语言发音模型研究综述
2018-06-26张金光
张金光
北京大学 中国语言文学系,北京 100871
1 引言
传统观点认为语音是离散的线性的序列,是由最小语音单位(音素或音段)按照时间顺序排列组合而成的。然而发音音系学(Articulatory Phonology)却认为言语信号是连续的非线性的语音聚合群,是由交叉重叠的发音器官姿势(音姿)协同变化产生的[1]。
到底语音是如何产生的?能不能建立模型,模拟语音的产生过程?研究者们做过哪些尝试?成功和失败的原因是什么?本文尝试梳理各种有较大影响的语言发音模型的文献资料,概括已有的研究成果,探索这些问题的答案。
很早以前,人们就对语言发音的原理产生了浓厚的兴趣,并尝试利用机械手段模拟语言发音过程。在中国,唐朝小说家张鷟所著的《朝野佥载》卷六,有木和尚说话化缘的记载:将作大匠杨务廉,甚有巧思,常于沁州市内刻木作僧,手执一椀,自能行乞,椀中钱满,关键忽发,自然作声云“布施”,市人竞观,欲其作声,施者日盈数千矣。在外国,18世纪80年代匈牙利人Wolfgang von Kempelen发明了一个讲话机,用风箱模仿肺,用笛子模仿声带,用管子模仿口腔,不仅能产生一些元音和辅音,而且能发出完整的词和短语[2]。第一个基于电子技术的广为人知的语言发音模型是1939年在纽约世界博览会上展出的Voder,这个模型用脉冲发生器作为浊音声源,用噪声发生器作为清音声源,用滤波器产生共鸣效果。
语言发音模型的理论基础是言语产生的声学理论。根据Stevens的观点,声门把气流通道分成了上下两部分,对于大多数语音的产生过程而言,声门以下的系统提供了气流能量,喉部和声门以上的结构对气流进行调制,产生可以听到的声音[3]。经过对语音进行深入研究,学者们普遍认为:(1)由声带震动产生周期信号,通过声道共鸣,形成浊音;(2)由气流爆破或者摩擦产生非周期噪声,形成清音;(3)清音和浊音经过唇、鼻辐射,在空间进行传播,形成语音。根据这种理论,只要掌握了声源、共鸣、辐射的声学规律,就可以模拟语音的产生过程。
2 发音模型分类
Klatt把语音合成器分成了两类:(1)第一类是生理合成器,企图忠实地模拟发音器官的机械运动,以及由此产生的肺部、咽喉、口腔和鼻腔里的体积速度和声压的分布情况;(2)第二类是共振峰合成器,利用声学描述的简单规则集,构造语音波形[4]。Sondhi和Schroeter把语音合成器分成了3类:共振峰合成器、线性预测系数合成器和生理合成器[5]。
Theobald把可视化语音合成系统分成了3类:生理合成、基于规则的合成和拼接合成[6]。Birkholz和Jackel用两个标准对声道模型进行了分类,他们认为,一方面,声道模型可以分为二维模型和三维模型,二维模型用发音器官轮廓描述中矢面声道形状,而三维模型却生成真实的声道三维形状;另一方面,声道模型可以分为几何模型、统计模型和生物机能模型,几何模型基于先验经验描述发音器官的几何形状,统计模型利用统计分析方法建立发音器官形状的变化规则,生物机能模型通常利用有限元方法研究发音器官的肌肉动作[7]。
借鉴以上分类方法,本文把语言发音模型分为言语声音模型和言语动作模型,针对言语声音模型,重点讨论基于频谱分析原理的Vocoder语码器,基于共振峰原理的Klatt合成器,以及基于生理发音模型的ASY合成器;针对言语动作模型,将讨论几何特征模型、统计参数模型和生理机能模型。
3 言语声音模型
言语声音模型研究语言发音的声学原理,利用声音信号处理技术重构语音信号波形。由于对声源和共鸣之间的关系的认识不同,以及对共鸣的分析方法的不同,产生了3种不同的语言发音模型,第一种是频谱分析模型,第二种是共振峰模型;第三种是生理发音模型。
频谱分析模型把语音信号从时域变到频域,以基频信号作为声门激励,以频谱包络作为声道响应,经过信号处理之后,重构语音信号波形。共振峰模型利用周期信号作为浊音声源,利用噪声信号作为清音声源,利用共鸣器(滤波器)在特定频率位置构造极点和零点,模拟共鸣和反共鸣,声源信号经过滤波产生具有特定共鸣特征的语音信号。生理发音模型反对声源-滤波的线性模型,认为声源和共鸣之间有耦合,提出直接解声学方程的方法,尝试建立符合发音生理过程的语言发音模型。
3.1 频谱分析模型
所有基于频谱分析的语言发音模型的根本特征都在于解卷积。语音信号是声门激励、声道响应和唇鼻辐射的卷积。通过解卷积,把声门激励和声道响应分离开。Channel Vocoder、LPC分析和倒谱分析是3种解卷积的方法。
