基于基准相似空间分布优化的偏好预测方法
2018-05-28高全力
高 岭 高全力 王 海 王 伟 杨 康
1(西安工程大学计算机科学学院 西安 710048) 2 (西北大学信息科学与技术学院 西安 710127) (gl@nwu.edu.cn)
随着“大数据”时代的到来,数字化信息资源呈现出几何级爆炸性的增长,其展示平台与资源获取途径虽然在近年来有了较大的发展,但受制于数据稀疏性与冷启动问题[1],影响了推荐服务的准确度[2].特别是随着移动客户端的普及,资源展示界面越来越小型化,用户及服务提供商对于高质量的推荐系统的需求也越来越大.
大量研究者通过深入的实践研究,给出了有效的推荐服务实现方法.例如融合项目内容过滤的推荐策略[1-2]、结合图模型的推荐策略[3]、基于项目间隐性信任关系的推荐策略[4]等.其中,基于协同过滤的推荐算法应用最为成熟和广泛,其在个性化音乐电台、视频网站、图书网站等领域都有广泛的应用.但是其仍有2个局限性一直困扰着研究人员和服务提供商:数据稀疏局限性[5]和冷启动局限性[6].数据稀疏性问题指的是在当前大多数的推荐系统中,受制于目前的信息采集手段与用户浏览量等问题,导致了多数用户仅有少量的偏好行为记录,基于此现有的推荐系统难以建立起有效的用户兴趣模型,也就难以提供准确的推荐服务.冷启动是数据稀疏性的极端表现,指的是完全没有相关用户的偏好行为记录,或者没有用户对新商品作出过评价,在这种情况下也就难以为该用户生成推荐服务.
针对这些问题,许多研究者都提出了不同的解决方案,Fouss等人[3]基于图模型相关理论提出了一种基于随机游走的节点相似度计算方法,有效地缓解了上述2个局限性对推荐服务精度的影响;Chen 等人[5]提出了一种随着时间变化并考虑用户接受能力的推荐方法,在数据稀疏性的环境下,提高了推荐准确度;朱夏等人[6]用研究云环境下基于协同过滤的推荐策略,取得了更好的推荐精度与推荐效率;Linden等人[7]提出了一种独立于用户与项目数量的实时推荐系统,有效的缓解了数据稀疏性与冷启动问题;王鹏等人[8]提出了一种基于核密度估计的用户兴趣估计模型,能够更好地描述用户兴趣在项目空间上的分布,提高了数据稀疏环境下的推荐质量;Xue等人[9]提出了一种基于位置增强的目的地预测方法,通过概率估计提高数据密度,有效地缓解了数据稀疏性问题;Guo等人[10]提出了一种通过融合信任关系缓解数据稀疏性与冷启动问题的协同过滤方法;潘一腾等人[11]提出了一种基于信任关系隐含相似度的度量方法,能够充分挖掘用户在评分和社交数据中的隐含信息,提高了数据密度与推荐质量.
在这些方法中,待预测偏好用户最近邻的选取只是根据行为相似性算法,度量用户偏好行为间的相似性,并根据此获取待预测偏好用户的偏好近邻及其相应的偏好行为,通过不同的偏好生成策略生成推荐服务.这些方法都没有对相似性值进行判定,也没有考虑偏好发生的上下文信息对用户偏好的相似性的影响,特别是受用户偏好行为记录的稀疏问题(数据稀疏性问题)影响,所获取的偏好近邻个数较少,在此基础上获取的用户最近邻,即使与当前用户的偏好行为不相似,由于近邻用户较少,也被当作当前用户的最近邻,这必然会影响推荐服务的准确度.针对这种情况我们采用用户-用户间相似全局中心与相似幅度获取相似基准空间,并基于平均近邻与异常评分对相似基准空间外的用户行为进行修正,能够获取到与待预测偏好用户偏好行为更相似的最近邻用户.
1 基准相似空间分布优化的预测方法
1.1 行为相似度度量
在基于协同过滤算法的推荐系统中,用户的历史偏好行为数据一般都是采用评分值的形式进行存储,如表1所示.基于用户的历史偏好数据,通过行为相似性算法度量用户偏好行为间的相似性,并根据此相似性值,获取最近邻并根据最近邻的偏好行为为当前用户生成推荐结果.
目前主要的相似性度量方法主要有标准的余弦相似度(cosine similarity)、修正的余弦相似度(constrained cosine similarity)、皮尔森相关系数(Pearson correlation coefficient)三种,设用户i与j间都有偏好行为记录的商品集合为Ii j,具体描述为:
1) 标准余弦相似性.将用户的历史偏好行为抽象为与之相匹配的评分向量,用各评分向量间的夹角来度量相应用户偏好差异程度:
(1)
其中,Pi a与Pj a分别指代i与j对于商品a的历史偏好值.
