基于递归神经网络的自动作曲算法
2018-06-01李雄飞冯婷婷张小利
李雄飞,冯婷婷,骆 实,张小利
(1.吉林大学 计算机科学与技术学院,长春 130012;2.吉林大学 软件学院,长春 130012)
0 引 言
近年来利用计算机技术分析音乐情感的特性,以及以乐谱为研究对象的计算机作曲已成为计算机音乐的一大重要研究方向[1-5]。计算机算法是通过某种策略控制生成音符序列,进而组成音乐旋律,最终得到完整乐谱,此类方法需要大量音乐知识规则。而以音频为研究对象进行人工智能(Artificial Intelligence,AI)作曲,可使计算机自动生成音乐片段的排列组合生成新的音乐音频。基于音频的AI作曲不依赖大量的音乐知识规则,又能传递给听众直观感受。因此,该类算法比基于乐谱的传统作曲方法更具有实用性。本文以音乐音频作为研究对象,基于长短期记忆递归神经网络提出一种新的自动合成乐曲算法。
在传统计算机作曲方面,神经网络曾一度被认为不能学习到音乐的结构并且不适合用来做音乐作曲等研究,为解决该问题,Eck等[6]用了两个长短期记忆(Long short term memory, LSTM)模型来训练学习创作蓝调音乐,一个用于学习和弦,另一个用于学习旋律,和弦网络的输出连接到旋律网络作为旋律网络的输入。最终实验结果表明,系统能够学习标准的12小节蓝调和弦小节并且生成遵循和弦规律的音乐。此后,Franklin[7]也使用LSTM网络来学习和训练爵士音乐。他们开发了一种在主歌和副歌三等分的音调表示方法。在此基础之上,Liu等[8]又使用了递归神经网络(Recurrent neural network,RNN)来学习了古典音乐,采用由Allan&Williams收集的巴赫的midi片段数据集,他们首先验证了神经网络在重组音乐的能力,将神经网络学习重组的音乐片段与原始的巴赫音乐片段进行比对,此后进一步对使用神经网络利用音乐碎片进行谱曲,在验证方面,采用多分类的测试指标对实验结果进行测试,最终测试结果表明,与人类感官有着比较大的差距。
在传统研究中,梅尔倒谱系数(Mel frequency cepstrum coefficient,MFCC)在音乐信号上能够高效地识别音调和频率,一直被用作分析音乐音频,Dhanalakshmi等[9]采用MFCC和线性预测编码(Linear predictive coding,LPC)分别作为音频分类的特征向量,使用支持向量机通过训练将音频进行场景分类,结果证明MFCC作为特征向量时分类精度更高。Mathieu等[10]在GNU (General public licence)通用公共许可协议下开发了一个音频特征提取的系统YAAFE用于快速提取音频特征。而AI作曲又是以乐谱为载体进行研究,实质的研究为文本挖掘类研究,而本文首次提出以音频本身作为研究对象,从MFCC入手,将音频信号处理与AI作曲融合,提出了基于LSTM-RNN的音乐音频自动合成算法,验证了AI作曲以音频为载体的可能性,使得成果更直观地展现于听众。
1 与音乐生成模型相关的形式化
描述
