高速网络环境中适合大数据传输的改进UDT协议
2018-07-05吴承荣复旦大学计算机科学技术学院上海200433
邢 璐 严 明 吴承荣(复旦大学计算机科学技术学院 上海 200433)
0 引 言
近些年,随着互联网、云计算、大数据集群等技术的发展,大数据时代到来,数据如今渗透到各行各业,数据规模已从TB级增长到PB级[1]。数据总量多,单个数据文件大,通过现有的网络传输数据往往需要很长时间,这给不同地区机构之间的数据交流带来了困难。如果网络发生变化或者网络出现中断,传输性能还将进一步降低。传输数据规模大,传输效率要求高,传统的互联网协议和传输工具已经无法满足大数据时代对传输的要求,因此亟需研究和构建新的高速网络传输协议。
目前,研究者提出了很多改进的传输协议用来提高大数据在广域网上的传输性能。ESnet[2-3]科学网使用GridFTP协议即Globus Toolkit组件之一,实现两台主机之间高速、可靠的数据传输。优化的高速网络传输协议一般分为两类:一类是基于TCP的,如GridTCP[4]、FDT(Fast Data Transfer Tool)[5]、fast-TCP[6]和sftp[7];另一类是基于UDP的,如UDT[8]、QUIC[9]、PAT等。
传统的TCP协议可以提供可靠的、面向连接的传输功能,但是在复杂的广域网环境中,由于TCP协议的固有瓶颈使得基于TCP的高速传输协议无法充分利用网络带宽。在TCP协议中,速率控制和拥塞控制是以丢包作为控制的信号,因而,丢包将对TCP传输速度产生很大的影响[10]。在链路条件较好的情况下,这种自诱导式丢包数会超过其他原因的丢包,使得传输无法获得平稳的速度。而在广域网的环境中,网络环境复杂,丢包可能因为多种情况,并非一定是带宽的限制,因而这种方式将导致对网络拥塞状况估计的误判,而基于TCP的高速网络传输协议会继承TCP协议的相关特性。GridFTP协议有三个重要的参数:并行、并发和管道[11],并通过并行TCP数据流充满网络带宽,但多个TCP流在一方面会加重网络负担,造成网络资源的竞争,引起不必要的重传,使得带宽资源浪费。另一方面主机端在处理时需要使用更多的CPU资源和内存资源来维护每个TCP流的状态,加重其系统负担。
UDT协议是基于UDP协议的应用层协议,应用程序可以基于UDT协议实现可靠的文件传输功能[8]。UDT协议显式通知发送方丢包序列,使用连续发送包对的技术对带宽进行预测,将基于速率的拥塞控制和基于窗口的流控机制相结合,实现高速网络的可靠传输。在UDT的架构中,可以实现定制化的拥塞避免策略和流控机制来满足不同网络条件下的传输控制而不用修改操作系统内核代码。
在千兆网环境中,未优化的UDT协议在吞吐率、公平性、TCP友好性以及稳定性等方面具有良好的性能,但是与TCP协议相比会占有更高的CPU资源。随着网络技术的发展,出现了10 Gbps、40 Gbps甚至更高带宽的网络环境,然而在这些高速网络环境中,有许多因素阻碍网络传输速度的进一步提升,如CPU和存储速度。
本文通过对UDT协议在10 Gbps带宽的高速网络环境中进行大数据文件传输时的传输瓶颈和主机丢包的原因进行分析,提出了基于UDT的改进A-UDT(Advanced UDT)协议。本文的主要贡献包括以下三个方面:
1) 分析高速网络环境中UDT协议的传输瓶颈和丢包原因,提出了一系列的系统优化措施。
2) 改进UDT协议的重传机制,减少超时重传的次数,增强了UDT协议的可靠性。
3) 分析主机端使用UDT协议时CPU的分布规律,通过减少系统调用的次数优化了CPU的利用率。
1 相关工作
TPG[12-13]是一种用来提升端到端传输性能的通用框架,并以UDT协议为例子,验证了在高速网络中TPG可以提升传输协议的性能。在TPG的相关文献中,列举了可能影响UDT传输的因素和相关参数设置,并通过调整数据包大小、块大小和缓存大小提升UDT协议的传输速度。在文献的实验部分,TPG指出实验需要网卡支持jumbo frames模式来实现巨型帧达到修改数据包大小的目的,但是对广域网的传输,这就要求链路上的节点都支持这种模式。此外,大的数据包也意味着出现丢包时,重传的代价也将更大。文献[14]测试了基于TCP和UDP的多种高速网络传输工具在不同RTT和背景流量的情况下的传输性能,实验结果显示UDT在RTT较高的情况下仍然有较高的传输速度和稳定的吞吐率。
