多特征因子融合的引文推荐算法
2018-07-19陈志涛李书琴何进荣
陈志涛,李书琴,刘 斌,何进荣
(西北农林科技大学 信息工程学院,陕西 杨陵 712100)
0 引 言
在学术文献数量飞速增长的当代,据DBLP(digital bibliography & library project)[1]统计,在计算机相关领域每年约有30万篇学术文献发表,而如何让科研工作者在海量学术文献中高效挖掘出适合自己的科研文献是一个亟待解决的问题。
为解决上述问题,引文推荐已成为一个新兴的科研方向。文献[2]提到引文推荐是指给定一篇文献通过相关算法为其推荐匹配的参考文献。引文推荐和传统文献推荐有着一定的区别,传统的文献推荐是通过分析作者日志等信息进而发现和作者兴趣相同的作者群体,根据这个作者群体从而产生推荐。而引文推荐是为目标文献或者根据目标文献中引文标识符的上下文来推荐已有的研究成果。引文推荐主要分为两类:全局推荐和局部推荐[3]。全局推荐通过分析目标文献中的标题、摘要、作者等相关信息来挖掘相关引文,这样可以较为全面的获取相关文献,而局部推荐是根据引文标识符的上下文进行推荐,由于上下文信息量较少难以推荐较为相关的文献,因此本文聚焦于全局引文推荐。目前在引文推荐研究领域主要的推荐模型包括文本相似度、主题模型、协同过滤算法模型以及混合推荐方法等。文献[4]是基于引文上下文信息感知的引文推荐方法,其分析每个引文的本地上下文信息以提取相关特征,但是本地上下文信息模糊以及查询内容过短,导致预测结果不准确。文献[5]是基于主题的相似性方法利用潜在主题模型找到主题相关的论文,但是仅仅依靠主题分布来衡量相关性是不够的,大量论文可以共享同一主题,使得主题相似性不能很好地表示论文的重要性。这两种方法主要侧重于推荐基于相关内容的论文,而忽略了论文的重要性和论文质量等关键信息。文献[6]利用引文链接导出结构相似性和权威性,这个是对基于内容推荐的一个很好的补充,但却忽视了内容的重要性。文献[7]提出基于协同过滤和相似度计算相结合的混合式推荐方法,在数据稀疏的情况下,对新用户和低被引文献上表现不良。以上引文推荐相关推荐算法考虑特征单一,不能很好地把握论文的总体情况,而且存在局限性如推荐的结果过于专门化及冗余重复,缺乏多样性、新颖性、推荐的论文不够权威等问题。
基于此,本文从多个角度来分析引文推荐,综合考虑多种因素对引文推荐的影响。本文在PageRank算法上添加入链因子、出链因子及引用衰减因子来优化PageRank算法的主题漂移问题和歧视新文献等问题;根据近三年论文引用率和局部趋势计算论文引用的局部活跃度;运用ID2vec改善重启随机游走算法的随机性进而提升查询内容的相关性;引入Author2vec来构造作者相关度因子;最后通过多特征因子融合模型融合多个特征,进而给候选论文集排序,将排名靠前的N篇论文推荐给用户。实验结果表明,本文提出的算法有效提升推荐效果,改善推荐质量。
1 引文数据预处理
通过Word2vec模型将论文中的单词、论文、论文ID以及论文作者进行分布式表示学习,转化成算法所能识别的向量,进而为后续引文推荐相关算法提供数据支撑。
1.1 Word2vec词向量模型
