基于机器学习的P2P网络借贷违约风险预警研究
——来自“拍拍贷”的借贷交易证据
2018-06-14王翔宇
涂 艳, 王翔宇
(中央财经大学 信息学院,北京 100081)
一、问题的提出
P2P借贷是一种创新的金融形式,能够满足中小企业及个人的借款需求,缓解“金融排斥”现象。然而,P2P借贷存在较大的风险,P2P借贷平台面临着信用风险、技术风险、合规风险等问题[1],其中信用风险是最突出的风险之一[2]。由于P2P借贷中平台和出借人风险控制能力有限,以及业务模式的限制,借款人违约情况时有发生。传统借贷中,商业银行通过线下实地考察等方式防控借款人的风险,但P2P借贷业务大多发生于线上,借贷双方仅通过网络平台进行借贷交易,交易可信度大大降低[3]。目前,一些平台建立了追偿机制,并设置风险准备金作为对出借人的资金保障。然而,这些举措并未从根本上降低P2P借贷交易中存在的违约风险。
在实践中,平台可通过分析借款人的硬信息、软信息对其违约风险进行预警,为出借人决策提供参考。例如,通过借款金额、利率、期限、身份等硬信息和社交关系、照片等软信息对借款人的违约行为进行预测[4-5]。诸多学者采用Logistic模型预测借款人的违约概率,但使用机器学习算法进行违约风险预测的研究成果较为鲜见,然而,机器学习在各领域的分类问题中均表现出了极好的运算效果和较强的场景适用性,能否将其应用于P2P借贷违约风险预警这一研究问题呢?本文将选取多类主流的机器学习算法,通过使之与传统计量回归模型预测效果的实验对比研究,深入探讨机器学习算法对P2P网络借贷中借款人违约风险预警效果的影响,继而剖析各算法对P2P借贷违约风险预测的适用性。
二、理论背景与机器学习方法适用性分析
在P2P网络借贷交易中,信息不对称问题较为突出[6],由此而引致的道德风险及逆向选择问题导致借款人的违约率居高不下。因此,无论是学术界还是实业界,对借款人的违约风险进行有效预警成为亟待解决的问题。
当前对P2P网络借贷违约风险预警问题的研究主要使用计量分析方法,建立Logistic、Probit、Cox比例风险等回归模型[7],通过研究借款人身份信息(包括年龄、性别、收入等)、标的信息(包括借款金额、利率、期限等)、社交信息(包括朋友数、群组社交活动等)对借款人违约概率的影响,继而识别出对借款人违约行为影响较大的关键变量,并对借款人的违约风险概率进行预测[8-12]。
由于风险预警的本质在于预测借款人违约的概率,属于“违约”和“不违约”的二分类问题。一方面,尽管传统计量回归模型兼具预测功能,但是其研究重点却并不在违约概率的预测问题上,而是分析相关变量对违约概率影响的方向和大小,继而甄别出变量之间的影响关系;另一方面,由于现有风险预警模型大多为线性模型,对于非线性的分类预测问题效果不佳,与之相反,分类及预测问题却是神经网络、支持向量机等机器学习算法的核心功能。鉴于上述原因,本文提出使用机器学习算法改进计量方法的研究思路,采用主流机器学习方法建立风险预警模型,预测借款人违约概率。