单一的音符是没有意义的。从乐理上讲,一个曲子可划分为若干个小节,每个小节由一系列音符组成,因此,一个音乐小节是表达含义的最基本单位,将这些小节有机地组织起来才能体现出音乐情感和含义价值。著名的例子是莫扎特的圆舞曲《音乐骰子游戏》,他创作了176个音乐小节,然后将小节编号排列为两个特别的矩阵图,用掷骰子的方式来决定演奏的次序,每次掷骰子都是这些音乐片段的重组。本文将这样的可重复组合排序的一个或多个小节称为音乐模式,将大量音乐曲目分解为音乐模式,构成音乐模式库。这样,基于AI的音乐创作就可分为两个步骤:①在大量乐曲上训练音乐模型;②利用音乐模型从音乐模式数据库中抽取音乐模式组成乐曲。

定义1 单位音乐与音乐向量
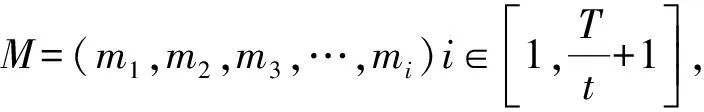
定义2 前序信息
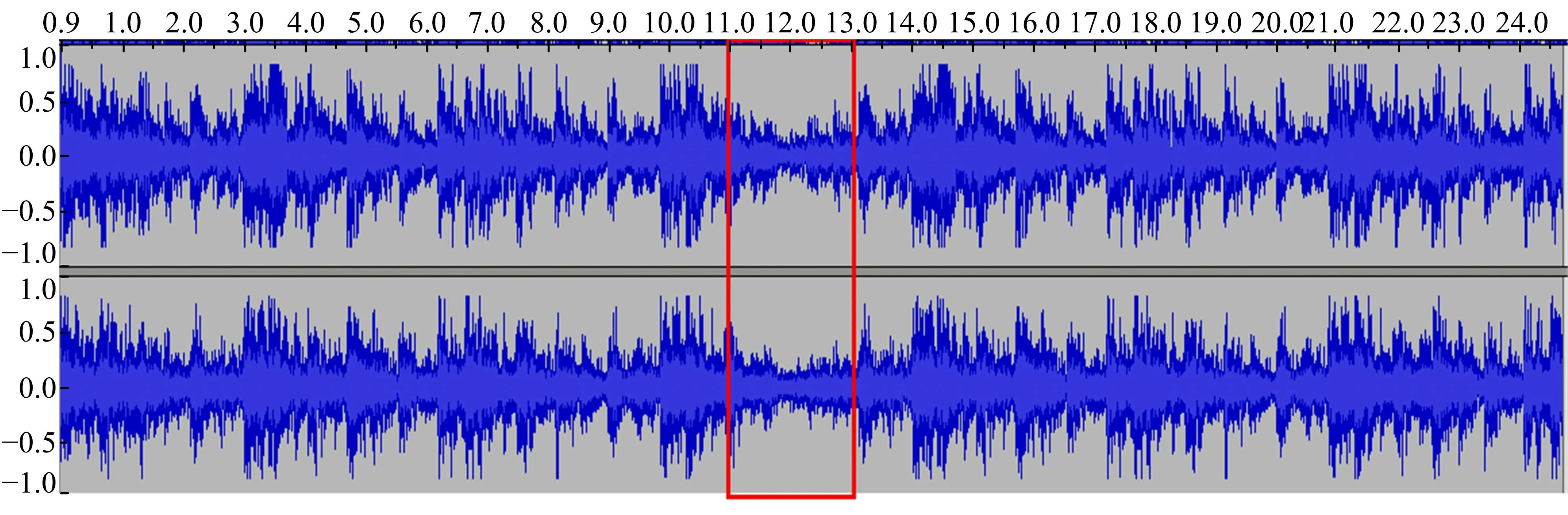
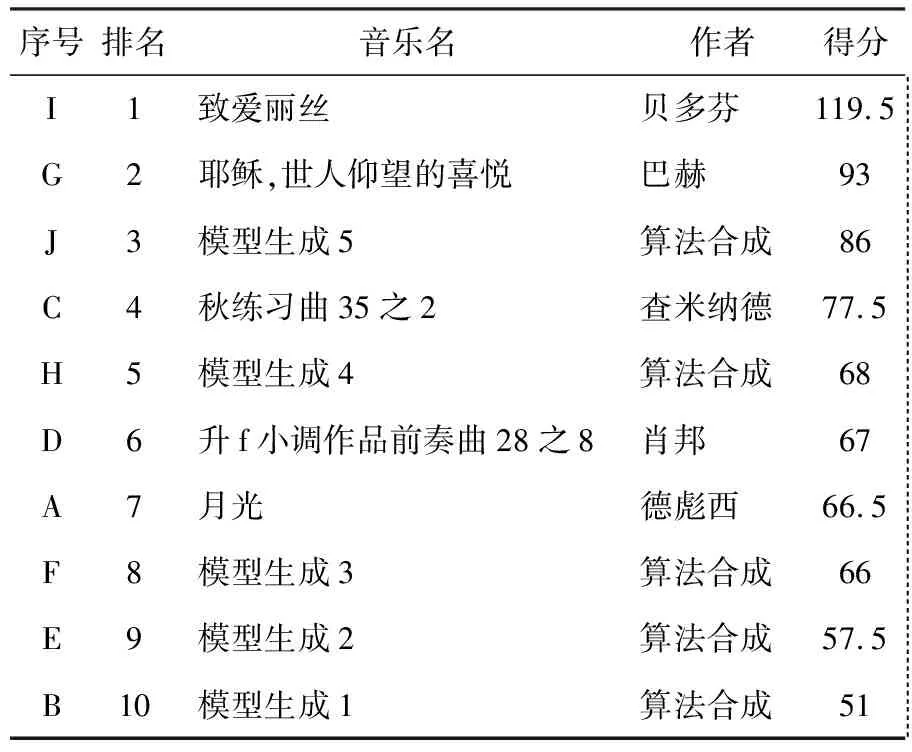
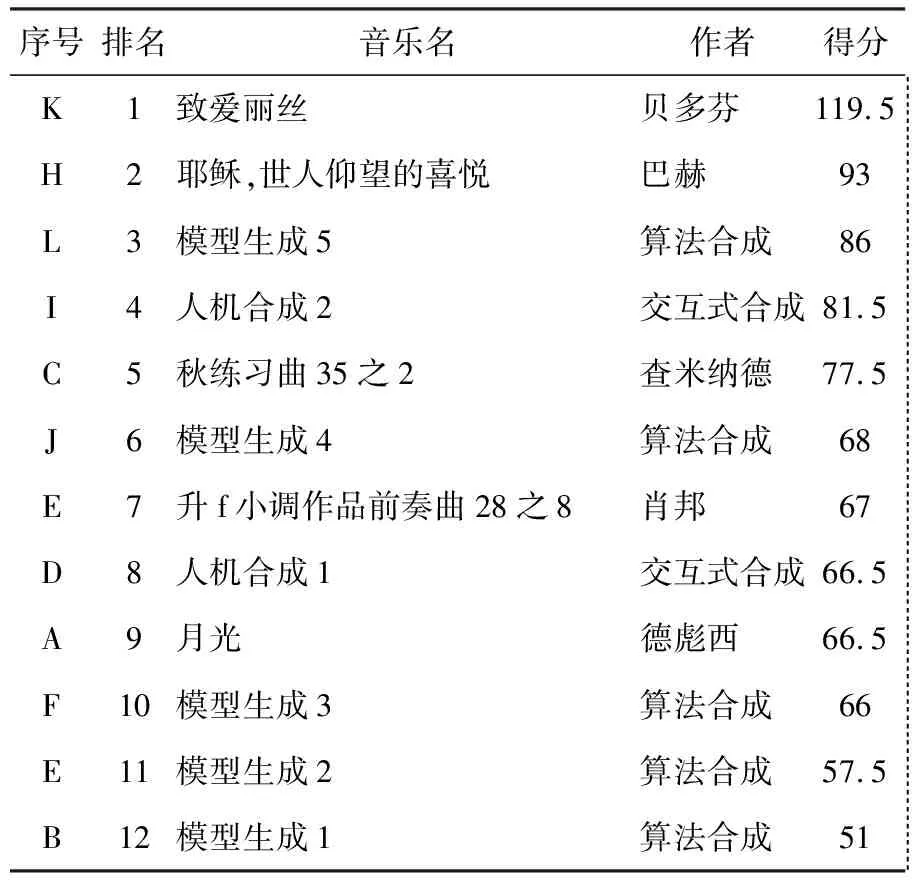
对于一段乐曲中任意一个单位音频mi,与其有时间顺序的前n(n 可以把合成算法看成是已知前i-1个单位音乐推测第i个单位音乐的问题,其中n 定义3 AI生成音乐 针对目标函数F,选择一个m1后,就音乐序列M=(m1,m2,,…,mn)而言,对任意0 选择一批音频乐曲用于构建训练集。将每个乐曲分割为单位音乐序列,具体步骤如下。 2.1.1 分割单位音乐 在获取单位音乐时,旨在保留音乐节拍的强弱性以及较短的旋律性,因此,若单位时长t的取值太小,会破坏小节的完整性,则丧失了音乐的强弱节拍感,若单位时长t取值太大,容易保留过多的旋律信息,经过试验,本文取单位时长t=3 s,当音乐速度为90~180 节拍/min时,单位音乐m包含的小节数约为2~3小节。音频编码中,编码流dm与时长有着依赖关系,依据音乐时长,将音频流切割成等单位时长的音频片段序列,式(1)用于切割流数据d(t): d(t)=dm[0:fmrt*t] (1) 式中:t为单位时长;fmrt为该音频文件的采样频率;dm[0:fmrt*t]表示对数据流dm的从下标0到下标fmrt*t的数据切片。 2.1.2 特征处理 音乐通过影响人的听觉感受以传递情感信息,实验表明,人的听觉感受对音调的变化是呈线性变化的。MFCC通过对频率和音调的对数关系转化反映了人耳的音高听觉特性。在以音频为载体的音乐情感和场景分类问题的研究结果表明,MFCC在音乐信号上能高效地识别音调和频率,可作为音频分类的特征[9]。因此,本文取MFCC作为单位音乐的特征。 常见的MFCC为39维,由13维静态系数、13维一阶差分系数以及13维二阶查分系数组成,其中差分系数表示音乐的动态特征,而13维静态系数又是由1维能量特征和12维系数构成。 MFCC的计算过程为: (1)对每一帧信号做快速傅里叶变换(Fast fourier transform, FFT)计算幅度频谱。 (2)将幅度频谱利用梅尔尺度变换到梅尔域,经过等带宽的梅尔滤波器组滤波之后,将滤波器组的输出能量进行叠加: (2) k=1,2,…,K 式中:Sk为第k个滤波器的对数能量输出;Hk(j)为第k个三角滤波器的第j个点对应的权值;|X(j)|为变换到梅尔尺度上的FFT频谱幅值;K为滤波器的个数,一般为24个。 (3)将滤波器的对数能量进行离散余弦变化,可以得到MFCC系数: n=1,2,…,L (3) 式中:L为MFCC静态系数的维数,一般L≤P,本文取L为13维。 至此,令V(mi)表示第i个单位音频mi的音乐向量,则V(mi)=(c1i,c2i,…,cni)称为单位音乐向量,其中V(mi)∈R,n为单位音乐向量的维数。 将提取完MFCC的单位音乐向量V进行Softmax归一化,对于V(mi)中的第k个元素ck,Softmax归一化的值为: (4) 则归一化后的单位音乐向量表示为V(mi)=(v1i,v2i,…,vni)。 训练样本表示为(V(pre(mi)),V(mi)),令包含了n首音乐M的数据集S={M1,M2,…,Mn},i为单位音频mi在数据集S中的索引。则,对于该模型来说,输入是单位音频mi的前序音乐序列pre(mi),形如[V(m1),V(m2),…,V(mi-1)],输出是单位音频mi的相似特征向量h,通过计算h与数据集S中单位音频的距离确定mi。 该模型目标函数设为tanh函数,LSTM-RNN模型音乐预测问题F(pre(mi);θ)问题可表示为参数集θ=(W,U)的函数构造问题: F(pre(mi);W,U)=hi (5) hi=oitanh(ci) (6) 式中:oi表示LSTM模型中的输出门,令Vi表示第i时刻的前序信息pre(mi)的音乐向量V(pre(mi)),φ表示sigmoid函数或tanh函数,则有: oi=φ(WoVi+Uohi-1) (7) (8) (9) 输入门Ii和遗忘门fi分别控制新内容的输入和旧内容的遗忘: Ii=φ(WIVi+UIhi-1) (10) fi=φ(WfVi+Ufhi-1) (11) 当记忆单元进行更新后,隐藏层会根据当前输入门得到的计算结果计算当前隐藏层hi,如式(6)所示。 至此,当W和U确定后,构造函数F也就唯一确定了。在LSTM中通常确定W和U的过程需引入优化函数RMSProp,令θ=(W,U),RMSProp的迭代过程如下: 从训练集中随机抽取一批容量为N的样本{V1,V2,…,VN},以及其相关的输出F(Vi;θ)及对应单位音乐mi。计算梯度θ和误差并更新r: (12) (13) 再根据r和梯度θ计算参数更新量并更新θ: (14) θ=θ+Δθ (15) 式中:ε为学习率;δ为数值稳定量;ρ为衰减速率。 由于音乐曲目通常在首尾两处单位音乐的MFCC与中间主体部分距离相差悬殊,图1展示了15首音乐的单位音乐特征的相邻两向量的距离,因此,分别将首尾部分的2个单位音频取出放入集合Sh和St,而其余部分作为乐曲主体放入集合Sb,即,对于一首时长为T的音乐M=(m1,m2,…,mk),k=T/t+1有m1,m2∈Sh;m3,…,mn-2∈Sb;mn-1,mn∈St,则数据集S=Sh∪Sb∪St,S共有N=k1+k2+…+kn个单位音乐。在音乐合成中,首先从集合Sh中随机挑选出一条单位音频m1作为输入,h作为输出,然后不断将算法合成的输出h与S中的单位音乐向量进行相似度匹配,本文中采用的相似度匹配策略是进行欧氏距离计算,距离最近的但为音乐向量即为模型预测的下一条单位音乐mi+1,如式(16)和式(17)所示。 