基于多特征权重分配的源代码搜索优化
2018-05-21辛园园
李 阵,钮 俊,王 奎,辛园园
(宁波大学 信息科学与工程学院 浙江 宁波 315211)
0 引言
在软件开发过程中,代码复用是提高软件开发效率的重要手段。目前,互联网中积累了大量的开源代码,如知名开源库GitHub[1]、OSChina[2]、CodePlex[3]等。在编制程序时,程序员可以对这些开源代码进行复用,从而降低开发成本。代码搜索是对其复用的前提。如何从开源软件中准确地提取高质量的代码资源并复用到软件产品中,是提高软件开发效率需要解决的重要问题。
针对代码搜索算法输入的不同形式,当前已经出现了基于关键字、接口、输入输出等形式的开源代码搜索引擎。不同于其他输入形式的搜索方法,由于方法签名是开发者通过一些能表达方法功能的词语根据驼峰命名法则命名的,所以基于关键字的搜索在匹配方法签名时往往更能体现方法功能的匹配;但针对面向对象语言开发的开源软件,当前基于关键字的搜索没有考虑其源代码具有多种代码特征[2],或者只考虑了用户查询语句与方法签名的单一匹配而忽视了源代码的其他重要特征如注释、类名等。比如源代码注释是对代码功能的描述,其中含有能体现方法功能的大量信息,这些信息对搜索特定功能的源代码是有帮助的。同理,类名中也含有少量体现代码功能的信息,而且源代码中各特征之间会有一定的联系。匹配时不能仅仅匹配单一方法名或者将多个代码特征转化成纯文本进行搜索而不考虑各代码特征的重要度,因此,将方法签名、源代码注释、方法体等代码特征结合起来应用于代码搜索中。
源代码的注释有描述代码功能的作用,根据描述的对象不同分为类注释与方法注释。在代码搜索中,对于代码功能模块来说,当搜索定位到方法为功能模块的最小单位时,则与方法相关的代码特征的重要程度会比较大。不同类型的注释对代码搜索的准确度都有贡献,且贡献度不一样。方法注释的贡献度要大于类注释。文献[5]虽然也是基于关键字搜索并考虑了多个代码特征,但是没有对注释进行分类,且未区分不同类型注释的重要性程度。另外对于方法签名来说,开发者在命名需要实现的功能模块时,通常使用具有代表性的可以概括这些模块功能的有意义的名称,但考虑名称的简洁性,方法签名往往只是由若干个单词组合而成,所以一个完整的方法签名往往不能完全描述出方法实现的功能。考虑到代码注释通常有描述方法功能的作用,注释中往往含有方法签名中未包含的关键词。针对结合注释的搜索在一定程度上满足了基于语义的匹配。
搜索代码时,将注释与方法签名和方法体等代码特征分别与查询语句进行匹配。根据不同代码特征的重要程度对匹配结果进行加权组合,制定评分机制,得到代码方法与查询语句的相似度评分。根据结果评分对代码方法进行排序,得到结果列表。
1 相关工作
传统源代码搜索主要是识别用户查询语句与方法签名之间的相关度而将相关度最大的方法返还给用户,这在一定程度上忽视了源代码的其他代码特征。文献[4]通过识别查询语句与应用程序编程接口(Application Programming Interface,API)的关系来提高搜索准确度。文献[5]通过分析查询词在方法签名中扮演的角色来确定相关的源代码,并整合四个部分内容:查询词在剩余代码中的使用率、查询词在方法签名中的语义角色、查询词在方法签名中的头部距离以及分析源代码的哪个位置比较有利于相关性最大化。文献[6]通过对Google经典算法PageRank的修改并应用在代码函数之间的调用上,从而找出“流行度”最大的函数,然后结合对源代码内容的匹配,返给用户最相关的源代码。文献[7]通过代码克隆技术,识别克隆代码并根据函数调用关系找出被调用最多的克隆代码。但这些研究都忽视了源代码中一个比较重要的代码特征:代码注释。
