基于多源数据融合的移动商务个性化服务研究
2018-05-24陈志刚
陈志刚,方 卉
(湖北工业大学经济与管理学院)
伴随着互联网、移动智能终端和大数据技术的高速发展,海量的结构化或非结构化数据不断渗入移动商务企业的日常运作中,大量学者开始关注基于多源数据融合的移动商务个性化服务研究,使之发展成为学界探讨的主流问题。移动终端具有动态感应位置、无线信息交流、情境状态演变的特点,如何从各类智能传感设备获取的数据以及移动商务平台生成的交易信息和社交网络用户实时分享的地理位置等多源数据中挖掘出对用户集群有用的信息,提取用户特征并对其使用行为进行感知,从而实现个性化的推荐与定制服务成为当前亟待研究的课题。
近几年移动商务个性化服务在国内外被普遍关注,应用范围涵盖医疗业、娱乐业、服务业等各个领域,而面向多源数据融合的移动商务个性化服务研究在国内外的进展差异较大。随着信息融合技术的不断发展,多源数据融合(Multi-source Data Fusion)应时而生,并被各国视为重点开发的核心技术之一。Choi等人提出根据用户的情景化偏好、互动结果等多维度计算每一个偏好属性的权重来实现用户的个性化服务。[1]Tuzhilin等人提出了一种基于数据仓库的多维推荐方法,在传统二维用户推荐系统的概念上进行了全面的概要剖析和联机分析处理以表达复杂情境的语句查询,使用户更加灵活的与推荐系统进行交互。[2]刘晶等人针对移动商务用户位置、情境特性,提出大数据平台下的多源关联个性化模型,为用户的偏好、决策提供精准的推荐服务。[3]纵观当前的理论成果,国内移动商务个性化服务对多源数据融合的探讨不够深入,在时下大数据平台上提供的技术服务较少,大多依靠单一的推荐算法或有限的数据来源进行模型构建,缺乏对多源数据的处理研究和情景应用。由于这些异构、复杂的数据在共享发展的时代下难以实现关联互享,导致形成了一个个信息孤岛,因此,基于多源数据融合的移动商务个性化服务研究十分必要。
1 多源数据分析
大数据背景下,仅靠单源信息无法保障商务平台的竞争实力,不能满足当前阶段的信息需求,因此,对多源数据的处理分析十分必要。各类终端、传感器、浏览页面等渠道所产生的海量数据具有不可估量的挖掘价值,但数据规模庞大,传统的挖掘技术难以采集、互联和处理,而通过多源数据的交叉融合,可以实现数据的精准识别与标准化管理,保证了数据在多维度上的一致性,也挖掘出大数据的潜在价值。
1.1 数据收集
传统方法上,移动商务的数据收集主要集中于结构化或半结构化数据,如,用户的个人信息、访问日志等内容。然而,这类数据仅是大数据的冰山一角,大量隐匿于用户社交活动和情景环境的多模态数据(如,GPS、蓝牙、评论内容、浏览足迹等)尚未被挖掘利用。
