基于大数据技术和特征推荐的就业信息管理平台的设计
2018-06-28李俊成黄晗文
李 健,杨 幸,李俊成,黄晗文
(湖南工业职业技术学院信息工程学院,湖南 长沙 410208)
0 引 言
2018年,全国普通高校毕业生人数将达到820万人,创历年新高,就业工作面临复杂严峻的形势,其中高职院校毕业生占近40%。高职院校是以就业为导向的高等教育,其办学宗旨是培养生产建设和服务管理第一线所需的高素质劳动者和技术技能人才。因此,学生的就业工作在高职院校各项工作中处于重要地位,就业率、就业质量直接关系到学生的前途和发展,也影响学校的发展和声誉。就业工作涉及政府、企业、学校、学生等各个方面,并且具有较强的政策性、时效性、服务性和个性化特征,如何加强各方面的联系,及时获取大量的就业信息,针对学生的个体就业需求,进行就业信息的精准推送和就业服务的个性化指导,具有重要意义。本文拟利用信息技术手段,构造一个基于就业需求特征推荐的就业信息管理平台,创新就业管理模式、就业管理机制、就业管理载体和就业服务手段,实现就业管理的科学化、规范化、信息化和智能化。本文主要利用网络爬虫技术对典型人才招聘平台进行特征信息获取,获取就业信息的大数据,根据学生就业需求特征参数,利用推荐算法,对就业信息有效推送,最大可能满足个性化需求,提高就业服务质量。
1 平台功能及架构
1.1 平台功能
根据就业信息管理平台涉及的用户和流程,平台具有基础信息管理、用户权限管理、毕业生信息管理、招聘企业管理、就业指导信息管理、就业状态统计、就业情况调查、平台基本设置、就业信息特征参数设置、就业信息爬取、简历撰写、求职意向(求职特征)管理、职位推荐、求职登记、网络在线求职、企业注册、招聘岗位管理、网络在线招聘等功能。
1.2 平台功能架构
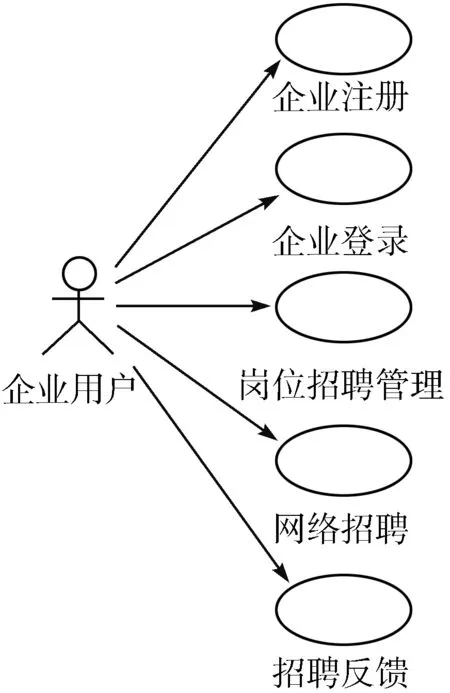
图1 企业子系统用例图

图2 学生子系统用例图
就业信息管理平台作为联系政府、企业、学生、学校的纽带,必须具备信息的充分共享、实时传送、分类管理的功能,从企业、学校、学生的需求角度出发,满足员工招聘、人才推荐和服务、就业求职等核心功能,平台分为企业、学生、学校3个子系统,企业、学生子系统的用例图分别如图1和图2所示。本平台中学校作为就业管理的主体,要同时为企业和学生服务,其具有的功能较多,采用分层用例图进行描述,其顶层用例图如图3所示,学校子系统中职位数据管理用例的子层用例图如图4所示。

图3 学校子系统顶层用例图

图4 职位数据管理模块子层用例图
企业子系统主要满足企业员工招聘的功能需求,主要包括企业注册、登录、招聘岗位发布、网络招聘(求职资格审查、在线面试、在线测试)、招聘结果反馈等功能。其中企业注册,需要根据教育主管部门的相关文件要求,提供相应的企业的详细信息及相关资质证明材料,并遵循学校关于就业信息管理平台的协议约定。企业注册后必须等待学校进行审核,只有审核通过后,才能发布招聘岗位及开展网络招聘。
学生子系统主要满足就业求职需求,主要包括个人信息维护、简历的制作与修改、求职意向管理、推荐职位、求职助手、求职登记等功能。其中求职意向功能,主要是学生设置期望求职的单位性质、工作地点、从事行业、岗位、月薪、福利,同时,将学生的学历、工作经验结合起来,作为求职需求特征参数;推荐职位功能是本子系统的核心功能,根据求职需求特征参数,运用推荐算法,从职位招聘信息大数据中进行相似度计算,将计算结果进行排名,将排名前列的若干招聘信息推荐给指定的学生,从而实现较为精准的就业个性化推荐和服务。
学校作为企业、学生、政府之间联系的纽带,学校子系统应具有对企业的资质及招聘岗位审核,对学生进行就业指导与服务,对教育主管部门的通知和要求等文件进行传达和解读,就业情况调查、就业情况分析与统计及招聘职位信息管理的功能。其中招聘职位数据管理是本子系统的重要功能,学生就业的成功率在很大程度上与企业招聘的职位数据的多少有关,就业平台的招聘数据一方面来自于平台注册企业提供,另一方面必须定期从典型人才招聘服务平台(如智联招聘、51job、BOSS直聘、58同城、中华英才网)挖掘招聘信息,然后进行数据清洗和归整,形成职位招聘信息的大数据,只有具有充分的招聘职位需求信息,才能有效提高就业服务的质量和水平。
2 平台的关键技术
2.1 学生求职意向特征模型的设计
学生的就业需求是学生从学校走入社会的第一份职业需求,其期望要素涉及诸多方面,既与自身所具备的专业知识、专业技能和综合素质相关,也与其所处的区域位置、社会环境、行业背景、消费水平相关,甚至包括家庭的影响,因此,求职意向特征应具有多维性,其维度也应与企业能提供的岗位之间具有一定的对应关系。本平台的特征模型包括如下8个维度,为了便于数据挖掘和预测,规范各个维度的取值,各个含义及取值说明如下:
特征模型:{学历;工作经验;期望单位性质;期望工作地点;期望从事行业;期望岗位;期望月薪;期望福利}
各维度约定如下:
学历:1 博士;2 硕士;3 本科;4 专科;5 中专;6 高中;7 初中以下或无要求
工作经验:n-m表示n-m年工作经验;n表示n年或以上;0表示无需要工作经验
期望单位性质:1 事业;2 国企;3 民营;4 上市;5 外资;6 合资;7 创业;8 其它
期望工作地点:省/市;省;直辖市;直辖市/区,若只写了省或直辖市,则等同于该省或直辖市均可
期望从事行业:行业规范参照国家国民经济行业分类标准(或典型人才招聘服务平台的行业分类)
期望岗位:参照国家相关职位分类标准(或典型人才招聘服务平台的职位分类)
期望月薪:由n表示,[n-500,n+500],若为4000,表示3500~4500之间均可,即默认为500元的上下浮动空间,系统可以设置
期望福利:包括“五险一金、周末双休、餐饮补贴、年终奖…”等各种类型表达方式
表1为样本数据示例。
表1 样本数据示例

工作经验学历期望单位性质期望工作地点期望从事行业期望岗位期望月薪期望福利14事业;民营;上市广东省/深圳市;广东省;北京市/丰台区计算机软件;互联网/电子商务Java;开发;工程师4000五险一金、周末双休、餐饮补贴
2.2 基于特征标识的爬虫技术的职位信息抓取
国内各大型人才招聘服务平台发布有大量的企业招聘信息,一般情形下这些信息并没有针对特定的求职用户,属于招聘信息的“广播”模式,没有筛选、过滤和个性化推送功能。对于求职的学生来说,因为信息量大,信息不直接,针对性不强,选择起来比较困难,不易找到合适的就业企业。因此,如何从这些人才招聘服务平台获取招聘信息就成为就业信息服务平台的核心功能。
各典型人才招聘服务平台因其设计的独立性、技术上的封闭性,在各类信息的分类上没有统一的标准,存在差异性,如对行业、职位等信息的分类,在对“行业”的层次进行划分时,某服务平台分为11个一级大类,而另一个服务平台分为13个一级大类,并且职位信息发布的要素上也存在一定的差异,如某服务平台上除招聘岗位的名称、招聘人数、工作地点、学历要求、经验要求、待遇、福利保障外,还提供了该企业人力资源对求职者的反馈时间及反馈比例等信息,从而让求职者可以了解该企业的效率。因此,对特定的服务平台,首先要分析其职位信息发布页面的源代码,找出职位相关信息点位置及内容标签结构,确定爬虫工具的爬取规则(即正则表达式或标签选择器),再利用Python语言编写爬虫程序,获取招聘职位的大数据。
2.3 基于大数据技术的数据职位信息的清洗与归整
因为招聘服务平台中数据格式的差异性及描述方式的多样性,如“工作经验”要求描述方式有“5-7年经验、1年经验、无工作经验”等描述方式;“招聘人数”描述方式有“招2人、招若干人”;“薪资”的描述方式有“6-8千/月、1.5-2万/月、10-12万/年”等方式。因此,这些爬取的原生数据不能直接用于数据的分析和处理,必须对数据进行清洗与归整,尽可能将文本信息数值化。本平台对数据进行了相关约定,并对数据进行清洗和归整,如“工作经验”统一规整为“n或n-m”格式,“无工作经验”归整为0;如“招聘人数”数据统一规整为整数n,“招若干人”归整为15;薪资数据统一以元/月为单位,格式为“n-m”。
2.4 基于用户需求特征的职位推荐算法
职位推荐就是要根据学生个性求职需求,结合自身求职经历、其他类似学生就业信息情况及招聘岗位的特点,给学生推荐可能感兴趣的职位或就业成功率较高的职位。目前,推荐算法主要包括基于人口统计学的推荐、基于内容的推荐和协同过滤3种方法。推荐算法涉及用户和物品2个方面,本系统中学生的求职期望相当于用户,企业的职位招聘信息相当于物品。
基于人口统计学的推荐是根据当前学生的求职期望信息(模型),计算与当前系统中其他学生的相似度,将相似度较高的学生所接受(或成功入职)的招聘职位推荐给当前学生,该算法只关注了学生求职期望的相似度,没有关注用户对招聘职位的接受程度。此算法的优点是不需要历史数据,没有冷启动问题,不足是算法较粗糙,精准度不高,只适合简单的推荐,对于没有求职经历的学生,在首次进入系统时,可应用此方法获取学生初步的职位喜好。
基于内容的推荐与基于人口统计学的推荐类似,核心是基于内容数据建模,只关注招聘职位的相似度而不考虑求职期望的相似度,其前提是需要学生以往接受招聘职位的历史数据,存在冷启动的问题,另外招聘职位的属性模型也会限制算法的精度。