关于机器学习方法在P2P网络借贷研究中的应用而言,Wang发现使用贝叶斯网络可辅助出借人进行投资决策,并取得较好收益[13];Zhao等使用改进的UCF(User-based Collaborative Filtering Recommendation)推荐算法为出借人推荐风险较低、收益较高的标的[14];Zhang等发现决策树对风险预警的效果较明显,样本外准确率达到81.22%[15]。目前,采用机器学习算法进行风险预警的研究成果较少,现有文献采用的算法模型亦较为有限,缺乏多种不同机器学习算法的性能对比分析及其适用性的系统研究。本文将采用BP神经网络、支持向量机、决策树、KNN(K-Nearest Neighbor)分类算法、随机森林和Adaboost等算法预测借款人违约概率,并分析各算法的预测准确率,探讨不同算法的适用场景,为P2P借贷平台建立风险预警模型提供参考。
BP神经网络是一种多层前向神经网络,它的学习过程包括信号的正向传播与误差的反向传播两个部分。BP神经网络的结构如图1所示,就BP神经网络在P2P借贷违约风险预警中的应用而言,可将借款人身份信息、标的信息等输入网络,输出层输出借款人违约的结果。输出层计算实际输出与期望输出的误差,将误差分摊给各隐含层的神经元,通过公式计算出调整后的权重,直到误差小于给定阈值或学习次数达到设定上限为止。在P2P借贷中,影响借款人违约概率的变量较多,因此,输入层的神经元个数较多,而输出层仅有一个神经元,以0和1分别表示不违约和违约。隐含层的神经元个数通过经验公式或遗传算法等寻优算法确定。图1以三层BP神经网络为例,展示了BP神经网络的结构。其中X0、X1为输入层的神经元,U0、U1、U2为隐含层的神经元,Y0为输出层的神经元,ωxu为输入层到隐含层的权重向量,ωUY为隐含层到输出层的权重向量。由于神经网络原始输出的结果是二值数据,即借款人是否违约,而不是连续的违约概率,实际上神经网络在输出时进行了转化,即使用Logistic、relu等激活函数,将连续数据转化为二分类数据,因此,本文将直接使用转化前的连续数据作为借款人的违约风险概率。
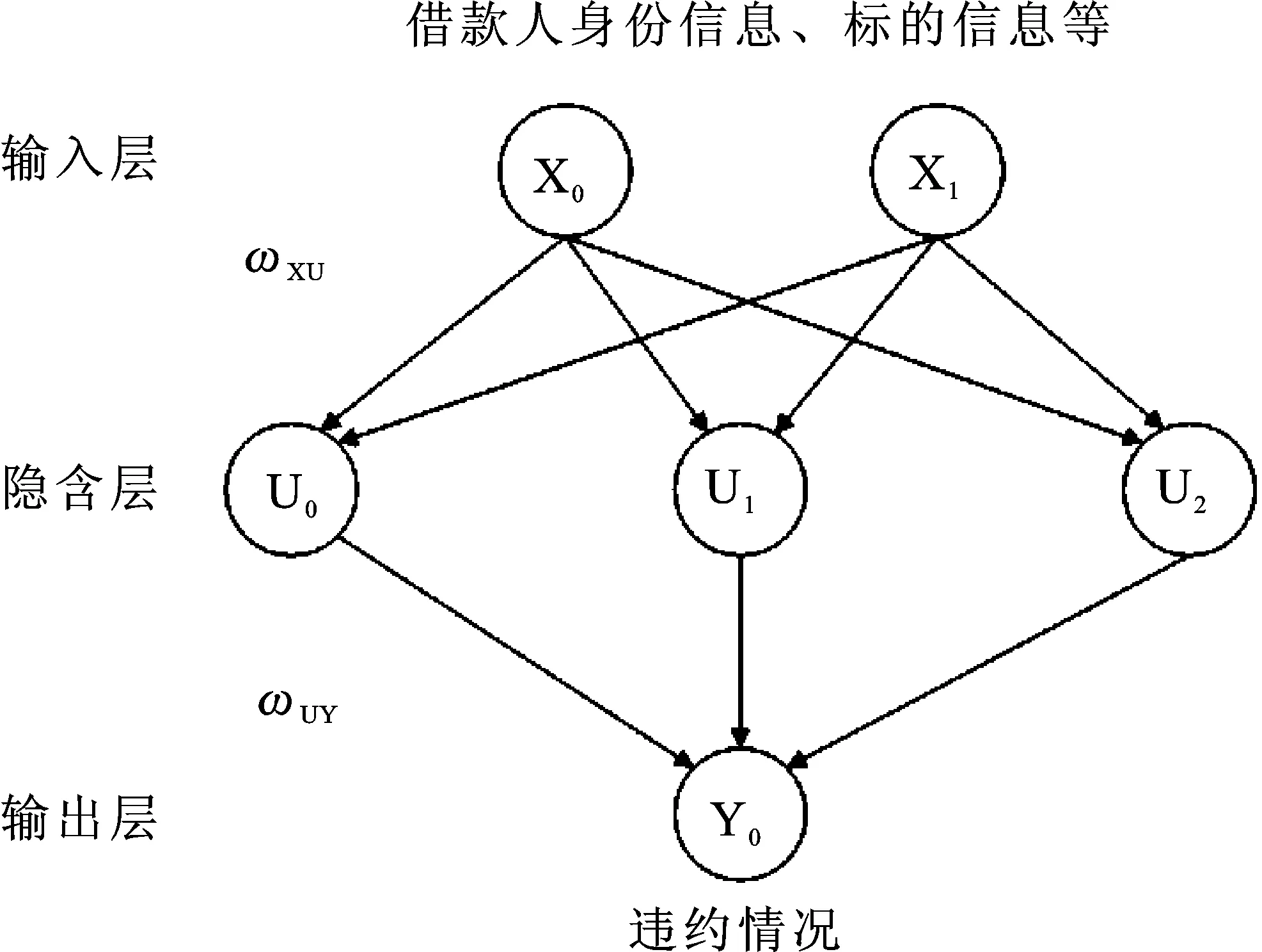
图1 BP神经网络结构
支持向量机主要针对二值分类问题提出,属于监督式学习方法,其被广泛运用于统计分类及回归分析中。就支持向量机在P2P借贷违约风险预警中的应用而言,支持向量机力图寻找超平面,实现违约标的和非违约标的分离,其原理主要是通过核函数将低维空间特征转化为高维空间特征,进而实现线性可分。支持向量实际指“支持”该超平面的点,即在间隔区边缘的训练样本点,支持向量机基本示例如图2所示,其中黑色实线即为所选超平面,将黑色样本点和灰色样本点划分为两大区域,支持向量机指两条虚线上的样本点。由于支持向量机对二分类问题预测效果较好,同时P2P借贷交易中借款人违约预测恰好符合二分类问题情境,因此,从理论上推测,支持向量机适用于解决本研究问题。
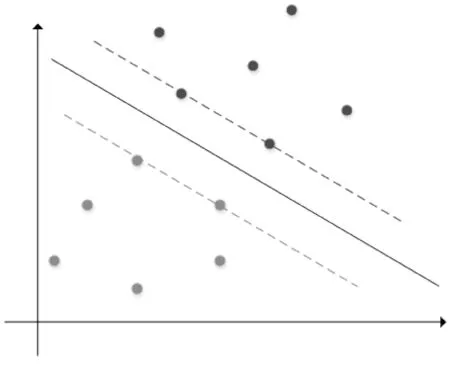
图2 支持向量机示例
决策树是以实例为基础的算法,从实例中推导出决策树后,进而形成分类器进行预测。决策树的构建过程包括决策树的生成和剪枝两个步骤,其中,决策树的生成是自顶向下的过程,在决策树的每个非叶子结点上,对测试属性值进行测试,使用信息增益、信息增益率、基尼系数等指标比较测试结果,选择最佳属性,从而将样本分为若干子集。最后,基于全体样本训练出一棵完整的决策树,每个结点代表一条合取规则,在预测新样本时,从根节点开始,沿各节点选择不同的分枝,直到叶子节点。决策树的剪枝技术旨在去除噪声,减小决策树的复杂程度,预防过拟合问题。在P2P网络借贷中,出借人投资决策是多层次的,考虑变量先后顺序,例如当标的借款金额大于2万时,出借人将查看借款人的认证情况,以做出合理的投资决策;或只有当借款人信用等级为AAA及以上时,出借人将继续投资决策,否则放弃投资。这种多层次的顺序决策过程在Logistic回归中无法体现,但决策树恰好可以模拟该类决策过程。