在本文中,针对用户行为的数据收集分为显性数据收集和隐性数据收集两部分。① 显性数据是指用户在网络访问或现实生活中通过信息或商务交易等一系列活动所产生的特征数据(行为特征及个人信息),具有显著的分析价值,能够直接被电商平台采集、存储和运用。如,电信营业厅会对前来办理业务的用户登记个人信息,包括其姓名、电话、住址等基本内容,并且会结合用户以往或现有的业务数据为其提供新的服务方案;线上线下商家可以通过问卷调查或询问交流来获取用户的消费满意度,了解用户当前的消费喜好和未来的购物倾向。② 隐性数据是指用户在社交网络、页面平台等环境下实时留下的情景数据(自然情景、社会情景、应用情景),与用户动态的兴趣爱好及心理状态密切相关,需要通过特征化处理和关联运算来挖掘数据背后隐藏的价值,其收集主要通过各种智能穿戴设备、移动终端等多模传感器获得。如,手机、腕表上的GPS定位功能可以挖掘用户的运动轨迹,利用空间位置的相似程度来分析用户的行为特征;微信、Facebook等社交软件能够借助网络平台分享的朋友圈、通讯录等情境信息,融合用户评论、发表内容以及浏览痕迹来挖掘其社交行为,进而预测其个人需求。
1.2 数据清洗
在经过用户数据收集的阶段后便进入到数据清洗。当前,大数据时代的数据清洗分为三个方面:数据滤重、数据除杂和数据纠正(见图1)。海量用户数据的来源多样、结构各异,存在噪声和冗余的干扰,需要对这些多源数据进行过滤来纠正错误、排除杂质,保证数据的一致与完整。如,用户在社交平台(微博、脸书)更新的评论、说说、收藏等内容,其中可能包含移动商务平台所需的用户偏好、个性特征。当然,大量的数据可能是异构、零碎的,且不易被完整清洗,因此,从多维度、多来源去融合各类数据才能获得高价值的用户信息。
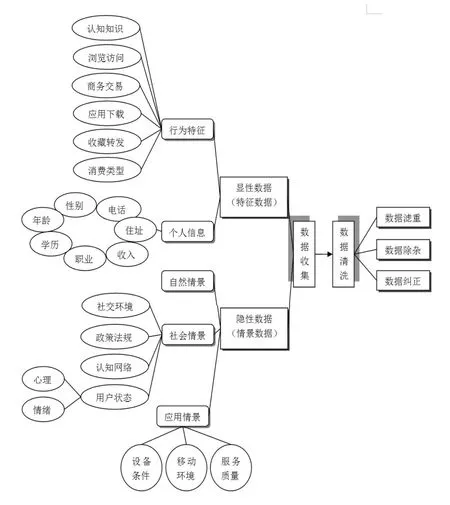
图1 多源数据收集-清洗模型
1.3 数据融合
多源数据融合被定义为一种处理多格式、多维度的同质或异构数据的综合信息技术,通过对数据多层的分析,使不同的数据优势互补和去除冗余,获得鲁棒性高、可信度强的目标数据。HU Jiaqi提出了基于数据层、特征层、相似度层和决策层的四层数据融合思路。[4]李广建等人总结了大数据环境下信息融合的理论框架,包括形式上的多元表示、语法结构的相关联系等,利用唯一识别、异构加权等手段实现多源信息融合进而投入到企业的生产运作中。[5]基于多源数据融合的理论基础,移动商务用户的数据融合可以优化为三个环节:首先,对用户数据(实时与非实时数据)进行清洗,包括用户的个人信息、行为数据和情景数据;其次,对清洗后的用户离线数据和预测数据进行特征提取,确定特征向量,并与知识库(用户、商品及情景知识)中的信息匹配;最后根据行为向量得出最终的决策判断,建立融合多源数据的用户行为模型(见图2)。

图2 多源数据融合模型
2 用户行为感知
近年来,手机网民的数量不断增加,互联网上大量关于商品信息基于文本、图像的数据交融复杂,使得用户对智能终端多元个性化的服务愈加重视。相关研究发现,移动用户的兴趣喜好与其使用行为联系密切,移动商务用户行为感知即是通过对用户行为活动的研究分析,来感知并预测其行为意向,从而掌握用户特征,实现个性化推荐的手段。