Word2vec是谷歌公司开源的一款将词表征成分布式词向量的工具,它是一种深度学习的模型,基于神经网络,通过感知机将底层特征转换为高层的抽象特征。Mikolov等[8]在文献中提到Word2vec包括两种模型,分别是CBOW(continue Bag-of-Words)和Skip-gram模型,CBOW模型是通过上下文来预测目标词,Skip-gram模型是通过当前词来预测上下文。两种模型都是包含了输入层、投影层、和输出层的三层神经网络如图1所示。相比于CBOW模型,Skip-gram模型通过跳跃词汇来构造词组,避免了因窗口大小限制导致丢失语义信息从而有更高的语义准确率。本文应用Skip-gram模型作为训练框架,训练窗口为5,指定词向量的长度为200维。
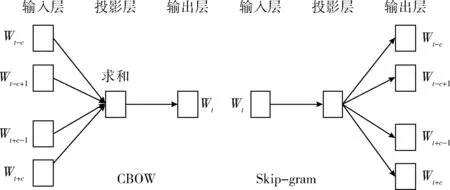
图1 CBOW和Skip-gram模型
Word2vec不仅在词向量的训练中有很好的表现,而且在其它场景的应用也效果出众。文献[9]通过Word2vec发现维吾尔语深层语义关系进而提升分类效果。Patrick Ng[10]应用Word2vec去表示DNA序列,进而发现基因之间的关系。Nevyana[11]通过应用Word2vec训练Spotify上的用户所点击的音乐列表来找到相关音乐从而给用户推荐相关音乐,在推荐的新颖性、偶然性和多样性上有较好的表现。
1.2 构造论文向量
本文通过论文标题以及论文的关键字来表示这篇论文。假设论文i的标题以及关键字共有Ki个词,论文经过Word2vec处理后得到的论文向量为Pi如式(1)所示
Pi=(vi1,vi2,…,vic,…,vin)
(1)
Wi(j)=(wj1,wj2,…,wjc,…,wjn),j∈{1,2,…,Ki}
(2)
式(2)中Wi(j)表示论文i第j个词的词向量,n表示每个词向量的维度,wjc表示n维词向量第c维的值,Ki个词向量相加平均后即可得到论文i的向量Pi,如式(3)所示
(3)
1.3 构造论文ID向量
每篇论文都会有一个参考文献列表,这个列表的文献基本是属于同一个领域或者主题相关。参考文献的引用列表有着一定的先后关系,在一篇论文前部分引用的基本都是前人一些较为成熟的研究成果,例如在论文的相关介绍部分会介绍本领域的国内外研究状况,引用的文献为本领域相对权威的研究成果。在论文后部分引用的文献基本是近期的成果,例如在实验部分通常和近期的一些成果进行对比,因为和近期的文献成果对比其意义更大。综上所述参考文献引用列表在内容上是相关的,在时间上有一定的先后关系。基于以上分析,提出ID2vec概念模型,在非重叠论文ID数据集上应用Word2vec进行训练,进而将论文ID转换为分布式向量表示,如式(4)
IDi=(di1,di2,…,dvc,…,din)
(4)
式中:IDi为论文i的ID向量表示,dvc为向量的维度值。
本文给每篇论文分配唯一的ID值,用ID值来代表这篇论文。在构造ID数据集的过程中,ID值相当于一个单词,论文的所有参考文献的ID值放置在一个文件中相当于一篇文章。由于ID数据集相对较小,所以将ID数据集进行重组,根据文献[10]中提到的方法,将一个序列转化成非重叠窗口大小为3的序列,并且这种方法的效果比重叠窗口数据构造方式在K邻近算法上表现更好。本文通过非重叠窗口大小为3的形式构造数据集,假设一篇论文的引用文献列表对应的ID值原始序列为QWERTYZASDFG,其中每个字母代表一篇论文的ID值,如下序列1、序列2、序列3为原始序列生成的非重叠序列,序列4为其生成的重叠序列。
序列1:QWE RTY ZAS DFG
序列2:WER TYZ ASD
序列3:ERT YZA SDF
序列4:QWE WER ERT RTY TYZ YZA ZAS ASD SDF DFG。
