基于深度神经网络的说话人自适应方法研究
2018-05-23古典,李辉
古 典,李 辉
(中国科学技术大学 电子科学与技术系,安徽 合肥 230027)
0 引言
近年来,深度神经网络在语音识别领域的应用使得语音识别技术取得突飞猛进的发展,深度神经网络技术已经成为构建语音识别声学模型的主流技术,相对于传统的GMM-HMM语音识别框架,单词错误率下降超过30%。在实际应用中,由于训练集和测试集的说话人不匹配,导致语音识别系统的性能受到影响。语音识别中的说话人自适应技术可以解决不匹配问题,从而能够进一步提高语音识别的性能。
在传统的GMM-HMM框架下,比较著名的自适应技术有最大似然线性回归(MLLR)[1]、最大后验线性回归(MAP-LR)[2]和向量泰勒级数(VTS)[3]等。然而,这些自适应技术不能直接应用到DNN-HMM的框架中,因为GMM是一个生成性模型,DNN属于判别性模型。随着DNN技术的成熟,大量研究者投入到DNN自适应领域,并提出了很多优秀的自适应方法。这些方法可以被分为两大类:模型域自适应以及特征域自适应。线性输入网络(LIN)[4]是将一个线性层添加到输入层和第一个隐层之间。这种方法的思想是通过线性变化,将说话人相关的特征与说话人无关的DNN模型相匹配。与此类似的方法还有线性隐层网络(LHN)[5]和线性输出网络(LON)[6]。扩充特征的方法是将声学特征和代表说话人信息的特征进行拼接,作为深度神经网络的输入。一个比较好的方法是利用i-vector[7]作为说话人信息。文献[8]提出,在自适应任务中引入多任务学习方法可以进一步提升系统性能。采用学习性隐层单元贡献(LHUC)[9]的方法,在保留原有基线网络参数的基础上,在隐层的每个神经元上引入一个参数对相应神经元的输出进行矫正,使得网络能够匹配特定的说话人,并且仅增加少量的自适应参数。
然而少量的自适应数据限制了LHUC自适应参数的调整,基于对上述缺陷的分析,本文从以下两个方面对原方法进行改进:(1)由于自适应网络性能的提升来源于获取的自适应数据所包含的信息量,而i-vector作为一种表示说话人信息的向量可以为自适应网络提供额外的信息,可以以此来弥补自适应数据信息量的不足;(2)受文献[8]的启发,将多任务学习引入LHUC自适应训练中,通过增加辅助任务,有助于自适应参数的更新,使自适应网络提升获取自适应数据信息的能力,以达到进一步提升系统性能的效果。
本文的主要工作包括:搭建DNN-HMM框架的连续语音识别系统作为基线系统,采用LHUC方法对DNN进行自适应训练;在现有模型的基础上,分别融合i-vector和多任务学习方法,并分别对实验结果进行分析。
1 基于DNN-HMM的基线系统
1.1 DNN-HMM
在DNN-HMM的框架中,HMM用来描述语音信号的动态变化,DNN利用其强大的分类能力估计观察特征的概率。DNN的输出层节点数对应于HMM的状态数。
DNN实际上是具有多个隐层的多层感知器(MLP),分为输入层、隐层和输出层。网络的计算公式为:
(1)
(2)
式中,l代表层数,wl表示l-1层到l层的权重,bl表示l层的偏置,x为输入向量,Zl表示激励向量,al表示l层的输出。对于每个隐层,激励向量通过激活函数获得激活向量作为输入送往下一个隐层,对于输出层,第j个神经元的值表示sj的后验概率,所以需要用softmax函数进行归一化,公式如下:
(3)
1.2 DNN训练
DNN的训练准则一般采用交叉熵准则,它用来衡量目标后验概率与实际后验概率的差异度,交叉熵函数的公式如下:
(4)
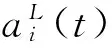
DNN采用反向传播算法进行训练。对于输出层,损失函数对最后一个隐层输出的误差为:
(5)
误差由输出层从后向前传递,通过式(5)中误差的回传,逐一求出前几个隐层的误差:
(6)
利用式(5)、(6)可求出损失函数对更新参数w和b的偏导数,公式如下:
(7)
(8)
参数的更新公式为:
(9)
(10)
式中,α为学习率,根据式(9)、(10)进行参数更新,寻找使得损失函数取得最小值时的权重。
2 LHUC自适应方法
LHUC模型采用说话人独立的神经网络模型,针对每一个特定人,用特定人的自适应数据进行自适应训练,固定原网络参数不变,只更新自适应参数,保留与特定说话人有关的参数。定义一组说话人有关的参数r,作用于网络中每个神经元的输出,如下式:
(11)
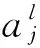
LHUC关于r参数的更新采用类似于训练说话人独立网络的反向传播算法,对于最后一个隐层r的梯度表示为:
(12)
由于剩下的隐层参数的梯度必须经a传导,故优先求出对于a的梯度:
(13)
前面各个隐层有关a的梯度可以由下式推导获得:
(14)
最终,前几个隐层对于r的梯度由前一层a的梯度获得:
(15)
以上获取了所有r参数的梯度。然而r参数不是共享的,它只对特定说话人有意义,如果测试集含有多个说话人,则需分别进行自适应训练获取特定人参数。
3 改进方法原理介绍
3.1 i-vector核心思想
