基于集成学习的情感模糊计算分类方法
2018-07-19李学勇黄永峰
刘 磊,李学勇,黄永峰
(1.清华大学 电子工程系 信息认知与智能系统研究所,北京 100084;2.河南科技学院 信息工程学院,河南 新乡 453003;3.清华大学 信息科学与技术国家实验室,北京 100084)
0 引 言
现有情感分类方法[1-3]主要有2类:有监督方法和无监督方法。其中有监督的情感分类又分为两类:一种是基于机器学习的方法,另一种是基于深度学的方法[4]。
训练标注数据集在有监督情感分类中是一项重要的基础工作[2]。在获得标注好的训练数据集后,通过训练数据集对分类模型进行训练,得到训练数据集上分类模型的最优参数,然后基于训练好的模型,对测试数据集进行分类。网络文本情感分类属于文本分类,因此,任何有监督文本分类方法都可以应用到网络文本极性分类中,如朴素贝叶斯、最大熵、支持向量机(SVM)、神经网络等。周哲[5]采取有监督文本分类方法(朴素贝叶斯)对电影评论进行情感极性分类,把电影评论分成正负两类。实验结果表明,使用朴素贝叶斯作为分类器,电影评论的情感极性分类取得了较好的性能。由于有监督情感分类精度较高,一直受到研究者的关注。有监督情感分类方法存在两个问题:一是领域依赖性强,只有针对特定的领域进行大量的人工标注训练集才能取得良好的分类效果;二是网络文本领域类型多,对每个领域单独标注训练数据集,成本太高。阻碍了有监督学习的应用[6,7]。
为解决以上存在问题,不需要标注训练数据集和具有一定领域普适性的无监督情感分类方法受到越来越多研究者的重视,并逐渐成为学术研究热点。
1 相关工作
