基于混合多目标差分进化的流水车间调度问题研究
2018-07-05张闻强河南工业大学信息科学与工程学院河南郑州450001
王 宇 张闻强(河南工业大学信息科学与工程学院 河南 郑州 450001)
0 引 言
调度问题研究是将具有相关具有约束条件的有限资源,按照问题实际需求合理配给一个或者多个目标对象。流水车间调度问题FSP(Flow shop scheduling problem)是一类经典的多目标调度问题,按照实际工业生产需求约束后的数学建模,属于NP-hard问题,在工业自动化领域广泛存在。其中以最短拖期与总完工时间为双目标的调度问题意在合理地排列出机器、工件、时间等资源分配,有效率地满足自动化生产过程中经济或性能[1]。在1954年,FSP由Johnson等[2]提出,在此之后大量的论文提出了不同的方法,试图确定更好的工作序列。平衡找到高品质的解决方案,而且消耗合理的计算时间。
近年来在工业自动化领域,众多学者针对不同目标的FSP问题进行了广泛的探讨。研究单台机器混合型车间调度问题提出分支绑定算法,强调特殊情况下的启发式或最优解,尽量减少制造时间[3]。流程车间调度问题是典型的组合优化问题、解集复杂、数据量大、结果中通常不存在最优解,学者针对问题对最新的智能计算算法:混合遗传算法、粒子群优化和猫群优化算法的四个元学说的实验比较研究[4]。Gao等[5]提出两种建构性启发式方法,嵌入局部搜索和修改迭代算子,改进了混合启发式算法,在约束条件下最大可能地降低调度的总流程时间。然而,单目标的研究已不能满足当下制造自动化的生产环境,多重约束下的有限资源分配成为主流。为了弥补单一智能算法的弊端,结合不同算法的优势。在牺牲一定程度时间复杂度的情况下,学者对经典的演化算法进行组合。混合不同的算法使其具有相关父代算法的优势特性,针对实际环境优化后应用前景更加广泛。杨开兵等[6]根据成组工件的FSP问题,在保持种群的多样性与收敛性能上分别引入适应度计算策略和进行局部搜索。何启巍基于粒子群优化算法的特点,加入一种变邻域搜索策略,极大地提高了解的分布性,混合算法用于对调度问题进行求解,提高了解集的范围[7]。陈可嘉等[8]通过对经典的NSGA-Ⅱ算法进行改进,仿真生物食物链策略,算法收敛性能有所提高。
差分进化算法DE(Differential Evolution)用于解决实数优化问题,在1997年由Storn等[9]提出,是一种先变异,后交叉的启发式全局搜索算法,由于采用浮点数编码,算法解析容易实现,对连续空间具有高效的全局搜索能力。标准差分算法文档中使用锦标赛选择,便于实现,遗传方式与众多智能算法相同。差分算法的主要策略在于变异操作方式,带有方向目标性,区别种群中优势的个体,使得其他个体根据决策者的需要以优势个体为前提进行一定的扰动,实现个体变异,得到下一代。差分策略根据种群分布的特点,让优秀的个体成为“榜样”,避免传统遗传算法随机“盲目”式的变异方式,提高算法的搜索能力。现在,基于差分进化算法被广泛应用到数据挖掘、自动化、机械工程等各个领域。同时,也延伸于多目标优化与调度问题。针对最小化最大完成时间问题,提出自适应邻域搜索差分演化(NS-SGDE)基于概率模型的指导代理,以指导DE的探索阶段来产生后代[10]。