复杂高维数据中异常点挖掘算法研究*
2018-06-01徐晓丹
徐晓丹
(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
0 引 言
异常点挖掘是数据挖掘领域的一个重要分支,其目的是在数据集中找出那些明显偏离常规数据对象的点,这些点往往表现为由不同的机制产生[1].目前对异常点没有统一的定义,一般是指那些行为模式明显区别于普通数据的点.在某些文献[1-4]中,异常点也被称为离群点、不一致点(discordant object)、例外点(exception)、 差错点(aberration)、特色点(peculiarity)和惊奇点(surprise)等.不同的术语反映了在不同的情形下,研究者对待这类数据的不同方式.
随着数据挖掘需求的深入,那些包含重要信息的异常点正受到越来越多的重视.实际上,在很多应用中,人们更关注的是那一小部分表现异常的数据,因为这些数据中往往包含着重要信息.例如,异常网络传输行为预示着黑客或病毒入侵,异常的地质活动有可能是地震或海啸的前兆,异常的天气数据有可能预示着极端天气的发生等等.这些偏离常规的数据,可能正是某种规律的真实反映,往往比正常数据更有价值.因此,对异常点的检测研究在信用卡欺诈、网络入侵检测、疾病诊断、突发事件检测、时空数据异常等领域已成为数据分析的主要对象,越来越彰显其价值[4-9].
传统的异常点检测算法面对高维复杂数据时效率明显降低,为了解决这个问题,出现了很多新的算法,这些算法能有效地处理高维数据.这些最新算法主要包括基于近邻的方法、基于子空间的方法和基于集成的方法.
基于近邻的方法主要是根据一个点在其近邻的排序值来获得异常度值,这些近邻包括k近邻[10]、反向近邻[11]和共享近邻[12].在k值的选择上,文献[13]提出了一种基于迭代随机采样策略的排序算法,该方法定义了一个可观测因子(observability factor,OF)来衡量一个点的异常值,为了确定最佳的k值,该方法还定义了OF的信息熵,使OF的熵值达到最大的k值,就是最佳的k值,因为此时OF值的区分性最大,即每个点的Outlier的排序能力最大.基于近邻方法都是在所有的维度空间中进行计算,然而随着维度的不断增加,很多异常现象只在由少部分维度组成的子空间中体现,如果在所有维度中进行计算,那么那些不相关的维度就会干扰计算结果,影响算法的效率.因此,查找和异常特性相关的有效子空间,是高维空间异常点检测的一个关键,也是当前研究的一个热点.
基于子空间的异常点检测方法主要可以归纳为两类:一是基于稀疏子空间查找方法[14-16];二是相关子空间查找方法[17-23].基于稀疏子空间方法根据用户给定的稀疏系数的阈值,将整个数据集映射到稀疏子空间中,那些在子空间中出现的数据被认定为异常点.基于相关子空间方法的基本原理是找到和异常特性相关的子空间,在这些子空间中计算点的异常值.基于相关子空间的异常点检测算法是一种精确查找策略,为了得到算法最优需要遍历所有可能的子空间,就不可避免地存在子空间组合爆炸问题.随机采样子空间的方法不需要遍历所有的子空间,但由于采样的不完整性可能会造成一些异常点不能被识别出来.
基于集成的方法是对现有的这些算法进行有效集成.目前,在合适的子空间上集成异常点算法越来越受到研究者的关注[24].随机子空间集成方法[25]的原理是每次随机选择d维数据生成子空间,在子空间内使用LOF算法得到异常点值,将这些异常点值合成后得到最终的结果.该方法存在的一个问题是对算法的选择顺序较为敏感,导致算法的稳定性得不到保障.文献[26]提出的方法不是采样特征维度,而是通过随机采样数据集中的数据对点进行局部密度估计,以减少集成算法的时间开销.为了提高算法的准确率并降低时间开销,文献[27]提出了一种基于特征集成和数据采样的异常点检测方法,该算法是对文献[25-26]提出方法的综合:使用文献[25]提出的Feature Bagging获得集成算法中每次迭代的子空间,在计算异常点时使用文献[26]的子采样Subsample方法获取计算所需要的数据.此算法中每次迭代使用随机采样特征得到子空间的方法提供了集成算法部件的多样性,在获取一个点的局部区域时添加Subsample方法可以有效提高算法的精度并节省计算时间.
