基于正则抽取的竹种数据结构化方法研究
2018-06-20李绍稳许高建林建彬
李 欣,李绍稳,许高建,林建彬
(安徽农业大学 信息与计算机学院,安徽 合肥 230036)
0 引 言
中国是世界竹林大国,在竹亚科植物的分类及种质资源保存上已经取得了举世瞩目的成绩。《中国植物志》、《中国竹类植物图志》和各地地方植物志文献的公开出版及《竹类研究会刊》等领域重点期刊集中报道了大量的竹类研究论文和著作,此外竹类植物相关的专业性网站也陆续上线,如中国竹网、中国竹子网等。这些文献及电子资源都极大地丰富了竹类研究领域的信息交流。然而随着数字化技术的发展,如何有效管理这些庞大的文献资源,将竹类种质资源的基础信息完整、准确、高效地保存下来,并实现在专业领域内的共享、交流和利用,成为竹亚科研究领域急需解决的问题。数据库是实现数据存储和共享的有效方式,构建竹类种质资源基础数据库势在必行。
目前竹类研究的文献及电子信息资源大都是没有结构的文本文档、半结构化数据或Web数据,而竹类植物的基础数据库字段设计复杂、属性维度高、数据采集量大,纯手工录入效率低[1]。信息抽取(information extraction)技术致力于从自然语言文本中获取结构化信息,已经成功地应用于情报检索、自动文摘、文本分类等多个领域。
信息抽取是指依据一定的规则实现从文本中抽取特定的内容(如实体、关系和事例等)得到结构化的数据,将抽取结果存储到数据库中或结构化文件中形成一个数据集,为后续的数据挖掘、信息检索和知识发现服务提供数据支撑[2]。著名的信息抽取会议(message understanding conferences,MUC)对信息抽取进行了严格的定义,指出信息抽取就是从一堆数据中提取特定内容填充给定的数据表结构模版的属性值[3]。一直以来,信息抽取技术就是文本挖掘和自然语言处理研究的热点问题,并有效解决了从海量知识中快速提取关键信息,从自由文档或半结构化文档中提取结构化数据的问题[4]。基于以上研究,文中提出一种基于信息抽取技术的竹种数据结构化方法,构建正则抽取模型,实现竹种基础数据库的快速构建。
1 方 法
1.1 信息抽取系统
