卷积神经网络声学模型的结构优化和加速计算
2018-07-03王智超张鹏远颜永红
王智超,徐 及,张鹏远,颜永红,2
(1.中国科学院 语言声学与内容理解重点实验室,北京 100190;2.中国科学院 新疆理化技术研究所新疆民族语音语言信息处理实验室,乌鲁木齐 830011)
0 前 言
近年来,深度神经网络(deep neutal network, DNN)模型在语音识别领域中的应用带来了识别精度的大幅提升[1-6]。相比于传统的混合高斯模型(Gaussian mixture model, GMM),DNN拥有更出色的信息表达和分类能力,可以对发音状态的后验概率给出更加准确地预测。
神经网络作为一种鉴别性的分类模型,其结构多种多样,其中卷积神经网络(convolutional neural networks, CNN)由于对网络输入特征具有高度的抗形变能力而被广泛应用于在图像识别和计算机视觉领域[7-9]。CNN通常是在网络前端加入一个或者多个卷积结构,每个卷积结构由一个卷积层(convolutional layer)和一个采样层(pooling layer)组成,卷积层和采样层的共同作用使得CNN对输入信号的平移、比例缩放等形变具有高度容忍性。同时,CNN采用权值共享的方式,大大降低了模型参数量。意味着相比于非权值共享网络,卷积神经网络减少了对训练数据量的需求。基于这些优点,CNN逐渐被引入到语音识别领域,在多个英文识别任务中的识别精度都超过DNN[10-13]。
尽管CNN带来了识别精度的提升,但其结构复杂变量多,卷积层数、卷积滤波器个数和参数都会影响其性能,且卷积结构计算慢,不易加速,这些也是将CNN应用于语音识别时所面临的挑战。针对这些问题,本文首先将CNN应用于一个中文大规模连续电话语音识别任务,详细分析了卷积层数、卷积滤波器个数以及滤波器的窗长对识别性能的影响;同时提出了卷积层矢量化的方法对卷积计算进行加速。卷积层矢量化是在结构上对卷积计算进行优化,而不进行任何假设和近似,因此不会造成CNN声学模型在识别精度上的损失,可大大提高CNN的实用性。
1 卷积神经网络
CNN是一种特殊结构的神经网络,由一组或多组卷积层和采样层以及若干全连接层构成[14]。其中的卷积层对输入语音信号进行局部卷积操作,抽取特征信息,用于建模,这种建模方式更加符合语音信号的实际分布特性,因此,可获得比DNN更好的建模效果。
1.1 输入层
CNN应用于声学建模时,其输入层是一个二维语音特征图,如图1所示。纵轴表示频域,以fbank特征为例,该维度为语音信号经时-频变换之后所保留下来的频带数;横轴表示时域,由当前帧与其前后若干帧特征并联构成。由于差分特征可对静态特征进行信息补充,所以在特征图的时域维通常会加入特征的一阶和二阶差分来提高特征图包含的信息量。
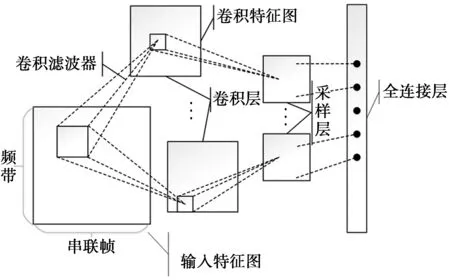
图1 卷积神经网络示意图Fig.1 Diagram of convolutional neural network
1.2 卷积层
