基于深度学习的马铃薯畸形检测方法研究1
2018-07-13汪成龙黄余凤庄学敏
汪成龙,黄余凤,庄学敏,谢 珩
(惠州学院 电子信息与电气工程学院,广东 惠州 516007)
随着马铃薯商业价值的增加,马铃薯的品质检测成为必不可少的一部分.传统的马铃薯品质检测采用人工的方法,但其成本高昂,检测速度慢,已无法满足国内马铃薯工业生产的要求,因此亟需采用一种自动检测技术代替人工检测.
马铃薯外形多种多样,大小不一,发生病变畸形的形状也千差万别,导致传统的机械视觉所采用的检测算法识别正确率大幅下降,或由于情况过于复杂造成算法难以生成.若采用深度学习的方法对马铃薯进行形态特征进行学习,可以简单的得到符合要求的识别算法.深度学习是近年发展起来的多层神经网络学习算法,通过对多层网络结构的非线性特征的学习,完成对复杂多维空间的拟合[1].在图像识别方面,深度学习可分为无监督的特征学习和有监督的特征学习两种方法[2].无监督学习通常用于对象的特征提取,在收集所提取特征之后,再进行分类算法进行分类;有监督的特征学习是在拥有大量带有标记的样本时,通过不断地对分类器的参数进行调整优化,使分类器满足性能要求.基于深度学习的方法实现对图像特征进行提取制作的图像识别系统,可以完成甚至超过通过人眼进行识别的工作效果.
1 卷积神经网络的工作原理
卷积神经网络由卷积层、池化层、全连接层和其他层组成[3].其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类.
1.1 卷积层
卷积层的作用是从输入的图像中提取特征,卷积层由许多个卷积核(也称为滤波器)组成,通过卷积核与图像完成卷积操作,学习像素间的位置关系从而提取特征.现考虑一个25个像素的5×5的图片被一个3×3的卷积核所卷积.
用 xi,j表示图像的第 i行第 j列的像素;用 wm,n表示卷积核第m行第n列权重,用wb表示卷积核的偏置项;根据公式(1)和(2):
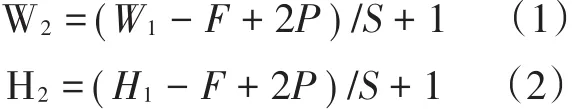
得卷积后得到一个3×3的特征图,其中W1和H1表示被卷积图片的宽度和高度,W2和H2表示卷积后输出特征图的宽度和高度,F表示卷积核的大小,P表示扩充的边缘大小,S表示卷积的步长.用ai,j表示特征图的第i行第j列元素;用f表示激活函数.然后,使用公式(3)计算卷积,可得到特征图
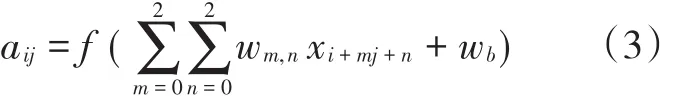
1.2 池化层
化层通常在卷积层之后,池化也被称为下采样.由于图像上相邻的像素之间具有一定的相关性,因此用其中一个像素的信息来代替与其相邻的一定范围内的像素信息,这种方法可以在完成对图像压缩的同时最大程度地保留图像原本的信息,减少网络中的参数数量,达到减少计算量的目的[4].最常见的池化操作有平均池化和最大池化.
平均池化:计算池化窗口选中的图像区域的像素值的平均值作为该区域池化后的值.
最大池化:计算池化窗口选中的图像区域的像素值中的最大值作为该区域池化后的值.
1.3 全连接层
