一种结合ORB特征和视觉词典的RGB-D SLAM算法
2018-06-26张生群
张 震 ,郑 宏 ,周 璇,张生群
1.武汉大学 电子信息学院,武汉 430072
2.武汉大学 大疆创新无人机实验室,武汉 430072
1 引言
当机器人处于一个完全陌生的环境中时,如何通过自身传感器获取到的信息,完成自身的定位和对周围环境的建模,是一项具有重要意义同时又极具挑战性的工作,一般将这个问题称为同时定位与建图(Simultaneous Localization and Mapping,SLAM)。SLAM被认为是真正实现机器人自主运动最核心的部分[1]。目前常用的方法采用激光雷达获取周围障碍物信息,但受限于激光雷达昂贵的价格,很难进行广泛的应用。微软于2010年推出了可同时获得彩色图与深度图的相机——Kinect。由于其低廉的价格,迅速在计算机视觉以及机器人领域得到了广泛的应用。
当前求解SLAM问题主要可以分为两种方法。传统的方法将定位看作一个状态估计问题:在给定了从初始时刻到当前时刻的控制输入以及观测数据的条件下,构建一个联合后验概率密度函数来描述当前位姿和地图特征的空间位置。通过递归的贝叶斯滤波方法对此概率密度函数加以估计,从而实现同步定位和地图创建。根据滤波器选择的不同,可以分为基于扩展卡尔曼滤波(EKF)的方法,基于扩展信息滤波(EIF)的方法和基于粒子滤波(PF)的方法等。基于滤波器的方法主要存在两个问题:一是线性化模型导致的累计误差,二是高计算复杂度导致更新效率缓慢,因此很难被应用到大规模环境地图创建中去。这都是由滤波器模型本身的缺陷所造成的。Lu和Milios于1997年首次提出了一种基于图优化的SLAM方法[2],他们以激光传感器为基础,阐述了图优化SLAM方法的基本思想。这种方法很快在基于视觉的SLAM方法中(Visual-based slam,V-slam)得到了广泛的应用。基于图优化的SLAM方法将相机的位姿轨迹描述成图的形式,其中,图的节点代表相机的位姿估计或环境特征点,图的边表示位姿之间的约束关系。通过对不一致的约束进行优化,可以得到更加精确的相机位姿。
Henry[3]等人最早提出了一种使用深度相机的SLAM算法。该算法首先提取图像的SIFT特征点,然后采用迭代最近点(Iterative Closest Point,ICP)算法求解两帧图像之间的运动变换,最后利用图优化工具TORO进行全局优化。Engelhard等人[4]采用SURF(Speed-Up Robust Features)特征点取代SIFT特征点进行特征匹配,然后结合深度信息,获得三维的匹配点对集合,接着采用随机采样一致性(Random Sample Consensus,RANSAC)算法求出相邻两帧的初始运动变换,并将其作为ICP算法的初值进一步优化,最后采用Hogman位姿图优化方法求解出全局最优位姿。Endres[5]等人采用环境评估模型(Environment Measurement Model,EMM)来进一步判断RANSAC和ICP求解出的运动变换是否正确,在后端则采用通用图优化工具g2o优化全局位姿。Gao[6]等人认为物体边缘附近的深度值通常是不准确的,而特征点又往往分布在物体的边缘,这种矛盾会影响ICP算法的准确性,所以提出了一种算法来筛选出平面特征点(planar point features)。ElGhor等人[7]则通过提取平面来给平面边缘的特征点赋予一个更加可信的深度值来解决上述问题。还有一些研究人员从其他角度入手改进算法。Houben等人[8]通过使用多个摄像头来解决无结构的平面缺少特征点和重复的纹理难以进行匹配等问题。Ma等人[9]通过融合惯性测量单元(Inertial Measurement Unit,IMU)的数据来解决户外大场景下的SLAM问题。
由于采用SIFT或SURF特征,所以计算速度较慢,一般需要通过GPU进行加速,所以无法应用到没有GPU或者GPU运算能力弱的设备上。此外,上述算法在闭环检测上的效率也较低。
针对上述问题,本文提出了一种结合ORB特征和视觉词典的RGB-D SLAM算法。该算法采用ORB特征描述符,不需要经过GPU加速,使其可以应用于没有GPU或者GPU运算能力弱的设备上。同时由于采用了视觉词典,使得闭环检测的效率和实时性得到了提高。
2 基本原理和实现方法
算法的整体流程如图1描述。在前端,首先提取图像的ORB特征,然后利用kNN匹配找到对应的最临近与次临近匹配,然后采用比值检测与交叉检测剔除误匹配点,接着采用改进的PROSAC-PnP算法计算相邻帧之间位姿变换,并判断该帧能否成为关键帧。在后端,利用基于BoW(Bag of Words)的闭环检测算法进行闭环检测,采用倒排索引记录每个单词对应的关键帧集合,从倒排索引中找出与当前帧具有共同单词较多的帧计算得分,挑选得分高的进行特征匹配,判断是否发生回环,将回环作为新的边约束添加到姿态图中。最后,利用通用图优化工具g2o对姿态图进行全局优化,得到全局一致的位姿与点云地图。
2.1 ORB特征提取
在SLAM领域中,前端(Front End)一般研究相邻两帧之间的配准,以此来获得相机位置的估计。在前端的处理中有两种主要的方法:直接法(Direct Method)和基于特征的方法(Feature Based Method)。对于基于特征的方法而言,特征与描述符的选择对配准的速度与准确性有着至关重要的影响。在传统的RGB-D SLAM算法中,SIFT[10]和SURF[11]特征描述符是两种非常流行的选择。但是无论是SIFT还是SURF都要求很长的时间来计算特征描述符。一些算法采用GPU加速的SIFT算法(SiftGPU)[12]来加快特征描述符的计算,但是这种方法对于嵌入式设备或者缺乏GPU运算功能的设备来说并不适用。Rublee等人[13]于2011年提出了一种新的特征描述符计算方法,称为ORB算法。ORB算法采用改进的FAST角点检测方法获取特征点,采用BRIEF特征描述子生成特征描述符。由于FAST和BRIEF的计算速度都非常的快,所以相较于SIFT和SURF而言,ORB算法在速度上具有绝对的优势,不需要经过GPU加速,适合在嵌入式设备或缺少GPU运算能力的设备上使用。