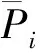
(2)
3) 皮尔森相关系数.通过减去当前商品的被评分均值来修正用户间偏好相似性的计算:
(3)
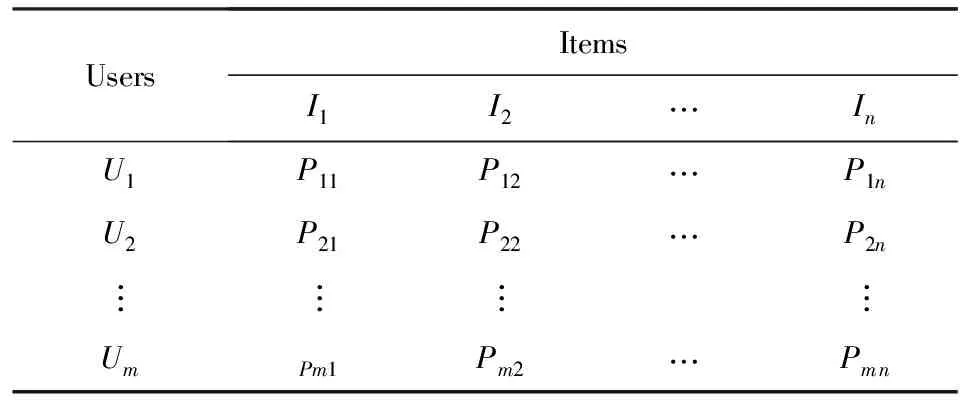
Table 1 The User-item Ratings Table表1 用户-项目评分表
1.2 基准空间分布优化
现有的基于协同过滤的推荐系统[11-13]多是基于余弦相似度、修正的余弦相似度、皮尔森相关系数等偏好行为相似程度度量方法,得到由用户的历史偏好行为所体现出的其偏好间的相似情况,并进一步的获取其偏好近邻,并依其近邻的相关选择提取待预测用户的偏好[14-17].这些方法在选取最近邻时,只是依据由行为相似性算法所获取的相似性度量值直接进行比较来获取,这种做法特别是在数据稀疏的环境下,会将一些与当前用户相似程度较低的用户作为其最近邻,影响了推荐的精度.据此,我们提出一种用户偏好行为相似性修正策略,方法流程图如图1所示:
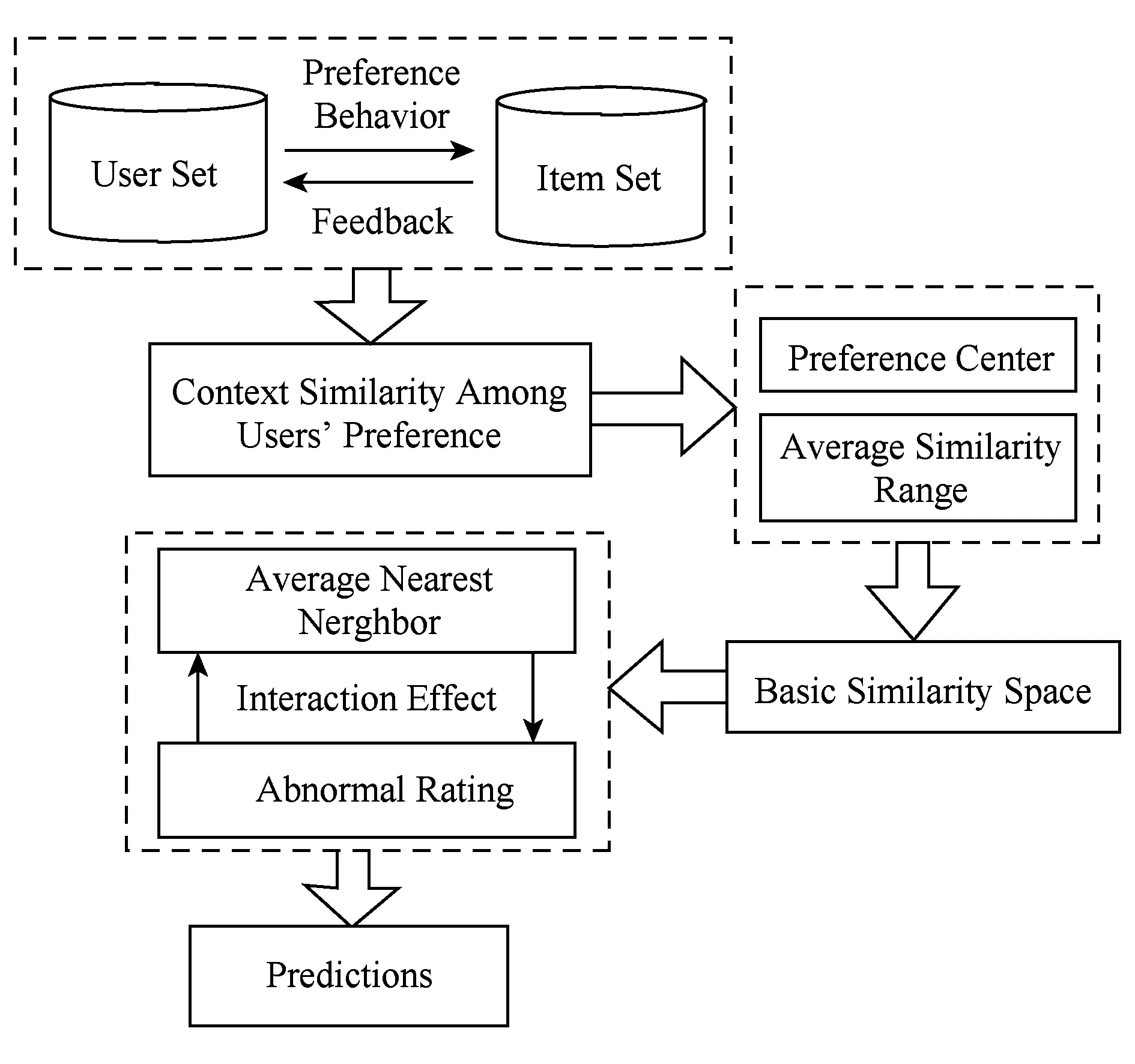
Fig. 1 The generic process of generate preference图1 偏好获取总体流程图
方法首先通过结合上下文环境的偏好行为相似程度度量方法,获取用户-用户间的原始的偏好相似度,根据偏好相似度分布首先获取偏好相似度的偏好中心点,根据其他相似度值距相似度偏好中心点心点的平均距离获取平均相似幅度,在距中心点左右两侧,距离为平均相似幅度的偏好相似度区间内,属于正常的偏好行为相似度值,我们只对于其两侧区间外的相应数据进行修正.相关定义及方法如下.
定义1. 上下文用户偏好相似性(context similarity among users’ preference).基于各种上下文信息与用户历史偏好所体现出用户偏好间的相似性.主要方法是在基于历史偏好的行为相似性度量方法基础上加入产生偏好时的各种上下文信息:
Sim(i,j)=S(i,j)×(1+Sim2(Ci,Cj)),
(4)
其中,S(i,j)为采用传统的相似度度量方法(如式(1)~(3)所示,具体选择由实际应用环境而定)所获取的传统用户偏好间相似关系;Ci与Cj表示用户i与j上下文信息;Sim2(Ci,Cj)为用户i与j上下文信息间相似性:
(5)
其中,clic与cljc分别表示用户i与用户j的上下文信息c的度量值,也即是采用量化的数据表示上下文信息.
