面向处理器微体系结构评估的高通量MicroBenchmark研究
2018-07-19苗福涛叶笑春孙凝晖徐文星
薛 瑞 苗福涛 叶笑春 孙凝晖 徐文星
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) 2(中国科学院大学 北京 100049) 3(中国农业银行 北京 100073) 4 (北京石油化工学院 北京 102617) (xuerui@ict.ac.cn)
随着互联网、云计算、社交网络等技术的飞速发展,全球产生的信息量急剧增长.全球数据库每天以2.5 MB的数据增长,其中90%的数据是在过去2年创造的,这些数据无处不在[1].例如能源、制造业、交通运输业、服务业、科教文化、医疗卫生等领域都积累了TB级、PB级乃至EB级的大数据.著名的全球连锁超市沃尔玛每小时需要处理100余万条的用户请求,维护着一个超过2.5 PB的数据库;在高能物理实验中,2008年开始投入使用的大型强子对撞机每年产生超过25 PB的数据;社交网络Facebook现已存储超过500亿张照片.
海量数据的快速处理的需求,对面向高通量应用的处理器微体系结构设计提出了更高的要求[2-3].然而,现阶段面向高通量应用的Benchmark,如DCBench,LinkBench,CloudSuite,BigDataBench等,大都是在Hadoop等计算机集群平台针对目标系统进行测试,主要衡量的是网络、IO等系统能力,难以对处理器微体系结构的设计进行有效的评估.因此,针对高通量处理器微体系结构评估的需求,也急需一套新的、面向高通量应用的处理器微体系结构评估的基准测试程序.
针对上述问题,本文首先从高通量的典型应用出发,分析高通量应用实例的整体特征;然后选取高通量应用中的典型Workload作为代表,分析面向高通量应用的处理器的微体系结构需求,设计并实现了一套面向高通量应用的处理器微体系结构评估的基准测试集:HTC-MicroBench;最后通过HTC-MicroBench对现有的代表性多核和众核处理器微体系结构进行性能测试和分析.
1 相关工作
Benchmark的主要作用是对计算机系统或计算机的各组件进行测试评价,从而更好地指导计算机系统的设计或者指导消费者选择合适的计算产品.而对处理器微体系结构的研究作为计算机系统结构研究中的重点方向,也离不开对相应Benchmark研究的支持.
传统的高性能计算领域的Benchmark有SPEC基准测试体系[4],SPEC CPU 2006是业界常用的一套程序集,包括整型计算和浮点计算,覆盖到了计算机编程、算法、人工智能、基因、流体力学、分子动力学和量子计算等方面,保证了测试的完整性.PARSEC是多线程应用程序组成的测试程序集[5],具有多线程、新型负载、非针对高性能和研究性等几个典型特征,主要应用于计算机视觉、视频编解码、金融分析、动画物理学和图像处理等.HPCC是测试高性能计算能力的基准测试集[6],包含HPL,DGEMM,STREAM,PTRANS,FFTE,RandomAccess和带宽延迟[7]测试7个主要的测试程序,可以对浮点计算能力、持续内存带宽大小、处理器协作能力、随机内存访问效率和内部高速互联网络的性能等方面进行测试.以上Benchmark主要针对高性能应用中计算量大的特点进行基准测试程序的设计,而没有考虑高通量应用的主要特征.
对于大数据相关应用领域的Benchmark也已经有大量的研究成果[8].HiBench是Intel开放的Hadoop Benchmark集[9],包含9个典型的Hadoop负载,用于测评运行Hadoop集群的性能;雅虎开发的YCSB用于对比NoSQL数据库的性能[10],其目的是评估键值和云数据库;DCBench是针对数据中心负载的Benchmark集[11-12];第1个发行版本含有19个代表性的负载,根据应用特征的不同,可以分为on-line和off-line这2类,根据编程模型的不同,可以分为MPI,MapReduce等[13];LinkBench是Facebook开发的一套用于对社交网络数据库进行性能测评的工具集[14];专门用于测试存储社交图谱和网络服务的数据库;CloudSuite[15]是针对云计算开发的一套测试程序集,CloudSuite2.0选取了数据分析、数据缓存、数据服务、图分析、流媒体、软件测试、网络搜索和网络服务等云计算中常用的负载;BigDataBench[16-17]是由中国科学院计算技术研究所开发的一套互联网大数据应用相关的Benchmark集,其覆盖了结构数据、半结构数据和非结构数据,其负载模拟了搜索引擎、社交网络和电子商务等业务模型[18].
一个Benchmark必须有特定的目标系统和特定的目标应用类型[16].因此,虽然以上Benchmark的目标应用具有高通量应用的特点,但是其目标系统不是处理器的微体系结构,没有针对处理器的微体系结构进行测试和评估.例如HiBench用于对Hadoop集群性能测试、YCBS用于对NoSQL数据库系统测试、LinkBench用于对社交图谱数据库测试、BigDataBench关注互联网服务系统整体性能等.
在目标系统层面,系统级的评价主要关注系统运行的整体性能,如集群内部协同工作的效率、板间互连和通信的效率、系统软件栈的性能等.而对于处理器的微体系结构的测试和评估主要关注如众核处理器中多个核的并行处理能力、线程在处理器中的调度效率、共享存储的利用效率、Cache效率、CPU吞吐量等.在目标应用层面,学术界对高通量应用的研究尚不完善,缺少一个整体的对高通量应用的归纳、分类和分析的工作.本文的目标系统是高通量处理器微体系结构,目标应用是高通量应用.
2 高通量应用Workload分类模型
2.1 高通量应用及Workload
高通量处理器是适用于互联网新兴应用负载特征的在强时间约束下能够全局可控地处理高吞吐量请求的高性能处理器系统.高通量应用和传统的高性能应用存在本质上的区别,表1对高通量应用负载特性和高性能负载特性进行了对比.从表1中可以看出,面向网络服务的新型高通量应用在很多方面和面向科学计算的高性能应用存在着不同之处.传统高性能计算主要针对科学计算应用,程序往往具有较好的局部性,属于数据密集型和计算密集型应用,其所追求的目标是提高单个应用的执行速度,这类应用以LINPACK[19]为典型代表.而高通量应用面向的是新型网络服务,任务并发度大且对实时性有较高要求,其数据量大且程序局部性较差,属于数据密集型和请求密集型应用[20].这类应用追求的目标是高通量,即提高单位时间内处理的并发任务数目[21].

Table 1 The Comparative Analysis of High-Throughput Load and Conventional High-Performance Load 表1 高通量负载与传统高性能负载对比分析
通过对业界已有典型的大数据Benchmark[22-23]和UC Berkeley提出的patterns中的相关内容,调研分析了当前热门的高通量研究领域和实用领域,总结出典型的高通量应用包括大数据分析、机器学习、网页搜索、社交网络、电子商务、无线网络控制器和流媒体等.
上述的每一类应用又包括各自特有的Workload集合.表2所示是高通量应用及各应用的Workload汇总.
在此基础上,本文提出了一种基于高通量应用需求特点的高通量Workload的分类模型,对上述高通量Workload进行分类和分析.
