Spark和Flink平台大数据批量处理的性能分析
2018-05-29马黎
马 黎
(1.武汉大学计算机学院,湖北 武汉 430072;2.商丘职业技术学院学报编辑部, 河南 商丘 476000)
0 引 言
信息时代,数据呈几何级增长。对这些大数据的存储和处理需求也随之增加。通常而言,大数据不仅包括大量的数据,同时还包括存储和处理这些数据的新范式和各种技术。在这个背景下,催生了众多处理框架,如MapReduce[1,2]、Apache Spark[3,4]和Apache Flink[5]等。对这些技术框架进行研究具有较大意义,可直接指导项目开发和应用。
自从Google公司在2003年推行MapReduce后,该框架已经引发了一场技术革新[6]。该框架以并行化、分布式的方式处理和生成大型数据集。即MapReduce框架分割数据,且在集群之间对其进行分发;然后,再以并行的方式对划分出的数据片段执行相同的操作;最后,对结果进行聚合,并送回主节点。该框架对所有任务的调度和检测进行管理,并且在任务失败的情况下重新执行该任务。
通常来说,MapReduce及其开源版本Apache Hadoop[7]是首批面向大数据存储和处理的分布式编程技术。自此之后,大数据的快速发展促使了一些新工具出现。Apache Spark正是这些框架中的一种,即一种基于内存的大规模数据快速处理通用引擎。而Apache Flink是近两年内备受关注的新框架,可用于分布式流数据和批量数据处理。
简单来说,Apache Spark是基于弹性分布式数据集(Resilient Distributed Datasets, RDD)的数据结构[8],其开发动机是解决MapReduce/Hadoop范式中的局限性[9]。且Spark允许用户程序将数据加载到内存中,并反复进行查询,因此它是在线计算和迭代计算的合适工具。Apache Flink框架着眼于在分布式系统上,处理具有非常低的数据延迟和高容错性的数据。Flink的核心特征是能够实时处理数据流,提供了一个较高的容错机制,使数据流应用可以持续地恢复状态。这一机制持续地生成分布式数据流和操作符。Flink的两个主要的API是DataStream和DataSet,它们支持流式数据和批量数据的处理。且这两个API均建立于底层流式数据引擎之上。
本文对Apache Spark和Apache Flink框架的ML库进行了比较研究。主要目的是研究这两个框架在进行批量数据处理时的性能差异和相似性。主要比较了两个框架的ML库都具备的两个算法,即支持向量机(Supported Vector Machine, SVM)算法和线性回归(Linear Regression, LR)算法。此外,本文还实现了分布式信息理论的特征选择(Feature Selection of Distributed Information Theory, FS-DIT)算法,以进一步比较每个框架的不同功能。
1 Spark和Flink的比较
本节将介绍Spark和Flink两个平台的引擎间主要差异和相似性,以解释两个平台分别适用的场景。然后,将重点介绍实施在这两个平台中的三个机器学习算法之间的主要差异,这三个算法分别为FS-DIT算法,SVM算法和LR算法。
1.1 引擎间的比较
两个引擎之间的第一个显著区别在于摄取数据流的方式不同。Flink是一个native流式处理框架,即数据进入后立即处理,可以处理批量数据;而Spark最初的设计理念则是通过弹性分布式数据集(Resilient Distributed Datasets, RDD)对静态数据进行处理,且Spark使用微批处理的方式处理流式数据。因此,Spark对输入数据进行分割,每次处理一个数据片段。其主要优点在于Spark选择的DStream结构是一个简单的RDD队列,允许用户在流处理和批处理之间切换。但当系统要求非常低的延迟时,微批处理的执行速度可能无法达到要求,而Flink在这些系统中有着极好的兼容性,这是因为Flink的特性是对于所有类型的工作负载均使用流式数据。
