基于连续噪声谱估计的谱减法语音增强算法*
2018-07-09严思伟屈晓旭娄景艺
严思伟,屈晓旭,娄景艺
(海军工程大学 电子工程学院,湖北 武汉 430033)
0 引 言
语音是人类交流信息最自然、最有效、最方便的手段。伴随着通信技术的发展,语音通信已经成为人们日常工作和生活中不可或缺的一部分。然而,语音通信过程中不可避免地会受到来自环境、设备内部等一系列的噪声。这些噪声的存在会影响语音处理系统的性能,最终影响接收者接收信号的质量。为了从被污染的语音信号中提取尽可能纯净的话音信号,语音增强技术应运而生。目前,语音增强的主要方法有基于短时谱估计的语音增强法[1-2]、基于听觉掩蔽的语音增强法[3]、噪声对消法[4]和小波变换法[5]等。在基于短时谱估计法中,Boll等人提出的语音功率谱减法以其算法的简单、高效一直被沿用至今。但是,该算法由于其平稳性假设,同实际含噪声情况不相符,在实际应用中存在较大的音乐噪声。Berouti等人[6]提出了功率谱过减法,有效平衡了噪声残留。张悦等人[7]对文献[6]中的算法进行了改进,运用人耳的听觉特性即听觉掩蔽效应[8],适当加入宽带噪声来掩盖音乐噪声。该算法虽然在一定程度上能够降低音乐噪声的影响,但是在信噪比较低的情况下,降噪效果不明显,还有可能导致语音的恶化。语音的端点检测(VAD)用来确定语音信号的起点和结束点。有效的端点检测可以最短化处理时间,并提高语音质量[9]。通常的VAD采用短时过零率进行,文献[10]对该方法进行了说明,但是在低信噪比下该方法准确率不足。
短波信道噪声谱是时变的,所以必须进行连续噪声谱估计。本文在传统谱减法的基础上结合连续噪声谱估计算法和维纳滤波器提出了一种新的谱减语音增强算法,在此基础上通过维纳滤波器对处理后信号进行连续的频域平滑处理。通过仿真,比较了短时过零率端点检测和改进的端点检测算法,以及传统谱减法和改进后的谱减法,证明改进的算法效果更好。