现在的基于无监督的情感分类研究方法主要分为两类:一种是基于情感极性词典的分类方法;另一种是基于自学习的无监督网络文本情感极性分类方法。
基于情感词的无监督网络文本极性分类方法核心思路是:首先,基于现有情感词极性分类方法,计算网络文本中情感词的极性;然后,综合情感词和情感短语的情感极性,计算文本的整体情感强度;最后,比较文本整体情感强度与阈值“0”的大小,实现网络文本极性分类。
在计算情感词极性时,王志涛等[8]主要基于情感词典来进行情感分类,没有对情感词极性的文本领域依赖性进行处理;刘浩[9]主要基于语料库,通过领域语料库的统计信息,部分解决了情感词极性的文本领域依赖问题,但从分类效果看,性能一般。同时,基于语料库构造领域情感词典,需要对每个领域都重新构造词典或进行跨领域移植。对每个领域构造情感词典消耗太大,进行跨领域移植精度较差。为解决情感词极性的文本领域依赖问题,有一些研究者借鉴有监督学习的思路,提出了基于自学习的无监督网络文本极性分类方法[10,11]。
基于自学习方法的主要步骤为:一是基于情感词典方法,生成初始伪标注数据集,训练自学习情感分类器;二是基于自学习框架,循环迭代更新初始伪标注数据集,训练网络文本极性分类器;三是基于训练好的分类器实现网络文本情感分类[2]。基于自学习的方法,通过自动生成初始伪标注数据集,训练领域情感分类器,试图解决情感词极性的文本领域依赖问题。基于自学习方法性能与伪标注数据集的情感类别正确性和领域类别代表性相关。现有基于自学习的方法,在生成初始伪标注数据集时,没有考虑网络文本的领域类别代表性,最终在自学习过程中,引入较多错误伪标注数据[2]。
2 分类框架整体设计