KNN同样是基于实例的分类算法。以P2P借贷风险预警为例,训练集中已知相关借款人信息及标的违约情况,对于新入样本,通过距离公式计算新样本与其它借款人和标的的相似度,确定样本的K个近邻,以大多数近邻的违约状况预测该样本的违约状况。邻居间距离以不同借款人相似性表示,这种相似性来源于身份信息、标的信息等数据的相似性。另外,不同距离的近邻权重可以设置为不同取值,使权重与距离呈现负相关,这样的结果将更加准确。
随机森林与Adaboost都是对决策树模型的扩展。其一,随机森林使用多个决策树训练样本进行预测并形成模型,通过数据、特征的随机选取,构建多棵决策树,最后,由多棵决策树的众数决定输出类别。在P2P借贷中,基于借款人身份信息、借款标的等信息,随机选取构建多棵决策树,构成随机森林,以提高预测准确率。其二,Adaboost同样是基于多棵决策树模型的分类器模型。广义Adaboost不仅可对决策树模型进行强化训练,同时可对任何弱分类器进行强化。Adaboost首先训练弱分类器,最小化权重误差函数,随后计算并更新弱分类器权重,使分类器对误判样例分类效果更好,直到形成最终的强分类器为止。本文将基于决策树的Adaboost,对训练集训练不同的决策树弱分类器模型,将所有决策树模型集合为强分类器。
机器学习算法更符合P2P借贷交易的大数据特征,因此,从理论上推断它也将更适合P2P借贷情境下的违约风险预警问题分析。本文将建立上述机器学习算法,并基于“拍拍贷”平台上的实际P2P网络借贷交易数据,对P2P借贷违约风险预警准确率进行实验对比研究,进而探讨各类机器学习算法用于借款人违约预测的实际效果。
三、算法实验
数据来源于中国P2P借贷平台之一的拍拍贷,爬取借款人身份信息、标的信息,并随机抽样形成本文的数据集。全部的自变量包括借款人认证情况、职业、性别、年龄、信用等级、注册时间、历史还款次数、历史违约但还清次数、出借次数、自有头像、金额、利率、期限和标的类型,因变量是借款人是否违约。使用相关自变量对二分类因变量进行预测。该项预测本质上是分类问题,可以用相关机器学习算法进行分类预测。
(一)数据处理
将借款成功的借款列表分为80%的训练集和20%的测试集,并利用训练集样本训练各算法模型,利用测试集样本测试各类算法模型对P2P网络借贷违约风险的预警准确率。首先,在实际数据处理过程中,由于违约标的与非违约标的数量不平衡,为了避免正负样本数目不平衡,造成模型构建及准确率计算存在偏差,本文通过随机抽样方法,控制并确保正负样本比例均衡。具体而言,在借款成功的借款列表中,总标的数量为130 271条,其中违约标的共5 157条,不违约标的共125 114条,违约率为3.96%。因此,本文从非违约标的中随机抽样提取出5 157条样本数据,与5 157条违约标的样本组成本文模型实证分析的数据来源,共计10 314条交易标的数据。然后,在违约标的与非违约标的中各进行80%、20%的训练集和测试集样本划分,保证训练集和测试集内正负样本均为1∶1。最后,对连续变量进行归一化处理,以保证各类机器学习算法的效率和实验对比结果的准确性。