i-vector在说话人确认和识别领域取得了广泛的应用,它能够很好地表征说话人信息并且具有固定的维度,这种优良的特性成为说话人自适应的一个理想工具。i-vector方法基于高斯混合模型-通用背景模型(GMM-UBM)。它将说话人信息和信道信息作为一个整体进行建模,特定说话人的GMM均值超矢量由以下公式表示:
VS=m+TwS
(16)
其中,VS表示说话人s的GMM均值超矢量,m表示与说话人无关的UBM均值超矢量,T为全局差异矩阵,wS为服从正态分布的总差异因子。i-vector的提取过程即为对总差异因子进行极大后验点估计。
语音特征主要包含语义信息,i-vector代表特定说话人信息,将语音特征和i-vector进行拼接,形成了说话人归一化的特征空间,新的特征输入到DNN中,DNN利用i-vector信息能够降低说话人差异带来的影响,提高系统的识别能力。
3.2 多任务学习
多任务学习[10]是一种通过同时学习多个相关任务来提高模型泛化能力的机器学习技术。深度神经网络这种对输入特征层层抽象的性质很适合采用多任务学习方法。如图1所示,DNN网络含有不止一个输出层,这些输出层共享网络的隐藏层,不同的输出层同时进行误差回传,它们的误差按照如下公式进行计算:
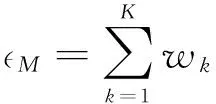
(17)

图1 多任务学习框架
4 实验结果与分析
本文首先构建基线系统及LHUC自适应网络,然后分别进行两种方法的LHUC改进实验。
4.1 基线系统及LHUC自适应实验
实验采用TED-LIUM版本1英语语料库,内容为英语演讲音频,采样率为16 kHz。语料库包括发音词典、训练集、开发集、测试集及对应的文本标注。训练集时长118 h,开发集时长10 h,测试集时长15 h。本实验将开发集也作为一个测试集使用,两个测试集分别记为Dev和Test。测试使用的3gram语言模型来自Cantab提供的TEDLIUM release1.1。系统评价指标采用单词错误率WER。
实验工具采用kaldi[11]语音识别工具包和PDNN[12]深度学习工具。首先建立HMM-GMM系统,在此基础上构建HMM-DNN基线系统。DNN网络采用6隐层结构,每个隐层含有1 024个神经元,实验采用sigmoid激活函数。输出层采用softmax函数,节点数为4 082,对应于HMM状态数。特征采用40维的Fbank,通过CMVN归一化处理,取前后各5帧进行拼接,共440维作为输入特征。训练集取总数据的5%作为交叉验证集。训练算法采用随机梯度下降算法,超参数batch-size设为256,训练之前进行SDA预训练。
在基线系统的基础上做LHUC自适应训练,Dev和Test两个测试集分别含有8和11个说话人,抽取每人的 15个句子作为自适应数据。
表1给出了基线系统及LHUC自适应系统的WER,实验验证了LHUC自适应方法可以有效地提升系统的性能,WER相比于基线系统下降了8%。

表1 基线系统和LHUC自适应系统的性能 (%)
4.2 i-vector方法的LHUC自适应实验
首先构建与i-vector相关的DNN基线系统。分别提取训练集和测试集中每个说话人的i-vector,向量维度设为100。将训练集语音特征与对应说话人的i-vector进行拼接,作为新的特征进行训练,获得说话人归一化网络,网络结构和训练方法与基线系统保持一致。LHUC自适应阶段,同样将自适应数据与i-vector拼接。
表2给出了基于i-vector方法的基线网络和LHUC自适应系统的性能。结果表明,在引入i-vector作为额外信息后,自适应系统的性能进一步得到提高,WER比原LHUC系统降低了2.5%。由此可以得出结论:i-vector信息的引入,提高了自适应网络对说话人的区分能力,缓解了自适应数据稀疏造成的影响。
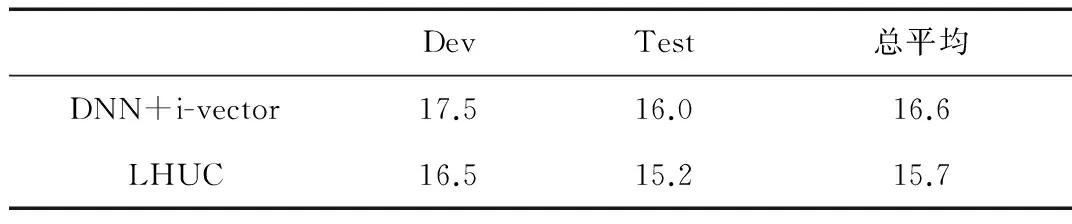
表2 i-vector网络和LHUC自适应系统的性能 (%)
4.3 多任务学习的LHUC自适应实验
实验的辅助任务选取单音素识别,单音素个数为46,对应辅助任务输出层的节点。首先训练辅助任务输出层的参数,利用训练集在基线网络上做单音素训练,保持隐层参数不变,只更新输出层参数。
将训练得到的辅助任务输出层应用到LHUC自适应训练中,进行多任务训练,主任务的误差权重设为1,不断改变辅助任务的误差权重做对比实验。
表3给出了辅助任务在不同权重下,自适应系统性能的变化。实验结果表明增加辅助任务可以有效提升系统的性能,性能随着辅助任务的权值变化而变化。当权值为0时,相当于不使用多任务方法,随着权值的增加,系统性能逐渐提升。当权重为3时,性能达到最优,WER相比LHUC基线降低了1.9%。随着权重的继续增加,性能出现下降,这是由于主任务的比重相对下降造成的。单音素识别与主任务具有一定的相关性,在自适应过程中,辅助任务的信息对有限的自适应数据进行了补偿,提升了自适应网络的泛化能力。
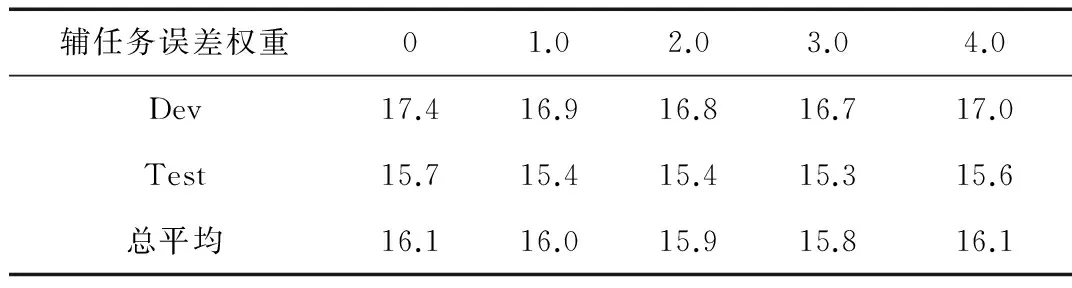
表3 辅助任务不同权重下LHUC系统性能 (%)
5 结束语
