统一着色架构3D引擎关键技术研究
2018-06-20韩立敏
邓 艺,田 泽,韩立敏
(中航工业西安航空计算技术研究所,陕西 西安 710065)
1 概 述
统一着色架构是现代图形处理器(graphics processing unit)的主要实现方式,是实现计算机图形学领域众多算法和策略的平台,具备并行处理及快速构建2D、3D图形,场景和渲染的能力[1]。
统一着色架构的3D引擎作为GPU的核心部件,是完成3D图形、图像加速计算的基础,其架构设计如图1所示。它通过统一架构的图形流水线,实现图形绘制和渲染功能,将自图形流水线中输入的一系列离散的顶点任务渲染为可在屏幕显示的连续像素块,输出到显示存储单元中。
统一着色架构3D引擎基于单一着色器分时处理顶点任务或像素任务的特性,通过任务调度策略对着色器执行任务的分配和着色器资源的统一管理,实现对着色器资源的高效利用,从而提高系统处理性能。同时由于执行单元和配套资源的共享化,以及针对不同的渲染任务设计统一的执行单元、相应接口以及操作方式,在一定程度上简化了软、硬件开发流程。统一着色架构使GPU更加灵活,可编程性大大提升[2-3]。
统一着色架构3D引擎的并行处理通过三级层次结构组织实现[4]。在最底层,由着色器核构成流处理器(stream processor,SP),以单指令多数据(single instruction multiple data,SIMD)或单指令多线程(single instruction multiple threads,SIMT)方式执行操作。在中间层,SIMD(或SIMT)执行架构的多个SP被组织成流多处理器(stream multiprocessor,SM),其局部存储可被组内SP快速访问。在顶层,3D引擎由多个SM单元组成,并连接到全局图形存储器。

图1 统一着色架构3D引擎架构框图
统一着色架构的3D引擎在带来较高图形处理性能的同时,也对其设计提出了挑战。首先,作为统一着色架构3D引擎最基本的计算单元,统一着色器主要完成顶点、像素的统一着色功能,是影响3D引擎计算性能的关键因素。众多统一着色器的组织方式,通过多级调度策略采用着色器资源两级分组管理、动态分配管理和统一调度实现,避免了资源分配不均,提高了性能/能耗比。此外,3D引擎多层次的存储结构与任务调度策略中的调度资源存在映射关系,因此存储系统的数据传输能力与系统整体性能密切相关。基于以上分析,多层次存储结构设计、多级调度策略和着色器体系结构设计作为影响单个着色器处理性能发挥及整体3D引擎数据吞吐率的重要因素,成为统一着色架构GPU研究的重点。
2 统一着色架构的存储层次
GPU的多核特性使其对存储通路的存储带宽有更高的要求,因此存储系统的数据传输能力与系统整体性能密切相关。统一着色架构3D引擎在提升系统处理能力的同时,也导致了更严重的“存储墙”问题,对存储系统提出了更高的要求[5]。
目前,在GPU硬件资源有限的条件下,提高存储带宽利用率,充分使用共享和复用减少对外部存储器的访问次数,成为“存储墙”问题通用的解决方案。统一着色架构3D引擎为减少各请求源对外部存储器的访问频率,减少DDR3存储通路的带宽压力,采用层次化的存储结构,存储架构如图2所示。
其中L0层是各请求源内部的寄存器级缓存,具有速度快、容量小的特点,访问最频繁;L1层主要包括单个SM级的本地存储和L1Cache;L2层主要包括所有SM能够共享的着色程序存储器、纹理Cache的二级缓存;L3层是两条数据位宽的独立通路,组成DDR存储访问与控制,用以访问片外存储,其访问速度最慢、容量最大[6]。