定义2. 偏好中心点(preference center,PC).偏好中心点指的是在所有的用户相似度值的全局平均值.其获取方法是获取每个用户与其他所有用户在上下文环境下的相似性值,用均值算法获取其平均值,偏好中心点代表了整个用户群体间的平均偏好相似情况,具体度量方法为
(6)
其中,PC为偏好中心点,U为所有用户的集合,card(U)为用户集合U内的用户数量,Sim(i,j)为用户i与j偏好行为间的相似程度度量值.
定义3. 平均相似幅度(average similarity range,ASR).相似幅度指的是其他所有用户间的相似度值距离偏好中心点的距离,平均相似幅度指的是相似幅度的平均值,平均相似幅度能够反映出用户偏好相似程度的平均分布情况,具体度量方法为
(7)
其中,ASR表示平均相似幅度.
定义4. 基准相似空间(basic similarity space,BSS).指的是以偏好中心点为中心,以平均相似幅度为半径的用户间偏好相似度分布区间.基准相似空间是为了区分正常的偏好相似度值与需要修正的相似度值而设定的,基准相似空间内的相似度值属于能够涵盖和表示多数用户间相似度分布的分布空间,具体的区分策略为
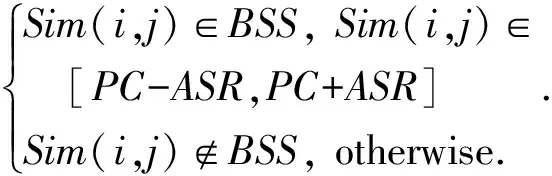
(8)
获取了基准相似空间,也即是获取了待修正的用户偏好行为(基准相似空间之外的相似度值),我们基于最近邻个数与当前用户的异常评分个数对其进行修正,具体的修正策略及相关定义如下.
定义5. 平均近邻(average nearest neighbor,ANN).用户的近邻数指的是与待预测偏好用户偏好相似度值不为零的用户个数,其表示了与待预测偏好用户有类似行为的用户数量,用户的近邻数越多,那么存在与待预测偏好用户偏好相似用户的概率也就越大,也就越有可能获取到更佳的偏好提取效果.那么用户的平均近邻就指的是所有用户近邻数的平均值,具体度量方法为
(9)
其中,ANN指代平均近邻数值,NNi指代用户i的近邻数量,card(U)指代U中的用户数量.
定义6. 异常评分(abnormal rating,AR).异常评分指的是在用户的历史偏好行为中,由于受特定的自身因素及上下文环境影响所产生的一些与该用户的其他偏好不相符的行为记录,例如以电影评分为例,用户A对于“惊悚”类的电影评分普遍较低,却较为反常的对其中一个“惊悚”电影评分较高,这条偏好行为记录就是A的异常评分记录.异常评分的数量能够反映出用户历史偏好的波动情况,异常评分越小,则说明依据该用户的历史偏好行为记录为其生成推荐,越有可能生成符合其偏好的推荐结果.我们通过i对任一m的历史偏好行为,与用户i对于与商品m同类商品的平均偏好差异性来区分用户i对商品m的历史偏好行为是否为异常评分:
如果
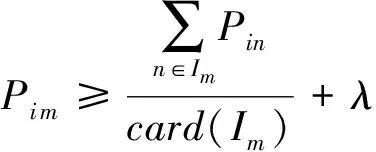
(10)
其中,Pi m指代用户i对于商品m的偏好分值,ARi指代i的异常评分集,Im指代与商品m同类的其他商品集合,λ为修正参数.
那么在获取到平均近邻与异常评分后,对于Sim(i,j)∉BSS的相似偏好行为的修正策略为

(11)
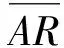
1.3 偏好获取
在获取到修正后的用户偏好行为相似性之后,根据新的相似度值获取用户的最近邻(相似度值最高的若干个近邻),并根据最近邻的选择为当前用户生成推荐,具体为
(12)
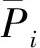
1.4 方法实施步骤
基于基准相似空间分布优化偏好获取方法的实施步骤:
1) 获取用户-项目间的历史偏好数据与相关上下文数据;
2) 通过行为相似性度量方法获取用户间偏好行为初始相似度值;
3) 根据偏好近似度分布,计算偏好中心点与平均相似幅度;
4) 构建基准相似空间;
5) 建立基于平均近邻与异常评分交互影响的修正模型,优化基准相似空间;
6) 根据修正后的相似度值为用户生成推荐结果.
2 实验设计及结论
2.1 实验数据集
由于在公开的数据集中还没有包含上下文信息的数据集,我们使用的是扩充后的BookCrossing数据集*http://www2.informatik.uni-freiburg.de/~cziegler/BX,数据集BookCrossing由Cai-Nicolas Ziegler使用爬虫程序从BookCrossing图书社区上采集的真实数据.其中共包含278 858名读者对于271 379图书的行为记录.通过加入合理的上下文生成规则,建立了一个模拟真实数据集BookCrossing-MN.生成规则的选取原则为:将现有的情景感知推荐方法在扩充后的数据集上进行测试,以MAE、多样性为度量标准,通过判断生成规则对于上述推荐方法的推荐质量的影响,来选取最优的生成规则.经过反复实验测试,本文选用规则:对于用户的位置和状态信息,通过将具体的信息与数值进行关联(编号),根据相关数值循环填充原始数据集.
BookCrossing-MN共包括4个部分:
1)BC-MN-Users.读者的ID、位置、年龄;
2)BC-MN-Books.图书的标题、编号、所属领域、出版社、作者、页码;
3)BC-MN-Ratings.读者对相应图书的偏好值;
4)BC-MN-Contexts.包括时间、位置、状态信息等上下文信息.