无监督情感分类虽然不用标注训练数据集,也可在线实时跨领域进行分类,但是依然存在着分类精度低和伪标注数据错误多的问题。鉴于这种情况,我们提出了一种基于集成学习的情感模糊计算分类框架,该框架如图1所示,主要由2部分组成。
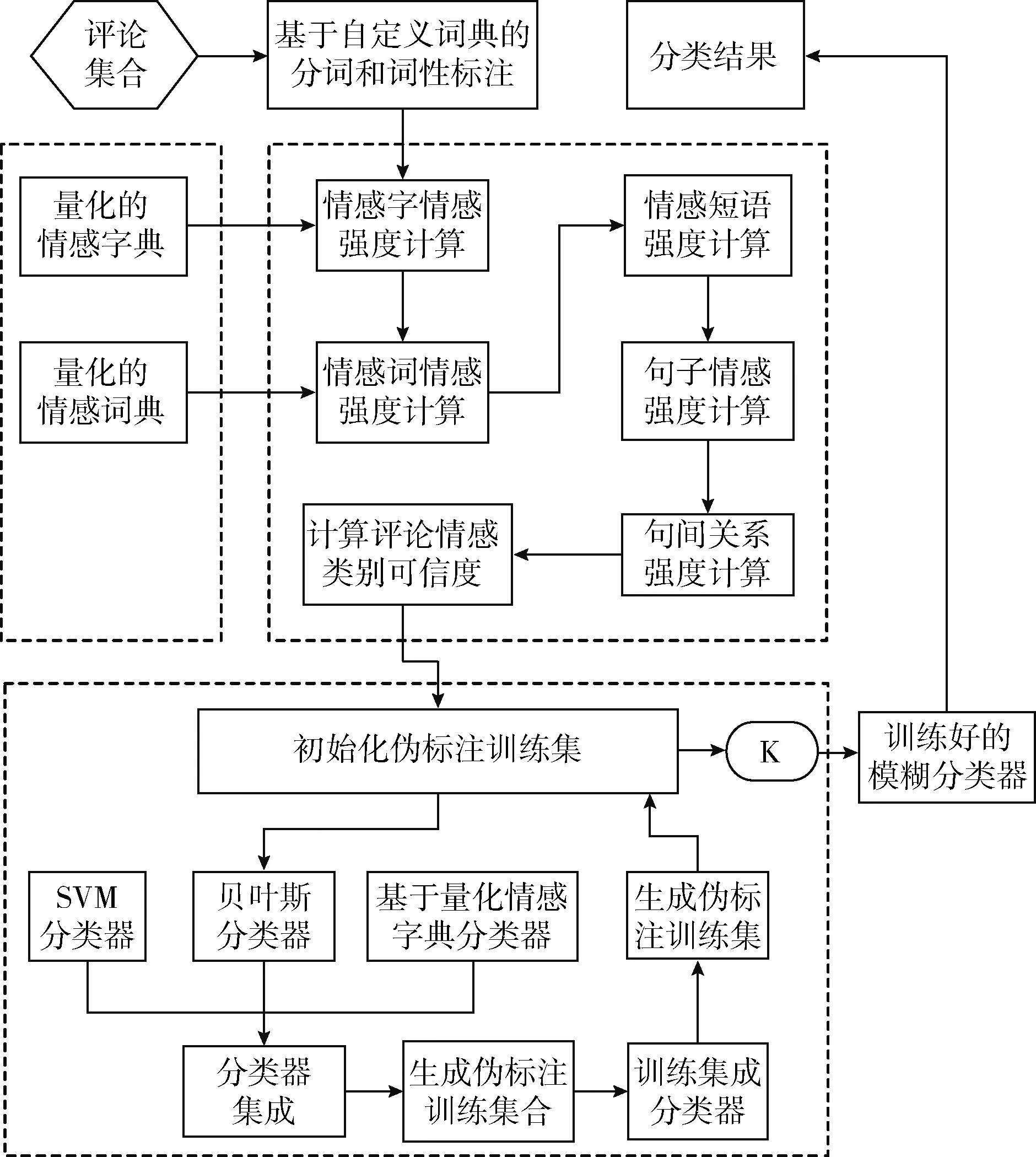
图1 量化情感词典的模糊计算和多分类器集成的情感分类框架
(1)基于量化情感词典和字典的网络文本情感模糊计算方法
现有无监督情感分类主要通过情感词,情感短语进行情感分类,有的研究者提出了从情感词,情感短语,情感句子和句间关系等多个粒度来进行情感分类,但这些方法都没有考虑情感词本身的情感强度。针对以上问题,本文提出一种基于量化情感词典的网络文本情感强度计算方法。该方法按照人类理解语言的规律,从字、词、短语和句子4个层次粒度,计算网络文本的情感强度。
目前基于情感强度的情感极性计算方法主要采用比较网络文本的情感强度与阈值‘0’的大小[2],来识别网络文本的极性。由于情感强度的模糊性,采用确定性理论在描述情感强度与网络文本情感极性的关系时存在一定的偏差,为此,我们提出了基于情感强度的网络文本情感极性模糊计算方法。基于模糊集合理论,对网络文本的情感强度与情感极性关系进行描述。
(2)多分类器集成的迭代自学习方法
现有基于自学习的无监督方法在使用分类器时,多采用单个分类器。但单个分类器的性能毕竟有限,而且每个分类器都有其适合分类的数据区间。某一分类器,对训练集中,某种分布的数据表现出比较好的效果,但是对测试数据集中另一种分布的待测试数据效果可能就变差很多。针对以上问题,框架提出了一种多分类器集成方法,通过对多个分类器的分类结果进行融合,选取情感分类结果精度高的文本生成伪标注文本集合,训练自学习情感分类器。通过多个分类器进行集成的方式既能提高分类的性能,又能保证测试结果的稳定性。