本文将i-vector和多任务学习这两种方法分别与LHUC自适应方法相结合,两种方法从不用的角度均缓解了原系统中自适应数据的稀缺问题。其中,i-vector包含的说话人信息向自适应网络提供了额外的信息;多任务学习方法中,辅助任务的信息对自适应数据进行了补偿。实验结果表明,两种方法都提升了自适应网络的泛化能力,WER相对下降了2.5%和1.9%。
参考文献
[1] GALES M J F, WOODLAND P C. Mean and variance adaptation within the MLLR framework[J]. Computer Speech & Language, 1996, 10(4): 249-264.
[2] CHESTA C, SIOHAN O, LEE C H. Maximum a posteriori linear regression for hidden Markov model adaptation[C]//Sixth European Conference on Speech Communication and Technology, 1999: 211-214.
[3] UN C K, KIM N S. Speech recognition in noisy environments using first-order vector Taylor series[J]. Speech Communication, 1998, 24(1): 39-49.
[4] TRMAL J, ZELINKA J, MÜLLER L. Adaptation of a feedforward artificial neural network using a linear transform[C]//International Conference on Text, Speech and Dialogue. Springer, Berlin, Heidelberg, 2010: 423-430.
[5] GEMELLO R, MANA F, SCANZIO S, et al. Linear hidden transformations for adaptation of hybrid ANN/HMM models[J]. Speech Communication, 2007, 49(10): 827-835.
[6] LI B, SIM K C. Comparison of discriminative input and output transformations for speaker adaptation in the hybrid NN/HMM systems[C]//Eleventh Annual Conference of the International Speech Communication Association, 2010: 526-529.
[7] DEHAK N, KENNY P J, DEHAK R, et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 788-798.
[8] HUANG Z, LI J, SINISCALCHI S M, et al. Rapid adaptation for deep neural networks through multi-task learning[C]//Sixteenth Annual Conference of the International Speech Communication Association, 2015: 3625-3629.
[9] SWIETOJANSKI P, RENALS S. Learning hidden unit contributions for unsupervised speaker adaptation of neural network acoustic models[C]//Spoken Language Technology Workshop (SLT), 2014 IEEE. 2014: 171-176.
[10] CARUNA R. Multitask learning: a knowledge-based source of inductive bias[C]//Machine Learning: Proceedings of the Tenth International Conference, 1993: 41-48.
[11] POVEY D, GHOSHAL A, BOULIANNE G, et al. The Kaldi speech recognition toolkit[C]//IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, 2011.
[12] Miao Yajie. Kaldi+ PDNN: building DNN-based ASR systems with Kaldi and PDNN[Z]. arXiv preprint arXiv:1401.6984, 2014.