信息抽取系统的任务是从指定文本中按照一定的规则提取特定的事实(命名实体、关系、属性值等)填充到预定义的数据库模板中[5]。抽取规则构建即抽取模式的获得,是构建信息抽取系统最重要的一个环节。依据抽取模式获取方法的不同,信息抽取方法可以分为两类:基于机器学习的方法和基于规则的方法[6]。机器学习方法的一般思路是先利用训练数据构建一个抽取模型,选择一种机器学习算法作用于训练数据得到模型的参数并完善模型,再用这个构建好的抽取模型实现对未标注语料的抽取任务;该方法的优点在于自动学习规则,自动构建模型,领域移植性强,缺点是需要大量的训练语料才能保证模型的准确率[7]。基于规则的方法又叫基于知识工程的方法,其一般思路是先根据信息抽取对象的特定领域构建规则集(最初通常是手工构建),再根据抽取规则对目标文档执行抽取操作;该方法的优点是基于领域知识编写规则,大幅提高了信息抽取的准确率,缺点就在于对领域知识的依赖性强,且手工构建规则成为该方法的技术瓶颈[8-9]。其后,越来越多的学者将两者相结合,采用机器学习算法进行知识的自动学习和处理,手工编写规则与基于语料库自动学习规则相结合,再根据抽取结果辅以手动修正规则[10]。
文中研究的竹类种质资源属于特定学科领域,数据集小,更宜采用基于规则的信息抽取方法。研究根据竹类植物数据的特点,将正则表达式用于信息抽取系统中的模式匹配和规则构建,提出一种正则抽取模型,以确保抽取结果的准确率。
1.2 正则表达式
正则表达式(regular expression,RE)是用于描述字符匹配规则的一种工具,或者说是一种记录文本规则的代码,功能在于可以用单个字符串来描述、匹配一系列符合某个句法规则的字符串[11]。正则表达式是软件开发中处理字符串的利器。简单的说,正则表达式在字符串处理中有三大作用:一是匹配作用,检测预定的字符串和正则表达式的过滤逻辑是否匹配,如数据包检测过滤、账号密码验证、邮箱地址验证等;二是查找作用,在能正确匹配的基础上,将所需要的字符查找出来,如信息抽取、自动文摘等;三是替换作用,在正确查找的基础上,将查找结果进行替换[12]。正则表达式已经广泛应用于信息抽取和信息检索领域[13-14]。