2 代码搜索引擎结构
源代码搜索是将从开源平台上获取的源代码资源收集起来构成本地代码仓库;对仓库中的源代码进行预处理,建立源代码对应的抽象语法树(Abstract Syntax Tree, AST)[8]并从中识别出对搜索有用的代码特征并建立索引;用处理过的用户查询语句在索引文件中搜索出相关的代码文件并计算相似度;根据相似度评分对结果进行排序。具体流程如图1所示。
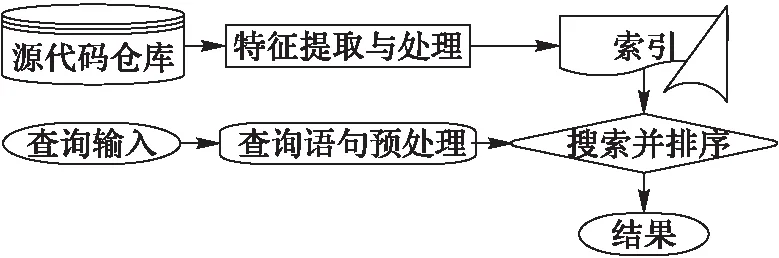
图1 代码搜索引擎流程 Fig. 1 Flow chart of code search engine
2.1 源代码处理
2.1.1 源代码获取
现在一些开源搜索引擎如GitHub、CodePlex等积累了大量的开源项目,这为源代码搜索的研究提供了“原材料”。本文从GitHub中获取源代码。
2.1.2 代码特征识别
本文从三个代码特征:注释、方法签名、方法体入手,对获取的源代码进行处理。通过建立并遍历源代码文件的AST,提取出源代码中的这三种代码特征。其中,方法模块的功能往往需要包名、类名和方法名的结合才能完整地描述出来。比如用户希望搜索到连接MySQL数据库的方法实现,识别出来的描述性的名称有包名:org.com.Mysql、类名:Connection、方法签名:getConnection(),此时识别完整路径上的名称才能满足精确的查找。重构后的方法签名为:org.com.Mysql.Connection.getConnection()。本文针对传统的方法签名进行重构,在原有的方法签名前加上方法所属类的类名及包名。
2.1.3 代码特征索引的建立
对所有代码特征进行文本标准化,然后对代码特征建立索引。在面向对象的语言中,所有方法都隶属于一个具体的类,则针对每个方法可能存在对应的方法注释和属于该类的类注释。每一个代码方法为一个搜索单位,建立索引时其对应一个Document,而Document是Lucene框架中存放在索引中的对象,每个Document根据不同代码特征分成多个域(Field)。因为针对注释这一代码特征来说分为类注释与方法注释,所以在注释层次将分为两个域,最终针对索引中的Document会有4个域。这4个域隶属于一个Document,也就是针对每个方法将4种代码特征规约在一起。在建立索引的同时可以指定每个域所占有的权重。
2.2 搜索与排序
2.2.1 查询语句预处理
本文假定用户输入的查询语句为自然语言,这样可以使具有不同开发经验的开发者都可以使用代码搜索引擎。软件开发初学者不必纠结于以何种格式的输入才能准确地找到结果,但是必须要对查询语句作一定的处理,使之可以用来匹配我们识别出来的代码特征。
2.2.2 搜索索引