文献[15]指出在高速网络的环境中,操作系统网络协议栈处理数据包的速度已经无法与网卡速度相适配,CPU是限制主机传输速度的主要瓶颈。Luigi Rizzo等[16]提出了一种高效的收发数据包的框架netmap,与传统Linux网络协议栈不同,它主要从三个方面减少数据包的处理代价:数据包动态内存分配、减少系统调用代价和内存拷贝次数。通过这些优化netmap提高了CPU的利用率,提升了数据包的收发处理速度。实验结果显示netmap运行在900 MHz的单CPU上,数据包收发次数可以达到14.88 Mpacket/s。但是,netmap并不提供可靠性的保证和网络拥塞控制。DPDK[17](Data Plane Development Kit)协议也是一种高性能的快速包处理工具,DPDK可以绕过传统的Linux协议栈,将数据包直接存放在用户态空间,极大地减少了接收数据包时系统调用和内存拷贝次数。DPDK的优化效果很好,但是如果用户选择使用DPDK,就需要实现TCP和UDP协议来满足应用层协议的需求。
2 Advanced UDT
Advanced UDT(A-UDT)在继承UDT良好框架的基础上,实现了UDT协议在万兆网上的可适应性。本文主要从以下三个方面分析和解决UDT协议在高速网络中的传输瓶颈:
1) 在万兆网的环境中,UDT传输出现严重的丢包问题。
2) UDT协议持续丢包引起超时重传的现象。
3) UDT协议占用过多的CPU资源问题。
2.1 系统调优
缓冲区在高速网络的传输过程中有很大的作用,越大的缓冲区对突发数据流的处理能力越强。数据包从网卡接收到拷贝至应用层进行处理流程如图1所示。

图1 数据包一次接收过程
数据包在网络中传输,先到达接收方主机的网卡,ring buffer是网卡接收缓存区,在处理收发数据包时对突发情况有着重要的作用,而一般网卡的默认的接收缓冲区较小,可以重新设置。当网卡接收到数据包后,会通过触发IO中断的方式告知内核有数据包到达,操作系统内核将网卡数据包存储到内存中,一般系统内核参数对于TCP协议的接收缓存会自适应的设置,而对UDP协议则没有。之后UDT接收端会调用系统内核提供的UDP套接字接口函数获取数据包。应用程序会在用户空间中开辟了一段内存,用来顺序存放接收到的UDT数据包。这段内存作为环形队列,重复利用,队列空间满时,UDT接收端并没有重新调整的机制。
在万兆网的环境中,使用UDT传输工具传输大文件时,会出现传输速度慢,带宽利用率低,并且伴随着严重丢包的现象。使用流量监控服务器对接收端流量进行分析,发现在网络的链路上没有发生丢包,发送方发送的数据包都到达了接收方,但在应用层,UDT发送方仍然收到了大量的NAK控制包,使得文件的传输速度很低。
根据之前对数据包在接收方的接收流程的分析可以得出,数据从链路上获取之后,会暂存在不同的缓存队列中等待下一步的处理,数据包的处理需要获取CPU资源。当CPU不足以处理高速网络的传输流量时,数据包会在缓冲区累积,当超过缓冲区的容量时,数据包就会被丢弃,造成链路中没有发现丢包,但UDT接收端在应用层接收不到相应数据包,一直发送NAK控制包进行重传操作的现象。
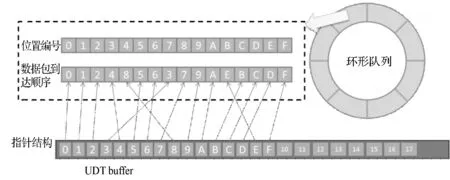
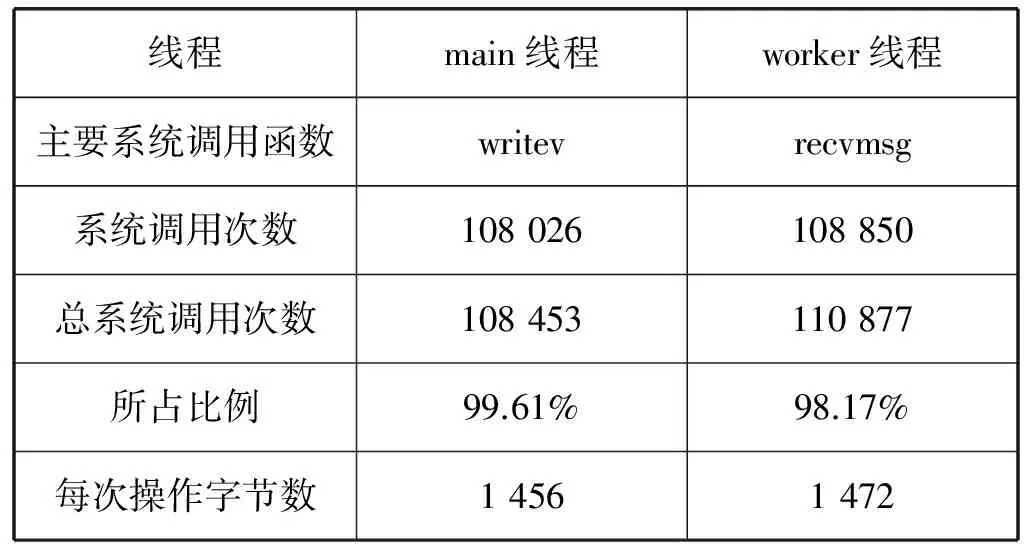
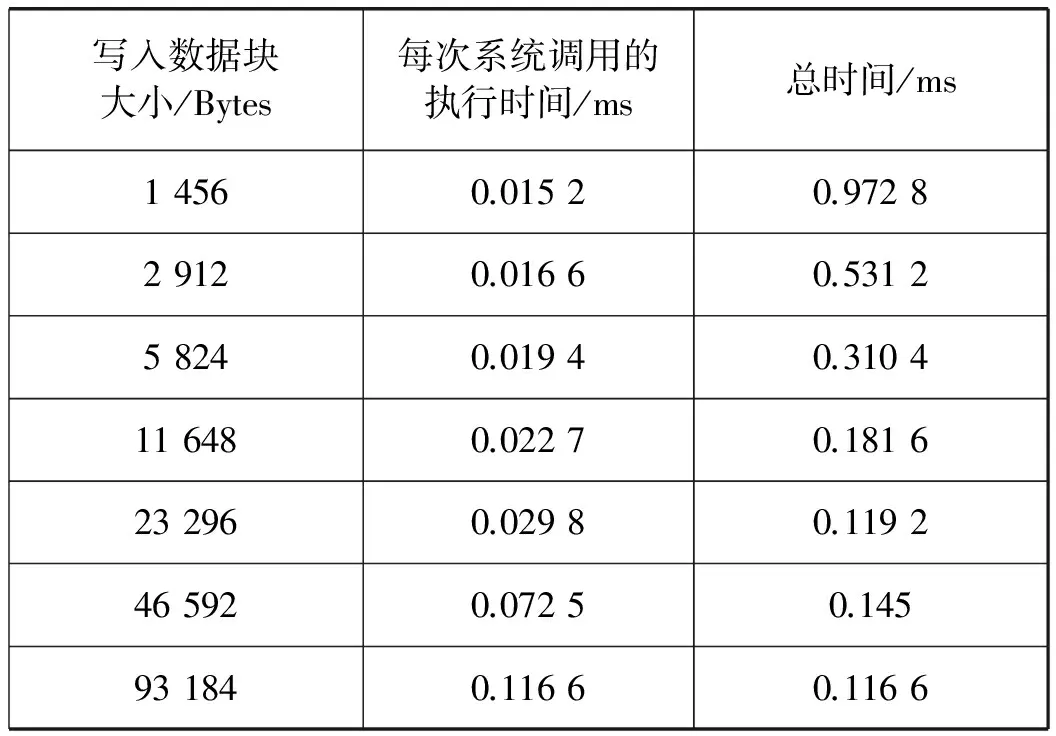
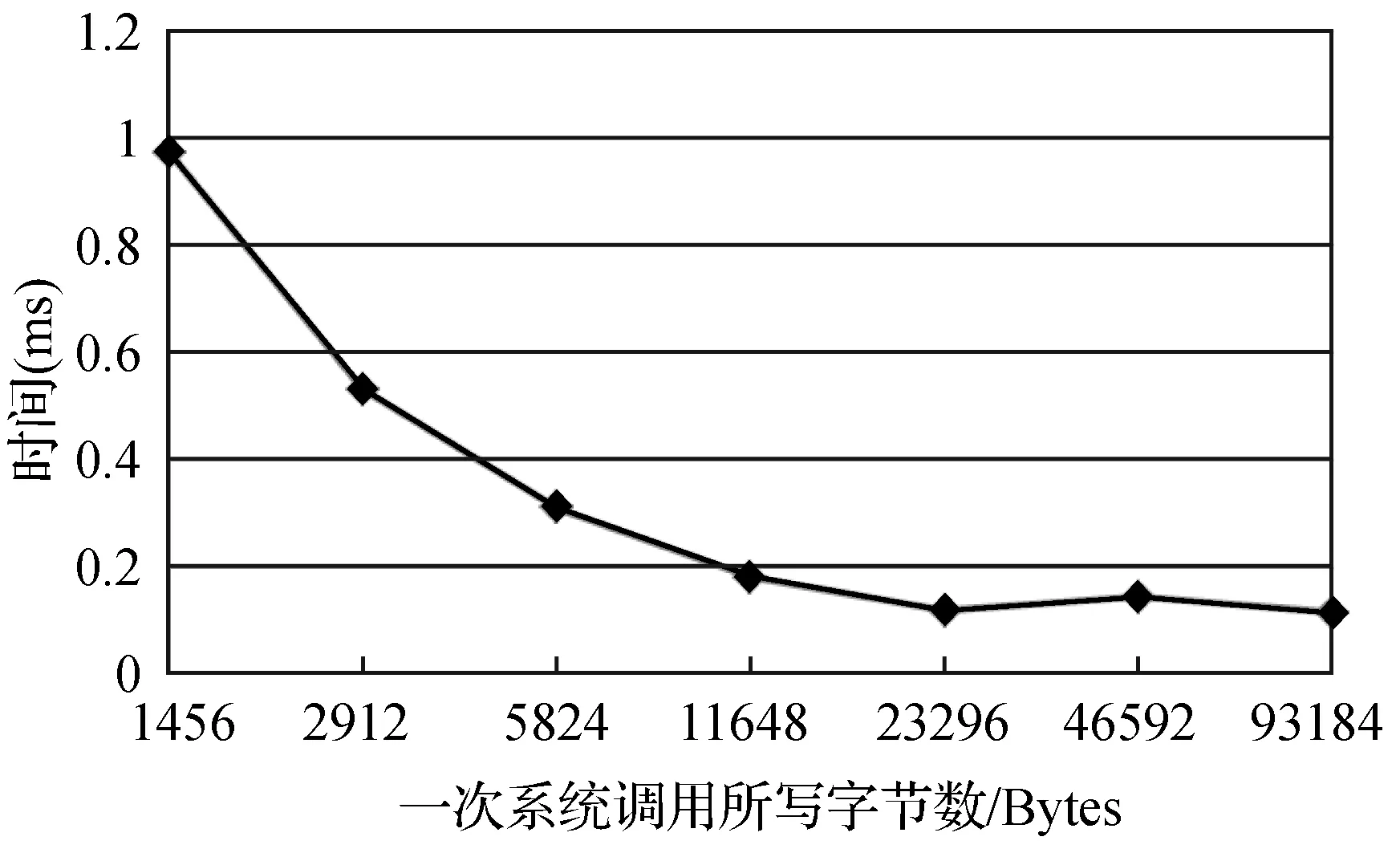
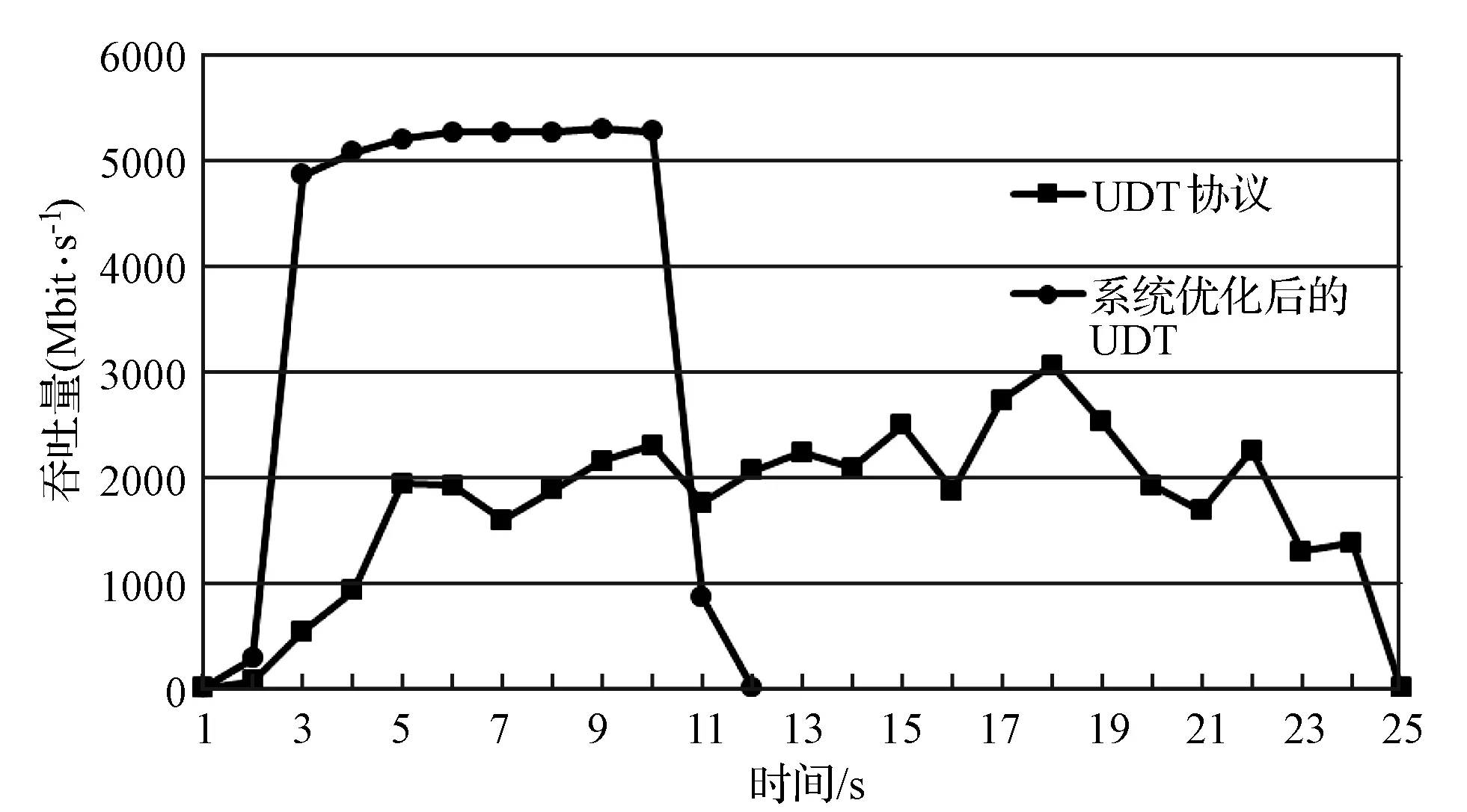
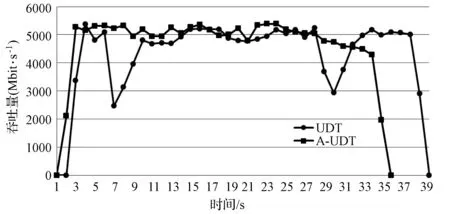
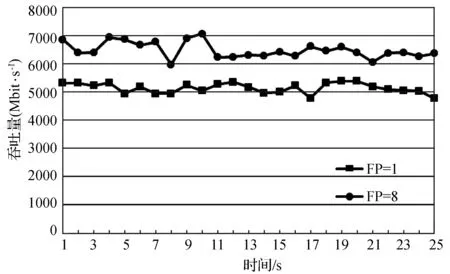