正则表达式的构建:一个正则表达式是由一些基本字符(元字符、限定符及特殊字符等)组合成的文字模式,描述了待搜索字符串的匹配模式[12]。元字符用来规定其前导字符在目标对象中的出现模式,限定字符是指定数量的代码,常见的元字符和限定字符如表1所示[12]。在构建正则表达式时,只需将希望查找匹配对象的模式内容放进定界符“/”中间,如匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/。

表1 正则表达式中常用元字符和限定符
为了说明正则表达式的用法,下面给出一个正则表达式的例子(Linux的防火墙体系下用于检测网络协议的正则表达式):
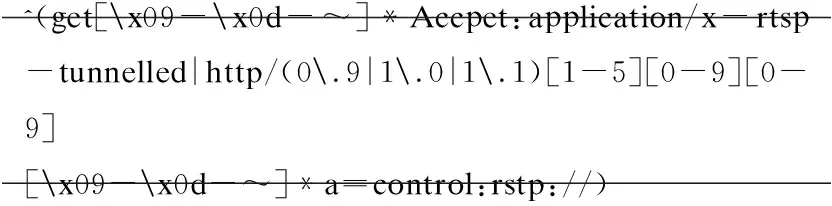
^(get[x09-x0d-~]*Accpet:application/x-rtsp-tunnelled|http/(0.9|1.0|1.1)[1-5][0-9][0-9][x09-x0d-~]*a=control:rstp://)
其中的主要正则语句描述如下:

^(get…|http…) 匹配以get…或http…为开头的字符串[x09-x0d-~]匹配任意个可打印的字符,范围从x09到x0d及从空格到~http/(0.9|1.0|1.1)匹配http/0.9或http/1.0或http/1.1[1-5][0-9][0-9]匹配一个三位数,范围从100到599
1.3 方法实现
(1)抽取模式。
竹种基础数据库的表结构即竹种信息抽取系统的抽取模板,根据竹种外在形态结合生殖器官和营养器官,从地下茎、竹竿、竹箨、竹叶、花果形态五个维度共设计字段57个,下面给出部分字段设计,见表2。以数据表的属性名称为规则触发词,构建完整的触发词集。
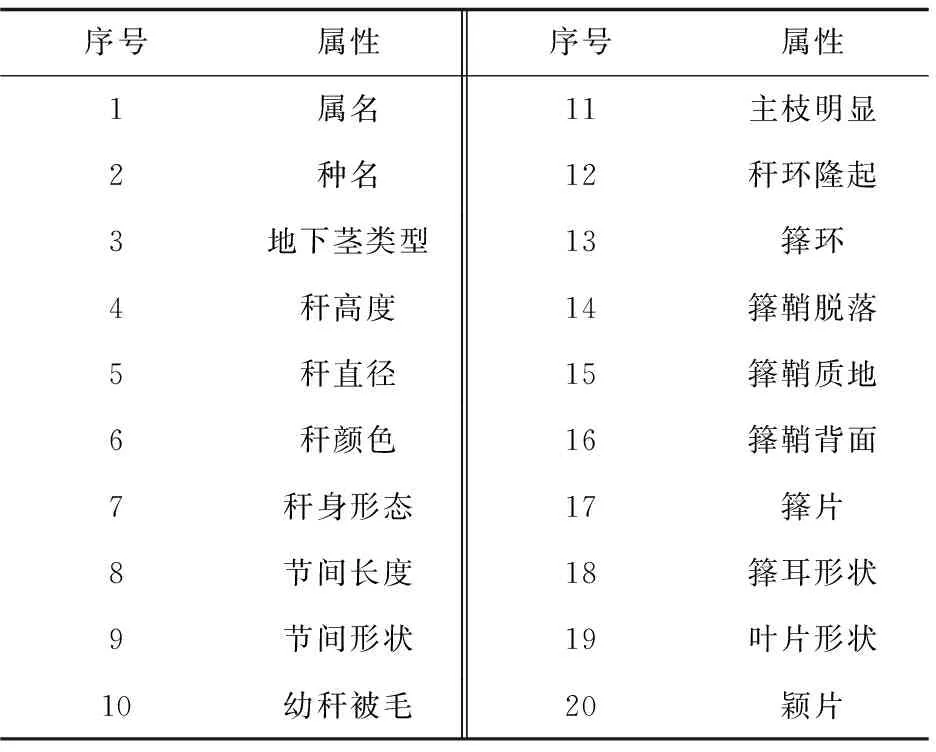
表2 竹种基础数据库属性(部分)
(2)抽取规则构造。
对竹种信息的抽取分为两部分:网页解析和字段抽取。
网页解析是为了实现对网页中文本信息的抓取,通过定位词找到关键信息,通过构造正则表达式,过滤标签提取纯文本信息,网页解析的正则表达式构造如:“
字段抽取是从纯文本描述中,依据正则表达式的模糊匹配功能找到字段的属性值,填入对应的数据库模板中。对字段抽取的规则构造加以举例说明,如表3所示。
(3)正则抽取系统的设计与实现。