通过此种方法增加论文ID的数据量,进而能提升训练的精度。通过ID2vec可以发现论文中共被引关系即两篇论文如果被其它论文同时引用的次数越多,两篇论文的ID向量相似度会越高。ID2vec也能发现共引关系即两篇论文同时引用一篇文献,如文献A和共引文献C有很高的相似度,同时文献B和共引文献C也有很高的相似度,这样文献A和文献B也就有相对较高的相似度。
1.4 构造论文作者向量
一篇论文有多名作者,而这多名作者有较强相关性,在研究领域方面其基本属于同一个研究领域,在空间方面其基本是同一个学院或者同一个学校,同时论文的作者和参考文献的作者在研究内容上也存在一定相关性。本文基于以上分析提出Author2vec概念模型,将论文作者和参考文献作者通过上文提到的窗口为3的非重叠序列构造方式构造数据集,在此数据集上运行Word2vec,将论文作者进行分布式表示。如式(5)所示
Aj=(aj1,aj2,…,ajc,…,ajn)
(5)
式中:Aj为作者j的向量表示,ajc为向量的维度值。
2 多特征因子融合的引文推荐算法
多特征因子融合引文推荐算法(MixFeatures)的核心思想是:论文链入链出关系越多,论文越重要,通过引用衰减函数来调节新旧论文的引用情况;融合论文的近三年引用频率和近两年的引用趋势挖掘论文的局部引用特性;通过ID2vec计算论文引用网络中相邻节点的相似性改进重启随机游走算法,进而提升查询相关度并且优化主题漂移问题;通过Author2vec计算作者之间的相关度,通过作者之间的相关性进一步优化待推荐结果集的排序结果。
算法的整体流程如图2所示,主要包括两个主要部分:
(1)在线下部分,本文首先通过Word2vec将单词、论文、论文ID、作者转换成向量表示。其次计算整体影响力、局部活跃度、查询相关度及作者相关度,最后通过多特征因子融合模型进行有效融合。
(2)在线上部分,根据用户的查询语句做相关性计算,依据多特征因子融合模型打分结果进行排序,将最相关的N篇文献进行推荐。
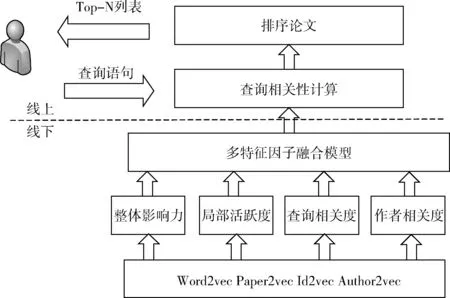
图2 多特征因子融合算法整体流程
2.1 整体影响力因子
本文基于链接网络中PageRank算法[12]引入整体影响力模型,模型主要思想是:论文入链和出链越多,论文越重要,添加引用衰减函数,提升新论文的排序位置同时降低旧论文的权重。整体影响力因子如式(6)所示
(6)
式中:d为阻尼系数通常取0.85,Win为链入因子,Wout为链出因子,decay为引用频率衰减函数。
在引文网络中权威论文应该在排序过程中有较为核心的排序位置并且起到关键作用,这就要求该论文有较多的入链同时也有较多的出链。但是原始的PageRank算法基于论文的正向链接来均分论文的PR值,导致一些质量相对差的论文有较高的PR值引起论文主题漂移等问题。因此在计算论文的PR值时应根据论文的入链数目和出链数目来计算论文的重要程度同时分配PR值,这样权威的论文就会有较为合理的排名。同时在引文网络中认为入链更为重要,所以在整体权威度模型中,给链入因子分配权重较链出因子权重大一些,实验结果表明α取值为0.7效果最佳。链入因子Win[13]和链出因子Wout的相关计算公式如式(7)和式(8)
(7)
(8)
式(7)、式(8)中,Iu表示论文u的入链,Ou表示论文u的出链,B(v)是指向论文v的引用论文集合,Ip是论文v引用论文的入链,Op是论文v所引用论文的出链。
