基于情感直方图特征的中文文本情感分类方法
2018-07-19李跃新
韩 毅,张 涵,李跃新
(1.安阳工学院 计算机科学与信息工程学院,河南 安阳 455000;2.华中科技大学 国家数控系统工程技术研究中心,湖北 武汉 430000;3.湖北大学 计算机工程与通信学院,湖北 武汉 430000)
0 引 言
本文主要考虑中文文本的情感分类问题,目前中文文本情感分类方法也比较多,主要分为两类:基于有监督学习的情感分类方法和基于语义理解的情感分类方法[1-13]。前者主要是通过文本数据的有监督学习来进行情感分类,如文献[11]研究基于机器学习的中文微博情感分类方法,提取文本的信息增益和词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)特征,采用支持向量机和贝叶斯分类算法进行学习和分类,对微博评论的情感分类效果较好。但此类方法的分类精度与训练样本的完备性关系较大。后者的核心是分析文本中词汇的语义特征,通过理解词汇的情感来实现文本情感的分类。如文献[12]结合粒子群优化(particle swarm optimization,PSO)和高斯处理(Gaussian process,GP)构建PSO-GP分类模型。对于文本数据抽取的情感词典,经过特征筛选、数据降维及TF-IDF特征提取,生成情感特征向量,将特征向量输入PSO-GP分类模型得到情感分类结果。此类方法可以对不同领域的文本进行情感分类,但易受词汇的句式与搭配的影响而降低分类正确率。目前多数情感分类方法是将这两类方法进行融合,基本思路是先提取文本中的情感特征,然后再采用机器学习方法进行训练和分类。如文献[13]提出了一种基于多特征融合的中文情感分类方法,其核心是提取每一个情感词汇的情感极性得分,并将每一个主观情感词汇对3种极性的情感极性得分的平均值作为情感词汇的情感特征。然后采用机器学习方法中的支持向量机进行特征的训练与分类,可以很好地实现产品和服务评论的情感分类。然而,该方法还存在3个问题:第一,该方法将情感词汇对3种极性的得分进行平均,这样可能弱化情感特征对每一种极性的表达能力。第二,该方法所描述的主观情感词汇的情感特征相互独立,没有表达情感词汇之间的关联关系。第三,该方法再对主观词汇和客观词汇进行划分是采用固定阈值方法,容易出现错分现象。