文中提出基于正则表达式的竹种信息抽取模型,采用Java语言编程开发竹种信息抽取系统,主要包括数据采集与预处理模块、抽取模式生成模块和信息抽取执行模块。系统中采用的分词工具为中科院的ICTCLAS分词系统2014,该工具能对汉语文本进行切分并标注词性。系统结构如图1所示。

表3 字段抽取示例
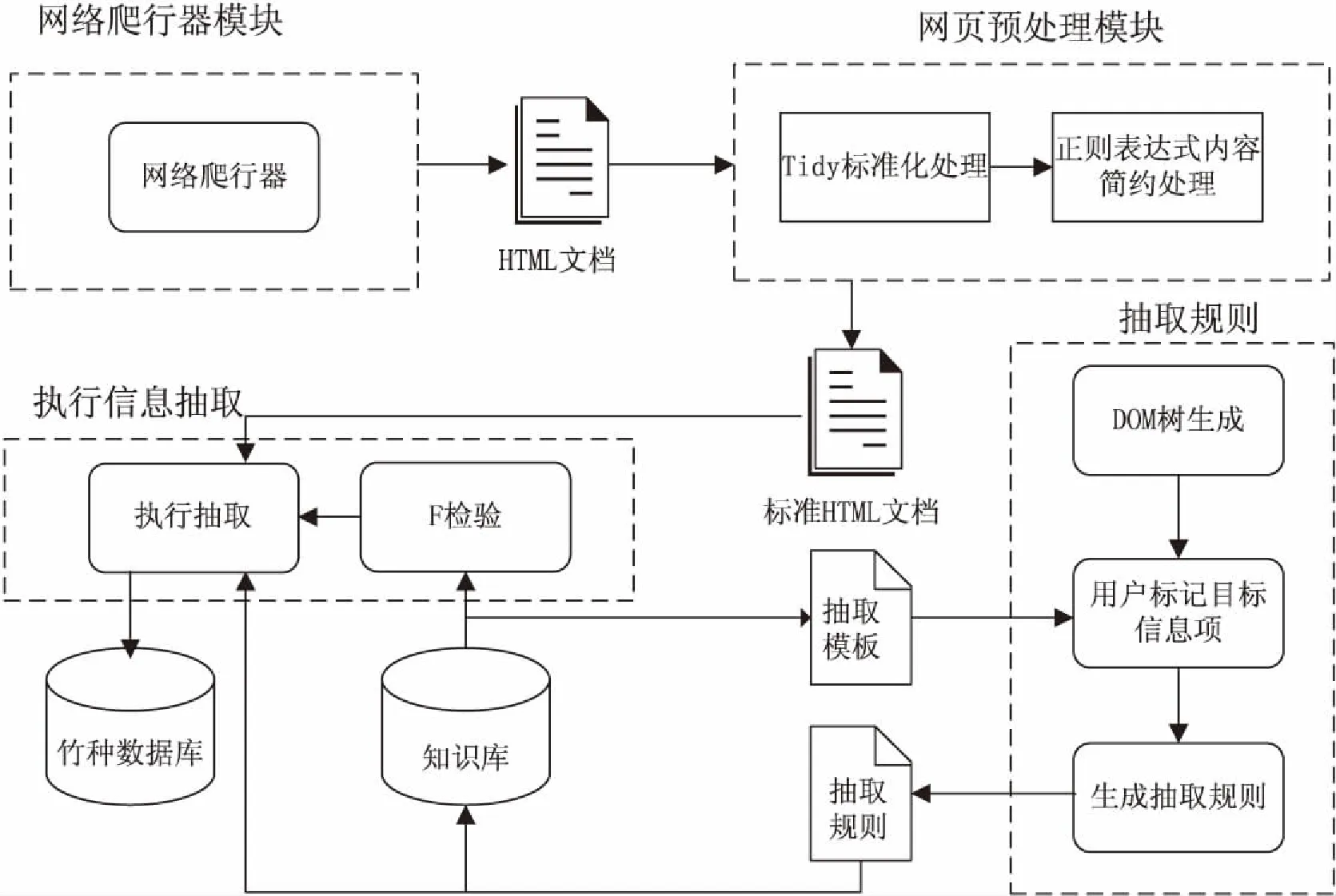
图1 竹种信息抽取系统结构
1.4 抽取效果评价与指标
常用的信息抽取模型的评价指标有准确率(Pr)、召回率(Re)和F-测度(F-Measure),计算公式分别见式1~3[15]。准确率显示了模型的正确率,召回率显示了模型的性能,F-测度是准确率和召回率的综合性能评价方法。

(1)

(2)

(3)
F-测度当β取1时,就是F1-测度。文中采用上述的Pr、Re和F-测度作为对正则抽取模型及竹种信息抽取系统的性能评测指标。测试的目标是希望得到最大的F值。
2 实 验
2.1 数据采集与预处理
文中采取网络爬虫技术实现目标源数据的网页采集工作。以竹种信息采集为例,具体做法是用爬虫算法进行竹子信息网页的自动采集和下载,通过预处理简化源HTML文档,只留下与抽取模式匹配的HTML代码,再去除HTML标签读取文本信息,将文本信息存储为待抽取文档。
以中国植物志在线版为抽取对象,进行抽取实验。从网页上截取一小段竹种描述信息:“地下茎为单轴或复轴型。秆散生,直立;节间在有分枝一侧的基部乃至中、上部扁平或具纵沟槽。”对语料进行如下分析:
特点1:句子与句子之间的区分界限很明显,即对竹子的不同部位的描述在不同的句子里。
特点2:每个句子的第一个词是句子的关键词,如前述语料的的关键词分别是地下茎、竿、节间。
特点3:在句子内部,属性与属性之间的分隔界限也很明显,如“竿散生,直立”。
特点4:待抽取属性名称,如地下茎类型、竿高度、节间长度,这三个短语的关键词也是地下茎、竿、节间。
根据以上分析,在进行抽取时第一步将文本信息以“;”或者“。”切分成句子集,然后根据触发词定位到关键句,再对单个句子进行分析;第二步将单个句子用“,”切分成短语集,利用抽取规则对短语集进行遍历匹配,进而抽取出对应的属性值。由此得出抽取算法的一般过程为:
输入:一段自由文本