通过对知网、万方等数据库中有关用户接受行为文献的整理发现,在移动商务初始接受阶段,常用的理论及模型有理性行为理论(TRA)、创新扩散理论(IDT)、规划行为理论(TPB)、技术接受模型(TAM)、价值接受模型(SVAM)和整合型科技接受模式(UTAUT)。而在持续使用阶段,期望确认模型(ECM)及其扩展架构是主要的分析手段。当前,大多学者认为影响用户使用态度的因素不外于有用性、易用性、主观规范和信念,而态度决定了其行为意图,促使实际行为的产生。然而,伴随着研究的不断深入,人们发现用户的需求态度是多维复杂甚至是有冲突的,可能在初始接受阶段用户倾向于移动商务的高效便捷,但在持续使用阶段可能更倾向于其成本、风险的大小。[6]当用户的心理发生改变,或自身特性具有差异时,仅依靠上述理论模型显然已不能适应用户不断改变的需求。因此,近年来不少学者在用户行为感知的研究中引入情景因素,通过利用实体的情景信息、感知当前情景(地理位置、情绪状态、目标和任务等)来识别用户的动态特征,有效应对用户需求的实时变化。为了实现规范的感知并收集用户的情景数据加以利用,采取基于本体的语义描述,形成统一的语义化用户情景。依据本体的表示技术能够将用户语义信息转化成共识的形式化信息,从而全面、有序地阐述用户的行为模式。因此,在用户行为模型构建中,可以借助本体与情景结合的感知方法,来设计基于情景本体的行为感知模型。① 通过传感设备、互联网或其他数据源来收集用户的情景数据,包括在线情景(空间位置、浏览交易、评论转发)和离线情景(个性特征、知识服务信息、社交环境、历史行为记录);② 对获取的情景数据采取语义化处理,将统一的情景本体与商品本体关联融合,并进行用户相似度计算,以提高本体的解释力度;③ 构建情景本体模型,通过分析不同用户的情景状态来了解用户态度,解释其行为意图,最终感知用户的动态行为(见图3)。
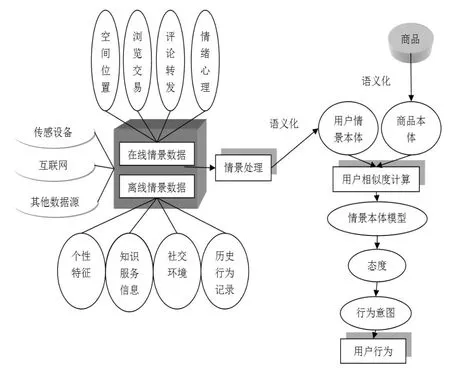
图3 基于用户情景本体的行为感知模型
3 个性化推荐算法
随着移动商务逐渐被人们熟知,业务规模不断扩大,用户想要在海量信息中找到心仪的商品十分困难。因此,为了能够更好地满足用户需求,电商开始利用个性化推荐技术向用户推荐其可能感兴趣的产品,并将推荐结果及时精准地进行反馈。目前,常用的推荐算法有四种。① 协同过滤算法:通过对不同对象(用户或商品)之间的相似度计算,选取与目标对象最贴近的匹配对象,根据匹配对象的偏好特征对目标对象实施个性化推荐。② 基于内容特征的推荐算法:通过用户已经购买或浏览过的商品相似性,向其推荐特征相似的商品。③ 基于关联规则的推荐算法:根据用户的行为数据(已经购买的或浏览、收藏的商品)生成关联规则,向用户推荐当前环境下的关联商品。如,许多电商网站会利用关联规则对用户的消费行为进行挖掘,将分析后的常买商品捆绑销售,既方便了用户的交易过程也促进了商品销量。