基于视频场景深度学习的人物语义识别模型
2018-06-20岳文静
高 翔,陈 志,岳文静,龚 凯
(1.南京邮电大学 计算机学院,江苏 南京 210023;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
视频语义是对视频信息所包含事物的状态描述和逻辑表示,涉及人和物的动作、表情、音频、图像序列等信息[1-2]。视频语义分析与识别是对视频包含的语义信息进行特征提取、整理、分析与识别的过程,涉及人的视觉机理、图像识别、机器学习、模式识别和深度学习等领域[3]。
在对视频中有序的帧图像进行语义分析中,由于一段视频中可能包含多个场景,而这些场景又由一组有序的帧图像组成,为了更好地分析视频语义,需要对视频进行预处理,包括把视频中的内容按某种方式进行镜头分割并场景化[4-5]。在上述视频人物语义分析中,首先将通过镜头检测和寻找镜头变化的方法对视频进行分割,其次将找出镜头中的关键帧集,并通过计算所有镜头的关键帧图像之间的相似度来进行聚类,最后研究视频场景化中的人物语义[6-7]。
视频人物语义分析往往是以研究视频中的人物行为语义为中心,同时辅助视频中除人物以外的事物所构成的上下文环境对象的语义,来提高分析人物语义信息的准确性[1]。目前视频语义分析一般都是通过学习图像特征这种方法,图像特征主要包括低层特征和中层特征。低层特征是基于视频的像素经由各种变换而来的,没有具体的语义含义。对于简单行为的识别,低层特征具有很好的描述效果,但通常难以对真实场景下的复杂行为进行有效建模[6-7]。
文中提出一种人物语义识别模型(DVSM),该模型由语义通道层和语义融合层构成,从人物身份、人物行为、上下文环境等通道对视频预处理好的场景图像运用卷积神经网络进行处理,从底层图像抽取中层特征,再将这些中层特征融合到语义融合层来识别视频人物语义。
1 相关工作
1.1 视频场景划分
镜头分割是视频场景预处理的第一步,现如今比较成熟的镜头分割方法有X2直方图匹配算法与梯度法。基于X2直方图匹配与梯度法的镜头检测算法检测视频中的镜头切换和淡入淡出。该算法是通过计算视频中连续两帧图像的直方图差值来检测镜头切换。除切换外,另一个重要的镜头连接方式是淡入淡出,其特点是视频帧的画面先渐渐暗下去,然后再亮起来,因此每帧画面的相邻像素相关性都会先变小再变大,而每两个像素的梯度恰好能代表他们的相关性。
关键帧提取是要获取视频场景中能够代表镜头内容的图像。Li等提出一种基于非相邻帧比较的关键帧提取算法[1]。该算法的思想是选择镜头中的第一帧作为第一个关键帧和参考帧,然后计算后续帧和当前参考帧的差异,当差异大于预定的阈值时,则选后续帧为关键帧和参考帧,重复上述过程直到镜头结尾。
镜头聚类是完成视频场景预处理的重要步骤,首先通过HSV空间中的颜色直方图来描述关键帧的整体颜色特征,并以此作为特征值进行关键帧聚类;接着通过计算关键帧之间的相似度值作为输入来计算镜头相似度以对上述颜色直方图特征进行匹配;最后计算簇中元素间的最大相似度,当相似度值大于一个预先设定的阈值时,将这两个簇合并为一个簇,直到簇间距离都小于阈值则聚类终止。归为一类的镜头集,即为场景,聚类结束即完成对将视频的场景划分。
