基于RFID位置语义的室内移动轨迹聚类算法
2018-07-03裴海英
夏 英,杨 雪,张 旭,裴海英
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
随着城镇化和信息化建设的不断推进,人们在室内空间的活动更加频繁和丰富,由于非视距传播、多径传播等因素的影响,传统的GPS定位技术已不能提供高质量的室内位置服务[1],但无线射频识别(radio frequency identification,RFID)、蓝牙、WiFi等室内定位技术的发展,使人们在室内的轨迹信息可以被及时、准确地获取。聚类作为一种重要的轨迹分析方法,旨在将有相似行为的移动轨迹划分成在同一个簇中,是室内热点分析、移动模式分析、空间布局优化、个性化路线推荐等信息服务的基础。
由于室内环境在空间结构、定位技术、距离度量、位置语义等方面的特殊性,室内轨迹聚类分析具有一定的挑战,但也取得了一系列成果。文献[2]基于室内指纹定位采集的数据,提出一种k-medians算法,该算法根据对数高斯距离度量标准选择各簇的中心点,以各簇的某个子集为搜索范围,找到数据的近似中值进行聚类。文献[3]针对室内移动轨迹提出了时空偏移的概念,使用动态时间归整(dynamic time warping,DTW)算法评价轨迹相似性时引入空间衰减因子,并在此基础上建立时空图进行轨迹聚类。文献[4]以室内RFID轨迹的时间维度和当前轨迹点的下一个位置为特征划分轨迹子簇,直到子簇中的轨迹长度满足阈值MAX_DEPTH,并结合(ordering points to identify the clustering structure,OPTICS)算法的聚类规则,剔除轨迹中的噪音数据。文献[5]提出改进的凝聚型层次聚类(agglomerative nesting,AGNES)算法,计算轨迹位置的曼哈顿距离,并考虑室内轨迹的时间、距离属性和空间拓扑关系,使得聚簇更加精确。文献[6]将移动对象的空间位置轨迹转化成语义轨迹,并提取代表移动对象运动行为的停留位置序列,对具有相似行为的轨迹进行全链接层次聚类,同时挖掘出每个聚类的地理模式集。
目前RFID定位技术在商业服务、公共安全等诸多领域得到了广泛应用,它是一种结合自动识别功能的短距离通信技术,通常由读写器、电子标签和数据管理系统组成,利用固定的阅读器读取进入其感应范围内的移动标签信息,从而识别并定位移动对象,具有成本低、应用简便、易于集成等优点[7]。本文为了提高室内轨迹聚类的准确性和效率,结合室内空间结构和RFID位置记录特征,提出一种基于RFID位置语义的室内移动轨迹聚类方法(indoor trajectory clustering based on RFID location semantics,ITCRLS)。该方法首先通过检测室内轨迹特征点来简化轨迹,然后从轨迹空间相似度和语义相似度2个方面综合度量轨迹相似性,最后对相似轨迹进行层次聚类。
1 相关定义
结合室内空间结构及移动对象的室内运动行为,对相关概念做如下定义。
定义1(室内空间要素[8])室内空间是三维的,由楼栋、楼层、房间、墙体、门窗、通道等多种要素组成。其中,室内通道描述了楼层内和楼层间用于连接的公用空间,反映楼层内多要素之间和楼层间的可达关系,如走廊、电梯、楼梯等。
定义2(室内位置)移动对象的室内位置pi采用三维坐标表示,即
定义3(RFID位置记录[8])RFID阅读器固定部署在室内空间,当携带电子标签的移动对象进入其覆盖范围时将产生位置记录。RFID位置记录为
定义4(室内停留位置)移动对象在位置pi的停留时间pi.staytime可根据RFID阅读器检测到的到达时间ts和离开时间te计算,若超过预先设定的时间阈值δt,则pi可视作室内停留位置。
