[12],利用肺结节图像的标签信息求解哈希函数中的系数向量 [w1,w2,…,wr], 求解过程如下:
(1)通过标签信息来表征样本间的语义相似性,利用l个标签样本构建标签矩阵S∈Rl×l, 若样本xi与xj相似,则Sij=1,否则Sij=-1;
(2)哈希算法的目标是经哈希函数映射后,使得相似样本的汉明距离最小,反之最大。根据汉明距离与哈希码内积的对应关系,发现相似样本(Sij=1)的哈希码内积最大为r,不相似样本(Sij=-1)的哈希码内积最小为-r;
(3)
(4)使用贪婪算法求解目标函数,完成哈希函数的构造,最后使用构造好的哈希函数对肺结节图像进行映射。
本文提出的稀疏有监督哈希算法通过PCA算法保留肺结节图像中的主要信息特征,使得经哈希函数映射得到的哈希码含有原数据集中的主要信息,减少了映射误差;利用KSH保留了肺结节图像在高维空间的相对位置关系,能够有效区别不同征象类型的肺结节图像,提高了哈希函数的编码质量。
3 查询样本检索
2.2节已经完成了哈希函数的构造,将已有数据库与检索图像通过哈希函数映射为二值哈希码,再比较哈希码之间的距离即可找到与检索图像为相似的图像。然而在检索结果中会存在多张肺结节图像与查询图像的汉明距离相等,但实际上它们与查询结节图像并不一定都相似的情况,如图3所示。若此时将检索结果返回,会导致检索结果的不准确。由于本文采用的PCA映射的哈希方法保留了欧式空间的ε近邻关系,所以为解决上面这个问题,本文采取了加入欧氏距离进一步精确检索的处理。

图3 汉明距离相等而不相似情况