第一种频谱分析模型是Channel Vocoder。Dudley的Voder是第一个成功的Channel Vocoder,在分析阶段,首先用10个模拟带通滤波器对输入信号进行频率分离,然后通过积分电路获得每个频带的幅度包络。在合成阶段,用振荡器产生基频信号,作为浊音声源,用“s”噪声作为清音声源,通过10个带通滤波器分别进行滤波,然后叠加,生成语音信号。因为每个通道只保留了幅度丢失了相位,所以叫Channel Vocoder,后来增加了对相位的处理,叫Phase Vocoder。在同态滤波器的基础上,Opennheim提出了Homomorphic Vocoder[8-9],这种方法利用倒谱算法,对声源和共鸣进行分离,经过处理之后,再进行合成,产生语音波形,Homomorphic Vocoder是现在很多HMM TTS合成器的基础。
第二种频谱分析模型称为LPC分析,用线性预测编码(LPC)技术,对语音信号的声源和共鸣进行分离。这种技术最初用在图像处理领域,由于声音信号和图像信号有类似的变化规律,才被引入语音信号处理领域。从时域来看,相邻时刻的语音信号有很大的相似性,如果把前一个信号作为当前信号的预测值,通常情况下预测误差很小。假设一帧内的所有样本各自乘以系数ai,把得到的样本序列的前p个样本之和,作为当前样本的预测值,运用最小二乘法,计算使得残差平方和最小的ai系数矩阵,这就是LPC系数,预测误差称为LPC残差。如果把一帧LPC系数按照固定比例(比如乘以15 000)放大幅值,并在前后添加0,构成512个样本,对这组样本做傅里叶变换,就可以得到平滑的频谱包络[10],因此,从频域来看,LPC系数体现了频谱包络变化规律,代表的是声道响应特征;LPC残差包含的是基频信息,代表的是声门激励状态。用LPC系数和声门信号可以重构语音波形。如果声门信号用记录的LPC残差,合成出来的语音与原始语音几乎没有差别,但是这只是记录和回放而已,LPC处理失去了建立语言发音模型的意义。
第三种频谱分析模型是倒谱分析模型,利用倒谱分析技术分离声门激励和声道响应。先对语音信号进行快速傅里叶变换,把信号从时域变到频域,如果把这个频域信号当成时域信号,不难看出这是一个抑制了副半周期的调幅波,原始信号的基频相当于载波,原始信号的频谱包络相当于调制信号,对这个信号再进行傅里叶变换(称为inverse FFT),输出信号的低“频”区是原始信号的频谱包络,高“频”区是原始信号的基频载波[9-10],此时,声源和共鸣已经分开了,通常在傅里叶逆变换之前对信号取对数,取对数之后的信号只保留实部,然后进行傅里叶逆变换,就得到了倒谱。之所以“频”字加引号,是因为实际上信号已经回到时域了。在基于HMM的语音合成中,经常采用美尔(Mel)倒谱分析模型。所谓美尔倒谱,是对傅里叶变换的结果经过美尔滤波之后,取对数,然后再求倒谱。所谓美尔滤波,是符合人耳生理特征的滤波,在人耳基底膜上,频谱成分是一组一组叠加在一起进行感知的,每一组形成一个临界带,频率越高临界带的带宽越宽,可以设计滤波器组模拟基底膜的工作过程,这就是美尔滤波器。之所以取对数有两个原因,其一,振幅和音强,基频和音高,都不是线性关系,通常呈现对数关系;其二,语音信号可以近似表示为声门激励和声道响应的卷积,二者不是线性关系,无法进行加法运算,但是取对数之后,可以变成线性叠加关系,这叫同态处理[9]。对语音信号进行预加重,提升高频成分,然后进行快速傅里叶变换,计算谱线能量,计算通过美尔滤波器的能量,取对数,用离散余弦变换(DCT)求倒谱,这样就得到了MFCC系数[11-12]。
频谱分析模型的共同问题都在于声源信号的有效控制,如果用L-F Model等周期性声门脉冲作为声源信号,合成的语音存在无法消除的金属声,另外,声源和共鸣无法彻底分离[13]。
3.2 共振峰模型
共振峰模型是在频域上特定位置构造极点和零点,模拟共鸣和反共鸣。共振峰合成器有3种类型,共鸣器并联组合的PAT合成器,共鸣器串联组合的OVE合成器,共鸣器串并联组合的 Klatt合成器[2,4,14],Klatt合成器的DECTalk版本是最成功的共振峰合成器。
Klatt合成器的浊音声源可以是自然声源(声带震动)的采样信号(语音波形逆滤波),也可以是理想声源信号(如L-F Model),Klatt合成器的清音声源是由随机数产生的噪声声源。共鸣效果用数字共鸣器(滤波器)实现。Klatt合成器的数字共鸣器通过输入信号、前一个时刻的输出信号、前两个时刻的输出信号,三者相加来实现,如公式(1)所示,其中,A、B、C 系数由Gold和Rabiner给出的公式来计算,如公式(3)~(5)所示,PI是常数π,BW是带宽,F是共振频率,T是每个样本的时长[15]。其传递函数如公式(2),根据 A、B、C 的值,可以画出共鸣器的频率响应曲线。
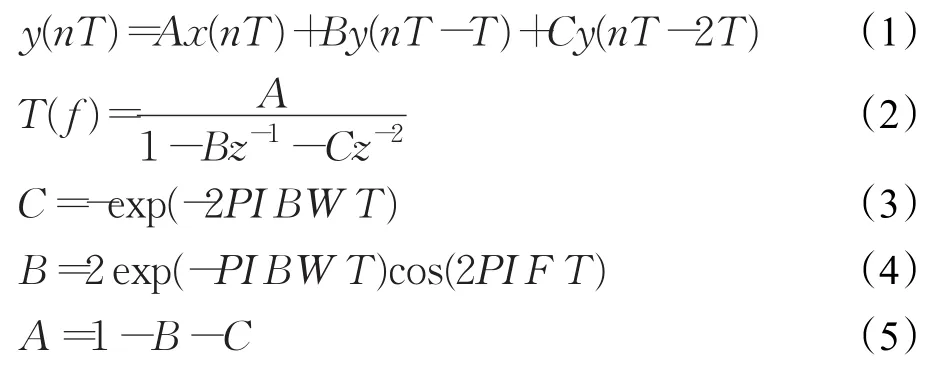