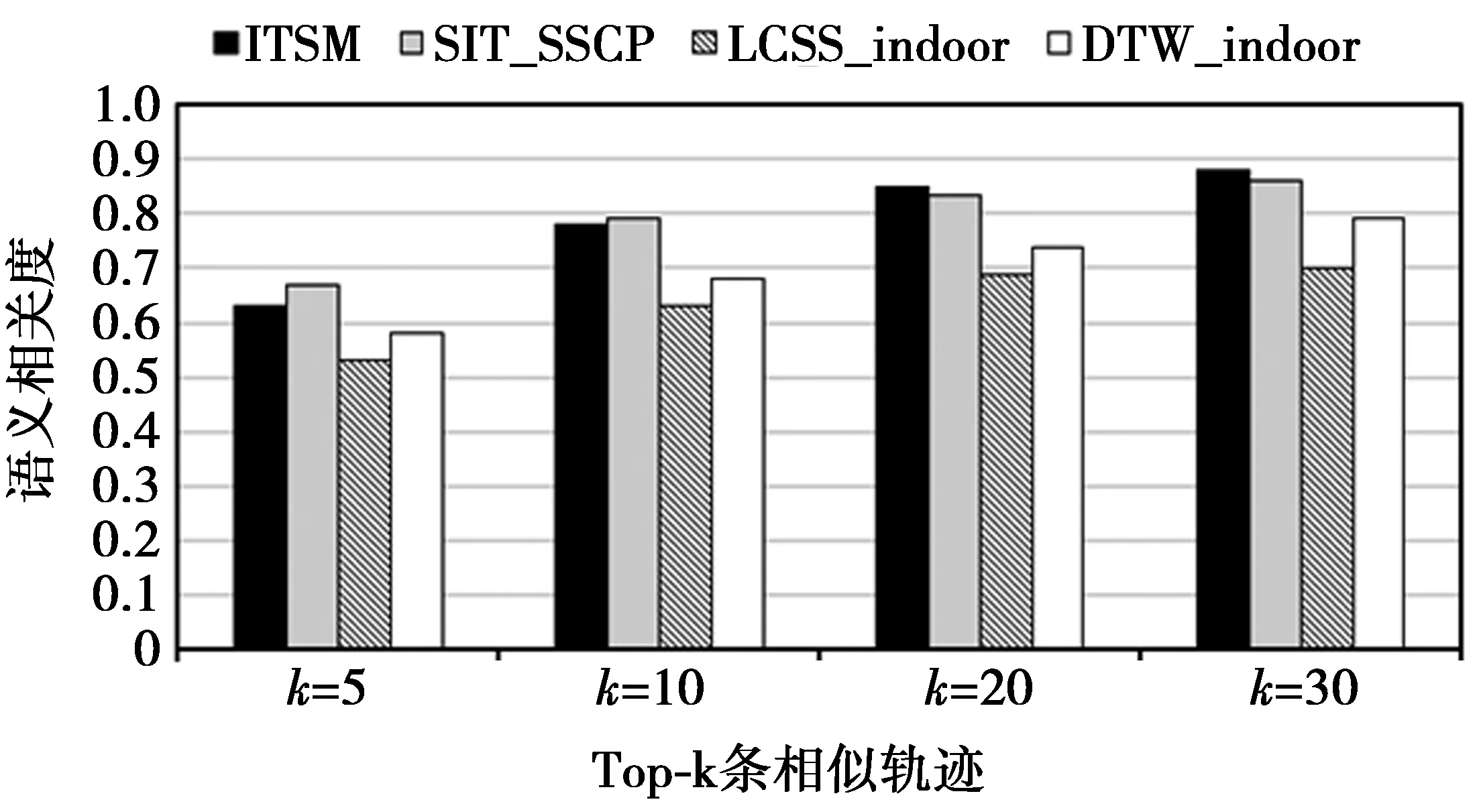
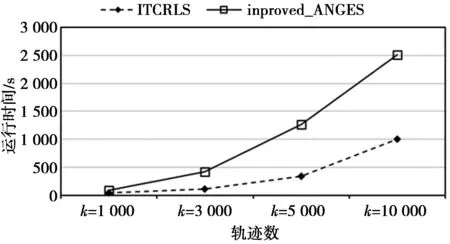
定义5(移动轨迹)某移动对象的室内位置序列,即TR={ 定义6(室内语义轨迹)通过RFID阅读器所在位置的语义信息,可确定pi的语义标签labeli。通过在移动轨迹基础上增加各位置的语义标签形成室内语义轨迹,即TRS={ 定义7(位置语义相关度)已知室内位置pi和pj的语义标签,则pi和pj的位置语义相关度为loc_E(pi,pj),具体取值可由应用者自行定义。比如,若2个位置语义标签完全相同(如均为楼梯)则取值为1,若属于同一类型(如不同品牌的运动类服装店)则取值为0.5,完全不同则取值为0。 定义9(特征点)当室内位置pi满足以下任意一个条件时可记为语义轨迹TRS的一个特征点。 1)pi是TRS的初始位置或者结束位置; 2)pi位于室内通道内; 3)角度偏移Api大于阈值θ; 4)pi是室内停留位置,体现了移动对象对该位置的关注程度[10]。 定义10(相似度线性表)存储室内语义轨迹簇间相似度的有限序列,即线性表Ltable={x1,x2,…,xn},其中,每个元素xi= 轨迹相似性度量即选择合适的算法衡量多条轨迹之间的相似程度,是实现轨迹聚类的基础。为了在保持轨迹特征的前提下提高轨迹相似度的计算效率,首先根据定义9提取轨迹中的特征点,然后计算轨迹空间相似度,再结合移动对象的到达时间和停留时间计算轨迹语义相似度,并将两者进行加权求和。将此方法命名为ITSM(indoor trajectory similarity measurement)。 假设2条室内语义轨迹分别为trs1和trs2,其轨迹相似度计算为 Sim(trs1,trs2)=α*spaSim(trs1,trs2)+ (1-α)*semSim(trs1,trs2) (1) (1)式中:spaSim(trs1,trs2)表示轨迹的空间相似度;semSim(trs1,trs2)表示轨迹的语义相似度;α为影响权重。当α取值为0.5时,表示空间距离和语义2个因素在轨迹相似性度量时的影响程度一致。 每条轨迹邻接的2个特征点可以构成线段,由此室内轨迹便可以表示为多个线段构成的有序序列。本文引入文献[11]提出的二维线段相似性度量算法,并定义室内空间距离函数,使其适用于室内三维空间。 假设在室内空间 2)水平距离:d‖=(L‖1,L‖2) 3)高度距离:dh=h 其中,dh可根据轨迹线段所在的楼层差计算,计算室内轨迹线段间的距离函数为:dist(Li,Lj)=ω⊥×d⊥+ω‖×d‖+ωh×dh+ωθ×dθ,函数中ω⊥,ω‖,ωh,ωθ4个参数可根据真实室内场景取值。本文中将参数设置为等值,该函数考虑了线段的长度和方向,能够准确反映线段间的差异。 图1 线段的室内距离图示Fig.1 Illustration of the indoor distance between line segments 实数代价编辑距离(edit distance on real sequence,EDR)是计算轨迹相似度的经典方法。本文结合RFID位置记录的数据特征,采用改进的EDR方法计算轨迹相似度,如(2)式所示。该方法既适用于采样间隔不等、长度不一致的轨迹数据,又对由于传感器故障引起的轨迹噪声有较好的鲁棒性。 DisTR(tra1,tra2)= (2) (2)式计算了2条轨迹tra1和tra2的室内距离DisTR(tra1,tra2)。假设轨迹经过特征点检测后的长度分别为|tra1|和|tra2|,tra(i)表示轨迹tra的第i个线段,Rest(tra)表示tra移除第一个线段后的轨迹。