差分算法过快的收敛速度容易陷入局部最优。通过设定自适应缩放因子,建立分布模型,对种群进化过程中的优势个体进行统计,自适性的改变选择方式,有效地防止子代陷入局部最优[11]。可变邻域(DEVNS)搜索在收敛性方面具有很强的优势,结合可变邻域的差分演化算法来解决流水车间调度问题具有很高的竞争力[12]。张晓霞等运用基于概率模型的分布估计算法,避免算法陷入局部最优,求解混合零空闲置换流水车间问题[13]。
向量评估算法VEGA(Vector evaluated genetic algorithm)[14]利用并行方式解决多目标优化问题,根据多目标子函数设立不同后代、分层成比例的选择机制,独立种群按照决策者需要可以进行独立遗传操作或者融合进化。不同的后代群体朝着不同的方向进化,这种特性表现出很强的朝着Pareto前沿面的边缘区域收敛的能力,同时分布性不好。一种基于Pareto支配与被支配关系的适应度函数PDDR-FF(Pareto dominating and dominated relationship-based fitness function)[15]用来判断个体之间的区别。PDDR-FF函数针对个体的支配信息对其优劣程度与位置进行区别划分,根据个体支配数与被支配数赋予不同的数值。个体在Pareto前沿面分为中心区域与边缘区域,其中中心区域的可支配面积比边缘区域要大。PDDR-FF的特点促使个体朝着具有更大支配数的优势方向前进,也就是表现为朝着具有更大支配面积的中心区域进化。混合采样机制不仅具有良好的收敛性能,同时保护了种群的分布性。基于混合采样策略的多目标进化算法HSS-MOEA(Multi-objective hybrid evolutionary algorithm)与NSGA-Ⅱ和SPEA2相比,混合采样后的算法在收敛和分布性能上要好,在时间消耗、运算效率上,也优于传统遗传算法[16]。
混合采样策略不仅具有VEGA偏好边缘区域的优势,同时具有朝Pareto前沿的边缘区域收敛的能力,而DE对精英解进一步优化。本文在HSS-MOEA的基础上引入差分策略,设计混合算法框架及变异操作中备选个体的选择策略。以此提出多目标混合差分进化算法(HMODE)来解决复合FSP问题。混合算法保留了收敛速度和分布性能,以及DE提高HSS-MOEA应用后的效率性。
1 问题描述
流程车间调度可以描述如下:在集合J={J1,J2,…,Jn}里有n个工件。在不同的m个机器{M1,M2,…,Mm}进行处理。模拟机器工件在机器上的操作顺序进行处理,则Oji被定义为作业Ji的第i个操作,并且机器Mi上的Oji的处理时间是Pji。目标是找到一套相对最优的解决方案,最大限度地减少加工时间和最大延迟。
令π=(π(1),π(2),…,π(1))是作业的某一组操作顺序,πa是排列π的运动作业,n是作业数。U表示所有可能的过程组合,π∈U。Ci(j)表示机器Mi上作业πj的总完成时间,tji是机器Mi上的操作完成时间。如果在机器Mi上处理操作Oji,则xji=1,否则,xji=0;如果在Okh之前操作Oji,则yjikh=1,否则yjikh=0。FSP的数学公式可以描述如下:
(1)
j=2,3,…,ni=2,3,…,m
以最大完工时间为目的的FSP是从解集U找到一组序列π*:
(2)
所有约束条件如下:
(3)
解决最小化最大拖期与最小化总完工时间的多目标流水车间调度问题要保证在同一时间里一个工件只能在一台机器上加工,约束条件要保证一台机器在某一个工作时间内只能加工一个工件,所有工件加工顺序相同。约束条件式(3)中前四个公式表示所有机器的作业加工订单,分别确保加工排列的可行性,作业的唯一性和机器的独特性。其余方程定义约束条件为非负。
求解最小化最大拖期是FSP中最常见的问题。假设Tmax(π)是序列π的最大拖期时间,Tπ(j)和Dπ(j)分别表示作业π(j)的拖期和项目时间。项目时间由“厂商”确定。类似地,FSP的最大拖期数学描述标准如下:
(4)
最大拖期与最大完工时间双优化目标流水车间调度问题可以形式化为:
min{Cmax(π),Tmax(π)}π∈U
(5)
2 混合多目标进化算法与差分演化策略结合
2.1 算法框架
本研究基于多目标混合采样进化算法,算法在同时保证收敛性能和分布性能的前提下,时间复杂度尽量降低。在此基础上,混合DE算法对精英种群进行处理,谋求进一步提高最优解集的收敛性和分布性,提高算法的性能。混合算法克服单纯DE算法对于问题的局部搜索能力弱、搜索效率低的弊端,并重新设计问题编码方式、遗传操作中对备选个体的选择策略以及参数设置。促使混合后的算法在Pareto前沿面的各个方向,尽可能地向着真实Pareto前沿面收敛并且均匀分布,以弥补单一算法的不足,提升算法的效力和效率。
算法大致框架如图1所示,以t代HMODE的演进过程为例。A(t)表示精英解集,作为第t代的精英保留策略,P(t)代表第t代种群。初始化参数,设置结束条件。一代的解决过程包括5个阶段。
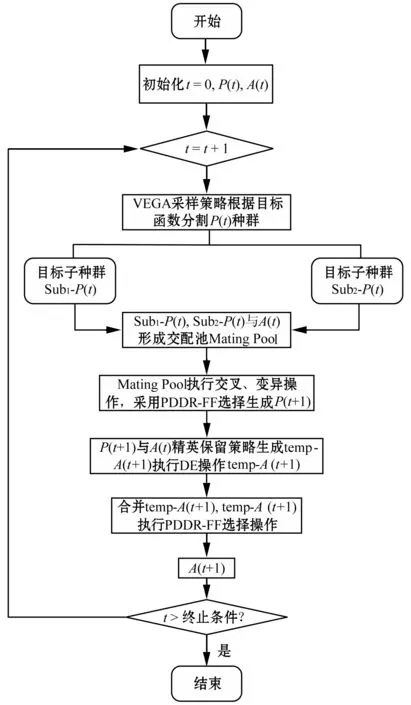
图1 算法流程图
1) 第一阶段:VEGA采样策略 在这个阶段,利用VEGA采样策略选择优秀个体,利用对Pareto前沿面边界地区的强收敛能力依据目标函数把P(t)分割成子代种群Sub1-P(t)与Sub2-P(t)。子代种群只考虑单一目标演化,是单目标最优解集,按照降序排列。VEGA特性选择出来的优秀个体处于Pareto前沿面边界处。
2) 第二阶段:融合交配池(混合采样) VEGA对Pareto前沿面边缘区域处的搜索能力很好,多个子种群同时搜索导致单个个体的多样性欠佳,原因就在于它的选择偏好。在研究中,采样得到的单个目标子种群与精英种群A(t)的组合,形成一个交配池Mating Pool。在交配池中,以一个目标存储好优秀个体子种群Sub1-P(t),子种群Sub2-P(t)为另一个目标拥有优秀个体,而精英种群基于PDDR-FF适应度函数选择后具有多目标最优解,位于Pareto前沿面中心区域。因此,在交配池中,三分之一的个体服务于一个目标,三分之一是另一个目标,最后三分之一是两个目标,如图2所示。
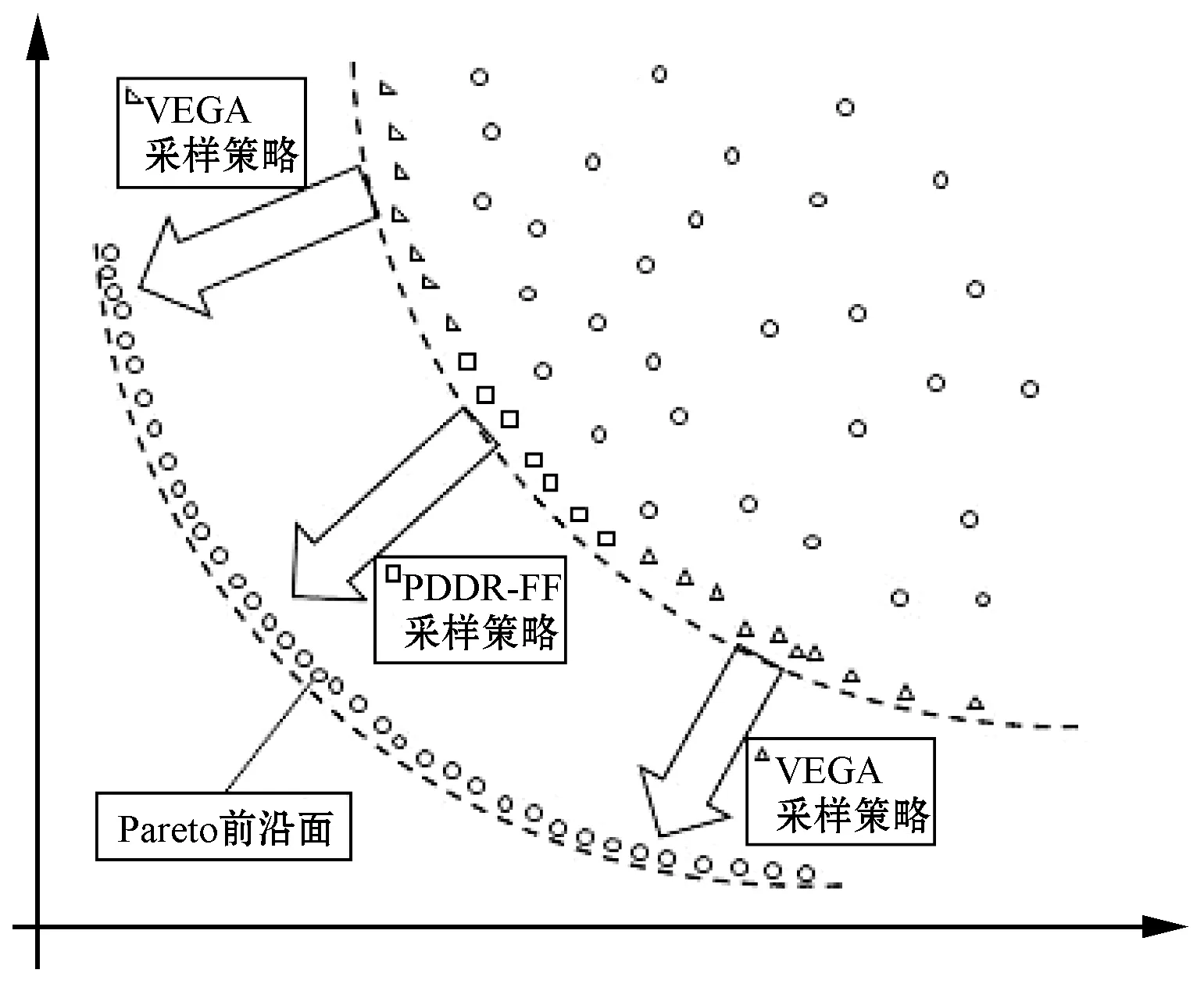
图2 混合采样