本文采取的方法为首先为各个征象类构建哈希表,然后计算待检索结节图像与各征象类中心的距离,确定查询图像可能属于的候选征象类。这里,为了提高检索的查全率,本文选取距离最小的前m个征象类作为待检索结节所属的候选类。然后根据KSH_PCA算法获得的候选征象类别的哈希函数对查询图像编码,并从候选类的哈希表中检索出近似的肺结节CT图像,最后使用欧式距离进行重新排序进行精确排序。由粗到精的检索算法的肺结节检索过程如图4所示。
由粗到精的检索算法的详细步骤如下:
由粗到精的检索算法:
输入: 待检索肺结节CT图像q
检索过程:
(1)确定查询项q可能属于的m个候选征象类
(2)确定查询项q的m个候选近似结节图像
根据候选类别C1,C2,…,Cm中的哈希函数为查询项q编码为code1,code2,…,codem, 将这些编码与对应类别的哈希表中的所有哈希码进行汉明距离的计算, 分别从这m个征象类中选取汉明距离最小的数据项作为候选近似肺结节(candi)1,(candi)2,…,(candi)m。
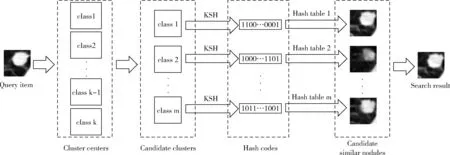
图4 肺结节检索过程
(3)检索出最近似结节图像
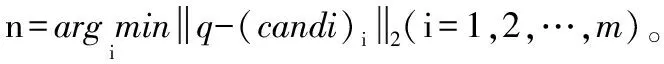
输出: 近似肺结节图像(candi)1,(candi)2,…,(candi)n。
4 实验结果与分析
4.1 数据集