由于分析长度变化范围较大的轨迹时,容易使长轨迹之间的距离远大于短轨迹之间的距离,这对于发现具有相似移动行为的轨迹是不合理的,因此需要对室内距离DisTR(tra1,tra2)进行归一化,并通过(3)式得到2个轨迹的空间相似度。轨迹间的室内距离越小,其相似度越高。 (3) 室内轨迹中引入位置语义标签[12],能够更全面地反映用户的室内运动模式。通过RFID位置记录和室内停留位置分析,可以得到室内语义轨迹并反映出移动对象到达某位置的时间和停留时间。如果2个移动对象在相近的时间范围内产生了相似的室内语义轨迹,则2条轨迹具有较高的语义相似度。因此,考虑基于移动对象到达时间和停留时间进行室内轨迹的语义相似性分析。 语义行为模式之间的相似性与其之间的公共子序列相关,该子序列的长度代表了语义轨迹间的相似程度。室内语义轨迹不仅有语义标签的信息,还具有同样重要的时间信息。因此,本文基于最长公共子序列(longest common subsequence,LCSS)的方法做了改进,将室内语义轨迹的到达时间和停留时间考虑到相似度计算中。假设a和b分别为2条室内语义轨迹,它们基于时间信息的最长公共子序列的长度记作ISLCSS(a,b),其计算公式为 ISLCSS(a,b)= (4) (4)式中:|a|表示轨迹的语义位置数;Rest(a)表示序列a移除第一个语义位置;ai是第i个语义位置;TFai,bj(ts,staytime)是一个时间因子,由位置ai和bj的到达时间ts和停留时间staytime计算,如(5)式所示,其中,系数λ取值为0.5,表示到达时间和停留时间对于ISLCSS值计算的影响程度相同。可以看出当轨迹位置在语义、到达时间和停留时间都相等时,TFai,bj(ts,staytime)值为1,表示该语义位置为2条轨迹的公共位置。 TFai,bj(ts,staytime)=λ× (5) 在(4)式的基础上,通过ISLCSS值与较小的轨迹长度的比值计算轨迹的语义相似性,即 (6) (6)式中,semSim(a,b)取值为[0,1],其值越大表示2条轨迹在语义方面越相似。 ITSM算法的有效性分析主要分为空间相似性分析和语义相似性分析。随机选取Q条移动轨迹作为查询轨迹,对于每条查询轨迹q采用top-k(k=5,10,20,30)的方式筛选出与其相似度最高的轨迹集合,记为R={r1,r2,…,rk}。 2.3.1 空间相似性分析 采用空间距离度量方法计算返回的k条轨迹与查询轨迹的平均室内距离。平均距离越小表示返回轨迹与查询轨迹在空间距离上越接近,算法在空间相似度计算方面的表现越好。计算公式为 (7) 2.3.2 语义相似性分析 CG(cumulative gain)[13]方法常用于信息检索领域,用于评价检索结果的相关性。采用该方法计算每条返回轨迹与查询轨迹的语义相关度,即 (8) (8)式中,loc_E(rj,qj)用于计算2条轨迹第j个位置语义的相关度。轨迹间的语义相关度Sem_rel(r,q)需要进行归一化处理,最后取k条返回轨迹与查询轨迹的语义相关度的平均值,取值为[0,1],其值越高,表示返回轨迹与查询轨迹在语义上越接近,算法的语义相似度计算效果越好。 层次聚类算法可排除噪声点的干扰,适用于形状不规则、规模差异大的室内轨迹。完成室内轨迹特征点检测和轨迹相似性度量之后,即可对具有相似运动模式的用户进行层次聚类。 常见的凝聚型层次聚类算法(如AGNES)先将每条轨迹看做单独的簇,计算簇之间的距离并存储在矩阵中,选择距离最近的2个簇进行聚类操作,再更新矩阵重复上述步骤,直到满足终止条件。