假设当前传输的文件大小为D,网卡接收速度为Snet,CPU的处理速度为Scpu,不考虑丢包重传,接收时间可以表示为D/Snet,当Scpu 当文件较小时(即D比较小时),系统默认的缓存大小可以满足传输需求不会发生丢包;当文件较大时,就会有持续的数据流量,导致所需缓存大小增大,系统的默认配置已无法满足需求导致数据包被丢弃。 在Linux系统中可以通过调整不同阶段的参数缓解丢包现象。首先,可以使用ethtool命令修改网卡配置,增大环形缓冲区的大小。其次,Linux的内核参数配置可以写在sysctl.conf文件中以达到修改接收数据包最大内存的目的,其中参数rmem_max表示最大接收数据包的内存大小。最后,UDT接收程序则提供了两个API函数接口:UDT_RCVBUF和UDP_RCVBUF来设置UDT的接收缓存和UDP的接收缓存。 这个部分我们解决的主要问题是分析为什么主机出现丢包时会引发超时重传,分析UDT可靠机制存在的问题,减少超时重传的次数。 2.2.1UDT可靠机制 在最新的UDT4.0版本中,发送方和接收方各自维持一个丢失列表,接收方丢失数据包的集合用RLL={l1,l2,…,ln}表示,发送方丢失数据包的集合用SLL={l1,l2,…,lm}表示,li表示丢失数据包的序列号。 当数据包到达接收方后,首先检测是否发生丢包事件,在UDT协议中,接收方会记录已接收到的最大数据包的编号smax。如果当前接收到的数据包的序列号si>smax+1,则表明出现丢包,此时更新smax为si,并将未接收到的数据包的序列号区间加入到丢失列表中,即: RLL=RLL∪{smax+1,smax+2,…,si-1} 之后,接收方会发送NAK控制包告知发送方需要重传的数据,相同的序号区间会加入到发送方丢失列表SLL中,并通过拥塞控制算法降低发送速度。当丢失列表不为空时,发送方优先发送丢失列表中的数据包,当数据包一旦重传成功,就将其从丢失列表SLL中删除;同时当接收方接收到数据包后,也将其序列号从RLL中删除。 对万兆网中使用UDT协议进行传输的情况分析,在未进行系统优化前,进行大文件传输速度慢的原因是存在大量持续的丢包,并且一旦出现丢包,会有传输速度降低为0 bit/s并触发超时重传定时器的现象。由于网卡速度很快,在超时重传操作之前,发送方已将发送窗口中的所有数据发送完毕,不再发送数据包,此时发送瞬时速度降为0 bit/s并持续到超时重传定时器启动。超时重传的主要原因是发送窗口中的数据一直没有收到确认,对于丢失列表中的数据包,发送方只在丢包检测的时候发送一次NAK控制包。当链路状况不好或者主机处理能力不够的情况下,重传的数据包发生丢包,而此时UDT协议没有二次重传的机制,从而导致超时重传的现象。 2.2.2 改进重传机制 UDT协议存在两种ACK控制包,一种是常规ACK控制包,常规ACK控制包是通过定时器触发的,一般是0.01 s的间隔发送一次。这种ACK中包含较多的控制信息:确认序列号、往返时延、UDT可用缓冲区大小、预估接收速度和链路容量等信息。另一种是轻量级ACK控制包,只包含确认序列号,当接收端接收到一定数量的数据包会发送一个轻量级ACK控制包用于确认。 超时重传使得大数据传输的速度变慢并降为0 bit/s。根据传输过程分析发现,在发送方将发送窗口中的所有数据包发送完毕并等待接收方确认期间,发送方会多次收到具有相同序列号的轻量级ACK控制包,这也是丢包的信号。但是UDT接收端只会在第一次判断丢包时发送NAK控制包,发送端接收到的NAK控制包后会重传数据。重传的数据如果发生丢失,UDT接收端是没有相应机制发现的,因为UDT协议忽略了多次收到相同序列号的ACK控制包这个丢包信号。 我们提出改进的UDT可靠性控制算法,能够及时发现链路中丢失的二次重传数据包,并充分利用ACK控制包信息,避免超时重传。在算法中,当接收端在发送一系列ACK控制包{ACK1,ACK2,…,ACKn}后,首先检测当前发送的ACK控制包是否与之前发送的相同,如果相同,记录序列号相同次数的变量RAsame加1,否则,清零。使用TAsame表示发送相同ACK序列号次数的阈值,如果RAsame超过TAsame,则将RAsame清零并重传RLL列表中的数据包,即发送NAK控制包(优先选择序列号小的连续的数据包)。