本实验所根据的共1053个肺部CT影像病例,由3类数据源构成:LIDC数据库、LISS数据库以及合作医院肺部CT影像数据集。其中,LIDC是全球最大的肺部影像数据库[13]。LISS是北理工与权威医师共同合作对肺部征象进行专业准确标注的肺部CT影像数据集[14],合作医院为山西某医院CT室。表2具体描述了本文所使用的肺结节CT影像数据集构成。其中,每个病例是否具备9种征象均有详细专业的标注。另外,本实验为了确保训练集与测试集之间不存在相关性的干扰,使用数据集来源为LIDC与LISS的肺部CT图像作为训练集,来源为合作医院数据集的肺部CT图像作为测试集。
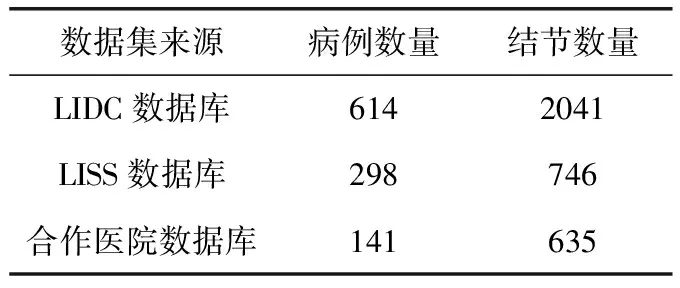
表2 数据集来源及数量的描述
4.2 实验评价标准
本文所设计的性能评价指标为F1。
F1是由准确率和召回率组合得到的一种综合评价指标。准确率P和召回率R的具体计算公式如下
(4)
(5)
F1的计算公式如下
(6)
4.3 实验结果
本文与其它5种算法包括KSH[12]、RBM(restricted Boltzmann machines)[15]、E2LSH[16]、PCAH[17]、SH(spectral hashing)[18],说明本文提出的方法的检索性能。
表3展示了6种算法在数据集上对比结果,表4展示了6种算法的运行时间。此运行时间表示每种算法在对CNNs提取到的特征生成8~64位哈希码所需时间,其中为避免特殊性,每种算法分别做5次实验,取5次运行时间的平均值。k为索引的位数,每种索引位数下的最佳结果在表中已用黑体标注。

表3 数据集上的实验结果