Klatt合成器可以单独用并联共鸣器组,也可以用串并联共鸣器组,共鸣效果取决于预先设置的共振频率、带宽和增益,这些特征值以参数的形式传递给程序。根据读入的每帧参数数据,按照公式(3)~(5)计算各个共鸣器的A、B、C系数值,然后,这些A、B、C系数值分别被送入各个共鸣器,根据公式(1)进行计算,产生样本数据。一般情况下,语音信号在10 ms时间内频谱稳定,因此每帧参数通常持续10 ms,如果采样频率设置为16 000 Hz,那么每组参数要产生(16 000/1 000)×10=160个样本,也就是说,需要循环160次进行共鸣运算。各个共鸣器的输出信号进行叠加产生的样本就是合成出来的语音波形数据[16]。
共振峰发音模型的优点在于语音学意义非常清晰,各个语音学特征值可以自由调整,并且可以合成出理论上存在而现实中没有的语音。其缺点在于合成的语音不够自然,与真实语音存在无法消除的差别,另外,参数的准确提取非常困难,参数设置非常复杂,通常需要手动反复尝试。
3.3 生理发音模型
生理发音模型认为传统声源-滤波模型是一种线性模型,这种线性模型把声源的发声和声道的调音当成了两个独立的系统,在某种程度上,这种假设限制了共振峰合成器的语音质量。因此,生理发音模型反对频域分离方法,提出了时域模拟思想,尝试建立符合发音生理过程的语言发音模型。
早在1959年,Flanagan就提到了一种基于生理发音原理的声道合成器[17]。1962年,Kelly和Lochbaum提出了Kelly-Lochbaum声道计算模型[18]。1969年,言语产生的生理发音模型基本形成,Flanagan提出了用声门下压(subglottal pressure)、声带张力(vocal-cord tension)和声道形状(vocal-tract shape)三个生理因素,合成所有语音的目标[19]。1960年代到1980年代,Coker、Mermelstein、Rubin、Maeda等人加入了生理发音模型研究的行列。生理发音模型的早期语言发音理论框架主要体现在Maeda和Rubin的研究论文当中。
根据Maeda的描述[20-21],生理发音模型包含一个气流恒压源,一个时变声门,两个管子,一个代表口腔,一个代表鼻腔。有两个规则,一个是空间矩形规则,是指某个变量在一个空间段内的积分值等价于空间中点的积分值乘以空间长度,一个是时间梯形规则,是指某个变量在一个时间段内的积分值等价于下限积分值和上限积分值的平均值乘以时间长度,通过这两个规则,制约声波产生和传播的原理,被转换成了离散变量表征的声学方程。由于频率曲变(frequency warping),这种离散化处理引起了频谱变形,频率曲变程度取决于采样频率和空间取样间隔。Maeda以20 kHz的采样频率和1 cm的空间取样间隔,合成了11个法语元音。尽管频谱的第三共振峰有明显变形,这些元音听起来还是很自然,很清晰。当采样频率等于40 kHz的时候,4 kHz以下的频谱变形几乎可以忽略。在Maeda的发音模型中,没有独立的声带模型,而是把声门面积变化的时间函数看作声道面积函数的一部分。在Maeda的发音模型中,也没有考虑声道中噪声的产生方式,而是通过平均体积速度和截面积,估计特定位置噪声信号的大小。
根据Rubin的描述[22],ASY生理发音模型的声道传递函数的计算方法来自于Kelly-Lochbaum模型。利用ASY的言语动作模型,把声道近似等间距(缺省模式0.25 cm)分段,每一段作为一个均匀声管,中线的长度代表声道的长度,然后根据文献所提供的每段声道的形状,计算声管截面积。根据Kelly-Lochbaum模型,利用声管截面积计算声道传递函数。用特定波形信号作为声源激励,激励信号输入到声道传递函数,就可以产生语音信号波形。
图1[22]是声道等效电路。

图1 声道等效电路
图1中的(a)图是浊音和送气音的等效电路模型,经过诺顿等效变换之后,可以看出其传递函数是:

这个公式反映了浊音和送气音的输出声压pm+pn和声门激励Ug之间的关系。图1中的(b)图是擦音的等效电路模型,其传递函数是:
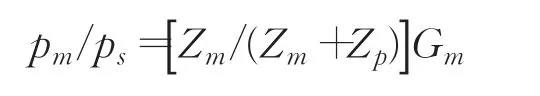
这个公式反映了擦音的输出声压pm和擦音声源的声压之间的关系。根据前面两个公式,只要计算出相应的阻抗Z和增益G,就可以根据声源信号波形,计算输出信号声压。每段声管n的阻抗为:
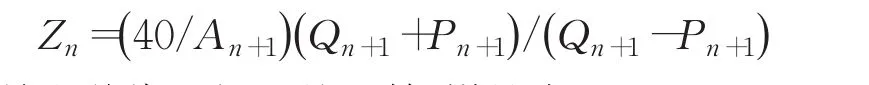
这是声道截面积A的函数,增益为:

其中,α1/2=1-0.007/是传输损耗

也是声道截面积A的函数。根据声源阻抗和辐射阻抗,利用如下公式:
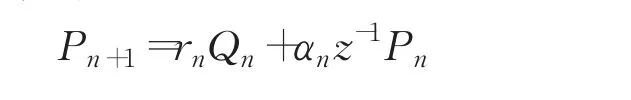
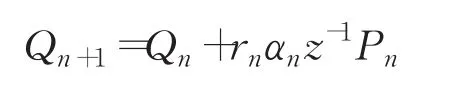