图1中,输入层之后是卷积层。卷积层的作用是利用卷积滤波器不断地在输入特征图上沿时间轴和频率轴平移,逐步对语音的各个局部特征进行观察,并通过卷积运算抽取有用的特征信息,得到卷积特征图。卷积运算的过程中共享同一组滤波器参数,可以大大减少网络的参数量。但是一个卷积滤波器的参数有限,所能抽取的信息也较为单一,因此,会使用多个参数不同的卷积滤波器从不同视角上进行观察,得到更加丰富的信息。卷积操作的计算公式为
(1)
(1)式中:hj,k表示第j个卷积滤波器第k次卷积操作后的输出神经元;s表示卷积滤波器窗的大小;wb,j表示第j个滤波器的权值参数;vb+k-1表示第k次卷积的输入特征矢量;aj表示网络偏置;θ(x)是非线性激活函数,本文中采用的是sigmoid函数。
1.3 采样层
语音信号中存在一些局部特性,不同的音素会在不同的频率范围内产生共振峰,反映在频谱图中就是不同音素的能量集中在不同的频带范围中。我们可以通过语音信号的局部频谱特性来区分不同音素,然而背景噪声等环境因素会对音素的频谱能量分布产生影响。同一个音素根据不同的说话人所显现出的发音特性也会不同,甚至同一个说话人在不同的语句中对同一个音素的发音也不同。这些情况导致语音信号的局部特性在一定的频带范围内产生波动,给识别任务增加困难。而CNN中的采样层可以有效地解决这个问题。如图1所示,每个卷积层之后是一个采样层,它会对卷积层的输出进行降采样,采样的方法包括最大值采样、随机采样以及p-范数采样等[15]。本文采用最大值采样,选取采样窗内神经元节点中的最大值作为采样层的输出。通过采样层的处理,可以保证即使一个音素产生的共振峰在一定的频率范围内发生波动,其采样层的输出结果保持不变,有效提高了模型鲁棒性。同时,采样层的存在大大降低了神经元节点的数目,进一步缩小了模型参数量。最大采样函数为
(2)
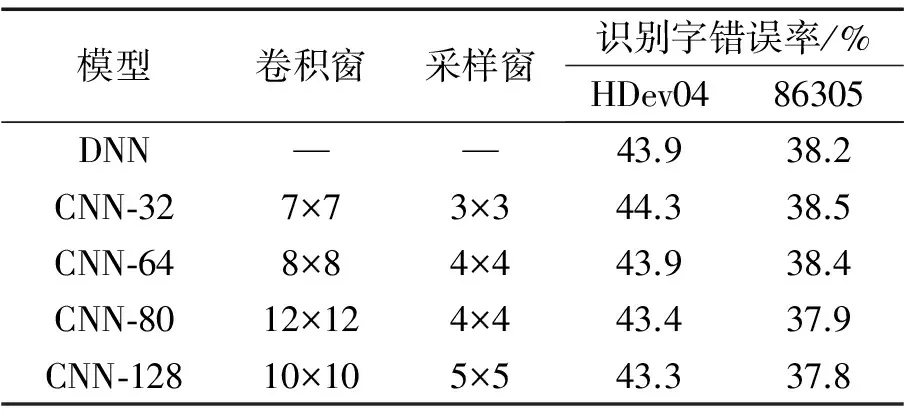
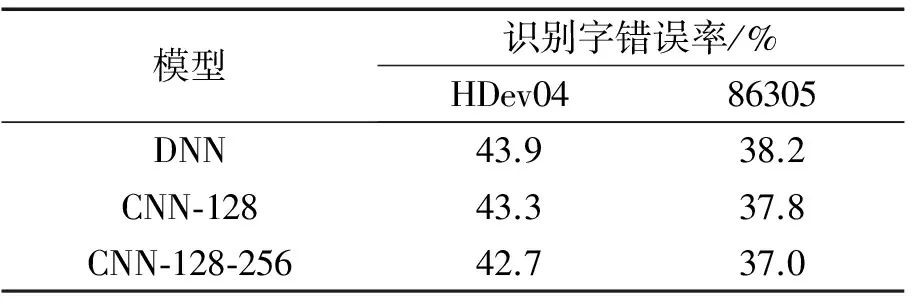
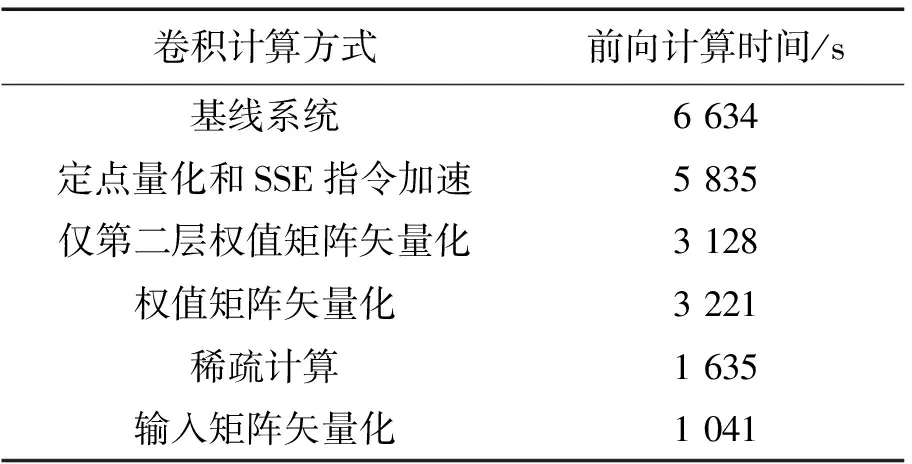
(2)式中:Sj,m是采样层对第j个卷积特征图进行第m次采样后的输出节点;r表示采样窗的大小;n表示采样窗的平移步长;可以通过控制n来调整采样率(n 通过卷积层和采样层的局部信息抽取,我们已经得到了多个相互之间独立的卷积特征图。在采样层之后添加全连接层可以对不同特征图信息进行综合整理,最后通过网络的输出层对特征信息进行分类判决,得到语音特征的后验概率。 神经网络声学模型在语音识别领域的成功应用使得识别准确率得到了显著提高。与此同时,其巨大的运算量导致模型训练周期和解码时间较长,达不到实际的应用需求。因此,如何加速神经网络的计算成为一个热门的研究课题。在文献[16]中详细介绍了对DNN计算进行加速的方法。本文将其中的定点量化和SSE(streaming single instruction multiple data extensions)指令并行计算的加速方法应用于CNN进行加速。 定点量化是将网络各层的输入输出和权重从浮点型变量量化为字符型变量,再结合SSE指令集一次对多个变量进行乘加操作,从而起到加速的效果。