1.2 视频语义分析
视频中人物的语义信息具体可以细分为人物的身份信息、动作、表情、语音等几个主要方面。现有融合语义主题的方法将每幅图像的视觉特征表示为一个视觉“词袋”,设计一个概率模型分别从视觉模态和文本模态中捕获潜在语义主题,采用一种自适应的不对称学习方法融合两种语义主题[8]。Atan等提出了基于多用户和多处理的系统学习框架来识别视频中的人脸[9],与已有的强化学习技术相比,在高度动态的环境中,这种方法学习接近最佳状态的收敛速度更快。Kumar等提出了一种新颖方法来挖掘新闻视频语义[10],首先通过基于人脸识别来命名新闻视频中人物,并对视频中人物聚类成多个社区,其次再通过语义分析模型分析出社区之间的联系。Liang等提出了一个表达深度模型来自然地融合人和周围的环境以高层次地在静止图像中理解动作[11]。特别地,训练了一个深度置信网络以从不同的噪声源中融合信息。Zhan等提出了一种基于稀疏表示的核判别分析加KNN的视频语义方法[12],通过引入核分类功能到KSVD字典优化算法来建立可判别模型,通过该模型完成稀疏表示特征到高位空间的映射,使用基于优化的稀疏表示的加权KNN方法来分析视频语义。
Zhang等提出了一个深层次的学习策略,以融合多复杂事件识别的语义线索[13]。通过回答如何共同分析人类行为、对象和场景来解决识别任务。首先,每种类型的语义特征被馈送到一个相应的多层特征抽象的路径,由一个融合层连接所有不同途径。然后,通过无人监督的跨通道编码方式学习语义线索相互作用的关联性。最后,通过微调架构上大幅度的目标,来回答语义线索如何组成一个复杂的事件。相比于传统的特征融合方法,该方法有效地融合了识别的水平特征[12],但该语义线索局限在人类行为、对象和场景等方面,缺乏对每一个人物的身份信息提取和分析;此外,该方法在自编码学习过程产生的参数数量太多,增加了深度学习的难度。
文中在改进上述视频语义模型的基础上,利用视频场景深度学习构建人物语义识别模型。
2 基于深度学习的视频人物语义识别模型
2.1 视频人物语义识别模型框架设计

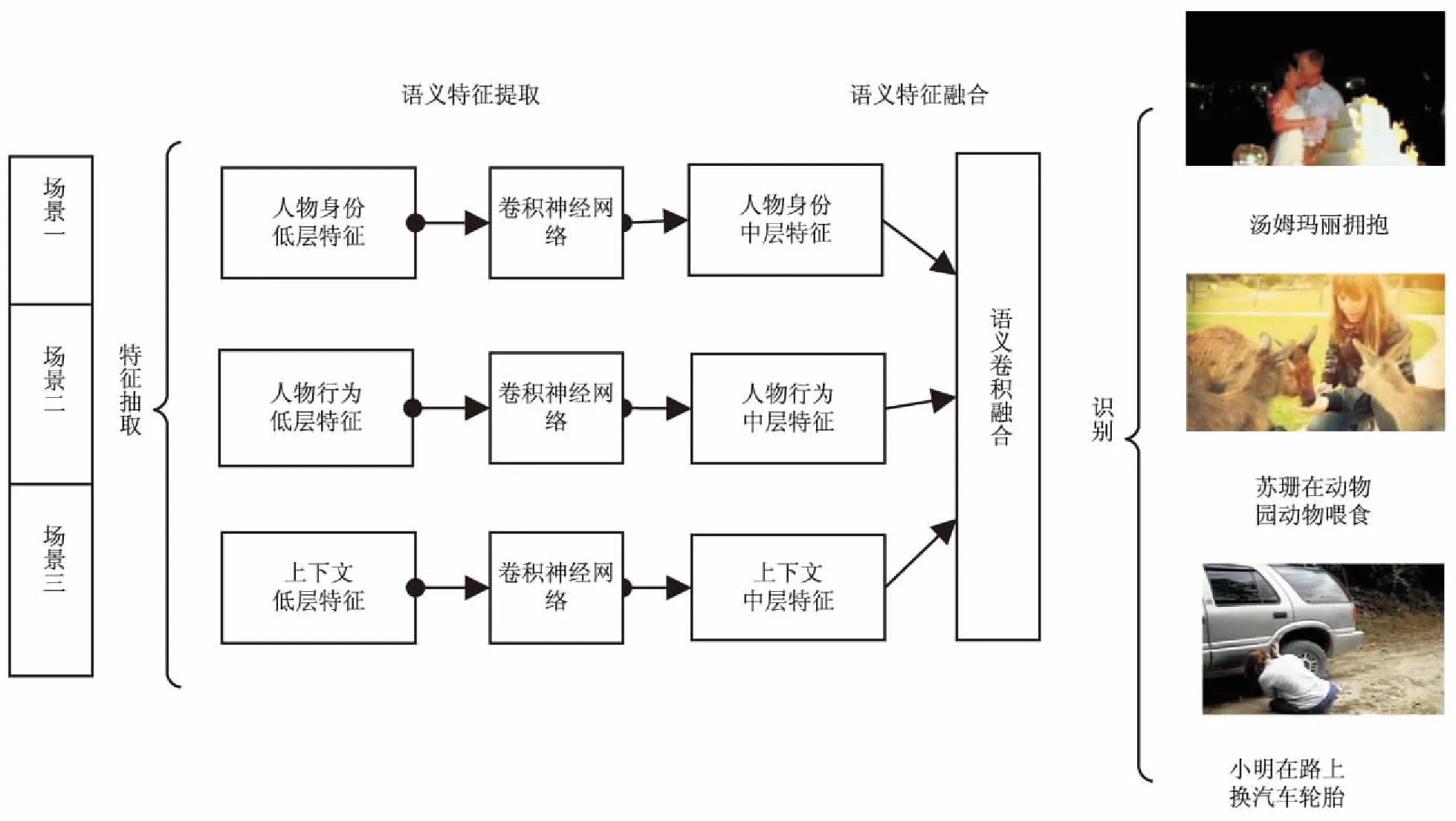
图1 基于视频场景深度学习的人物语义识别模型框架
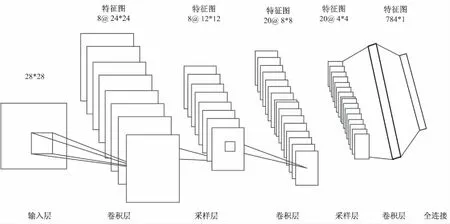
图2 通道语义特征提取过程
2.2 通道中层语义特征提取
通道中层语义特征提取主要是卷积神经网络中的卷积、采样和全连接过程。卷积本质上是通过一个或多个可训练的滤波器即卷积核,对原特征向量做一次或多次非线性变化。为了更好地描述每两层之间的卷积过程,通过(Nl,bl*bl)来描述第L层神经元;通过多个可训练的滤波器f(n*n)向量和多个连接表Nl*Nl-1来描述L层和L-1层之间神经元的卷积运算。通过多个可训练的滤波器f(n*n)向量卷积一个输入为m*n维的图像,然后加上偏置b,得到卷积层的输出特征图,用(Nl,bl*bl)描述,其中Nl表示第L层的特征图个数,bl表示第L层的特征图维数。第一层输入的是图像,后面阶段输入的是从前一层抽取的卷积特征图集合的一个子集。具体要几个特征图来卷积构成后一层的一个特征图,需要先设定好一张两层特征图之间的连接表,该表记录着两层特征图之间的连接关系。