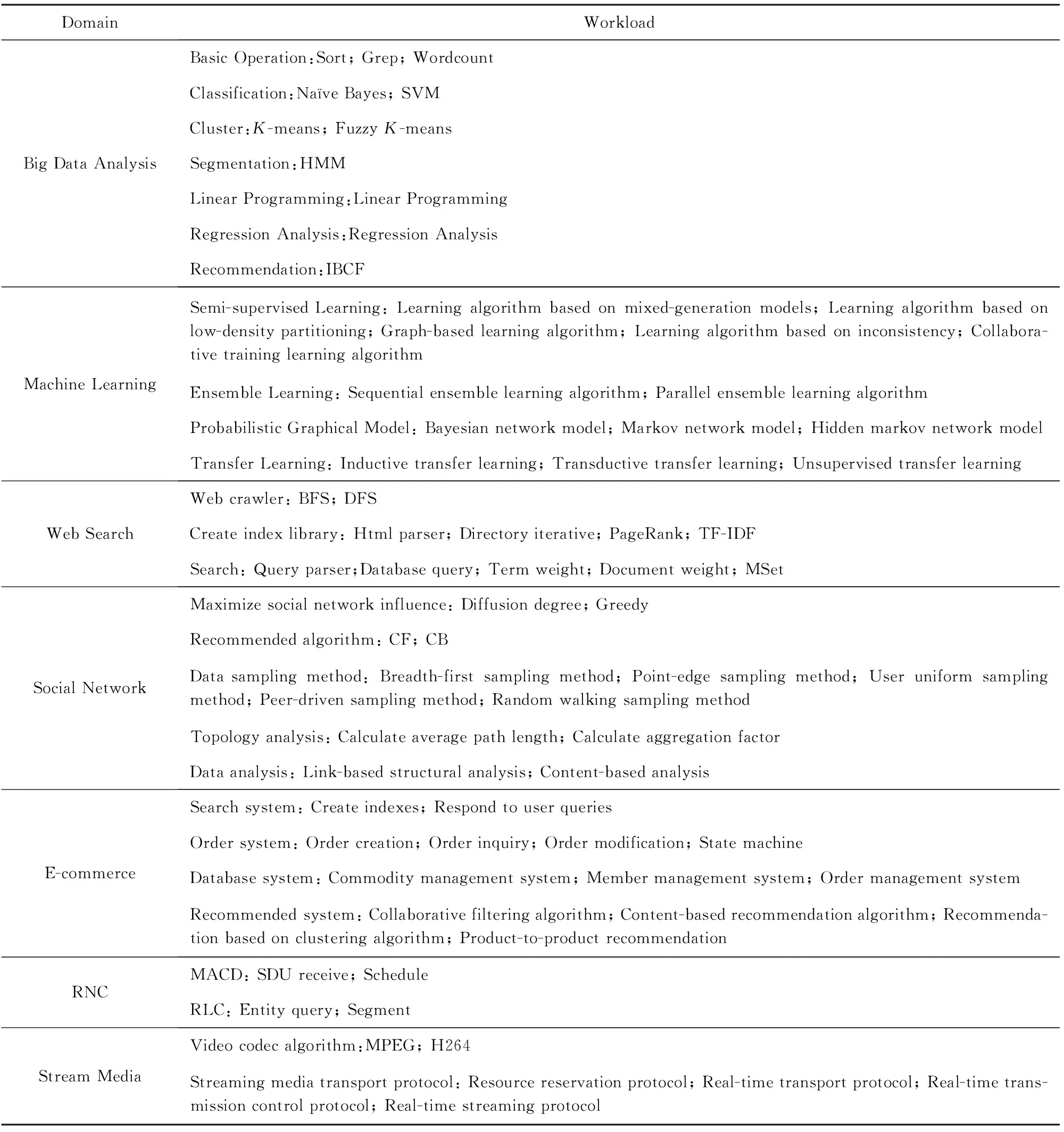
Table 2 Summary of High-Throughput Application and Workload表2 高通量应用及Workload汇总
2.2 分类模型介绍及Workload选取
对表2列出的应用进行应用特征分析,可将高通量应用的需求分为:单位时间内能够处理尽量大的数据量、单位时间内能够处理尽量多的请求数、能够同时支持尽量多的用户在线实时处理数据.根据上述3种高通量应用的需求,我们将高通量Workload分为数据处理类、数据服务类和实时交互类这三大类.图1所示是基于高通量应用需求的高通量Work-load分类模型.
本文所实现的Benchmark的选取主要基于2点原则:
1) 从3类高通量Workload中选取代表性Work-load.根据分析可知,每一类高通量Workload在应用特征和性能指标方面有很大的相似性,因此,从每一类高通量Workload中集中选取包含至少一个应用领域的Workload,来代表此类Workload.
2) 选取的Workload是使用量较大的.要保证从每一大类中选取出来的Workload具有代表性,则需要此Workload在测试性能中的使用量大.
基于以上2点原则,表3所示是本文选取的HTC-MicroBench中的Workload.
数据处理类选取了字符统计、Tera数据排序、聚类和搜索匹配等Workload来实现HTC-MicroBench[24],因为以上Workload均是大数据处理中的基础算法,使用量广泛.并且Workload之间相对独立,各个Workload所反映出的应用特点、程序特性和对硬件系统的需求也很相似.典型应用有大数据分析及机器学习.