协同过滤推荐算法的核心是基于用户交互行为的数据建模,它具体可分为基于用户的推荐(User-based Recommendation UF)、基于项目的推荐(Item-based Recommendation UF)和基于模型的推荐(Model-based Recommendation UF)。基于用户的推荐与基于人口统计学的推荐类似,只是前者是在基于当前学生对招聘职位历史偏好数据的基础上,采用“k-邻近”算法计算用户的相似度,将相似度高的其他学生喜好的职位推荐给当前学生;基于项目的推荐与基于内容的推荐类似,只是前者是在基于当前学生对招聘职位历史偏好数据的基础上,采用“k-邻近”算法计算招聘职位的相似度,将相似度高的职位推荐给当前学生;基于模型的协同过滤推荐是基于学生已往职位偏好信息的样本,训练一个推荐模型,然后根据实时的求职期望信息进行预测,计算推荐[1-5]。
本系统运行中,学生首次登录时,没有求职登记记录(即无以往求职经历),系统不知道其具体期望,这时可以通过借助学生的背景资料(如学历、所学专业)来推荐相关的热门岗位(薪资较高、招聘岗位较多、一线城市),随着学生信息的完善和求职行为数据的产生,逐步过渡到基于人口统计学的推荐和基于协同过滤的算法推荐,实现所推荐职位的逐步精准,不断满足个性化需求,最大程度提升学生的就业质量。
3 技术实现及结果
3.1 爬虫技术实现及结果
基于Python的爬虫程序的部分代码如下:
#职位字典定义
…
job_dic={′jobtitle′:[],′jobarea′:[],′companyname′:[],′money′:[],′compannyattribute′:[],′companysize′:[],′companytype′:[],′workexperience′:[],′degree′:[],′number′:[],′workwelfare′:[]}all_urllist=[]#存放需要爬取的url列表
#页面内容获取函数定义,根据url,获取页面内容的HTML流(页面源代码)
def get_html(url):
try:
request=urllib2.Request(url)
response=urllib2.urlopen(request)
html=response.read()
strs=html.decode("GB2312","ignore").encode("UTF-8")
return strs
except:
pass
return
#爬虫函数定义,根据url,进行数据抓取
def get_urlpage(url):
ht=get_html(url)
cn=re.findall(r′′,ht,re.I|re.M|re.S)#正则表达式,确定信息标签位置
#工作职位
if(len(cn)>=1):
title=re.findall(r′
′,cn[0],re.I|re.M|re.S)
job_dic[′jobtitle′].append(title[0])
…
#运行
if__name__==′__main__′:
page_urllist=[]
url=′…′
base_html=get_html(url)
num=re.findall(r′共(d+)页′,base_html,re.I|re.M|re.S)[0]
for i in range(1,int(num)+1):
u=′…′
page_urllist.append(u)
pool1=Pool(20)#多进程爬虫技术
pool1.map(get_jobpage,page_urllist)
pool1.close()
pool1.join()
…
对某典型人才招聘服务平台发布的招聘职位数据运行爬虫程序,经过初步清洗,获得近87000条有效职位数据。
3.2 数据整理技术实现及结果
数据整理的部分主要对单位性质、学历、工作经验、薪资、招聘人数等数据进行归整,归整为以数字表示的形式。
对薪资的各种表示形式,如10-12万/年,0.8-1.2万/月,6-8千/月等形式的数据,统一归整为XXXX-XXXX元/月的形式,Python程序的部分代码如下:
def value3(val):
if u′年′ in val:
if ′-′ in val:
if u′万′ in val:
s=val[:-3].split(′-′)
s=str(int(round(float(s[0])*10000)/12))+"-"+str(int(round(float(s[1])*10000)/12))