2.2 实验评价标准
我们所采用的平均绝对误差(mean absolute error,MAE)是统计精度度量策略中比较常用和受到广泛认可的评价策略.MAE通过度量所提出的推荐算法预测出的用户偏好与实际用户偏好间的差异程度来评价所提出推荐算法的优劣,其值越小则说明提出的推荐算法所作出的预测与用户实际偏好间的偏差越小,推荐准确度越好.假设根据偏好提取方法获取到的用户偏好假设值为{p1,p2,…,pN},而其对应的真实用户偏好分值为{q1,q2,…,qN},那么MAE可表示为
(13)
另一个指标是覆盖率(coverage rate,Coverage),其指代相应偏好获取算法处理长尾效应的能力,即是为了防止推荐系统只推荐一些比较热门的资源,而无法把一些可能满足用户偏好的冷门项目推送至特定用户.推荐效果与其值是正比关系.具体表示为
(14)
其中,R(u)指代向用户u生成的推荐列表,I指代训练集中项目集合.
多样性描述了推荐列表中项目两两之间的不相似性.多样性值越大,表明推荐结果覆盖大多数用户兴趣点的概率也就越大.假设s(i,j)∈[0,1]定义了项目Ii和Ij之间的相似度,|R|表示推荐列表的长度,则推荐列表R的多样性:
(15)
2.3 实验设计及结论
本文的实验首先对所提出的算法中涉及的参数进行检验实验,以取得针对当前数据集,推荐结果最优的参数取值;然后将本文算法与现有的偏好获取方法进行对比,以检验所提出算法能否取得更佳的推荐准确度.
实验1. 参数λ检验实验.
针对实验所用数据集BookCrossing-MN,我们分别提取20%,40%,60%,80%的数据作为训练集,其余作为测试集进行实验,对异常评分检测参数λ进行实验.经过反复测试,针对当前数据集,采用修正的余弦相似度所获取的用户相似度相比与其他2种方法,能够取得更好的推荐精度,所以我们采用修正的余弦相似度作为基础相似度度量方法,并采用式(1)中策略对其进行修正.参数λ的选取直接影响异常评分的选取,间接地对推荐精度产生影响.我们改变参数λ在不同数据集上的不同取值,通过对比所提出算法的MAE值来选取针对当前数据集最优的参数λ值.经过反复实验测试,我们选取了5组有代表性的参数λ取值,如表2所示,相关的实验结果如图2~5所示.