以行为语义通道为例,卷积层公式如下:

(1)
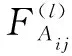
子采样本质上是给卷积层中得到的每一个特征图进行降维。典型的操作一般是对输入图像中大小为n*n块的所有像素进行求和,这样输出图像在两个维度上缩小了n倍。文中将每一幅特征图中每个不重复邻域的两个像素求和,变为一个像素,然后通过乘性偏置βx+1加权,再增加加法偏置bx+1,然后通过sigmoid激活函数产生一个缩小二倍的特征映射图Sx+1。这里以行为语义通道为例,卷积层公式和采样层公式如下:
(2)
其中,down函数表示子采样函数。每个输出特征都对应一个乘性偏置β和一个加性偏置b。
全连接是将卷积核在前一层所有的特征图上做卷积操作,将特征向量降为1*n维的向量。文中将每个通道上的语义通过各自全连接层,输出一个1*n向量特征。
2.3 多通道语义特征融合
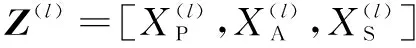
Z(l+1)=σ(F(l)Z(l)+b(l+1))
(3)
其中,Z(l+1)表示融合层三层中层语义的卷积输出。但是由于视频中存在语义噪声,会造成语义抽取的不完整或者丢失,为了让文中提出的语义模型可以学习到多通道语义之间的关联关系,增强语义融合的鲁棒性,定义式5作为融合语义的损失函数。
(4)
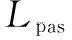
语义融合的完整损失函数如下:
(5)
2.4 整体精调与语义识别
通过有监督的机器学习来调整整个网络所有层参数并完成语义识别任务,特别是在SVM分类器中加入最大间隔分类来构造损失函数。一种流行的方法是训练多个一对多的模型,一个类别对应一个模型,其中每个模型计算真实类别y∈{1,-1}和预测类别之间的损失,然后将融合层特征向量Z作为前向传播的训练数据,W作为融合层和识别层之间的权重参数,大间隔损失函数如下:
max(1-WT*z*y,0)
(6)
为将式6加入到深度学习网络中,借鉴Zhang等在多层语义融合时运用的l2-loss函数,考虑到该函数的权值衰减问题,最终融合层的大间隔代价函数类似于二类SVM分类器公式[13]。
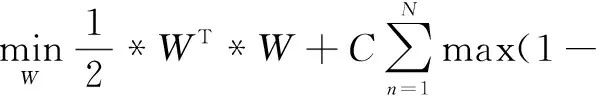
WT*z*y,0)
(7)
为了简化多层框架的训练过程,将上述二类扩展到多类,与之相匹配的l2-loss函数如下[13]:
(8)
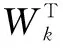
3 实验与结果分析
3.1 数据集和预处理
选择OA视频集中的事件作为实验数据,该数据集是发生在办公室里面人物的日常行为,是公开的RGB-D视频数据集,包含1 180个视频序列,10个以上人物,两个办公室地点,每一个事件同一个人做两次,还包括两个人物之间的交互事件。上述数据集分成两组子数据集:OA1和OA2,每一个子数据集有10类事件,OA1是单个人物的事件,OA2是两个人物的交互事件,具体如表1所示。