但是CNN中特有的卷积运算,其计算过程较为复杂,大大降低了定点量化和SSE指令的加速效率,卷积运算示意图如图2所示。主要原因有2点:①卷积运算过程中需要卷积滤波器在输入特征图上进行不断地平移,导致运算过程中的循环控制成本很高;②与DNN的集成化矩阵乘加运算不同,卷积运算由大量的微型乘加运算组成,而SSE指令集采用16字节对齐的模式进行运算加速,导致在卷积运算过程中产生大量的冗余计算,且卷积运算中的输入在内存中并不是连续存储的,这也降低了SSE指令的读取效率。 图2 卷积运算示意图Fig.2 Diagram of convolution operation 针对上文提到的卷积计算复杂度高的问题,我们对卷积结构进行优化,提出了将卷积层进行矢量化展开的方法对卷积运算进行简化,以提高定点量化和SSE指令对卷积运算的加速效率。卷积层矢量化的目的是将卷积运算转换为全连接矩阵乘法,减少卷积运算过程中循环控制消耗的时间,同时降低SSE指令产生的冗余计算。本文采用了2种方法对卷积层进行矢量化:权值矩阵矢量化和输入矩阵矢量化。 2.2.1 权值矩阵矢量化 权值矩阵矢量化首先将卷积层的输入视为一维向量,然后对卷积滤波器的权值矩阵按照输入向量进行矢量化展开并在相应的位置补零,如图3所示。权值矩阵中的一列对应一次卷积操作的卷积滤波器参数。 通过权值矩阵矢量化可以提高集成化计算程度,减少循环控制操作,提高运算效率。但是从图3中可看出权值矩阵矢量化后会产生大量零权值,导致新的冗余计算产生,矢量化后零权值数量的计算公式为 (3) (3)式中:N0表示零权值数量;NI表示卷积输入向量长度;NW表示卷积滤波器参数量;c表示卷积运算次数。从(3)式中可看出卷积输入向量长度与滤波器参数量之间的差值越大,矢量化后零权值数量越多,新产生的冗余计算量越大,矢量化后的加速效果越差。 图3 权值矩阵矢量化Fig.3 Vectorization of weight matrix 为降低零权值带来的负面效果,我们进一步采用稀疏计算的方式,在运算过程中加设了控制位直接跳过16字节全零的权值,这样可减少部分冗余计算。 2.2.2 输入矩阵矢量化 输入矩阵矢量化是将滤波器权值矩阵视为一维向量,将卷积的输入矩阵按照权值矩阵进行矢量化展开,整理为与权值矩阵相匹配的连续输入,如图4所示。矢量化后输入矩阵的一行代表一次卷积运算的输入。可以看出,输入矩阵矢量化后结构更加紧凑,不增加新的冗余计算,加速效率更高。 图4 输入矩阵矢量化Fig.4 Vectorization of input matrix 由于卷积层的输出神经元节点数量较大,导致激活函数的运算量很大。针对这个问题,考虑到sigmoid激活函数是单调递增函数,在最大采样之后进行激活函数的运算并不影响最终的输出结果,而经过采样后的神经元节点数大大减少了,可以通过激活函数后移的方式来降低激活函数的计算量,进一步起到加速的效果。 在文献[17]中,详细描述了CNN在小规模数据集(TIMIT)和浅层网络结构中(3个隐层)的性能表现。本实验主要研究在汉语大规模数据集和深层结构下卷积层数、滤波器个数和采样窗的大小对CNN性能的影响。