return s
else:
s=val[:-3].split(′-′)
s=str(int(round(float(s[0])*1000)/12))+"-"+str(int(round(float(s[1])*1000)/12))
return s
…
3.3 推荐算法技术实现及结果
推荐算法的关键是相似度的计算,本平台采用欧氏距离计算当前用户和其他用户的相似度,然后对相似度进行排名,选择相似度高的前top N推荐给当前用户,实现推荐的冷启动。基于欧几里得距离推荐的Python程序的部分代码如下:
#返回一个有关person1与person2的基于距离的相似度评价
def sim_distance(prefs,person1,person2):
#得到shared_items的列表
si={}
for item in prefs[person1]:
if item in prefs[person2]:
si[item]=1
#如果两者没有共同之处,则返回0
if len(si)==0:return 0
#计算所有差值的平方和
sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2)
for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares))
4 结束语
就业工作是职业院校的重要工作,它的质量不仅关系到学生的职业发展和未来,同时,也是学校办学水平和实力的直接体现。本文根据就业管理工作的目标,从就业指导、管理、服务的角度出发,充分考虑政府、企业、学校等就业工作相关方的需求,针对就业工作中招聘职位数量和质量需求难、学生个性化求职期望与职位有效推荐服务不一致、就业工作统计分析工作量大且结果不直观等问题,遵循软件工程的思想,利用现代信息技术手段进行了设计与实现,主要包括利用UML建模工具进行了系统设计,利用爬虫技术获取了招聘职位的大数据,利用大数据技术对获取的职位大数据进行清洗、归整,成为可供平台应用的有效数据,根据学生的就业期望,利用基于人口统计学、基于协同过滤等推荐算法进行职位的有效推荐,利用Web技术和数据库技术对系统进行了实现。实践证明,本系统能有效促进学生就业,方便企业进行人才招聘和选拔,提高学校就业指导、管理和服务的水平,同时,也能为学校专业建设、人才培养方案优化等提供数据和技术支撑。
参考文献:
[1] 秦冬梅,钟守广,管鹏,等. 大数据背景下高校就业信息整合系统开发[J]. 科技资讯, 2017,15(17):15-16.
[2] 郭佳. 数据挖掘技术在高校学生就业信息管理系统中的应用研究[J]. 桂林师范高等专科学校学报, 2015,29(3):148-150.
[3] 杨露. 基于数据挖掘技术的就业信息管理系统设计与实现[J]. 中小企业管理与科技, 2015(29):202.
[4] 陈燕纯. 数据挖掘技术在高职院校就业信息分析的应用研究[J]. 科技展望, 2014(11):24-25.
[5] 黄荣喜,粟圣森,邓江荣. 关联规则在高职院校就业信息管理中的应用—以广西农业职业技术学院为例[J]. 无线互联科技, 2017(22):130-132.
[6] 朱楠. 国内高校学生就业信息管理系统的应用情况研究[J]. 现代交际, 2018(3):35-36.
[7] 朱露婕,庞文驹,植健. 基于Web的高校毕业生就业信息管理系统的优化设计[J]. 玉林师范学院学报, 2016,37(5):132-136.
[8] 高海涛. 基于云计算的高校毕业生就业信息平台的设计[J]. 才智, 2016(12):185.
[9] 倪天伟,林金珠,朋仁正. 基于Java EE的高校就业信息管理系统设计研究[J]. 赤峰学院学报(自然科学版), 2017,33(12):7-8.
[10] 钟召春. 学生就业信息服务平台建设中存在的问题及对策[J]. 黑河学院学报, 2017,8(4):83-84.
[11] 尚光龙,王坤. 高校毕业生就业信息管理系统开发与实现[J]. 武汉职业技术学院学报, 2015,14(3):75-78.
[12] 卓志宏. 浅析高职院校就业管理系统的设计与性能分析[J]. 电子世界, 2016(8):36-37.
[13] 贾甜夏. 基于就业信息平台的高职院校个性化就业指导研究[J]. 职业技术, 2018,17(4):32-34.
[14] 杨利江. 基于人本理论的就业指导服务体系构建——以南方某大学为例[J]. 西部素质教育, 2017,3(16):183-184.