针对这些问题,本文对文献[13]所述方法进行优化,在情感极性得分的基础上,借鉴图像处理领域的直方图概念,提出一种情感直方图特征,用于中文文本的情感分类。本文方法的主要创新点在于:①以情感词汇对各个极性的情感极性特征为输入,采用BP神经网络训练主观词汇与客观词汇分类器,可以有效降低文献[13]采用固定阈值法引起的词性错分现象。②在情感极性得分特征的基础上,将图像处理领域常用的直方图特征引入文本特征提取领域,提取文本的情感直方图特征,不仅可以包含情感词汇对不同极性的情感表达特征,而且涵盖了情感得分的整体分布特性,可以更充分地描述不同文本的情感差异,提高情感分类正确率。
1 基于多特征融合的中文情感分类方法
文献[13]提出了一种基于多特征融合的中文情感分类方法,该方法融合了3种特征,包括:无内容特征、领域特征和情感特征,简要介绍如下:
(1)无内容特征
文献[13]使用的无内容特征共有250种,包括词汇特征87种、句法特征158种和结构特征5种。
(2)领域特征
文献[13]在提取邻域特征前先对词汇进行分类,将词汇分为领域相关词汇和非领域相关词汇两类。在此基础上,分别构造两类词汇的模式和词汇集合。具体地,依据特征和极性词模式的共现频率构造模式集合,依据标注词性构造词汇集合。其中,考虑到分类结果与词典的完整性密切相关,文中采用二次模式抽取策略完善词典构建。
(3)情感特征
文献[13]将形容词、副词和动词3类词当作情感词汇,提取情感特征。具体实现时,先采用HowNet情感词典计算每一个情感词汇W的正面情感倾向值,公式为
(1)
式中:j表示词汇的极性,j∈{正面,负面,客观};Nj表示极性j对应的基准词数量,WPji表示极性j对应的基准词集合中的第i个基准词。sim(W,WPji)表示情感词汇W与基准词汇WPji之间的相似度。
然后,分别对情感词汇对3种极性的分数,公式为
(2)
式中:POS∈{形容词,副词,动词}, 集合S表示W=POS且W极性为i的词汇构成的集合。|S|表示集合S中的词汇数量。
将情感词汇对3种极性的得分进行平均,得到情感词汇的情感极性分数,公式为
(3)
文献[13]依据情感词汇的情感极性分数构建情感特征集合。其中,使用阈值分割思想,将情感词汇分为主观词汇(情感极性分数不大于0.5)和客观词汇(情感极性分数大于0.5),只提取主观词汇的情感特征。