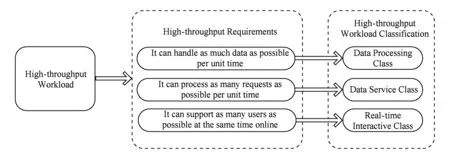
Fig. 1 High-throughput workload classification model图1 高通量Workload分类模型
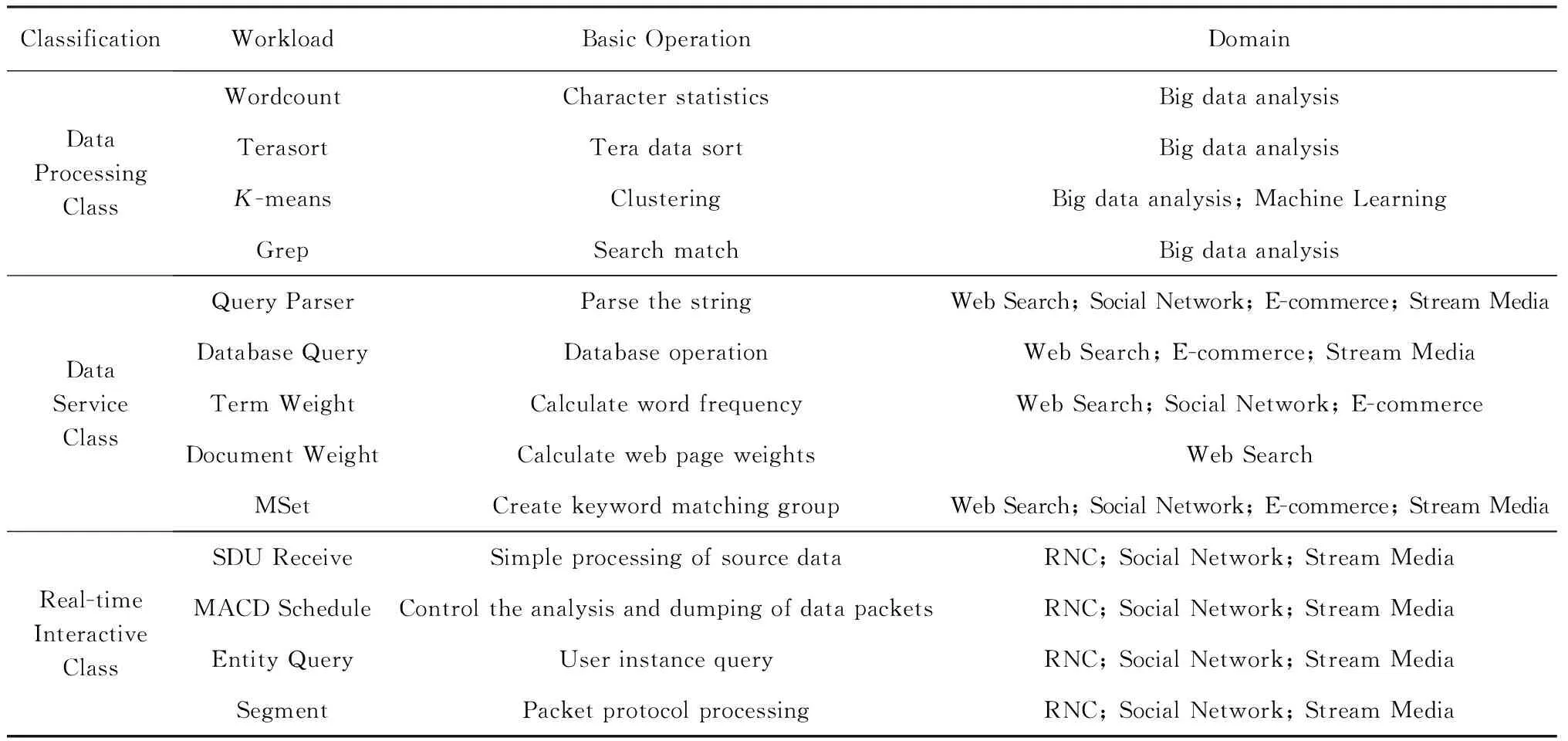
ClassificationWorkloadBasic OperationDomainDataProcessingClassWordcountCharacter statisticsBig data analysisTerasortTera data sortBig data analysisK-meansClusteringBig data analysis; Machine LearningGrepSearch matchBig data analysisDataServiceClassQuery ParserParse the stringWeb Search; Social Network; E-commerce; Stream MediaDatabase QueryDatabase operationWeb Search; E-commerce; Stream MediaTerm WeightCalculate word frequencyWeb Search; Social Network; E-commerceDocument WeightCalculate web page weightsWeb SearchMSetCreate keyword matching groupWeb Search; Social Network; E-commerce; Stream MediaReal-timeInteractiveClassSDU ReceiveSimple processing of source dataRNC; Social Network; Stream MediaMACD ScheduleControl the analysis and dumping of data packetsRNC; Social Network; Stream MediaEntity QueryUser instance queryRNC; Social Network; Stream MediaSegmentPacket protocol processingRNC; Social Network; Stream Media
数据服务类选取了解析字符串、数据库操作计算词频、计算网页权重和建立关键词匹配组等Work-load来实现HTC-MicroBench,因为以上Workload的特征要求在单位时间内处理尽量多的请求数,最符合数据服务类HTC-MicroBench的特点.典型应用有网页搜索、社交网络、电子商务和流媒体.
实时交互类选取了源数据的简单处理、控制数据包的解析转存、用户的实例查询和数据包的协议处理等Workload来实现HTC-MicroBench,因为以上Workload是根据协议的定义,模拟数据包处理流程,并且各个Workload之间是一个有机的整体,均需要能够对大量用户进行实时响应与处理,与实时交互类HTC-MicroBench表现特征一致.典型应用有无线网络控制器、社交网络、流媒体.
3 HTC-MicroBench的实现
由第2节分析可知,高通量应用的典型特点是含有大量小规模作业,作业之间耦合性低.因此,要提高处理器对高通量应用的吞吐效率,必须支持多处理节点并行处理.如Hadoop等系统级的软件栈[25-26],提高应用程序吞吐效率的重要手段就是采用分布式系统,并行化多节点处理作业.在处理器级别能够并行工作的载体是线程,因此,要实现HTC-MicroBench,需要将不同的作业处理节点用线程实现,以达到在处理器级别多节点并行的效果.
本文提出了一种适用于面向高通量处理器微体系结构评估的HTC-MicroBench的并行模型思想:基于线程的作业处理多节点并行模型.
3.1 数据处理类HTC-MicroBench多节点并行化模型
数据处理类HTC-MicroBench通常使用MapReduce框架,将算法的处理分为Map阶段和Reduce阶段[27].本文参考以共享内存方式实现的MapReduce框架的Phoenix系统对数据处理类HTC-MicroBench进行了实现[28].在基于线程来实现MapReduce框架时,我们在每个阶段,将算法中需要处理的大量数据分块,每块数据作为一个作业,交给不同的处理节点处理,一个处理节点为一个线程.图2所示是数据处理类HTC-MicroBench实现模型:
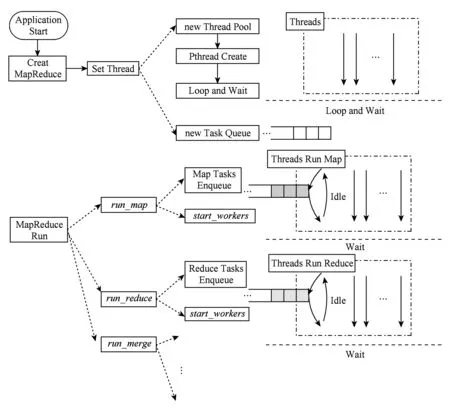
Fig. 2 Implementation model of data processing图2 数据处理类实现模型
算法开始运行时,首先会创建MapReduce类,在MapReduce类中创建线程,当线程创建时,会运行一个线程体,当线程体没有执行任何算法时,线程体会被一个信号量阻塞,进入Wait状态,不执行具体操作,同时将作业压入Task Queue中.然后,当算法开始执行后,执行到函数run_map时,DPUMRLIB内部会调用函数start_workers,打开信号量,此时线程体开始执行通过函数指针传入的函数,同时从Task Queue中取作业.运行完一个作业后,线程会再从Task Queue中取下一个作业来执行.最后,直到Task Queue中的作业被执行完毕,线程再次进入Wait状态,等待下一阶段(Reduce或Merge)的函数start_workers.
此设计的优点在于,即使Workload的Task都不相同,但每个物理线程执行的工作量是相同的,有利于均衡.另外,将线程处理的数据记录在Task中,并将线程执行的函数用函数指针表示增加了灵活性,线程可以在创建之后完成多种任务直到线程被停止.
基于此模型,本文对大数据分析中的Wordcount,Terasort,K-means,Grep算法进行了实现,作为数据处理类HTC-MicroBench.
Wordcount算法是经常用于大数据文本处理的1个算法,用来统计文本中各单词出现的次数.构建Wordcount测试用例需要完成split,map,reduce这3个功能函数.