逐段迭代,计算各段声管的阻抗和增益,利用传递函数,就可以得到输出信号声压。
Kelly-Lochbaum模型经过Liljencrants的发展,在生理语音合成领域被广泛应用,称为RTLA(Reflection Type Line Analog)模型,这个模型的特点是在时域逐段声管计算声波前后传递的声压和气流,其缺点在于计算过程中声管长度必须固定,无法处理那些引起声管长度改变的语音序列,如从[u]到[i],从[a]到[u]等[23]。
1987年,Sondhi和Schroeter提出了时域和频域混合的生理发音模型。用非线性声带振荡器模型作为激励信号,这个信号依赖于声门上压,体现了声道和声源的耦合,这是与声源-滤波模型的根本不同之处。用噪声信号作为送气音和擦音声源,信号强度取决于雷诺数。利用频域模型分析声道(包括口腔和鼻腔),利用时域方法处理声门。文中提到了生理发音模型的两种计算声道传递函数的方法,Flanagan和Maeda用的是第一种方法,利用微分方程对声门和声道进行建模,这种方法需要求解大量线性或非线性方程,计算量太大;第二种方法是Kelly-Lochbaum模型,这种方法把声道当成数字传输线,分析声波的前后传播,计算速度较快。然而,时域和频域混合方法却不同于这两种方法,而是把频域声道信号通过傅里叶逆变换转变到时域,然后和时域声门信号进行数字卷积。这个发音模型把声道分成了4个区域:KG从声门到软腭,KN从软腭到鼻孔,KC从软腭到收紧点,KL从收紧点到双唇,每个区域对应一个包含A、B、C、D函数的频域矩阵。这种方法的优势在于可以利用发音器官形状码本[5]。
1988年,出现了一种简化声道计算的有争议的Distinctive Regions and Modes(DRM)理论[24-26]。该理论把声道分成了8个对称的区域,各区域占整个声道长度的比例分别为:1/10,1/15,2/15,2/10,2/10,2/15,1/15,1/10。在每个区域中,对应于声道截面积的增大(或减小),共振峰 F1、F2、F3增大(或减小),并且与敏感函数成比例,所谓敏感函数是指均匀声管中声波的动能减去势能,其原理如图2[26]所示。
尽管DRM有争议,生理语音合成器的商业化软件GNUSpeech的声道模型却基于DRM。HILL等人运用声管共鸣原理和DRM理论设计了一个生理发音模型,并用于GNUSpeech。这个模型把口腔和咽腔分成10段等长均匀声管,中间的第4和第5段连在一起对应于DRM的第4区,第6和第7段连在一起对应于DRM的第5区,鼻腔分成6段[27]。这个模型利用声管共鸣模型TRM(Tube Resonance Model)[28]和特异区域模式DRM,并借助双向延迟线,分析声音在声道中的传播过程,实现了声道形状和波形输出的精确控制。

图2 DRM模型
4 言语动作模型
言语动作模型研究发音的生理过程,利用图像信号处理技术重构发音器官的发音动作。言语动作模型主要研究主动发音器官的动作,如双唇、下颌、舌头、软腭、声带等。舌头、软腭和声带通常无法直接观察,需要借助X光成像、磁共振成像、超声、腭位照相、动态腭位记录、光纤维喉镜等技术,捕捉它们的运动过程。
根据建模方法的不同,言语动作模型可以分为3类:生理机能模型、几何特征模型、统计参数模型。
4.1 生理机能模型
生理机能模型利用生理结构分析的方法,研究发音器官的组织结构形式和肌肉运动过程,通常运用3D建模技术,构造三维动态模型。
最早建立生理机能模型的是Perkell。在博士论文中,他描述了一个舌头动态生理调音模型,这是一个中矢面二维功能性模型,输入和输出都是可以测量的生理变量,这个模型包括16个相互连接的承载质量的fleshpoints模型,这些fleshpoints通过38个主动拉力元素,47个被动拉力元素,连接到骨质成分上。张力、体积守恒力、滑动摩擦力和硬结构抗穿透力作用到fleshpoints模型上,决定它们的运动方式[29]。
Wilhelms-Tricarico利用有限元方法建立了三维生理发音模型。他在1995年的论文中提到:用有限元方法,建立双唇、舌头等软组织在言语产生中的生物力学模型,通过求解拉格朗日运动方程的方法,计算这些软组织的位移和形变,他预期中的生理发音模型包括6个部分:下颌、舌体、舌叶、双唇、软腭咽腔接口、咽腔,但是最终只用8条肌肉建立了一个舌头模型[30-31]。
Honda等构造了一个双唇发音模型通过唇肌肉收缩模式到唇轮廓形变过程的线性映射建立模型,用多元线性回归分析,估计唇轮廓上7个点的x、y坐标。肌电信号分析表明存在唇型的肌肉群组选择模式,闭唇是中性唇形,唇轮匝肌OOI和降下唇肌DLI的共同收缩产生了圆唇的各种形变,OOI有两层,分别是边缘层(marginal layer)和周围层(peripheral layer),在突唇动作中,OOI的周围层活动增强[32]。