为了更好地分析上述算法的特性,本文对上述算法进行了深入的分析,相较于以往文献[3-9]中只提供部分算法比较而言,本文通过一系列实验,使用不同评价指标提供了较为全面、系统的算法比较,同时,本文采用的10种算法是上述这3类最新算法的典型代表,更能综合地分析算法的性能,以期为新算法的研究提供一定的参考.
1 实验结果及分析
本文在ELKI[28]提供的平台上对10种代表性算法在8个数据集上进行测试比较,这些算法包括基于统计的方法GUMM[29]、k近邻相关算法(kNN,kNNW,ODIN,LOF,FASTABOD,LoOP)、基于子空间的方法(COP,SOD)和基于集成的算法(HiCS).本实验采用的数据集来源于UCI数据集,异常点的预处理采用文献[30]的方法.表1列出了实验中使用的数据集,每个数据集包括数据集名称、数据大小、异常点的个数、属性值及异常点的类别.例如,SpamBase数据集中包含4 601个数据,其中异常点的个数有1 813 个,实验中把non-spam这一类作为异常点处理.

表1 实验用数据集
精度是衡量异常点检测算法的一个常用指标.图1列出了10种算法在8个数据集上的精度r-precision[31](下文用r表示)的比较结果.
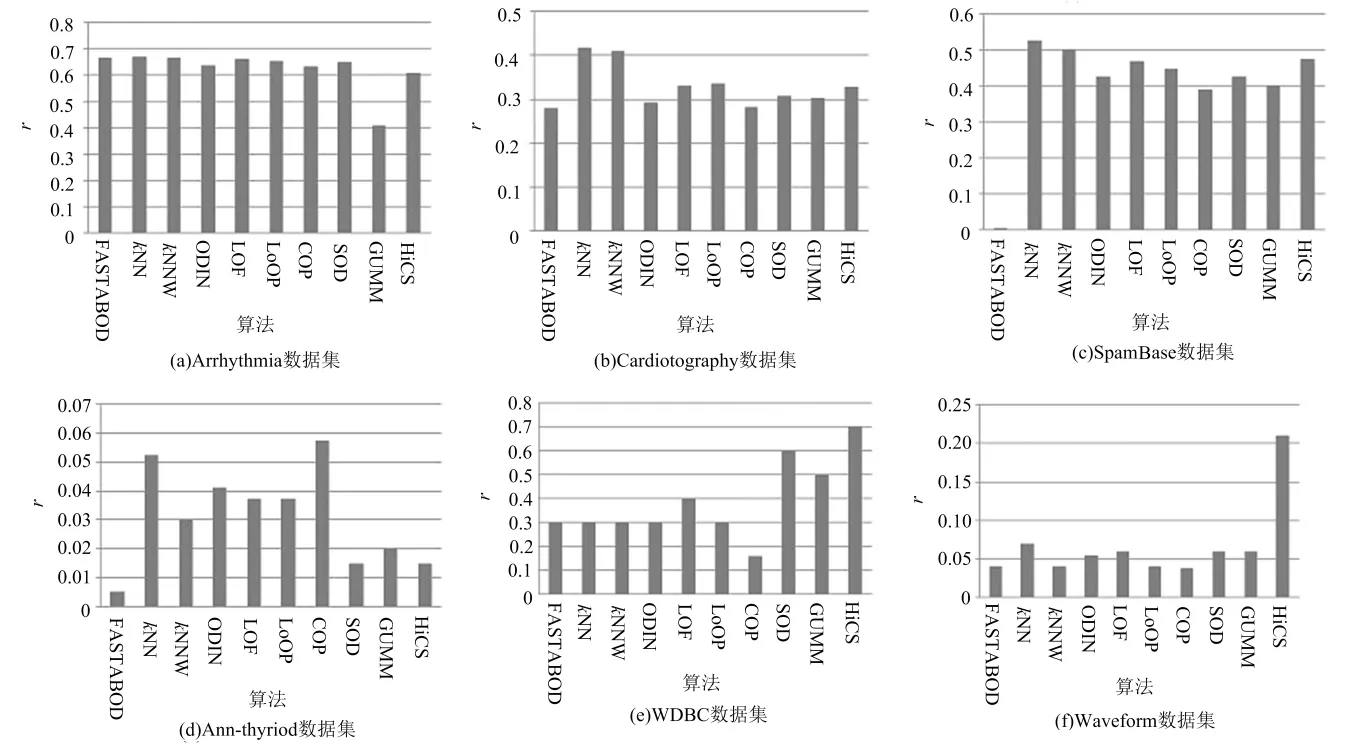

图1 不同数据集上精度r值比较
从图1可得到,基于近邻的算法在各个数据集中的结果较为稳定,在Arrhythmia,Cardiotography,SpamBase和Ann-thyriod这4个数据集中精度r的值为最优.而HiCS算法和FASTABOD算法在不同的数据集上差异较大,例如,HiCS算法在WDBC和Waveform中效果最好,在PenDigits,KDDCup99和Ann-thyroid 这3个数据集中效率最低;对FASTABOD算法来说,在 PenDigits数据集上得到了最优值,而在SpamBase 和 Ann-thyroid 上的值最低,其部分原因在于这些数据集中异常点的个数相对于正常点来说比例太低,从而导致r值偏低.