1 传统的谱减法
传统的谱减法以其简单、高效的特性一直沿用至今。在噪声信号和语音信号互不相关以及在频域内是加性关系的假设前提下,通过从带噪语音的功率谱中减去对噪声功率谱的估计,从而得到纯音信号的功率谱;基于人耳对语音信号的短时相位不敏感的感觉特性,可以通过纯音信号的功率谱和原带噪语音信号的相位谱来恢复纯净的语音信号。流程图如图1所示。
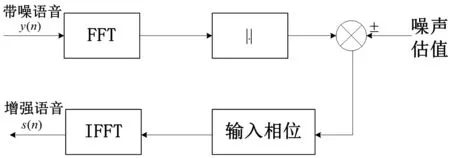
图1 谱减法实现流程
假设语音是平稳信号,则带噪语音信号可以表示为:

其中, y ( n)、 s( n)和d(n)分别为带噪语音、纯净语音和噪声信号,经过分帧、加窗处理后,等式两边同时做FFT变换,则原式时域和频域分别表示为:
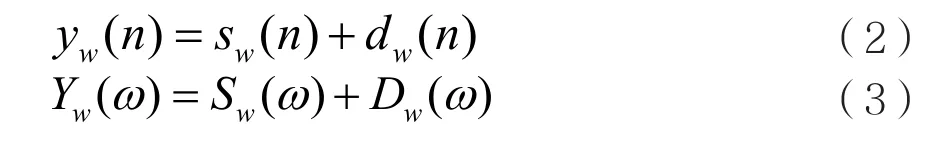
其中,表示加窗处理, Yw( ω )、 Sw(ω)和Dw(ω)分别为 y ( n)、 s( n)和d(n)的FFT。考虑到人耳对相位的不敏感,忽略语音和噪声相位的区别。又由于语音和噪声的互不相关,则原带噪信号的幅度谱和功率谱可表示为:
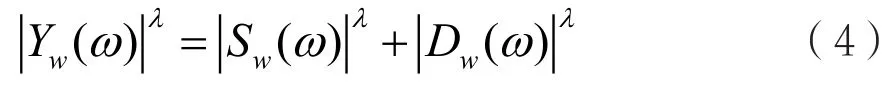
其中,λ为谱指数。当λ=1时,表示为幅度谱,λ=2时,表示为功率谱。在估计出噪声谱的情况下,可以直接通过从原带噪信号谱中减去噪声估计谱来得到纯音信号谱,且将原带噪信号的相位作为纯音信号的相位,从而达到语音增强的效果。具体表达式为:
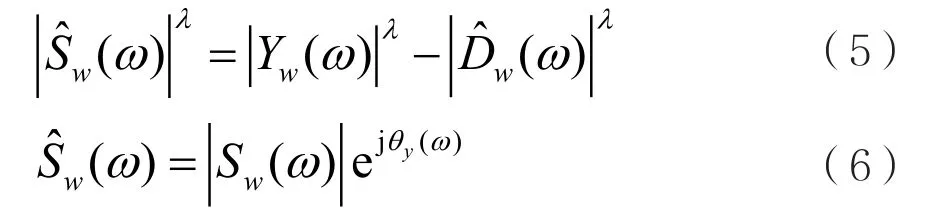
其中,表示语音的估计,)(ωθy表示带噪语音信号的相位。对进行IFFT后,可以得到增强后的语音信号。
2 改进的谱减法
针对传统谱减法存在的问题,本文提出了一种结合连续噪声谱估计和维纳滤波器的改进的谱减法,具体流程如图2所示。