④ 混合推荐算法:结合多种技术理论的优点,弥补了单一算法的不足,形成优势互补。混合推荐算法的种类有很多,可以是协同过滤和基于内容相结合的推荐算法,也可以是关联规则和协同过滤相融合的推荐算法。而在大数据时代下,仅靠传统的推荐算法不能应对多源数据的复杂性,需要利用大数据分析算法,如,聚类、神经网络、Web数据挖掘、回归分析等来增强计算的可信度,使用户获得最精准的个性化推荐服务。因此,本文提出了融合关联规则和聚类分析的推荐算法。
3.1 关联规则算法
根据韩家炜等[7]的观点,关联规则定义为:假设是项的集合。建立一个商务活动的数据集A,其中的每个对象E均从属于集合C,因此每项活动都有与之对应的标识符ECA。运用关联规则讨论活动A的支持度,即A中同时发生M和N的概率;活动A的置信度即是在发生M的前提下,又发生了N的条件概率。关联规则的价值程度取决于其是否达到设定的最小支持与置信度阈值,如果符合这两种标准则证明规则是有意义的。用一个简单的例子说明。下表是用户商务交易的数据集A,含有6个对象。项集C={碗,筷子,水杯,盘子}。
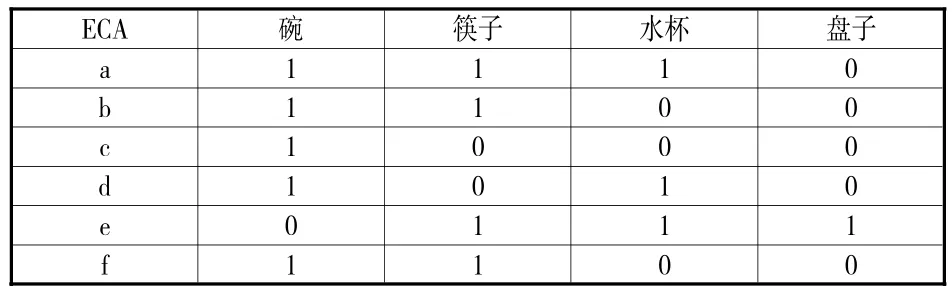
表 用户商务交易的数据集A
根据关联规则可得:碗和筷子,活动a、b、c、d、f包含碗,活动 a、b、f同时包含碗和筷子,M^N=3,A=6,支持度 (M^N)/A=0.5;M=5,置信度(M^N)/M=0.6。当设置最小支持度 minα=0.5,最小置信度minβ=0.6,则说明用户购买碗和筷子的动机是具有联系的。
3.2 聚类分析算法
聚类分析(ClusterAnalysis)是针对目标事物的具体特征,依据设定的划分标准将目标事物归类为相似特质的群体分析方法,使得同一组内的数据性质相似,而不同群组的数据性质各有差异。最常见的分类方法是依据数据样本间距进行分组,用A={ai|i=1,2,…,n}代表数据集,其中,ai用c维特征向量ai=(ai1,ai2,…,aic)来表示,aih(h=1,2,…,c)表示c个描述属性B1,B2,…,Bc的实际数值,通过样本间距映射其相似程度。样本ai和aj的间距为c(ai,aj),通常用欧氏距离、曼哈顿距离和明考斯基距离来进行计算。
3.3 混合算法
关联规则的两大要素是置信度和支持度,置信度代表规则的可信程度,支持度表示规则前后项均在数据集中显现的概率,要素概率越大说明其间的关联性越强。大数据环境下,各类数据海量的积累、算法的迭代导致执行时间逐渐加长,关联规则数量的激增也会促使虚假无用规则的产生。而聚类算法正好可以克服关联规则的缺点,依靠改进数据集和区域细分来提高算法的精确性。[8]基于聚类分析与关联规则融合的推荐算法,首先,要分析用户的交易、浏览等行为,根据其特征相似度对用户采取分类,使得偏好相同的用户聚集在同一类别中;其次,对用户在行为过程中产生的数据进行预处理分类,其结果即为算法的输入值,产生的数据集被区域细化,方便了下一步的数据关联;最后,对每类数据关联处理,产生的关联规则一定是事物集中用户共同偏好的规则,减少迭代的频数,提高推荐的准确性。
