基于关键信息的问题相似度计算
2018-07-19齐乐张宇刘挺
齐 乐 张 宇 刘 挺
(哈尔滨工业大学社会计算与信息检索研究中心 哈尔滨 150001) (lqi@ir.hit.edu.cn)
社区问答系统(community question answering, CQA)以其灵活的用户交互特性能够满足人们获取和分享知识的需求,成为广受用户喜爱的只是知识共享平台[1].与其他社会媒体相比,CQA提供了一种特有的交互方式.首先,提问者将其信息需求以问题的方式提交给系统,并等待其他用户给出答案.回答者根据其个人兴趣、知识水平,选择适当的未解决问题来回答,以分享自己的知识[1].
在社区问答中,问题相似度计算有着很重要的意义.针对用户提出新的查询,我们可以通过判断问题相似,在历史纪录中检索与之相似的已解决问题,并将这些问题的答案推荐给用户,从而避免用户的重复提问,也方便用户更快速地获取问题答案[1].
社区问答中的问题通常包括2个部分:1)问题的主题或标题;2)问题的详细描述.这2部分对于判断问题相似都有很重要的作用.然而,用户的提问长短不一,而且由于需求和背景不同,问题描述中可能包含大量对判断问题相似无意义的背景信息.举个例子,对于相似问题S和T(来源于QatarLiving①),如表1所示,两者句子长度相差悬殊,而且问题T中包含大量背景信息.在小规模的语料中,由于训练语料不足,若将全部文本作为神经网络的输入会引入大量噪声,而神经网络无法很好地去除这些噪声,因此会干扰对两者相似程度的判断.同时,问题主题是问题全部信息的高度概括,相似问题往往拥有相似的主题,主题不同但问题相似的概率很低,表1中的示例也证明了这一点.因此问题主题也是判断问题相似的重要依据.