另一个值得注意的是,在PenDigits数据集中,FASTABOD算法要显著高于其他算法,其原因在于该数据集的属性描述的是0~9的数字信息,这些属性是相关联的,因此,采用余弦相似度计算的FASTABOD算法能够得到较好的效果,而对于WDBC 和 Waveform等包含较多不相关的属性的数据集来说,基于子空间的方法SOD及子空间集成方法HiCS表现突出.
基于高斯的异常点检测算法主要依赖于数据的分布,因此,在WDBC数据集上获得了较好的效果,而在Arrhythmia,Ann-thyriod等数据分布无规律性的数据集上效率较低.
除了精度值r外,AUC(area under the corresponding curve)[8]是评价异常点检测算法的另一个常用指标,它计算的是ROC(receiver operating characteristic)曲线的面积,ROC曲线的每个点是不同概率下真正类率(true positive rate)和负正类率(false positive rate)的比值.图2给出了FASTABOD,kNN,kNNW,ODIN,LOF,LoOP和HiCS这些算法在AUC上的值,同时为了分析k值对算法的影响,给出了k从3变化到50的曲线.
从图2可以得到,kNN,kNNW算法在各个数据集上的AUC值普遍较好,而HiCS算法在各个数据集上的差异较大.例如,在WDBC和Waveform数据集上,HiCS的值要明显优于其他算法,而在Arrhythmia数据集上效率最低.值得注意的是,FASTABOD算法在SpamBase数据集上的AUC值异常低,几乎为0,部分原因是数据集中异常点个数比例偏小,还有部分原因和数据集本身的特点相关:SpamBase数据集描述的是电子邮件文档中单词和字符出现的频率,这些数字化的频率信息几乎没有组的属性,并且本质上没有相似的性质.因此,FASTABOD算法不适合这样的数据集,因为它是通过余弦来计算对象的相似性.
为了分析k值对算法的影响,图2给出了k值取3到50时,各个基于k近邻算法的AUC值比较结果.由于HiCS在高维数据和较大数据集上运行较慢,所以该算法在Ann-thyriod和KDDCup99中的运行结果在图2中不显示,FASTABOD算法在数据集KDDCup99运算中由于内存不足问题终止了计算,其计算结果也没有在图2中显示.