为了减少计算复杂度,ITCRLS算法根据定义10将语义轨迹簇间的相似度以 算法1ITCRLS算法。 输入:室内语义轨迹集TR={tra1,tra2,…,tran},簇间相似度阈值threshold; 输出:室内轨迹簇集TC={TC1,TC2,…,TCn}; 步骤: 1.TC←TR//初始化每条轨迹为一个簇 2.maxsim←0//maxsim初始化 3.fori←1ton 4.forj←i+1ton 5.ε←CalTrackSimilarity(TCi,TCj) 6.cr←TCiandcs←TCj 7.Ltable← 8.endfor 9.endfor 10.do{ 11.fork←1to|Ltable|//线性表长度为|Ltable| 12.if(Ltablek.ε>threshold)do 13.Ltablek.cr←Ltablek.cr∪ Ltablek.cs//合并簇 14.deleteLtablek.csthenupdateLtable 15.endif 16.if(Ltablek.ε>maxsim)then 17.maxsim←Ltablek.ε 18.endif 19. }whilemaxsim>threshold//聚类终止条件 20.returnTC 算法中函数CalTrackSimilarity(TCi,TCj)用于计算簇TCi和簇TCj的相似度,参数maxsim用于保存相似度的最大值。计算2个簇之间的相似度时,若每个簇为一个轨迹集,为了消除异常值对聚类的干扰,簇间相似度计算将采用average-linkage思想[14],即计算簇间两两轨迹的相似度并取其中值。假设对n条室内语义轨迹聚类,ITCRLS算法每次聚类操作完成了多个簇的合并,而不仅仅选择相似度最大的2个簇进行聚类,若平均每次合并t个簇,共聚类次数为n/t,其时间复杂度为Ο(n2/t)。 聚类过程中将利用(1)式计算轨迹间的相似度,其值大于设定阈值则为相似轨迹,应归为一簇。为了反映聚类效果,本文选取精确度(precision)、召回率(recall)和F-measure作为聚类质量评价指标。准确率和召回率根据TP,FP和FN计算[15],即precision=TP/(TP+FP),recall=TP/(TP+FN),其中,TP表示同簇中的相似轨迹数,FP表示同簇中的非相似轨迹数,FN表示未正确聚类的相似轨迹数。F-measure是precision和racall的加权调和平均值,计算如(9)式所示,其取值为[0,1]。 (9) 本文采用的实验环境为2.30 GHz CPU,8.0 GB内存,Windows7操作系统,java语言,Eclipse环境。实验数据集使用室内移动轨迹生成工具IndoorSTG[16-17]模拟生成,模拟的室内环境来源于真实商场,共6层楼,94个室内要素。原始数据格式为(ID,Read_ID,Move_ID,EnterTime,LeaveTime),表示移动对象Move_ID在EnterTime时刻进入阅读器Read_ID的感应范围,LeaveTime时刻离开。实验分别模拟了50,250,500,1 000个移动对象在20天之内产生的RFID移动轨迹数据,轨迹数目分别为1 000,5 000,10 000以及20 000条,并对原始轨迹进行了语义扩充和室内空间位置的标注。 1)为了验证轨迹相似度计算的有效性,将ITSM算法与文献[9]同样计算室内语义轨迹相似度的SIT_SSCP,LSCC_indoor DTW_indoor算法进行对比,设参数α为0.5,停留时间阈值δt为10 min,角度偏移阈值θ为45°,实验随机选取100条移动轨迹作为查询轨迹。 ITSM算法与对比算法在室内空间距离和语义相关性的分析结果分别如图2、图3所示。 