实验在汉语普通话大词表非特定人电话自然口语对话识别任务上进行,训练数据为美国语言数据联盟LDC提供的汉语普通话数据:Call-Home和Call-HKUST,共100 h。测试集为2个:其中,测试数据HDev04是由香港大学2004年采集的电话自然口语对话数据,它包含了24个电话对话,全集长度大约4 h。我们从中随机选取出了1 h的数据用于测试。测试数据86305是国家863组织的语音识别评测在2005年的测试集,时长为48 min[18]。识别评判标准为字符错误率CER(character error rate)。CNN的输入特征为39维的filterbank特征,连同其一阶、二阶差分,以及前后各6帧进行拼接,扩展得到39×39的二维输入特征图。网络的输出为6 245个3因子音素状态。对比基线系统为拥有5个全连接隐层结构的DNN,每个隐层2 048个神经元节点。CNN和DNN均采取交叉熵准则进行训练。训练过程中学习率的调整策略为:每一次训练数据迭代完毕后计算开发集的帧正确率,若增幅小于设定阈值(本文为0.5%),则在之后的每次迭代中学习率减半,当开发集上帧正确率的增幅第3次小于设定阈值时停止训练。 3.2.1 CNN与DNN性能对比 表1给出了在一个卷积层和4个全连接隐层的结构下,卷积滤波器个数对CNN模型识别精度的影响,并给出了与基线DNN的识别对比结果。在实验过程中,为了保持CNN与DNN参数量的一致,在调整卷积滤波器个数的同时,会随之调整卷积滤波器和采样窗的大小,全连接层的节点数与基线DNN保持一致,都为2 048。表1中的第一列为模型结构,CNN-32代表卷积层采用32 个卷积滤波器。可以看出,采用一个卷积层的CNN,随着卷积滤波器个数从32逐步增加到80,识别字错误率下降较为显著。这是由于卷积滤波器的权值共享机制在减少参数量的同时也导致了其信息抽取局限性,因此,当卷积滤波器个数较少时,卷积层所抽取的特征信息量不够丰富,以致识别性能不好。在少于64个卷积滤波器时CNN的性能不如基线DNN。另一方面,在卷积滤波器个数由80增加到128时,CNN性能提升不明显。说明卷积滤波器个数在80个时其抽取的信息量已经基本达到饱和,再增加滤波器个数并不能带来明显地识别性能的提高,反而会由于计算量的增加而导致模型训练时间增加。由此看出,选取合适的滤波器个数对于CNN的建模性能具有重要意义。 表1 单卷积层不同滤波器个数的CNN与DNN识别字错误率对比Tab.1 Word error rate comparisons between DNN and CNN with one convolution layer 在单卷积层实验中,最优的CNN结构相比于DNN在识别字错误率上得到平均绝对0.5%的下降,性能提升有限。根据CNN在图像处理中应用的经验,适当增加卷积层数可以提高其性能,因此接下来采用2个卷积层和3个全连接层的CNN结构进行实验,表2 给出了实验对比结果。为保持各模型间参数量的一致,CNN参数配置为第1层采用128个卷积滤波器,窗为7×7,采样窗为3×3;第2层采用256个卷积滤波器,窗为4×4,采样窗为2×2;全连接层仍为每层2 048个节点。