从图2可以看出,受k值影响最小的是FASTABOD算法,它在这些数据集中的值随k值的变化非常小;受k值影响最大的是HiCS算法.就基于距离的算法而言,kNNW由于进行了加权调整比kNN更加稳定,而对基于密度的算法来说,采用局部密度统计的算法LoOP受k值的影响比LOF算法要小得多.
同时可以观察到的另一个现象是,所有的算法在KDDCup99 和 PenDigits这2个数据集上的AUC值变化幅度明显要高于其他数据集.这是由于这2个数据的异常点比例值要明显小于其他数据集(其中KDDCup99为0.4%,PenDigits为0.2%).同理,对SpamBase(39.4%的异常点)和Arrhythin (45.7%的异常点)这2个数据集来说,由于包含的异常点比例较高,因此,这2个算法受k值的影响相对小一些.
算法效率是衡量异常点检测方法实际应用的一个重要方面,表2给出了这10种算法在不同数据集上的运行时间.由于KDDCup99数据集包含6万多条数据,因此,其运行时间明显大于其他数据集,本次不列入表2进行比较.从表2可以看出,基于近邻的方法(kNN,kNNW,ODIN,LOF,LoOP)的效率明显高于其他算法,另外,HiCS算法在每一个数据集上的时间复杂度都高于其他算法,这是因为算法本身需要遍历所有可能的子空间.
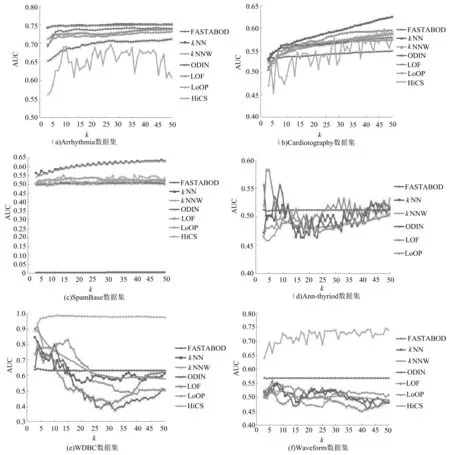

图2 不同数据集上AUC值比较(k从3到50)
2 结 语
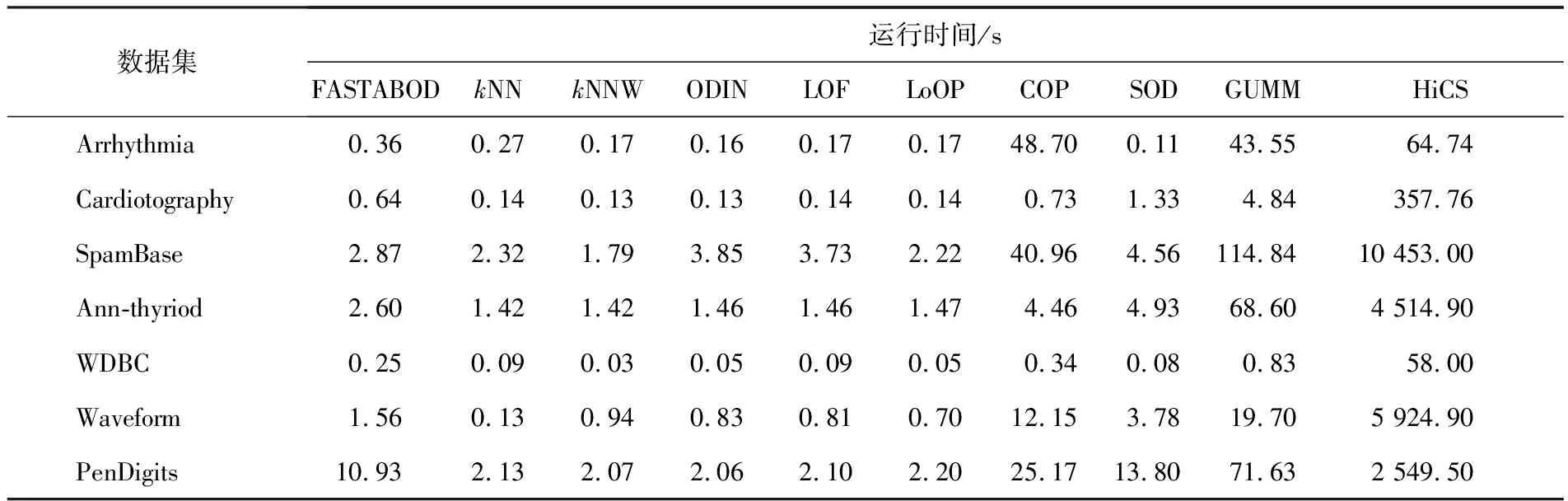
表2 异常点检测算法在各个数据集上的运行时间
在以上分析中给出了最新的高维数据异常点检测方法的实验分析比较及算法特性分析.在异常点检测领域,面对日益复杂的数据,新的问题不断涌现,主要体现在以下几个方面:
1)基于近邻的异常点检测算法通常对邻居数目k值的选择较为敏感,如何找到最合适的k值是基于近邻算法的一个难题.