2 本文方法
本文借鉴文献[13]提出的情感极性得分特征,在此基础上提出了情感直方图特征,不仅可以包含情感词汇对不同极性的情感表达特征,而且涵盖了情感得分的整体分布特性,可以更充分地描述不同文本的情感差异,有益于中文情感分类。同时,本文采用BP神经网络训练主观词汇与客观词汇分类器,能够有效降低文献[13]采用固定阈值法引起的错分现象。另外,本文采用随机森林学习方法构建情感特征分类器,可以实现多类情感分类,应用场合更广泛。本文方法的实现流程如图1所示,其中虚线箭头指代训练流程,实线箭头指代测试流程,主要包括文本分词、词性筛选、情感极性得分计算、主观词汇与客观词汇分类、情感直方图特征提取和特征训练与分类6个部分。详细描述如下。
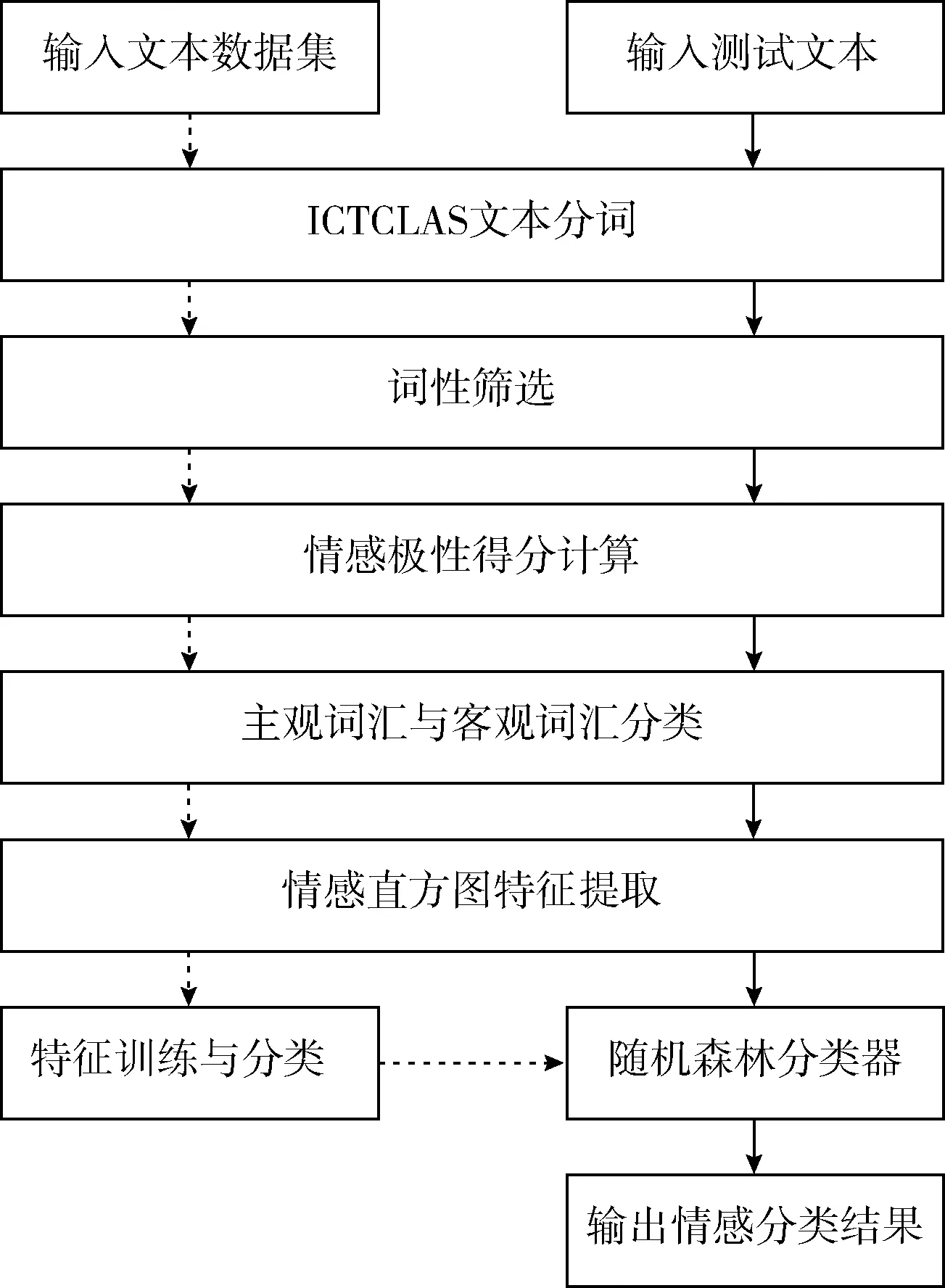
图1 情感分类实现流程
2.1 文本分词
在中文文本分词领域,常用的是中国科学院计算机研究所张华平等开发的ICTCLAS中文分词系统,也称为NLPIR中文分词系统。该系统采用层叠隐马尔科夫模型进行分词,并对词性进行标注。本文采用该系统进行文本分词,将每一个文本都转换为一个不同词性的词汇集合。
2.2 词性筛选
通常,文本分类系统只需要去除停用词等对文本内容意义不大的词汇。而对于情感分类而言,文本中所存在的大量描述文本主题内容的名词等词汇,会对情感分类产生很大的干扰,尤其是在不同主题的文本的情感分类问题。对于情感分类而言,起主要作用的是形容词、副词和动词3类词性[13]。因此,本文在词性筛选阶段只保留分词之后的形容词、副词和动词3类词性的词汇集合。
2.3 情感极性得分计算
文献[13]提出了一种情感词汇的情感极性得分的计算方法。如上一节所述,文献[13]首先采用HowNet情感词典,计算每一个情感词汇的正面情感倾向值。然后,分别计算形容词、副词和动词3类情感词汇对正面、负面和客观3类极性的情感极性得分,如式(2)所示。文献[13]通过实验表明,情感极性得分能够有效反映情感词汇所要表达的情感类别。因此,本文也采用情感极性得分作为情感词汇的特征表达。
2.4 主观词汇与客观词汇分类
一般地,词汇有主观词汇和客观词汇之分,主观词汇是表达用户情感的主要手段。文献[13]在获取了每一个情感词汇的情感极性得分之后,将情感词汇对3种极性的得分进行平均,得到情感词汇的情感极性分数,如式(3)所示。然后使用阈值分割思想,将情感词汇分为主观词汇和客观词汇两类,只提取主观词汇的情感特征。