当发送方接收到NAK数据包后,重发丢失重传的数据包。执行过程如算法1所示。 算法1 改进的UDT可靠性控制算法Input:aseriesofACKsequencenumbers{ACKi}whichthesenderhasreceived. thethresholdTAsame thetimesRAsameforeachACKiwhensenderreceivestheACKdo ifACKi=ACKi-1then RAsame++; else RAsame=0;foreachreceivedACKdo ifSLLisNULLthen ifRAsame>TAsamethen insertthepacketsequencenumberACKiintoSLL; RAsame=0;foreachpacketintheSLLdo retransmitthelostpacket; 高速网络传输的瓶颈在于CPU资源不足,在千兆网的环境中,单个UDT流和单个TCP流相比使用更多CPU的资源[8],而在10 Gbit/s带宽的网络环境中,UDT协议将占用更多的CPU资源。由于UDT处理一个数据包代价较高,当CPU的处理速度低于网卡的接收速度,数据包会暂存在缓冲区。在10 Gbit/s高速网络进行大文件传输时会有持续的大数据流量涌入主机,如果缓冲区容量较小,就会发生主机丢包的现象。因此需要适当的增大缓冲区的大小,这也是我们要做系统调优的原因。然而如果我们过度增大缓冲区,就会增大端到端的网络时延,导致bufferbolat[18]的现象出现。 由于UDT协议是单进程的,因而如果我们能够提升单个CPU处理数据包的效率,对使用高速网络传输大数据的性能将会有很大的提升。处理数据包的开销主要包含以下三个方面[16]:系统调用代价、内存拷贝和动态内存分配。由于UDT协议是应用层协议,下层使用的是操作系统的TCP/IP协议栈,netmap和DPDK作为高性能的数据包快速处理架构,可以替代原用操作系统的协议栈达到优化的目的。而在应用层,我们可以通过减少处理数据包的代价进一步降低CPU的占用率。 在进行传输实验的过程中,我们观察CPU的使用情况可以看到其中一个CPU的利用率高达99%,并通过工具获取执行一次文件传输所消耗的时间、花费在用户模式的CPU时间以及内核模式的CPU时间。通过实验我们发现,完成一次大文件传输的用户CPU时间和内核CPU时间比约为1∶8。这表明在内核中执行系统调用所花费的时间占很大比例,因此我们可以降低系统调用时间来减少UDT对数据包处理的代价。 通过跟踪UDT接收端进行文件传输所产生的系统调用情况,发现UDT接收方在运行时有两个线程:一个work线程负责从操作系统内核提供的API接收数据,主要的系统调用是从UDP套接字中读取数据;另一个是主线程,负责将接收到UDT数据包进行分析并将其数据部分写入到文件中,主要的系统调用函数是系统内核提供的写文件操作函数。 UDT接收端有两个比较重要的数据结构,接收环形队列和接收缓冲区。worker线程将从内核接收到的数据包放入接收队列中,这时的数据包是包含UDT的头部信息和数据的。通过分析UDT数据包的头部信息,确定当前数据所在文件的位置,并将数据保存在接收缓冲区中,数据缓冲区的数据是按序存放的,保证了的UDT传输的可靠性。数据从接收队列到接收缓冲区的转移在UDT协议中是指针的赋值操作,没有进行额外的内存拷贝。接收队列是一个环形队列,保证了存储的内存空间可以循环利用,队列空间是事先分配,只有当空间不够时,接收队列的长度才会动态增加,因此,UDT协议的动态内存分配的代价比较小。数据包接收的具体过程如图2所示。 图2 woker线程接收数据包的过程 以Linux环境为例,我们使用strace命令分析UDT接收文件时系统调用的具体过程。表1是我们传输150 MB大小的文件,UDT的两个线程运行时系统调用的分析结果。虽然使用系统调用分析工具会影响传输的速度,但是我们只考虑各个操作所占比例,所以不会对分析结果造成很大的影响。 