表1 OA视频场景数据集
实验数据集的预处理主要是将视频文件转换成文本文件格式数据。首先通过对视频进行场景分割和聚类,每个视频由一系列关键帧组成的场景集合表示,聚类好的每一个视频场景需要指定相应类别;然后对每个场景中的图片分别进行人脸、动作和上下文环境检测与特征提取,生成对应的人脸、动作和上下文环境的三张图片;最后通过对上面检测出来的三张图片分别进行灰度化与二值化,重新统一图片大小为28﹡28,将图片的所有像素按行遍历输入到文本文件中的一行大小为1﹡784,并在末尾加上所属类别。该文本文件就是三通道语义中层特征提取的训练数据集,具体包括三个训练集:person_train.txt、action_train.txt、context_train.txt;三个测试集:person_test.txt、action_test.txt、context_test.txt。
3.2 中层特征提取训练过程
根据第2节中提出的语义识别模型进行实验,其中中层特征提取包括人物身份、人物行为、人物所处的上下文环境的中层特征,三个通道并行利用6层卷积神经网络来训练3.1节预处理出的训练集。主要分成以下几步:
(1)卷积网络初始化。
实验的初始化主要是对卷积网络初始化卷积层和输出层的卷积核和偏置,其中卷积核和权重进行随机初始化,而对偏置进行全0初始化。
(2)前向传输计算。
实验的卷积网络按照输入层、卷积、采样、输出层来构成。实验中的每一个卷积层的卷积核大小为5*5,采样层的采样规模为2*2。实验经过多2层卷积2层采样最终输出1*n维特征向量。
(3)反向传输调整权重。
实验的反向传输过程是卷积神经网络最复杂的地方,主要通过输出层、采样层和卷积层的最小化残差来调整权重和偏置,输出层的残差是输出值与类别值的误差,而中间各层的残差来源于下一层残差的加权和,实验最终通过3次迭代调整整个网络权重。
3.3 多通道语义特征融合
将3.2节中的三个通道提取出的1*n维特征向量进行拼接,形成3*n维多通道语义特征向量,然后按照3.2节的操作过程进行特征提取,最终形成1*n维向量,在反向传输调整权重时的损失函数为式(5)。最后根据SVM分类器对多通道融合的语义特征进行分类,预测的准确率最高的事件类别即为对应的视频语义。
3.4 结果分析
表2和表3列出了文中提出的模型和其他对比模型在同一个OA数据集中每一个种类的识别准确率和平均准确率。
根据表2,在OA1数据集中,文中提出的DVSM模型在10种事件类别都取得了最高准确率,平均准确率为69.4%。如表3所示,在OA2数据集中,DVSM模型10种事件类别中有8个准确率达到最高,DVSM模型的平均准确率为54.5%。对实验结果进行分析发现,识别错误的原因是实验的特征语义缺少事物特征、音频特征等,上述语义线索在人物语义识别也应被考虑和利用。
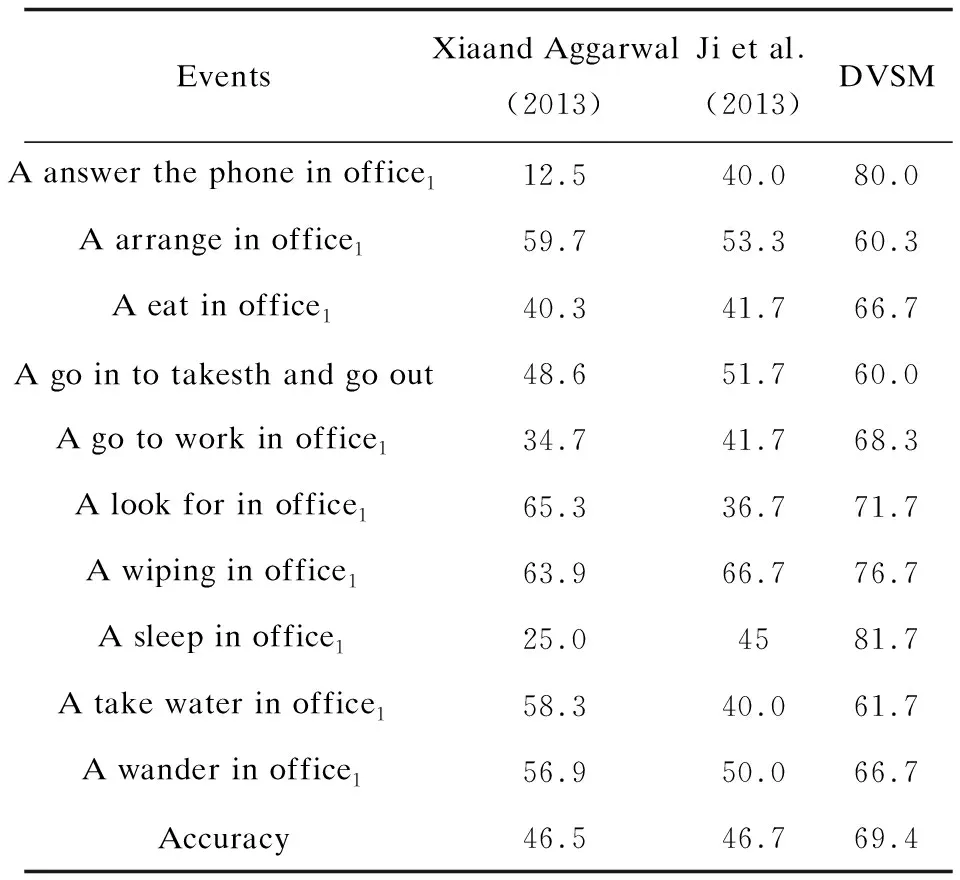
表2 OA1视频场景数据集实验结果比较 %
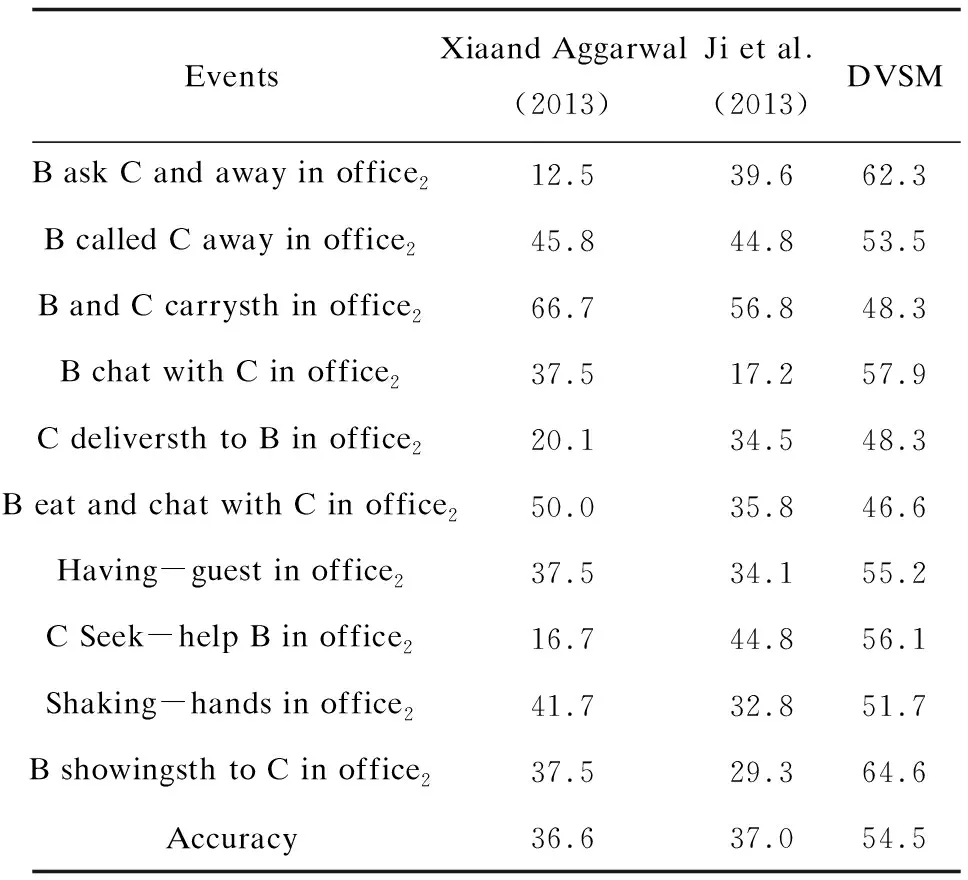