mi+1=S[x] (16) x=index(min{d(h,m1),d(h,m2),…,d(h,mN)}) (17) 式中:x为单位音乐在数据集S中的索引;index为索引函数,取h与S中所有单位音频m的最短距离所对应的单位音频索引;N为数据集S中的单位音乐总数。 图1 相邻单位音乐向量间距离图Fig.1 Distance between adjacent units vector 两个单位音频ma、mb之间的欧式距离dab计算过程如下: (18) 式中:j表示单位音乐m的n维向量V的第j维向量值。 循环上述过程直到模型找到一首音乐m∈St,则生成终止,音乐序列生成完毕。 上述算法过程描述如图2所示。 图2 算法描述Fig.2 Algorithm description 利用训练得到的LSTM模型可生成一个全新的音乐序列(m1,m2,…,mn)。接下来是音频处理工作,在对音乐进行拼接时,相邻的单位音乐需要对音频进行平滑处理使完成后的新曲目显得自然而不突兀,所以平滑处理的结果直接影响到生成模型最终得到的音乐质量。 在音乐两两连接时选取首尾相接处相同长度,即相同时间长度的数据流部分,对数据进行削弱处理,为保持数据变化的流畅性,采取对数据进行线性削弱处理,其中线性比例系数的计算根据式(19)得到。 (19) 式中:dm为单位音乐m的流数据;x为当前数据值在数据流dm中的索引;函数l为dm数据流的格式化数组长度;y为线性削弱方式,y∈{fadeout,fadein},当y=fadeout时,做比例系数从1至0的线性削弱计算,相反,当y=fadein时,做比例系数从0至1的线性增强计算。 根据式(20)对数据进行线性衰减计算。 (20) 式中:x为当前数据索引值;s为采样位数。 时间参数t成为了至关重要的参数,其决定了播放时所能听到的时间长度,即平滑处理的数据块的大小。 图3和图4分别展示了当时间值为1 s和2 s时经过放大后的响度值,矩形框内为衔接点。从图4看出,当时间值为2 s时,变化范围略长,依然能明显感觉到淡入淡出的处理感,使两首曲子连接松散不够紧密,从而从听觉上能很明确地分辨并不是一首音乐,而做音轨响度分析时,从处理后得到的数据部分的音轨响度图可以看到音频衔接处有明显的长段削弱部分,与原始音乐频率有很大差异。 而图3所展示的时间t=1 s时音乐衔接部分的突兀感减弱而线性变化感也不明显,在平滑部分得到了比较好的结果,从听觉上辨别已经不明显,在平滑部分得到了比较好的处理结果。 图3 当t=1时的音轨响度图Fig.3 Loudness of tracks when t=1 图4 当t=2时的音轨响度图Fig.4 Loudness of tracks when t=2 3.1.1 测试数据与参数设置 根据音乐相关理论,古典音乐的情感通常不是固定的,总是激昂与平缓交替出现,这种现象在频谱上表现为能量的突变,本次实验根据这些突变将音乐预先且分为不同情感段,再根据不同的情感段产生的单位音乐集生成不同情感的音乐。 