Table 2 The Value Series of λ表2 参数λ取值表
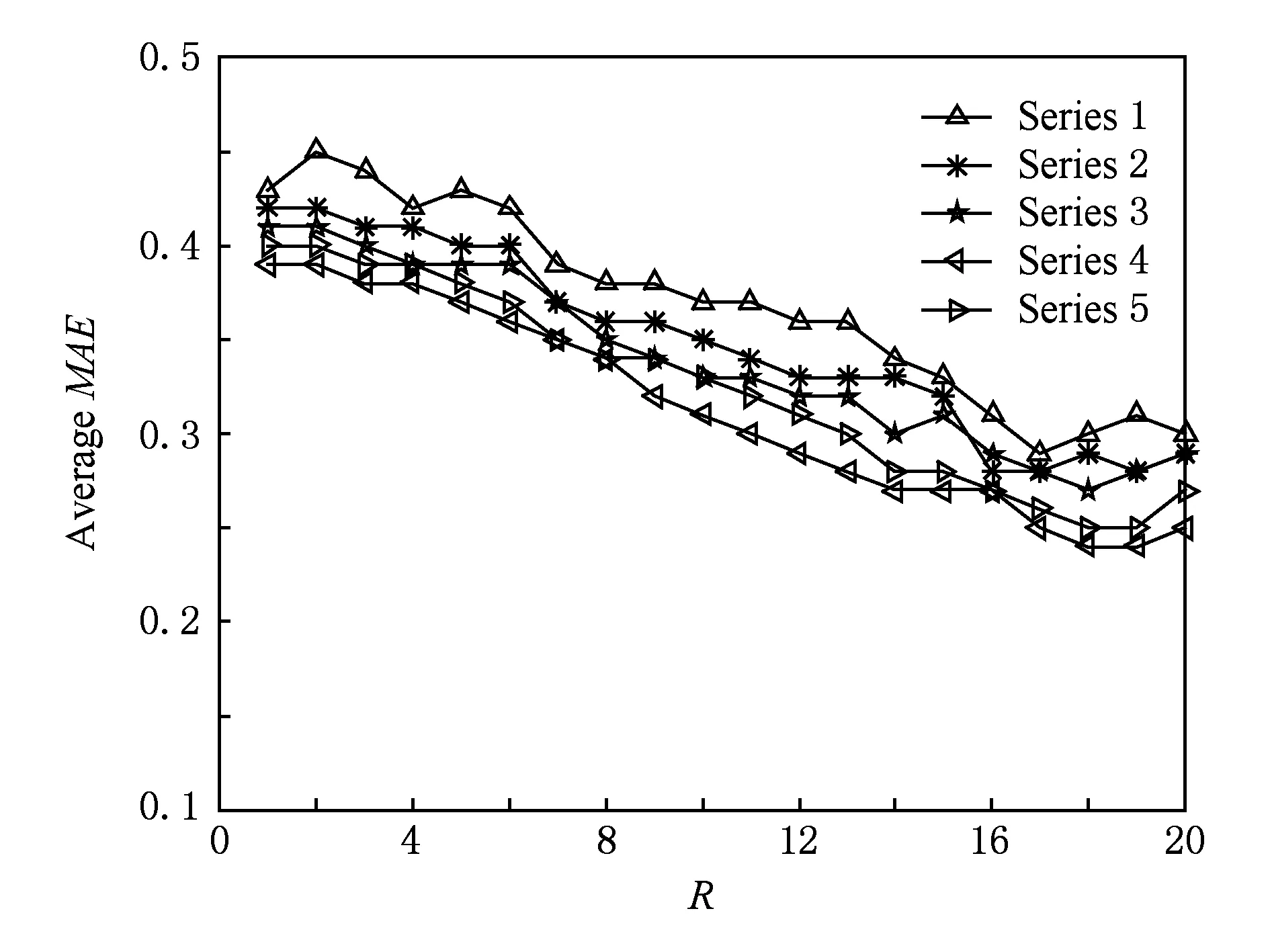
Fig. 2 The result of 20% data as training set图2 20%数据为训练集实验结果

Fig. 3 The result of 40% data as training set图3 40%数据为训练集实验结果
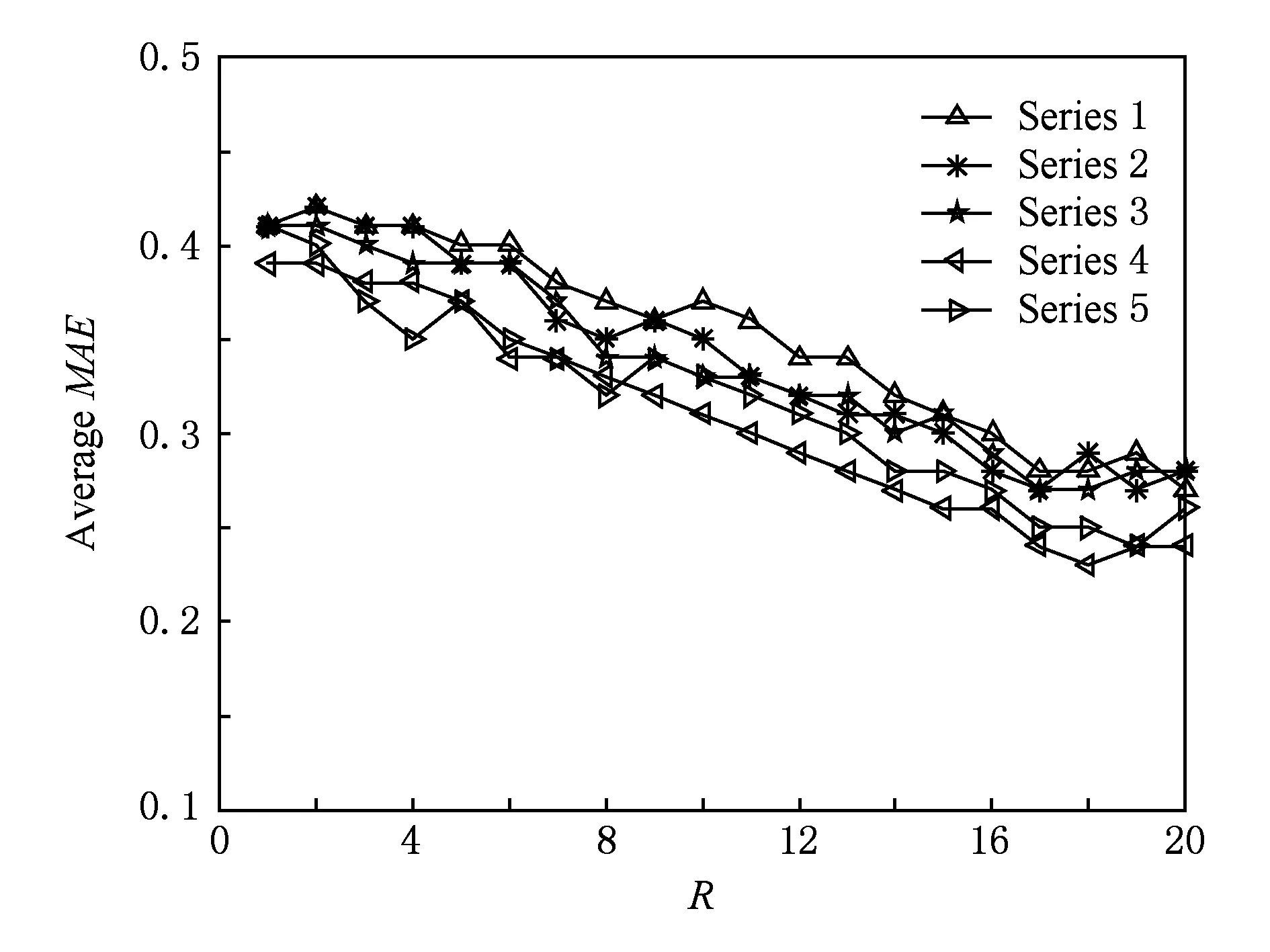
Fig. 4 The result of 60% data as training set图4 60%数据作训练集实验结果

Fig. 5 The result of 80% data as training set图5 80%数据为训练集实验结果
分别对比不同数据集比例下,5组参数λ的取值对所提出推荐算法MAE的影响可以发现,随着训练集比例的增加,所提出推荐算法的MAE值呈现出递减的趋势,即推荐的准确度越来越高.综合对比4组实验结果可以看出,当λ=1.8时,在不同的数据集模式下,所提出的推荐算法能够取得整体的最优值.说明针对当前数据集,用户历史偏好评分的波动幅度在1.8以内,超出1.8的评分即可判定为异常评分.所以在实验中,我们选取λ=1.8.
实验2. 与其他方法的对比实验.
针对当前数据集,对比实验主要包括2部分:
1) 在4种数据集模式上将本文方法与现有的偏好获取方法进行对比.经过反复筛选,我们选取了权重协同过滤算法(weighting schemes collaborative filtering, WSCF)[18]和动态负样本抽样的协同过滤算法(optimizing top-n collaborative filtering, OTCF)[19]作为算法的对比算法.其中,WSCF算法采用在协同过滤算法里加入权重尺度,以减轻数据的稀疏程度;OTCF算法采用动态的负项目抽样并考虑了部分上下文信息来提高协同过滤算法的推荐准确度.2种算法都致力于缓解数据稀疏性对于推荐精度的影响,并且均未对偏好相似性度量方法进行修正.实验结果如图6~9所示.