表4 算法编码运行时间对比表/s
由实验结果看出,本文提出的由粗到精检索的算法的表现在本文数据集上优于其它算法。但是本文算法仍然存在一定的局限性,表现为对哈希码位数的敏感度较高。当哈希码长不小于32位时,F1有随着哈希码位数的增加而下降的趋势,在码长达到64位时甚至低于码长为24位的结果。究其原因是由于哈希码位数达到一定长度后,返回相关的结节图像数量大幅下降,虽然返回所有结节图像数量也会下降,但是与前者相比而言,下降程度较小。因此,召回率大幅下降,准确率小幅下降,F1指标下降。
此外,由表4可得,本文提出的方法不具有最高的运行速率,综合检索结果,可认为本方法具备最好的时间效果比。
4.4 性能比较
本文方法用哈希码对肺结节图像库中的CT图像进行表示,相比于传统的利用提取到的图像特征对图像进行表示的传统方法,本方法的图像数据库占用内存更小,检索速度更快。其中,r=32时,检索一张结节图像的5次平均时间为1.683 s。图5展示了待检索结节图像、恶性结节图像和良性结节图像(黑框标注)以及在哈希码位为32,返回图像张数为30,ε近邻半径为0.3时检索出的前5张肺结节CT图像。
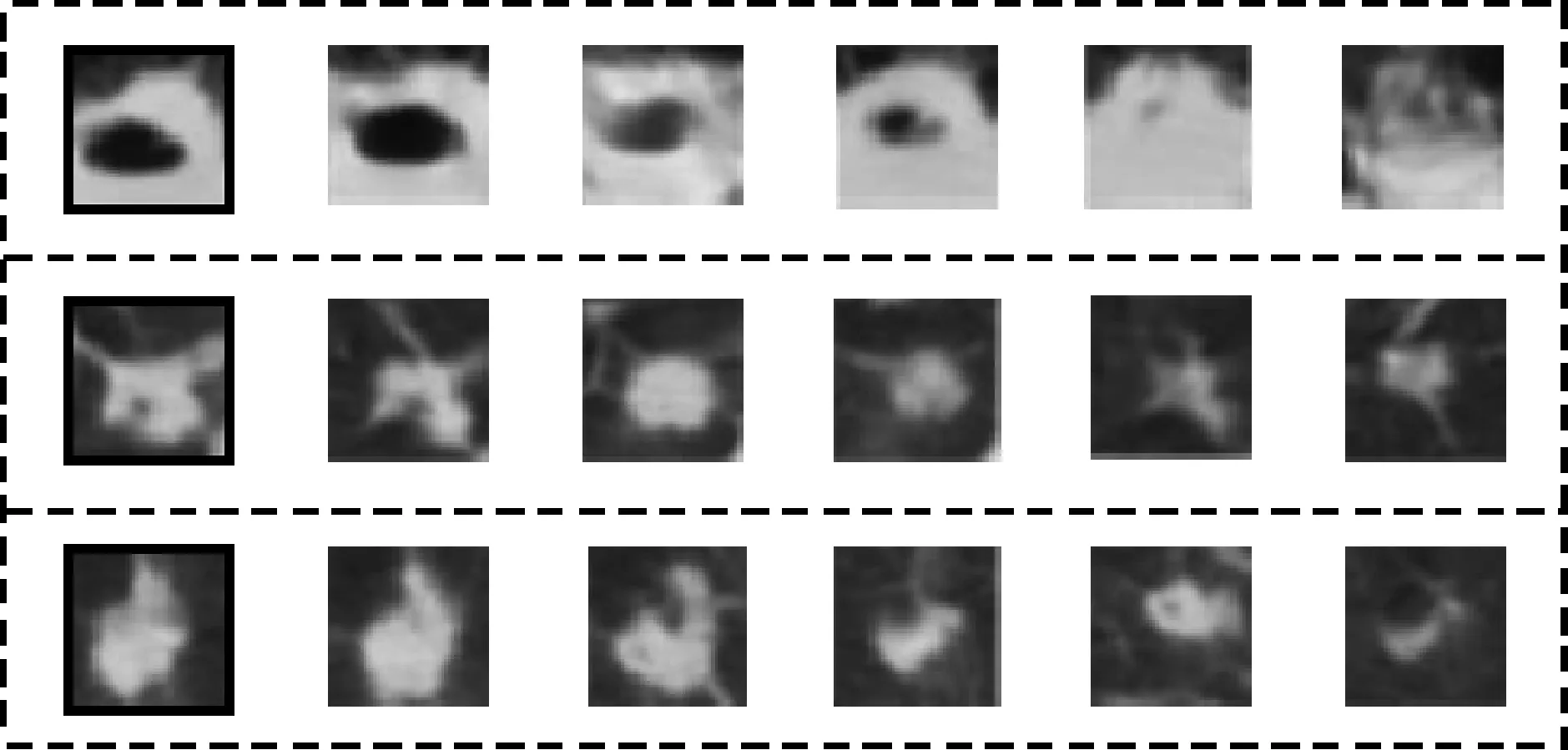
图5 查询图像以及相应的检索结果
根据检索的相似肺结节图像可以判定查询病灶所属的征象类别。本文根据KNN算法[19],在检索出来的相似肺结节CT图像中,若Pleural Dragging结节图像所占比重较大,则查询病灶所属征象类型为Pleural Dragging。