结果表明,2个卷积层的CNN得到了最优的识别结果,在2个测试集上相对于基线DNN在识别字错误率上性能稳定的提高了绝对1.2%,表明CNN在中文大数据量下的建模性能要优于DNN。 表2 两卷积层CNN与DNN识别字错误率对比Tab.2 Word error rate comparisons between DNN and CNN with two convolution layer 3.2.2 卷积层矢量化实验 在CNN加速实验中,为突出矢量化方法的加速效果,我们降低了全连接层在整个神经网络中所占的比重。实验采取了2个卷积层和一个全连接层的结构,同时适当减少滤波器的数量,每个卷积层使用64个卷积滤波器,以减少第2卷积层的输出节点,进一步减少全连接的权重数量。第1层卷积滤波器的窗为7×7,采样窗为3×3;第2层卷积滤波器的窗为4×4,采样窗为2×2;全连接层的节点数为1 024。采用上文提到86 305作为测试集,依据在测试集上解码时模型的前向计算时间来评判加速方法的有效性(进行3次解码,取平均时间),表3给出了实验对比结果。 表3 卷积矢量化加速实验结果Tab.3 Experiment results of convolution vectorization 表3中的第1行为本实验的基线系统,采用浮点型和循环方式进行卷积计算,第2行为直接采用定点量化和SSE指令对CNN进行加速的实验结果,网络的前向计算时间相对基线减少799 s,速度提升只有12%,加速效率较低;第3行表示只对第2个卷积层的权值矩阵进行矢量化,第3行表示对2个卷积层的权值矩阵都进行矢量化。可以看出,仅第2个卷积层进行权值矩阵矢量化带来了卷积运算速度的大幅提升,使前向计算时间由5 835 s减少到3 128 s,而对第一个卷积层也进行权值矩阵矢量化后并没有带来卷积运算速度的提升,前向计算时间反而由3 128 s增加到3 221 s。这是由于首层的输入为特征,其维度远大于滤波器权值向量的维度,导致权值矩阵矢量化后新增的零权值过多,产生的量冗余计算抵消了加速效果相,正如我们在第2.2.1节所分析的为降低权值矩阵矢量化产生的冗余计算量,进一步采用稀疏计算的方式提高加速效率。稀疏计算是在调用SSE指令时直接跳过16字节全零的权值。表3中第4行表示采用稀疏计算后,网络的前向计算时间,由3 221 s减少到1 635 s。最终权值矩阵矢量化结合稀疏计算,使卷积计算速度提高至基线系统的4倍。 表3中最后一行表示采用输入矩阵矢量化方法对卷积运算进行加速。由于该方法不产生新的冗余计算,因此,加速效率最高,网络的前向计算速度是基线系统的6.4倍。 3.2.3 激活函数后移 由于卷积层的输出神经元数量较大,经测试发现激活函数运算所消耗的时间已经占据前向计算总时间的近50%。为减少不必要的计算量,采取激活函数后移的方式,在采样层之后进行激活函数计算。表4给出了激活函数后移的实验效果。权值矩阵矢量化结合激活函数后移的方法,网络前向计算时间由1 635 s进一步降至1 241 s;输入矩阵矢量化结合激活函数后移的方法,网络前向计算时间由1 041 s降至653 s。 