函数split用于切分输入数据,将大量数据切分成小块数据,分发给多个函数map创建的不同线程.函数map是MapReduce中多线程并行处理部分,多个函数map由不同的线程来并行执行,函数map对各自对应的数据块进行词频统计.函数reduce用于合并各个线程得到的词频统计的结果.Wordcount算法执行过程如图3所示:
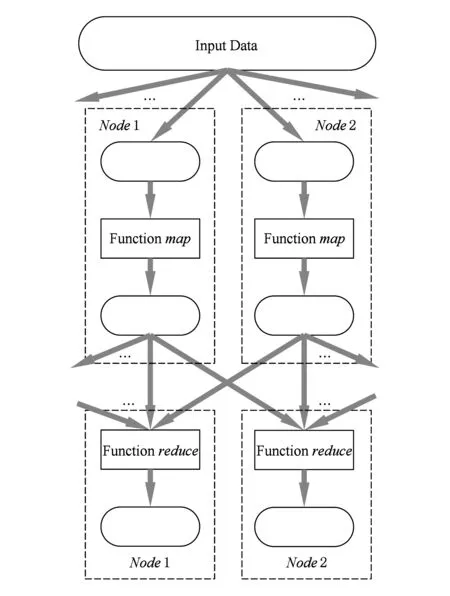
Fig. 3 Execution flow of Wordcount图3 Wordcount算法执行过程
Terasort算法是一个大规模键值对数据排序的算法,是计算机领域作为系统计算性能测评的标准算法.Terasort测试用例的构建主要包括3个步骤:
1) 数据采样.从需要排序的所有键值对数据中选取部分数据,采用传统的排序方式进行排序,然后根据需要的分割点个数,从排序后的数据中等步长的距离选择数据点作为分割点,组织到1棵Trie树中.在Map阶段,此Trie树中的数据作为将每个数据分到不同任务中的依据.
2) Map阶段.Map阶段的输入数据是对源数据进行简单切分后的一块数据,对其中的每一个数据,根据Trie树中的分割点信息,将数据分配到Reduce的各线程中.
3) Reduce阶段.每个Reduce的线程将从Map阶段得到的数据进行内部排序,然后按照Reduce的线程编号,顺序输出每个线程内部排序后的结果,即可得到最终排序结果.
K-means算法是用于聚类分析的经典算法,用于将多维空间中的大量数据点按照距离分到不同的集合.本文所实现的K-means测试用例流程如下:
1) 随机生成D维的数据点P个和D维的聚类中心点C个.对于每个聚类,定义一个D维的Sum,用于记录一次循环中,属于此聚类的各个数据点各个维度之和,定义一个Count用于计数属于此聚类的点的个数.Sum和Count用于在每次循环后,计算新的聚类中心点.
2) 每个数据点作为一个Map作业,每个Map作业计算此数据点到所有聚类中心点的距离,然后取距离最小的,作为此数据点此次循环所属的聚类.将此数据点的各维度的值与所属聚类的Sum各维度的值求和,得到新的Sum,Count值加1.
3) 所有数据点计算完成后,执行Reduce阶段,Reduce阶段对每个聚类计算新的中心点,计算公式为SumCount.
4) 循环执行过程2)3),直到所有数据点新计算出的所属聚类与上次循环计算出的所属聚类相同,结束循环.得到所有聚类中心点和所有数 据点所属的聚类.
Grep算法是大数据分析中最基本的算法.用于在大文本中匹配模式字符串.MapReduce框架实现Grep算法主要流程有3个步骤:
1) Split阶段对较大的源数据文件进行切分,每一数据块对应一个Map作业.
2) Map阶段在对应的数据块中查找模式字符串.
3) Reduce阶段对Map阶段匹配的结果做汇总.
3.2 数据服务类HTC-MicroBench多节点并行化模型
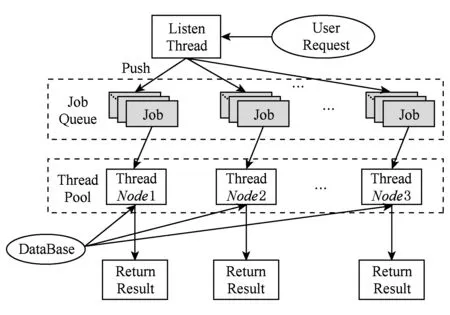
Fig. 4 Programming model of data service 图4 数据服务类实现模型
具体流程包括4个步骤:
随着身体的急速生长,个体的新陈代谢旺盛,血液循环和呼吸系统的功能也显著增强;心脏容积增大,收缩力增强。这给初中学生的活动范围提供了物质基础,使他们有了独立活动的体力和精力。一般来说,除了参加学校的体育活动之外,他们还有余力。如果剩余的精力用在不当之处,则会惹是生非。这就要求我们体育教师要善于引导他们,经常组织他们参加有益的集体体育活动,以利于他们的身心康健和培养他们良好的道德品质。
1) 创建一个Listen Thread,用于监听请求,将收到的请求发送到不同线程对应的Job Queue中.
2) 每个线程对应一个Job Queue,用于缓存Listen Thread接收到的用户请求.
3) 创建线程池,大量线程作为作业处理节点,循环从对应的Job Queue中获取作业,然后做相应处理.
4) 将处理结果返回给用户,作为对用户操作的响应.
基于此模型,本文对网页搜索应用响应用户请求中的Query Parse,Database Query,Term Weight,Document Weight,MSet算法进行了测试程序的实现,作为数据服务类HTC-MicroBench.
网页搜索应用中响应用户请求部分的执行过程如图5所示.
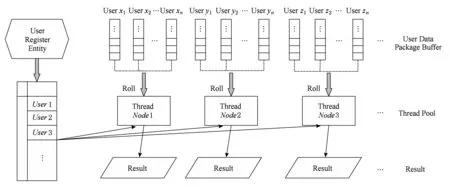
Fig. 6 Programming model of real-time interaction图6 实时交互类实现模型
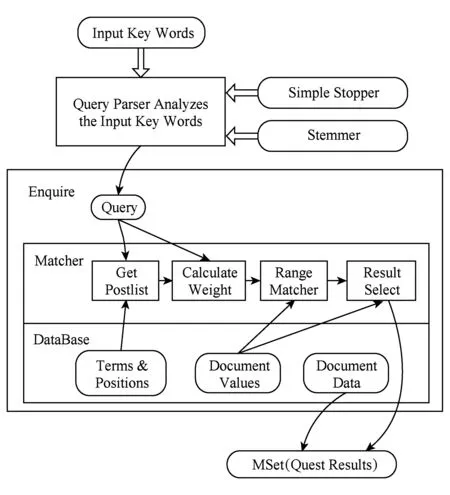
Fig. 5 Execution flow of response to the use request图5 响应用户请求部分执行过程
具体流程有4个步骤:
1) 由Query Parser对用户输入的Key Words进行解析得到Query,此过程主要是去掉Key Words中的Stop Words,提取单词词干得到Term,组织各个Term之间的布尔关系等,最后形成一个Query Tree;
2) 对Query Tree中每个叶节点的Term,进行Database Query,得到相应的数据;
3) 计算Term Weight,并结合Query Tree中的布尔关系,计算Document Weight;
4) 执行MSet过程,从查询结果中选取最符合要求的结果,返回给用户.