3) 第三阶段:重构 交叉操作是遗传算法的主要操作。只有通过连续交叉,才能生产新的个体,获得好的解集,突变算子是保持解的多样性。在传统解决FSP问题方式上,基于问题特性通常采用染色体编码。本文引入差分进化策略,对问题编码进行实数化。从二进制编码的思想出发,使用模拟二进制交叉SBX(simulated binary crossover)与(polynomial mutation)多项式变异。
SBX交叉模拟二进制串单点交叉共享重心的属性特点,交叉生成的子代个体与父代的重心对称。SBX交叉对于实数编码具有很高的稳定性。βi是随机数。
(6)
ci与pi分别表示第i个基因位的子代与父代个体。SBX模拟二进制码单点交叉的共享重心特性,对于子代个体与父代个体每一个变量尽可能地使βi=1,保证了后代与双亲的重心对称。
变异操作使用基于多项式分布的多项式变异方法。不均匀的方式改变个体,服从两个原则:突变体应随机抽样;随着算法的演化过程,突变的程度将会减少。
使用均匀分布U~(0,1)生成多项式分布数ξ。
(7)
第i个变量变异方式如下:
(8)
ξj是由式(7)生成的多项式分布随机数。Δmax是xj的最大允许摄动。
4) 第四阶段:精英保留策略 精英保留思想要把优秀的个体作为“榜样”传递到下一代,直到替换。A(t)作为优秀种群在一定程度上代表着当代最好的那一批个体,算法最后输出也是这个集合。精英种群和P(t+1)混合成临时种群temp-A(t)后按照PDDR-FF值适应度值排序。根据PDDR-FF性质,函数值越小越好,支配的面积大,其适应度值不超过1。同时,被支配个体的适应度值将超过1。此外,即使对于所有非支配个体,它们也具有不同的PDDR-FF值。非支配的个体根据位置分为边缘区域(接近1)和中心区域(接近0)。
计算PDDR-FF适应度值排序后,按照种群设置大小,选择出|A(t)|个体作为temp-A(t+1)。temp-A(t)中的个体被复制形成temp-A(t+1)。这种个体保留机制类似于精英抽样策略,基于PDDR-FF函数特点保证解集合处于Pareto中心区域。
5) 第五阶段:差分优化策略 更新解集以获取临时种群temp-A(t+1)后,应用差分进化策略对temp-A(t+1)进行优化。经过DE的突变和交叉运算后创建临时种群temp-A′(t+1)。此时的临时种群不仅有着上一代优秀的个体,同时包含根据“榜样”个体引导获得的下一代。融合后按照决策者对问题的需要选择下一代真实精英种群A(t+1)。与传统DE不同,应用与HSS-MOEA相同的优秀个体保持机制,对种群进行区域划分,依据PDDR-FF值更新解集。
2.2 混合差分策略
DE不仅加强算法在Pareto前沿面中心区域和边界区域的搜索能力,而且有助于弥补在过于强调中心和边界区域的搜索带来的剩余区域搜索能力不足的缺陷。但是需要根据问题背景的特殊性和复杂性来设计差分策略进入的时机。此时机需要克服单纯DE算法基于问题的局部搜索能力弱、搜索效率低的弊端。Pareto前沿面上个体代表着当代优秀的种群,作为目标向量,向着真实的Pareto前沿面搜索有利于提升算法的收敛性能;或者沿着当前Pareto前沿面搜索将有利于提升算法的均匀分布性能。