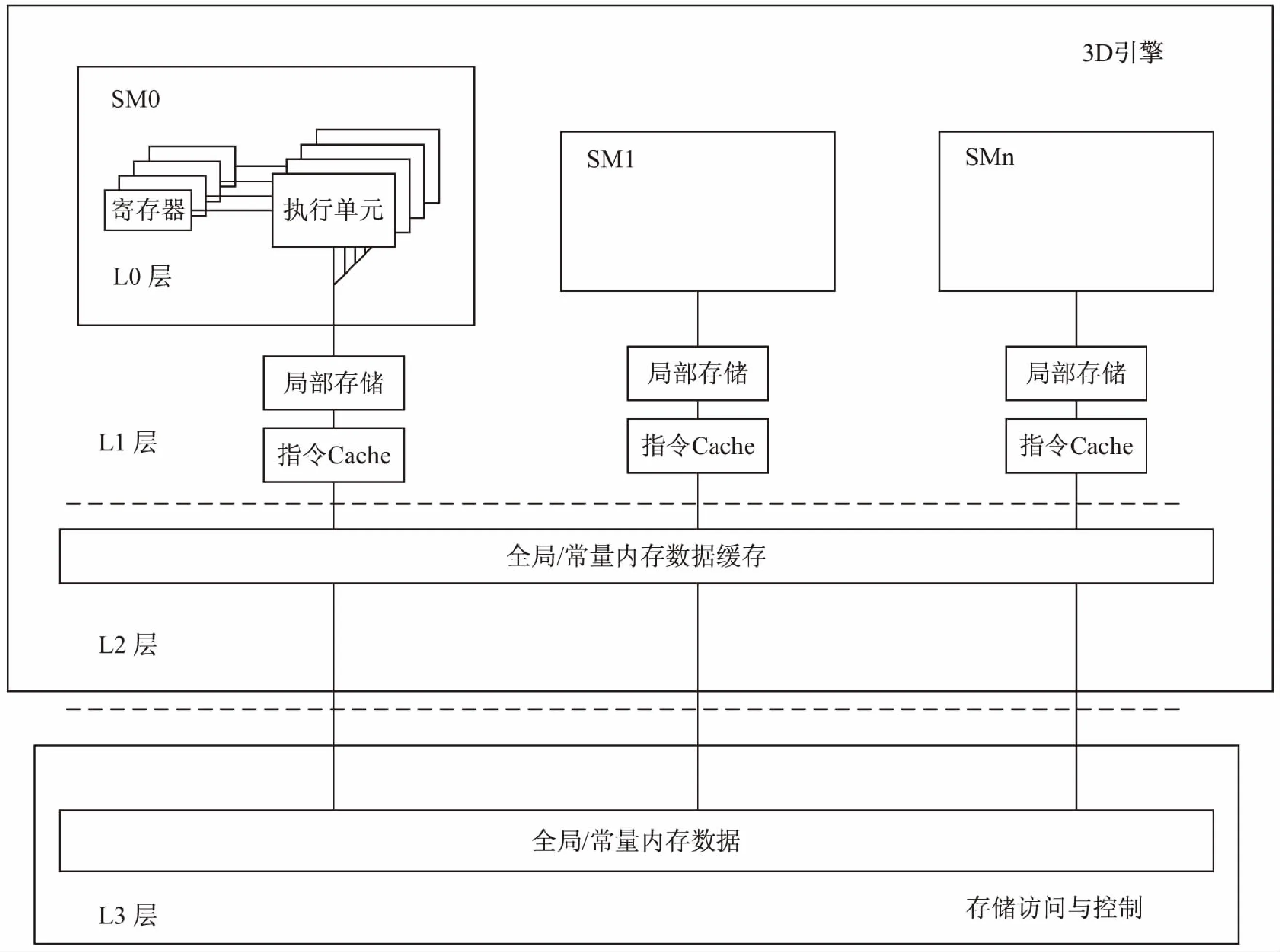
图2 统一着色架构的多层次存储架构
2.1 统一着色器的设计
统一着色器的设计主要包括指令集定义、数据通路设计、着色器架构、具体运算单元设计以及多个着色器的执行架构等方面。
统一着色架构的指令集定义遵循通用和高效的原则。在通用性方面,应基于OpenGL 2.0等相关通用标准,以及上文对统一着色器实现具体顶点、像素运算的内容分析,定义基本的常用运算指令、基于图形特性的特殊函数指令以及提升着色器效率的其他指令;在高效性方面,通过指令集的优化设计提升着色器的流处理特性来发挥其强大的运算优势[7]。
统一着色架构将统一着色器和特殊功能单元(special function unit,SFU)的数据通路相结合,其设计包括加法单元、乘法单元、乘加单元、移位单元、累加单元、浮点加法单元、浮点乘法单元等[8]。
统一着色器核主要包括取指令单元、译码单元、Register file、本地数据存储器、各种运算单元及输出寄存器,其体系结构设计如图3所示。
为提升3D引擎的并行性及数据吞吐量,单个SM处理器内部的多个着色器的执行架构采用单指令多数据(single instruction multiple data,SIMD)或单指令多线程(single instruction multiple threads,SIMT)架构组织实现,从而最大化地实现运算单元的复用。与传统的标量执行模式相比,SIMD和SIMT架构都能够实现数据的并行执行操作,标量架构的执行域以单一数据为基本单位,SIMD架构的执行域以一元向量为基本单位,SIMT架构的执行域以矩阵为基本单位。
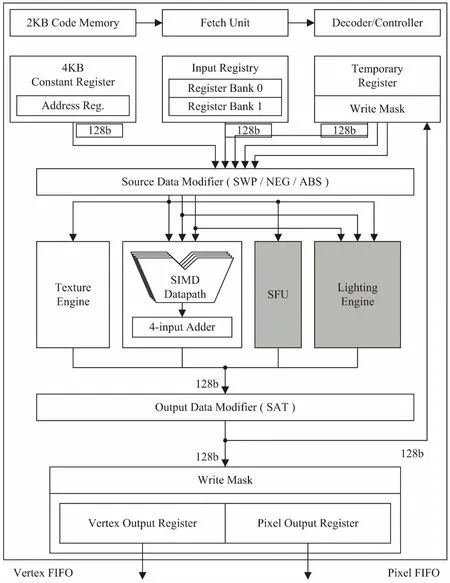
图3 统一着色器设计架构
SIMD结构有利于对向量和数组进行数据的并行计算,但同时也制约了它进行有效的多线程计算。GPU中的“硬件多线程”主要采用少数指令对大量数据进行操作的方式实现。在商用设计领域,NVIDIA将芯片架构逐步转向了SIMT模式。有别于AMD的SIMD架构,SIMT的优势在于数据无需凑成合适的矢量长度,同时SIMT允许每个线程有不同的分支。由于条件跳转会根据输入数据不同在不同的线程中有不同表现,纯粹使用SIMD无法实现并行执行有条件跳转的函数,而SIMT架构则能够实现。然而,SIMT架构的SM硬件设计结构较之SIMD更复杂,控制逻辑设计难度更高。AMD的SIMD架构可以用少量的晶体管构建庞大数量的流处理器,从而拥有强大的理论浮点运算能力;而NVIDIA的SIMT架构的单个流处理器所需的晶体管更多,理论浮点运算能力也更强。相较而言,AMD以数量弥补效率的不足,而NVIDIA以效率弥补数量的劣势[9]。
2.2 统一着色架构调度策略
基于对3D引擎图形流水线的研究,统一着色架构之前的性能瓶颈主要在于像素着色阶段,即使分离可编程架构中将1∶3作为顶点与像素着色引擎的黄金比例,依然无法满足复杂多变场景的渲染需求,因此资源利用率不足成为限制GPU性能提升的关键[10]。作为支持多任务的计算平台,统一着色架构3D引擎中每个计算单元的任务处理效率可能不同,为充分利用系统资源,需要3D引擎具备监控以及动态调度计算核心的能力。同时,统一着色架构3D引擎的核心处理性能主要由其任务调度能力和各个流处理器核的执行能力表征,因而兼顾灵活、高效以及可靠的任务调度与资源分配方案是统一着色架构3D引擎的研究重点和关键技术。