全连接层在神经网络的末端,一般有两到三层全连接层.它将前面卷积层输出的三维的图像特征转化为一维的向量来对应图像的标签,即将学到的图像特征映射到图像标记空间,在神经网络中起到分类作用[5].全连接层可以通过卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1×1的卷积操作.由于全连接层参数冗余,后来推出的一些性能优异的网络如ResNet和GoogleNet等采用全局平均池化替代全连接层来分类学得的特征.
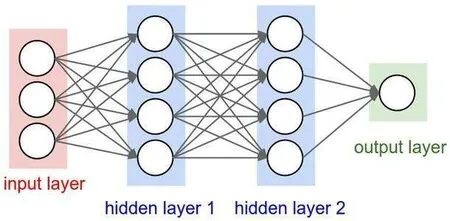
图1 全连接层
1.4 其他层
其他层包括激励层,损耗层,BN层,Dropout层
1.4.1激励层
在激励层中,使用激活函数对输入数据进行激活操作,从底层得到一个数据输入,运算后,从顶层输出一个数据.在运算过程中,没有改变数据维度的大小,即输入和输出的数据维度大小是相等的.激活函数为神经网络引入了非线性因素,由于神经网络的输入不一定是线性可分的,因此,引入非线性因素来解决线性模型所不能解决的问题.当前神经网络常用的激活函数有ReLU激活函数.
1.4.2损耗层
损耗层设置了一个损失函数用来比较网络的输出和目标值,通过最小化损失来驱动网络的训练.网络的损失通过前向操作计算,网络参数相对于损失函数的梯度则通过反向操作计算.
Softmax+损失函数(Softmax With Loss)一对多的分类任务计算多项逻辑斯蒂(Logistic)损失,并通过Softmax传递预测值,来获得各类概率的分布.公式如下:
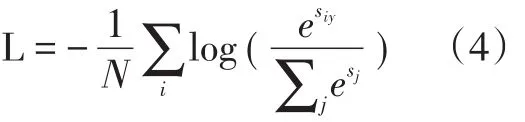
1.4.3BN层
BN即Batch Normalization,BN层的作用为批量正则化.在深度网络的训练过程中,网络前面引入的微小的误差会随着网络层次的增加而逐渐放大,使得后面的层的特征概率发生变化,影响训练的效果.因此,采用批量正则化来将每一层的概率分布变换为标准正态分布来规避参数摄动.批量的意思是批量的样本图片,正则化是将层的激活值的概率分布转化成均值为零,方差为一.
1.4.4Dropout层
Dropout层的作用是在网络训练的过程中,将输入本层的特征按照预先设定的概率进行舍弃.在深度和广度都很大的卷积神经网络的训练过程中,过拟合和训练时间长经常出现的问题,使用Dropout可以减少网络中传递的参数量,减少计算量,缩短训练时间.同时,Dropout消除了节点之间的相关性,减少了网络中的非必要特征,缓解了过拟合的现象.
2 基于caffe深度学习框架对马铃薯图像分类的研究
2.1 样本图片的处理
2.1.1采用留一法确定训练集和测试集
由于获取的马铃薯样本图片较少,只有153张,为了提高样本的利用率故采用留一法,将样本图片分成38张,38张,38张,39张四份小样本,每次训练网络模型时选取其中一份作为测试集,其余三份作为训练集进行训练,总共训练四次,并根据训练的效果确定的训练集为114张图片和测试集为39张图片.
2.1.2图像去均值化
图像去均值化是将用于训练的样本图片减去训练集图片的特征均值,把输入图片各个维度的数据都移到零点.
图2-1 畸形的马铃薯图片