3 基于量化情感词典和字典的网络文本情感模糊计算方法
现有基于情感词典的方法采用通用情感词典,计算网络文本的情感类别,很少考虑情感强度对网络文本情感分类的影响。由于自然语言的模糊性,特别是情感词情感强度的模糊,用确定性集合理论描述网络文本情感强度和极性的关系存在一定的偏差。为此,我们提出了基于量化情感词典的和字典的网络文本情感模糊计算方法。
3.1 量化情感字典的构建
在无监督网络文本的情感分类中,情感词有很重要的作用。对那些不在情感词典中的词,我们有多种处理方法。针对中文词和字之间的关系,借鉴前人的工作,我们构造了一个情感字典。我们使用量化情感字典来计算无法在情感词典中匹配到的情感词的情感强度。量化情感字典的具体构造过程如下:
(1)首先我们取出正向情感词典和负向情感词典里面的二字词,将所有的词放到一起,并把全部的词分解为单个的字,最后,去除重复的字。
(2)分别计算每个字在正负情感词典中出现的次数N(pos),N(neg)。
(3)这个字的情感强度P(ls)就是
P(ls)=N(pos)/(N(pos)+N(neg))
如果系数大于0.5代表正向字,小于0.5代表负向字。
3.2 量化情感词典的构建
现有基于情感词典进行情感分类的研究方法多以两个极性词典即一个正向情感词典和一个负向情感词典为基础实现情感分类。这种方法使得所有的情感词只有一个粗粒度的情感倾向,无法根据情感词本身的情感强度进行更好的分类。为此,我们提出了情感词典的量化计算方法,以Hownet情感词典为基准,将正负情感词典分别标注情感强度,情感强度量化值的大小由强到弱分别标注为从5到1。