本文构建的风险预警模型具体实现机制为:其一,针对神经网络算法,使用Keras包实现。主要原因在于神经网络算法涉及到大量调参步骤,而每一步的迭代次数均较高,由于Keras支持GPU计算,可节省大量调参过程中消耗的计算资源,因此,采用Keras包可有效提升神经网络算法的计算效率。其二,除神经网络外的其它算法均由scikit-learn包实现。
(二)模型建立及参数调整
1.Logistic回归
建立Logistic回归模型如下:
(1)
其中y代表借款人违约概率,xi代表借款人相关信息,包括身份信息、标的信息等。由于Logistic回归模型目的是预测分类,因此本文不剔除显著性较差的变量,将全部变量纳入模型中,保证分类准确率。
2.神经网络
在神经网络中,本文进行了最优参数的选择过程,这是因为神经网络的调参过程对于提高神经网络准确率及运算性能十分关键。
本文采用经典的3层BP神经网络。设置最大迭代次数为1 000次,并设置了两种激励函数——sigmoid和relu进行对比。已有理论证明,3层BP神经网络即可逼近任意连续函数,因此只需对隐含层节点数进行确定即可。神经网络隐含层节点数经验公式如下:
(2)
m=log2n
(3)
(4)
其中m代表隐含层节点数,n代表输入层节点数,l代表输出层节点数,α代表1~10之间的常数。经过计算,本文神经网络节点数设置为5~18。从中选择最佳节点数。
分别在两种激励函数sigmoid和relu以及不同节点数中进行选择,不同激励函数和节点数的准确率结果如图3和表1所示。由图3和表1可知,激励函数为relu、节点数为17时,效果最佳,准确率达到89.9%。因此,本文采用该参数作为神经网络的最优参数。

图3 神经网络寻优过程
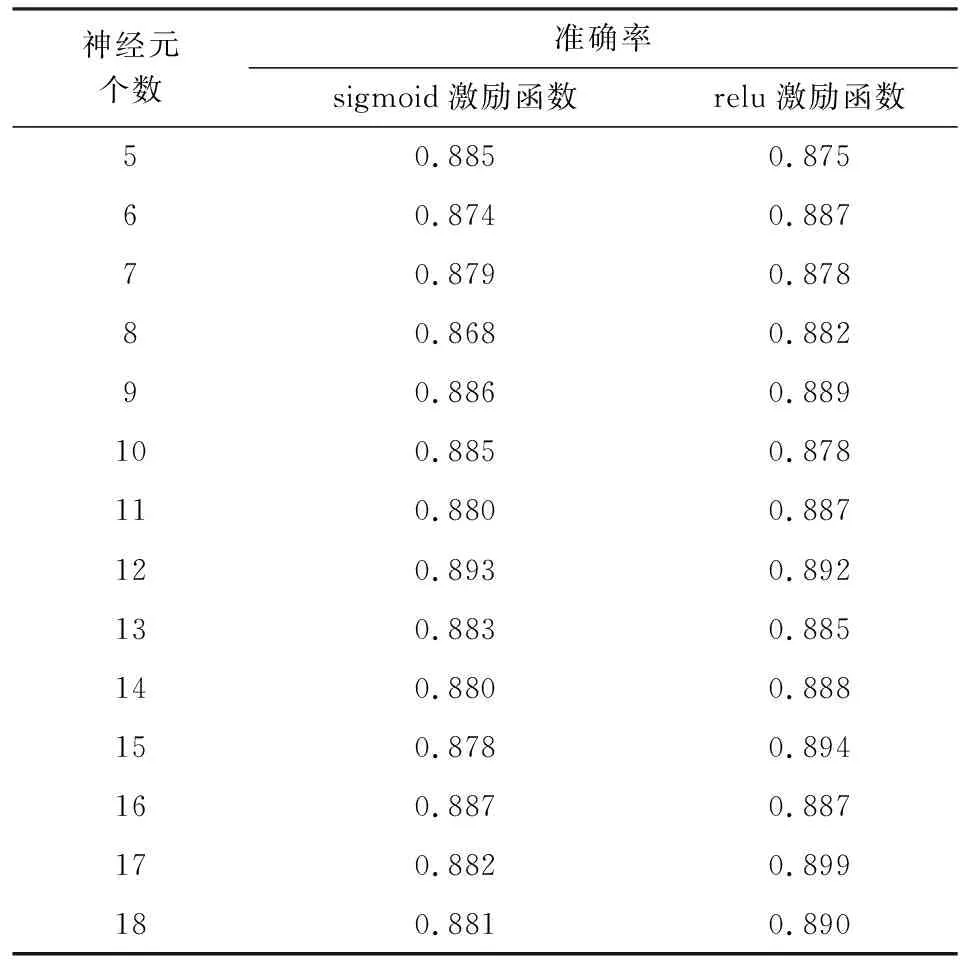
神经元个数准确率sigmoid激励函数relu激励函数50.8850.87560.8740.88770.8790.87880.8680.88290.8860.889100.8850.878110.8800.887120.8930.892130.8830.885140.8800.888150.8780.894160.8870.887170.8820.899180.8810.890
3.支持向量机
核函数是支持向量机的关键,它将高维空间的内积运算转化为低维空间计算,解决高维空间“维数灾难”问题。支持向量机中可选核函数众多,如线性核函数、多项式核函数、径向基核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数等。本文选择两种常用的核函数进行对比,一种是rbf径向基函数,另一种是linear线性核函数。径向基函数是局部性较强的核函数,函数作用范围随着其参数σ增加而减弱。线性核函数是最简单的核函数,主要用于线性可分情形,优点是参数少、速度快。使用两种核函数建立支持向量机模型,结果如表2所示。由数据分析结果可知,尽管linear核函数的准确率较高,但由于其运行时间过长,因此,本文在综合考虑准确率与运行时间之后,选取rbf作为支持向量机的核函数进行各算法的实验准确率对比分析。
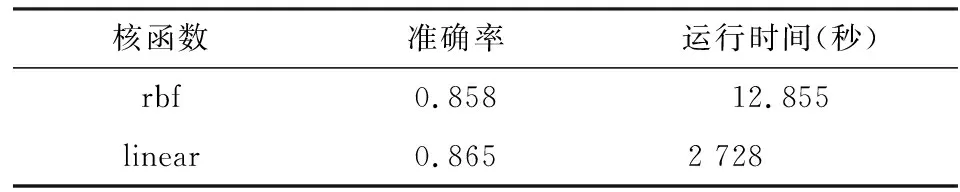
表2 支持向量机寻优过程
4.KNN