一个很重要的事实是一个作者更倾向于引用近期发表的论文去支撑他的观点。由此观点可以得出一篇论文是有自己的引用周期,在论文发表的一段时间里论文本身的被引用率较高而随着时间的增长论文的被引用频次是逐步降低的。如图3所示,文献[14]中描绘了ANN、KDD、EMNLP这3个数据集下随着时间的增加而论文的被引用频率逐步率衰减的过程。从图中可以得出不同期刊的论文的引用衰减曲线相似,从而得出引文的引用衰减曲线和具体的期刊关系较小。由此可知在计算论文的PageRank值的同时,论文的发表时间应作为一个因素考虑进来,这样能避免发表久的论文积累过多的引用,导致PageRank值过高,同时也能优化新发表的论文有可能是质量高的论文而排名靠后等问题。文中提出如式(9)引用衰减函数,用来拟合ANN数据集引用率衰减。式中decay表示衰减值,x表示当前时间和论文发表时间差
decay=0.2297×exp(-0.2031×x)
(9)
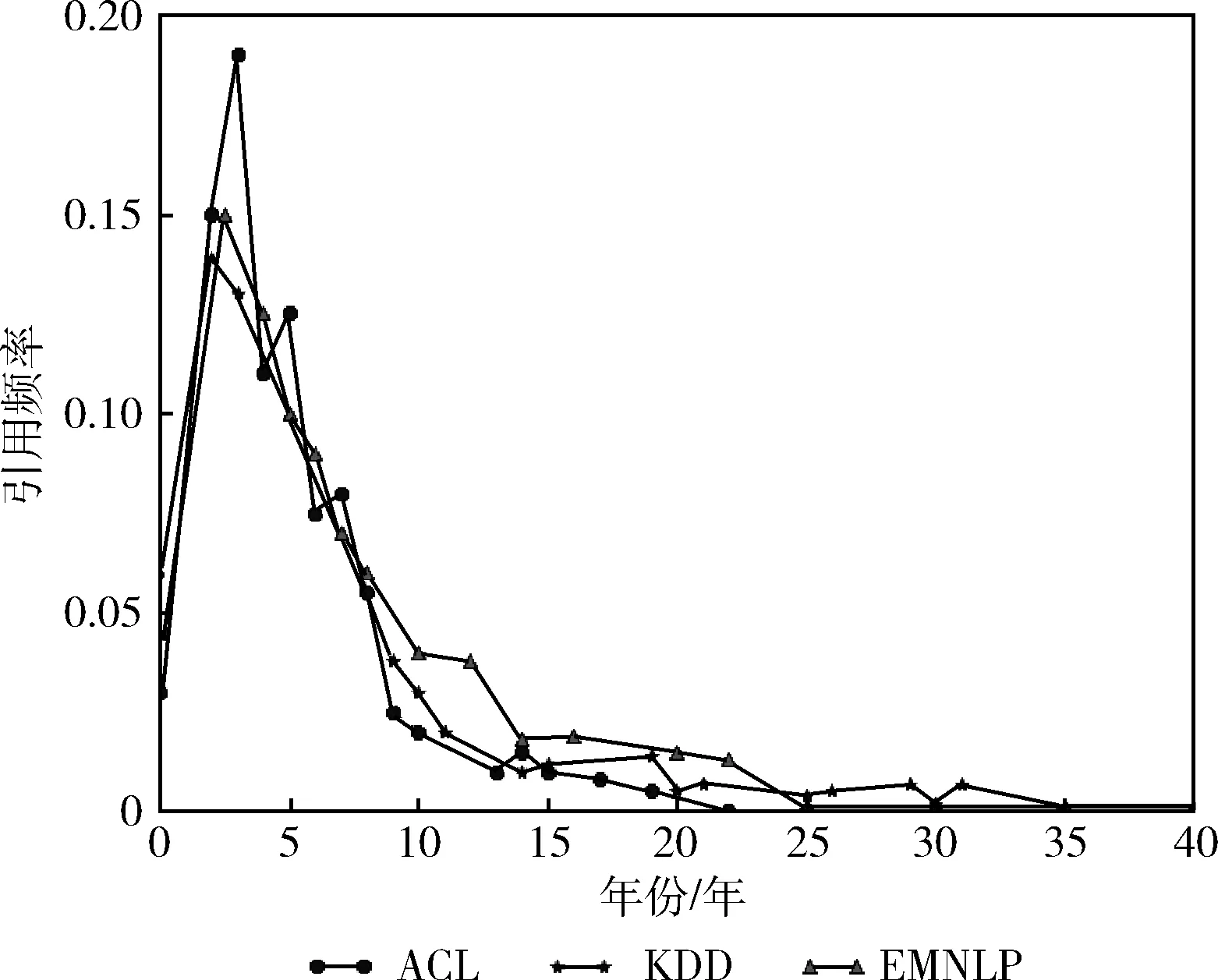
图3 论文引用衰减图
2.2 局部活跃度因子
在计算论文的整体权威度时,论文的引用频率衰减因子是一个较为重要的特征,这个特征主要描述了论文的整个生命周期,这个生命周期是可以用一个负指数模型的单调递减函数表示。所有论文的引用频率在整个生命周期是呈现下降趋势,然而论文也有各自的局部特征,也就是说一篇论文会在某个时期,它的价值是增长的,而这个增长时期有可能发生在论文发表的初期,或者是发表了多年的论文在它生命周期本应该呈现下降的趋势时,反而呈现出上升状态。所以仅仅用论文的生命周期去刻画一篇论文的引用规律是不够的,基于此引入局部活跃度,其表达一篇论文在某个局部时期表现出来的规律。
作者更关注近三年发表的论文,且近三年的论文有较高参考价值,因此局部活跃度因子包括近三年的引用频率[15],同时在近三年的引用频率上进一步细化局部特性融合近两年的引用局部趋势,最终局部活跃度模型如式(10)
(10)
式(10)中文献P的局部活跃度记作f(p),c表示近三年的被引用次数,t是文献的发表时间和推荐时间差,以一年为单位。例如今年是论文推荐的年份,那么本文设定前年为yo,去年为yn,而在yo时,论文的引用次数为c2,在yn的引用次数为c1,那么局部趋势定义为c1/c2。当论文发表在yo以后,表明这篇论文在近两年发表,由于论文较新无法获得更多的引用频次,因此应用其它论文发表前两年的局部趋势的均值来替代当前文献的局部趋势。当论文发表在yo以前,并且在yo和yn时间内都没有被引用过,这种情况局部趋势值为R,其值如式(11),此时的R值和引文衰减因子函数重合如式(9),当时间差为1的时候
R=0.2297×exp(-0.2031)
(11)
(12)
式(12)中A(i)为文献的平均局部活跃度,n为所有论文的个数,将所有论文的局部活跃度值进行归一化,就得到论文的平均局部活跃度。
2.3 查询相关度因子
本文利用改进的重启随机游走算法来度量论文的查询相关度,虽然有很多游走类的算法可以进行查询相关度的计算,但经过相关论文的证实,重启随机游走算法RWR(random walk with restart)[16]是一种高效的计算引文网络中的节点和查询输入之间的相关度的算法。
在重启随机游走算法中,假设随机游走粒子从节点x出发,根据引文网络从一点跳跃到另一个节点,同时每一步跳转都会有α概率可能性从A节点重新出发而跳跃到其它邻居节点的概率为1-α。重启随机游走算法如式(13)所示
r(t+1)=(1-α)Mr(t)+αq