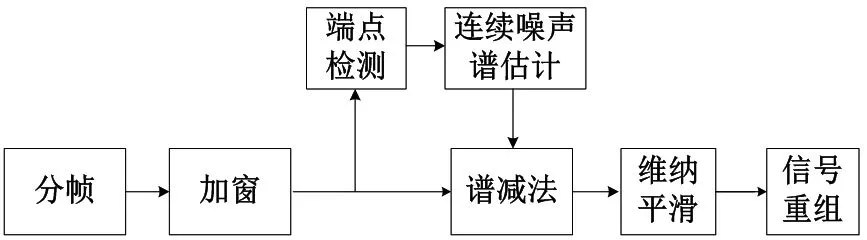
图2 改进谱减法流程
2.1 端点检测与连续噪声谱估计
传统谱减法的噪声能量通常以无语音期间噪声能量的统计平均进行估计。然而,由于短波信道的噪声谱是时变的,噪声频谱为高斯分布,仅仅通过采用“寂静段”噪声的统计平均来估计噪声谱。这样在某些噪声分量大的频率点会保留很大一部分噪声,使语音增强的效果不明显甚至恶化。改进算法通过端点检测来识别噪声段,并对噪声谱进行不间断的更新来进行噪声估计。传统的谱减法端点检测通常采用平均过零率来进行检测,即语音信号时域波形穿过时间轴的次数。这种算法在信噪比较高的情况下适用,然而在信噪比较低的情况下会失效。倘若在低信噪比的条件下,端点检测的失效会导致语音帧被判定为噪声帧进行处理,从而产生语音回声。
针对上述问题,提出了一种基于连续噪声谱估计的端点检测和噪声估计算法。它是在背景噪声相对于语音信号是近似稳态的基础上,运用能量平均法快速更新噪声能量谱以及进行端点检测。
首先,对原语音信号进行预处理,即分帧、加窗及FFT处理后,取ε帧信号的总能量的平均值作为初始噪声能量,此时的噪声估计值为:
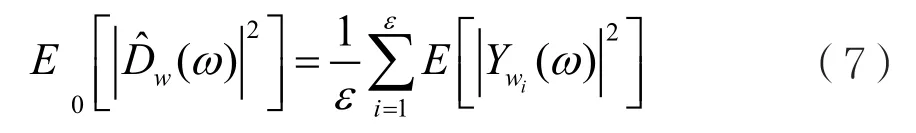
其中,是当前噪声能估计值,并将其设置为前ε帧的能量;是前ε帧各帧能量估计值。从后一帧开始,设定一个端点门限值。倘若该帧能量高过端点门限值,即判定这一帧为语音帧;否则,判定该帧为噪声帧。考虑到如果将语音帧当做噪声帧处理,会导致产生语音回声,因此语音帧的门限值需要设置较低,即所有可能的语音帧统一判定为语音帧。具体判定该帧为噪声的条件可以表示为:
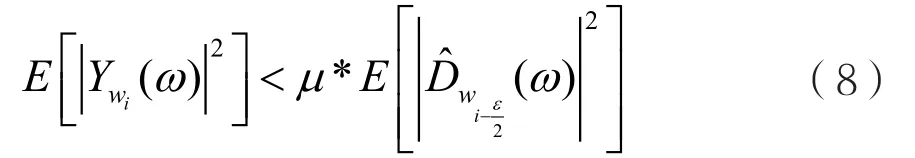
其中,µ为端点门限值。