然而,将情感词汇对3种极性的得分进行平均可能弱化情感特征对每一种极性的表达能力。而且,主观词汇和客观词汇很难通过平均情感极性得分进行严格区分,故采用固定阈值(文献[13]中阈值为0.5)分割的思想区分主观词汇和客观词汇尽管能够提升特征对用户主观评价的表达能力,但也会由于主观词汇和客观词汇的错误分类而产生特征区分能力下降的问题。
为了降低主观词汇和客观词汇分类的错误率,本文采用BP神经网络构建词汇分类器,用于对主观词汇和客观词汇进行分类。实现方法是:
首先,为了避免平均情感极性得分可能弱化情感特征对每一种极性的表达能力的现象,本文将每一个情感词汇对3种极性的3个情感极性得分组建成一个三维的情感极性特征向量。
然后,设计一个三层的BP神经网络,也即一个输入层、一个隐藏层和一个输出层。输出层的输出类别有两类,即主观词汇和客观词汇。输入层由每一个情感词汇的三维情感极性特征向量组成。
在训练阶段,将训练样本集中的所有情感词汇的三维情感极性特征向量以及标记的词汇类别标签送入BP神经网络,学习网络中的连接权重和偏置项参数。本文采用Matlab中自带的BP神经网络来实现分类器的构建,其中,隐藏层传递函数选择tansig函数,学习速率设置为0.05,最大迭代次数设置为1000,误差设置为1e-5。
2.5 情感直方图特征提取
文献[13]将每一个主观情感词汇对3种极性的情感极性得分的平均值作为情感词汇的情感特征。存在的问题是:第一,将情感词汇对3种极性的得分进行平均可能弱化情感特征对每一种极性的表达能力。第二,每一个主观情感词汇的情感特征相互独立,没有表达情感词汇之间的关联关系。针对这两个问题,本文将图像领域的直方图特征引入文本情感词汇分类领域,描述情感特征的空间分布特性。基本思路是:将每一个文本视作一幅图像,将每一个情感词汇视作图像中的一个“像素点”,将正面、负面和客观3种极性视作图像中的3个“颜色通道”,将每一个情感词汇对每一个极性的情感极性得分视作该情感词汇在每一个“颜色通道”上的“像素值”。
对于每一个文本数据,计算其在3个“颜色通道”上的情感直方图特征。下面以任意一个“颜色通道”为例,介绍其情感直方图特征的提取步骤,具体为:
步骤1 对于上一小节分类为客观词汇的情感词汇,将其对应的“颜色通道”的“像素值”都置为1;
步骤2 为了便于进行直方图统计,对“像素值”进行离散化处理。具体地,统计“颜色通道”上“像素值”的最小值,记为vmin。假设离散化后的“像素值”的“灰度级”为L,那么,“像素值”v离散之后的值为
(4)
式中:Int(·)表示取整运算。
由于v∈[vmin,1], 因此离散之后“像素值”的分布范围为[0,L-1]。
“灰度级”L越大,情感特征的细节区分能力越强,但同类情感特征的类内一致性越差。本文将在实验部分测试 “灰度级”L不同时情感分类正确率指标,据此选择最优的“灰度级”L。
步骤3 统计每一个“像素值”所对应的“像素点”数量,用其除以“像素点”总数(也即某一极性的情感词汇的总数)N,得到该“像素值”的分布概率(这里用频率近似),表示为
(5)
式中:Ni表示“像素值”为i的“像素点”数量。
步骤4 将所有“像素值”的分布概率串联在一起,得到该“颜色通道”的直方图特征,记为P{正面or负面or客观}={pi|i=0,1,…,L-1}, 维数为L。
这样,每一个“颜色通道”都可以提取一个维数为L的直方图特征,将3个“颜色通道”的直方图特征串联在一起,得到文本的情感直方图特征,记为F={P正面,P负面,P客观}, 维数为3L。本文提取的情感直方图特征不仅包含了情感词汇对不同极性的情感表达特征,而且涵盖了情感得分的整体分布特性,可以更充分地描述不同文本的情感差异。
2.6 特征训练与分类
对于提取到的情感直方图特征,需要采用机器学习方法进行学习,构建一个特征分类器,实现文本的情感分类。与文献[13]相同,本文也采用支持向量机分类器进行特征的训练与分类。该分类器是一个二元分类器,可以将文本分为好评(正面评价)和差评(负面评价)两种情感。
3 实验与分析
3.1 实验环境
(1)语料库构建
本文仿照文献[12]的语料库构建方法,采用网络爬虫工具,从淘宝(www.taobao.com)、京东(www.360buy.com)、国美(www.gome.com.cn)和苏宁(www.suning.com)4个网站上下载关于空调的评论,按照用户的打分标记评论的情感属性,其中,3分以下或者三颗星以下的评论的情感属性标记为负面,其它评论的情感属性标记为正面,具体见表1。