图1 算法整体流程图
ORB算法包含oFAST特征点检测和rBRIEF描述符提取两个步骤。FAST特征点不具备尺度不变性,同时也不具有方向信息。为了解决这两个问题,ORB算法用图像金字塔方法处理图像并在每一层金字塔尺度上检测特征点,之后再对特征点加上方向信息,构成了具备尺度不变性与方向信息的oFAST特征点。
ORB算法采用intensity centroid[14]计算方向信息。Rosin定义图像块的矩为:

其中,I(x,y)为图像的灰度表达式。矩的质心为:

因此,特征点的方向就可以简单地表示为:

随后,BRIEF描述符被用来生成对检测到的特征点的描述。BRIEF描述符具有计算速度快,表示简单和占用空间小的特点,但是不具备方向不变性。对于特征点周围大小为N的点集,定义S为一个2×N的矩阵:

根据图像块的旋转信息θ和相应的旋转矩阵Rθ,计算带旋转信息的矩阵Sθ=RθS。新的特征描述符可由如下的公式表示:

2.2 基于PROSAC-PnP的图像配准
在特征匹配时,误匹配是经常出现的,并会对图像配准的准确性产生巨大的影响。因此,如何去除误匹配点,得到鲁棒性强的匹配显得至关重要。本文所采用的算法步骤如下描述:
(1)采用ORB算法提取相邻帧的特征点并计算特征描述符。
(2)采用kNN算法计算两幅图像的最临近匹配以及次临近匹配,得到匹配向量M1、M2。
(3)移除最临近匹配与次临近匹配的距离比值大于给定阈值ratio的匹配,得到过滤后的匹配向量FM1、FM2。
(4)对FM1、FM2进行交叉匹配:只有同时出现在FM1和FM2中的配对点才被认为是合法的匹配,得到最终的鲁棒性强的匹配GM,GM被用于下一步的图像配准。
如图2显示的是原始的匹配结果与经过过滤后的匹配结果,可以看到经过算法过滤后,得到的配对点质量有了明显的提高。