2)异常点(离群值)往往表现出局部的异常行为.然而,在高维空间中对特征进行局部相关性分析并非一件易事,同时,如何准确测量相关性便成为更具挑战性的问题.
3)集成算法是提高算法效率的有效途径,而高维数据中部分维度与异常点的检测任务无关,因此在子空间上作特征的集成是一种较为有效的集成方法.利用穷举法获取的子空间虽然精度高但存在组合爆炸的问题,使用随机子空间的方法,如何保证随机子空间方法的精度是目前面临的一个问题;此外,集成方法中一个关键是如何针对异常特性选择准确率高的算法,如何来评价这些算法的优劣,对这些问题的深入研究值得期待.
4)由于异常点在数据集中所占的比例非常低,缺乏评价的统一标准,因此,如何对异常点检测算法进行有效的评价也是一个悬而未决的问题.
异常点挖掘作为数据挖掘领域的一个热门分支已在越来越多的领域展开研究.本文针对当前异常点挖掘所面临的数据高维和复杂问题展开深入分析,通过实验详细分析了当前最新的相关技术的特性,并对当前面临的主要问题及进一步研究方向进行了有效探讨.
参考文献:
[1]Chandola V,Banerjee A,Kumar V.Anomaly detection:A survey[J].ACM Computing Surveys,2009,41(3):1-58.
[2]Hodge V,Austin J.A survey of outlier detection methodologies[J].Artificial Intelligence Review,2004,22(2):85-126.
[3]Zhang Y,Meratnia N,Havinga P.Outlier detection techniques for wireless sensor networks:A survey[J].IEEE Communications Surveys and Tutorials,2010,12(2):159-170.
[4]Gogoi P,Bhattacharyya D K,Borah B,et al.A survey of outlier detection methods in network anomaly identification[J].Computer Journal,2011,54(4):570-588.
[5]Kaur G,Saxena V,Gupta J P.Anomaly detection in network traffic and role of wavelets[C]//International Conference on Computer Engineering and Technology.Chengdu:IEEE,2010:46-51.
[6]Phua C,Lee V,Smith K,et al.A comprehensive survey of data mining-based fraud detection research[J].Artificial Intelligence Review,2010,21(3):60-74.
[7]Gupta M,Gao J,Aggarwal C C,et al.Outlier detection for temporal data:A survey[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(9):2250-2267.
[8]Zimek A,Schubert E,Kriegel H P.A survey on unsupervised outlier detection in high-dimensional numerical data[J].Statistical Analysis and Data Mining the Asa Data Science Journal,2012,5(5):363-387.
[9]Aggarwal C C.Outlier analysis[M].New York:Springer,2013:50-89.
[10]Huang H,Mehrotra K,Mohan C K.Rank-based outlier detection[J].Journal of Statistical Computation and Simulation,2013,83(3):518-531.