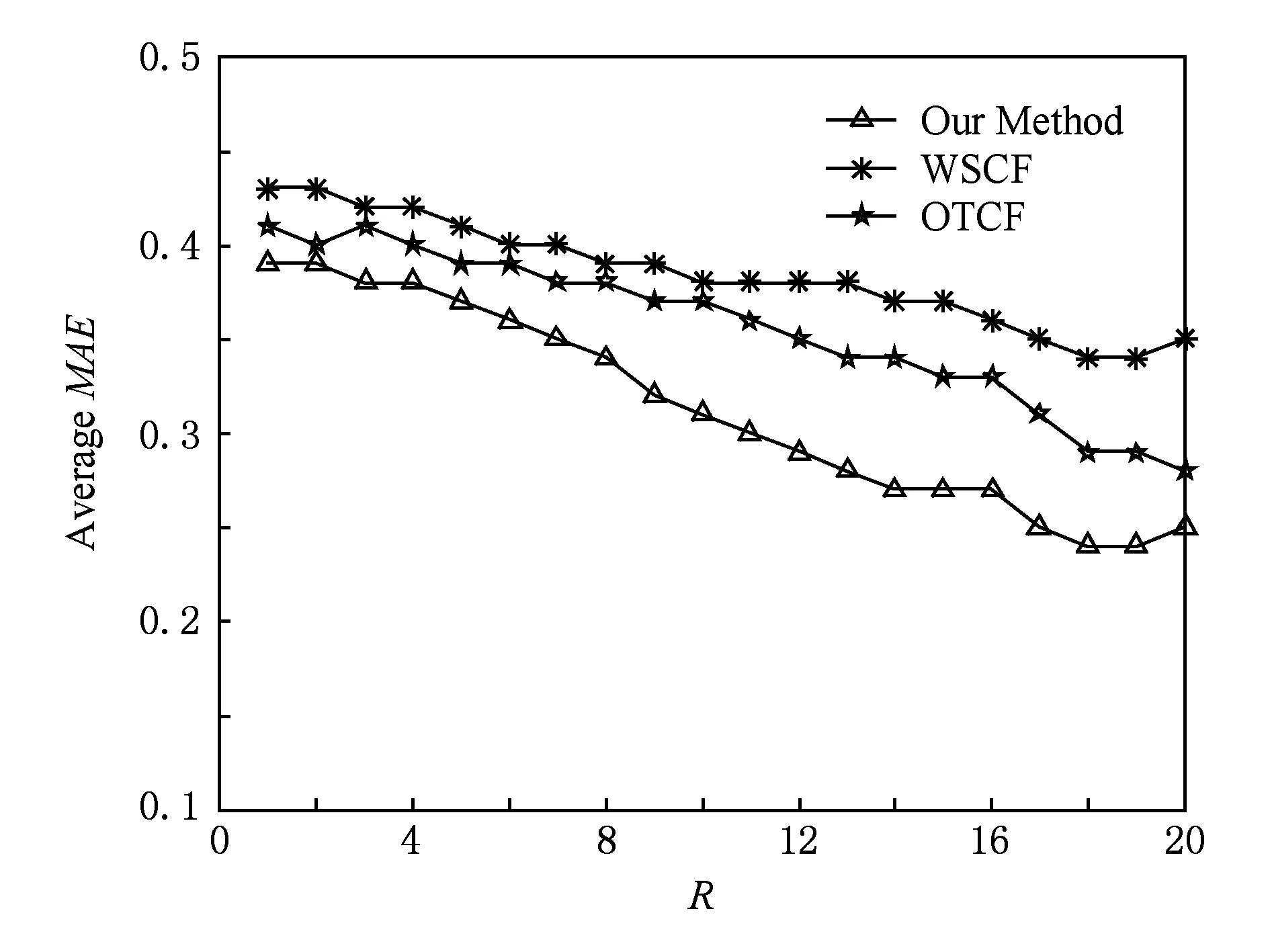
Fig. 6 The accuracy comparison result of 20% data as training set图6 20%数据为训练集的准确率对比实验结果
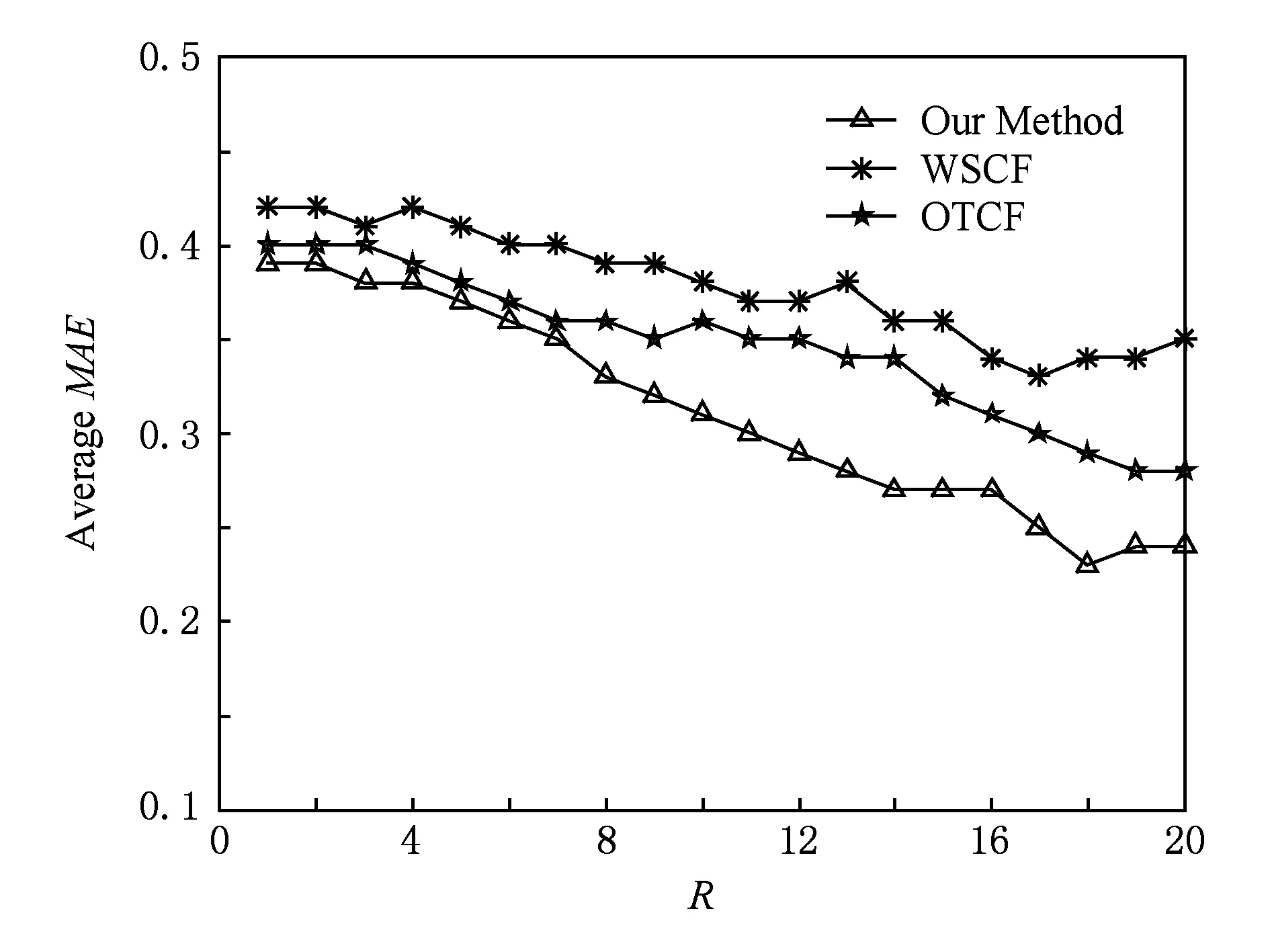
Fig. 7 The accuracy comparison result of 40% data as training set图7 40%数据为训练集的准确率对比实验结果

Fig. 8 The accuracy comparison result of 60% data as training set图8 60%数据为训练集的准确率对比实验结果

Fig. 9 The accuracy comparison result of 80% data as training set图9 80%数据为训练集的准确率对比实验结果
2) 经过反复对比实验,分别对本文算法及WSCF与OTCF的覆盖率进行度量,并取2种数据集下的实验结果均值作为各算法的覆盖率度量值,实验结果如表3所示:
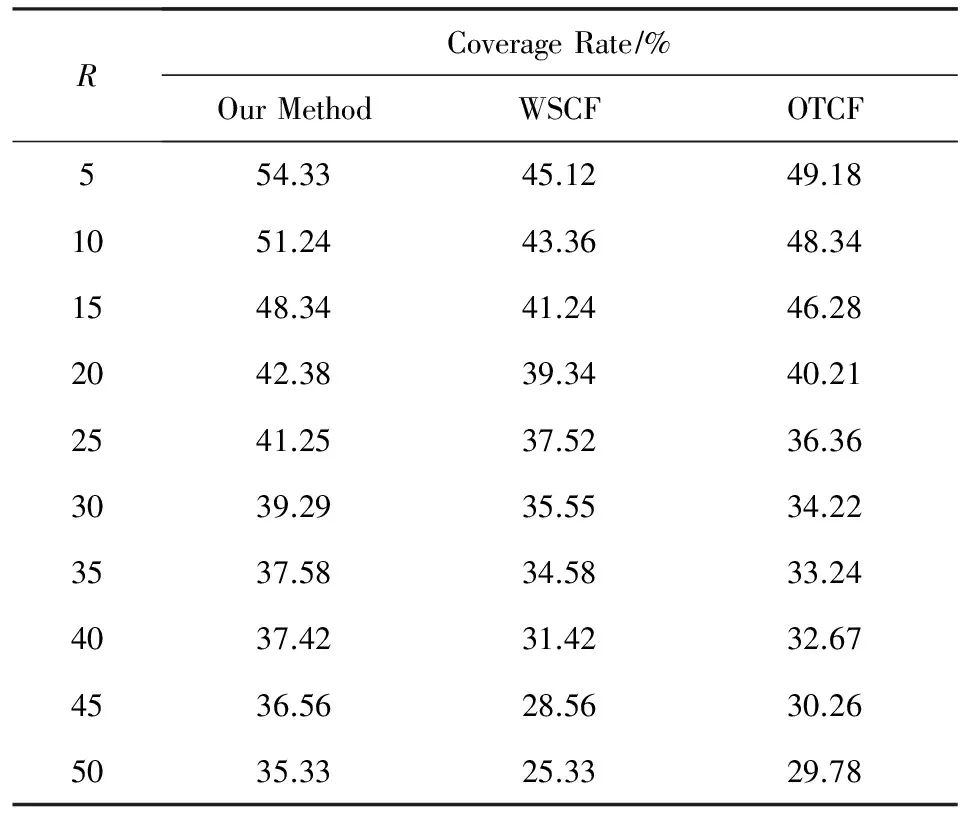
Table 3 The Comparison Results of Coverage Rate表3 3种算法覆盖率对比