表3 OA2视频场景数据集实验结果比较 %
4 结束语
利用基于视频场景的人物语义学习模型来完成视频中人物语义的识别。该模型使用卷积神经网络提取和融合人物身份、人物行为、上下文环境等通道语义信息,引入损失函数发现不同通道语义之间的潜在关联关系和精调整个网络学习参数,并通过SVM分类器完成识别人物语义任务。与现有的视频人物语义识别模型相比,提出的模型在特定数据集上识别的准确率较高,能够有效识别视频中人物的基本语义。
在人物语义识别中,视频中的音频、时序与一些逻辑知识信息都是识别视频中人物语义的重要线索[14-15],后续工作将研究如何在该模型中融合更多语义线索,以提高语义识别的准确性。
参考文献:
[1] LI Yahui,CAI Cheng.Video segment retrieval based on affine hulls[C]//Proceeding of 2015 10th Asian control conference.[s.l.]:[s.n.],2015:1-6.
[2] 王 煜,周立柱,邢春晓.视频语义模型及评价准则[J].计算机学报,2007,30(3):337-351.
[3] 吴 飞,刘亚楠,庄越挺.基于张量表示的直推式多模态视频语义概念检测[J].软件学报,2008,19(11):2853-2868.
[4] PANG L,ZHU S,NGO C W.Deep multimodal learning for affective analysis and retrieval[J].IEEE Transactions on Multimedia,2015,17(11):2008-2020.
[5] 沈 晴,班晓娟,常 征,等.基于视频的人机交互中动作在线发现与时域分割[J].计算机学报,2015,38(12):2477-2487.
[6] KIM H,KIM J,OH T,et al.Blind sharpness prediction for ultra-high-definition video based on human visual resolution[J].IEEE Transactions on Circuits & Systems for Video Technology,2017,27(5):951-964.
[7] ZHU H,LIU Y,FAN J,et al.Video-based outdoor human reconstruction[J].IEEE Transactions on Circuits & Systems for Video Technology,2017,27(4):760-770.
[8] 李志欣,施智平,李志清,等.融合语义主题的图像自动标注[J].软件学报,2011,22(4):801-812.
[9] ATAN O, ANDREOPOULOS Y, TEKIN C,et al.Bandit framework for systematic learning in wireless video-based face recognition[J].IEEE Journal of Selected Topics in Signal Processing,2015,9(1):180-194.