[11]Radovanovic M,Nanopoulos A,Ivanovic M.Reverse nearest neighbors in unsupervised distance-based outlier detection[J].IEEE Transactions on Knowledge and Data Engineering,2015,27(5):1369-1382.
[12]Pan Z M,Chen Y L.Local outlier detection algorithm based on shared reversek-nearest neighbor[J].Computer Simulation,2013,30(2):269-273.
[13]Ha J,Seok S,Lee J S.A precise ranking method for outlier detection[J].Information Sciences and International Journal,2015,324(S):88-107.
[14] Zhang J F,Zhang S L,Chang K H,et al.An outlier mining algorithm based on constrained concept lattice[J].International Journal of Systems Science,2014,45(5):1170-1179.
[15]Aggarwal C C,Yu S.An effective and efficient algorithm for high-dimensional outlier detection[J].The VLDB Journal,2005,14(2):211-221.
[16]Zhang J,Jiang Y,Chang K H,et al.A concept lattice based outlier mining method in low-dimensional subspaces[J].Pattern Recognition Letter,2009,30(15):1434-1439.
[17]Dutta J,Banerjee B,Reddy C K.RODS:Rarity based outlier detection in a sparse coding framework[J].IEEE Transactions on Knowledge and Data Engineering,2016,28(2):483-495.
[18]Kriegel H P,Kroger P,Schubert E,et al.Outlier detection in axis-parallel subspaces of high dimensional data[C]// Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining.Berlin:Springer-Verlag,2009:831-838.
[19]Emmanuel M,Schiffer M,Seidl T.Adaptive outlierness for subspace outlier ranking[C]//ACM Conference on Information and Knowledge Management.Toronto:ACM, 2010:1629-1632.
[20]Emmanuel M,Schiffer M,Seidl T.Statistical selection of relevant subspace projections for outlier ranking[C]//Proceedings of the 27th International Conference on Data Engineering.Hannover:IEEE Computer Society,2011:434-445.
[21]Keller F,Emmanuel M,Bohm K.HiCS:High contrast subspaces for density-based outlier ranking[C]//Proceedings of the 28th International Conference on Data Engineering.Arlington:IEEE,2012:1037-1048.
[22]Stein B V,Leeuwen M V,Back T.Local subspace-based outlier detection using global neighbourhoods[C]//International Conference on Big Data.Washington:IEEE,2016:43-53.
[23]Zhang J,Yu X,Li Y,et al.A relevant subspace based contextual outlier mining algorithm[J].Knowledge-Based Systems,2016,99(S):1-9.
[24]Aggarwal C C.Outlier ensembles[J].Acm Sigkdd Explorations Newsletter,2017,14(2):49.
[25]Lazarevic A,Kumar V.Feature bagging for outlier detection[C]//Proceedings of the 17th International Conference on Knowledge Discovery and Data Mining.Chicago:ACM,2005:157-166.
[26]Zimek A,Gaudet M,Campello R J G B.Subsampling for efficient and effective unsupervised outlier detection ensembles[C]//Proceedings of the 19th International Conference on Knowledge Discovery and Data Mining.Chicago:ACM,2013:428-436.
[27]Pasillas-Diaz J R,Ratte S.Bagged subspaces for unsupervised outlier detection[J].Computational Intelligence,2016,33(3):507-523.
[28]Achtert E,Kriegel H P,Reichert L,et al.ELKI data mining[EB/OL].(2010-03-01)[2010-08-10].https://elki-project.github.io/releases/.
[29]Eskin E.Anomaly detection over noisy data using learned probability distributions[C]//Proceedings of the 17th International Conference on Machine Learning.San Francisco:ACM,2000:255-262.
[30]Campos G O,Zimek A,Campello R J,et al.On the evaluation of unsupervised outlier detection:Measures,datasets,and an empirical study[J].Data Mining and Knowledge Discovery,2016,30(4):891-927.
[31]Craswell N.Encyclopedia of database systems[M].Berlin:Springer,2009:2453-2455.