3.3 模糊计算方法
现在网络文本情感分类方法,主要基于确定性集合理论,计算网络文本的情感强度和极性。由于自然语言的模糊性,采用确定性集合进行计算时存在一定的偏差。为此,当我们计算网络文本的情感类别时,我们应该采取模糊集合来描述情感强度和情感类别的关系。以文本集合R={ri} 中文本ri的情感强度si(ri)为基础,我们定义文本集合R={ri} 的正负情感类别为模糊集P和N
P={(ri,μP(ri)|ri∈R)}
N={(ri,μN(ri)|ri∈R)}
这里,μP(ri)μN(ri) 是文本ri属于正负情感类别P和N的隶属函数。我们选择2次抛物函数作为文本ri的正负向情感类别隶属函数
(1)
(2)
这里ri是文本,si(ri)是文本ri的情感强度,a,b是决定成员函数边界的可调参数。
基于网络文本的正负类别隶属度函数,依据最大隶属度原则,我们把模糊集的正负隶属度函数合并为统一的模糊集分类函数。最终,我们得到以下模糊集的分类函数
(3)
我们定义k=(a+b)/2, 最终,我们不需要设定两个参数a和b的值,只需要设定一个参数k的值,就能实现文本的情感分类。在参数设定时,我们使用文章基于多粒度计算和多准则融合中的方法实现参数k的确定[2]。
4 多分类器集成方法
现有的基于自学习的情感分类方法主要基于单个分类器计算文本的情感类倾向度,然后按照文本可信度,选取伪标注文本[2]。因为采用单一分类器进行分类时分类精度不高,导致在生成伪标注数据集时,会生成较多错误标注数据。
为解决以上存在的问题,本文提出了一种基于多分类器集成的自学习情感分类方法,实现网络文本的精准分类。