在KNN分类算法中,邻居数是最重要的参数之一。KNN算法中邻居是正确分类的对象,在对待测样本分类时,只根据最邻近的一个或几个“邻居”决定该样本点的类别。本文将邻居数设置为从1到100,进行最佳邻居数的寻优。不同邻居数的KNN算法准确率如表3和图2所示。由表3和图4可知,邻居数设为1时,准确率最高。邻居数递增时,准确率降低,在邻居数为46以后,准确率基本收敛于77.5%附近。因此,本文在各算法的实验对比研究中,将KNN算法的邻居数设定为1。

表3 KNN寻优过程

图4 KNN寻优过程
5.决策树
有两种经典的决策树算法——ID3和CART算法。ID3在分枝时采用“信息增益”衡量分类集合的熵值。信息增益由信息熵与条件熵的差得出。信息熵的计算公式为:
(5)
其中D代表样本,H为信息熵,pi表示所有样本第i个子类的概率。
条件熵指选取某个特征后的信息熵,公式为:
(6)
其中A代表某一特征,H(D|A)为条件熵,qi表示某一特征下样本第i个子类的概率。
信息增益为信息熵与条件熵的差,即:
g=H(D)-H(D|A)
(7)
而CART在分枝时采用“分类基尼指数”衡量分类集合的熵值。基尼指数计算公式为:
(8)
其中Ck是D中属于k类子集的数量。
在特征A条件下,样本D被分为D1和D2,则基尼指数为:
(9)
基尼指数反应的是特征划分样本D的不确定程度,因此在对决策树剪枝时,采用基尼指数小的特征。
本文将两种算法进行比较,结果见表4。由于CART算法是在ID3算法的基础上提出的,由表4数据分析结果可知,CART算法的准确率较高,因此,本文将采用CART算法作为决策树分枝时的首选算法。
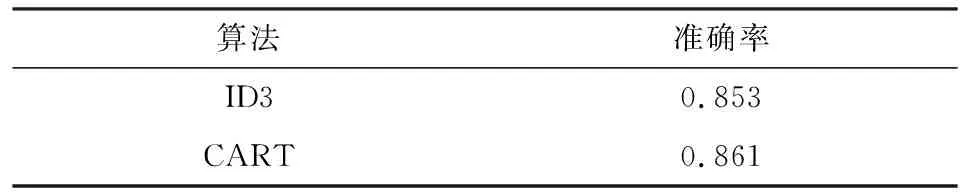
表4 决策树寻优过程
6.随机森林
随机森林是由不同决策树组成的,基于决策树中CART算法的良好性能,在随机森林中,本文将沿用CART算法。随机森林是从原始训练集中有放回随机抽取样本,并从所有特征中随机选择特征,生成新的训练集构建决策树的方法。不同决策树最终形成一个随机森林模型。本文将优化特征数参数,设置特征数为1到60,进行最佳特征数的寻优。寻优结果如表5和图5所示。分析数据可知,当特征数为55时,准确率最高,达到91.3%,当特征数为1时,准确率最低,为81.0%。特征数从1到15时,准确率有较大提高,特征数在15和56之间时,准确率波动较小,基本收敛于90%附近。
综上所述,本文通过训练集样本逐步训练并确定了各模型的相关参数、函数、迭代次数及具体算法,并将继续使用测试集对各机器学习算法的预警准确率进行对比实验分析,以确定各算法在P2P网络借贷违约风险预警问题上的适用性。

表5 随机森林寻优过程
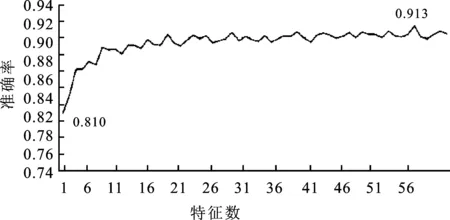
图5 随机森林寻优过程
四、实验结果对比分析
针对上述各算法模型,经由测试集样本测试,发现对照组Logistic和实验组中各机器学习方法准确率如图6所示。结果显示,在实验组中,随机森林算法的准确率最高,达到91.3%,显著高于对照组Logistic算法的违约风险预警准确率;而KNN的准确率最低,为80.5%,低于对照组Logistic算法的预警准确度。

图6 各算法模型的预警准确率对比