输出:字段的属性值
(1)以“;”或“。”将文本切分成句子集;
(2)取出属性名称与上述句子集的每个句子的关键词进行比对;
(3)通过步骤2的比较定位到关键句;
(4)定位到关键句后,对该关键句用“,”切分成短语集;
(5)取出属性的抽取规则的正则表达式与步骤4中的短语集进行遍历匹配;
(6)如果匹配成功,则抽取出属性值的信息,并返回;
(7)如果匹配失败,赋空值,并返回。
2.2 抽取结果及评价
抽取执行过程及结果如图2所示。
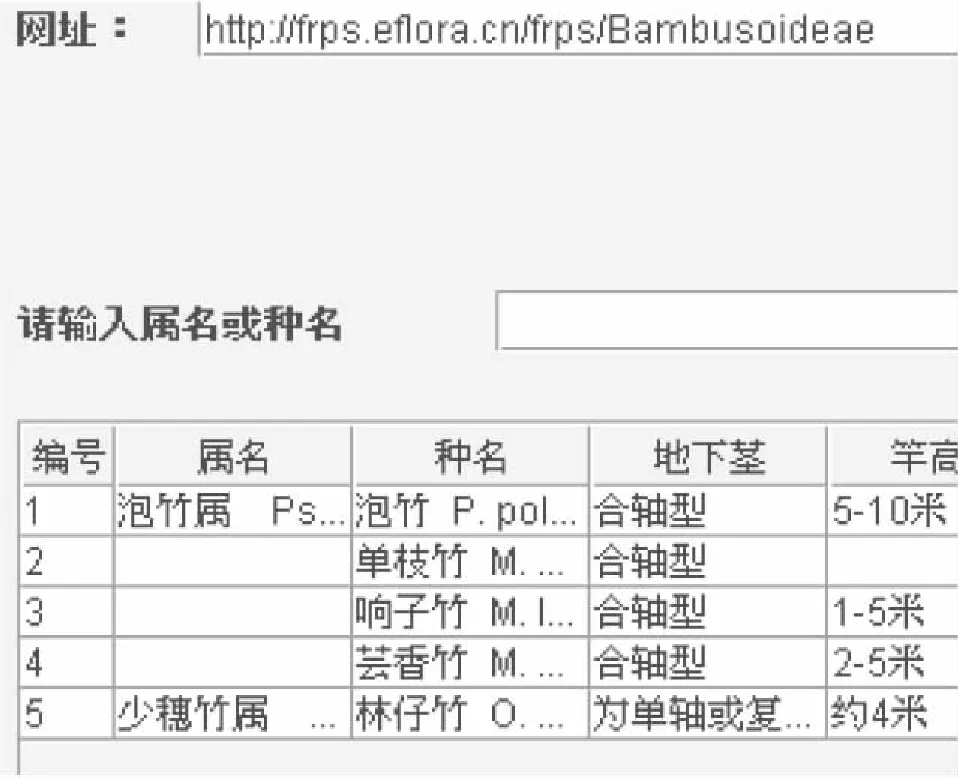
图2 竹种信息抽取过程
对竹种数据库中数据表的前八个字段的抽取结果进行统计分析,选取簕竹属、牡竹属、刚竹属和玉山竹属下46个竹种作为样本点,统计Pr、Re和F-Measure,如表4所示。
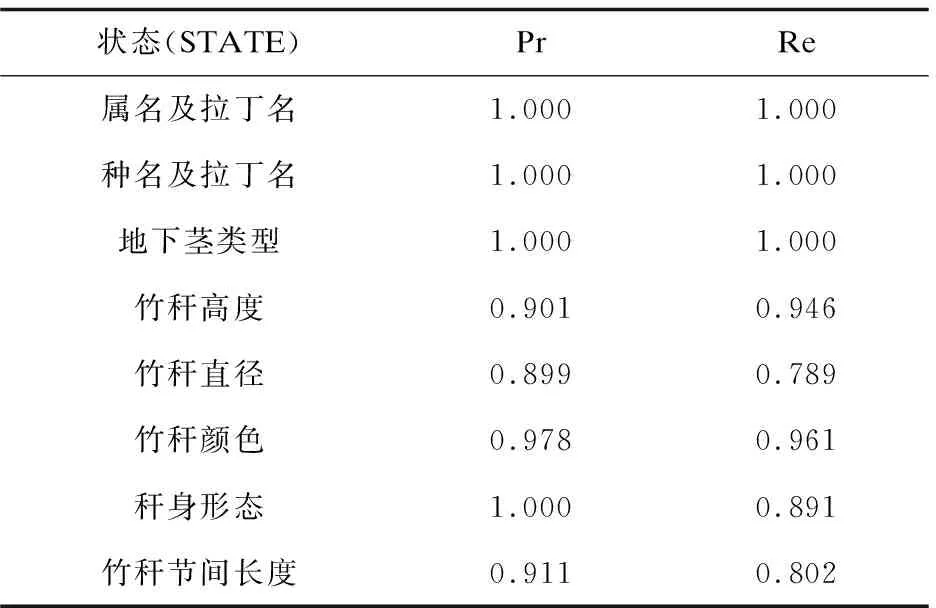
表4 竹种抽取系统实验结果
对取样结果进行分析表明,提出的正则抽取模型准确率较高,能够有效地从竹类植物电子文献或Web网页上自动采集抽取到相应的竹种信息。研究开发的竹种信息抽取系统是可行有效的。
3 结束语
基于正则表达式能快速匹配文本和基于规则的抽取准确率较高的优势,提出了基于正则抽取模型的竹种数据结构化方法。该方法以竹种数据库属性为抽取模式,利用正则表达式构建抽取规则,设计实现了竹种信息抽取系统,以中国植物志在线版为抽取对象,实例验证了系统的抽取准确率。而抽取规则的构建需要竹亚科领域专家的参与,领域依赖性较高,这导致系统不具备很好的移植性。下一步的研究中将考虑借助本体的知识工程方法来提高信息抽取模型的精确匹配,利用竹亚科本体中包含的领域知识及语义信息来指导信息抽取的整个过程。
参考文献:
[1] 邢新婷.竹类种质资源的收集、保存及其数据库构建[D].北京:中国林业科学研究院,2006.
[2] NÉDELLEC C, NAZARENKO A,BOSSY R.Information extraction[M]//Verification plans.USA:Springer,2002:737.