Table 1 A Pair of Similar Questions in QatarLiving表1 QatarLiving中的相似问题
针对上述问题,本文将关键词和问题主题视为问题的关键信息,利用这些信息辅助神经网络模型判断问题相似,提出了一种基于关键词和问题主题的相似度计算模型(convolutional neural network based on keywords and topic, KT-CNN).该模型在文本间相似及相异信息的卷积神经网络(convolu-tional neural network, CNN)模型[2]基础上引入了关键词抽取技术并融入了问题主题间的相似度作为特征.
1 相关工作
在国内外均有大量研究人员进行社区问答中计算问题相似度方面的研究.部分研究人员使用基于翻译模型的方法判断问题相似或检索相关问题.Jeon等人[3]利用答案间语义的相似程度来估计基于翻译的问题检索模型的概率;Lee等人[4]基于经验将非主题词以及无关词汇去掉,构造了一个紧凑的翻译模型.除了词汇级别的翻译模型外;Zhou等人[5]提出了一种短语级别的翻译模型以提取更多的语境信息.基于翻译模型的可以在一定程度上解决文本相异但语义相近的问题,但其无法获取问题的结构信息、词共现信息以及语料中的词分布信息,而且会被翻译模型本身的误差所限制.
除了基于翻译模型的方法外,还有人利用基于主题模型的方法.Duan等人[6]使用基于最小描述长度(minimum description length, MDL)的树模型来识别问题主题和焦点,再通过问题主题和焦点来搜索相似问题;Zhang等人[7]认为问题和答案包括相同的主题,提出了一个基于主题的语言模型.该方法不仅对词项而且对主题进行了匹配;熊大平等人[8]则提出了基于潜在狄利克雷分布(latent Dirichlet allocation, LDA)的算法,该算法利用问句的统计信息、语义信息和主题信息来计算问句相似度.这一类方法主要利用问题主题的信息,其基本思想是主题相似的问题一定相似.其利用主题在语义层次上表示问题,但可能忽略文本中的一些细节问题.
于此同时,基于神经网络的方法也很流行.dos Santos等人[9]提出了一种将词袋模型同传统CNN模型相结合的神经网络模型,其效果要优于传统词频-逆文档频率(term frequency-inverse document frequency, TF-IDF)模型和基于长文本的CNN模型;Lei等人[10]为了解决关键信息隐藏在大量细节中的问题,提出了一种循环卷积网络将问题映射到语义表示.基于神经网络的模型从文本中自动抽取特征,可以更好地利用文本的语义信息,深层次地考虑文本间的相似性.
与这些模型相比,我们的模型利用了问题的关键词及主题信息,对问题的细节及全局信息进行了建模,能更好地表示问题.
2 模型介绍
我们提出的模型包括关键词抽取、基于关键词相似及相异信息的问句建模、计算主题相似度、问题相似度计算4个模块.对于输入的问题S和T,我们进行操作:1)进行一系列的预处理操作,再通过关键词抽取模块抽取S和T的关键词序列KeyS和KeyT;2)利用KeyS和KeyT间相似及相异信息对问题S和T建模得到S和T的特征向量FS和FT;3)对问题S和T的主题TopicS和TopicT计算相似度Simtopic;4)基于S和T的特征向量FS和FT以及问题主题间的相似度Simtopic计算问题S和T的相似度Simq.模型的结构如图1所示:
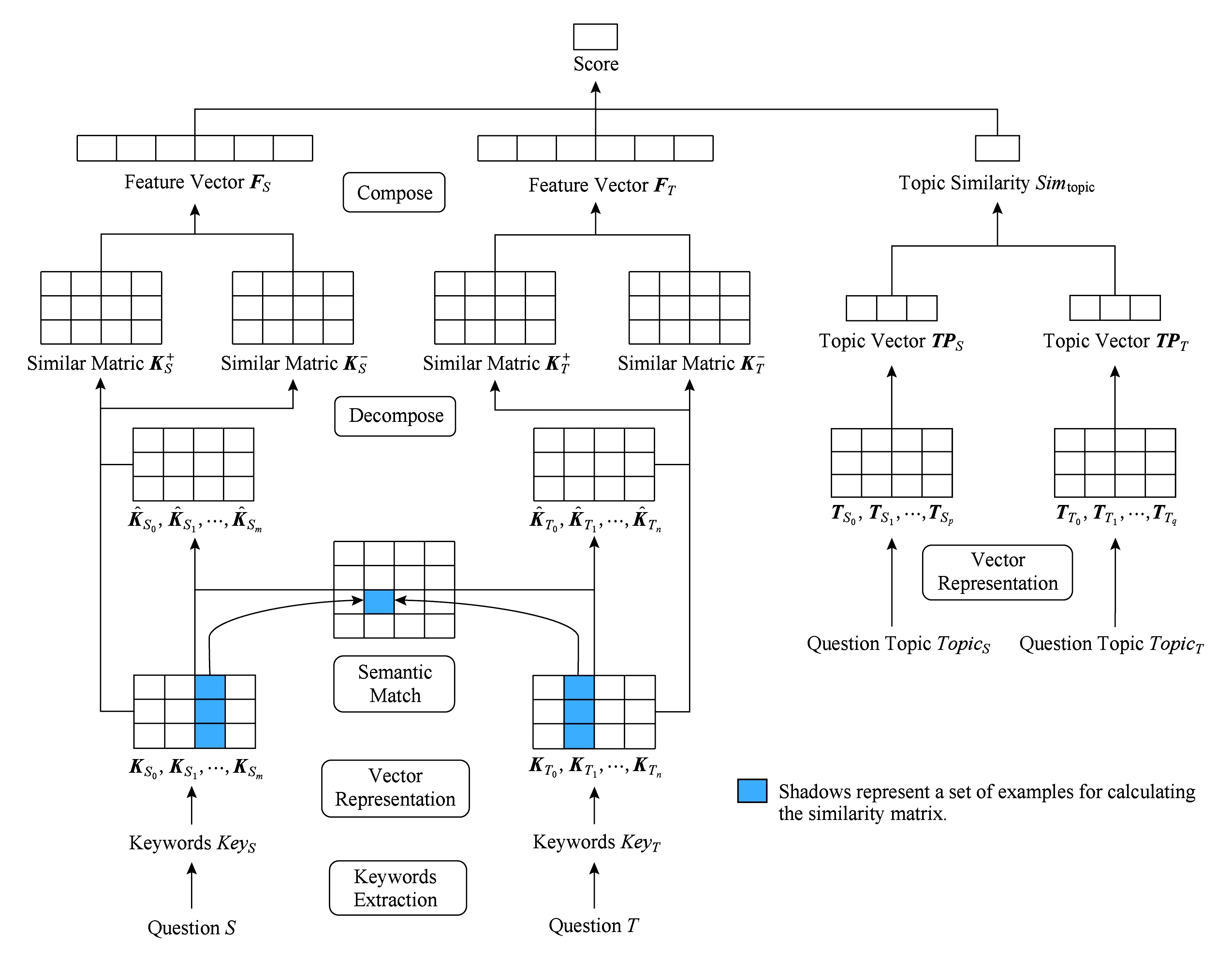
Fig. 1 Model architecture图1 模型结构
2.1 关键词抽取
我们对问题S和T的主题及描述抽取关键词KeyS和KeyT.由于问题的主题及描述可能包含多个句子,因此我们对问题的每个子句都抽取关键词.我们将其子句的关键词按照得分进行排序,然后再按照子句出现的顺序对所有的关键词进行排序,得到问题的关键词序列.
对于每个子句,我们使用了一种无监督的基于依存排序的关键词提取算法.该算法由王煦祥[11]提出,我们在该算法的基础上进行了一些改进.对于给定的问句,该算法利用统计信息、词向量信息以及词语间的依存句法信息,通过构建依存关系图来计算词语之间的关联强度,利用TextRank算法[12]迭代计算出词语的重要度得分.
算法流程如图2所示,主要步骤包括构建无向有全图、图排序以及选取关键词.