此时,考虑到噪声是近似稳态的,或者说是一种慢变的过程,可以采用滤波法进行噪声估计[11]。噪声功率谱估计值可以表示为:
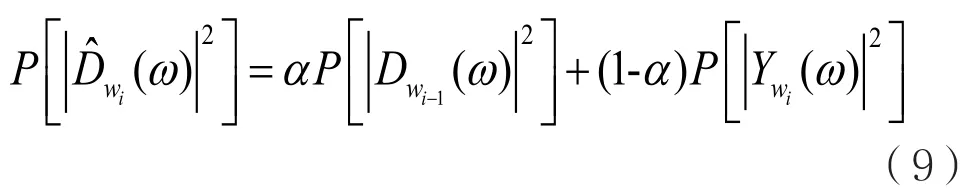
其中,α为滤波系数,典型的取值为0.8~0.95,本文选取α值为0.8。相反,如果该帧能量大于端点门限值,即:
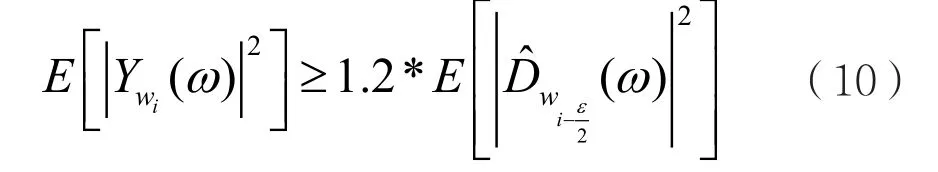
则判定该帧为语音帧。此时,为了端点检测和噪声估计的准确性,置该帧相邻前后帧为语音帧,并置这ε帧噪声能量为第帧能量。经过反复的运算,直到找出所有的语音帧和各帧噪声估计值。基于连续谱估计的端点检测和噪声估计算法的实现流程,如图3所示。
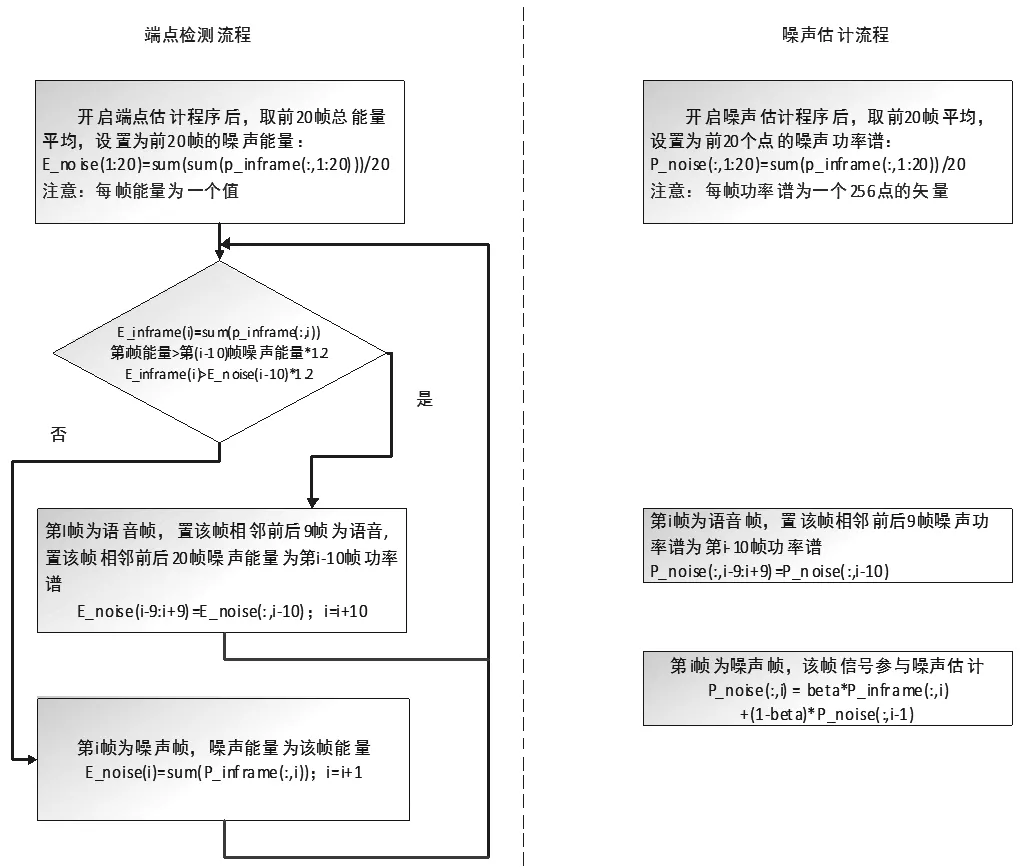
图3 端点检测和连续噪声谱估计
通过传统功率谱减法后的语音信号,在频率域中还存在残留噪声。为了消除或者削弱这些噪声,可以多减去一些噪声值,降低噪声的影响,这种方法叫功率谱过减法。具体的实现过程可以表示为:
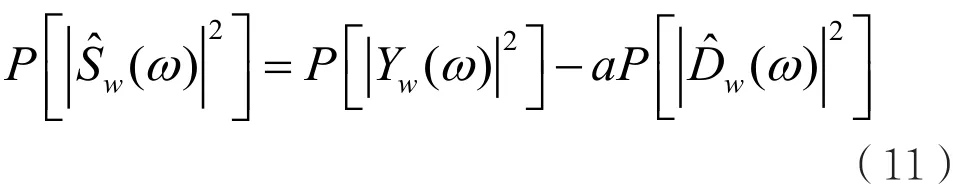
式中,a为降噪系数。当a=1时,为传统功率谱减法;信噪比大时,a可设置得大一些,此时为功率谱过减法。这里还存在一个问题,即如果噪声估计值过大,可能会有负谱的出现。为了防止负谱的出现,这里采用半波整流法,即当时,将其结果置为0。
为了确定降噪系数a,这里每10s进行一次信噪比(SNR)估计。若取a=3;若取a=2;否则,取a=1。
2.2 维纳滤波平滑
在信号频域处理的过程中,由于相邻频率点进行的处理可能并不相同,导致了相邻连续频率点之间的不连续性,从而影响增强语音的质量。因此,有必要在谱减法之后对增强信号进行频域的平滑处理。仿真实验证明,维纳滤波平滑有效。所以,这里采用维纳滤波进行平滑处理。