表1 150 MB文件传输系统调用统计表 如表1所示,UDT接收端每次处理的数据包大小是1 472字节,写入文件大小是1 456字节(去除头部信息)。两个线程最主要的系统调用函数是writev和recvmsg,所占比例分别为99.61%和98.17%,这说明在UDT接收端接收数据包和写文件的操作占用了大部分的系统资源。 假设ni表示每次系统调用写入数据块的大小,ti表示对应每次系统调用的执行时间,则将N字节数据写入文件的总时间T可以表示为: T=(N/ni)×ti 我们比较在不同数据块大小下写入相同数据到文件中所用的时间,如表2所示,写入总字节数为1 456字节×64=93 184字节。 表2 写操作执行时间 从表2中我们可以看到,开始时,随着ni成倍的增长,时间ti增长并不明显,写文件的总时间T下降明显,但当文件块大于11 648字节的时候,写文件总时间没有很大的变化。 每次系统调用的时间ti由两个部分组成:中断响应时间和中断处理时间:ti=interupti+processi,中断响应时间interupti一般是相对固定,而中断处理时间processi则是与所写文件大小相关。 如图3所示,当我们将ni从1 456增长到11 648时,写文件的总时间T明显的下降。这是因为当所写字节数比较少时,中断响应时间所占比例较大,减少中断次数就会有很明显的效果。而当继续增大ni时,总时间T没有很大的变化,这是因为此时中断处理时间占很大比例,中断响应时间的影响可以忽略。 图3 系统调用所写字节数与时间关系 将顺序到达的数据包一起写入到文件中,可以增大每次写文件的数据块,减少写文件的系统调用次数,降低中断响应时间所占比例,提升CPU的利用率。原始UDT接收端在应用层处理数据包时,首先是从队列中找到一个空闲的单元存放数据包。然后再按序放在接收缓冲区中,数据包在物理上存放的位置与到达顺序和空闲单元的位置有关,并不一定是连续的,因此无法将多个数据包合并到一起写入到文件中。 我们提出一个算法可以将连续到达固定数目的数据包连续存储。首先设置FP为每次写入到文件中的最大数据包的个数,并对于每一个环形队列的元素,申请一块连续的内存区域,固定大小为FP×数据包大小。然后,当接收方收到FP个序号连续的数据包,将其存储到环形队列的一个单元中,并通过一次写文件系统调用将数据包写入到文件中。当数据包不是连续到达,即出现了丢包或者重传时,先假设要接收到的数据包是顺序到达,将它临时顺序存放在队列中,然后找到合适的空闲队列存放。数据包存放好之后,会将连续存储的数据区域链接到数据缓冲区中,并记录每个区域有效数据个数,最后将数据缓冲区中的数据写入到文件中。图4显示,当FP=4时,数据包的接收过程,一般而言,在链路条件好的情况下,数据大部分是按序到达接收端的。 图4 FP为4时数据包的接收过程 在UDT协议中,接收端的worker负责将接收到的数据包先暂存在队列中,然后再链接到接收缓存中。在A-UDT中,环形队列的每个单元会有一个标记位,这个标记位用来指示到达的数据包是否是顺序存储的,1表示数据包序号连续,0表示不连续。在处理最新到达的数据包时,先将这个数据包存储在之前接收的数据包后面,之后比较这个数据包的序列号和当前已接收数据包的最新序列号。如果连续,不做操作,如果不连续,将这个数据包重新分配到一块新的固定空间中,将标记位置为0,并将之前连续的存储空间链接到接收缓存区中。 在主线程中,我们会将接收缓存中的数据顺序写入到文件中。首先需要找到标记位为0的位置,这表示连续存储的开始位置,再计算这块连续存储区域的大小,如果后续的数据包标记为1,则将这个数据包的大小加入到总和中。如果后续的数据包是0,则将之前的数据写入到文件中,更新记录的起始位置,并将统计连续数据包大小总和置为0。将数据包放入到接收缓存区的过程描述如算法2所示。 