在不同的域中,对建立的倒排索引进行搜索,找出与查询语句相关的Document。Document中的任何域对应的代码特征与查询语句相关,则定义Document与之相关。将各种相关的代码特征按照不同权重组合,给出多特征下的代码特征总的相关度,这里的相关度是处理过的查询语句与每个Document中4个域表示的代码特征转化为等维向量后的余弦相似度分数。查询语句与每种代码特征的相关度分数在没有权重影响下取值区间为[0,1],0表示查询语句与该代码特征不相关。其中任何一种代码特征与查询语句的相关度分数不为零,则表明包含该代码特征的Document是与查询语句相关的,而Document对应的代码方法能被检索到并返回。
2.2.3 排序
根据返回结果相似度分数的高低,对返回结果进行排序并将排好序的结果列表返回给用户。
3 代码注释的提取与索引
源代码的不同类型注释在相关度匹配中的重要程度不同。在以源代码中的方法为搜索单位时,类注释的重要程度要小于方法注释。根据重要程度对各类型注释赋予不同的权重。图2 是识别并处理不同类型注释的流程。
3.1 注释的提取
将源代码转换为对应的抽象语法树。抽象语法树作为源代码的语法结构表示,在源代码分析和代码复用中起着重要作用。在抽象语法树中每个节点都有相应的节点类型,根据不同节点类型来访问节点的值。图3所示为一般抽象语法树的部分节点类型树。在EclipseJDT[9]中,抽象语法树的根节点表示为CompilationUnit;在PackageDeclaration中获取包名;在TypeDeclaration中包含类注释和类名。BodyDeclaration节点下还有MethodDeclaration类型的节点,可以从中获取方法注释、方法名和方法体。
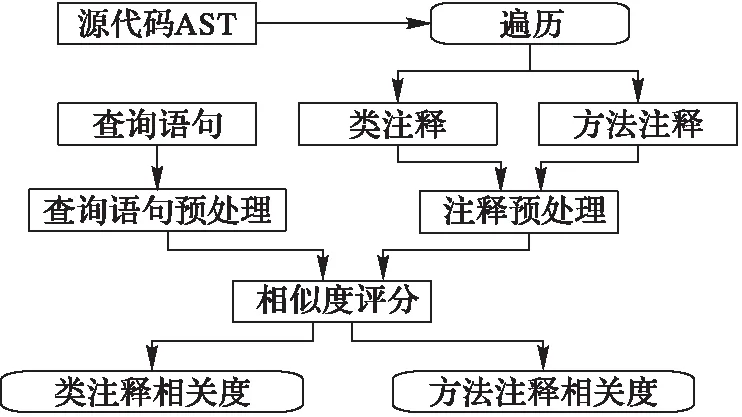
图2 不同类型注释处理流程 Fig. 2 Flow chart of processing different types of comments
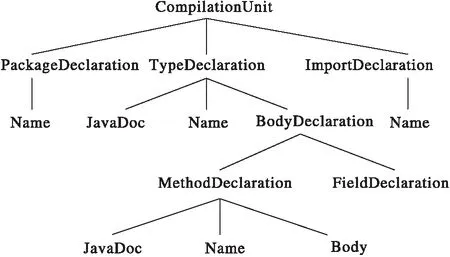
图3 抽象语法树节点类型树 Fig. 3 Node type tree of AST
本文使用EclipseJDT中的ASTParser与ASTNode对源代码抽象语法树进行创建与访问。根据Java设计模式中的访问者模式编写访问类,提取出不同类型的注释与相应的方法签名、类名、包名以及方法体等代码特征。
3.2 注释及查询预处理
对查询语句及不同类型的注释进行处理,包括文本标准化、去除停词、词干提取等操作。对其他种类的代码特征作同样的预处理。
3.2.1 文本标准化
文本标准化主要包括去除代码注释与查询语句中的标点符号以及对其分词。由于源代码中的方法名基本上是由很多单词组合在一起,通常是从第二个单词开始首字母大写,而注释有对方法功能的语义描述功能,其中可能也存在组合的单词。因此,本文采用大小写分词算法[4]。Lucene检索包中已经封装好了基本的分词模块。针对普通的英文语句,Lucene能进行分词并去除其中的停词[10]以及词干的提取,但是针对源代码,开发者往往在命名方法签名时,通常使用驼峰命名法则,所以Lucene自带的分词模块不能满足针对源代码的分词。本文在Lucene分词模块的基础上设计了针对驼峰命名的词语的分词模块。