从图2中可以看出,ITSM方法的平均室内空间距离明显小于传统算法,说明返回的相似轨迹在空间距离上与查询轨迹更接近,这是因为ITSM充分考虑了室内空间特征并计算轨迹间的室内距离。同时随着返回轨迹数量的增加,ITSM也能表现出较好的优势,因为定义的空间距离函数采用了改进的EDR方法,减少了轨迹中异常位置点的影响。从图3中可以看出,ITSM的轨迹语义相关度高于对比算法。ITSM算法描述了轨迹位置间的语义关系,并考虑了移动对象的停留时间和到达时间,使得查询结果更精确。 图2 平均室内空间距离对比Fig.2 Comparison of average indoor spatial distance 图3 轨迹语义相关度对比Fig.3 Comparison of trajectory semantic relevancy 2)为了分析室内轨迹聚类质量,将ITCRLS算法与文献[5]中基于室内环境的improved_ANGES算法进行对比,设簇间相似度阈值threshold为0.7,α取值为0.5,实验结果如图4所示。 图4 聚类算法的性能对比Fig.4 Comparison of clustering algorithm performance 由图4可见,ITCRLS算法的精确度、召回率和F-measure指标均高于对比算法。improved_ANGES算法采用曼哈顿距离处理符号化轨迹数据,并需要预先设定聚类的簇数,而ITCRLS算法通过分析轨迹的语义相似性能够获得更好的聚类效果。 此外,图5表明ITCRLS算法在运行时间方面也得到了较大改善。这是因为ITCRLS算法通过特征点检测简化了原始轨迹,并采用线性表存储轨迹相似度,从而降低了计算复杂度。而improved_ANGES算法采用相似矩阵存储数据,需要消耗更多的存储空间和计算时间。 图5 聚类运行时间对比Fig.5 Comparison of clustering runtime 室内轨迹聚类有利于发现室内热点和用户移动模式。本文通过分析室内空间结构及RFID位置语义特征,提出了一种室内移动轨迹聚类方法。该方法首先通过轨迹特征点检测简化原始轨迹,减小后续的计算复杂度。其次,综合考虑室内轨迹在空间特征、到达时间和停留时间等位置语义,可以提高轨迹相似度计算的准确性。在此基础上采用改进的层次聚类方法对移动轨迹进行聚类。实验结果表明,该方法能有效评价室内轨迹的相似性,提高了聚类质量和效率。 参考文献: [1] 夏英,王磊,刘兆宏.基于无线局域网接收信号强度分析的混合室内定位方法[J].重庆邮电大学学报:自然科学版,2012, 24(2): 217-221. XIA Ying, WANG Lei, LIU Zhaohong. Hybrid indoor positioning method based on WLAN RSS analysis[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2012, 24(2): 217-221. [2] CAMPOS R S, LOVISOLO L, CAMPOS M L R D. Wi-Fi multi-floor indoor positioning considering architectural aspects and controlled computational complexity[J]. Expert Systems with Applications, 2014, 41(14): 6211-6223. [3] HUNG C C, PENG W C, LEE W C. Clustering and aggregating