与Hadoop MapReduce不同,Spark和Flink支持数据复用和迭代。Spark通过显式缓存,在不同迭代间将数据保存在内存中。然而,Spark采用无环图执行计划,这意味着其需要在每次迭代时调度和运行相同的指令集。反之,Flink在其引擎中基于循环数据流(即一次迭代进行一次调度),实现了彻底的迭代处理。
早期Spark主要使用JVM的堆内存[10],对所有的内存进行管理。但这个解决方案可能会发生内存溢出等问题。得益于新的Stungsten项目,这些问题得到了一定程度的解决。现在,Spark可以通过DataFrames管理自己的内存栈,并充分利用了现代计算机中可用的内存层次结构(L1和L2 CPU缓存)。然而,Flink的研究人员则在设计初始就考虑到了这些问题。由此,Flink的设计团队提出了一个具有自调控能力的内存栈,并采用二进制格式的提取和序列化策略。这些设计好处很明显,具有:内存错误少,垃圾收集压力小,以及更好的空间数据表示等优点。
在优化方面,这两个框架的机制都是通过分析用户提交的代码,产生一个给定执行图的最佳管道代码。举例来说,在Flink中,一个join操作可被规划为两个集合的一次置乱,或对最小元素的一次广播。Apark也提供了手动优化,允许用户控制分区和内存缓存。本文省去了对编码和调整的易用性,以及各种不同操作符的比较,因为这些因素不会对执行性能造成影响。
1.2 算法运行的细节比较
1.2.1 特征选择算法
本文在两个平台上都实施了一个基于信息理论的特征选择框架[11],即在一个贪婪算法中集合多个信息论准则。通过一些独立性假设,允许将多个准则变换为Shannon熵的线性组合项,即互信息(Mutual Information, MI)和条件互信息(Conditional Mutual Information, CMI)。该框架中包括了一些相关算法,例如最小冗余最大相关,信息增益等。该算法的主要目的是采用一个简单的得分机制对特征进行评价,并根据排名选择相关性更高的特征。特征评分通用框架可被表示如下:
(1)
式中,第一项表示候选输入特征Xi和类Y之间的相关性(互信息),第二项表示已经选择的特征(在集合Set中)和候选特征之间的冗余(互信息),第三项表示两个集合Xj和Xi与类Y之间的条件冗余(条件互信息)。η表示条件互信息的权重因子,α表示互信息的权重因子。
本文对已有的框架重新进行设计,以期达到在分布式环境中更好的表现。实施的主要改动如下:
(1)逐列转换:大部分特征选择算法按列进行计算。这意味着以往将数据转换为纵列格式或许能提高计算性能,例如当对相关性或冗余进行计算的时候。相应地,本文提出的程序的第一步旨在将原始集合转换到列中,其中每个新实例包含着原始集合中每个特征和分区数值。
(2)保留重要信息:一些预计算的数据,例如转换输入或者初始相关性,被缓存放在内存中,以避免下个阶段对其进行重复计算。如果该信息在开始的时候被计算过一次,那么该信息的保留在内存能够显著加快算法性能。
(3)变量的广播:为了避免在每次迭代中对转换后的数据进行移动,本文保留了这个设置,并且对当前迭代中涉及到的列(特征)进行广播。例如,在第一次迭代中对类特征进行广播,以计算每个分区中的初始相关性。
在Flink的实现中,本文使用了批量迭代过程,以处理贪婪程序。在Spark的实现中,本文使用了带缓存和重复任务的典型迭代过程。
Flink代码在GitHub库中,具体网址如下:https://github.com/sramirez/flink-infotheoretic-feature-selection。
Spark代码被汇集到一个包,已经传到了Spark的第三方库中,网址如下:https://spark-packages.org/package/sramirez/spark-infotheoretic-feature-selection.。
1.2.2 支持向量机分类算法