Dang等人建立了一个三维生理发音模型(如图3[33]),包括下颌、舌头、双唇、牙齿、硬腭、软腭、咽腔壁、喉等器官。对双唇和软腭没有进行生理建模,而是用一个可变长度和截面的短管代表双唇,用鼻腔和咽腔接口面积大小表示软腭的运动。用粘弹圆柱代替弹簧振子对舌头进行建模,用基于分布的有限元方法提高建模的准确性。研究表明发音器官的空间位置和肌肉拉力存在唯一不变映射关系,主动肌和拮抗肌的协同收缩,可以控制舌尖和舌背到达各自的目标位置[33-34]。

图3 Dang的声道模型
Wu等人采用计算机仿真的方法对言语产生过程中控制发音器官运动的肌肉协同工作方式进行了探索,用有限元方法(Finite Element Method),建立了一个可以模仿人类发音器官动作的生理模型,该模型包括舌头、下颌骨、舌骨、声道壁等发音器官,以及控制发音器官运动的肌肉组织,此外,他们还建立了一套模型的自动控制方法,使模型可以用于探索人类言语产生的生理机制。自动地找到一组肌肉激活模式,并控制模型达到目标位置,这是设计的难点,Wu等人已经研究出一套自动控制的方法,可以对模型进行有效控制[35]。
Steiner等人运用多重线性形状空间模型,开发了一个端到端的系统,在这个系统中,发音人参数决定了舌头的解剖特征,姿势参数代表了发音动作相关的形状特征,解剖特征和形状特征映射到多边形网格,形成三维舌头结构。该系统首先应用传统HTS(隐马语音合成)方法融合语音和动作两个模态,然后把两个模态分离,调整多重线性舌头模型,使其适应TTS过程,从而直接从文本合成出语音和三维舌头发音动作[36]。
生理机能模型模拟了发音器官的肌肉活动方式,但是由于模型的生理解剖参数难以获得,并且控制方式过于复杂,这种模型产生的发音动作准确度并不高。
4.2 几何特征模型
几何特征模型不注重发音器官内在的生理组织结构,而是更关注发音器官外在的形状轮廓,以及这些形状轮廓之间的变化关系,尝试用简约的线条描述发音器官的运动方式。
1971年,Lindblom等建立了一个几何特征模型,通过指令控制发音器官动作产生元音,这个模型包括5个发音器官:双唇、下颌、舌尖、舌体和咽喉,在这个模型中,下颌是区分不同元音的主要因素,语音动作通过发音省力原则进行优化,语音音质运用最大感知对立算法进行优化[29,37]。
Coker建立的调音模型包括4部分:(1)接近真实发音的调音系统;(2)发音状态之间插值的器官动作约束系统;(3)声源激励系统,包括:声门下压、声带夹角、声带张力3个子成分;(4)发音指令转化为发音动作的控制系统。这个模型的发音器官动作方式如图4[38]所示。
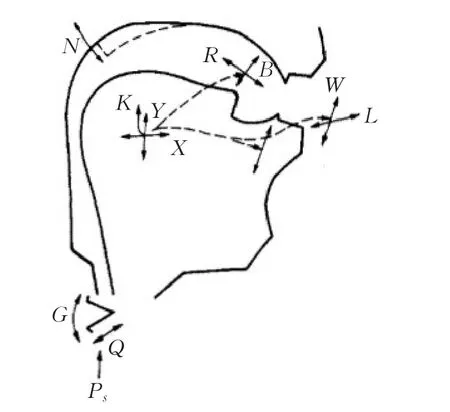
图4 Coker的声道模型
这个模型的舌体轮廓是一段圆弧,用两个坐标控制发元音时舌体的位置,以及下颌转动角度,用一个参数控制快速运动的辅音发音时舌头的位置,用5个参数控制其他辅音发音时舌头的位置,用两个参数控制舌尖的抬升和卷舌,还有两个参数控制闭唇和圆唇。这个模型有两种合成语音的算法,一种是用Flanagan-Ishizaka发音模型直接计算声压,一种是用迭代算法通过声道形状计算共振频率,然后驱动共振峰合成器产生语音[38-39]。
Mermelstein建立了声道调音模型ASY,这个模型和Coker的模型大同小异,Coker的模型强调基于规则的合成,而ASY更强调对咽喉以上调音器官的配置,以及交互式的系统性控制。这个模型的发音器官动作方式如图5[40]所示。
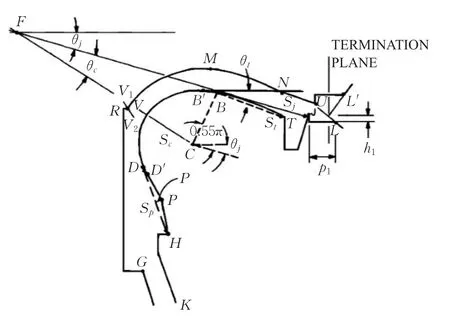
图5 Mermelstein的声道模型
ASY有6个发音器官:舌体、软腭、舌尖、下颌、双唇、舌根骨,这些器官分成了两组,一组能够独立运动,包括:下颌、软腭和舌根骨;另一组不能独立运动,包括舌体、舌尖和双唇,这3个器官的位置都依赖于下颌,舌尖的位置依赖于舌体。下颌和软腭的运动只有一个自由度,其他器官的运动都有两个自由度。软腭的运动既可以改变口腔声道的形状,也可以影响鼻咽耦合的程度。通过拼接准静态声道冲激响应的方式合成语音,元音依赖于下颌、舌体、双唇、软腭的位置,辅音取决于发音器官状态变化,这种变化是由底层元音为了满足发音位置约束而引起的,ASY用一段圆弧代表舌体轮廓[22,40]。其改进版本是CASY,用一条二次曲线代表舌体轮廓[41]。Birkholz等人对这个模型进行了改进,尝试在二维中矢面模型基础上,建立三维模型[7]。
几何特征模型的发音器官形状由简单的几何图形构成,并非真实的发音动作,尽管便于调整,但是经常出现超越生理极限的动作。