3.2.2 去除停词
为了比较完整地描述方法的功能,开发者往往会使用一些词语修饰关键词,这就会导致注释中包含了一些对搜索没有帮助的词语,在搜索引擎领域中这样的词语称为停词。本阶段去除这些停词,比如冠词a、the,系动词 is、are和副词how等。
3.2.3 词干提取
由于自然语言中的英文单词在句子中会根据不同语态使用相应形式的单词,针对不同形式存在的单词,必须保证能够匹配到。比如用户输入关键词find时,像finding、finds等词语都要被识别出,反之亦然。处理过程即把所有关键词的词干提取出来作为关键词进行匹配,本文使用PorterStem算法[11]进行词干提取。
3.3 相似度评分
在相似度评分的过程中,需要对注释建立索引。本文用传统搜索引擎中的倒排索引算法。
3.3.1 倒排索引
通常在某篇文章中找某个关键词的时候,需要建立文章号与关键词的对应关系,然后通过文章号找到文章中的关键词。所谓倒排索引,就是将这种关系逆转过来,通过关键词来找到包含该关键词的文章号。如表1和表2表示的关系。

表1 文章中包含的关键词Tab. 1 Keywords in the articles
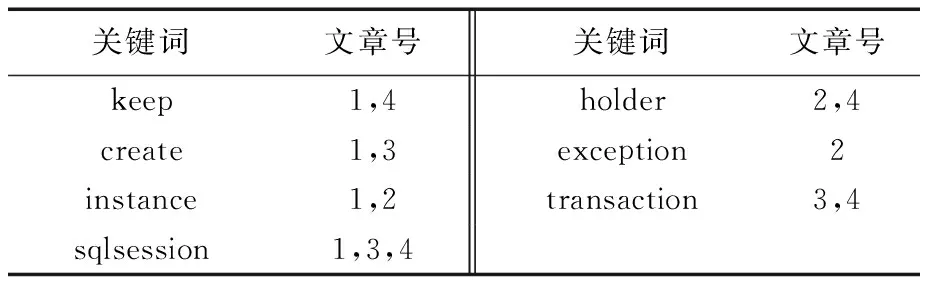
表2 关键词对应的文章号Tab. 2 Article numbers correspond to keywords
对于索引中的关键词按照字典顺序排序,通过二元搜索算法找到查询语句中的关键词在注释中的文章号,之后将注释和查询语句通过向量空间模型转化为一定维度的向量,进而求两者之间的相关度评分。
3.3.2 向量空间模型
本文使用向量空间模型[12]来实现查询语句与注释的匹配。将提取出来的注释转化为以关键词权重为元素的n维向量,其中n为关键词的个数。每个元素的权重使用全文检索技术中比较流行的TF-IDF(Term Frequency-Inverse Document Frequency)方法。
定义1 词频(Term Frequency, TF),即关键词在注释中出现的频率,计算公式如下:
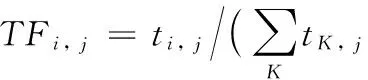
(1)
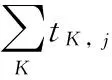
定义2 逆文档频率(Inverse Document Frequency, IDF)表示关键词的普遍重要性,计算公式如下:
(2)
其中:D表示注释总数,|{d|ti∈d}|表示包含关键词ti的注释数目。关键词i的权重记为Wi,计算公式如下:
Wi=TFi, j×IDFi
(3)
3.3.3 注释余弦相似度计算
将不同类型的注释转化为以关键词权重为元素的向量后,将用经过处理后的用户查询语句转化为与注释相同维度的向量。通常查询语句中的关键词的数量比较少,对于在注释中出现而在查询语句中没有出现的关键词,将查询语句向量相对应的权重设为零以保证未在查询语句中出现的关键词在计算相似度时贡献度为零。注释向量设为V(a)={W1,a,W2,a,…,Wn,a},查询语句向量为V(q)={W1,q,W2,q,…,Wn,q},计算两个向量的余弦相似度依据如下公式:
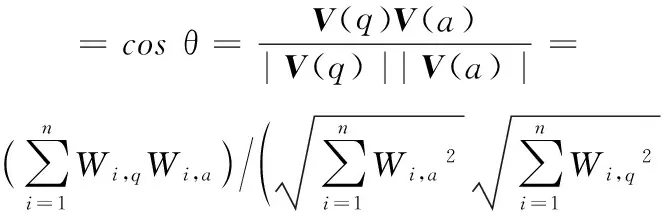
(4)
其中:分子是查询语句向量与注释向量的点积,分母是2个向量的欧几里得距离的乘积。
4 搜索与排序
在建立索引的过程中,以每个Java文件中方法为单位建立一个索引Document,在Document中添加4个Field:类注释(Class Comment, CC)、方法注释(Function Comment, FC)、方法签名(Function Signature, FS)、方法体(Function Body, FB)。将处理后的查询语句在每个域中进行匹配,得到查询语句与各代码特征的相关度评分。任何一个域所代表的代码特征与查询语句的相关度评分不为0,则表明该Document是与查询语句相关的。其中在建立索引的过程中,为每个Field设置一定的权重,以计算每个查询语句与搜索结果总的相关度评分。
4.1 搜索算法
由于第3章中在建立倒排索引的过程中,词典中的关键词都是按照字典顺序排序的,所以本文使用高效的二元搜索算法来实现对索引的搜索,只要关键词同时出现在查询语句与代码特征中,则该代码特征所对应的Document便能被检索到,从而得到有相关性的源代码文件Document,然后根据不同的权重分别计算查询语句与源代码文件中各代码特征的相关度评分。
4.2 权重分配
对不同类型的注释在建立索引时赋予不同的权重,然后计算注释与查询语句的相似度并结合不同权重的影响直接对搜索结果进行优化。针对注释阶段的匹配,给出计算注释方面的匹配分数Sc(Scoring Comments),计算公式如下:
Sc(c,q)=αSim(q,CC)+(1-α)Sim(q,FC)
(5)
其中:Sim(q,CC)表示查询语句与类注释的余弦相似度。Sim(q,FC)表示查询语句与方法注释的余弦相似度。α表示类注释在注释方面中占有的权重,(1-α)表示方法注释占有的权重。由于方法注释在注释方面的重要性大于类注释,所以1-α大于0.5,在此固定α的值为0.2。
针对方法对象Sf(Scoring Function)的匹配包括查询语句与方法签名匹配以及查询语句与方法体的匹配,其相关度得分依据如下公式计算:
Sf(F,q)=Sim(q,FS)+βSim(q,FB)
(6)
其中:Sim(q,FS)表示查询语句与方法签名的余弦相似度,Sim(q,FB) 表示查询语句与方法体的余弦相似度。β表示相对于方法签名,方法体在计算相关度的重要性。根据已有的研究[6],β的值一般取0.1。
针对用户搜索的结果(即代码方法),本文对方法对象与注释对象的相关评分进行权重分配并计算最终的相关度分数,其计算公式如下:
S(F,q)=Sf(F,q)+λSc(c,q)
(7)
其中:Sf(F,q)是由式(6)计算出的查询语句与方法对象的相关度评分,Sc(c,q)是由式(5)计算出的查询语句与不同类型注释的综合相关度评分,λ表示在方法对象和注释对象在计算相关度评分过程中的贡献度。由于注释是对方法对象的补充说明与描述,在计算相关度评分的过程中的贡献度远远大于方法对象中的方法体,故本文在此定义λ的取值区间为[0.2,0.8]。