3) 经过反复对比实验,选取40%与60% 这2种数据集比例,分别对本文方法及WSCF与OTCF的多样性进行度量,并取2种数据集下的实验结果均值,作为各算法的多样性度量值,实验结果如图10与图11所示.

Fig. 10 The diversity comparison result of 40% data as training set图10 40%数据为训练集的多样性对比实验结果

Fig. 11 The diversity comparison result of 60% data as training set图11 60%数据为训练集的多样性对比实验结果
从实验结果图6~9我们可以看出,在数据集上,以MAE为评价标准,所提出的推荐算法相比于WSCF和OTCF能够取得更好的推荐精确度.这也说明了上述2种算法的偏好提取方法所采用的用户行为相似程度计算策略所获取的最近邻,容易受到用户偏好行为记录稀疏程度的影响,导致所获取的最近邻与待预测偏好用户的偏好差异较大,进而影响了推荐结果的准确度.从实验结果表3可以看出,3种方法的覆盖率都是随着R值的增加而减少的,本文算法在各R值处能够取得比其他2种推荐算法更大的覆盖率,平均覆盖率提高了近4.81%,也即是本文方法具有更好的处理长尾效应的能力.从实验结果图10~11可以看出,R值与数据集对3种方法的多样性都会产生影响,随着R值的增加3种方法的多样性呈增加趋势.本文方法的平均多样性与WSCF基本保持一致,并且都优于OTCF.3个对比实验的结果也进一步地验证了本文所提出的结合基准相似空间分布优化的用户偏好获取方法能够修正最近邻用户的选取,能够提高推荐结果准确率.