3.3 实时交互类HTC-MicroBench多节点并行化模型
实时交互类HTC-MicroBench中,每个作业按照协议处理用户数据.实时交互类HTC-MicroBench的编程模型,如图6所示.
具体包括3个部分:
1) 每个用户注册之后都会有与具体协议相关的实例表,处理数据时需要查询;
2) 线程池,大量线程作为作业处理节点;
3) 每个作业处理节点对应多个用户,轮询处理每个用户的数据包Buffer,处理时查询相应的实例表.
无线网络控制器应用是移动通信陆地无线接入网中数据处理的核心部分,包含用户面和控制面.控制面主要控制初始化、资源的分配以及数据处理结束后的资源释放,用户面负责对接入用户的数据包接收、存储、数据的协议处理和转发,整个用户面按照协议来处理用户数据.
基于此模型,本文对无线网络控制器应用中的SDU Receive,MACD Schedule,Entity Query,Segment算法进行Benchmark的抽取实现,作为实时交互类HTC-MicroBench.
无线网络控制器应用中响应用户请求部分的执行过程有4个步骤:
1) 利用SDU Receive算法,从核心网获取数据,得到含有用户业务信息的源数据,对源数据进行几个操作相对简单的协议层协议处理,得到RLC层的服务数据单元(SDU),并将RLC SDU缓存于SDU缓存区.
2) 为了保证服务质量,MACD Schedule算法控制每10 ms中完成一个用户SDU数据包的解析和转存.设计一个作业调度线程,配合一个定时器来进行用户SDU数据包调度和分发.当计时完成,作业调度线程从SDU数据包缓存区中读取每个用户的数据包,发送到不同作业处理节点等待处理.
3) 利用Entity Query算法进行实例查询.每个用户在接入系统时,注册一个用户实例,此实例中包含业务处理的相关信息.在对每个用户的SDU数据包解析之前,需要根据用户ID、查询实例表,得到用户SDU数据包处理的相关信息,以进行SDU数据包的处理.
4) 利用Segment函数对数据包进行协议处理.从当前作业节点对应的作业队列中,读取一个SDU数据包,解析SDU,获取头部信息,从头部信息中读取用户ID,根据用户ID查询实例表,根据实例表中的信息进行数据包的处理,然后将得到RLC PDU缓存.
经过4个步骤,一个SDU数据包即可被成功地分段重组成PDU并放入缓存区.
4 实验评估
4.1 基本程序特征评估
根据高通量应用的特征分析,HTC-MicroBench主要从3个方面进行验证:
1) 能够多节点并发处理作业.面向高通量应用的处理器的一个重要目的是在线程级别,支持高通量应用的大规模并发作业,因此,处理器的吞吐效率与用于处理作业的节点数量的关系,可以体现出设计的Benchmark是否具有良好的并发性,从而可以验证HTC-MicroBench设计的正确性和有效性.
2) 作业之间耦合性较低.由于本文所实现的Benchmark是基于共享内存并行编程模型的[29],每个作业是由一个线程来处理,所有线程均在多核或众核处理器上运行.因此,核间共享数据量的大小,可以反映出作业之间耦合性的大小.
3) 数据处理类HTC-MicroBench由于处理的数据量大、处理的数据存储规则,因此Cache命中率高.数据服务类和实时交互类HTC-MicroBench由于处理的是不同用户的数据,数据离散性强,地址空间访问不规则数据空间局部性差,因此Cache命中率较低.
基于上述分析,本部分实验主要从作业并发性、作业之间耦合性和Cache使用效率3方面对HTC-MicroBench设计的合理性和有效性进行验证.
4.1.1 作业的并发性评估
对数据处理类HTC-MicroBench进行实验.本实验所用平台是Intel Xeon处理器,处理器配置如表4所示:

Table 4 Intel Xeon Configuration表4 Intel Xeon处理器配置
