中西文图书控制号、索书号自动生成工具整合及优化
2018-05-24西安交通大学图书馆
李 丹,张 茵(西安交通大学图书馆)
随着信息技术的发展和广泛应用,计算机技术与图书文献编目工作不断融合,图书编目从纯手工编目、单机编目很快发展到联合编目;控制号、种次号生成也从纯手工记录到软件取号。但是,图书馆中西文著录格式与规则的不同,形成中、西文种次号以各自独立的方式生成的现状。另外,各馆对中西文图书数据格式的规定不同,图书分类号的结构构成也不尽相同;各图书馆控制号、种次号生成方法不同,一些图书馆使用网络上公开的通用辅助工具,部分图书馆自行开发软件提供生成功能,[1]还有图书馆利用图书集成系统自带生成功能;[2]并且图书馆著录西文图书时,选取的著者号码表不尽相同,有CUTTER号码表、汉语著者号码表等,且编目员水平参差不齐,对著者号的选取不够重视,形成了各自为政的局面,影响了文献的排架质量及读者的检索效率。
西安交通大学图书馆在编目工作中,借助编目软件开展业务,但旧软件在兼容性和性能扩展度方面有一定的局限性。故笔者结合实际工作,在图书馆大量采购西文图书的背景下,开发出中西文控制号、索书号自动生成工具(简称CWCCAGT),该工具以扩展性良好的整合方式优化编目业务的开展,可辅助于开展图书编目,[3]以期为使用第三方软件实现生成功能的各类型图书馆和情报机构提供参考,继而推广使用。
1 构建中西文控制号、索书号自动生成工具架构
1.1 西安交通大学中西文图书控制号、索书号自动生成工具需求分析
西安交通大学图书馆原有编目工作软件包括中西文图书控制号、种次号生成程序和西文索书号生成程序两个独立的软件。其中,控制号软件作为编目员日常工作必须使用的软件,从1998年开始投入使用,随着台式电脑操作系统的更新换代,原有程序无法在新操作系统上安装使用,影响到编目的日常工作。并且该软件安装繁琐,网络配置复杂,无法统计工作数据。此外,由于中西文图书的种次号、著者号程序分别为两个不同的程序软件,平台不统一,给使用者带来诸多不便。
1.2 编目业务优化工具设计
基于控制号、中文索书号、著者号、西文索书号取号步骤并发进行,不同的操作相互独立、又有所关联的现状,通过梳理现有编目业务流程,笔者设计出CWCCAGT架构(见图1)。
首先,依据馆藏特征确定数据构成标准。西安交通大学图书馆将资源按文种(中文、西文、俄文等)分类,并按资源类型(普通图书、电子期刊、古籍善本、学位论文等)分类,构成对应的控制号;采用“分类号+种次号”的格式描述中文索书号,每个种次号按到馆先后顺序从1开始依次递增取号;采用“分类号+著者号+字母”的构成描述西文索书号。其次,确立数据构成标准后,分析数据操作的对象和关系,把系统中的各项功能碎片化,以微操作的形式进行封装。