算法2 接收缓冲区接收过程input:aseriesofpackets{Pi}theserverreceived,andtheirse⁃quencenumbersSanddatapartD. aseriesofunitsofthequeue{Ui}andtheircontinuousflagCF thefixedvalueofcontinuouspacketsFP thepriorpacket ssequencenumberstoredinthequeueLRSinitializethecontinuousflagofeveryunitinthequeueforeachunitin{Ui}do Ui.CF=0;foreachpacketPireceivedbyserverdogetNextAvailUnitUiforPi;Ui.CF=1;ifPi.S=LRS+1then UiintosetofContinuousUnits{CUi};ifthesizeof{CUi}==FPthen foreachCUiinthe{CUi}do calculatetheoffsetintheRcvBuffer; addthepointertoRcvBuffer; clear{CUi};else reallocatetheUnitUiforPi; Ui.CF=1; Ui.CF=0; releasetheUi; foreachCUiinthe{CUi}do calculatetheoffsetintheRcvBuffer; addthepointertoRcvBuffer; clear{CUi}andaddUiinto{CUj};LRS=Pi.S 将接收缓冲区的数据包写入文件的过程如算法3所示。 算法3 数据包写入文件input:aseriesofRcvBufferpointerspointingtolocationofpacketunits{RPi}→{Ui}foreachunitin{RPi}do do addRPi?Uito{CUi}; i++; calculatethesumofpacketslengthPL; whileRPi?Ui.CF=1; foreach{{CUi},{CUi+1},…,{CUj}}do findthestartlocationofthispartSP; writeSPtoSP+PLtothefile; clearthe{CUi}; updateSP; setPL==0; 在这个部分,我们将验证A-UDT协议的有效性,评估A-UDT协议在高速网络传输中的传输性能。 实验环境如图5所示。交换机之间的链路带宽是10 Gbit/s的带宽,链路时延为0.3 ms,接收方和发送方的服务器配置是相同的。网卡是BRCM 10 Gbit/s适配器,CPU是Intel Xeon E5-2620系列2.40 GHz,监控服务器所连交换机的端口,做了端口镜像,可以旁路式监控接收方和发送方流进和流出的数据包。服务器安装的系统是CentOS7,内核版本是Linux version 3.10.0。 图5 实验环境拓扑图 通过适当地增加系统缓存大小可以提高UDT传输的性能。在主机端,数据包最先到达网卡,因而,首先增大网卡环形缓冲区大小。然后,增大内核的数据包接收缓冲区,通过测试设置一系列rmem_max的值发现,在当前环境下,当缓冲区大小设置不小于224Byte时,UDT在传输过程中的丢包现象就可以得到有效缓解。最后,在初始化套接字接口时,需要设置UDT接收缓存的大小和UDP接收缓存的大小,并且两个值需要设置为相同,实验表明将其设为108Byte可以满足其需求。 netsniff-ng是一个高性能的网络包分析工具,支持数据包的捕获、过滤和分析,可以用来测试网络的性能和吞吐率。ifpps是netsniff的一个组件,提供Linux内核的网络和系统统计工具。借助上述工具,对使用UDT工具传输5 GB大小文件的过程进行分析,其结果如图6所示。从图6中可以看出,经过系统调优,UDT可以获得更高的吞吐率,并且平均传输速度从2 500 Mbit/s提升至5 000 Mbit/s。 图6 传输5 GB文件系统调优前后对比 这个实验比较了UDT接收端原生的可靠性算法和改进可靠性算法的性能。我们传输了20 GB大小的文件,并且ifpps工具记录不同时刻的传输速率,结果如图7所示。图中结果表明了改进后的可靠性算法,丢包对重传的性能影响更小,传输曲线更加平稳。 