[3] SODERLAND S. Learning information extraction rules for semi-structured and free text[J].Machine Learning,1999,34(1):233-272.
[4] SEKI K,MOSTAFA J.A hybrid approach to protein name identification in biomedical texts[J].Information Processing & Management,2005,41(4):723-743.
[5] 张素香.信息抽取中关键技术的研究[D].北京:北京邮电大学,2007.
[6] 李保利,陈玉忠,俞士汶.信息抽取研究综述[J].计算机工程与应用,2003,39(10):1-5.
[7] 金 莉.基于机器学习的Web信息提取技术的研究[D].武汉:华中科技大学,2003.
[8] 石 倩,陈 荣,鲁明羽.基于规则归纳的信息抽取系统实现[J].计算机工程与应用,2008,44(21):166-170.
[9] KLUEGL P,TOEPFER M,BECK P D,et al.UIMA Ruta:rapid development of rule-based information extraction applications[J].Natural Language Engineering,2016,22(1):1-40.
[10] 胡军伟,秦奕青,张 伟.正则表达式在Web信息抽取中的应用[J].北京信息科技大学学报:自然科学版,2011,26(6):86-89.
[11] 杨 桢,赵燕平,朱东华.基于正则表达式的信息抽取系统在国防技术监测中的应用[J].北京理工大学学报,2006,26:74-78.
[12] 弗里德尔.精通正则表达式[M].北京:电子工业出版社,2012.
[13] 向菁菁,耿光刚,李晓东.一种新闻网页关键信息的提取算法[J].计算机应用,2016,36(8):2082-2086.
[14] 朱文琰,郑肖雄.基于正则表达式构建学习的网页信息抽取方法[J].计算机应用与软件,2017,34(2):14-19.
[15] 赵 军,刘 康,周光有,等.开放式文本信息抽取[J].中文信息学报,2011,25(6):98-110.