(13)
(14)
式(13)、式(14)中M为概率转移矩阵,其值表示随意游走粒子从a节点游走到b节点的概率,如果a节点和b节点有引用关系,则c=1;否则c=0,Da表示节点a的出度。r(t)表示随机游走过程中第t步访问节点a的概率,q为查询向量,r(0)等于q。
根据以上分析可以得知在随机游走过程中状态转移矩阵M对最终的排序结果起到至关重要的作用。在传统的重启随机游走算法中,节点之间的概率转移是均分的,并未考虑节点之间的相互影响,从而导致随机性较强及预测结果精度较低等问题。而本文认为在随机游走过程中游走的概率不应该是一个平均值,而是根据节点之间的相关度,来给出不同的游走概率,这样每个节点在迭代平稳以后有一个更为合理的值。
本文通过ID2vec来计算相邻节点之间的相似性并融合节点之间固有链接关系进一步重新计算概率转移矩阵的初始值。因此在迭代过程中使得相关性较大的节点之间传递较高的分值,相关性较低的节点之间吸收相应较少的分值,最终致使节点获得一个较为合理的权重。Word2vec在单机条件下,24小时内可以训练千亿词,则本文提出的ID2vec可以在24小时内找到千亿篇文章的相关性。ID2vec训练出来的向量表示论文是从全局角度考虑,而并非仅仅从文本内容考虑,这个更符合概率转移矩阵的相关性计算。
首先通过ID2vec生成引文网络中每个节点的向量表示,假设式(15)表示任意节点a的向量,假设式(16)表示任意节点b的向量,节点a与节点b的相关度为IDSim(a,b)。欧式距离经常被用来计算两点之间的距离,因此应用欧式距离来表示引文网络上任意节点之间的相似度
Va=[x1,x2,x3,…,xn]
(15)
Vb=[y1,y2,y3,…,yn]
(16)
在无向的引文链接网络中任意两个节点a,b之间的相似度计算如式(17)
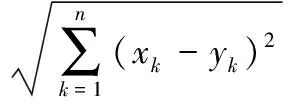
(17)
在改进的转移矩阵中,引入节点之间的相似度,节点的权值分配受两方面影响:一部分为节点固有链接关系,代表引文网络的固有结构影响力;一部分为节点之间的相似度,代表文献之间的内容上的相似性。在无向引文网络中任意两个节点a,b之间的转移概率如式(18)
(18)
式中:N(a)表示节点a的邻居节点集合; ∑z∈N(a)IDSim(Va,Vz) 用于IDSim(Va,Vz) 的归一化操作;参数β为两种影响因素的权重因子,用于调节影响因素占比。引文网络中节点a与节点b之间存在链接关系,则cab=1,否则cab=0。ka表示节点a的在引文网络中的度。
本文将ID2vec和RWR算法结合,因此命名本算法为IVRWR,算法的相关伪代码如下:
算法: IVRWR
输入: 查询句子w, 引文网络邻接矩阵M(mij), 重启因子α, 调节因子β;
输出: 稳态向量r;
(1)利用1.3节中ID2vec生成引文网络中节点向量;
(2)利用1.2节中论文向量生成方法生成论文向量和查询语句向量, 进而做相似度计算生成查询向量q;
(3)根据式(16)计算引文网络邻接矩阵的转移概率P;
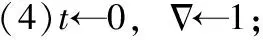
(6)r(t+1)=(1-α)Μr(t)+αq
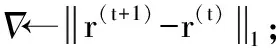
(8)t←t+1;
(9) end of while
(10)returnr(t)//返回稳态向量
2.4 作者相关度因子