实验数据通过采集215首3/4拍,演奏速度为每分钟60~180节拍的古典音乐的乐谱,通过专业的软件将其输出为音频文件,然后将这些音频文件分割成以3 s为单位时长的单位音频共计15 158条。根据本文第1节的描述,每个分离后的单位音频由1~3个小节组成,这样的单位音频则包含了可被重复组合的音乐模式。在LSTM-RNN模型中,经过多次实验,训练过程中参数初始化设置如下: (1)设置优化函数RMSProp的全局学习率ε=0.001,初始参数值θ=0.9,数值稳定量δ=108,衰减速率ρ=0.0。 (2)设置神经元连接的断开率为0.3。 (3)设置迭代次数为20次。 3.1.2 测试实验 在对计算机作曲领域,很难通过客观评价指标去评价效果,所以,一般采用主观法进行测试。例如,Salas等[11]进行了基于语言规则的作曲实验并在最终测试时采用类图灵测试,即用户调查的方式,他们从实验结果中选择了5首音乐与作曲家创作的5首音乐一同构成了测试问卷,并请26位测试者参与实验测试,请实验者对他们播放的音乐进行排序。本文将沿用Salas等[11]的测试方法,将实验得出的乐曲与人为创作的乐曲交替顺序给测试者播放,并且请测试者打分,以及评判喜好,再统计得出测试结果。 本次测试共有10首测试音频,其中5首来自训练曲库,5首来自模型生成。共24人参与了本次测试的主观评价,其中11位学过乐器,10位表示喜欢古典音乐。在测试中,他们只能看到音乐曲目的序号,其他信息不予显示,测试者试听音乐后,根据主观判断进行打分(0~5分),0分则表示不好听,5分则表示非常好听。测试网站为http://47.94.96.142:8000/index/。测试音频顺序列表如表1所示。各首曲子的主观评价直接得分如表2所示。 表1 实验一测试音乐顺序列表Table 1 Test music list I 表2 实验一测试得分及排名结果Table 2 Rank of test scores(Test I) 考虑到乐理知识以及主观喜好的倾向性,将测试人员的打分进行了加权统计,音乐评分通过式(21)进行计算。 (21) 式中:αk为基础权重;βki为加分权重;sk为测试人员对该曲目的评分;k∈[1,n]表示测试人员,i∈[1,m]表示m个加分权重项。权重αk和βki的取值如表3所示。 表3 权重分值表Table 3 Weight score table 经计算,各首曲子的主观评价得分如表4所示。 通过表2与表4的统计结果表明,对于原始得分较高、排名靠前的曲目,通常是被大众所喜爱的,所以加权后对其没有造成影响,而群众认知度不高的曲目,在具有乐理基础以及喜好古典音乐的听众与普通测试者中的得分差异性较大,造成加权后的得分排名与原始得分排名有了一些差异。 表4 实验一测试加权得分及排名结果Table 4 Weighted rank and scores(Test I) 结果显示,本算法生成的音乐与人工作曲音乐的排名分布相对均匀,测试人员不能明确区分人工音乐和算法音乐,且在测试人员的打分排名中,模型生成的音乐有一首进入了排名的前三,而排在第一和第二的均是大家非常熟悉的音乐,但是得分末位也是来自本算法,证明算法生成的音乐质量有差异;另外,该实验结果也说明了在音频处理方面,本实验所采取的拼接算法并不容易让人们发现音乐的拼接点,即在音乐拼接平滑处理方面效果较好。 