本文提出的基于多分类器集成的学习情感分类方法基于情感词的无监督方法通过以下3个步骤来实现网络文本的精确分类:①通过构建量化情感词典的计算方法,然后按照语言学的规则在字、词、短语、句型4个语言粒度,作为集成分类器中的第一个分类器。②在针对现有在自学习框架的基础上,使用SVM分类器和朴素贝叶斯分类器作为第二个和第三个分类器。③通过以上3个分类器作为集成分类器来生成和更新伪标注数据。集成分类器有效地减少了伪标注数据的错误率,从而提升了标注训练数据集的精确度,因此在整体上对自学习情感分类器在性能上有了较大的提升。
该方法的具体步骤如下。
(1)对非监督分类结果,按照文本情感得分进行排序。
(2)统计正负情感得分的文本数量,统计文本的正负不均衡性。
(3)借鉴SVM最大分类间隔的思想,选择一部分文本作为已标注好的训练数据。
选取规则:用数量少的类别为基准,选取50%-90%的比例作为训练数据个数。从最大和最小两端进行选择。
例如:按分值从大到小顺序排列的文本共100个,其60个大于0,40个小于0,我们可以选20个作为训练集。最大的10个和最小的10个。用这些数据训练SVM分类器和贝叶斯分类器。
(4)用训练好的分类器对其余文本进行分类。
(5)把基于情感词典的文本分类结果和两个分类器的文本分类结果求交集,一致的文本作为正确结果添加到伪标注训练集中。
(6)重复(4)、(5),直到没有新的文本添加到训练集为止。
(7)对剩余的网络文本按照最后得到的2个情感分类器进行情感分类,求2个情感分类器分类结果的交集,并把交集中的文本作为争取结果添加到伪标注训练集中。
(8)重复(7),直到没有新的文本添加到训练集为止。
(9)对剩余的网络文本,采用SVM分类器的分类结果作为最终分类结果。