系统功能包括公共模块、生成功能模块、数据管理模块和用户管理模块(见图1)。其中,公共模块不针对具体对象,可被各个功能模块调用、共享,包括大数据的显示、数据交互等操作;生成功能模块面向特定的图书对象,包括控制号生成、种次号生成等;针对每一类数据管理,基于数据表,通过调用对应功能模块,同时结合大数据加载、数据交互等公共模块完成数据的生成。操作请求和处理结果在服务器端和馆员端以特定的形式传递。
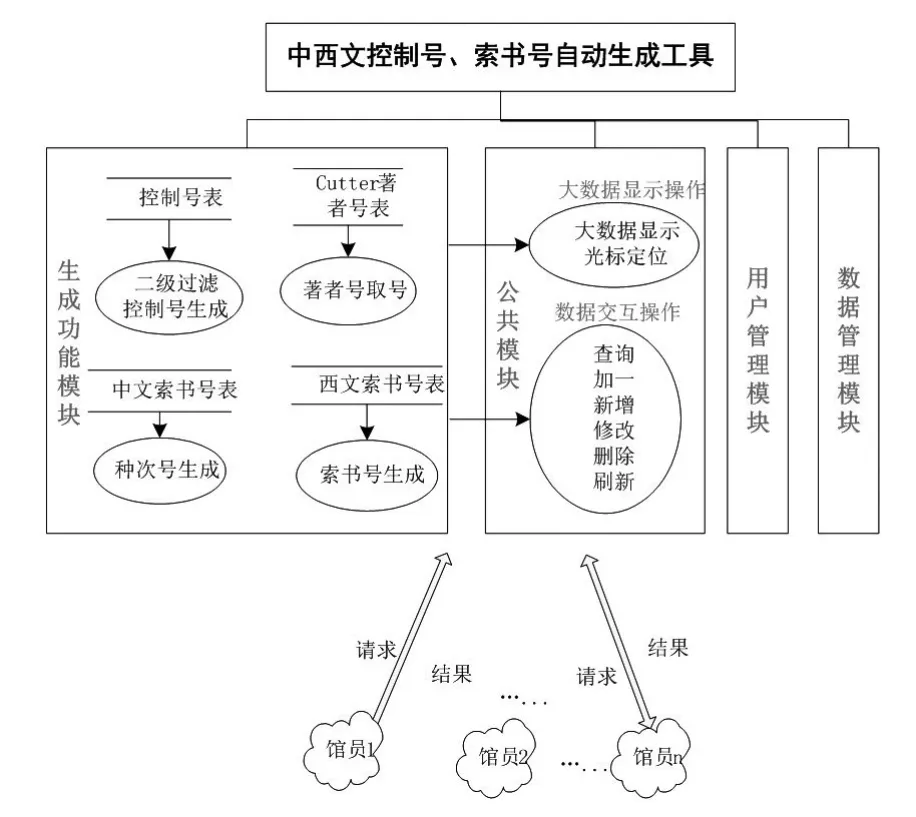
图1 中西文控制号、索书号自动生成工具架构
该生成工具提供完备的查询定位和多用户实时并发的功能;利用分页技术,提升信息处理速度,使生成有序化;为图书的分类排架提供规划支持,收集大量关键可靠的统计数据,记录图书数据、种次等;并统计每位编目员的工作量,是馆员编目工作的有力辅助工具。
2 实现关键技术
2.1 公共模块实现关键技术
(1)大数据显示。实践中往往会遇到并发操作十几万条数据的情况,如果使用传统InsertItem函数,其插入过程很耗费时间,若采用分页显示的方法则可快速加载大量数据。加载数据的算法如下。
a)把数据库记录集的数据分成PageSize大小的数据块,访问数据库时,每次数据加载只加载一个数据块到 List Control。
b)变量CurrentPage记录数据块的序号。
c)通过点击BN_CLICKED的4类消息函数OnBn ClickedFirst(), OnBnClickedprepage(), OnBnClickednext page(),OnBnClickedLast()变换CurrentPage的值,同时通过指针移动来指向每条记录在记录集合中的位置,实现数据的分页加载和单条记录定位。
分页显示时,数据库仅打开一次,数据集指针指向位置很关键。其中,查询、新增等数据交互操作都建立在分页显示的基础之上。
由于数据量很大,在查找、新增、修改等操作后都需要定位光标位置,系统默认不提供光标定位、高亮的接口。工具构建NM_CUSTOMDRAW类消息函数OnCustomdrawList1,通过函数 Ensurepoint(CStringtemp)触发OnCustomdrawList1消息函数,实现ClistCtrl中指定行高亮显示。
(2)数据交互。数据交互操作中最重要的是更新操作。当多位用户在几乎相同的时间对同一条数据执行更新(如加一)操作时,原有工作软件会出现控制号、分类号、索书号生成重号的现象,重号会产生一系列连锁反应,一本书的编码会直接影响到后续图书的编码,甚至会出现书库图书的批量退架现象。新工具采用加锁机制,弥补了功能上的缺陷,提供灵活的并发控制功能,基本满足馆员并发操作的需求。