Spark和Flink都使用一个线性优化器,实施SVM分类器。即待求解的最小化问题如下:
(2)
式中,q为权重向量;xi∈Rb为数据实例;β为正则化常数;fi为凸损失函数。默认正则化项均为L2范式,损失函数均为:
fi=max(0,1-yiqTxi)
(3)
高效通信的分布式双坐标上升算法(Distributed Dual Coordinate Ascent Algorithm, DDCAA)[12]和随机双坐标上升(Stochastic Dual Coordinate Ascent, SDCA)[13]算法被用在Flink中,以求解先前定义的最小化问题(即式(2))。DDCAA包括每个分区上SDCA的一些迭代和部分结果的聚合。
Spark采用了分布式随机梯度下降(Stochastic Gradient Descent, SGD)算法。在SGD中,数据的一个样本被用于在每个阶段中计算次梯度。仅对来自每个工作节点的部分结果在网络上进行发送,以更新全局梯度。
1.2.3 线性回归
线性最小二乘法是Spark中实施的另一个简单的线性方法。尽管针对回归而设计,但其输出可适用于二元分类问题。线性最小二乘遵循如式(2)所示的最小化公式和优化方法(基于随机梯度下降算法),但使用了平方损失函数,且无正则化,即:
(4)
该算法的Flink版本与Spark的开发人员创建的算法非常相似。Flink使用随机梯度下降来逼近梯度解。然而,Flink只提供了平方损失,而Spark则提供了许多选项,例如logistic函数损失等。
2 实验结果
本节将在相同数据集上,使用上述三种机器学习算法的实验,以比较Spark和Flink的性能。
2.1 数据集
实验中使用的数据集为ECBDL14数据集[14],该数据集曾被用于大数据的机器学习竞赛。ECBDL14数据集中包括631个特征(包括数字和分类属性)和3200万个实例。同时该数据集涉及一个类分布高度不均衡的二元分类问题:正相关实例仅占2%。针对这一问题,本文应用了两个预处理算法。首先对原始数据中少数类的实例进行复制,直到两个分类的实例数量达到平衡。最后,对于FS-DIT算法,使用对数据集进行离散化。
实验中使用5个不同的百分比对原始数据集进行随机采样,以测量两个框架可扩展性的性能,使用的预处理数据集百分比分别为10%、30%、50%、75%和100%。由于当前Flink的限制,每个ECBDL14数据集样本的150个特征子集用于SVM算法。上述数据集的基本情况如表1所示。

表1 ECBDL14数据集的基本描述
2.2 结果比较
实验中,对SVM算法进行100次迭代,其中步长为0.01,正则化参数为0.01。对于LR算法,也使用100次迭代,步长为0.00001。最后,对于FS-DIT算法,使用最小冗余最大相关算法[15]选择出10个特征。
本文将总学习时长(秒)作为SVM和LR算法的评价标准,将总运行时长(秒)作为FS-DIT的评价标准。在所有的实验中,使用了9个计算节点和一个主节点组成的集群。计算节点的硬件配置如下:两个Intel Xeon CPU E5-2630 v3处理器,每个处理器8个核,主频均为2.40 GHz,20 MB缓存;2个2 TB的HDD,128 GB的RAM。在软件方面,本文使用了以下配置:来自Cloudera的开源Apache Hadoop分布式系统的Hadoop 2.6.0-cdh5.5.1;Apache Spark和MLlib 1.6.0,279个核心(每个节点31个核心),900GB RAM(每个节点100 GB);Apache Flink 1.0.3,270个任务管理器(每个核心30个任务管理器),每个节点100 GB RAM。
表2给出了使用简化版本数据集的实验结果。共有150个特征,对SVM进行100次迭代。由于当前的Spark的ML库中没有SVM算法,故没有比较Spark ML。从该表中可以观察到,Spark的性能大幅优于Flink。当数据集的规模增长时,Spark和Flink之间的时长差异也随之变大,实验开始阶段,Flink的耗时约为Spark的2.5倍,而使用完整的数据集时Flink的耗时为Spark的4.5倍。