图2-2 去均值处理畸形的马铃薯图片

图2-3 正常的马铃薯图片
图2-4 去均值处理畸形的马铃薯图片
2.2 CaffeNet的网络结构分析及特征提取
CaffeNet的输入为大小为64×64的图像,网络包含了5个卷积层,3个池化层,3个全连接层,第一个卷积层的卷积核大小为7×7,卷积步长为1,第二个卷积层的卷积核大小为5×5,卷积步长为1,其他的卷积层的卷积核大小都为3×3,步长为1;池化层均采用最大池化操作;3个全连接层的节点数量分别为4096,4096,2.
CaffeNet的特点是使用了3种不同大小的卷积核,这种结构在网络训练时可以兼顾不同大小的局部区域特征,提高了网络的精确性[6].

图3 CaffeNet网络结构

表1 CaffeNet的测试结果
使用CaffeNet提取的特征图:

图4-1 正常马铃薯图片的特征图

图4-2 畸形马铃薯图片的特征图
2.3 ResNet的网络结构分析及特征提取
随着人们对神经网络研究的深入,新构建网络模型层次也不断增加,网络深度的增加,带来了准确度的增加.但是增加网络深度后,网络前面的层梯度很小,导致这些层基本停止更新参数,这就是梯度消失问题[7].同时更深的网络意味着参数空间更大,网络优化难度加大,因此单纯地增加网络深度反而出现更高的训练误差,深层网络虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差.
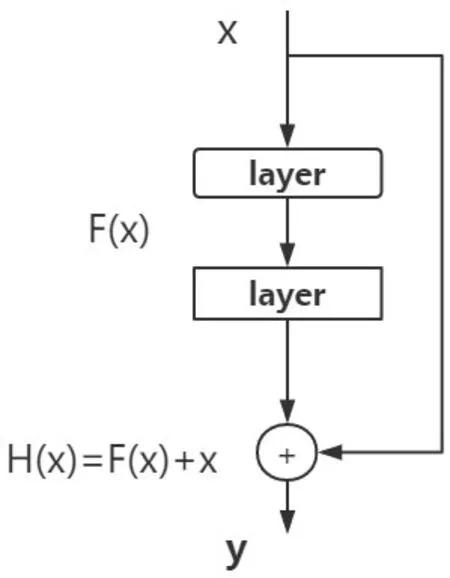
图5 残差模块示意图
为解决以上的问题,设计了一种残差模块能训练更深的网络.从图5可知,数据经过了两条路线,一条是常规路线,另一条则是“捷径”,是直接实现单位映射的直接连接路线.若把网络中的一个模块的输入和输出关系看作是y=H(X),直接通过梯度方法求H(X)会出现上文提到的退化问题,若使用这种带“捷径”的结构,可变参数部分的优化目标不再是H(X),若用F(X)来代表需要优化的部分,H( X ) =F( X ) +X,即F( X ) =H(X ) -X.因为在单位映射的假设中y=X即相当于观测值,因此F(X)对应着残差,因而ResNet又被称为残差网络.学习残差F(X)比直接学习H(X)简单,现只需要去学习输入和输出的差值,绝对量变为相对量H( X ) -X即是输出相对于输入变化量,优化难度大幅度降低.

表2 ResNet的测试结果
使用ResNet提取的特征图:

图6-1 正常马铃薯图片的特征图

图6-2 畸形马铃薯图片的特征图
2.4 DenseNet的网络结构分析及特征提取
针对随着网络深度的加深,而出现梯度消失的问题,上述的ResNet和许多其他类型的网络给出相应的解决方案,虽这些网络模型的结构并非完全一致,但其解决方案的核心都是在网络中的层与层之间创建“捷径”,而DenseNet的解决方案是从特征入手,通过达到对特征的极致利用来实现更好的效果[8].
DenseNet是一种具有密集连接的卷积神经网络.在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入.图7为DenseNet的基本结构示意图,BN层接ReLU层接卷积核为(1×1)的卷积层接BN层接ReLU接卷积核为(3×3)的卷积层,多个基本结构组成了一个完整DenseNet.每个基本结构的之间层称为transition layers,由BN层接卷积核为(1×1)的卷积层接平均池化层组成.
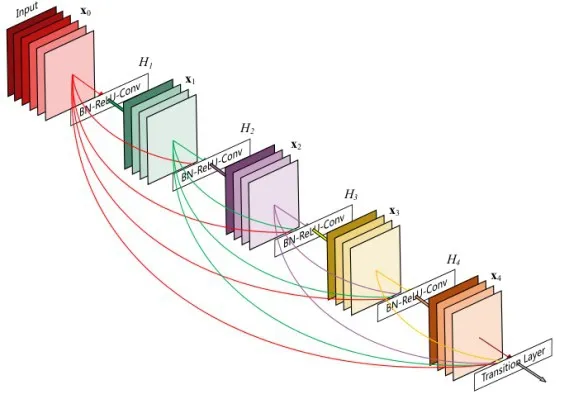
图7 DenseNet网络的基本结构
当网络层次很深时,相比于其他网络模型DneseNet的参数量大幅减少了.与ResNet的“捷径”思路相似,DenseNet的这种结构相当于每一层都直接连接输入,因此可以减轻梯度消失现象.