4.3 统计参数模型
统计参数模型通常用主成分分析、线性成分分析、回归分析、多层神经网络等统计方法建立发音器官模型,声道形状和控制参数都依赖于统计结果。
基于Maeda发音模型的VTDemo,是介于几何特征模型和统计参数模型之间的类型,虽然这个模型对声道参数进行了因子分析统计建模,但是整个声道形状依然是几何线条结构。Maeda建立发音动作模型的方法是用固定的半极坐标网格从声道中选取样本点,然后做因子分析,得到统计参数,如图6[42]所示。
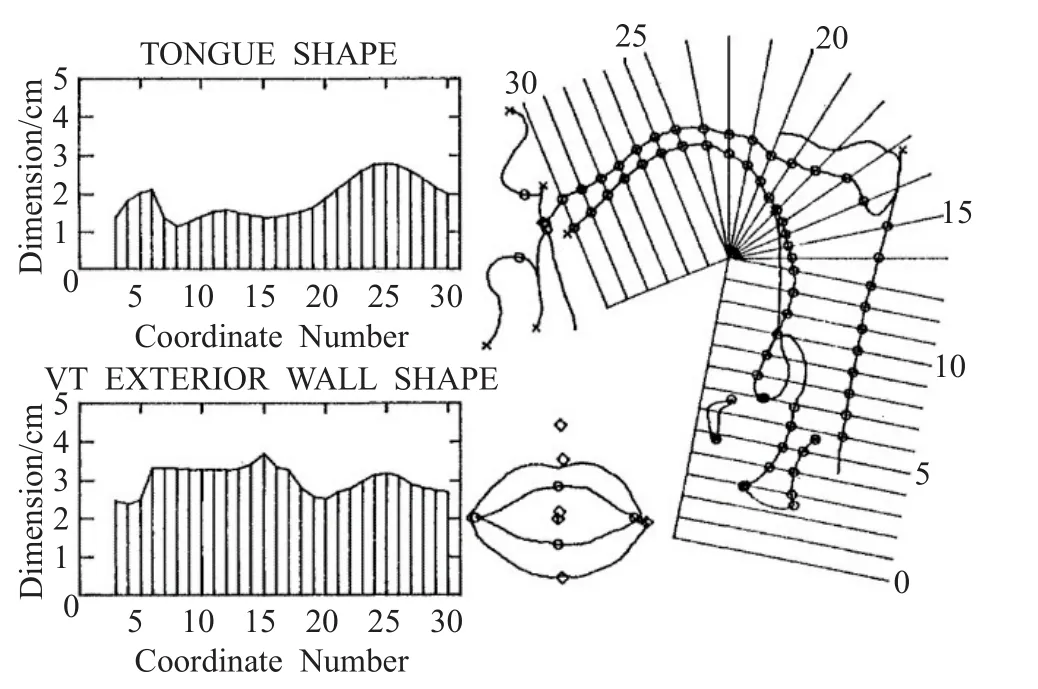
图6 Maeda模型的声道样本选择方法
在Maeda的模型中,舌头选了25个样本点,双唇选了4个样本点,咽喉选了5个样本点,经过因子分析之后,舌头有3个因子,双唇有2个因子,咽喉有1个因子。另外,下颌选了1个样本点,声道壁选了25个样本点,这些点没有做因子分析。这个模型有10个参数,分别控制下颌高度、舌体位置、舌头形状、舌尖前后、开口程度、突唇程度、喉头高度、声门面积、基频大小、鼻咽接口。Maeda的模型是静态发音模型,在应用过程中,可以灵活调整参数,然后根据因子分析的结果,用回归方程计算参数调整之后的声道的形状分布,各个样本点的回归算法如下:参数和对应的因子载荷相乘,再累加,然后再乘以标准差,最后加上样本点的平均值。这个模型的研究结果表明,在代偿发音中,为了得到相同的F1-F2模式,发前元音时下颌高度仅能通过舌体位置代偿,发后元音时下颌高度仅能通过开口程度代偿[21,42]。
Laprie和Busset用主成分分析法对X-ray和MRI图像进行了分析,建立了二维发音模型。对比Maeda模型而言,这个模型更接近统计参数模型。这个模型和Maeda模型的不同之处在于发音器官形状完全来自于统计参数,Maeda模型只有3个舌头因子,这个模型却有6个控制舌头的线性成分,能够精确匹配各种元音和辅音的原始X-ray和MRI图像。舌头轮廓取样的参照标准和Maeda模型也不同,不是半极坐标网格,而是曲线坐标。另外,这个模型建立了旋转算法,能够适应不同发音人的声道图像[43-44]。
Badin等人用主成分分析法[45]和线性成分分析法[46],对X-ray和MRI图像中的声道进行了建模。这个模型的2D版本用3个参数(LH、LP、LV)控制突唇、圆唇、翘唇等动作;用4个参数(JH、TB、TD、TT)控制下颌位置和舌头形状;喉头高度和唇参数有相关性,可以用一个参数(LY)控制喉头高度;舌根骨的水平位置和下颌高度有很强的相关性,然而舌根骨的竖直位置和喉头高度有更强的相关性,因此用一个参数(TA)就可以控制舌根骨[47]。这个模型还有一个3D版本,是先前2D中矢面模型的扩展,是同一个发音人的声道模型。利用这些模型,研究者分析了原始语音的共振峰,2D声道模型计算的共振峰,以及3D声道模型计算的共振峰,结果发现三者之间差别很小。优化的2D模型对声道面积函数的计算相当准确。另外,研究者发现用2D中矢面生理发音模型的命令参数可以驱动3D生理发音模型[45]。
统计参数模型针对真实的发音器官动作进行建模,符合发音器官的运动规律,但是建模样本特征点的自动提取技术很复杂,通常需要手工测量,限制了样本的数量,另外发音器官动作通常无法灵活调整。
5 结束语
语言发音模型研究非常重要,因为语言发音模型不仅可以用于发音过程研究,揭示发音规律,促进语音合成技术的发展;而且还可以用于语言教学,无论是针对听障儿童,还是针对二语习得,发音器官动作示范,对于学习语言的重要性,已经反复被各种实验所证实。
言语声音模型研究曾经是语音合成技术的必要基础。然而,随着波形拼接语音合成技术的发展,言语声音模型研究逐渐退出了工程实践领域。近年来,情感语音合成受到关注,逐渐暴露了波形拼接技术的内在缺陷,言语声音模型研究再次引起普遍重视,共振峰语音合成和生理语音合成有望突破技术瓶颈,达到情感语音合成的目标。
言语动作模型研究由于技术条件的限制进展缓慢。近年来,由于核磁共振成像技术飞速发展,拍摄清晰的连续的发音器官动作图像,逐渐变得可行,舌头和软腭等发音器官的发音动作研究在未来几年将取得重大突破。
语音的个性特征,以及情感特征,与声门波形和频谱包络的关系,及有效控制,是未来研究的重点和难点。统计建模、规则控制和深度学习相结合,是未来发展的趋势。
[1]Goldstein L,Fowler C A.Articulatory phonology:A phonology for public language use[C]//Schiller N O,Meyer A S.Phonetics and Phonology in Language Comprehension and Production,2003:159-207.