图1是表2的曲线形式,可以看出随着预处理百分比数据越高,Spark MLlib与Flink的差距越大,差距最大可以达到625秒左右。
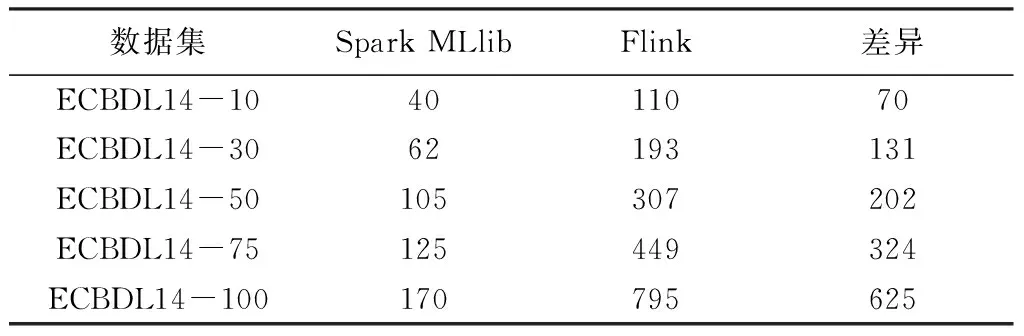
表2 支持向量机的学习时长(s)

图1 SVM算法在不同平台上的性能比较
表3比较了LR算法,进行100次迭代所得的学习时长。Spark MLlib(API接口基于RDD)和Spark ML(API接口基于DataFrame)之间的时长差异主要是由于ML运行时,对数据集从DataFrame到RDD进行内部转换(但对于用户来说,DataFrame的API接口比RDD接口更加友好,实际使用中,推荐使用Spark ML。因为建立在DataFrame基础上的Spark ML中的一系列算法更加适合创建包含“数据清洗—特征工程—模型训练”等一系列工作的ML管道)。Flink的耗时大约为Spark ML的8倍。因此,与Flink相比,Spark MLlib和Spark ML版本的性能优于Flink。从本文的学习时长来看,Spark MLlib稍微优于Flink ML。
图2是表3的曲线形式,可以看出,对于LR算法来说,Spark MLlib的学习时长没怎么增加,说明了LR算法在Spark MLlib平台上非常稳定,不随预处理数据集的多少变化而变化,而且学习时长最少。而Spark ML和Flink会随着数据集的大小起伏变化。预处理数据集越大,学习时长越大。
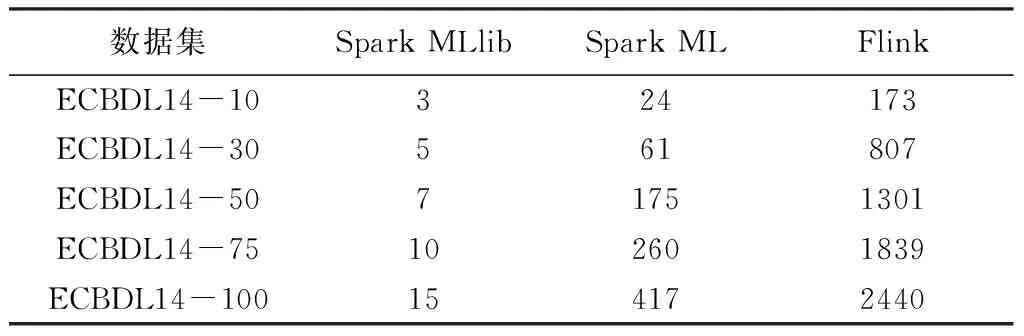
表3 线性回归的学习时长(s)
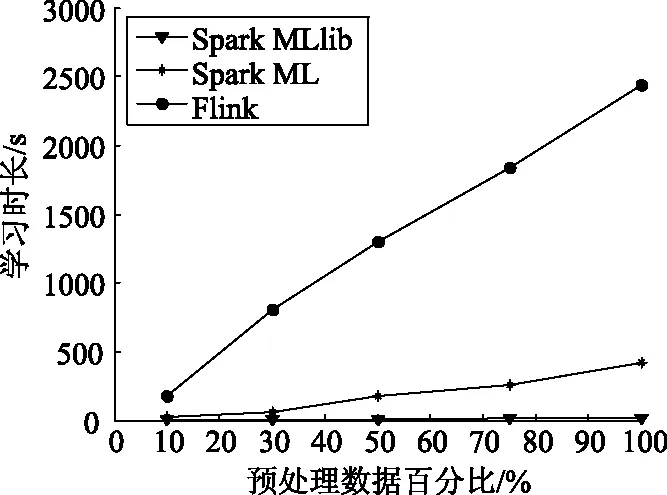
图2 LR算法在不同平台上的性能比较
表4比较了FS-DIT算法的总运行时长。其中,从离散后的数据集中选择了前10个特征。如前面所述,Spark MLlib和Spark ML之间的时长差异来自于所面向的数据类型不一样。从表4可以观察到,当使用10%,30%和50%的数据集时,Flink的运行时长约为Spark的9-10倍;当使用75%的数据集时,Flink的时长约为Spark的7-8倍;当使用完整数据集时,Flink的时长约为Spark的4倍。
图3是表4的曲线形式,对于FS-DIT算法,Spark ML和Spark MLlib表现出了相似的性能,其细微区别表现在它们所面向的数据类型不一样。在运行总时长方面,它们均优于Flink,在数据集较少的时候,其时长差异最大。从这方面看,Spark更加成熟。这印证了在批处理方面,Spark的确具有比Flink更好的适应性。

表4 FS-DIT的运行时长(s)

图3 FS-DIT算法在不同平台上的性能比较
Flink是一个新框架,而Spark则正成为大数据环境中的参考工具。Spark通过版本不断的更新,实现了不少的性能改进,而Flink则刚给出了第一个较为稳定的版本。虽然Spark的一些性能改进在Flink设计之初就考虑过(当然两者之间也相互学习借鉴)。但从实验结果来看,Spark依然是一个比Flink成熟得多的框架。
3 结 语
本文对两个流行的大数据处理和存储的框架Spark和Flink可扩展性进行了比较研究。使用了这两个框架库中都具有的SVM算法和LR算法。本文还在两个平台上实施并测试了特征选择算法。得出结论:Spark的可扩展性更佳,总运行时长更短。其次,虽然Spark MLlib和Spark ML之间的性能差异很小,但前者还是略微优于后者。
总体来说,在批处理方面,Spark优于Flink,Spark获得的业内认可度也更高。但Flink商业应用的吸引力巨大,已经有一些研究表明Flink的流处理比Spark更好(本文研究的是批处理)。经过必要的改进后,会成为分布式数据流分析的重要参考工具。这可能也是华为战略投资Flink的原因之一。
