基于双向预测的变采样率分块压缩视频感知
2018-07-06,
,
(浙江工业大学 信息工程学院,浙江 杭州 310023)
传统的信号采集过程遵循香农经典采样定理,即为了准确完整地恢复原始信号,采样频率必须大于等于奈奎斯特频率(即原始信号的带宽)的两倍.对于高清的数字图像和多媒体视频数据来说,这种先采样后压缩的信号处理方式会造成资源的极大浪费;同时,由于这种采样方式只利用了信号是有限带宽的假设信息,而没有利用其他任何先验知识,会造成采集到的数据信号存在极大程度的冗余现象[1].2004年,Candes等[2]等科学家提出了压缩感知(Compressive sensing,CS)理论,该理论摒弃了香农定理先采样后压缩的方式,将信号采集与信号压缩合二为一,同时利用了信号稀疏性等先验信息,有效地避免了冗余现象的发生和频谱资源的浪费[3-5].因此,压缩感知技术在很多领域得到了发展和应用,如人脸识别技术[6]、无线传感器网络数据压缩[7]等.
近年来,压缩感知理论在视频信号编码[8]中得到了广泛的应用,出现了一系列压缩视频感知(Compressive video sensing,CVS)方案.2006年,Rice大学提出了基于CS理论的单像素照相机[9],利用CS采样方法对单帧静态图像进行采样,但是高分辨率的图像像素较高,原始信号维数过大,造成测量矩阵需要较大的存储空间以及重构过程复杂度较高.之后,Gan[10]提出了一种块采样方式,将视频帧图像分块并用固定采样率对所有块进行采样,解决了整帧像素过高的问题,大程度地提升了采样重构的速度和质量.虽然这种块采样方式有效地提高了采样性能,但是它忽视了视频数据独有的特点,即具有很强的帧间相关性.基于此,一些学者提出了自适应采样方式,如:Warnell等[11]利用了人在视觉上对前景图像与背景图像的关注度不同的特点,自适应地为其分配采样率,但是这种分配方案重构出来的背景图像质量很低,在应用中没有实际意义;Soni等[12]利用CS树对稀疏信号进行自适应的变采样率采集和测量,处理上存在较高的复杂度;Narayanan等[13]提出了基于分布式压缩视频感知(DCVS)方案,这种方法只对某些特定帧进行分割并且将运动预测从编码端转移到了解码端,造成了其解码端的复杂度较高,降低了解码速度;练秋生等[14]提出了基于帧间相关性自适应地分配采样率的方案,但是这种压缩视频方案忽略了当前帧与其前后帧均存在较强的帧间相关性,采集的数据存在一定的冗余度.基于文献[14],笔者提出了一种基于双向预测的块图像自适应采样方案.该方案在分配采样率之前,将当前图像进行双向预测,为其分配合理的采样率.实验结果表明:这种双向预测的自适应采样方案可以在相同甚至更低采样率的条件下,获得的重构视频图像质量更高.
1 现有的自适应采样率分块CVS算法

(1)

Yt-1=ΦXt-1
(2)
式中:Yt-1∈RM×K;Xt-1∈RN×K.
根据非参考帧与参考帧之间的时域相关性程度,将非参考帧的图像块分成3 类:近似不变块、缓慢变化块及快速变化块.首先将非参考帧与参考帧进行相同的不重叠分块处理,测量2 帧之间对应图像块的残差能量与参考块能量的比值,以此作为分类的判决标准,即
(3)
设定2 个阈值T1,T2(T1
(4)
式中:n2为非参考帧总的像素数;K1,K2,K3分别为第1,2,3类图像块的个数;K为非参考帧分块的总个数,满足K=K1+K2+K3.
在数据接收端,对参考帧使用单帧压缩感知的快速重构算法进行独立重构.对于非参考帧,首先对其进行预处理,然后参考之前重构的参考帧,进行多假设预测得到预测帧,再对其进行变采样率的残差重构处理,重构出非参考帧.
以上方案采用了当前非参考帧与前一参考帧之间的相关性[15],进行自适应采样.这种方法虽然在性能上有所提升,但是它忽略了非参考帧和后一帧存在的相关性,造成采集到的数据存在一定的冗余.为了解决这个问题,笔者提出了一种基于双向预测的自适应采样率分块压缩视频感知方案.
2 基于双向预测的变采样率分块CVS方案
2.1 视频序列的自适应采样测量