变异操作中备选个体的选择策略。基于DE算法,需要根据当前个体、备选个体个数和方向以确定搜索起点、步长和方向。这些个体的选择策略直接决定了新生成个体的收敛和分布性能。拟采用的变异操作根据当前个体的适应度评价函数值为DE/rand/1,仿真结果采取的设置如下:
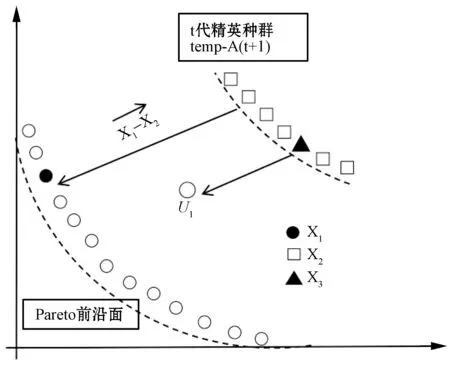
Ui=X3+F(X1-X2)
(9)
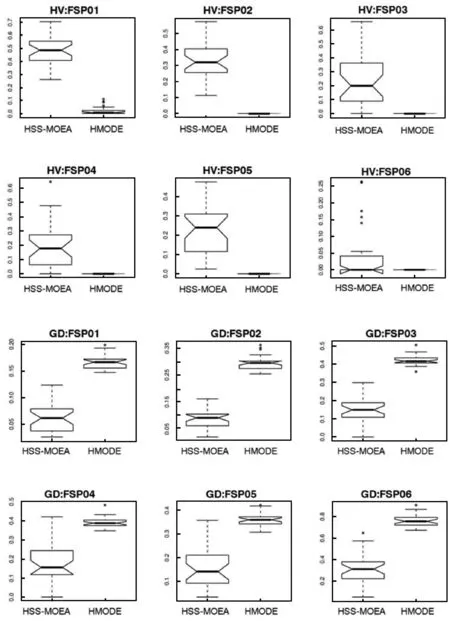
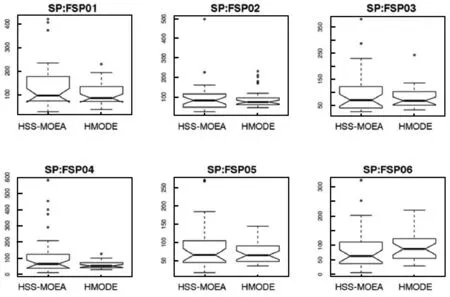
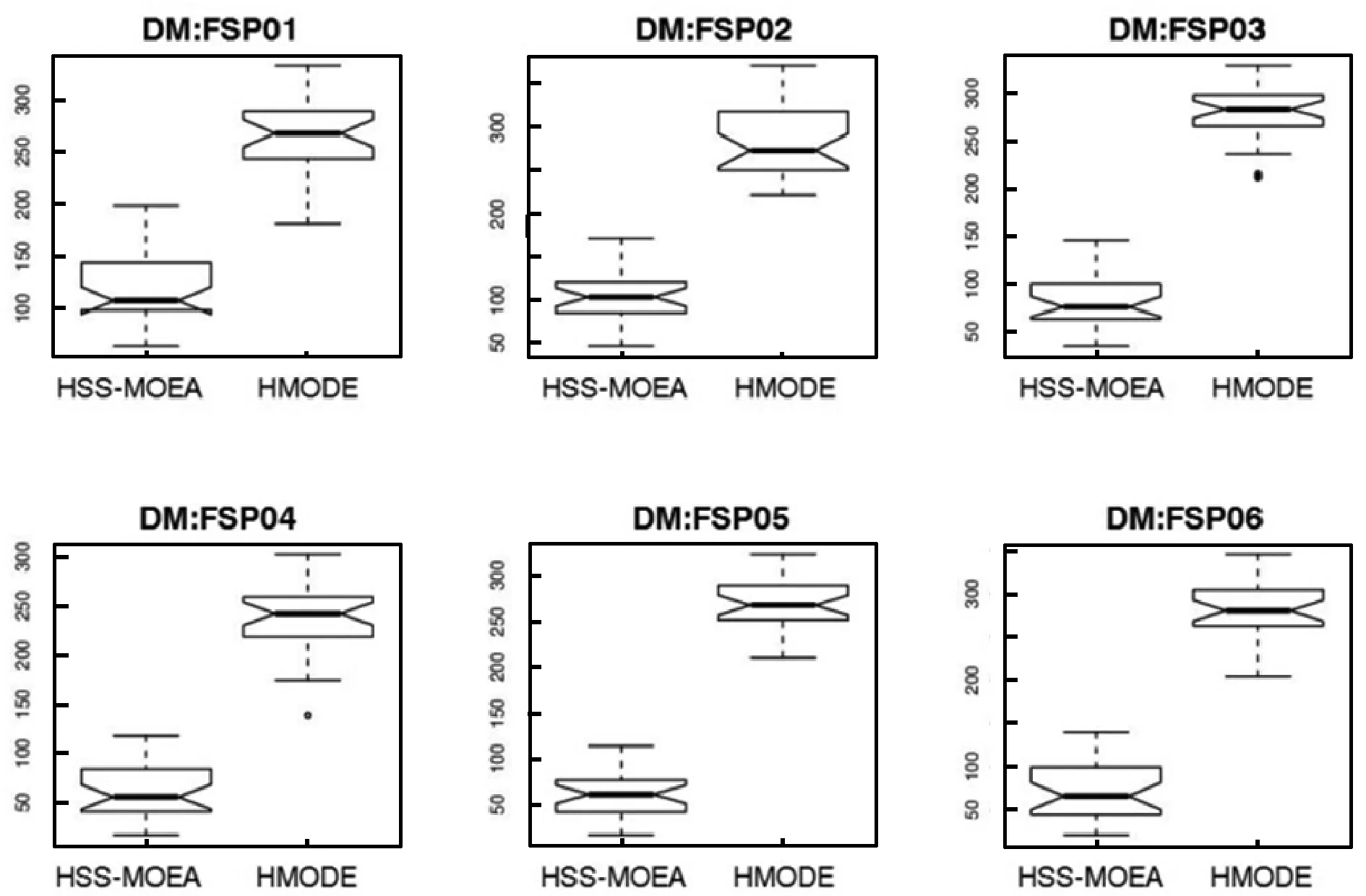
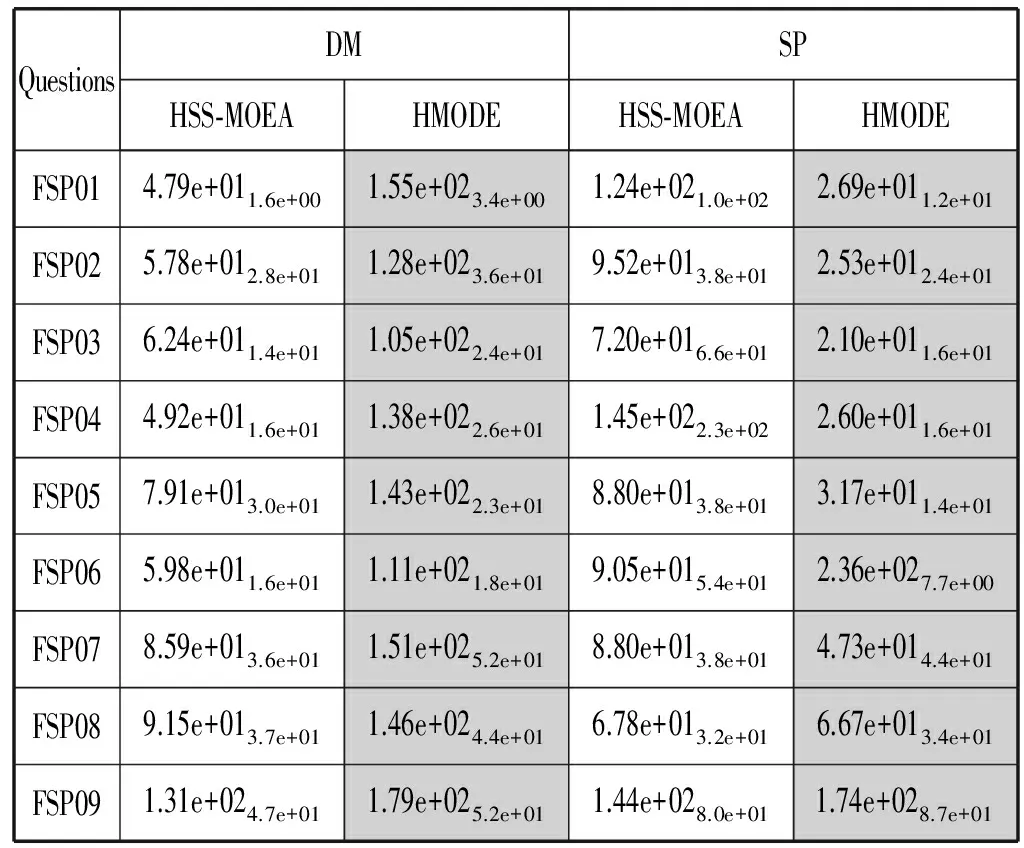
依据支配关系把Pareto前沿面可划分边界区域与中心区域。对于初始精英解集temp-A(t+1)获得差分演化算子,随机选择三个不同的个体。根据PDDR-FF值,保证选择的个体eval(X1) 图3 收敛性 图4 分布性 模式一:X1与X2位于帕累托前沿面相同的区域时,不考虑X3个体位置,进化方向有助于提高解集的收敛性能。 模式二:X1与X2位于帕累托前沿面不同的区域时,个体进化有助于提高解集的均匀分布性能。 被选最差个体位于中心区域,最优个体分布边界区域时,个体朝两边进化。 只表示单个目标的优势个体集中在边界处,具有多目标的最优个体位于中心区域,个体朝中心处移动。 混合算法框架如图3所示,改进了遗传算法,根据问题的特征采用实数编码引入了DE策略对精英个体进行优化处理,使得算法的收敛性有了较大的改进。加入自适应密度评价函数PDDR-FF,对前沿面分块化,弥补了遗传算法容易陷入局部最优解的缺点,加强了全局搜索的能力,使得算法能够向多个方向演变,并在算法中根据问题相关的偏好信息设计DE策略执行时期,提高算法的搜索速度。算法伪代码如下所示。 算法1 HMODA⁃DEforMOPsStep0 Initialization:Sett=0,P(t)和A(t)Step1 Reprodution:1.1PartitionP(t)intoSub⁃P1(t)andSub⁃P2(t)byVEGA1.2TheSub⁃P1(t),Sub⁃P2(t)andA(t)mixedintoMatingpool1.3P(t+1)wereobtainedfromthematingbycrossoverandmutationStep2 Differentialevolution:2.1TheA(t)andP(t+1)generatetemp⁃A(t+1)byelitistretentionstrategy2.2X1,X2andX3selectedfromtemp⁃A(t+1).Accordingto⁃thepropertiesofPDDR⁃FFfunction,temp⁃A′(t+1)wereobtainedbydifferentialevolution.Step3 Selection:SelectA(t+1)fromtemp⁃A(t+1)Utemp⁃A′(t+1)Step4 StoppingCondition:Ifthestoppingconditionismet,stop;otherwise,sett=t+1andgotoStep1. 