表4 激活函数后移实验结果Tab.4 Experiment Results of activation backward 本文将卷积神经网络应用于汉语普通话大词表电话自然口语对话识别任务中进行声学建模,分析研究了卷积层数、卷积滤波器个数和参数对于CNN模型性能的影响。最终使得最优结构下的CNN声学模型相比DNN模型在识别字错误率上下降绝对1.2%。针对CNN网络卷积结构计算复杂,常规的定点量化和SSE指令加速效率低的问题,我们提出了2种卷积结构优化的方法:权值矩阵矢量化和输入矩阵矢量化方法来提高卷积运算的效率。最终通过输入矩阵矢量化结合激活函数后移的方法,使得卷积运算速度相比定点量化、SSE指令后再次提高8.9倍。由于卷积结构优化的方法不会改变卷积的运算结果,因此不会对模型带来性能的损失,大大提高了CNN的实用性。 参考文献: [1] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups[J]. Signal Processing Magazine, IEEE, 2012, 29(6): 82-97. [2] DAHL G E, YU D, DENG L, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recogni-tion[J]. IEEE Transactions on Audio, Speech, and Language Processing,2012,20(1):30-42. [3] JAITLY N, NGUYEN P, SENIOR A W, et al. Application of pre-trained deep neural networks to large vocabulary speech recogni-tion[C]//International Speech Communication Association. Portland, USA: IEEE, 2012: 2578-2581. [4] SAINATH T N, KINGSBURY B, RAMA-BHADRAN B, et al. Making deep belief networks effective for large vocabulary continuous speech recognition[C]//IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). Hawaii: IEEE, 2011: 30-35. [5] GRAVE A, MOHAMED A, HINTON G. Speech recognition with deep recurrent neural networks[C]//IEEE International conference on Acoustics, speech and signal