各测试程序所用数据集分别为Wordcount(500 MB),Terasort(200 MB),K-means(12 MB),Grep(500 MB),数据处理效率与线程数的关系,如表5所示.
本部分主要关注各测试程序吞吐效率的并行加速比,因而对所有测试程序得到的数据,以1线程的情况为标准进行归一化,归一化数据吞吐率与线程数之间的关系,如表6所示.
数据服务类HTC-MicroBench关注的需求指标是单位时间内处理的请求数.对数据服务类HTC-MicroBench,即网页搜索应用中的响应用户请求部分进行实验.单位时间处理请求量与线程数的关系,如表7所示.
Table5TheRelationshipBetweenDataProcessingEfficiencyandTheNumberofThreads
表5 数据处理效率与线程数的关系 MBs
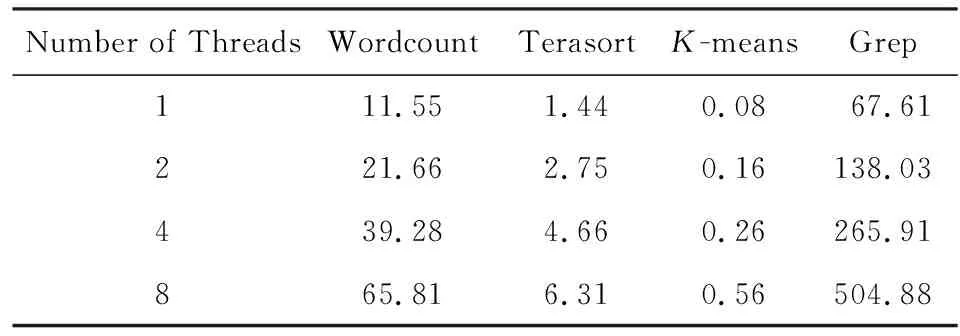
表5 数据处理效率与线程数的关系 MBs
Number of ThreadsWordcountTerasortK-meansGrep111.551.440.0867.61221.662.750.16138.03439.284.660.26265.91865.816.310.56504.88
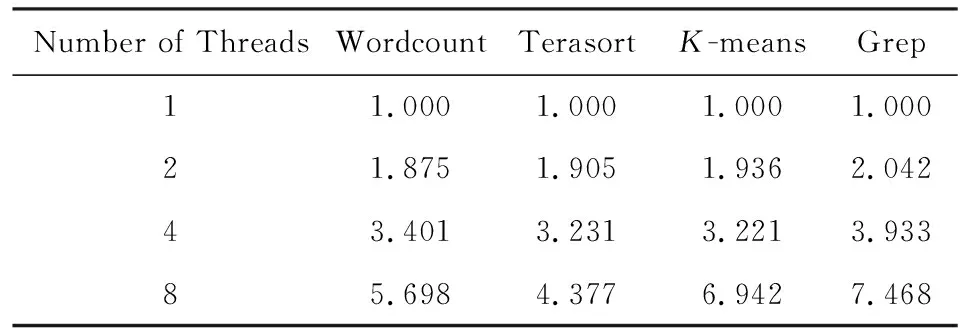
Table 6 The Relationship Between Normalized Data
Table7TheRelationshipBetweentheThroughputandNumberofThreads
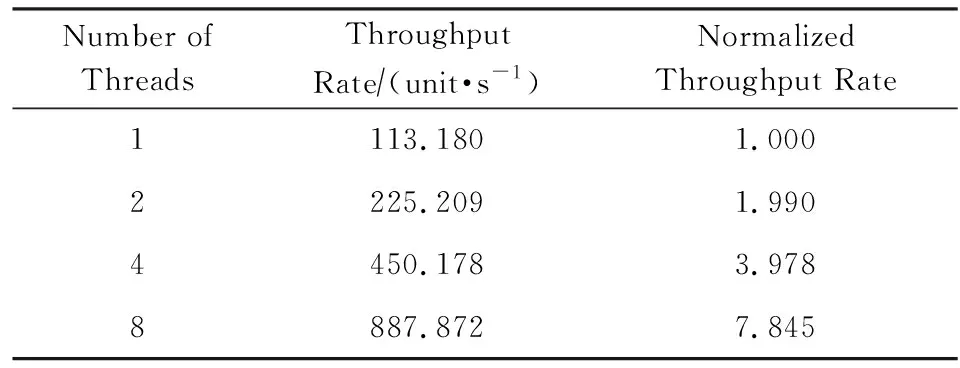
表7 单位时间处理请求量与线程数的关系
实时交互类HTC-MicroBench关注的高通量应用需求指标是在保证对每个用户的服务质量的前提下,能够同时支持在线用户数.实时交互类HTC-MicroBench,即无线网络控制器应用进行实验.支持用户数与线程数之间的关系,如表8所示:
Table8TheRelationshipBetweentheNumberofSustainingUsersandtheNumberofThreads
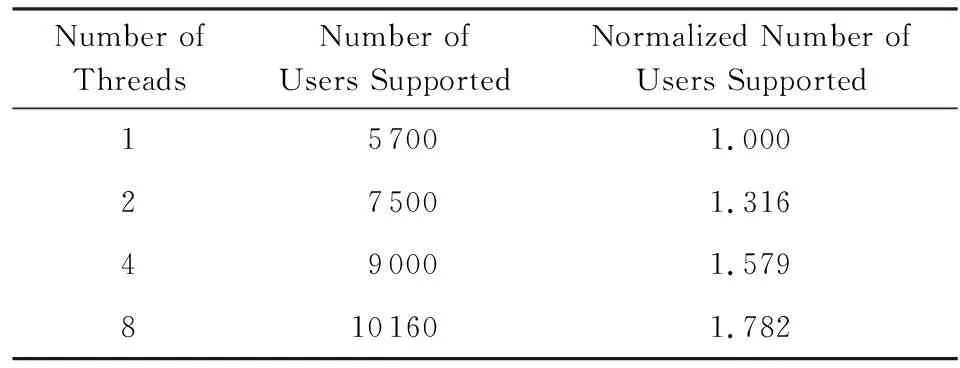
表8 支持用户数与线程数之间的关系
对以上各个测试程序的归一化测试结果做图表,HTC-MicroBench中各测试程序的并行加速能力,如图7所示:

Fig. 7 The ability of parallel acceleration for HTC-MicroBench图7 HTC-MicroBench各测试程序并行加速能力
由图7实验结果可以看出,HTC-MicroBench中的测试程序均有较好的并行加速特性,即各测试程序的作业之间具有良好的并发性,能够反映出高通量应用并发性的特点.当线程数为8时,加速比较线程数为1时有了4~8倍的提高.
4.1.2 作业之间耦合性
本实验使用Intel的硬件性能测试软件VTune进行实验,通过统计核间共享数据量占访存总量的比例来反映作业之间的耦合性,实验结果如图8所示.
由实验结果可以看出,HTC-MicroBench核间共享数据量占访存指令总数的比例是极小的,Wordcount只有不到0.02%,Terasort不到0.19%,K-means不到0.06%,Grep,Search,RNC均都不到0.02%.其中Terasort核间共享数据量所占比例最大,由于Terasort算法中,大部分需要多线程之间共享数据,但是,核间共享数据量也只有不到0.19%,而其他几个算法所占比例几乎是可以忽略的.因此,HTC-MicroBench能够正确反映出各作业之间低耦合性的特点.
4.1.3 Cache效率的评估