3.2.1 测试实验 音乐是极富个人色彩的作品,为了让本算法更具有灵活性,本文在3.1节实验一的基础上增加了交互式计算的部分,在开始生成音乐时,可由使用者指定一个音乐片段作为开头,在音乐声称中间曲目时可由使用者决定是否介入人工选择,如果介入,系统将会在生成mi时,根据LSTM的输出h与数据集S中的单位音乐进行匹配,将提供与h距离最短的3首单位音乐给使用者进行选择;如果不人工介入,算法默认自动匹配距离最短的单位音乐。加入人机交互部分后的算法流程如图5。 图5 人机交互式算法描述Fig.5 Algorithm description 本次实验选取了2首加入交互式计算产生的音乐与加入3.1.2节中的城市音乐列表进行对比测试,测试音乐顺序列表如表5所示,得分结果如表6所示。 表5 实验二测试音乐顺序列表Table 5 Test music list II 表6 实验二交互式测试加权得分及排名结果Table 6 Weighted rank and scores(Test II) 测试结果显示,加入交互式计算的效果整体比不加入交互式计算得到的音乐要好,证明加入交互式计算可使算法合成音乐的质量更趋于稳定。 本文以音乐音频为操作对象在AI作曲以音频为载体的方面进行了尝试,借鉴语音信号处理手段,以MFCC作为特征向量,将音乐曲目看成具有时间序列特性的音乐片段序列,并以LSTM-RNN作为训练模型进行生成训练,该模型不仅能生成新的音乐序列,而且能平滑地将音乐片段拼接为一条完整的音频,在以音频为载体而进行AI作曲方面做了很好的尝试,但是模型作曲有长有短,结果也参差不齐,作曲质量依赖于音频素材的数量和质量,在加入交互式计算后得到一些生成质量上的提升,但是在如何得到普遍更高质量的音乐和算法的适应性方面还有待改进。 参考文献: [1] 刘涧泉. 第三种作曲方式——论计算机音乐创作的新思维[J]. 中国音乐,2006(3):51-54. Liu Jian-quan. The third way of composing music on the new thinking of computer music creation[J]. Chinese Music,2006(3):51-54. [2] Turkalo D M. All music guide to electronica (book review)[J]. Library Journal, 2001,126(13):90. [3] Hiller L A, Isaacson L M. Experimental music/composition with an electronic computer[M]. New York: McGraw,1959. [4] Loubet E. The beginnings of electronic music in Japan, with a focus on the NHK studio: the 1970s[J]. Computer Music Journal,1998,22(1):49-55. [5] Sigtia