本文对比了提出的检索方法与SVM(support vector machine)[20]、ELM(extreme learning machine)[21]分类算法,分别在含有9种征象类别图像、良性结节图像和恶性结节图像进行比较。识别的准确率和误识率是评价识别算法性能的有效指标,其定义如式(7)、式(8)所示。图6和图7分别展示了这3种方法在数据集中的9种肺结节征象类上的识别准确率和误识率
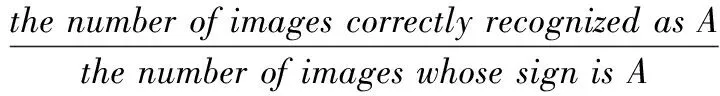
(7)
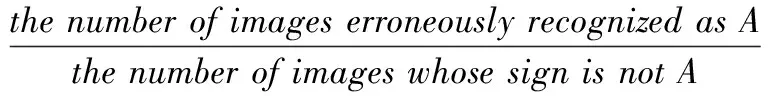
(8)
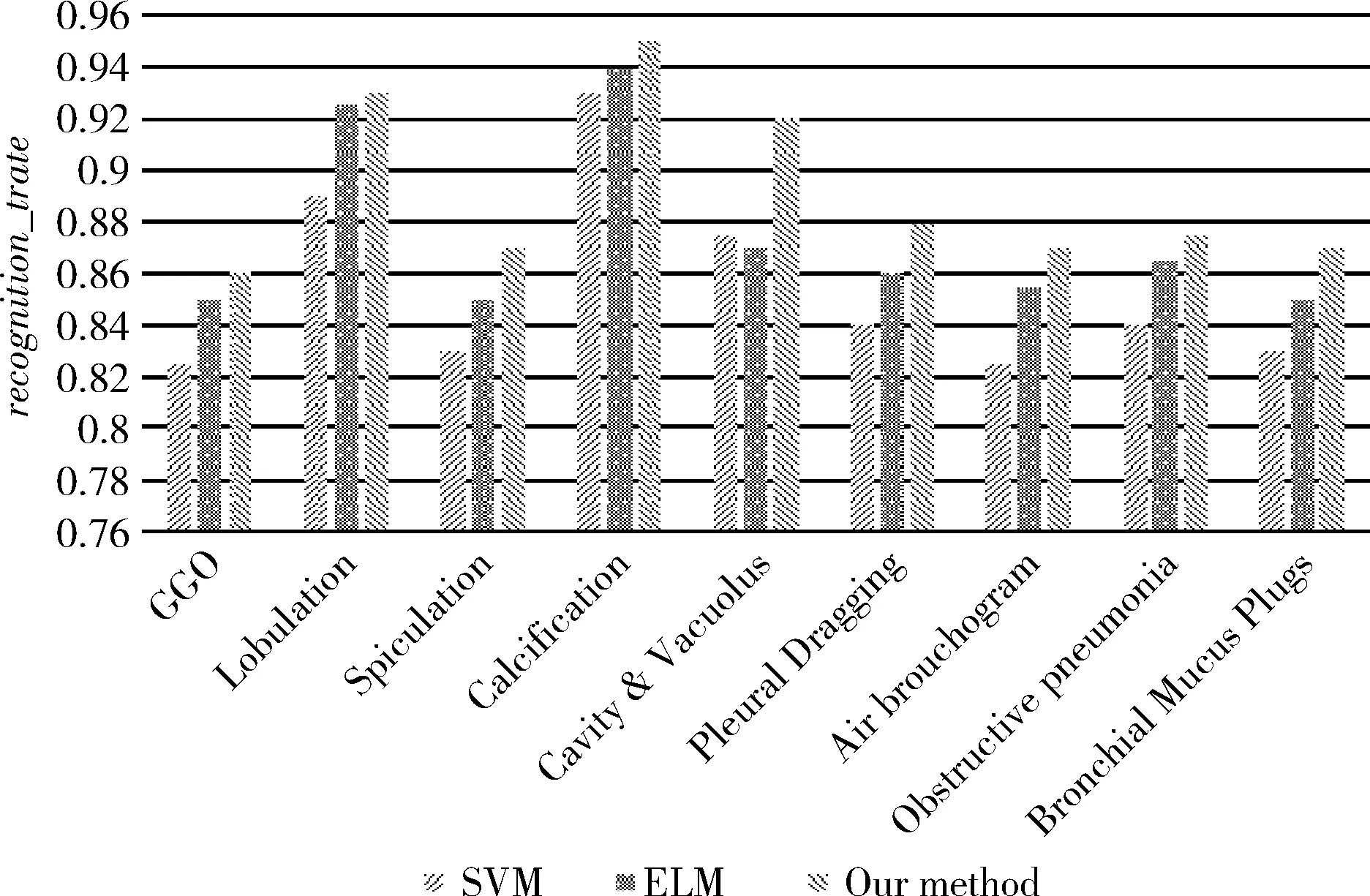
图6 不同分类方法的识别准确率
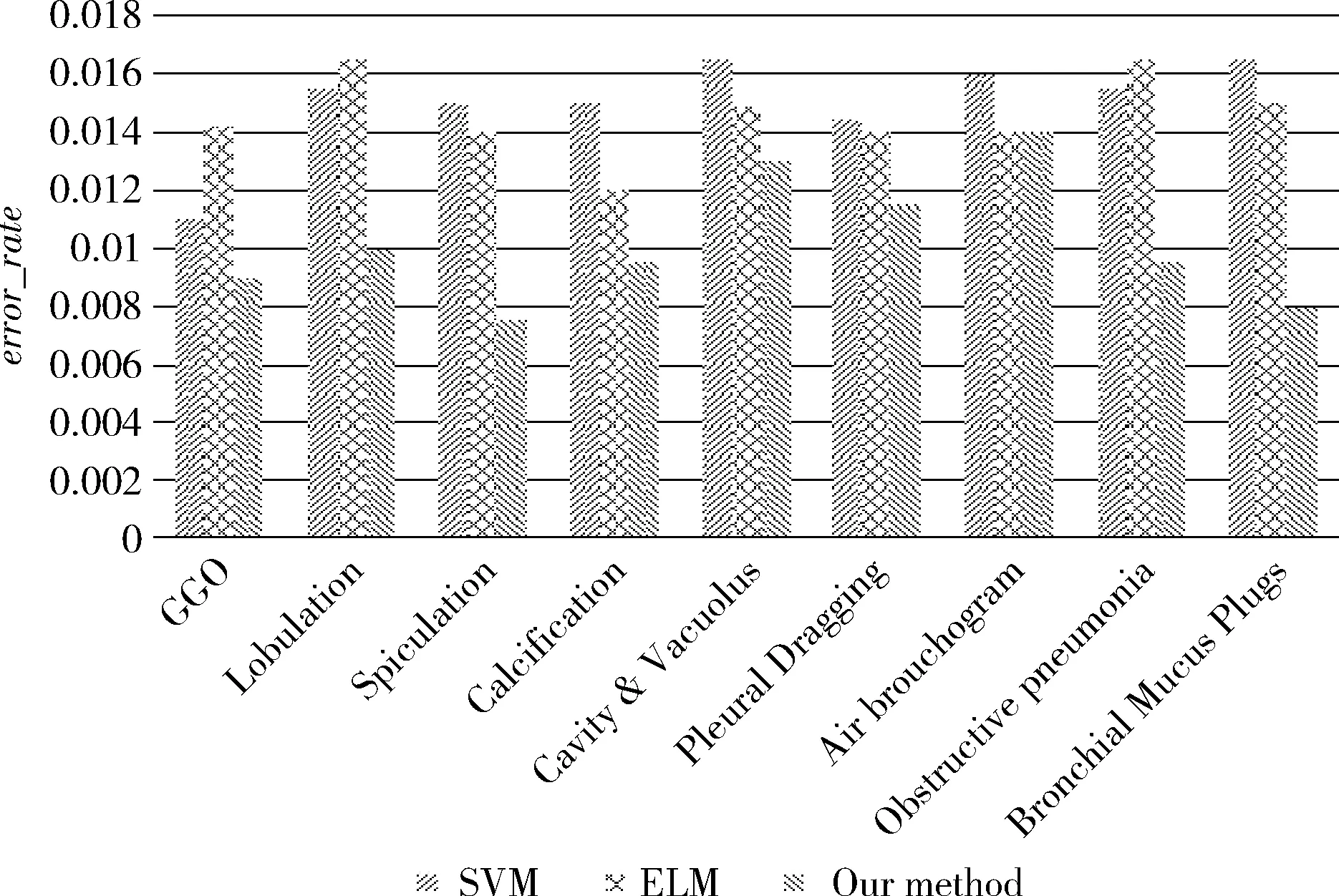
图7 不同分类方法的误识率
5 结束语
本文提出一种基于深度哈希的肺结节CT图像检索方法。首先利用一个7层的卷积神经网络将结节图像特征进行充分提取,然后通过改进的有监督哈希对高维特征进行降维并且学习哈希函数,进而哈希编码,最后再经过由粗到精的检索方法,实现对肺结节图像的有效检索。对3422张肺结节CT图像的实验结果表明,本文所提出的深度哈希算法,在区分肺结节常见9种征象类别上具有良好的判定识别效果。并且本文算法具有检索精度高与占用内存小的优势,在肺结节CAD诊断上具有可应用性与可推广性。下一步工作我们将在算法效率优化上做进一步研究。