Fig. 2 The flow chart of keywords extraction图2 关键词提取流程图
首先,我们根据句子的依存句法分析结果对所有非停用词构造无向图.依存句法分析的结果为树结构,只要去掉根节点并忽略弧的指向便可以得到无向的依存关系图G=(V,E),V=w1,w2,…,wn,E=e1,e2,…,em,其中wi表示词语,ej表示2个词语之间的无向关系.
接着,我们利用词语之间的引力值以及依存关联度计算求得边的权重.
词引力值得概念由Wang等人[13]提出.作者认为2个词之间的语义相似度无法准确衡量词语的重要程度,只有当2个词中至少有一个在文本中出现的频率很高,才能证明2个词很重要.其受到万有引力定律的启发,将词频看作质量,将2个词的词向量间的欧氏距离视为距离,根据万有引力公式来计算2个词之间的引力.然而在社区问答的环境中,仅利用词频来衡量文本中某个词的重要程度太过片面,因此我们引入了IDF值,将词频替换为TF-IDF值,从而考虑到更全局性的信息.于是我们得到了新的词引力值公式.文本词语wi和wj的引力:

(1)
其中,tfidf(w)是词w的TF-IDF值,d是词wi和wj的词向量之间的欧氏距离.
依存关联度的概念由张伟男等人[14]提出.无向的依存关系图保证了问句中的任意2个词之间都有一条依存路径,而依存路径的长短反映了依存关系的强弱.因此,该算法根据依存路径的长度,计算依存关联度:
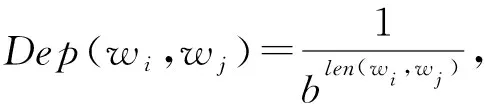
(2)
其中,len(wi,wj)表示词语wi和wj之间的依存路径长度,b是超参数.
综上,2个词语之间的关联度,即边的权重值是2个词的引力与依存关联度的乘积:
weight(wi,wj)=Dep(wi,wj)×fgrav(wi,wj).
(3)
最后,我们使用有权重TextRank算法进行图排序.在无向图G=(V,E)中,V是顶点的集合,E是边的集合,顶点wi的得分由式(4)计算得出,其中weight(wi,wj)由式(3)计算得出,Cwi是与顶点wi有边连接的顶点集合,η为阻尼系数.我们选取得分最高的t个词语作为句子的关键词:

(4)
2.2 基于关键词间相似及相异特征的CNN模型
由于文本间相似信息和相异信息对判断2段文本是否相似均有重要的作用,因此我们使用了一种基于文本间相似及相异信息的CNN模型[2]对问题的关键词序列进行建模,并在原模型的基础上进行了改进.

2.2.1 词向量表示
我们使用基于Pennington等人[15]提出的GloVe模型预训练的词向量来表示关键词.对于关键词序列KeyS和KeyT,我们将其表示为矩阵:
KS=(KS0,KS1,…,KSi,KSi+1,…,KSm)
(KT=(KT0,KT1,…,KTj,KTj+1,…,KTn)),
其中,KSi和KTj是关键词的d维词向量,m和n是KS和KT中包含的关键词数量.
2.2.2 语义匹配

为了计算语义匹配向量,我们先计算KS和KT的相似矩阵Am×n.原论文使用余弦相似度计算词汇间的相似程度,我们将其替换为皮尔森相关系数,即Am×n中的每个元素ai,j是KSi和KTj的皮尔森相关系数,相对于余弦相似度,皮尔森相关系数考虑了对均值的修正操作,对向量进行了去中心化:
ai,j=Pearson(KSi,KTj),
(5)

(6)