这里定义一个传递函数Gk,表达式为:
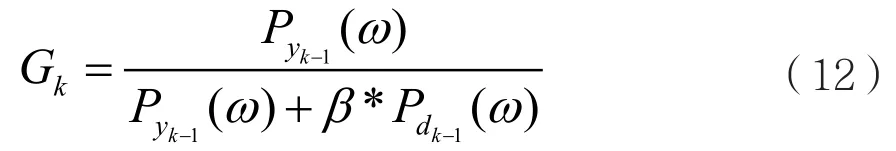
其中,kG 表示第k帧维纳滤波传递函数,表示第 k − 1 帧输入信号的功率谱,表示第 1k− 帧的噪声功率谱,那么第k帧输出增强信号功率谱可以表示为:
其中,表示通过维纳滤波平滑之前的输出增强信号。
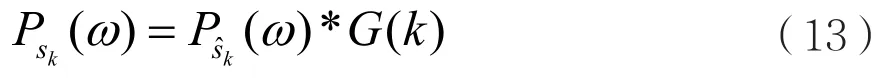
3 仿真结果
在MATLAB7.0的操作系统下对语音信号进行仿真。输入语言采用NOIZEUS语料库中的语音,采样率为8 kHz。用汉明窗对带噪语音进行分帧加窗处理,帧长256 ms,帧间叠接128 ms,选取ε为20帧,端点门限µ为1.2,滤波系数α为0.8。首先,在纯音信号中添加高斯白噪声生成不同信噪比(-10 dB、0 dB、10 dB和20 dB)的语音文件,然后运用短时过零率、短时能量分别对语音进行端点检测。图4为端点检测算法仿真,4张图片分别对应信噪比为-10 dB、0 dB、10 dB和20 dB时能量和过零率的情况对比。
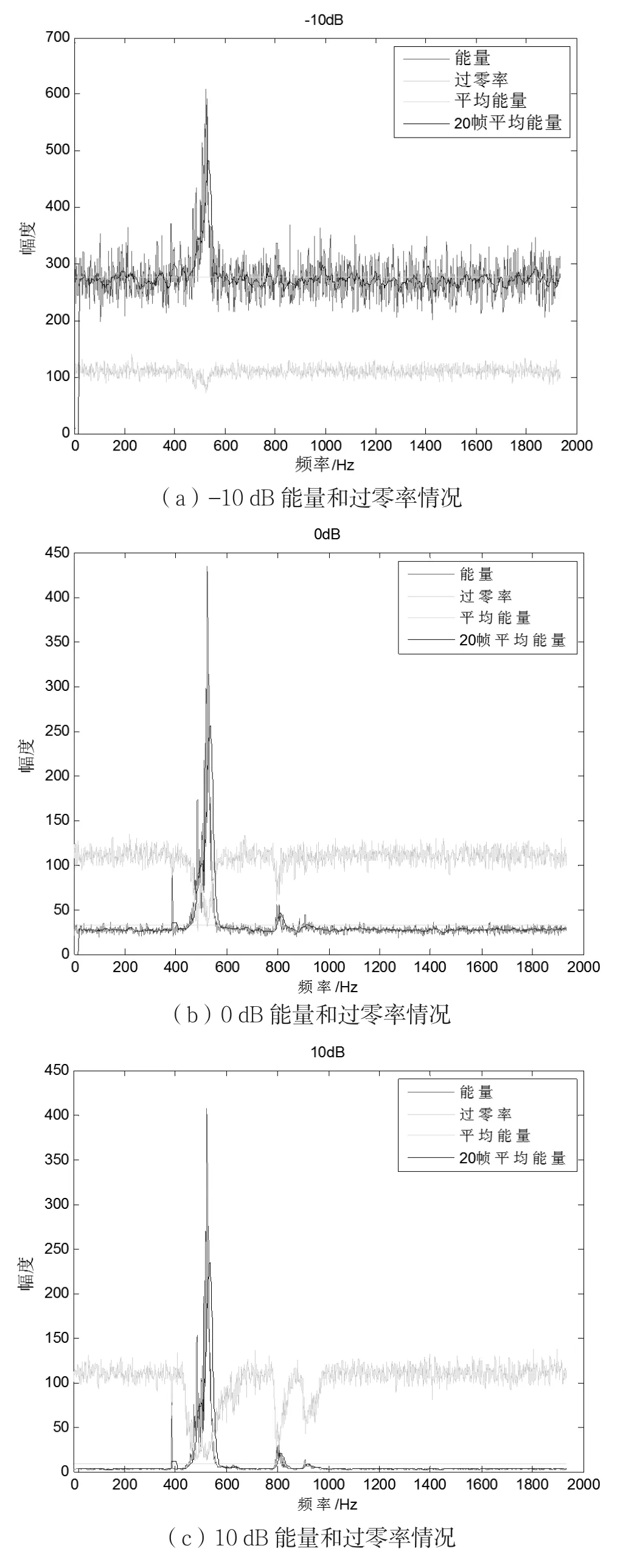
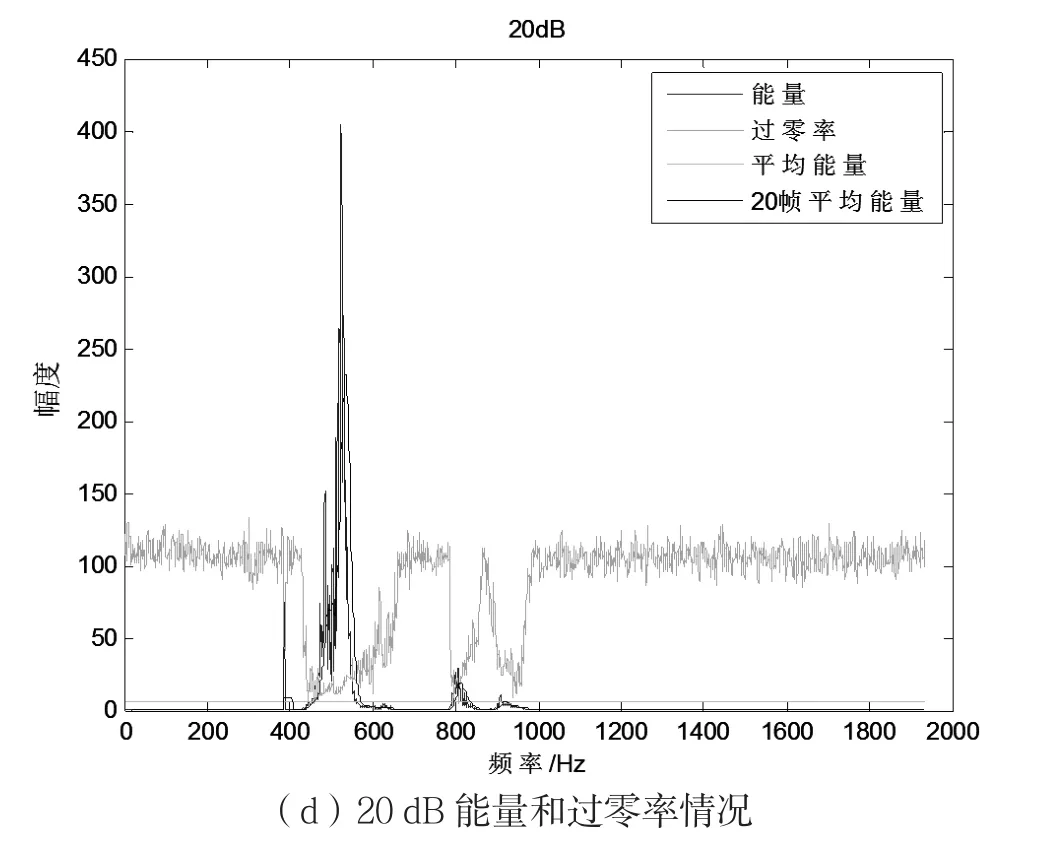
图4 不同信噪比下能量和过零率情况
由仿真结果可知,在信噪比较高时,过零率检测能够粗略检测出端点位置,但在低信噪比时失效;而能量检测在低信噪比和高信噪比下均有效,在低信噪比时因噪声占主导,端点检测错误而得到的噪声估计仍然有效。
在此基础上,用MATLAB对改进谱减算法进行仿真实现,并将增强后的语音信号同原信号进行时域和频域的对比,观察两者之间时域和频域的波形,可以直观反映出语音增强的效果,如图5所示。