首先,通过刷新按钮获取最新号值(流程见下),然后利用一定的锁定机制(见图2)控制数据更新操作,保证数据的完整性、连续性和原始性。更新数据库时,通过调用Open方法打开ADO记录集,从而修改记录集中的字段。刷新流程如下。
a)获取CListCtrl中当前页选中行的行数和主键字段值(分类号)。
b)从数据库中实时读取 CListCtrl中当前页所有记录,并重新显示。
c)高亮显示a)中的选中行记录。
2.2 生成功能模块实现
自动生成工具提供了控制号生成、中文分类号生成、著者号取号和西文索书号生成的功能。控制号生成功能基于文种和文献类型的灵活组合,生成控制流水号,同时可以对字段进行初始化和加一。卡特著者号取号功能兼任模糊和精确的查询定位,中西文索书号生成功能针对索书号的不同构成进行取号,同时以上功能支持不同类型的数据交互操作。
(1)不同类型资源编目中的控制号生成。隔一定时间,工作人员需要初始化控制号,之后,通过文种、文献类型二级过滤命中对应类型资源,并高亮显示;加一操作后,即更新控制号,同时需要把该流水号写入Millennium中。由于总是存在多个用户同时生成流水号的情况,为避免数据的不准确,用户需要刷新得到实时最新数据后才能进行下一次的控制号生成(见图 3)。
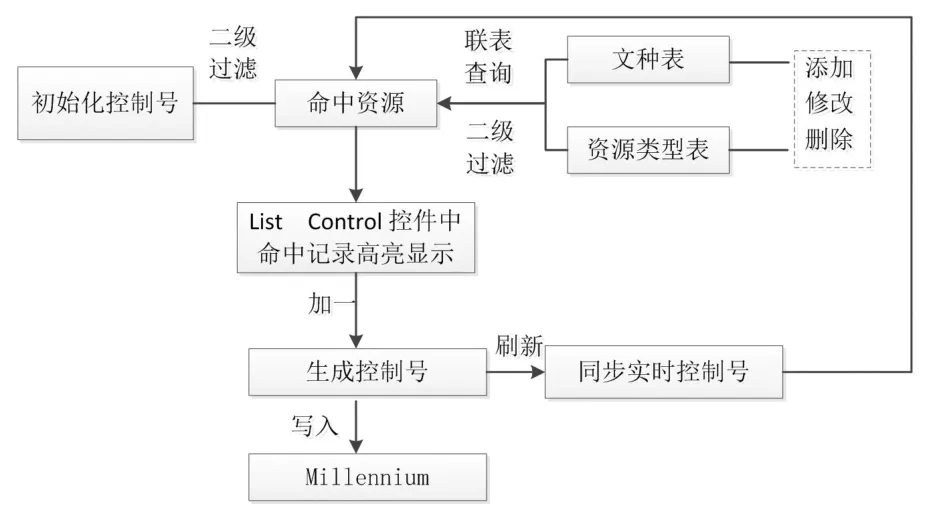
图3 控制号生成
(2)西文图书编目中的卡特著者号取号。西文图书按照Cutter著者号码表来取著者号。著者号一般从个人责任者字段取号,对应西安交通大学图书馆西文MARC记录中的100字段;如果图书没有责任者,只有编者,而西文图书编者不作为主要贡献者,而是以书目题名的第一个单词做标目取著者号,对应西安交通大学图书馆西文MARC记录中的245字段。针对卡特著者号取号规则,取号算法如下。
① 通过ADO方式连接Cutter著者号码数据库表。② 采用分页方式在客户端界面加载Cutter著者号码表。③ 根据输入的著者名称进行查找。④ 如果可以找到则显示精确查找结果:取著者姓氏第一个字母+著者号;如果卡特表中没有与查询的著者姓氏相匹配,把所有著者姓名按照字典序排序后,采用靠前取号原则,取所有小于查询姓氏中排序最后的一条记录。⑤ 加载对应页面,定位该记录在数据库中的位置并高亮显示。
(3)中西文图书标引中的索书号生成。中文索书号管理和西文索书号管理数据交互操作类似,只是加一操作的对象数据格式不同。中文图书加一操作针对种次号,按图书到馆先后顺序从1开始依次递增取号;西文图书采用在著者号后加上小写字母(如a)依次递增取号。西文图书之所以采用这样的取号规则,是因为会出现同一著者编著的同类主题图书往往拥有同样的分类号和著者号。以中文索书号取号为例,取号的具体方法是:分类号取号页首次加载显示分类号全记录,支持翻页查看分类号信息。