clues of trajectories for mining trajectory patterns and routes[J].The VLDB Journal,2015,24(2):169-192. [4] WU Y, SHEN H, SHENG Q Z. A cloud-friendly RFID trajectory clustering algorithm in uncertain environments[J]. IEEE Transactions on Parallel & Distributed Systems, 2015, 26(8): 2075-2088. [5] HUANG W Q, DING C, WANG S Y. An efficient clustering mining algorithm for indoor moving target trajectory based on the improved AGNES[C]//Proceedings of the 2015 IEEE Trustcom.Washington:IEEE,2015:1318-1323. [6] 黄健斌,张盼盼,皇甫学军,等.融合语义特征的移动对象轨迹预测方法[J].计算机研究与发展, 2014, 51(1): 76-87. HUANG Jianbin, ZHANG Panpan, Huang Fuxuejun, et al. A trajectory approach for mobile objects by combining semantic features[J]. Journal of Computer Research and Development, 2014, 51(1): 76-87. [7] 王斌,何佳佳,孔祥吉.一种新型宽带圆极化UHF RFID读写天线[J].重庆邮电大学学报:自然科学版,2015, 27(5): 620-625. WANG Bin, HE Jiajia, KONG Xiangji. Novel circular polarization planar broadband antenna for UHF RFID applications[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition,2015, 27(5): 620-625. [8] 金培权,汪娜,张晓翔,等.面向室内空间的移动对象数据管理[J].计算机学报,2015,38(9): 1777-1795. JIN Peiquan, WANG Na, ZHANG Xiaoxiang, et al. Moving object data management for indoor spaces[J]. Journal of Computers, 2015,38(9): 1777-1795. [9] JIN P,CUI T,WANG Q,et al.Effective similarity search on indoor moving-object trajectories[M].Berlin:Database Systems for Advanced Applications,2016:181-197. [10] 夏英,温海平,张旭.基于轨迹聚类的热点分析方法[J].