在多任务环境下,图形处理系统通过多任务调度框架的多级调度设计,保证整个系统高效的调度效率和良好的图形处理性能,调度框架如图4所示。调度的对象是经过组装的一组固定格式的顶点或像素warp(又称wavefront)。

图4 GPU的多任务调度框架
当一部分任务分发至3D引擎之前,主机接口与前端处理模块首先接收任务输入,并通过分析多任务间的资源竞争问题[11],完成初步的多任务队列排序及任务的分发功能。在统一着色架构3D引擎内部,warp任务组装单元接收来自主机接口与前端模块的顶点任务输入,以及来自3D引擎内部其他模块的像素任务;全局任务调度单元接收组装完成的warp任务输入,对待分发任务进行统一分配、对所有执行单元任务执行状态进行统一调度管理,并采用各流多处理器(SM)内部的调度器,完成3D引擎内部的两级调度,最终实现对SIMD(或SIMT)架构的执行单元以及统一着色器的调度管理。同时全局任务调度层通过SM调度单元内部的统计与反馈,实现统一任务调度单元的实时、动态调度。
在多任务调度系统中,采用的调度策略主要分为以下几类[12-14]:
第一类是基于先到先服务(first come first served,FCFS)的简单调度策略,该调度策略便于实现,硬件资源占用较小,但无法适应统一着色架构对灵活的调度性能需求。
第二类采用完全公平调度策略(completely fair scheduling,CFS),使每个待调度任务公平地共享计算资源,同时以任务的优先级和任务运行时间作为调度的依据,在任务的优先级相同时,优先调度之前占用3D引擎执行时间较少的任务,既保证了调度的公平性又增加了灵活性,但未区分统一着色架构面向图形类应用和非图形类应用时不同的调度需求。
第三类采用基于分类和多优先级队列(class priority multiple queue,CPMQ)的多任务调度系统,面向图形应用、通用计算、实时着色等多种任务类型的调度需求,采用加权公平排队算法(weighted fair queuing,WFQ)对待分发任务进行排序,有效降低了图形任务的响应时间,提升了应用系统的图形用户体验。
依据上文对GPU调度框架的分析,3D引擎内部的调度策略可以分为两级,包括全局的任务调度和各SM内部的调度。全局的任务调度主要完成的功能包括对所有待处理任务的统计与排序,对待处理任务向各SM内部统一着色器的调度分发,以及对所有SM内统一着色器的执行状态和执行类型进行管理;各SM内部的调度策略为隐藏着色器执行操作中对各级存储的访问延迟而设计,通过单指令多周期执行和多个warp的调度切换来实现。
3 结束语
基于统一着色架构的3D引擎是当前图形处理技术的研究热点,它统一了上一代分离可编程架构中分离的顶点着色器和像素着色器,打破了因资源分配不均导致的性能瓶颈,同时对统一着色器、多层次任务调度策略和多层次存储架构等相关设计提出了更高的要求。
目前对这几项关键技术的研究已取得了一定的进展,向自主研制统一着色架构GPU的方向迈进了一大步,但在统一着色器的指令集设计、面向图形领域与通用计算领域的多任务并行调度,及统一着色架构GPU各类关键技术的性能评价体系等方面,仍需进行更深入的理论研究和优化设计。
参考文献:
[1] 田 泽,张 骏,许宏杰,等.图形处理器低功耗设计技术研究[J].计算机科学,2013,40(6A):210-216.