馆员选取分类号,在分类号—种次号表中查找,如果存在相同的分类号,通过数据库记录集合指针,确定其所在页数和在页面中的位置(函数Getpagenum(CString temp)实现),对选定位置高亮显示(函数Ensurepoint(CString temp)实现);同时,展示查找分类号前两个字母开头的相近记录,把对应种次号加一。也可进行修改等操作,修改数据时,由于该条记录位置已定,可通过传递当前页面变量CurrentPage值和操作的分类号值给函数Queryone(CString temp,int page1)来显示相近条目,同时高亮显示最新操作过的条目。如果未找到该分类号,显示相近记录,可选择新增分类号到表中,种次号默认初始化为1。由于该条记录的位置未定,则需要Getpagenum和Ensurepoint函数进行定位焦点并高亮显示。如果还需对其相近条目进行加一、修改等数据交互操作,方法和上部分类似(见图4)。
3 编目生成工具实践与思考
结合西安交通大学图书馆使用中西文控制号、索书号自动生成工具的实践经验,从多用户并发、不同规模下大数据加载时间、新旧程序操作时间对比以及可扩展性和通用性等角度对CWCCAGT进行分析测试,探索未来对不确定编目控制变化提供支持的可行方法。工具基于VMware虚拟服务平台,采用VC++语言编程开发和SQL Server 2008构建数据库。兼容Windows XP、Win7等操作系统,迁移原有软件数据10万余条,其中迁移著者号1.2万余条,中文索书号两万余条,西文索书号6万余条。

图4 中文索书号管理
3.1 多用户并发
由于编目员每天需要处理一定数量的图书,因此这类工作软件的首要需求是简单易用。经测试,新工具提高了编目员的处理效率,提供可视化友好编目界面,支持多用户并发操作,且数据的准确性可以保证。同时,工具考虑编目员工作习惯,运用非模态对话框的显示技术,支持多操作窗口同时打开。并充分考虑界面设计紧凑、小巧,可停靠在显示器一侧,同时各子界面为长条形状,采用多界面互切换技术,方便一个屏幕可同时打开其他工作软件如Millennium。
3.2 不同规模下大数据载入时间对比
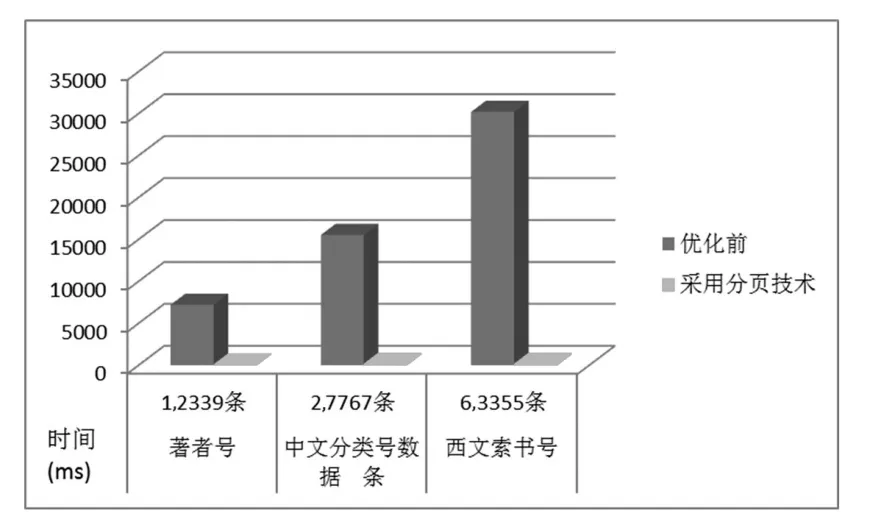
图5 不同规模下大数据载入时间对比
图5 给出了大数据载入在不同输入规模下显示所花费的时间。优化前表示采用Clist Control提供的m_list1.InsertItem (row,"") 和 m_list1.SetItemText(row,index,itemtext)方法的程序,分页技术表示笔者采用分页显示数据优化程序。测试结果表明:在不同数据规模情况下,优化前程序和采用分页技术程序所花费的数据加载时间相差很大。随着数据规模的增大(从12,339条到63,355条),优化前程序数据加载时间和采用分页技术程序数据加载时间的比值越来越大,采用分页技术程序数据加载执行时间增长缓慢,而优化前程序的执行时间则急剧增长。