3 结束语
现有的偏好获取方法中,待预测偏好用户最近邻的选取只是根据行为相似性算法,度量用户偏好行为间的相似性,并根据此获取待预测偏好用户的偏好近邻及其相应的偏好行为,通过不同的偏好生成策略生成推荐服务.这些方法都没有对相似性值进行判定,特别是受用户偏好记录稀疏程度的影响,所获取的近邻个数较少,在此基础上获取的用户最近邻,即使与当前用户的偏好行为不相似,由于近邻用户较少,也被当作当前用户的最近邻,那么在这种情况下,必然会影响推荐结果的准确度.我们基于用户间相似偏好中心与相似幅度获取相似基准空间,并基于平均近邻与异常评分对于相似基准空间外的用户行为进行修正.相比于现有方法,能够获取到与待预测偏好用户偏好行为更相似的最近邻用户,实验验证也证明了所提出的推荐方法相比于现有的偏好获取方法,能够取得更好的推荐准确度、覆盖率与多样性,显著地提升了推荐质量.未来的研究工作将会致力于研究通过融合情景感知等方法提出新的行为相似性度量方法,以期进一步地提高推荐质量.
[1]Liu Qi, Chen Enhong, Xiong Hui, et al. Enhancing collaborative filtering by user interest expansion via personalized ranking[J]. IEEE Trans on Systems Man and Cybernetics Part B Cybernetics, 2012, 42(1): 218-233
[2]Das M S, Amer Y G. Mri: Meaningful interpretations of collaborative ratings[J]. Processing of the VLDB Endowment, 2014, 4(11): 122-132
[3]Fouss F, Pirotte A, Renders M, et al. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 19(3): 355-369
[4]Ma Hao. An experimental study on implicit social recommendation[C] //Proc of the 36th Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2013: 73-82
[5]Chen Wei, Hsu W, Lee M L. Modeling user’s receptiveness over time for recommendation[C] //Proc of the 36th Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2013: 373-382
[6]Zhu Xia, Song Aibo, Dong Fang, et al. A collaborative filtering recommendation mechanism for cloud computing [J]. Journal of Computer Research and Development, 2014, 51(10): 2255-2269 (in Chinese)
(朱夏, 宋爱波, 东方, 等. 云环境下基于协同过滤的个性化推荐机制[J]. 计算机研究与发展, 2014, 51(10): 2255-2269)
[7]Linden G, Smith B, York J. Amazon.com recommenda-tions: Item-to-item collaborative filtering[J]. Internet Computing, 2003, 7(1): 76-80
[8]Wang Peng, Wang Jingjing, Yu Nenghai. A kernel and user-based collaborative filtering recommendation algorithm[J].Journal of Computer Research and Development, 2013, 50(7): 1144-1151 (in Chinese)
(王鹏, 王晶晶, 俞能海. 基于核方法的User-Based协同过滤推荐算法[J]. 计算机研究与发展, 2013, 50(7): 1144-1151)
[9]Xue A Y, Qi Jianzhong, Xie Xing, et al. Solving the data sparsity problem in destination prediction[J]. Very Large Data Bases, 2015, 24(2): 219-243
[10]Guo Guibing,Zhang Jie,Thalmann D. Merging trust in collaborative filtering to alleviate data sparsity and cold start[J].Knowledge Based Systems, 2014, 57(4): 57-68
[11]Pan Yiteng, He Fazhi, Yu Haiping. Social recommendation algorithm using implicit similarity in trust[J]. Chinese Journal of Computers, 2016, 39(8): 65-81 (in Chinese)
(潘一腾, 何发智, 于海平. 一种基于信任关系隐含相似度的社会化推荐方法[J].计算机学报, 2016, 39(8): 65-81)
[12]Yang Xingyao, Yu Jiong, Ibrahim T, et al. Collaborative filtering model fusing singularity and diffusion process[J]. Journal of Software, 2013, 24(8): 1868-1884 (in Chinese)
(杨兴耀, 于炯, 吐尔根, 等. 融合奇异性和扩散过程的协同过滤模型[J]. 软件学报, 2013, 24(8): 1868-1884)
[13]Zhao Qinqin, Lu Kai, Wang Bin. SPCF: A memory based collaborative filtering algorithm via propagation[J]. Chinese Journal of Computers, 2013, 36(3): 671-676 (in Chinese)
(赵琴琴, 鲁凯, 王斌. SPCF: 一种基于内存的传播式协同过滤推荐算法[J]. 计算机学报, 2013, 36(3): 671-676)
[14]Wang Licai, Meng Xiangwu,Zhang Yujie. A cognitive psychology-based approach to user preferences elicitation for mobile network services[J].Acta Electronica Sinica, 2011, 39(11): 2547-2553 (in Chinese)
(王立才, 孟祥武, 张玉洁. 移动网络服务中基于认知心理学的用户偏好提取方法[J]. 电子学报, 2011, 39(11): 2547-2553)
[15]Gao Rong, Li Jing, Du Bo, et al. A synthetic recommenda-tion model for point-of-interest and location-based social networks: Exploiting contextual information and review[J]. Journal of Computer Research and Development, 2016, 53(4): 752-763 (in Chinese)
(高榕, 李晶, 杜博, 等. 一种融合情景和评论信息的位置社交网络兴趣点推荐模型[J].计算机研究与发展, 2016, 53(4): 752-763)
[16]Guo Jinging, Ma Jianfeng. Trust recommendation algorithm for the virtual community based internet of things(IoT)[J]. Journal of Xidian University, 2015, 42(2): 59-65 (in Chinese)
(郭晶晶, 马建峰. 面向虚拟社区物联网的信任推荐算法[J]. 西安电子科技大学学报, 2015, 42(2): 59-65)
[17]Pedro C, Markus K, Nicolas W. Content-based music audio recommendation[C] //Proc of ACM Int Conf on Multimedia. New York: ACM, 2015: 211-212
[18]Ghazanfar M, Prugel B A. Novel significance weighting schemes for collaborative filtering[J]. Generating Improved Recommendations in Sparse Environments, 2010, 4(3): 25-38
[19]Zhang Weinan, Chen Tianqi, Wang Jun, et al. Optimizing top-ncollaborative filtering via dynamic negative item sampling[C] //Proc of the 36th Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2013: 785-788