图5(a)是增强信号和带噪语音信号的时域对比。显而易见,增强信号幅度上没有改变,而背景噪声得到了有效消除,音乐噪声得到了良好抑制。图5(b)是两者的功率谱对比。可以看到,语音增强信号和带噪语音功率谱相比,没有发生变化,说明增强信号很好地保留了语音信号的特征和质量。
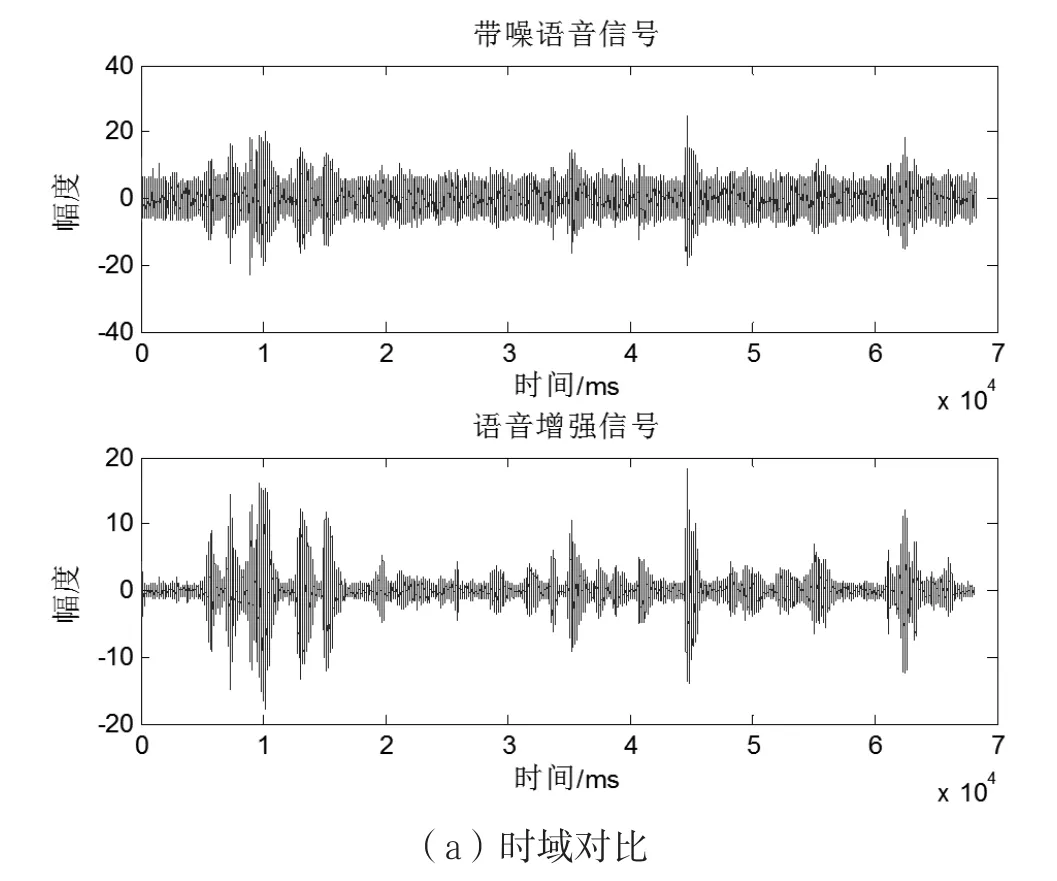
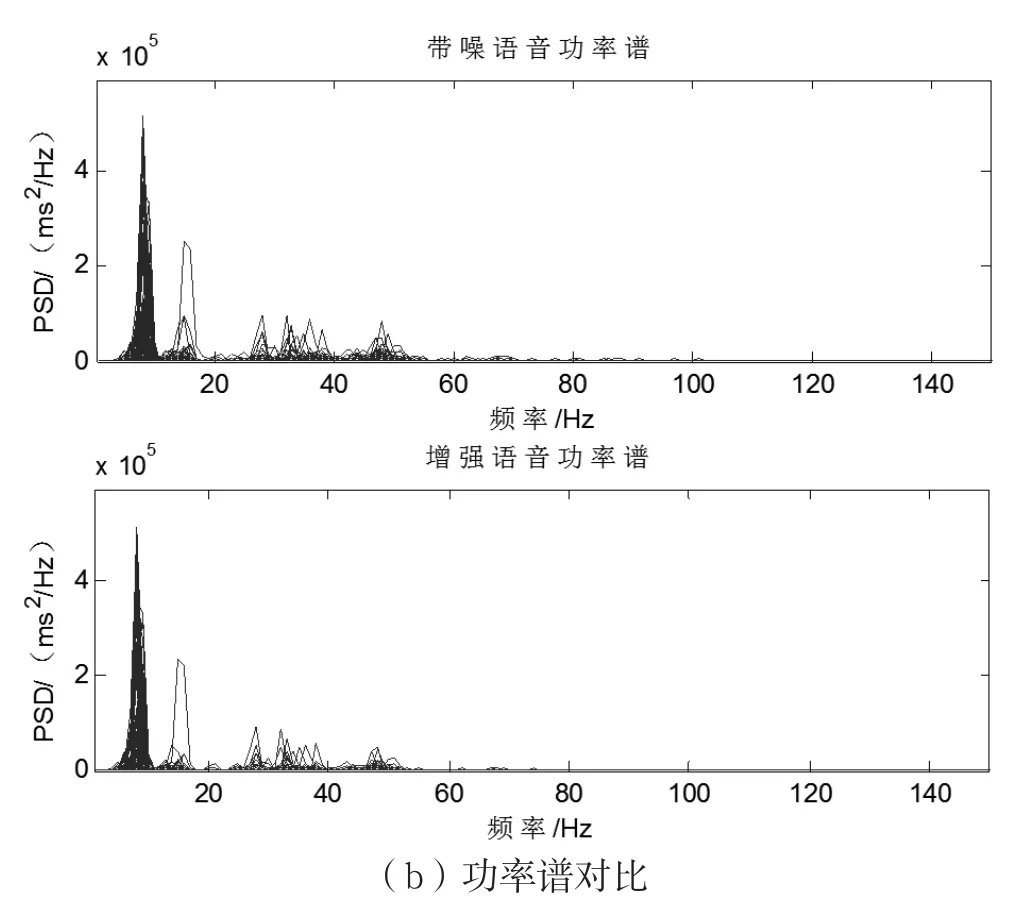
图5 语音信号对比
4 结 语
传统的谱减法虽然能够从带噪语音信号中提取比较纯净的语音信号,但是会产生明显的“音乐噪声”。它要比原始语音中的噪声清楚得多,也更加令人反感。本文针对短波信道中噪声谱的时变问题,提出了改进的连续谱估计谱减法。进行反复连续的端点检测和噪声估计,通过选取合适的降噪系数,不但能够消除背景噪声,提高语音信号的信噪比,而且能有效抑制“音乐噪声”,得到更好的语音可懂度和清晰度。
[1] Chen J,Benesty J,Huang Y,et al.New Insights into the Noise Reduction Wiener Filter[J].IEEE Transactions on Audio,Sjzeech,and Language Processi ng,2006,14(04):1218-1234.
[2] Boll S.Suppression of Acoustic Noise in Speech Using Spectral Subtraction[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1979,27(02):113-120.
[3] 蔡军,李飞,张毅.基于听觉掩蔽效应的语音增强算法[J].计算机工程,2017,43(07):288-292.CAI Jun,LI Fei,ZHANG Yi.A Speech Enhancement Algorithm Based on Auditory Masking Effect[J].Computer Engineering,2017,43(07):288-292.