:
[1] Vaidya M. MapReduce: a flexible Data Processing Tool[J]. Communications of the Acm, 2010, 53(1): 72-77.
[2] 王加亮, 秦勃, 刘健健,等. 基于MapReduce的交互可视化平台[J]. 电信科学, 2012, 28(9): 22-27.
[3] 彭特里思. Spark机器学习[M]. 南京:东南大学出版社, 2016.
[4] 孙科. 基于Spark的机器学习应用框架研究与实现[D].上海:上海交通大学, 2015.
[5] Rabl T, Traub J, Katsifodimos A, et al. Apache Flink in current research[J]. it - Information Technology, 2016, 58(4): 157-165.
[6] Dean J, Ghemawat S. Simplified data processing on large clusters[J]. In Proceedings of Operating Systems Design and Implementation, 2004, 51(1): 107-113.
[7] 肖强, 朱庆华, 郑华. Hadoop环境下的分布式协同过滤算法设计与实现[J]. 现代图书情报技术, 2013, 29(1): 83-89.
[8] Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C]// Usenix Conference on Networked Systems Design and Implementation. 2012: 112-122.
[9] Junqueira B F, Reed B. Hadoop: The Definitive Guide[J]. Journal of Computing in Higher Education, 2001, 12(2): 94-97.
[10] 罗永刚, 陈兴蜀, 杨露. 一种Mapreduce作业内存精确预测方法[J]. 电子科技大学学报, 2016, 46(6): 986-991.
[11] 张跞. 基于信息论的特征选择算法研究[D]. 哈尔滨:哈尔滨理工大学, 2013.
[12] Jaggi M, Smith V, Taká?倣 M, et al. Communication-Efficient Distributed Dual Coordinate Ascent[J]. Advances in Neural Information Processing Systems, 2014, 31(4): 3068-3076.
[13] Shalev-Shwartz S, Zhang T. Stochastic Dual Coordinate Ascent Methods for Regularized Loss Minimization[J]. Journal of Machine Learning Research, 2012, 14(1): 201-213.
[14] Triguero I, Río S D, López V, et al. ROSEFW-RF: The winner algorithm for the ECBDL’14 big data competition: An extremely imbalanced big data bioinformatics problem[J]. Knowledge-Based Systems, 2015, 87(14): 69-79.
[15] 张新静, 徐欣, 凌至培,等. 基于最大相关和最小冗余准则及极限学习机的癫痫发作检测方法[J]. 计算机应用, 2014, 34(12): 3614-3617.