[2]吕士楠.汉语语音合成:原理和技术[M].北京:科学出版社,2012:4-6.
[3]Stevens K N.Acoustic phonetics[D].Massachusetts Institute of Technology,1998.
[4]Klatt D H.Software for a cascade/parallel formant synthesizer[J].Journal of the Acoustical Society of America,1980,67(3):971-995.
[5]Sondhi M M,Schroeter J.A hybrid time-frequency domain articulatory speech synthesizer[J].IEEE Transactions on Acoustics Speech&Signal Processing,1987,35(7):955-967.
[6]Theobald B.Audiovisual speech synthesis[C]//International Congress on Phonetic Sciences,2007:285-290.
[7]Birkholz P,Jackel D,Kroger B J.Construction and control of a three-dimensional vocal tract model[C]//Proceedings of the International Conference on Acoustics,Speech,and Signal Processing,Toulouse,2006:873-876.
[8]Oppenheim A V,Schafer R W.Homomorphic analysis of speech[J].IEEE Transactions on Audio&Electroacoustics,1968,16(2):221-226.
[9]Oppenheim A V.Speech analysis-synthesis system based on homomorphic filtering[J].Journal of the Acoustical Society of America,1969,45(2):458.
[10]Coleman J.Introducing speech and language processing[M].Cambridge:Cambridge University Press,2005:79-83.
[11]Pols L C W.Spectral analysis and identification of Dutch vowels in monosyllabic words[D].Amsterdam The Netherlands:Free University,1977.
[12]Zheng Fang.Comparison of different implementations of MFCC[J].Journal of Computer Science and Technology,2001,16(6):582-589.
[13]Taylor P.Text-to-speech synthesis[M].Cambridge:Cambridge University Press,2009:408-409.
[14]Klatt D H,Klatt L C.Analysis,synthesis,and perception of voice quality variations among female and male talkers[J].Journal of the Acoustical Society of America,1990,87(2):820-857.
[15]Gold B,Rabiner L R.Analysis of digital and analog formant synthesizers[J].IEEE Transactions on Audio&Electroacoustics,1968,16(8):81-94.
[16]张金光.视听言语合成技术综述[J].电声技术,2017,41(z2):103-107.
[17]Flanagan J L.Estimates of intraglottal pressure during phonation[J].Journal of Speech& Hearing Research,1959,2(2):168-172.