(5)

图1 基于双向预测的变采样率分块压缩视频感知框图Fig.1 Block diagram of block compressive video sensing based on bidirectional prediction and variable sampling rates
用这个比值e作为判别B帧中图像块类别的准则,判决过程如图2所示.
根据这个判定结果,可以对B帧进行变采样率测量,最后得到1 个测量向量,而B帧的实际采样率计算与式(4)相同.
2.2 基于自适应采样测量值的视频重构
2.2.1 参考帧的重构
由于参考帧使用固定高采样率测量,可以直接单独重构出高质量的视频帧,使用K-SVD字典和正交匹配追踪(OMP)算法重构视频图像.K-SVD字典使得视频信号可以表示为1 个正交基和稀疏系数相乘,其计算式为
(6)


(7)
这是1 个NP难问题,通过OMP追踪算法找到视频信号的最佳稀疏矩阵,然后按列更新字典,通过SVD(奇异值分解)循序地更新每一列和该列对应的稀疏矩阵的值,由此重构参考帧的视频信号.
2.2.2 非参考帧的重构
对于非参考帧(P帧和B帧)的重构,首先要在接收端对收到的非参考帧的各个图像块作判断,如果是近似不变块的话,需要先进行预处理.近似不变块的采集点数是M1,用参考帧测量值中的后面M-M1个值将近似不变块的测量向量补全到M.然后对参考帧作多假设预测,对于P帧来说,它的图像块预测的最佳线性组合仅来自于重构的参考帧中相应位置的搜索窗口内,通过计算得到预测帧,然后通过残差重构得到重构的P帧.对于B帧来说,使用双向运动估计来获得预测帧,也就是说它在重构的参考帧和P帧这两帧内的对应搜索窗里得到图像块的最佳预测线性组合,这种组合方式可以减少预测误差,最后通过残差重构获得高质量的B帧.
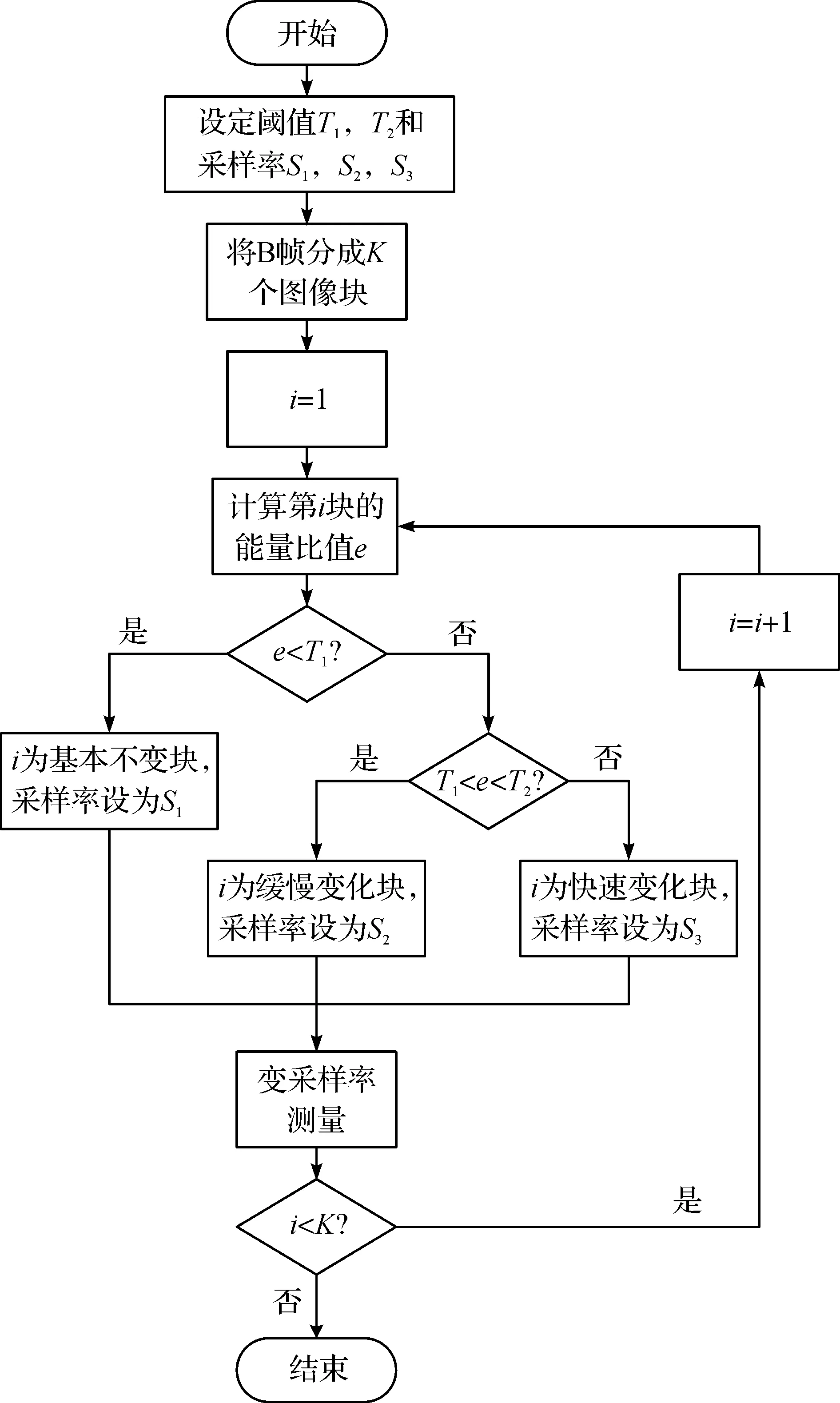
图2 B帧的块类别判定和自适应采样过程Fig.2 Block type decision and adaptive sampling process for B-frame
3 实验仿真结果