S, Benetos E, Boulanger-Lewandowski N, et al. A hybrid recurrent neural network for music transcription[C]∥2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),Brisbane,QLD, Australia,2015:2061-2065. [6] Eck D, Schmidhuber J. A first look at music composition using LSTM recurrent neural networks[M]. Lugano:IDSIA USI-SUPSI Instituto Dalle Molle, 2002. [7] Franklin J A. Recurrent neural networks for music computation[J]. Informs Journal on Computing,2006,18(3):321-338. [8] Liu I, Ramakrishnan B. Bach in 2014: music composition with recurrent neural network[J]. Eprint Arxiv, 2014.https//arxiv.org/pdf/1412.3191.pdf. [9] Dhanalakshmi P, Palanivel S, Ramalingam V. Classification of audio signals using SVM and RBFNN[J]. Expert Systems with Applications,2009,36(3):6069-6075. [10] Mathieu B, Essid S, Fillon T, et al. YAAFE, an easy to use and efficient audio feature extraction software[C]∥International Society for Music Information Retrieval Conference, Ismir 2010, Utrecht, Netherlands,2010:441-446. [11] Salas H A G, Gelbukh A, Calvo H. Music composition based on linguistic approach[C]∥Advances in Artificial Intelligence,Mexican International Conference on Artificial Intelligence, Pachuca,Mexico, 2010:117-128.2 音频预测和音乐合成
2.1 训练数据集组织
2.2 模型训练与预测
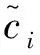



2.3 平滑拼接


3 实验结果与分析
3.1 实验一



3.2 实验二


4 结束语