表3 DenseNet的测试结果
使用DenseNet提取的特征图:

图8-1 正常马铃薯图片的特征图

图8-2 畸形马铃薯图片的特征图
3 基于图形用户界面的马铃薯图片识别应用设计
使用caffe软件的指令实现已经训练好的网络模型对马铃薯图片进行识别,这种方法虽然在网络模型训练调试阶段能够直接对网络的调用以及修改,但是在实际生产应用中,这种方式显然是不够人性化,不够高效化的[10].因此,使用图形用户界面开发程序来为检测程序制作界面.
首先,编译caffe的matlab接口,在caffe的文件夹中找出CommonSettings.props文件,后将文件编译matlab接口的语句改为ture,并添加matlab的文件路径,接着使用Visual Studio生成解决方案,若在caffe的文件夹中出现了matcaffe文件夹即编译成功.有了matlab接口后,使用matlab对网络模型进行训练、测试、图像识别以及各种可视化操作,同时matlab自带的图形用户界面可以用来开发检测程序的界面.
程序流程图;开发图形用户界面如下:
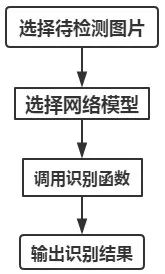
图9 应用程序流程图

图10 应用开发截图
应用程序运行效果:
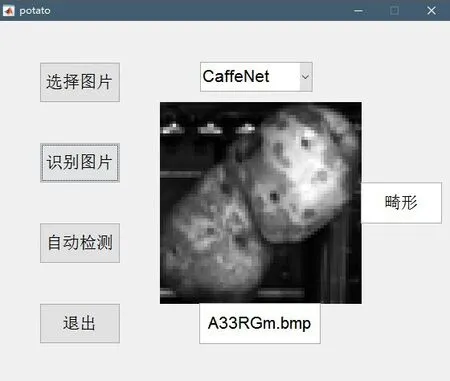
图11-1 应用效果图(畸形)
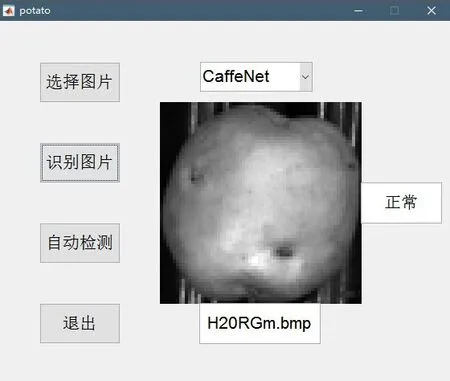
图11-2 应用效果图(正常)
4 结论
本文的主要内容为研究利用神经网络对马铃薯图片进行检测分类的方法,介绍了卷积神经网络的基本工作原理,采用留一法确定样本图片的训练集和测试集的分配,确定的训练集为114张图片和测试集为39张图片,并对图像进行了去均值化的处理.同时研究了CaffeNet、ResNet和DenseNet三种神经网络模型的结构特点,以及三种网络模型对测试集的马铃薯图片的分类效果,最终得到如下结果:
1)迭代次数分别为 400、800、1200、1600、2000、2400的CaffeNet模型对马铃薯图片测试集的识别准确率分别为89.7%、92.3%、92.3%、97.4%、100%、100%;
2)迭代次数分别为 400、800、1200、1600、2000、2400的ResNet模型对马铃薯图片测试集的识别准确率分别为89.7%、92.3%、97.4%、100%、100%、100%;
3)迭代次数分别为 400、800、1200、1600、2000、2400的DenseNet模型对马铃薯图片测试集的识别准确率分别为92.3%、94.9%、94.9%、97.4%、100%、100%.