[18]Kelly J L,Lochbaum C.Speech synthesis[C]//Proceedings of the Stockholm Speech Communications,Stockholm,1962:1-4.
[19]Flanagan J L,Cherry L.Excitation of vocal-tract synthesizers[J].Journal of the Acoustical Society of America,1969,45(3):764-769.
[20]Maeda S.A digital simulation method of the vocal-tract system[J].Speech Communication,1982,1(3):199-229.
[21]Maeda S.Improved articulatory models[J].Journal of the Acoustical Society of America,1988,84(S1):146.
[22]Rubin P,Baer T,Mermelstein P.An articulatory synthesizer for perceptual research[J].Journal of the Acoustical Society of America,1981,70(2):321-328.
[23]Kroger B J,Birkholz P.Articulatory synthesis of speech and singing:state of the art and suggestions for future research[C]//Multimodal Signals:Cognitive and Algorithmic Issues,2009:306-319.
[24]Mrayati M,Carre R,Guerin B.Distinctive regions and modes:A new theory of speech production[J].Speech Communication,1988,7(3):257-286.
[25]Mrayati M,Carre R,Guerin B.Distinctive regions and modes:Articulatory-acoustic-phonetic aspects:A reply to Boe¨and Perrier’s comments[J].Speech Communication,1990,9(3):231-238.
[26]Boe L J,Perrier P.Comments on“distinctive regions and modes:A new theory of speech production” by M Mrayati,R Carre and B Guerin[J].Speech Communication,1990,9(3):217-230.
[27]Hill D R,Taubeschock C R,Manzara L.Low-level articulatory synthesis:A working text-to-speech solution and a linguistic tool[J].Canadian Journal of Linguistics,2017,62(3):1-40.
[28]Manzara L C.The tube resonance model speech synthesizer[J].Journal of the Acoustical Society of America,2009,117(4):2541.
[29]Perkell J S.A physiologically-oriented model of tongue activity in speech production[D].Massachusetts:Massachusetts Institute of Technology,1974.
[30]Wilhelms-Tricarico R.Physiological modeling of speech production:Methods for modeling soft tissue articulators[J].Journal of the Acoustical Society of America,1995,97(1):3085-3098.
[31]Gerard J M,Wilhelms-Tricarico R,Perrier P,et al.A 3D dynamical biomechanical tongue model to study speech motor control[J].Physics,2006,1:49-64.
[32]Honda K,Kurita T,Kakita Y,et al.Physiology of the lips and modelingof lip gestures[J].Journal of Phonetics,1995,23(1):243-254.
[33]Fang Q,Dang J.Speech synthesis based on a physiologicalarticulatory model[C]//Chinese Spoken Language Processing.Berlin Heidelberg:Springer,2006:211-222.
[34]Dang J,Honda K.Construction and control of a physiological articulatory model[J].Journal of the Acoustical Society of America,2004,115(2):853-870.
[35]Wu X,Dang J,Stavness I.Iterative method to estimate muscle activation with a physiological articulatory model[J].The Acoustic Society of Japan,2014,35(4):201-212.
[36]Steiner I,Maguer S L,Hewer A.Synthesis of tongue motion and acoustics from text using a multimodal articulatory database[J].IEEE/ACM Transactions on Audio Speech&Language Processing,2016,25(12).
[37]Lindblom B E,Sundberg J E.Acoustical consequences of lip,tongue,jaw,and larynx movement[J].Journal of the Acoustical Society of America,1971,50(4):1166.
[38]Coker C H.A model of articulatory dynamics and control[J].Proceedings of the IEEE,1976,64(4):452-460.
[39]Coker C H,Fujimura O.Model for Specification of the Vocal Tract Area Function[J].Journal of the Acoustical Society of America,1966,40(5):63-75.
[40]Mermelstein P.Articulatory model for the study of speech production[J].Journal of the Acoustical Society of America,1973,53(4):1070-1082.
[41]Iskarous K,Goldstein L M,Whalen D H,et al.CASY:The haskins configurable articulatory synthesizer[C]//15th ICPhS Barcelona,2003.
[42]Maeda S.Compensatory articulation in speech:Analysis of x-ray data with an articulatory model[C]//European Conference on Speech Communication and Technology(Eurospeech 1989),Paris,France,1989:2441-2445.
[43]Laprie Y,Busset J.Construction and evaluation of an articulatory model of the vocal tract[C]//European IEEE Signal Processing Conference,2011:466-470.
[44]Laprie Y,Vaxelaire B,Cadot M.Geometric articulatory model adapted to the production of consonants[C]//International Seminar on Speech Production,2014.
[45]Badin P,Bailly G,Raybaudi M,et al.A three-dimensional linear articulatory model based on MRI data[C]//The International Conference on Spoken Language Processing,Incorporating the Australian International Speech Science and Technology Conference,Sydney Convention Centre,Sydney,Australia,1998:533-553.
[46]Badin P,Elisei F,Bailly G,et al.An audiovisual talking head foraugmented speech generation:Models and animations based on a real speaker’s articulatory data[J].Articulated Motion&Deformable Objects,2008:132-143.
[47]Beautemps D,Badin P,Bailly G.Linear degrees of freedom in speech production:Analysis of cineradio-and labiofilm data and articulatory-acoustic modeling[J].Journal of the Acoustical Society of America,2001,109(5):2165-2180.