图2 匹配结果
传统的算法大多采用ICP与RANSAC结合的方法进行图像配准。RANSAC算法存在的问题是它随机选取匹配点进行计算,而忽略了匹配点的差异性。事实上在得到的配对点中,有一些也是误匹配的外点,即匹配点的质量存在差别。为此,本文结合PROSAC[15]算法,提出了一种RPOSAC-PnP算法,来进行图像配准,算法步骤如下描述:
(1)对得到的匹配点按照最临近与次临近距离的比值进行排序,即认为最临近与次临近距离相差越大的匹配点匹配质量越高。
(2)在排序后的点中选取前n个点作为高质量匹配点作为RANSAC算法的输入,不足n点则全部选取。
(3)在n个点中选取m个点,然后采用透视n点(PnP)算法计算变换矩阵T。
(4)对于剩余的未参与计算的点,分别应用T去测试,当误差小于某个阈值时,认为该点适用于当前模型参数T,将其视为内点。
(5)统计测试得到的内点个数,当内点数目大于给定的阈值并且当前模型内点数目大于上一次模型内点数目的时候,将模型参数替换为当前计算得到的参数,反之,则舍弃。
(6)如果迭代次数达到上限,则退出,否则重复从步骤(3)执行。
PROSAC-PnP算法基于一种假设,该假设认为最临近距离与次临近距离差别越大,得到的匹配点匹配质量越高。采用PROSAC算法后,可以适当减小算法的迭代次数,又因为选取的都是高质量的匹配内点,所以计算的速度和鲁棒性都会有所提升。
2.3 基于BOW的闭环检测
在相机姿态的计算过程中,由于只用到了上一帧的数据来进行计算,所以计算的结果会存在累计误差。典型的情况是当相机运动了一圈又回到起点的时候,相机的位姿估计会与初始位姿存在明显的误差。如果机器人可以识别出一个曾经来到过的地方,那么在当前帧与历史帧之间就可以建立起一种约束,利用这种约束就可以修正累计误差,得到更为精确的相机姿态。这个过程在SLAM中称为闭环检测。
图优化理论产生以来,出现了很多闭环检测的方法[16-18]。目前流行的闭环检测方法主要有两种:基于图像特征匹配的方法和基于词袋(BoW)的方法。基于图像特征匹配的方法将当前帧与已有的关键帧进行特征匹配,根据匹配的结果判断是否发生了闭环。随着算法的运行,关键帧会变得越来越多,而与每一帧都进行匹配的策略将导致算法的运行时间越来越长。为了解决这个问题,可以从关键帧中选取一个较小的子集进行匹配,闭环检测的质量也将严重依赖于子集的选取。Nister[19]等人于2006年提出了一种基于词袋模型的图像检索方法,该方法在原始词袋模型的基础上采用N层的树形结构描述和构建词汇树,这一方式大大提高了检索效率。
词汇树的构建过程是一个递归的过程。首先利用K-means聚类方法将训练集中的所有特征向量分成K类,然后对于每一类,递归的采用同样的方式进行聚类,直到达到所设定的层数。这样,整个词汇树就被表示成了一个K叉树的结构,如图3所示。
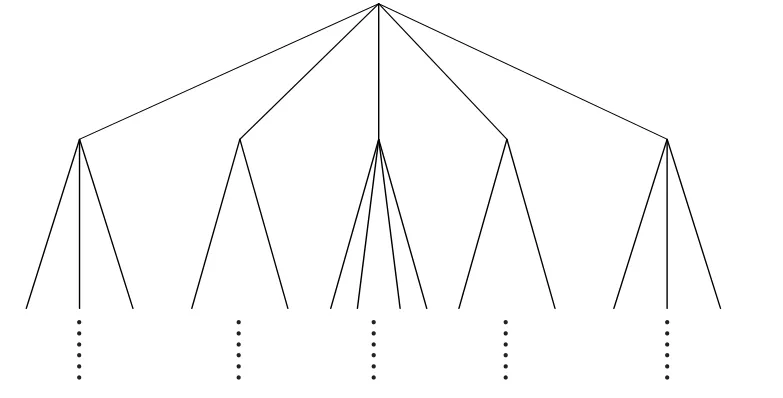
图3 词汇树
在构建完成整个词汇树之后,需要对每个叶节点赋予一个权重w,该权重的值是基于单词的逆向文本频率,也就是说:频繁出现的词汇将具有较小的权重,而出现次数很少的具有代表性的词汇具有较大的权重。权重w可通过下式计算:

其中,N是数据库中图片数目的总和,Ni是数据库中所有具有词汇i的图片的总和。然后待检索图片的特征向量和数据库图片的特征向量就可以表示成如下形式:

其中,ni和mi分别表示待检索图片和数据库图片中具有单词i的数目。然后,待检索图片与数据库图片之间的相似程度可通过下式得到:

有了上式,就可以计算出当前帧与旧的关键帧的相似程度。将当前帧与旧关键帧的每一帧都进行比较是不明智的,应该选取具有共同单词数较多的关键帧来进行比较。为此需要建立关键帧的倒排索引,来记录包含特定单词的所有关键帧。这样对于新来的一帧,首先计算出该帧包含的单词表,然后对于每一个单词,通过倒排索引查找具有该单词的所有关键帧,同时记录每个关键帧与当前帧的共同单词的个数。随后在所有与当前帧具有共同单词的关键帧中选取那些公共单词个数超过给定个数N的关键帧,分别计算得分。最后再选取得分超过给定阈值的关键帧,作为候选的可能与当前帧构成回环的帧,再进行常规的特征匹配判断,得到最后的回环的判定。若在随后的处理中当前帧被选定为关键帧,则需要更新关键帧的倒排索引。闭环检测的流程图如图4所示。
2.4 全局优化

图4 闭环检测流程图
在视觉SLAM中建立的三维的点云地图,对姿态一般采用6自由度建模描述。在这之中,又涉及到是否需要将图像的特征点作为节点加入到图结构,并在特征点节点之间与关键帧节点之间添加边约束。这会在图结构中生成更多的约束,所以会使优化的准确性提高。但是由于每帧图像都包含数量众多的特征点(几十甚至上百个),这会使得整个图结构变得巨大无比,给优化带来不便。因此,本文只对姿态图(即不包括特征点节点的图)进行优化。
姿态图的节点代表相机的6自由度姿态:
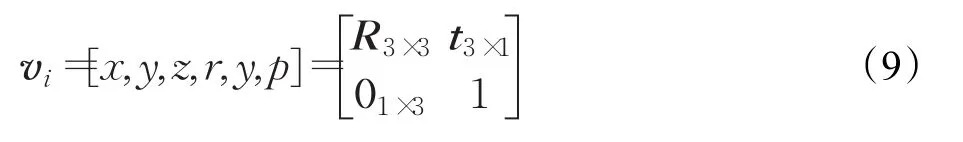
姿态图的边代表两个姿态的变换关系:

这样,对于两个由边连接的节点,会有一个误差:

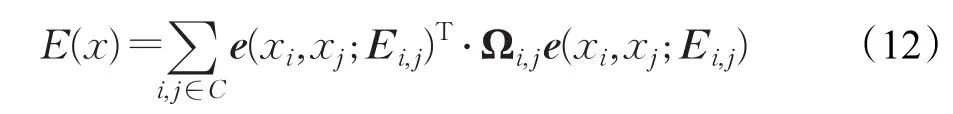
其中,i,j属于节点集合C,Ωi,j表示xi和xj之间的信息矩阵,E(x)就是要优化的误差函数,即找到一个序列X,使得:

整个问题被转化成了一个非线性最小二乘问题。g2o[20]是一个流行的图优化求解工具,可用来求解上述优化问题。优化过程中大部分时间都消耗在线性方程组的求解上,g2o提供了三种不同的线性求解器:CSparse和CHOLMOD基于乔里斯基分解(Cholesky decomposition),PCG则基于预处理共轭梯度算法(preconditioned conjugate gradient)。CSparse和CHOLMOD受初始值设定的影响较小,PCG在给定较好初值的情况下可以很快的收敛。本文采用CSparse求解器进行求解。
2.5 丢失恢复
在相机运动过程中,由于种种原因可能会出现图像失配的情况。如果不对这种情况进行处理,将严重影响以后的定位,甚至会造成整个算法崩溃。为此,本文加入了丢失恢复功能:当连续的N帧图像都出现失配的时候,立即将当前帧图像设为关键帧,并对当前帧进行闭环检测,以期待找到所有的与当前帧相近的场景并建立起帧间约束,降低运动丢失对定位造成的影响。
3 实验结果与分析
Sturm等人[21]使用Kinect记录了一系列的图像序列,同时用一个运动捕捉系统记录了相机的精确位姿信息。图像序列包括彩色图和深度图,分辨率为640×480,帧率为30 Hz,真实轨迹值由8个高速追踪相机(100 Hz)获得。整个数据库包括39个序列,包括办公室场景和工厂厂房。同时,他们还提供了一个自动评估工具,该工具可以自动计算出真实轨迹与算法估计轨迹之间的均方根误差(RMSE)。
为了验证本文算法的有效性,本文选取上述测试集中的数据进行了定位与建图实验,同时与文献[22-23]进行了对比。算法的实验平台为:Intel i5 6200U处理器(2.3 GHz),4 GB RAM,64位Ubuntu16.04操作系统。
3.1 定位误差分析
本文选取了fr1数据包中的fr1/xyz、fr1/rpy、fr1/desk、fr1/desk2、fr1/floor、fr1/room这6个数据集中的全部帧进行实验,每组数据集进行5次重复实验,记录每个关键帧对应的相机的位姿估计并采用文献[21]提供的评估工具计算算法的RMSE。同时,在实验过程中记录了算法的整体运行时间以便对算法的运行速度进行评估。最后,根据得到的相机轨迹与原始的图像数据生成三维点云图。表1为本文算法的详细实验结果。
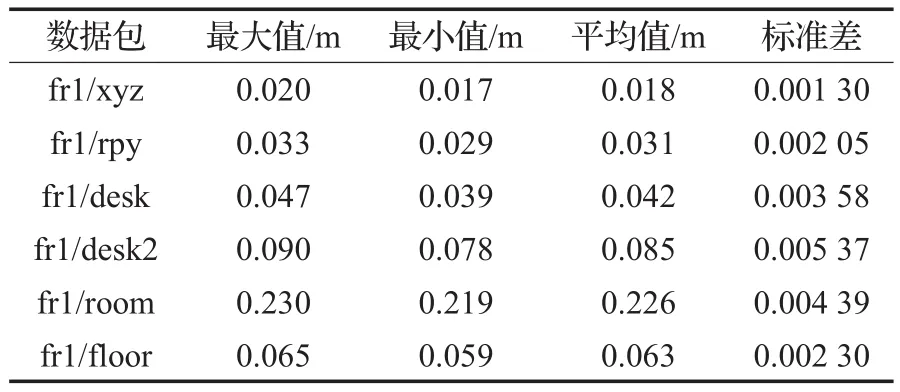
表1 本文算法的详细结果
为了体现本文算法的优越性,本文与其他算法做了对比。表2为本文算法与文献[22]和文献[23]算法的均方根误差对比。