为验证算法可靠性,实验数据来源于Taillard[17]提出的其中10个随机生成的调度问题,数据规模对应于工业问题的实际尺寸。分别为20×5、20×10、20×20,对应为20个工件。有5台、10台以及20台机器。目的是最小化完工时间与最小化最大拖期的双目标。所有的仿真都在Core i5处理器(3.3 GHz)上执行,内存为8 GB。程序为JAVA语言编写。HMODE和HSS-MOEA使用相同的编码和遗传操作,具体参数值如下:种群大小=100;最大代数=500;档案大小=50;交叉概率=0.90;突变概率=1/变量数,编码方法是实数编码。有20个变量。DE交叉概率=0.5,F=0.5。运行30次HMODE和HSS-MOEA以比较结果。在这项研究中,验证收敛性通过比较解集中的个体与参考点在目标空间中所围成的超立方体的体积HV(Hypervolume)指标,比较父代与子代之间的距离的GD(generational distance)指标。分布性通过多元化度量DM(Diversification Metric)和SP(Spacing),比较当前点的每个成员与其最近的邻居的范围(距离)的差异,DM通过个体与其他个体的最大欧式距离来评价,有效地评测解集的分布性。 实验数据Box箱线图如图5与图6所示。表1与表2分别表示SP、DM和HV、GD指标的平均值和方差。表中显示,HMODE的分布优于HSS-MOEA,表明DE促进了进一步演变。与HSS-MOEA相比,HMODE在收敛方面具有优势。由于使用差分策略,编码方案使用实数编码。HSS-MOEA和HMODE的时间复杂度高于顺序编码。同时,HMODE在计算上有不止一个步骤,消耗更多的时间资源。 图5 收敛性评测:HV与GD指标 图6 分布性评测:DM和SP指标 表1 DM 和 SP指标的均值与标准差 表2 HV和GD指标的均值与标准差 对于算法的效率,与传统遗传算法相比较可以从两方面来讨论。1) 距离计算方面,NSGA-Ⅱ时间复杂度为O(mNlogN);SPEA2计算复杂度为O(mN2logN);由于没有距离计算机制,因此HSS-MOEA与HMODE的时间复杂度为O(0)。2) 在适应度计算方面,HSS-MOEA与HMODE采用基于支配关系的混合采样,需要进行PDDR-FF值的计算。对于种群中m个目标,N个个体的PDDR-FF值的计算,总的比较次数可以按照下式计算: m(N-1)+m(N-2)+…+m×2+m×1=mN(N-1)/2 (10) 因此,需要进行mN(N-1)/2次比较来计算PDDR-FF的值,HSS-MOEA的时间复杂度为O(mN2);NSGA-Ⅱ与SPEA2时间复杂度同样为O(mN2)。由于HMODE引入DE计算,对每代精英种群进行优化处理,假设精英种群大小也为N,染色体长度为C。首先进行PDDR-FF排序,时间复杂度为O(mN2)。更新精英解集的最差时间复杂度为O(NC)。则HSS-MOEA的时间按复杂度为O(mN2)+O(mN2)+O(NC)。综上所述,HSS-MOEA的运算速度要比NSGA-Ⅱ与SPEA2快,HMODE比HSS-MOEA要慢,随着实际问题规模的增大,染色体长度C越大。