重庆邮电大学学报:自然科学版,2011, 23(5): 602-606. XIA Ying, WEN Haiping, ZHANG Xu. Hot route analysis method based on trajectory clustering[J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2011, 23(5): 602-606. [11] SKOUMAS G, SKOUTAS D, VLACHAKI A. Efficient identification and approximation of k-nearest moving neighbors [C]//ACM Sigspatial International Conference on Advances in Geographic Information Systems. New York: ACM, 2013: 264-273. [12] XU Y, LI G, XUE C, et al. Affinity-based human mobility pattern for improved region function discovering[J]. Journal of China Universities of Posts and Tele- communications, 2016, 23(1): 60-67. [13] MANNING C D, RAGHAVAN P. An introduction to information retrieval[J]. Journal of the American Society For Information Science & Technology, 2008, 43(3): 824-825. [14] FOUEDJIO F. A hierarchical clustering method for multivariate geostatistical data[J]. Spatial Statistics, 2016, 18(17): 179-198. [15] YEH C C, YANG M S. Evaluation measures for cluster ensembles based on a fuzzy generalized Rand index[J]. Applied Soft Computing, 2017, 57(9): 225-234. [16] HUANG C, JIN P, WANG H, et al. IndoorSTG: A Flexible Tool to Generate Trajectory Data for Indoor Moving Objects[C]//IEEE International Conference on Mobile Data Management. Washington: IEEE, 2013: 341-343. [17] JIN P, DU J, HUANG C, et al. Detecting Hotspots from Trajectory Data in Indoor Space[C]//International Conference on Database Systems for Advanced Applications. Berlin: Springer International Publishing, 2015: 209-225.
2 轨迹相似性度量
2.1 空间相似性度量

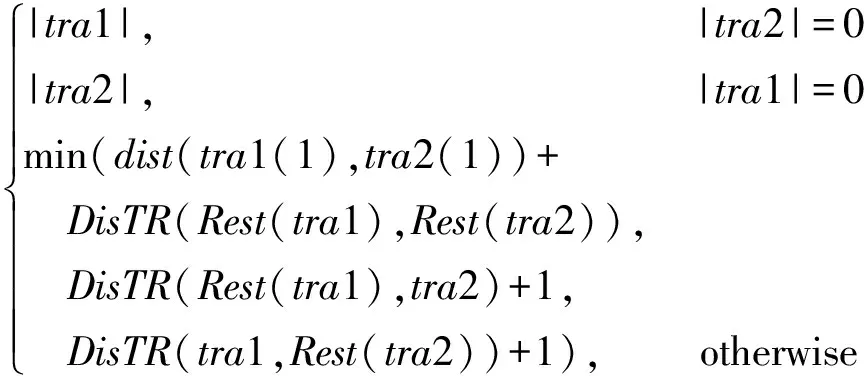
2.2 语义相似性度量
2.3 轨迹相似度计算的有效性分析
3 轨迹聚类
3.1 改进算法描述
3.2 轨迹聚类质量评价指标
4 实验分析
4.1 实验数据集
4.2 实验结果对比


5 结束语