采用分页技术相比优化前速度大幅度提升,虽然其进行数据交互操作时,需定位的数据不一定在当前页,故需定位页面位置和该记录在页面中的位置,一次性全部载入虽然省去上述步骤,但频繁地加载数万条数据往往会造成数据闪烁且加载时间很长。
3.3 新旧程序操作时间对比
图6对比了两个馆员并发操作时,著者号、西文索书号查询花费的时间。测试结果表明,在同样的数据规模下,查询同一个著者名,优化后新工具查询的性能比旧工具性能高很多,同样,进行西文索书号查询的性能比旧工具程序性能高很多倍。

图6 新旧工具查询性能对比(并发用户两人)
笔者还测试了4个并发用户时,控制号、中文分类号、西文索书号查询花费的时间。测试结果表明,控制号生成时间特别少,且新旧工具性能没有差别,这是因为控制号数据量本身很小,新工具的优化性能没有得到体现。在数万条数据规模下,新旧工具中文分类号、西文索书号查询时间对比明显,因为新工具重点优化大数据执行效率,这一结果完全符合计算机设计量化原理中的“重点关注常见情形”的指导原则。随着并发用户数增多,新旧工具执行时间都略有增加但不影响馆员的编目操作。
3.4 发挥编目工具优势,支持多部门工作
现代化编目手段和技术带来便利的同时,并不能因此而减少编目的环节和程序,图书馆应更加重视对馆藏图书的深层次加工,及对信息的深层次开发和提炼。编目工具所做的整合和优化工作不仅可以满足现有编目的需求,而且可适用于图书馆其他工作需要。① 发挥编目工作软件优势,建设特色馆藏。通过对馆藏目录和藏书状况分析,及时了解各类读者的需求,根据读者需求对馆藏纸质图书进行深层次加工,如,编制专题特色书目等。② 多角度挖掘软件数据,为图书采购提供参考。通过对某一类目馆藏书目分析,统计出馆藏中某一类图书所购买种数,宏观评估图书的学科分布特点,为后续购书提供参考。③ 灵活利用种次号,保证图书排架质量。图书馆书库空间有限,可充分利用该编目工具的数据分析功能,分析同一类号下的图书数目,为图书排架留出充足空间,不浪费书架位置;分析馆藏体系中已购西文图书同一类号下,同一著者的不同著作,将此类图书准确无误地加以集中,方便读者找书。
[参考文献]
[1]陆玉泉,等.外文图书索书号自动给号系统的设计与实现[J].现代计算机 (专业版),2013(4):68-72.
[2]张轶华,等.Aleph系统批量编目功能的研究与实践 [J].图书馆杂志,2015,34(1):66-72.
[3] PhilipYoung.Asurveyofbatchcatalogingpracticesand problems[J].Technical Services Quarterly, 2012(29):22-41.