processing.Vancouver,Canada:IEEE,2013:6645-6649. [6] SCHMIDHUBER J. Deep learning in neural networks: An overview[J]. Neural Networks, 2015, 61(1): 85-117. [7] ALAM M M, PATIL P, HAGAN M T, et al. A computational model for predicting local distortion visibility via convolutional neural network trained on natural scenes[C]//IEEE International Conference on Image Processing (ICIP). Quebec, Canada: IEEE, 2015: 3967-3971. [8] KAINZ P, PFEIFFER M, URSCHLER M. Semantic segmentation of colon glands with deep convolutional neural networks and total variation segmentation[OL]. (2015-11-21) [2016-11-14]. http://arxiv.org/abs/1511.06919. [9] TAIGMAN Y, YANG M, RANZATO M A, et al. Deepface: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE pree, 2014: 1701-1708. [10] ABDEL-HAMID O, MOHAMED A, JIANG H, et al. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Kyoto, Japan: IEEE, 2012: 4277-4280. [11] SAINATH T N, MOHAMED A, KING-SBURY B, et al. Deep convolutional neural networks for LVCSR[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Vancouver, Canada: IEEE, 2013: 8614-8618. [12] SERCU T, PUHRSCH C, KINGSBURY B, et al. Very deep multilingual convolutional neural networks for LVCSR[OL]. (2016-01-23) [2016-11-14]. http://arxiv.org/abs/1509.08967. [13] SAINATH T N, KINGSBURY B, SAON G, et al. Deep convolutional neural