5 实验及其结果分析
为验证我们的方法在不同领域文本数据集和非平衡文本数据集上的性能,我们选择图书文本,酒店评论和非平衡数据酒店评论作为本次实验的数据集。本次实验的数据集(http://www.datatang.com/data/11936/)由中科院谭松波博士提供集。每个数据都包含有正向评论和负向评论。实验所用数据集如见表1。
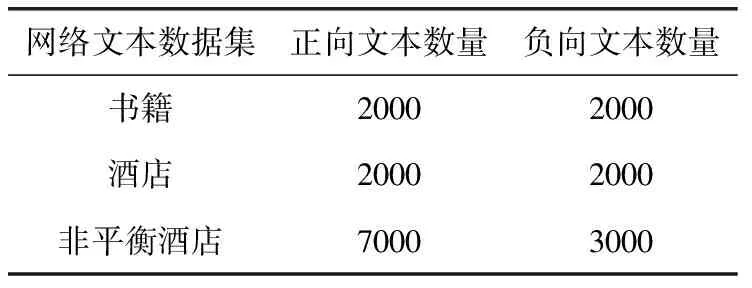
表1 文本数据集的分布
为验证我们所提情感分类方法性能,选取召回率R、准确率P、精度AC和F1,4个分类指标作为标准指标[2]。以基于情感词典的无监督网络文本情感分类方法SLE[12],基于情感词典和规则的无监督网络文本情感分类方法SLR[13],基于多粒度计算和多准则融合的方法SLC方法[2]作为比较基准。在4个评论数据集上进行了实验,实验结果见表2。
分析表2的实验结果可以发现,本文方法的性能比SLE,SLR和SLC方法都有明显的提升。与现有基于多粒度计算和多准则融合的方法SLC相比,在书籍测试数据集中,我们方法提升了4.42%的AC。在酒店测试的数据集中,我们方法提升了1.5%的AC。在非平衡酒店的测试数据集中,我们方法提升了1.41%的AC。实验结果充分说明了本文方法的有效性。
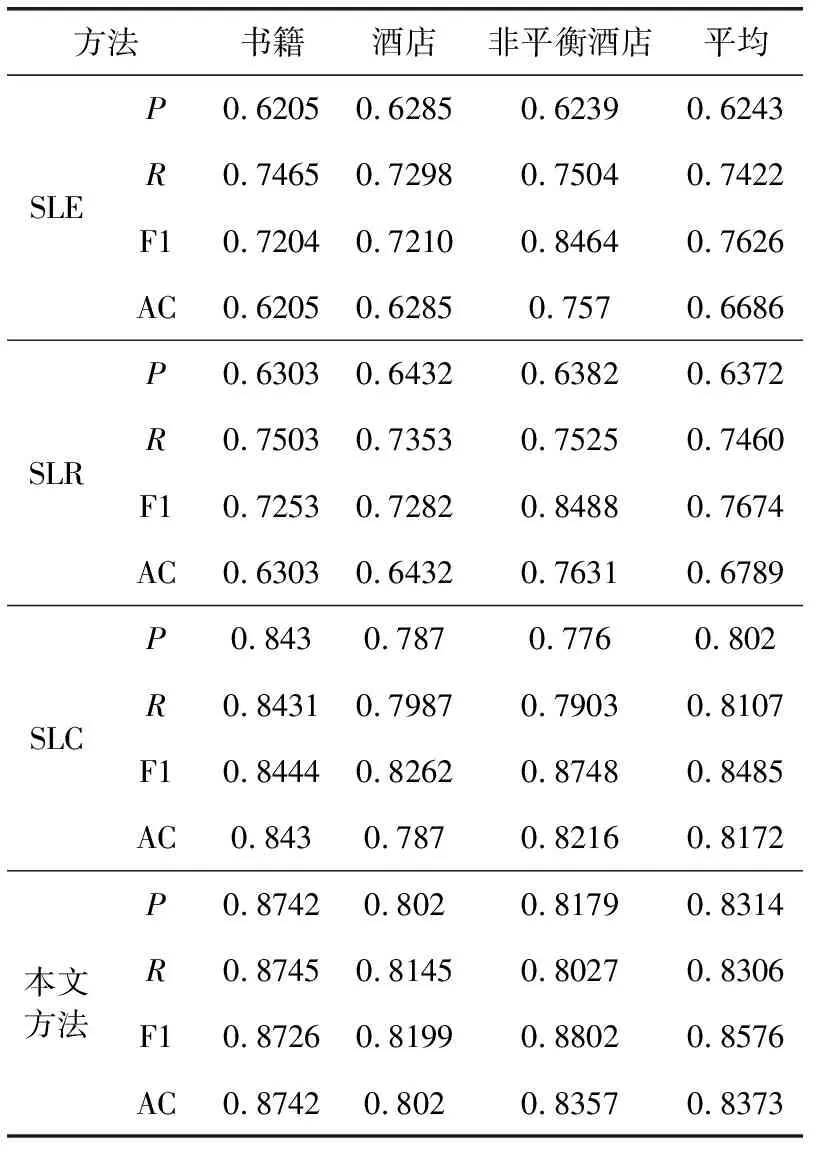
表2 不同法性能比较
为研究不用k值对本文方法的影响,分别选取k的值为-1、-0.8、-0.6,、-0.4、-0.2、0、0.2、0.4、0.6、0.8、和1.0作为参数k的取值,得到本文方法在不同k值下的准确率、召回率、F1值和精度分类结果,如图2~图5所示。