图7 增强传输可靠性传输曲线对比 CPU被认为是高速网络传输的瓶颈,UDT协议是应用层的协议,我们采用减少写文件的系统调用次数来优化应用层处理时的CPU利用率。如2.3节所述,增大每次写文件的块大小,每次系统调用代价所占比例就会减小。通过之前的测试,可以看到增大每次写固定大小数据包的个数,可以提高传输的性能。但是如果一直增大,时间并不会有很大改变。另一方面,将很多数据包暂存在缓存队列中,会造成写延迟,也会造成UDT协议回复ACK不及时。通过测试,我们发现当数目为8时,优化效果最佳,且不会浪费额外的缓存空间。 图8显示了UDT在优化前和优化后传输大文件时的稳定速度,表明A-UDT可以实现更高的网络的吞吐率。 图8 提高CPU利用率的传输对比图 本文分析了UDT协议在高速网络中丢包的原因和传输瓶颈并提出了相应的解决方案。通过系统调优,可以看到丢包现象得到缓解传输速度显著提升。另一方面,由于UDT协议的可靠性无法保证及时的二次重传,丢包严重时会导致超时重传,改进的可靠性控制算法平滑了传输曲线,提升了传输速度。 高速网络传输的瓶颈在于CPU,而UDT协议比TCP使用更多CPU资源。A-UDT协议通过减少写文件的系统调用代价提高了CPU使用效率,使得在相同条件下,A-UDT协议实现了更高带宽。 [1] 王元卓, 靳小龙, 程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013, 36(6):1125- 1138. [2] Dart E. The Science DMZ: a network design pattern for data-intensive science[C]// High Performance Computing, Networking, Storage and Analysis. IEEE, 2013:85. [3] Calyam P, Berryman A, Saule E, et al. Wide-area overlay networking to manage science DMZ accelerated flows[C]// International Conference on Computing, Networking and Communications. IEEE, 2014:269- 275. [4] Allcock W, Bresnahan J, Kettimuthu R, et al. The Globus Striped GridFTP Framework and Server[C]// Supercomputing, 2005. Proceedings of the ACM/IEEE SC 2005 Conference. IEEE, 2005:54. [5] Fast Data Transfer: an Application for Efficient Data Transfers[OL]. http://monalisa.cern.ch/FDT/. [6] Jin C, Wei D X, Low S H. FAST TCP: motivation, architecture, algorithms, performance[C]// Joint Conference of the IEEE Computer and Communications Societies. IEEE, 2004,4:2490- 2501. [7] Galbraith J. SSH File Transfer Protocol (SFTP)[OL]. 