与传统遗传算法相比时间复杂度上优势不明显,但收敛性与分布性上则进一步提高。以FSP01(20×5)为例,HSS-MOEA时间消耗的均值有标准差为:1.49e+011.6e+01,HMODE则为4.89e+021.9e+01。 在本文中,为解决最大完工时间和最小化最大拖期双目标流水车间调度问题,一种结合差分进化策略与混合采样策略的多目标优化算法HMODE被提出。混合采样策略对依据种群个体的函数值与支配关系在Pareto前沿面进行排序与区域划分,融合差分进化思想,引导每一代的进化方向。此外,DE操作对精英解集的处理,使得解在收敛到真正的Pareto前沿面的能力更大。数值比较表明,HMODE在收敛性和分布性上优于HSS-MOEA。 [1] 王万良. 生产调度智能算法及其应用[M]. 科学出版社, 2007. [2] Johnson S M.Optimal two- and three-stage production schedules with setup times included[J].Naval Research Logistics Quarterly,1954,1(1):61- 68. [3] Wang S, Liu M, Chu C. A branch-and-sbound algorithm for two-stage no-wait hybrid flow-shop scheduling[J]. International Journal of Production Research, 2015, 53(4):1143- 1167. [4] Bouzidi A, Riffi M E, Barkatou M. A comparative study of four metaheuristics applied for solving the flow-shop scheduling problem[C]// World Congress on Information and Communication Technologies. IEEE, 2015:140- 145. [5] Gao K, Pan Q, Suganthan P N, et al. Effective heuristics for the no-wait flow shop scheduling problem with total flow time minimization[J]. International Journal of Advanced Manufacturing Technology, 2013, 66(9- 12):1563- 1572. [6] 杨开兵, 刘晓冰. 无成组技术条件下流水车间调度的多目标优化[J]. 计算机集成制造系统, 2009, 15(2):348- 355. [7] 何启巍, 张国军, 朱海平,等. 一种多目标置换流水车间调度问题的优化算法[J]. 计算机系统应用, 2013, 22(9):111- 118. [8] 陈可嘉, 周晓敏. 多目标置换流水车间调度的改进食物链算法[J]. 