后续实验将在TB、JD、GM和SN这4个语料库上进行。对于每个语料库,随机选取90%的样本用于训练,其余样本用于测试,采用Weka挖掘工具进行10-fold交叉验证方式测试情感分类方法的性能,10次验证结果取平均值作为最终实验结果。

表1 语料库信息
(2)评价指标
情感分类方法常用的评价指标有3个,分别是查准率(precision)、召回率(recall)和微平均(F1),详见文献[12]中定义。查准率用于评价分类器的准确性,召回率用于评价分类器的完备性,两者是负相关的,一个指标的提升会引起另一个指标的下降。而微平均是对查准率和召回率的综合评价,定义为
(6)
其中
(7)
(8)
其中,true(cj)表示正确分类为cj的文本数量,response(cj)表示分类结果为cj的文本数量,doc(cj)表示文档中类别为cj的文本数量,C={+1,-1}表示类别集合,“+1”表示正面评价,“-1”表示负面评价。
因此,本文采用微平均F1对情感分类器的性能进行综合评价。
(3)对比方法与实验平台
考虑到本文是对文献[13]的改进,主要改进了特征提取部分和词汇词性的分类部分。因此,对比实验时主要是与文献[13]所述方法进行对比,首先对比主观和客观词汇的分类性能,然后综合对比不同方法的情感分类性能。为了更充分地验证本文方法的性能,本文还选择了近三年相关的两种方法(见文献[11]和文献[12])进行对比。为了公平起见,4种方法实验所用的语料库、实验平台和交叉验证方法都是相同的。实验平台主要参数为:Windows 7操作系统、Intel Core-i5 CPU 3.20 GHz、16 G DDR3 内存、Matlab 2012软件平台。在进行对比实验之前,先对本文方法涉及的重要参数进行实验分析。
3.2 参数分析
本文方法涉及的重要参数是情感直方图特征提取阶段使用的“灰度级”L。理论上,“灰度级”L越大,情感特征的细节区分能力越强,但同类情感特征的类内一致性越差。为了选择最优的“灰度级”,本文在TB语料库上实验了“灰度级”取值不同时评价指标F1的变化曲线,如图2所示。
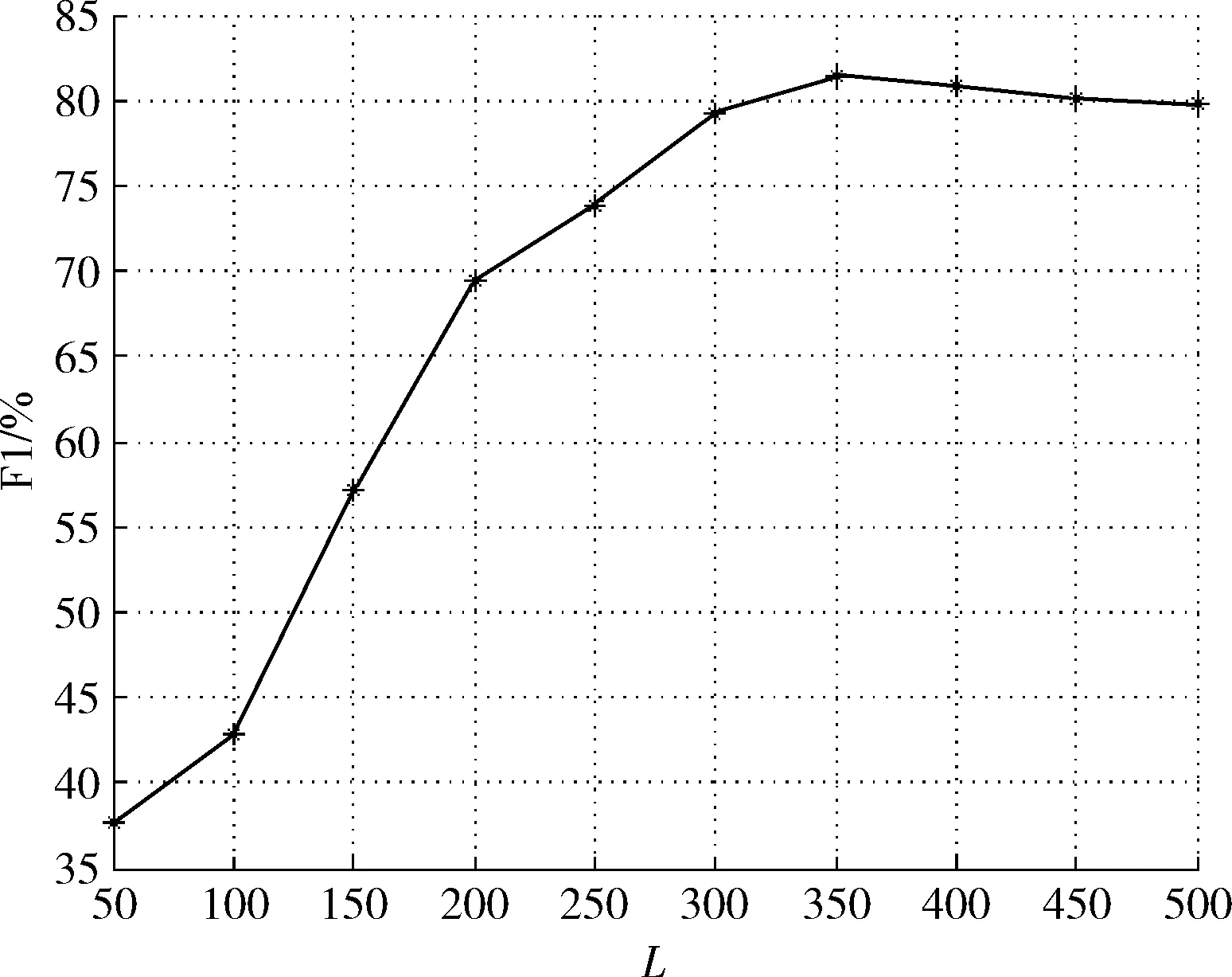
图2 F1随L的变化曲线
由图2可见,“灰度级”L=350时,F1达到峰值81.4%,因此,本文取“灰度级”L=350。
3.3 主观和客观词汇分类实验