2006.http://www. ietf. org/internet-drafts-ietf-secsh-fliexfer-12.txt. [8] Gu Y, Grossman R L. UDT: UDP-based data transfer for high-speed wide area networks[M]. Elsevier North-Holland, Inc. 2007. [9] Roskind J. QUIC(Quick UDP Internet Connections): Multiplexed Stream Transport Over UDP[R]. Technical report, Google,2013. [10] Floyd S, Henderson T. The NewReno Modification to TCP’s Fast Recovery Algorithm[J]. Expires, 1999, 345(2):414- 418. [11] Yildirim E, Kim J, Kosar T. How GridFTP Pipelining, Parallelism and Concurrency Work: A Guide for Optimizing Large Dataset Transfers[C]// SC Companion: High Performance Computing, Networking Storage and Analysis. IEEE Computer Society, 2012:506- 515. [12] Yun D, Wu C Q, Rao N S V, et al. Profiling transport performance for big data transfer over dedicated channels[C]// International Conference on Computing, Networking and Communications. IEEE, 2015:858- 862. [13] Yun D, Wu C Q. An Integrated Transport Solution to Big Data Movement in High-Performance Networks[C]// IEEE, International Conference on Network Protocols. IEEE, 2015:460- 462. [14] Yu S Y, Brownlee N, Mahanti A. Comparative performance analysis of high-speed transfer protocols for big data[C]// Local Computer Networks. IEEE, 2013:292- 295. [15] Gallenmuller S, Emmerich P, Wohlfart F, et al. Comparison of frameworks for high-performance packet IO[C]// Eleventh Acm/ieee Symposium on Architectures for Networking & Communications Systems. IEEE, 2015:29- 38. [16] Rizzo L. Netmap: a novel framework for fast packet I/O[C]// Usenix Conference on Technical Conference. USENIX Association, 2012:9- 9. [17] Intel Corporation. Impressive Packet Processing Performance Enables Greater Workload Consolidation[R]. Intel Solution Brief, 2013. [18] Gettys J, Nichols K. Bufferbloat: Dark Buffers in the Internet[J]. IEEE Internet Computing, 2011, 15(3):96.2.2 增强传输可靠性

2.3 提高CPU利用率



3 实验结果与性能评估
3.1 物理实验环境

3.2 系统调优
3.3 增强传输的可靠性
3.4 优化CPU的利用率
4 结 语