[2] 刘 坚.嵌入式多核GPU渲染流水线的研究与实现[D].成都:电子科技大学,2015.
[3] SHREINER D,WOO M,NEIDER J,et al.OpenGL编程指南[M].北京:人民邮电出版社,2007:23-51.
[4] PAUL B.Introduction to the direct rendering infrastructure[EB/OL].(2000-08-10)[2014-03-23].http://dri.sourceforge.net/doc/DRIintro.html.
[5] LINDHOLM E,NICKOLLS J,OBERMAN S,et al.NVIDIA Tesla:a unified graphics and computing architecture[J].IEEE Micro,2008,28(2):39-55.
[6] 卢 俊,颜 哲,田 泽.一种高效GPU存储系统体系架构设计[J].计算机技术与发展,2015,25(4):6-9.
[7] 黄伟钿.面向移动平台的3D图形处理器的设计[D].广州:华南理工大学,2011.
[8] WOO J H,KIM H,YOO H J.A low power multimedia SoC with fully programmable 3D graphics for mobile devices[J].IEEE Computer Graphics & Applications,2009,29(5):82-90.
[9] WOO J H,SOHN J H,KIM H,et al.A 152 mW mobile multimedia SoC with fully programmable 3D graphics and MPEG4/H.264/JPE[J].IEEE Transactions on Very Large Scale Integration Systems,2009,17(9):1260-1266.
[10] WANG P H,CHEN Y M,YANG C L,et al.A predictive shutdown technique for GPU shader processor[J].IEEE Computer Architecture Letters,2009,8(1):9-12.
[11] 丑文龙,梅魁志,高增辉,等.ARM GPU的多任务调度设计与实现[J].西安交通大学学报,2014,48(12):87-92.
[12] 宾雪莲,杨玉海,金士尧.一种基于分组与适当选取策略的实时多处理器系统的动态调度算法[J].计算机学报,2006,29(1):81-91.
[13] LIU Shuo,QUAN Gang,REN Shangping.On-line scheduling of real-time services for cloud computing[C]//Proceedings of the 2010 6th world congress on services.Washington DC,USA:IEEE Computer Society,2010:459-464.
[14] 刘加海,杨茂林,雷 航,等.共享资源约束下多核实时任务分配算法[J].浙江大学学报:工学版,2014,48(1):113-117.