Splash2[30]是传统并行应用领域中典型的Benchmark,是斯坦福大学推出的共享存储并行应用Benchmark,其中选取的算法和应用都是传统高性能并行应用,本实验以Splash2为对比,选取其中的Raytrace,Cholesky,Radix,Ocean,Radiosity,Barnes这6个测试程序进行指标测试,验证HTC-MicroBench与传统的并行应用在Cache使用效率方面的差别,同时说明本文所实现的HTC-MicroBench的有效性.
本实验使用Linux的性能评估软件Perf进行实验测试,分别得到HTC-MicroBench和Splash2的L1 Cache Hit Rate,L2 Cache Hit Rate,LLC Cache Hit Rate这3个指标,其分别如图9~11所示.
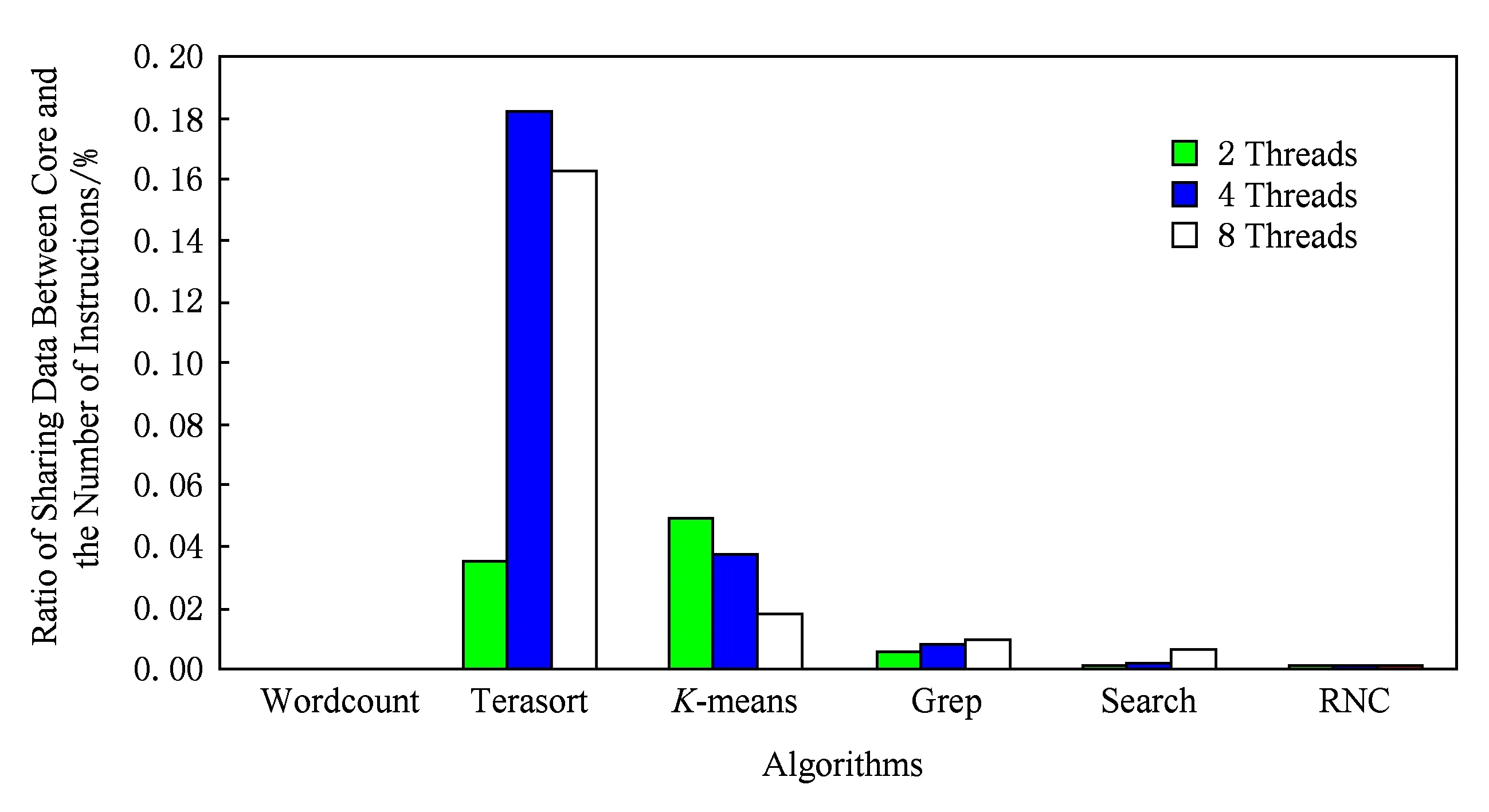
Fig. 8 The ratio of sharing data between cores for HTC-MicroBench图8 HTC-MicroBench各测试程序核间共享数据情况
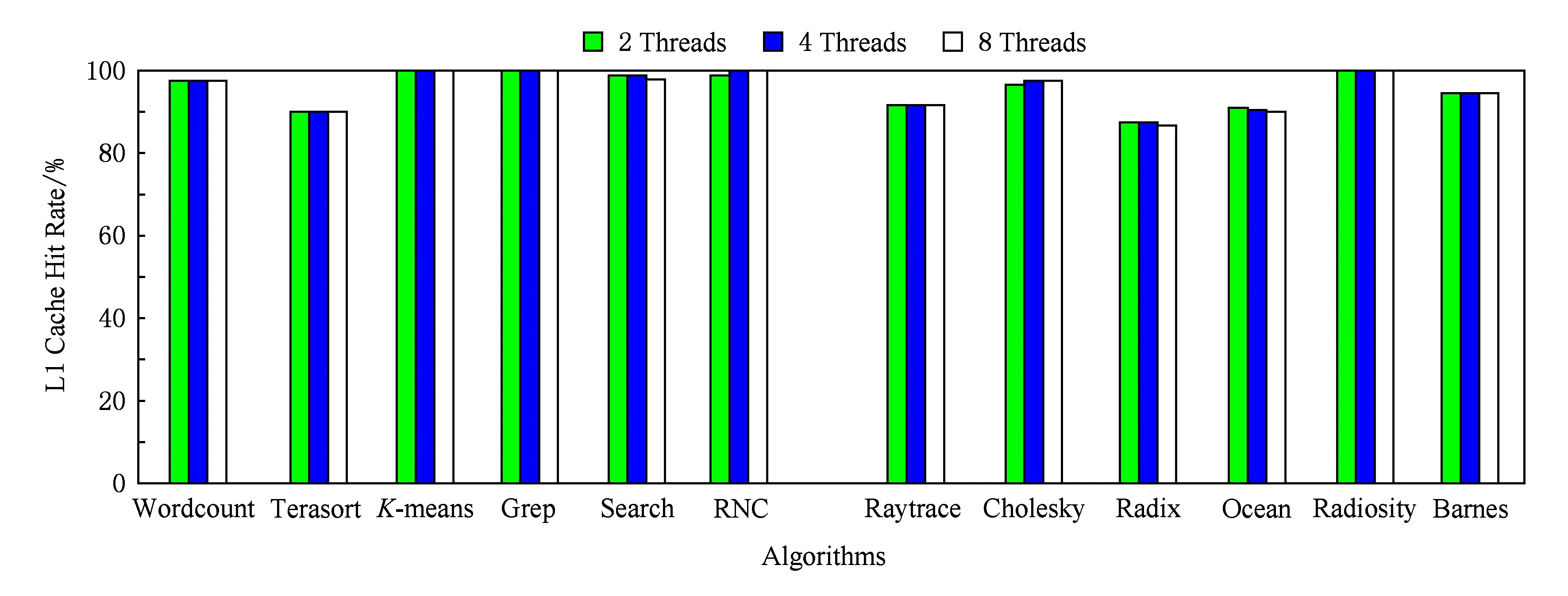
Fig. 9 The L1 cache hit rate of HTC-MicroBench and Splash2图9 HTC-MicroBench和Splash2各测试程序L1 cache命中率

Fig. 10 The L2 cache hit rate of HTC-MicroBench and Splash2图10 HTC-MicroBench和Splash2各测试程序L2 cache命中率

Fig. 11 The LLC cache hit rate of HTC-MicroBench and Splash2图11 HTC-MicroBench和Splash2各测试程序LLC cache命中率
由实验结果看出,HTC-MicroBench和Splash2的L1 Cache Hit Rate值都在90%以上,没有明显的差别.因为两者数据都具有较好的局部性特征,因此L1 Cache命中率高.而对于L2 Cache和LLC Cache,HTC-MicroBench的平均命中率比Splash2程序的明显要低.对于L2 Cache,HTC-MicroBench的平均命中率为65%,而Splash2程序为90%;对于LLC Cache,HTC-MicroBench的平均命中率为50%,而Splash2程序为80%.
这是由于L1 Cache具有较高的命中率,基本消耗了HTC-MicroBench应用的空间局部性特征,而且HTC-MicroBench应用具有流式特征,时间局部性并不强,且数据量巨大,时间局部性超出了低级Cache的相联度,导致L2 Cache和LLC Cache命中率较小.Splash2相对于HTC-MicroBench应用来说,时间局部性较强,数据量相对较低,因而L2 Cache和LLC Cache仍具有相对较高的命中率.
4.2 TILE-Gx和Intel Xeon处理器评估
TILE-Gx处理器是Tilera公司推出的一款众核处理器[31],使用了一种新的iMesh网络,iMesh是一种5层网络结构,使得各个处理器核之间能够高效通信.TILE-Gx处理器达到了处理效率更高,并发处理能力更强,能耗更小和扩展性更强等方面的效果.而处理器中的每一个核的处理能力有限,尤其对浮点计算的支持能力很弱.由于TILE-Gx处理器具有众核,并发处理能力强的特点,因此本实验采用的TILE-Gx系列中的TILE-Gx 8036处理器.
TILE-Gx 8036处理器有36个核,L1和L2这2级Cache是独立的,L3是共享的.表9所示是使用的TILE-Gx和Xeon这2种处理器的基本参数.
本实验主要关注TILE-Gx 8036与Xeon X7550在并行加速方面的性能对比.由于HTC-MicroBench主要是处理大量的规模较小、耦合性较低的作业,因此处理器的并行加速能力对作业处理能力具有决定性的影响[32].由于Xeon处理器只有16个硬件线程,因此以下实验均在16个线程及以下进行并行加速能力的对比.