本文在上一节指出,主观词汇和客观词汇很难通过平均情感极性得分进行严格区分,故文献[13]采用固定阈值分割的思想区分主观词汇和客观词汇往往存在错分现象。本文采用BP神经网络构建词汇分类器,用于降低主观词汇和客观词汇的分类错误率。如图3所示,给出了本文方法和文献[13]所述方法对主观词汇和客观词汇的分类错误率对比结果。
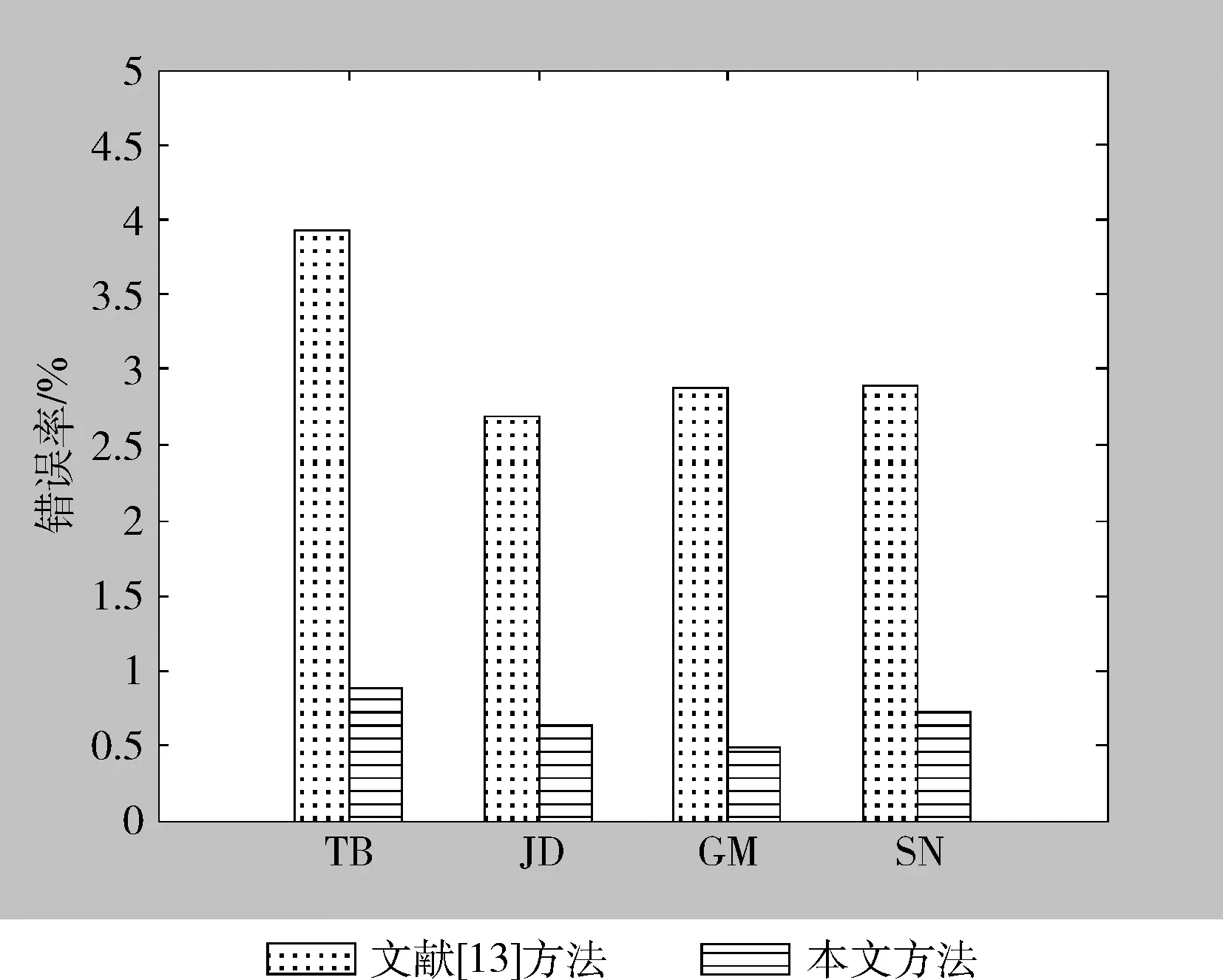
图3 主观和客观词汇分类错误率对比
由图3可见,在4个语料库上,本文方法对主观词汇和客观词汇的分类错误率都低于文献[13]所述方法,这也验证了在主观词汇和客观词汇分类方面,BP神经网络优于固定阈值。
3.4 情感分类实验
下面对本文方法和文献[11]~文献[13]所述方法进行情感分类对比实验,实验结果如图4所示。
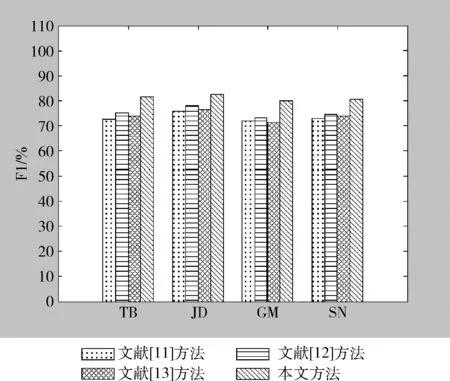
图4 不同方法F1性能对比
由图4可见,本文方法在4个语料库下的F1指标都高于其它3种方法。与文献[11]所述方法相比,本文具体针对情感词汇提取情感直方图特征,与信息增益和TF-IDF特征相比,更能体现词汇的情感特性。与文献[12]所述方法相比,本文的情感直方图特征比单纯的情感词典更能反映情感词汇之间的联系,在训练语料库相同的条件下,本文采用的支持向量机分类器的泛化能力优于PSO-GP分类模型。与文献[13]所述方法对比,本文采用BP神经网络降低了词汇词性分类错误率,采用情感直方图特征提升了情感极性得分特征的表达能力,并利用了词汇之间的情感极性得分的关联关系,从而最终提升了情感分类性能。
4 结束语
中文情感分类用于挖掘用户的情感信息,是大数据技术的研究热点之一。文献[13]使用的情感极性得分特征能有效表达词汇的情感倾向,对于情感分类很有意义。本文主要针对文献[13]所存在的词性分类错误率偏高,以及情感极性得分特征对每一种极性的表达能力偏弱和无法表达情感词汇之间关联关系的问题,借鉴图像处理领域的直方图概念,提出了一种基于情感直方图特征的中文情感分类方法。该方法采用BP神经网络降低主观词汇与客观词汇的分类错误率,通过情感直方图特征和支持向量机分类器提升情感分类性能,在对商品评论的情感分类实验中取得了比对比方法更好的分类效果。下一步研究将从多特征融合的角度,深入挖掘更充分的情感词汇特征,进一步提高情感分类性能。