4 面向多源数据的移动商务个性化服务实现方案
实现用户的个性化服务即是通过前期用户特征数据的多源收集、融合,对其行为进行感知进而向不同用户提供差异化的服务过程。如,最常见的手机APP定制,用户的私人行程记事、健康饮食等应用均可以轻易实现,让用户不断获得比自身需求更多的个性化服务,真正做到比用户更了解自己。
4.1 面向多源数据的云计算平台
实现个性化服务最重要的是推荐系统的构建,包括算法(数据处理与推荐算法)和平台架构的搭建。大数据环境下,移动商务用户数据结构各异、数量庞大,具有在空间、语义全面共享的属性,需要高技术的计算平台支撑。大量云计算环境中,Hadoop分布式计算平台以其高效性和高可靠性使得用户能够便捷构建并运行处理多源数据。Hadoop最核心的组成部分是分布式文件系统(Hadoop Distributed File System,HDFS) 和 Map Reduce引擎,位于底部的HDFS用于存储集群节点的全部数据,它的上层Map Reduce则用于创建索引。当前,为了从网络数据膨胀的环境下实现海量多源数据的挖掘,基于Hadoop平台的提出能够为多源数据的分析与存储提供有效保障,为移动商务企业在大数据时代站稳脚跟提供可靠助力。
4.2 移动商务个性化服务方案设计
综上所述,本文设计了基于Hadoop处理平台、Map Reduce计算框架和大数据可视化分析的个性化定制方案,其核心部分包括数据采集、数据融合、算法实现和应用服务这四个模块(见图4)。
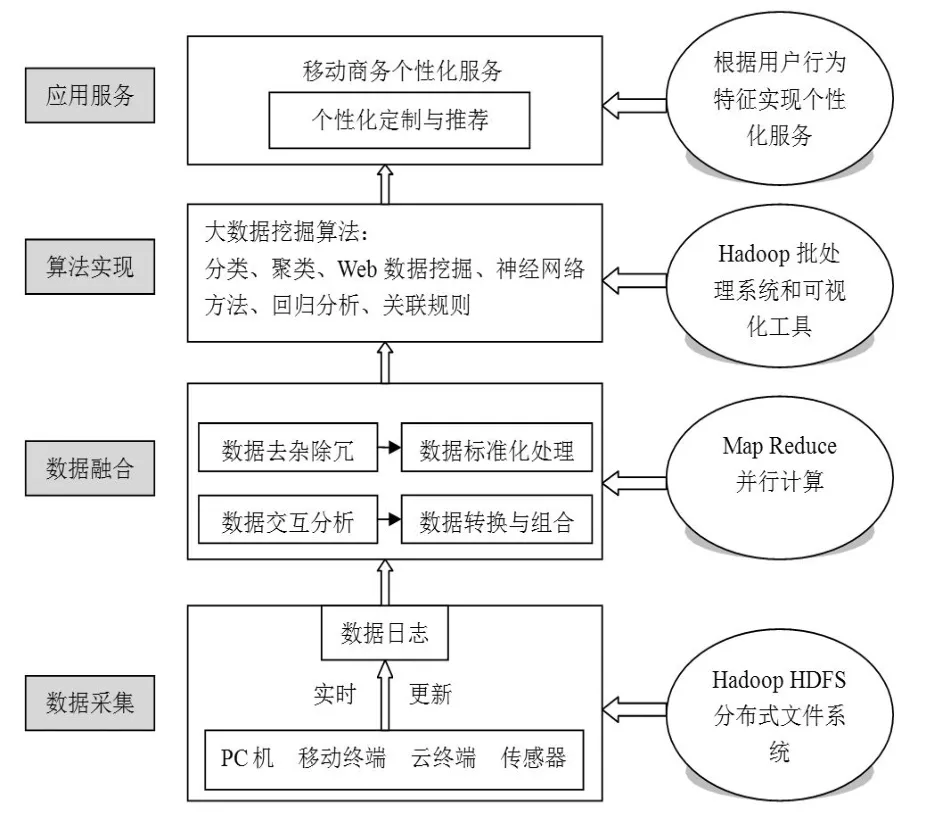
图4 面向多源数据的移动商务个性化服务实现方案
(1)数据采集。① 通过部署在低廉硬件上的HDFS分布式文件系统,对来源于PC机、移动终端、云终端和传感器的用户数据日志进行实时处理、更新。HDFS包容继承式的文件结构,文件系统之间的属性特征极为相似,用户可以将文件存储到创建的目录中,也能将文件在不同目录中转移与重命名。② HDFS系统内的DFS Shell接口可以让用户接触其中的数据,高吞吐量的特性允许大数据集的程序轻松被访问。
(2)数据融合。利用MapReduce对采集的多源数据进行融合处理。① 清洗用户数据,滤掉噪音、消除冗余;② 采取标准化处理,统一规范数据结构;最后,交互分析数据特征,实现信息转换与组合,挖掘出最有用的用户行为数据。MapReduce可以利用普通的服务器构建不等数量节点的计算集群,能够在集群节点上自主划分计算数据并进行处理,由系统对数据定位、容错优化等计算任务中细小繁琐的内容,减轻了系统开发人员的工作。并且它依据计算机语言设计Lisp的概念,搭建简易的运行与计算接口,结合Map和Reduce两种函数程序实现了大数据集的编程与并行计算任务。