第一,从预警准确率视角而言,多数机器学习算法的预警准确率均超出了基准算法Logistic的预警准确率,该结果表明,多数机器学习算法对P2P网络借贷场景下借款人的违约风险预警效果显著。主要原因在于:一是Logistic算法本质上仍属于线性模型,而P2P借贷违约预测问题属于非线性问题,例如决策树算法对应的P2P借贷多层次决策情景,因此,Logistic算法在违约风险预警问题上的适用性较之于机器学习算法更弱,存在欠拟合问题;二是经典计量算法使用特定的分布,例如Logistic算法使用标准Logistic分布,Probit算法使用标准正态分布,而机器学习算法并不受此限制;三是P2P网络借贷交易样本数据符合金融大数据属性,样本量较多,与机器学习算法的适用条件契合度更高。因此,不难看出,在P2P网络借贷违约风险预警方面,多数机器学习算法的适用性更强。然而,通过图6所示的对比结果观察发现,KNN算法的预警准确率较低,预警效果较差,主要原因在于:其一,KNN的分类原理不适用于预测P2P网络借贷中的违约风险。KNN主要基于寻找与待测样本最相近的N个邻居,依据此N个邻居中大多数邻居的所属类别,判定该样本的类别,导致样本最终的分类结果仅与部分相邻样本相关,而这一原理的出发点与P2P网络借贷的样本特征不符。其二,在P2P网络借贷情景中,个体间差异较大,特征较多且分散度较高,因此,依据全部特征的距离来判断违约并无明显效果,该问题也是导致KNN算法准确率较低的原因之一。其三,KNN算法不适用于样本比例不平衡的研究情景。P2P网络借贷中正负样本的比例差别较为悬殊,尽管本文在数据处理阶段尽可能控制并确保了正负样本比例的平衡,以避免此问题对各算法预测精度的影响,然而,在实际运用阶段,必将使用全部样本作为分析数据,此时,KNN的表现将大受影响。其四,KNN算法的计算量较大,需占用较多计算资源。
第二,从结论的可解释性视角而言,Logistic回归与决策树算法的结论可解释度较强。尽管在P2P网络借贷的违约风险预警情境下,Logistic回归模型存在欠拟合现象,然而,模型中的自变量系数仍然能够较为直观地反映出其对因变量的影响方向和作用大小。同样,决策树算法较好地刻画与描述多层次的决策判定过程,并产生决策规则,进而识别出对违约风险影响作用较大的关键因素。
第三,从算法分析机制视角而言,一方面,在BP神经网络中,relu形式的激励函数比sigmoid函数效果更好。该实验结果与Glorot等人的研究结果一致[16];另一方面,随机森林与Adaboost比决策树模型的预警准确率更高。主要原因在于:随机森林与Adaboost算法均是基于决策树算法提出的改进性算法模型,该实验结果恰好说明了上述两种算法作为决策树模型的增强版算法,确实提高了决策树算法的预警准确率。
综上所述,本文将上述Logistic模型及各机器学习算法的适用情况进行汇总,如表6所示。

表6 各机器学习算法适用性总结
五、结论及建议
P2P网络借贷作为新兴的互联网金融借贷形式,为推动普惠金融的实现发挥了重要作用,然而,由于其存在显著的信息不对称现象,进而导致借款人违约问题严重,制约着P2P借贷业务的健康发展,因此,P2P网络借贷中的违约风险预警成为了亟待解决的关键问题。现有研究主要使用Logistic回归等计量方法预测借款人的违约概率,然而,Logistic回归模型仍属于线性模型,对P2P借贷违约预测这一多层次非线性问题的预测效果不佳,而各类机器学习算法在P2P网络借贷情景中具有适用性,可对现有风险预警模型进行有效补充,进而优化P2P网络借贷违约风险预警模型。