表2 本文算法与文献[22]、[23]均方根误差对比m
由表2可以看出,对于fr1/rpy、fr1/desk、fr1/desk2、fr1/room数据包,本文算法都优于其他两种算法。对于fr1/rpy,本文算法误差比文献[22]低1.3 cm,比文献[23]低0.3 cm;对于fr1/desk,本文算法误差比文献[22]低1.0 cm,比文献[23]低0.6 cm;对于fr1/desk2,本文算法误差比文献[22]低2.5 cm,比文献[23]低0.5 cm;对于fr1/room,本文算法误差比文献[22]低1.0 cm,比文献[23]低4.1 cm。对于fr1/xyz数据包,由于该数据包本身的运动范围不大,对于该数据包的位姿估计已经比较精确了,本文的算法相比文献[23]来讲也没有提高,与其持平。而对于fr1/floor数据包,本文算法弱于其他两种算法,这是由于fr1/floor数据包的运动没有太多的回环,所以算法的性能更多地依赖于算法前端的特征匹配与图像配准。ORB特征相较于SIFT与SURF而言,虽然速度较快但是相应的鲁棒性不如前两者高,所以本文算法在该数据集上表现略差。从总体上来看,本文算法略优于其他两种算法。
3.2 运行速度对比
由于文献[23]只进行了特征点的提取,而没有进行描述符提取和特征匹配,所以本文只与文献[22]进行了速度对比,对比结果如表3所示。
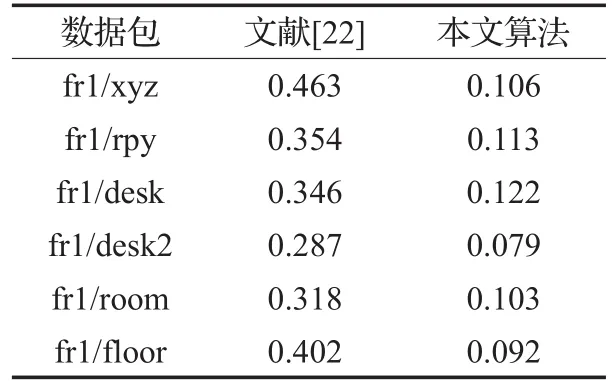
表3 本文算法与文献[22]算法运行速度对比s
文献[22]的算法运行在一个4核处理器的电脑上,本文算法运行在一个双核处理器的电脑上,主频只有2.3 GHz。然而,本文算法的运行速度要优于文献[22]。文献[22]处理一帧数据平均用时0.35 s,即每秒钟最多只能处理3帧数据,而本文算法处理一帧数据平均需要0.11 s,每秒可处理约10帧数据,速度是文献[22]的3倍。文献[22]已经通过并行加速获得了2~2.5倍的速度提升,而本文算法没有采用任何形式的加速,这些都表明了本文算法的实时性相较于文献[22]有了很大程度的提高。
3.3 地图构建分析
本文选取了fr1/desk和fr1/floor数据包进行建图分析。
fr1/desk是一个办公室场景,为手持kinect拍摄所得。由图5可以看到,该场景内的办公桌,电脑以及房间的墙壁都得到了比较好的重建。图像左边地面部分有一片黑色的空洞,这是由于拍摄过程中没有扫过那块地面造成的。