(3)算法实现。利用Hadoop批处理系统和可视化工具对大数据环境下的多源用户数据进行挖掘处理。大数据挖掘算法主要包括6种:① 分类是将目标对象按照性质特征进行划分,使得各数据项能够汇聚到对应类别中,通常被用于数据分类、偏好预测;② 聚类所面对的类别是未知的,跨类别的数据相似度很低而同类型的数据关联度很高;③ 回归分析反映了数据变量之间的相关性及相关强度,可运用于预测预报、误差控制的研究;④ 关联规则的结果是挖掘数据项之间的交互关系,然后依靠单个数据项推测出相关的隐藏对象,通常被用于用户的需求预测;⑤神经网络是模拟人思维的人工智能技术,其特点在于大量神经元汇聚而来的网络系统能实现信息的自行处理和分布式存储,具有较高的学习与泛化优势;⑥Web数据挖掘是利用挖掘技术从海量的网络知识中找出隐藏的、有价值的信息与模式,对Web页面的内容架构和活动信息实施全面的分析处理,具有高并行性、实时动态性等特点。
大数据处理中,最为常见的可视化工具有Processing和Gephi。Processing是数据可视化过程中的经典工具,根据程序员编写的基本数据代码并编译为Java语言即可执行于系统平台上,让用户能够便捷享受声光具备的交互体验。Gephi是基于Java语言的数据可视化分析工具,可以处理大规模数据集,主要用于探索性信息挖掘、分层图表构建、社交环境分析等方面。
(4)应用服务。平台的前端应用即是移动商务个性化服务,通过个性化的推荐、推送、检索来实现用户的偏好定制。[9]个性化推荐是依据收集的用户数据,向用户提供建议,帮助他们找到合适的商品并作出决策。推荐的内容要符合用户实时的情景状态,能够精准感知用户的行为,同时兼具新颖性和及时性。如,用户最近经常在网站上浏览护肤品,推荐服务便可以根据用户的年龄、收入以及以往的购买偏好来进行。个性化推送是通过移动终端向用户推送可能感兴趣的商品及服务,吸引新客户并留住老客户。个性化检索是为了让用户在输入查询内容后得到准确的需求信息,并且能够在用户表述之外为其显示关联的知识内容。如,用户在搜索引擎中输入“奶粉”,需要判断用户想买的是婴儿奶粉、成人奶粉还是中老年钙奶等,并且除了满足用户的检索需求,还可以向用户提供可能接受的关联结果。[D].Troy:RensselaerPolytechnicInstitute,2008.
[参考文献]
[5]李广建,化柏林.大数据环境下多源信息融合的理论与应用探讨[J].图书情报工作,2015(16):5-10.
[6]程晓璐.移动商务用户接受模型研究[J].江苏商论,2010(33):26.
[7](加)Jiawei Han,et al.数据挖掘:概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2012.
[8]孙世文.基于关联规则和聚类分析的个性化推荐系统的研究与实现[D].长春:吉林大学,2015.
[9]柳益君,等.大数据挖掘在高校图书馆个性化服务中应用研究[J].图书馆工作与研究,2017(5):23-29.