在引文推荐中有很多工作是发现论文作者之间的关系进而来提升个性化推荐精度。Guo等[17]通过作者之间的共作者关系和作者发表论文的主题去定义作者与作者的相关度,进而构建异构图进行推荐。Yu等[18]提出了一种有标记的有向图模型,其不仅利用文章内容而且利用共作者关系作为隐含信息进行科技文献推荐。这些方法是较为细粒度的发现作者之间的关系,算法运行效率较低,而本文通过一个粗粒度的方法去发现作者之间的关系,运行效率较高。
论文作者之间存在多种关系,如共作者关系也就是说几名作者是论文的共同作者,这样几名作者的研究领域相关性较大。作者发表的论文之间有引用关系,引用论文的作者和被引用论文的作者也是有一定的相关性,但是这种关系相对共作者关系较弱。本文进行作者相关性讨论,即论文作者的相关性可以用来调整引文推荐过程中的排序,当用户搜索相关论文时,根据在1.4节中的Author2vec算法将用户转化成向量表示,如式(19)
Vu=[x1,x2,x3,…,xn]
(19)
得到用户向量,用户向量和候选论文集中每篇论文中的多个作者向量计算余弦相似度,并且求和得到用户和候选论文集的作者相关度,如式(20)
(20)
式中:R(u,p)表示用当前用户u和候选论文的相关度,Sim(u,pi)表示当前用户u和论文p的作者余弦相似度,k表示论文作者数量。
2.5 多特征因子融合模型
为将上文提到的多种特征因子有效结合,本文提出多特征因子融合模型。整体影响力因子(GP)改善了Page-Rank值平均分配和偏重旧论文的问题,给每篇论文一个合理的影响力权重。局部活跃度(LP)更好地挖掘有潜力的新文献,适当提升其排名,更多地展现在用户面前,使其价值得以体现;查询相关度(SP)改善了随机游走算法的随机性,进一步优化主题漂移等问题,使和查询向量相关的文献排名更为靠前;作者相关度(AP)通过作者之间的关系进一步挖掘论文之间的隐性关系,将个性化信息考虑到推荐过程中,进而细化推荐权重。在以上特征因子基础上为了能更好的将各种特征因子进行有效结合,本文通过线性拟合的方法提出融合模型如式(21)
RankScore=αGP+βLP+γSP+∂AP
(21)
式中:4个特征因子的权重满足和为1,通过调节权重来确定最合理的组合方式。
3 实 验
3.1 实验数据
本文实验数据采用包括完整论文信息的ANN数据集(http://clair.eecs.umich.edu/aan/index.php)。本文从数据集中提取16 527篇文章包括完整的论文摘要和标题。数据集的年限是从1965年到2013年。每篇论文都经过处理,包括如下步骤:①抽取论文的标题、摘要、关键字;②剔除只含有3个或更少字符的单词;③去除停用词。
在预处理完的数据集中,本文用2013年以前的15 069篇论文以及9744名作者数据作为训练集,2013年的1458篇论文和1672名作者作为测试集,实验数据见表1。在此数据集基础上分别构造不同格式的数据集:
(1)单词集:将训练集和测试集中所有的论文中的数据构造单词集,用Word2vec训练生成词向量。
(2)论文ID集:将2013年以前的论文ID构造数据集,根据文中1.3节中提到的方式构建并用Word2vec生成论文ID向量。
(3)论文作者集:将2013年以前作者如文中1.4节方式构造数据集用Word2vec训练生成作者向量。
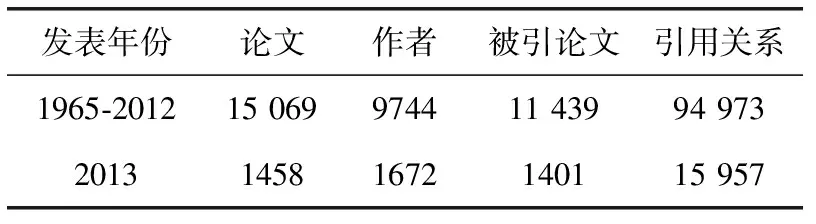
表1 实验数据