本文基于拍拍贷平台的实际交易数据,分别使用BP神经网络、支持向量机、KNN、决策树、随机森林等机器学习算法对P2P借贷违约风险进行预警,并将其与传统Logistic模型进行实验对比分析,发现大部分机器学习算法预警准确率较高,对P2P网络借贷违约预警具有较强的适用性。当需要提高预测准确率时,随机森林等算法的预警效果较好。当需要对模型进行解释时,决策树等算法效果较好。KNN算法不适于对P2P借贷违约风险进行预警。
使用机器学习算法对P2P网络借贷违约风险进行预警,能够有效识别风险较高的借款人,避免因信息不对称所引发的逆向选择和道德风险问题,有效降低P2P借贷违约风险。因此,P2P网络借贷平台可考虑使用机器学习算法建立违约风险预警模型,完善信用评价体系,警示风险较高的借款人,引导出借人投资于信用状况较好的借款人标的项目,进而提高P2P网络借贷交易过程中的信息透明度,并降低潜在的违约风险。
本文的研究工作还可从以下方面予以扩充:第一,改进和丰富机器学习算法。例如可将循环神经网络、卷积神经网络或全连接神经网络等深度学习算法纳入对比实验,测度并观测各深度学习算法对P2P网络借贷违约风险的预警效果。第二,扩充机器学习算法调整参数的种类和范围,使其更加契合P2P借贷交易的相关数据特征。第三,针对样本集正负样本比例不平衡等问题,可考虑尝试使用过采样、交叉验证等方法进行处理,并观测相应的数据处理效果。
参考文献:
[1] Wei S.Internet Lending in China:Status Quo,Potential Risks and Regulatory Options[J].Computer Law & Security Review,2015,31(6).
[2] 牛丰,杨立.基于博弈理论的P2P借贷信用风险产生机制分析[J].财务与金融,2016(1).
[3] Liu D,Brass D J,Lu Y,et al.Friendships in Online Peer-to-Peer Lending[J].MIS Quarterly,2015,39(3).
[4] Barasinska N,Schäfer D.Is Crowdfunding Different? Evidence on the Relation between Gender and Funding Success from a German Peer-to-Peer Lending Platform[J].German Economic Review,2014,15(4).
[5] Lin M,Prabhala N R,Viswanathan S.Judging Borrowers by the Company They Keep:Friendship Networks and Information Asymmetry in Online Peer-to-Peer Lending[J].Management Science,2013,59(1).
[6] Byungjoon Yoo,Seongmin Jeon,Hyunmyung Do.Information Asymmetry Issues in Online Lending :A Case Study of P2P Lending Site[J].The Journal of Society for E-business Studies,2010,15(4).