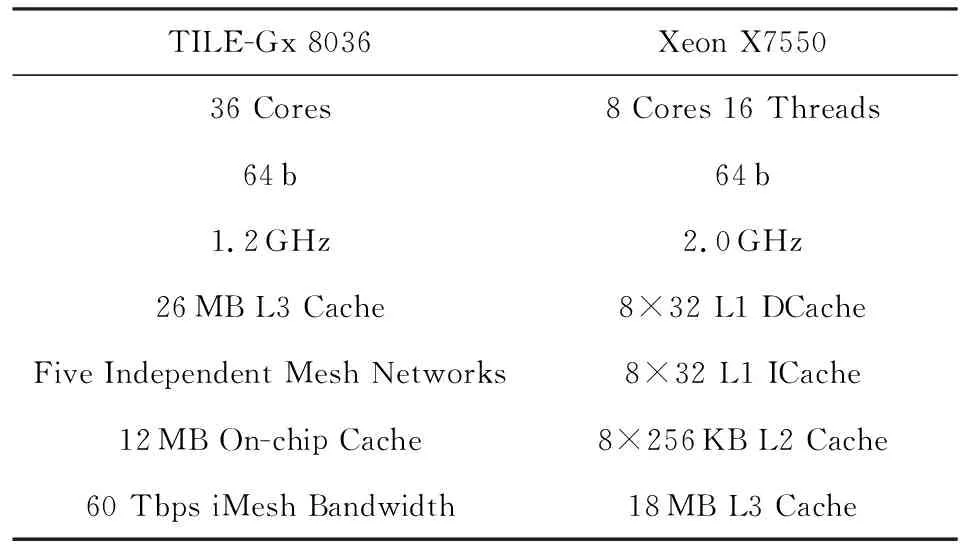
Table 9 The Basic Parameters of TILE-Gx and Xeon表9 TILE-Gx和Xeon的基本参数
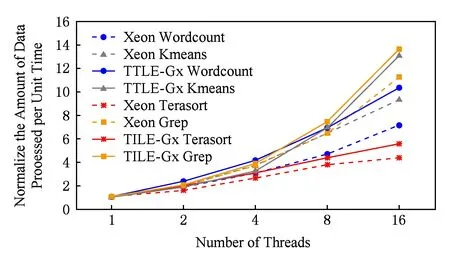
Fig. 12 The comparison between normalized throughput rate and the number of threads in Xeon and TILE-Gx图12 数据处理类测试程序在2种处理器平台并行加速比
对数据处理类HTC-MicroBench,在Xeon和TILE-Gx处理器分别对不同线程数的Workload单位时间处理数据量以单线程为标准进行归一化,得到归一化单位时间处理数据量与线程数之间的关系,如图12所示:
由实验结果看出,对于数据处理类HTC-MicroBench中的4种Workload,在TILE-Gx 8036处理器单位时间处理的数据量均大于在Xeon处理器单位时间处理的数据量.如矩形实折线部分Grep算法在TILE-Gx 8036处理器运行线程数达到16时,加速比比线程为1时提高了14倍,而矩形虚折线部分Grep算法在Xeon处理器运行线程数达到16时,加速比仅提高了11倍.因此TILE-Gx 8036处理器对数据处理类HTC-MicroBench有更好的并行加速比.
对数据服务类HTC-MicroBench,本实验测试单位时间内在Xeon和TILE-Gx处理器分别所能处理的请求数量,以单线程为基准做归一化,如图13所示:
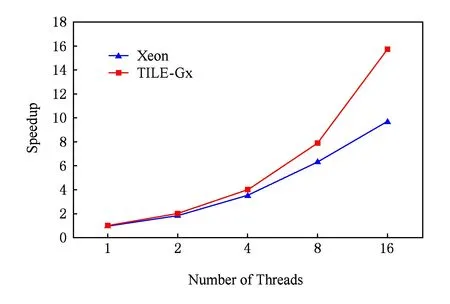
Fig. 13 The test result of speedup in Xeon and TILE-Gx processor (data service applications)图13 数据服务类测试程序在2种处理器平台并行加速比
由实验结果看出,TILE-Gx 8036处理器在线程数达到16时,加速比有16倍的提高,而Xeon处理器对数据处理类HTC-MicroBench的加速比仅提高了9倍.TILE-Gx 8036处理器对数据服务类HTC-MicroBench也具有更高的并行加速能力.
对实时交互类HTC-MicroBench,主要关注在保证对每个用户的服务质量的前提下,能够同时支持在线用户数.对于RNC用户面Benchmark,保证服务质量是指用户数据包由于系统繁忙而导致的丢包率在一定的范围之内,本文取丢包率小于5%为可接受的.
图14所示是实验得到RNC用户面Benchmark在Xeon和Tilegx这2种处理器上的结果.
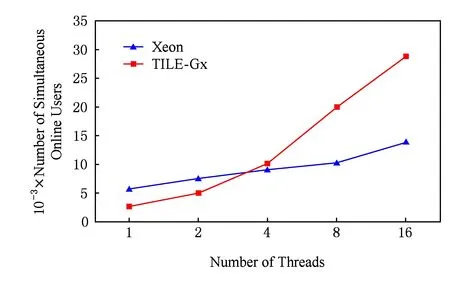
Fig. 14 The test result of speedup in Xeon and TILE-Gx processor (real-time interaction applications)图14 实时交互类测试程序在2种处理器平台并行加速比
由实验结果看出,TILE-Gx 8036处理器在线程数提高到16时,能支持的用户数是线程数为1时的11倍;而Xeon处理器对数据处理类HTC-MicroBench的加速比仅提高了3倍.对于实时交互类HTC-MicroBench,TILE-Gx处理器同样具有更高的并行加速能力.
综上实验结果可以看出,本文实现的面向高通量应用的HTC-MicroBench对Tile-Gx众核处理器和Xeon多核处理器均具有良好的并行加速比和并行处理能力,并且对于Tile-Gx众核处理器微体系结构具有相对更好的评估能力.
这也从另一个角度佐证了本文所抽取和实现的Benchmark对面向高通量应用的处理器微体系结构设计的评估是合理有效的.
5 结束语
本文实现了一个面向高通量应用的处理器微体系结构设计评估的Benchmark——HTC-MicroBench.首先,本文总结了高通量应用以及各应用相应的Workload,提出了面向高通量应用的处理器微体系结构设计评估的基准测试程序——HTC-MicroBench,并提出了一种基于需求特点的高通量应用Workload的分类方法.其次,提出并实现了一种基于线程的作业处理节点并行化模型,完成了HTC-MicroBench的设计和实现.最后,通过2组实验评估:1)对HTC-MicroBench中的Workload的并发性、耦合性和Cache使用效率进行了评估;2)使用HTC-MicroBench对比测试了8核Xeon处理器和众核TILE-Gx这2种处理器平台的并行加速能力,实验结果验证了本文所实现的HTC-MicroBench在面向高通量应用的处理器微体系结构评估方面的具有有效性和合理性.

XueRui, born in 1993. PhD candidate. Student member of CCF. Her main research interests include high throughput computing architecture and software simulation.

MiaoFutao, born in 1989. Master, engineer. His main research interests include the utilization of big data and machine learning in financial software system.