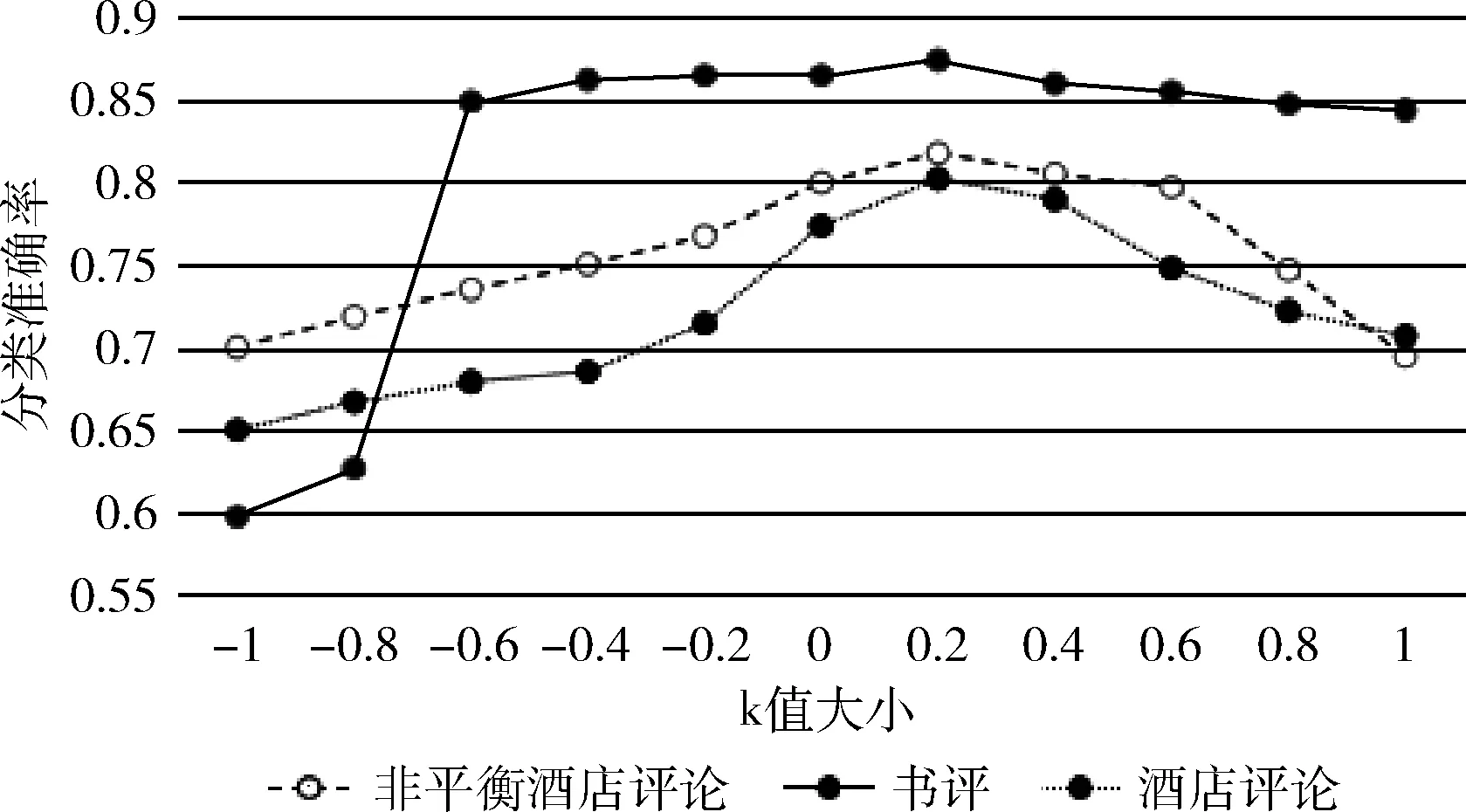
图2 准确率指标测试
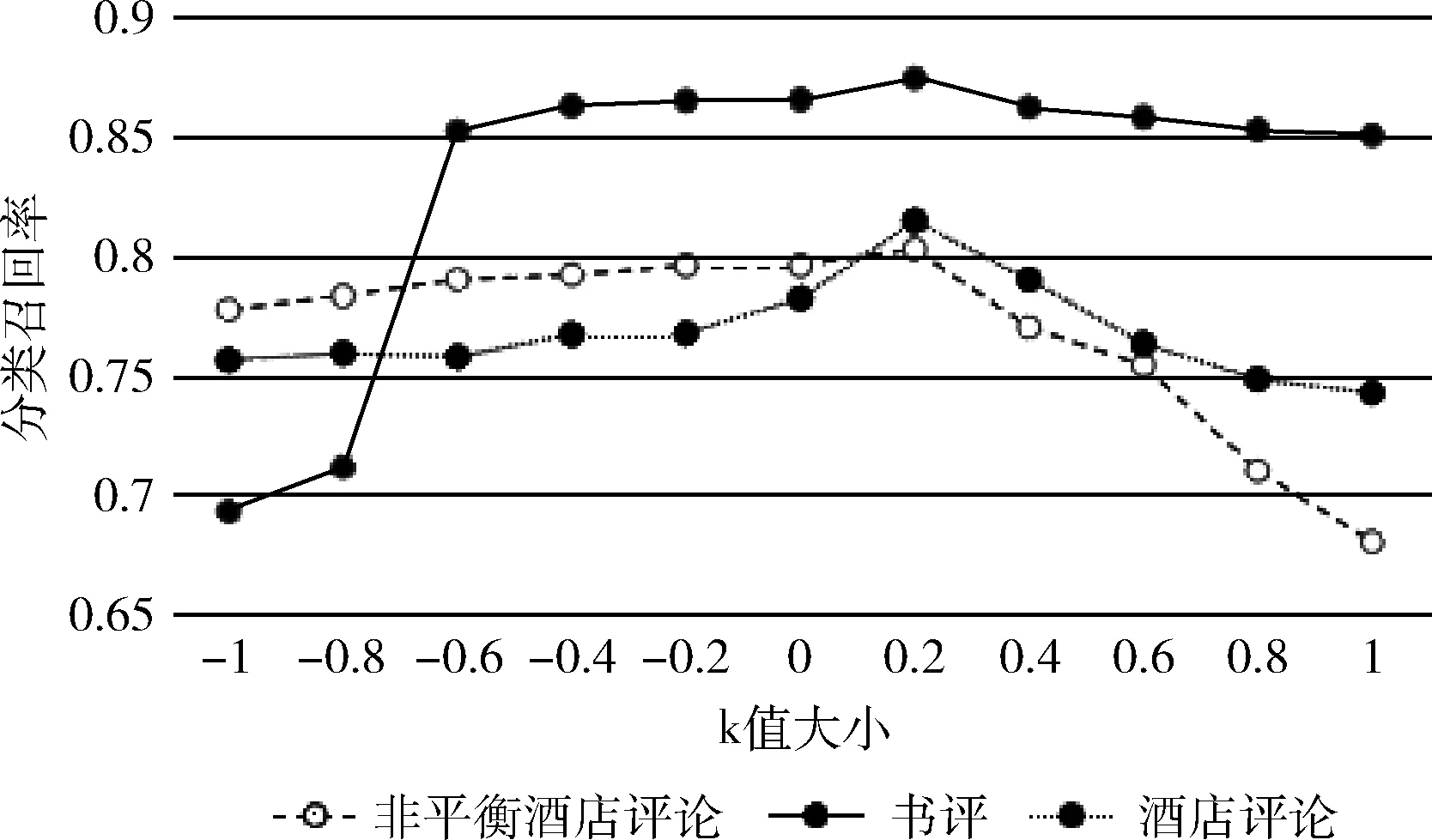
图3 召回率指标测试
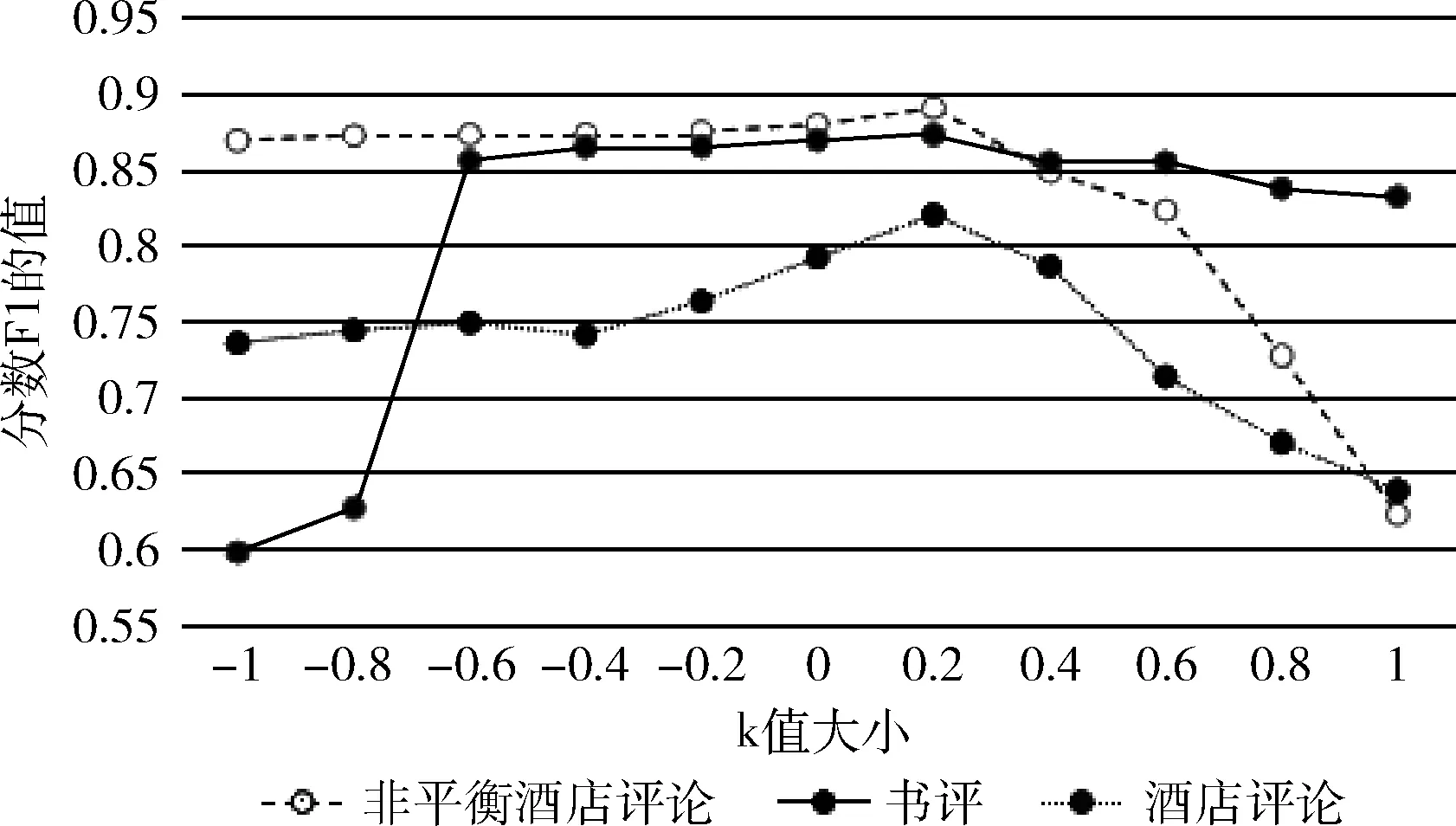
图4 F1值指标测试
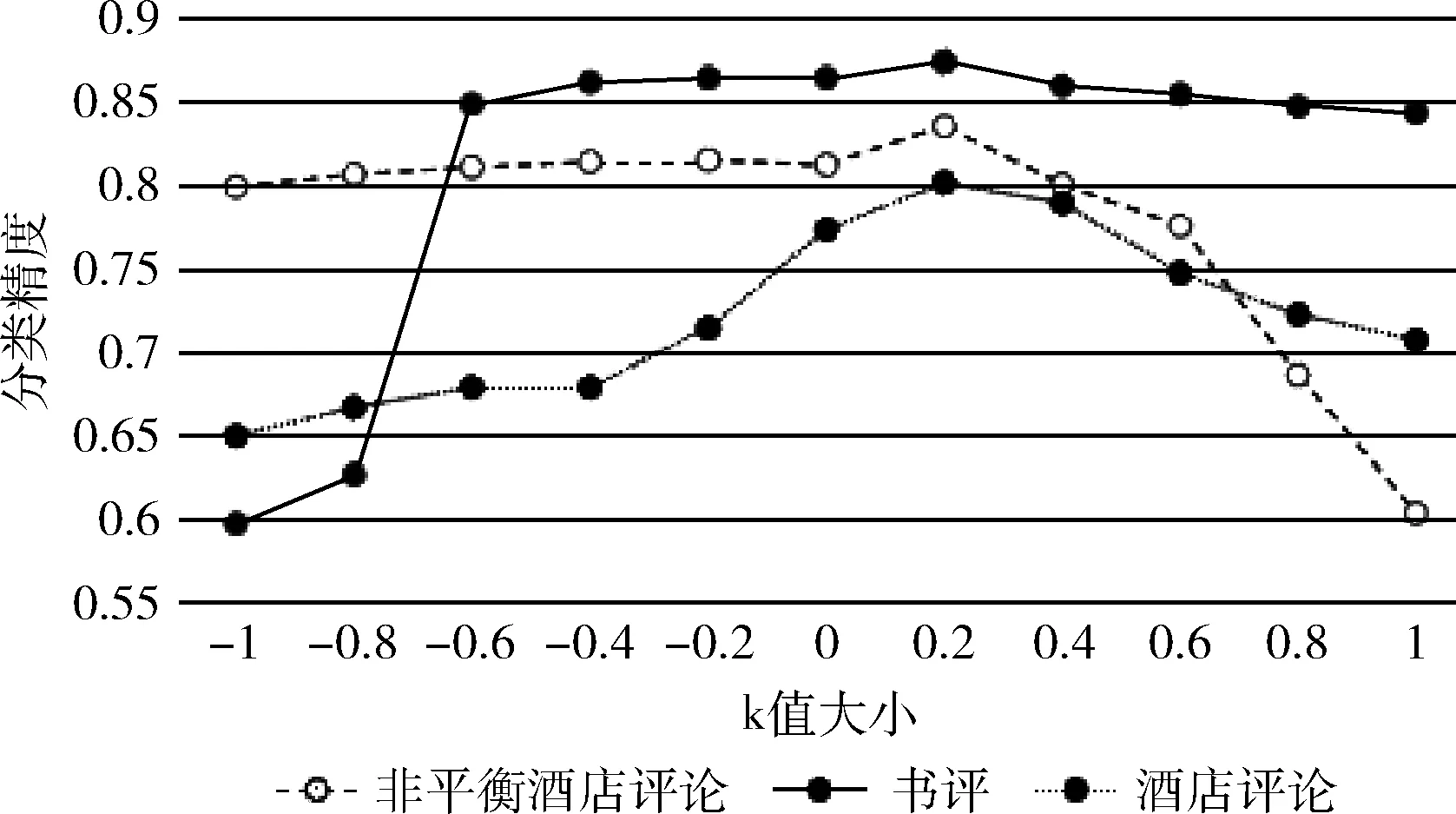
图5 精度指标测试
从图2~图5可以看出,在3个不同的评论数据集上,在参数k的取值大小为0.2时,本文的方法表现出了更好的性能。
我们的方法之所以取得较好的效果,主要原因在于,在网络文本的情感预分类阶段,我们构造了量化情感词典,与现有正负极性的情感词典相比,我们构造的量化情感词典对网络文本的情感强度计算具有更丰富和细致的表现能力。我们基于模糊集合理论对网络文本的情感强度和情感类别进行建模,较好地刻画了情感强度的模糊性。在网络文本情感分类的自学习阶段,我们通过多分类器集成,解决了单一分类器分类精度较低、构造伪标注训练数据集错误率高的问题,进一步提升了网络文本情感分类的精度。
6 结束语
本文提出了一种基于集成学习的情感模糊计算分类方法。对比已有文献的相关文本分类算法,分析已有算法存在的问题,对传统文本分类算法进行优化。针对相同情感极性情感词没有区分情感强度问题,构建了量化情感字典和量化情感词典。针对传统文本分类中没有考虑情感强度的模糊性问题,采用了情感强度的模糊计算方法。通过以上两种方法提高无监督情感预分类的精度。通过多分类器集成的方法可以降低伪标注数据集的错误率,从而整体上提高情感分类的准确率和精度。