[4] 蒙淑艳.自适应回声抵消和噪声消除算法的研究[D].长春:吉林大学,2004.MENG Shu-yan.Research on Adaptive Echo Cancellation and Noise Cancellation Algorithm[D].Changchun:Jilin University,2004.
[5] 李如玮,鲍长春,窦慧晶.基于小波变换的语音增强算法综述[J].数据采集与处理,2009,24(03):362-368.LI Ru-wei,BAO Chang-chun,DOU Hui-jing.An Overview of Speech Enhancement Algorithm Based on Wavelet Transform[J].Journal of Data Acquisition and Processing,2009,24(03):362-368.
[6] BEROUTI M,SCHWARTZ R,MAKHOUL J.Enhancement of Speech Corrupted by Acoustic Noise[C].IEEE International Conference on Acoustics,Specch,and Signal Processing,1979:208-211.
[7] 张悦.基于过量功率谱减的语音增强算法研究[J].兰州文理学院学报(自然科学版),2017(05):89-92.ZHANG Yue.Research on Speech Enhancement Algorithm Based on Excessive Power Spectrum Reduction[J].Journal of Lanzhou University of Arts and Science(Natural Science Edition),2017(05):89-92.
[8] Ogata S,Shimamura T.Reinforced Spectral Subtraction Method to Enhance Speech Signal[J].Proceedings of IEEE Region 10 International Conference on Electrical and Electronic Technology IEEE,2001:242-245.
[9] 张雪英.数字语音处理及MATLAB仿真[M].北京:电子工业出版社,2010.ZHANG Xue-ying.Digital Speech Processing and MATLAB Simulation[M].Beijing:Publishing House of Electronics Industry,2010.
[10] 沈宏余,李英.语音端点检测方法的研究[J].科学技术与工程,2008,8(15):4396-4397.SHEN Hong-yu,LI Ying.Research on Speech Endpoint Detection Method[J].Science Technology and Engineeri ng,2008,8(15):4396-4397.
[11] 徐岩.语音信号增强技术及其应用[M].北京:科学出版社,2014.XU Yan.Speech Signal Enhancement and Its Applications[M].Beijing:Science Press,2014.