为了验证笔者算法的性能,选用了Akiyo,Foreman,Suzie,Coastguard等4 组CIF格式的标准视频序列,这些视频序列可以在视频库网站http://trace.eas.asu.edu/yuv/index.html中下载.实验中,选取视频序列的前3 帧作为测试帧,在文献[14]提出的算法VS-MH中,第1 帧作为参考帧,第2,3 帧均为非参考帧;在笔者提出的算法(以下简称为BP-VS-MH)中,第1 帧作为参考帧,第2,3 帧分别为B帧和P帧;另外,引入了原始的多假设帧预测算法(MHFP)[16]作为参考比较.实验中设定视频帧的块大小为16×16,搜索窗尺寸设为±7 个像素大小.文献[14]通过多次实验找到了1 组高通用性的参数,在较低采样率的情况下保证了重构出较高质量的视频帧,沿用了这组参数,设定块分类判定的阈值为T1=0.003,T2=0.15,3 种块类别的采样率分别为S1=5%,S2=20%,S3=50%,参考帧的固定高采样率设定为50%.
为了提高实验结果的准确度和可信度,采用峰值信噪比(PSNR)和结构相似性(SSIM)的值作为图像重构质量的衡量标准.通过实验测试,得到了Akiyo,Foreman,Suzie,Coastguard这4 组视频序列中第2 帧的采样率和峰值信噪比值和结构相似性值.表1给出了MHFP,VS-MH,BP-VS-MH这3 种算法对视频序列不同的采样率以及重构质量的比较.结果表明:在其他条件均相同的情况下,与其他2 种算法相比,BP-VS-MH能在相同甚至更低采样率的条件下,保证更高的重构质量.对于运动变化较小的Akiyo序列来说,BP-VS-MH比VS-MH算法的重构质量高出1.53 dB,0.02;对于运动变化较小的Foreman序列来说,BP-VS-MH比VS-MH算法的重构质量高出1.70 dB,0.03.对于变化程度较大的Flower序列来说,重构质量高出2.17 dB,0.05;对于变化程度较大的Coastguard序列来说,重构质量高出2.55 dB,0.06.说明BP-VS-MH算法对提高运动变化程度较大的视频序列重构质量的效果更为显著.图3,4分别为Akiyo,Foreman 2 组视频序列的重构效果图,从图3,4中可以直观地看出BP-VS-MH算法对于运动变化程度较大的主要运动区域的重构质量较高,比如图3中的面部表情区域和图4中的嘴唇周围部分,说明BP-VS-MH算法可以有效抑制块效应,提升图像的重构质量.