networks for large-scale speech tasks[J]. Neural Networks, 2015, 64(1): 39-48. [14] LECUN Y, BENGIO Y. Convolutional networks for images, speech, and time series[J]. The handbook of brain theory and neural networks, 1995, 3361(10): 255-258. [15] SAINATH T N, KINGSBURY B, MOHAMED A, et al. Improvements to deep convolutional neural networks for LVCSR[C]//IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). Olomouc, Czech Republic: IEEE, 2013: 315-320. [16] VANHOUCKE V, SENIOR A, MAO M Z, et al. Improving the speed of neural networks on CPUs[C]//Deep Learning and Unsupervised Feature Learning NIPS Workshop. Granada, Spain: IEEE, 2011, 1. [17] 张晴晴,刘勇,潘接林,等.基于卷积神经网络的连续语音识别[J].工程科学学报,2015,37(9):1212-1217. ZHANG Qingqing, LIU Yong, PAN Jielin, et al. Research on continuous Speech Recognition by Convolutional neural networks[J]. Chinese Journal of Engineering, 2015, 37(9): 1212-1217. [18] ZHANG Qingqing, CAI Shang, PAN Jielin, et al. Improved acoustic models for conversational telephone speech Recognition[C]//International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery. Chongqing, China: IEEE, 2012.2 CNN的结构优化和加速计算
2.1 神经网络的加速计算
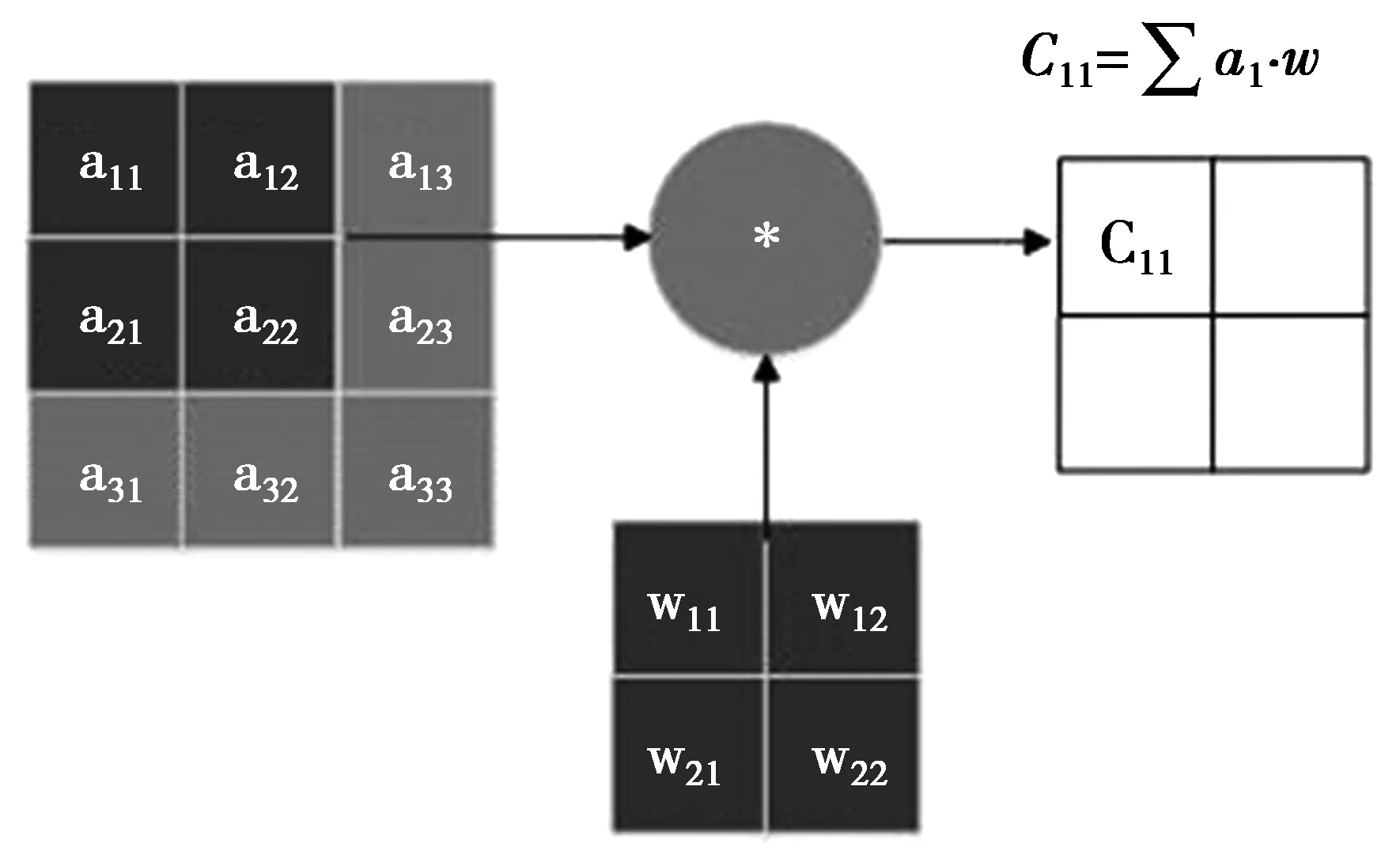
2.2 卷积结构优化
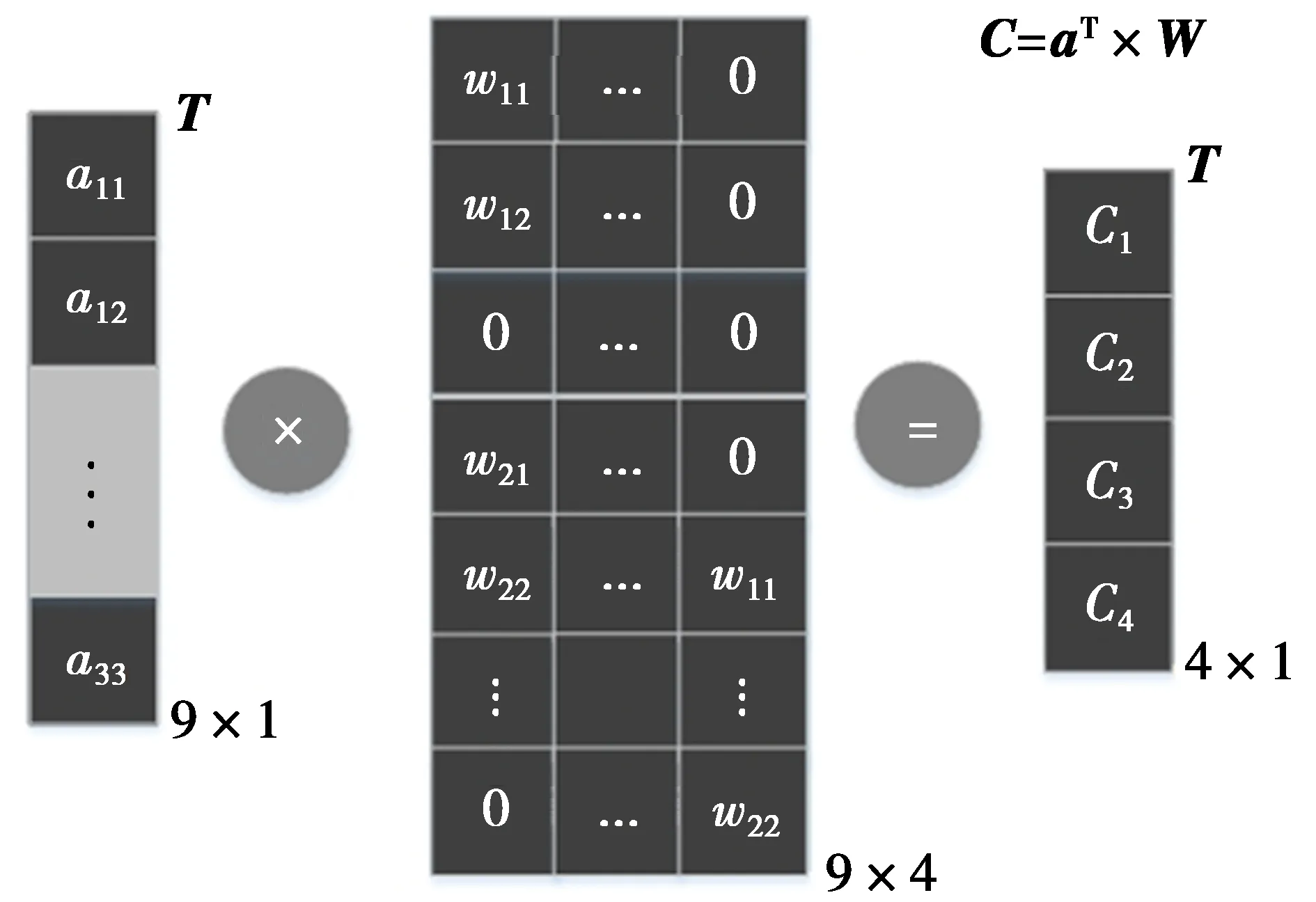
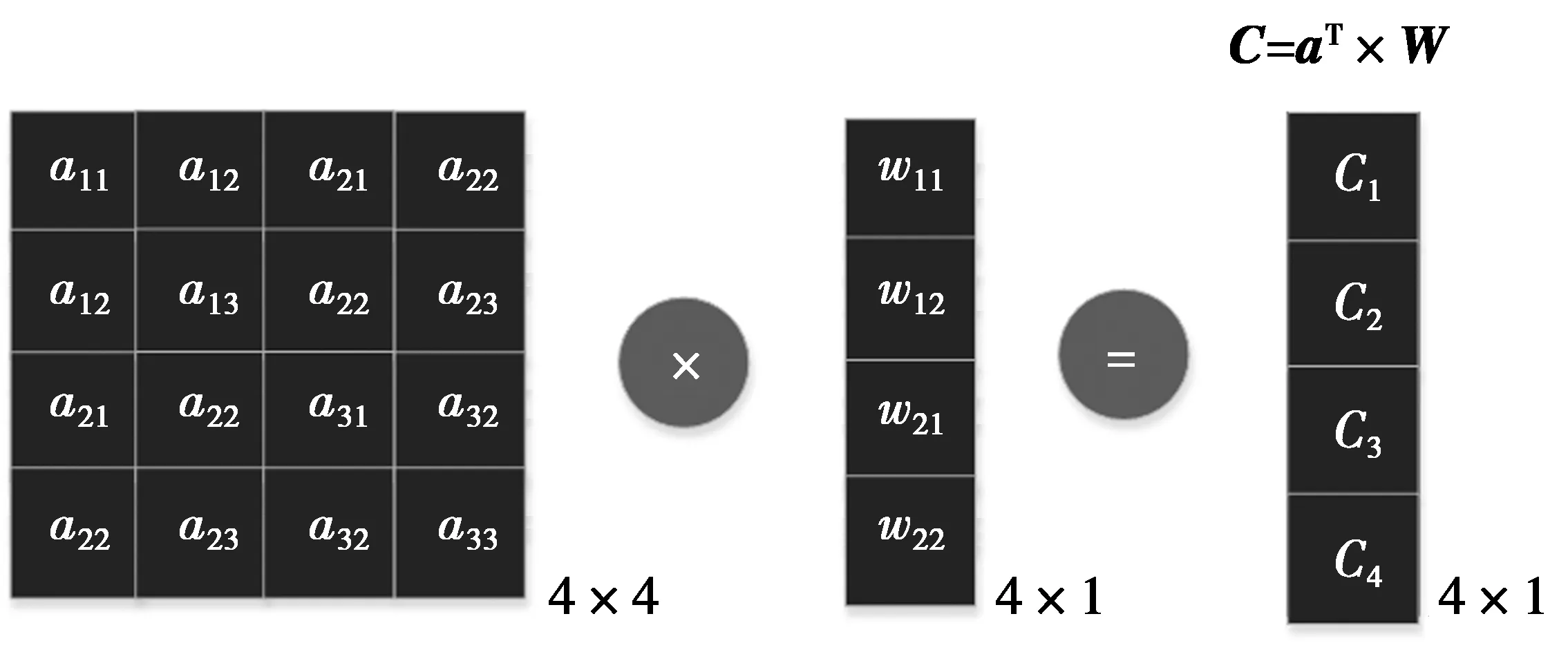
2.3 激活函数后移
3 实验与分析
3.1 实验条件
3.2 实验结果

4 结束语