中国机械工程, 2015, 26(3): 348- 353,360. [9] Storn R,Price K.Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces[J].Journal of Global Optimization, 1997, 11(4):341- 359. [10] Shao W,Pi D.A self-guided differential evolution with neighborhood search for permutation flow shop scheduling[J]. Expert Systems with Applications, 2016, 51:161- 176. [11] 刘红平,黎福海. 面向多目标优化问题的自适应差分进化算法[J]. 计算机应用与软件,2015,32(12):249- 252,269. [12] Yi W,Gao L,Zhou Y,et al.Differential evolution algorithm with variable neighborhood search for hybrid flow shop scheduling problem[C]// IEEE,International Conference on Computer Supported Cooperative Work in Design.IEEE, 2016:233- 238. [13] 张晓霞, 吕云虹. 一种求解混合零空闲置换流水车间调度禁忌分布估计算法[J]. 计算机应用与软件, 2017, 34(1):270- 274. [14] Schaffer J D. Multiple Objective Optimization with Vector Evaluated Genetic Algorithms[C]// International Conference on Genetic Algorithms. L. Erlbaum Associates Inc. 1985:93- 100. [15] Zhang W,Gen M,Jo J.Hybrid sampling strategy-based multiobjective evolutionary algorithm for process planning and scheduling problem[J]. Journal of Intelligent Manufacturing, 2014, 25(5):881- 897. [16] 张闻强, 卢佳明, 张红梅. 流水车间调度问题的快速多目标混合进化算法[J]. 计算机应用, 2016, 36(4):1015- 1021. [17] Taillard E. Benchmarks for basic scheduling problems[J]. European Journal of Operational Research, 1993, 64(2):278- 285.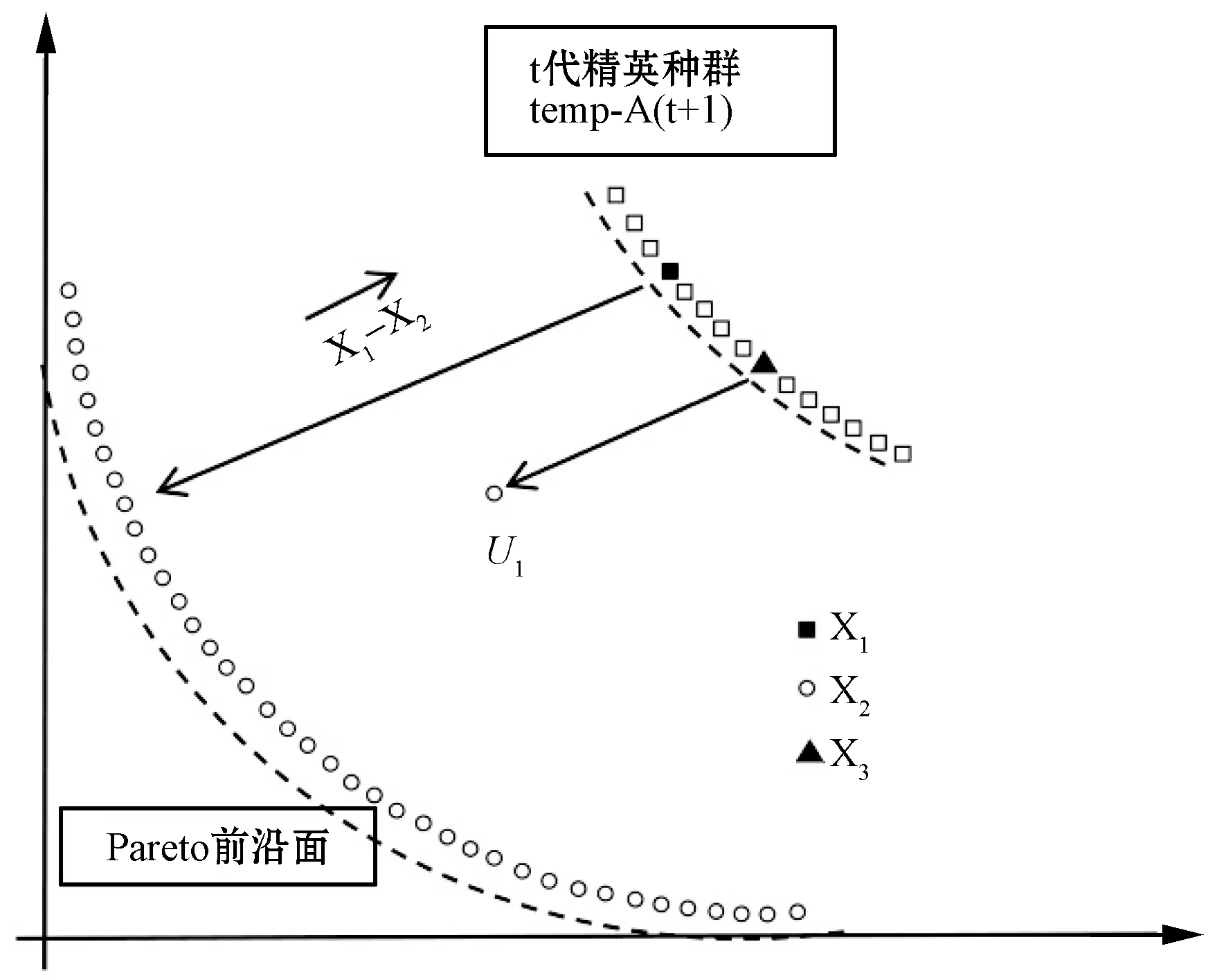

3 实验与结论

4 结 语