[10] KUMAR S H,SIVAPRAKASH P.New approach for action recognition using motion based features[C]//Proceedings of 2013 IEEE conference on information & communication technologies.Washington DC,USA:IEEE Computer Society,2013:1247-1252.
[11] LIANG Z,WANG X,HUANG R,et al.An expressive deep model for human action parsing from a single image[C]//Proceedings of 2014 IEEE international conference on multimedia and expo.Washington DC,USA:IEEE Computer Society,2014:1-6.
[12] ZHAN Y,DAI S,MA O Q,et al.A video semantic analysis method based on kernel discriminative sparse representation and weighted KNN[J].The Computer Journal,2015,58(6):1360-1372.
[13] ZHANG X,ZHANG H,ZHANG Y,et al.Deep fusion of multiple semantic cues for complex event recognition[J].IEEE Transactions on Image Processing,2016,25(3):1033-1046.
[14] DONAHUE J,HENDRICKS L A,GUADARRAMA S,et al.Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Washington DC,USA:IEEE Computer Society,2015:2625-2634.
[15] VENUGOPALAN S,HENDRICKS L A,MOONEY R,et al.Improving lstm-based video description with linguistic knowledge mined from text[C]//Proceedings of the 2016 conference on empirical methods in natural language processing.[s.l.]:Association for Computational Linguistics,2016:1961-1966.