在推荐过程中,将测试集的论文标题和关键字作为查询语句,根据通用做法将论文的真实引用论文列表作为正确的推荐结果,主要测评本文算法和正确结果之间的匹配度,进而验证本算法的合理性以及有效性。
3.2 实验环境与度量标准
实验环境为Ubuntu16.04操作系统下,运行原生Word2vec代码进行数据训练。在Windows7操作系统下,运行本文算法以及相关对比算法,算法开发环境为Anaconda2 Spyder,Python版本号为2.7版。
在测评方面运用推荐领域常用指标Recall和NDCG(normalized discounted cumulative gain)[19]其分别为推荐的准确性和预测的等级质量评价指标。
(1)召回率(Recall)
召回率定义为在推荐列表中的真正被引用文献在测试文献的参考文献集中所占比率,召回率是在测评推荐相关性的一个重要指标。召回率的计算公式如式(22)
(22)
式中:Q表示查询次数,N表示推荐列表长度,Rp是推荐列表所推荐的N个参考文献集合,Tp为测试文献真实的参考文献集合,Rp∩Tp是推荐列表中正确的推荐结果集合。
(2)NDCG
在推荐系统中对推荐的相关论文的位置非常敏感,相关的论文排序越靠前越好。本文通过NDCG这个测评指标去表示这一个规律。NDCG公式如式(23)
(23)
式中:Q为查询的次数,N为推荐列表的长度。ri为第i篇论文的相关度,在本文中当ri=1,则论文为正确的推荐结果,当ri=0,则论文为不相关推荐结果。IDCG@N是一个理想的推荐结果值用来规格化,其公式如式(24)所示
(24)
式中: |REL|为查询列表中正确的推荐结果的个数。ri的值和NDCG@N中的值相同。
3.3 实验结果分析
3.3.1 不同数据集下ID2vec对比分析
本文在2013年以前的数据基础上,根据文中1.3节介绍的数据集构造方法,分别构造3种不同的数据集:重叠数据集,非重叠数据集,原始数据集。基于3种数据集生成ID2vec,通过十折交叉验证的方法计算召回率,召回率的对比如图4所示,纵坐标为召回率,横坐标为推荐列表前k个数,可以清楚看到非重叠数据集的效果明显好于另外两者,主要原因为非重叠数据集相对前两者数据量有提升,而且非重叠数据集的构造方式更适合Skip-gram模型进行采样。
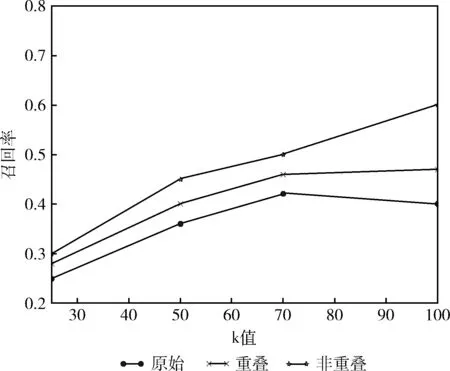
图4 不同ID数据集召回率对比
3.3.2 查询相关度对比
对比RWR算法和本文提出的IVRWR算法在召回率和NDCG两个测评指标上的表现。根据实验设置调节参数β取值为0.75,重启因子α取值为0.9。实验过程通过十折交叉验证来得出结果。如图5所示,纵坐标为召回率,横坐标作为推荐结果的前N个值,IVRWR算法相对RWR算法在召回率上平均提升了8.13%;如图6所示,IVRWR算法相对RWR算法在召回率上平均提升了29.7%。由此可知IVRWR算法不仅在推荐的正确性上有一定改善而且在推荐的顺序上也有较大的提升。由于IVRWR算法重新定义了引文网络中不同节点的转移概率,使其在状态转移过程中考虑邻居节点内容相关性,进而改善随机游走随机性,从而提升推荐效果。
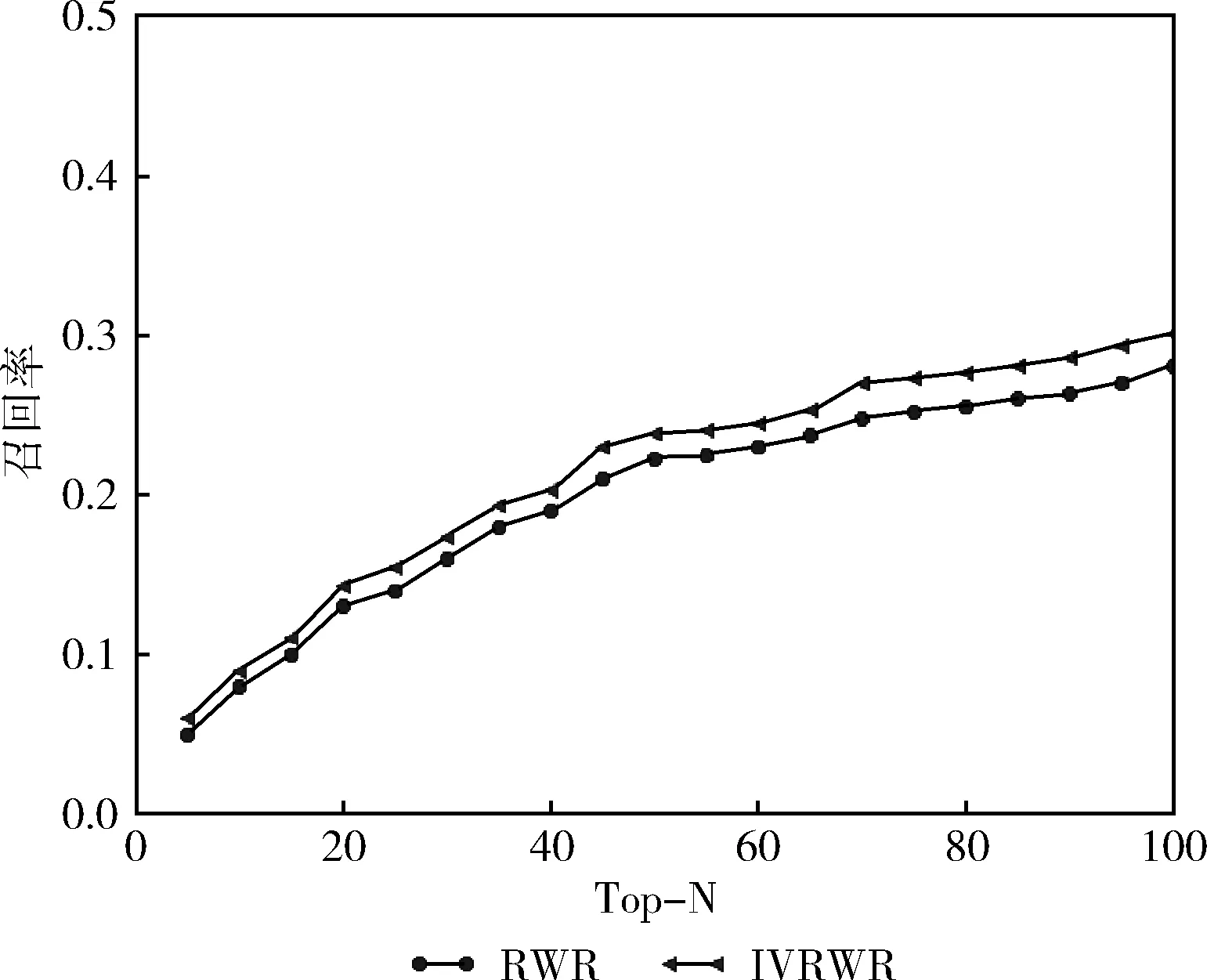
图5 原始RWR算法和IVRWR算法召回率对比
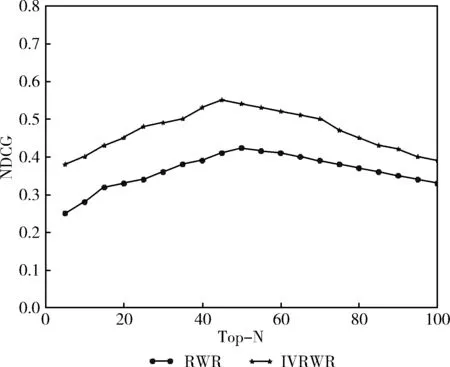
图6 原始RWR算法和IVRWR算法NDCG对比
3.3.3 MixFeatures算法调节可变系数