图5 fr1/desk点云图
fr1/floor数据集由机器人装载kinect采集所得,共1 200余帧。由图6可以看出,整个空间的轮廓也得到了较好的重建。

图6 fr1/floor点云图
4 结束语
本文提出了一种改进的RGB-D SLAM算法来进行同时定位与地图构建应用研究。在SLAM前端,本文采用ORB特征取代传统的SIFT和SURF特征,使其可以应用在嵌入式设备或缺乏GPU运算能力的设备上;同时采用改进的PROSAC-PnP算法增强相机位姿计算的鲁棒性。在SLAM后端,采用基于视觉词典的闭环检测算法进行闭环检测,通过通用图优化工具g2o对位姿图进行优化,得到了全局一致的位姿。最后,本文选取了fr1数据包中的6个测试数据集进行实验,并与文献[22-23]进行了误差对比,表明了本文算法的优越性。
由于本文算法采用ORB特征,相较于SIFT与SURF特征存在鲁棒性不足的缺点。因此对于缺少路径回环的场景来说,需要做进一步的改进以提高算法可靠性。
[1]Durrant-Whyte H,Bailey T.Simultaneous localization and mapping:Part I[J].IEEE Robotics&Automation Magazine,2006,13(2):99-110.
[2]Lu F,Milios E.Globally consistent range scan alignment for environment mapping[J].Autonomous Robots,1997,4(4):333-349.
[3]Henry P,Krainin M,Herbst E,et al.RGB-D mapping:Using depth cameras for dense 3D modeling of indoor environments[C]//The 12th International Symposium on Experimental Robotics,2010,20:22-25.
[4]Engelhard N,Endres F,Hess J,et al.Real-time 3D visual SLAM with a hand-held RGB-D camera[C]//Proceedings of the RGB-D Workshop on 3D Perception in Robotics at the European Robotics Forum,Vasteras,Sweden,2011:1-15.
[5]Endres F,Hess J,Sturm J,et al.3-D mapping with an RGB-D camera[J].IEEE Transactions on Robotics,2014,30(1):177-187.
[6]Gao X,Zhang T.Robust RGB-D simultaneous localization and mapping using planar point features[J].Robotics&Autonomous Systems,2015,72:1-14.
[7]Elghor H E,Roussel D,Ababsa F,et al.Planes detection for robust localization and mapping in RGB-D SLAM systems[C]//International Conference on 3D Vision,2015:452-459.
[8]Houben S,Quenzel J,Krombach N,et al.Efficient multicamera visual-inertial SLAM for micro aerial vehicles[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems,2016.
[9]Ma L,Falquez J M,Mcguire S,et al.Large scale dense visual inertial SLAM[M]//Field and Service Robotics.[S.l.]:Springer International Publishing,2016.
[10]Lowe D G.Distincitive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[11]Bay H,Tuytelaars T,Gool L V.SURF:Speeded up robust features[J].Computer Vision&Image Understanding,2006,110(3):404-417.
[12]Wu Changchang.SiftGPU:A GPU implementation of scale invariant feature transform(SIFT)[EB/OL].(2011-04-19).http://www.cs.unc.edu/~ccwu/siftgpu/.
[13]Rublee E,Rabaud V,Konolige K,et al.ORB:An efficient alternative to SIFT or SURF[C]//International Conference on Computer Vision,2011:2564-2571.
[14]Rosin P L.Measuring corner properties[J].Computer Vision&Image Understanding,1999,73(2):291-307.
[15]Chum O,Matas J.Matching with PROSAC-progressive sample consensus[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2005:220-226.
[16]Labbe M,Michaud F.Online global loop closure detection for large-scale multi-session graph-based SLAM[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems,2014:2661-2666.
[17]Khan S,Wollherr D.IBuILD:Incremental bag of binary words for appearance based loop closure detection[C]//IEEE International Conference on Robotics and Automation,2015:5441-5447.
[18]Volkov M,Rosman G,Dan F,et al.Coresets for visual summarization with applicationsto loop closure[C]//IEEE International Conference on Robotics and Automation,2015:3638-3645.
[19]Nister D,Stewenius H.Scalable recognition with a vocabulary tree[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2006:2161-2168.
[20]Kümmerle R,Grisetti G,Strasdat H,et al.G2o:A general framework for graph optimization[C]//IEEE International Conference on Robotics and Automation,2011:3607-3613.
[21]Sturm J,Engelhard N,Endres F,et al.A benchmark for the evaluation of RGB-D SLAM systems[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems,2012:573-580.
[22]Endres F,Hess J,Engelhard N,et al.An evaluation of the RGB-D SLAM system[C]//IEEE International Conference on Robotics and Automation,2012:1691-1696.
[23]付梦印,吕宪伟,刘彤,等.基于RGB-D数据的实时SLAM算法[J].机器人,2015,37(6):683-692.