(7)
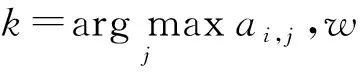
2.2.3 矩阵分解

(8)
2.2.4 矩阵合并

以问题S为例,CNN模型包括2个连续的层:卷积层和最大池层.我们在卷积层设置了1组过滤器{filter0,filter1} ,分别应用在相似通道和相异通道上来生成1组特征.每个过滤器的规模是d×h,d是词向量的维数,h是窗口的大小,其过程为
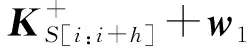
(9)

通过卷积层我们得到1组特征co=(co,0,co,1,…,co,l)特征的数量l取决于过滤器的规模以及输入关键词序列的长度.为了解决特征数量不固定的问题,我们对co进行最大池化的操作.我们选取co中最大的值作为输出,即co,max=maxco.因此,经过池化操作后,每组过滤器生成1个特征.最后特征向量的维数将取决于过滤器的数量.
2.3 问题主题间的相似度计算
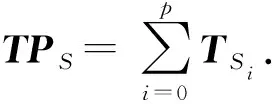
Simtopic=Pearson(TPS,TPT).
(10)
2.4 问句相似度计算
我们依靠基于关键词间相似及相异特征的CNN模型生成的问题S和T的特征向量FS和FT以及问题主题间的相似度Simtopic计算问题S和T的相似度.我们使用一个线性模型将所有的特征加权相加,其中w0,w1,w2是相应的权重,bsig是偏移项,最后我们用sigmoid函数将计算结果限制在[0,1]的区间内:
Simq=sigmoid(w0*FS+w1*FT+
w2×Simtopic+bsig).
(11)
3 实 验
为了证明我们提出模型的有效性,我们在SemEval2017[16]的评测语料上进行了实验.SemEval2017的任务3子任务B[16]的主题是社区问答中问题相似度计算.给定一个新提出的问题和10个由搜索引擎确定的相关问题,我们要依据问题间的相似度对相关问题进行重排序.该任务对相关问题设置了3个标签,分别为:PerfectMatch,Relevant,Irrelevant.我们认为标记为PerfectMatch和Relevant的是正例(不区分PerfectMatch和Relevant),标记为Irrelevant的是负例.对每一组问题的10个相关问题,我们使用模型得出的相似度对其进行重排序,并计算其平均精度,最后计算所有问题的平均精度均值(mean average precision,MAP)值作为系统的评价指标.MAP是反映系统在全部相似问题上性能的单值指标.系统检索出来的相似问题越靠前,MAP就可能越高.因此我们需要将标记为正例的问题排在标记为负例问题的前面.
SemEval2017的评测语料来自于QatarLiving,训练集包括270个问题,每个问题包括10个相关问题,共2 700个问题对.开发集包括50个问题,共500个问题对.测试集包括80个问题,共800个问题对.表2展示了1组训练数据的样例,每个问题包含问题主题和问题内容.虽然该任务是一个排序任务,但我们仍然按照分类任务对我们的模型进行训练并得到了很好的结果.

Table 2 The Sample of Training Data表2 训练数据样例
3.1 实验设置
在SemEval的语料中,由于用户书写不规范,语料中包含大量的错误.在实验前,我们对其中一些错误进行了处理.表3列出了一些错误示例以及我们处理后的结果.用户会将一些单词中的某些字符重复书写多次以表达感情,但这对我们处理问题造成了很大的干扰,因此我们将包含多余字符的词汇进行还原.而有些用户习惯用分号来分割句子,这会导致我们分句错误,因此我们将分号替换为句号.而且重复标点可能造成分词错误或句法分析错误,因此我们也将重复的标点去掉.与此同时,我们还将所有的字母全部变为小写以便后续处理.


Table 3 Error Example表3 错误示例
在CNN模型中,我们设置计算语义匹配向量的窗口w=3,卷积层中过滤器的尺寸为300×3,卷积层过滤器的个数为500.我们使用对数似然函数作为损失函数,使用SGD算法对模型进行优化,同时设置学习率为0.005.
在实验中,我们使用了2种不同的词向量.在关键词抽取模块以及CNN模块中,我们使用斯坦福大学GloVe模型[15]预训练的300维的词向量.该词向量没有在QatarLiving的语料上进行训练,更具有通用性,可以在一定程度上防止过拟合.而在基于问题主题的相似度计算模块中,我们使用了在QatarLiving语料上进行预训练的200维词向量[19].该词向量更具有领域的特殊性,因此更适合用于直接计算相似度.
3.2 结果及分析
首先,我们进行一组实验证明关键词提取和主题间相似度是有意义的.我们先后去掉基于主题信息的特征和关键词提取模块进行实验,接着我们将这2个模块全部去掉进行实验.实验结果如表4所示:

Table 4 Model Comparison Experiment表4 模型对比实验
实验证明,基于关键词的模型要优于基于全部内容的模型.我们从3方面分析原因:
1) 由于不同问题包含的词汇量不同,可能差异很大.这导致将全文作为神经网络的输入时,两者所蕴含的信息量相差悬殊,不利于网络学习.而抽取关键词则将两者词汇量上的差距缩小,所蕴含的信息量的差距也同时缩小,这有利于神经网络学习到有意义的特征.
2) 由于用户的背景不同,所提出问题的背景信息有很大差别,这些背景信息会干扰模型判断问题相似.抽取关键词可以将干扰信息减少,帮助模型判断问题相似.
3) 理论上,CNN模型可以通过多轮学习自动过滤无用信息,但要达到上述目标需要大量的语料.而由于语料不足,神经网络模型无法很好地从过长的问题中抽取特征,将全文作为模型的输入很有可能造成过拟合,而将关键词作为模型的输入则减轻了这一问题.
实验也证明了问题主题相似度的特征可以辅助模型判断问题相似度.我们认为,用关键词序列代替全部文本作为神经网络的输入不可避免地会造成一些信息的流失,关键词提取本身也会造成级联错误.于是我们可以人为添加一些对判断问题相似度有帮助的特征辅助模型进行判断.而大量的研究表明问题主题可以帮助我们判断问题相似,因此我们选择了问题主题相似度作为辅助判断的依据.
我们用实验证明关键词提取模块中,使用TFIDF而非词频来判断词的重要程度是更优的选择.实验表明引入全局信息有助于表示词的重要程度.结果如表5所示:
Table5ComparisonoftheFeatureUsedinComputingtheGravitationalValueofWords

表5 词引力值使用特征对比实验
同时,我们的模型中多次计算向量间的相似度.因此我们设计了一组实验来证明在我们的模型中皮尔森相关系数要优于余弦相似度,皮尔森相似度可以更好地表示向量之间的相关程度.我们在语义匹配和矩阵分解以及主题相似度计算模块中分别尝试了余弦相似度以及皮尔森相关系数,实验结果如表6所示:

Table 6 Comparison of Cosine Similarity and Pearson’s Correlation Coefficient表6 余弦相似度与皮尔森相关系数对比实验
从表6可知,除了当主题相似度计算模块使用余弦相似度时,在CNN模型中使用皮尔森相关系数的结果略差于余弦相似度且差距不大外,其他任何情况中皮尔森相关系数均优于余弦相似度.因此可以认为在我们的模型中,皮尔森相关系数要优于余弦相似度.
最后,将我们提出的模型同SemEval2017的评测结果进行比较,实验结果如表7所示:

Table 7 The Experimental Results in SemEval2017表7 SemEval2017评测语料实验结果
表7中名称均为参加评测的队伍名称,我们选择了评测中排名前3的模型进行比较.KeLP[20]系统基于SVM(support vector machine),使用具有问题间关系链接的句法树内核以及一些文本间的相似性度量计算问题间相似度.Simbow[21]系统在余弦相似度中融入了关系度量,其使用多种关系度量计算余弦相似度,最后使用逻辑回归模型计算问题相似度.LearningToQuestion[22]系统用神经网络模型生成特征再使用SVM或逻辑回归模型计算问题相似度.从表7中我们可以看出,我们的模型要优于评测中最好的模型,更远远优于基于IR(information retrieval)的基础模型.但是,我们的模型仍有一些不足:1)由于关键词提取技术的准确度不够,我们无法保证是否有关键信息遗漏;2)以关键词序列作为神经网络的输入破坏了问题的结构,我们无法利用问题结构上的信息来判断问题相似性;3)我们使用用户提供的问题主题间的相似度作为辅助判断的依据,但用户提供的主题可能太过简略,无法帮助甚至会阻碍我们判断问题相似.
4 结论及展望
我们提出了一种基于关键词间相似及相异信息的CNN模型去计算社区问答中问题相似度.同时,我们将问题主题间的相似度特征融入到模型中,以辅助模型进行判断.我们在SemEval2017的评测语料上进行了实验,并超过了现有的结果.下一步我们将尝试更多不同的关键词抽取算法以及不同的神经网络模型.同时,我们还会尝试在模型中融入主题模型来替代问题主题相似度.