为了有效融合上文提到的4个特征因子,本实验通过十折交叉验证方法进行参数调节,选择召回率在Top-N分别为25、50、75、100时的值作为评价指标。随机给出多组数据进行分析,如表2当查询相关度权重大于0.5时测评指标有明显上升,由此可知查询相关度在推荐过程中起到主要作用,而有部分原因为其抑制PageRank算法的主题漂移现象,使相关论文排名更靠前;全文影响力分配相对较高权重可以提升推荐质量,因为在全局影响力中改善PR值均分问题和融合论文衰减因子致使旧论文下沉新论文上浮,这样更符合推荐的意图;作者相关度较局部活跃度对结果有更大的影响,表明相关作者的论文的相关性更大。最终确定当(α,β,γ,∂)∈(0.2,0.1,0.5,0.2) 时实验效果最好。
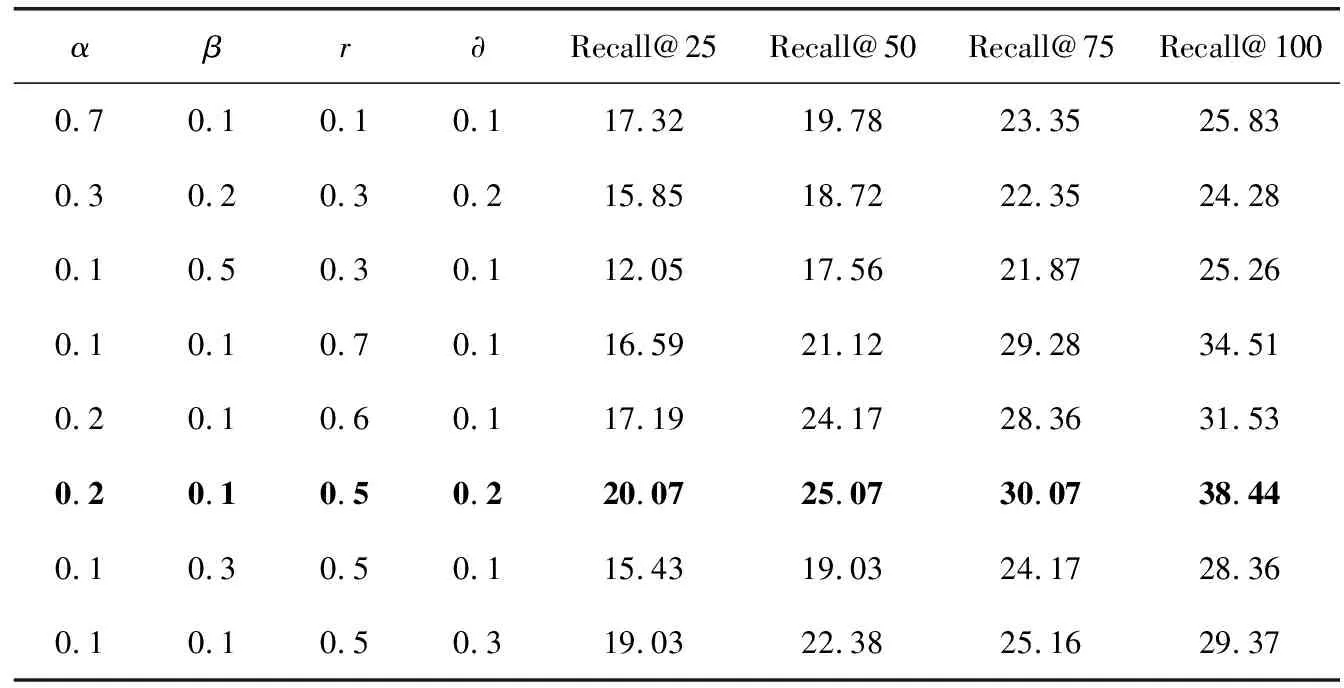
表2 可变参数对比
3.3.4 不同算法推荐效果对比分析
最后通过本文提出的多特征因子融合算法和其它算法进行对比,实验结果对比如图7所示。相对比算法介绍如下:
(1)GLOPageRank算法[20]:根据引文网络以及查询内容计算出每个节点的PageRank值,通过PageRank值进行排序,值越高推荐的机会越大,这种方法是基于图结构的。
(2)TopicSim:查询文本的主题和候选论文集中的主题进行相似度计算,同样相似度越高排名越靠前。本文用的是Topic2vec算法[21]将候选论文的主题通过分布式表示出来,再将查询文本也用其分布式表示出来,最后计算相似度,这种方法是基于主题的。
(3)BM25[22]:此模型是概率检索模型中比较有代表性的一个算法,根据用户的查询内容计算每个文档的BM25值,进而根据这个值来排序,值越高排序越靠前,这种方法是基于检索的。
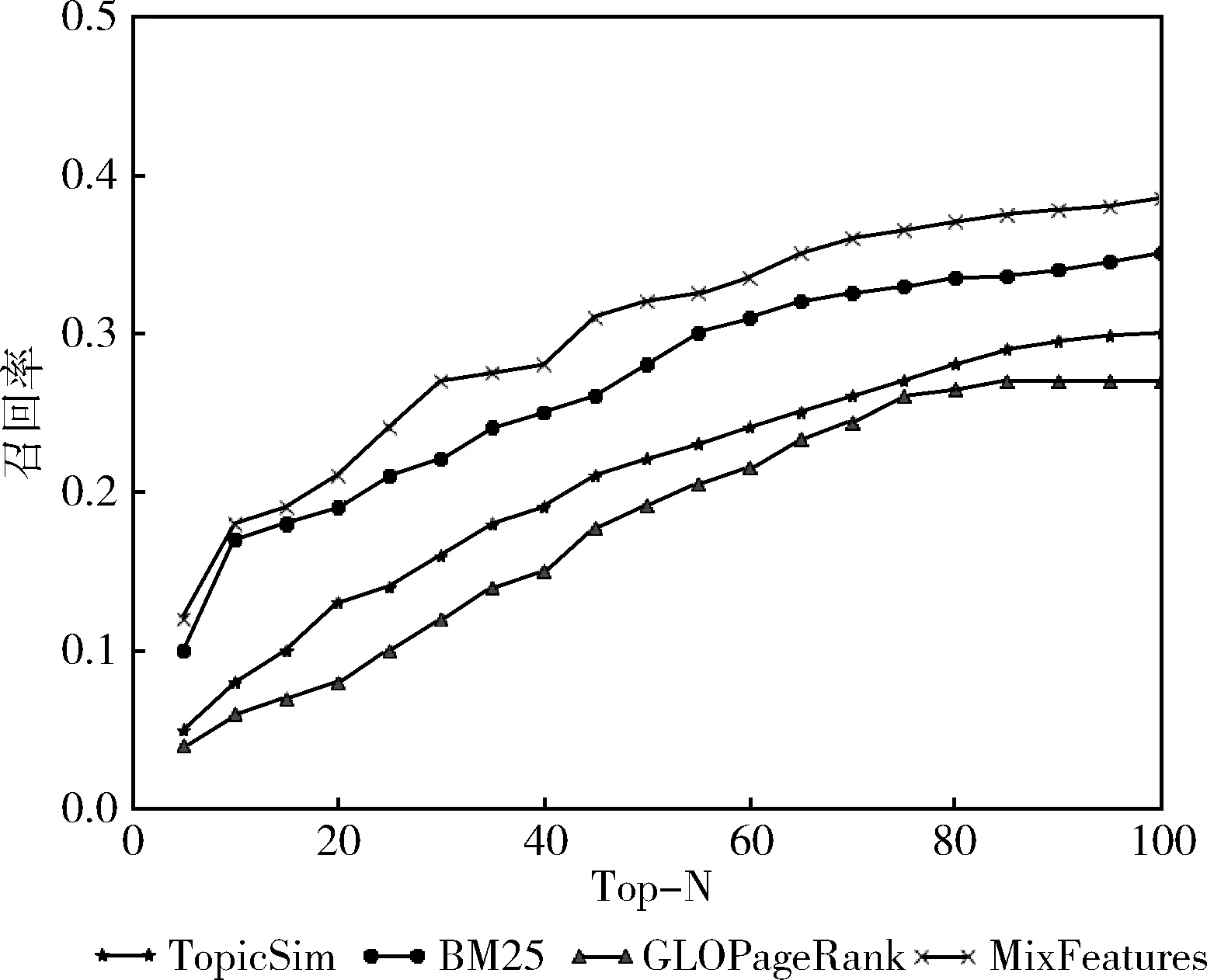
图7 不同推荐算法召回率对比
通过实验对比图7可知,GLOPageRank和TopicSim算法的推荐效果相对较差,因为仅仅通过引用关系或者是内容相关性来进行推荐论文存在一定的局限性。BM25算法效果相对前两者较好,因为BM25算法考虑的权重较多包括IDF因子、查询词在文档中的权重、以及查询词自身的权重等。而本文提出的MixFeatrues算法有较为明显的优势,因为考虑了多方面特征因子,综合这些特征因子给候选论文集一个合理的Rank值,这样通过排序后推荐效果明显有提升。
4 结束语
对比分析传统引文推荐算法中的不足,及已有解决算法的单一性,提出一种有效结合整体影响力因子、局部活跃度因子、查询相关度因子及作者相关度因子的MixFeatures算法,并达到优化引文推荐算法的目标。本文算法通过改进PageRank算法解决平均分配PR值问题和偏重旧论文的问题;结合局部活跃度因子,细粒度发现论文的引用情况;引入通过ID2vec改进的重启随机游走算法的查询相关度,提高查询结果的相关性,避免论文主题漂移的问题;添加基于Author2vec的作者相关度,通过作者之间的相关性进而发现论文之间的相关性。
实验结果表明,本文提出的MixFeatures算法有效改善目前引文推荐算法低效,推荐质量差等问题;IDRWR算法有效改善了随机游走算法在状态转移过程中存在较强的随机性问题,提升了查询相关性,为后续研究提供了新的思想。在接下来的研究过程中,将重点投入到随机游走重启算法在异构图中的应用,通过ID2vec和Author2vec两个概念模型,改善异构图中随机游走状态转移随机性,进而提升推荐效果。