表1 视频序列第2 帧重构质量比较Table 1 Comparison of the second frame reconstruction quality of video sequences

图3 Akiyo视频序列第2 帧重构结果图Fig.3 The second frame reconstruction results of Akiyo video sequences

图4 Foreman视频序列第2 帧局部重构结果图Fig.4 The local second frame reconstruction results of Foreman video sequences
为了说明表1中3 种算法的复杂度,笔者在相同的实验环境和电脑配置下,计算了这3 种算法处理Akiyo,Foreman,Suzie,Coastguard等4 个视频序列的平均运行时间,MHFP算法为8.23 s,VS-MH算法花费了20.05 s,BP-VS-MH算法使用了21.96 s.VS-MH之所以相比较于MHFP算法来说,运行时间较长,复杂度较高,是因为两者的重构算法不同,残差重构算法的过程是迭代优化求解,相对于对图像整体进行小波变换速度慢,相对地,其重构质量高.而BP-VS-MH算法的处理时间比VS-MH多了1.91 s,说明双向预测的变采样率处理比前向预测的复杂度略高,但是相差范围不是很大.
4 结 论
提出了一种基于双向预测的自适应采样率分块压缩视频感知方案,充分利用了当前帧与前后帧的相关性,减小了采集信号的冗余程度.与前向预测帧相比,双向预测帧可参考更多的图像,找到更接近自身的预测数值,因此可以减少采样率,提高压缩率;同时,双向预测帧这种参考前后2 帧画面的特性,相当于有内插的效果,可以减少噪讯,提高重构质量.实验结果表明:笔者算法能在降低采样率的同时提高图像的重构质量,证实了方案的合理性和有效性.
参考文献:
[1] 戴琼海,长军,季向阳.压缩感知研究[J].计算机学报,2011(3):3425-3434.
[2] CANDES E J,ROMBERG J,TAO T. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information[J]. IEEE transactions on information theory,2006,52(2): 489-509.
[3] DONOHO D L. Compressed sensing[J]. IEEE transactions on information theory,2006,52(4): 1289-1306.
[4] 石光明,刘丹华,高大化,等.压缩感知理论及其研究进展[J].电子学报,2009,37(5):1070-1081.
[5] 许志强.压缩感知[J].中国科学:数学,2012,42(9):865-877.
[6] 于爱华,白煌,孙斌斌,等.基于优化投影矩阵的人脸识别技术研究[J].浙江工业大学学报,2016,44(4):392-398.
[7] 龙胜春,龙军.一种应用于无线传感器网络的数据压缩方法[J].浙江工业大学学报,2014,42(2):210-213.
[8] 古辉,陈强.H.264帧内预测模式选择改进算法[J].浙江工业大学学报,2014,42(2):204-209.
[9] MA J W. Single-pixel remote sensing[J]. IEEE geoscience and remote sensing letters,2009,6(2):199-203.
[10] GAN L. Block compressed sensing of natural images[C]//Proceedings of the 15th International Conference on Digital Signal Processing. Cardiff,UK:IEEE,2007: 403-406.
[11] WARNELL G,REDDY D,CHELLAPPA R.Adaptive rate compressive sensing for background subtraction[C]//Proceedings of 2012 IEEE International Conference on Acoustics,Speech and Signal Processing.Kyoto: IEEE,2012: 1477-1480.
[12] SONI A,HAUPT J.Efficient adaptive compressive sensing using sparse hierarchical learned dictionaries[C]//Proceedings of 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals,Systems and Computers.Pacific Grove,CA:IEEE,2011: 1250-1254.
[13] NARAYANAN S,MAKUR A. Low complexity surveillance video coding based on distributed compressive video sensing[C]//2016 IEEE Region 10 Conference(TENCON). Singapore: IEEE,2016: 993-996.
[14] 练秋生,田天,陈书贞,等.基于变采样率的多假设预测分块视频压缩感[J].电子与信息学报,2013,35(1):203-208.
[15] 左觅文,常侃,施静兰,等.基于空时相关性的变采样率分块视频压缩感知[J].电讯技术,2013(11):1482-1486.
[16] TRAMEL E W,FOWLER J E. Video compressed sensing with multi-hypothesis[C]//Proceedings of the IEEE Data Compression Conference. Snowbird,UT:IEEE,2011: 193-202.