[7] Li J,Hsu S,Chen Z,et al.Risks of P2P Lending Platforms in China:Modeling Failure Using a Cox Hazard Model[J].Chinese Economy,2016,49(3).
[8] Duarte J,Siegel S,Young L.Trust and Credit:The Role of Appearance in Peer-to-Peer Lending[J].Review of Financial Studies,2012,25(8).
[9] Li S,Qiu J,Lin Z,et al.Do Borrowers Make Homogeneous Decisions in Online P2P Lending Market? An Empirical Study of PPDai in China[C]// The 8th International Conference on Service Systems and Service Management,IEEE,2011.
[10] 廖理,李梦然,王正位,等.观察中学习:P2P网络投资中信息传递与羊群行为[J].清华大学学报:哲学社会科学版,2015(1).
[11] Emekter R,Tu Y.Evaluating Credit Risk and Loan Performance in Online Peer-to-Peer (P2P) Lending[J].Applied Economics,2015,47(1).
[12] 廖理,吉霖,张伟强.语言可信吗?借贷市场上语言的作用——来自P2P平台的证据[J].清华大学学报:自然科学版,2015(4).
[13] Wang X,Zhang D,Zeng X,et al.A Bayesian Investment Model for Online P2P Lending[J].Communications in Computer & Information Science,2013(7).
[14] Zhao H,Wu L,Liu Q,et al.Investment Recommendation in P2P Lending:A Portfolio Perspective with Risk Management[C]// 2014 International Conference on Data Mining,IEEE,2015.
[15] Zhang Y,Jia H,Diao Y,et al.Research on Credit Scoring by Fusing Social Media Information in Online Peer-to-Peer Lending[J].Procedia Computer Science,2016,91(4).
[16] Glorot X,Bordes A,Bengio Y.Deep Sparse Rectifier Neural Networks[J].Journal of Machine Learning Research,2012(15).