4.3 结果排序
根据式(7)查询语句与代码特征的相关度评分对代码特征代表的结果排序,返还给用户。本文选取所有相关结果中的前30个结果,因为用户往往只关心排在前面的结果,排序相对靠后的结果对用户的帮助不大。
4.4 结果去重
由于在软件的开发过程中,针对一个规模比较大的软件来说,难免会出现功能相似的模块。这种情况下,用户往往倾向于复用已实现相应功能的代码以实现另一种功能。这种情况会导致在这个软件中有大量的代码是重复的,如果用户在搜索代码时返回大量功能相似的代码,则会增加用户查找结果的工作量。本文通过采用SimHash算法[13]对相似代码进行去重。
5 实验评估
5.1 实验环境
5.1.1 源代码选取
从当前最为流行的开源网站平台Github上下载51个Java开源项目,总大小为1.04 GB,这些项目中共有42 709个类,357 912个方法。选取的标准是比较开源项目在Github上的Star与Fork值,值大的优先考虑。往往这些开源项目较为稳定,在大量开发人员的共同开发下,这些项目的源代码在代码质量上优于一些刚成型的开源软件,并且这些开源代码中会存在大量的描述代码功能的各类注释。
5.1.2 开发工具包
本文通过遍历源代码的抽象语法树来识别各类代码特征,其中在遍历抽象语法树的过程中使用了EclipseJDT中的ASTParser和ASTNode工具包;在为代码特征建立索引并分配权重和搜索的过程中通过修改Lucene6.2.1全文检索开发工具包源码达到自己的搜索目的。
5.1.3 查询语句的搜集
根据以往研究[14]和一些软件开发者的查询日志,本文搜集到15条查询语句,如表3所示。

表3 查询语句列表Tab. 3 List of query statements
5.2 度量评估标准
在信息检索与统计学分类领域中最常用的度量标准为准确率与召回率。准确率(precision)表示检索出的相关结果占所有检索出的结果的比例。召回率(Recall)表示检索出的相关结果占所有相关结果的比例。由于本文的相关性取决于主观判断,所以无法在大量的源代码中确定具体数目的相关代码,而且当前也没有评测查询语句与代码是否相关的自动化判定方法,所以也无法计算出基于准确率与召回率的F-measure的评价指标,故本文放弃使用基于准确率-召回率的评价标准。
由于源代码的数量巨大,经过查询后返回的结果数量也是非常多的,但是用户往往只关注排在最前面的结果,所以本文选择基于排序的评价指标Precision@K。Precision@K表示设定一个阈值K,在检索结果到第K个结果是正确召回为止,排序结果的相关度。Precision@K(简写为P@K)的计算公式如下:
P@K=n/MK
(8)
其中:n表示在第K个结果是正确召回的前提下相关结果的数目,MK表示到第K个结果正确召回时总的返回结果个数。
因为P@K只能表示单点的策略效果,故引入Average_Precision@K评价标准,Average_Precision@K表示设定一个阈值K,在检索结果到第K个正确召回为止,排序结果的相关度。Average_Precision@K(简写为AP@K)的计算公式如下:
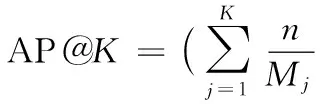
(9)
其中j表示不大于K的阈值。
因为涉及到一个策略在满足所有查询语句查询的结果,所以需引入Mean_Average_Precision@K(简写为MAP@K),MAP表示的是搜索查询结果Average_Precision@K值的均值,其计算公式如下:
(10)
其中:Q表示查询语句集合,i表示第i个查询语句,本实验总共搜集到15个查询语句。Mij表示在第i个查询语句查询时第j个结果正确召回时的返回结果总数。
在返回的结果序列中,第一个相关结果在序列中的位置可以反映出搜索算法的好坏。MRR(Mean Reciprocal Rank)是国际上对搜索算法进行评价的通用机制,即第一个相关结果在结果序列中位置的度量指标,其计算公式如下:
(11)
其中:Q表示查询语句集合,i表示第i个查询语句,ranki表示第i个查询语句搜索返回的第一个相关结果在结果序列中的位置。选择这个度量指标的原因是开发者往往找到第一个相关结果时便能满足搜索要求。第一个结果越靠前表明搜索算法越好。
5.3 实验结果
在基于关键词的搜索当中,Krugle可以命中包含查询关键字的源代码文件,同本文的搜索方式大致相同,所以为了验证本文提出的加入注释与重构方法签名的方法,在基于权重分配的条件下是否有效,选择与Krugle进行对比实验。在对返回的实验结果是否相关的问题上,由于相关性的判断是由人为判断的,所以为了尽可能地减少由于人为主观性带来的误差,本文选择编程经验近似的3名开发人员对实验结果相关性进行判断,并且将3名开发人员各自分开进行独立的判断,在3名开发人员同时将结果定为相关的时候,才将结果记录为相关。
上述实验结果是在默认权重下的实验结果,其中注释权重默认设为0.4。针对查询语句集中的append string to file的实验结果如表4所示。可以看出,准确率提升最少有8%,平均提升12%左右。一个查询语句对比结果的参考价值往往不高。
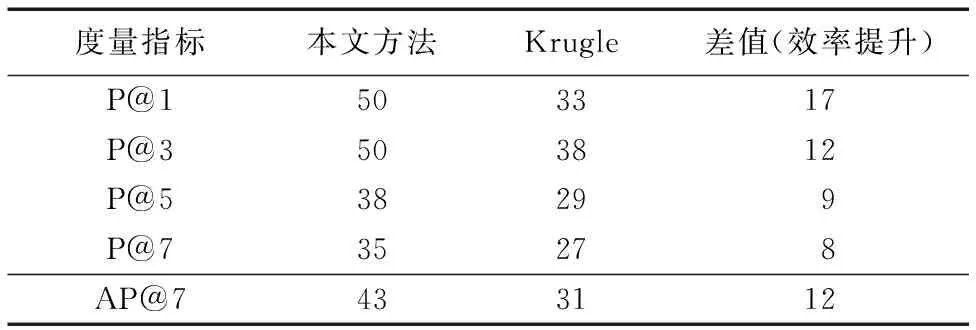
表4 单一查询语句AP@K实验结果 %Tab. 4 AP@K experiment results of single query statement %
下面对所有查询语句进行实验对比后得到MAP@K参数如表5所示。
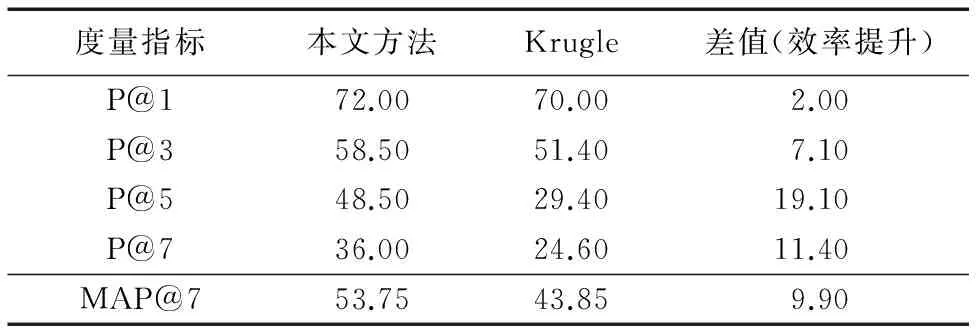
表5 复合查询语句MAP@K实验结果 %Tab. 5 MAP@K experiment results of multiple query statements %
由表5可以看出,在15条查询语句的实验对比下,本文的方法在相关结果排序上总体提升将近10%,这说明本文方法在提升搜索准确率上是有效的。为了使搜索优化度最大化,通过调整注释的权重,找出使MAP@K参数最大的权重系数。通过调整权重,得到实验曲线如图6所示,其中KMAP@7为Krugle搜索的MAP@7值。
在调整权重的实验中得出本文方法在不同权重下的MRR值与使用Krugle搜索的MRR值,由于Krugle没有考虑权重影响,所以Krugle针对本文的查询语句集合Q的MRR值是不变的。实验结果数据如表6所示。
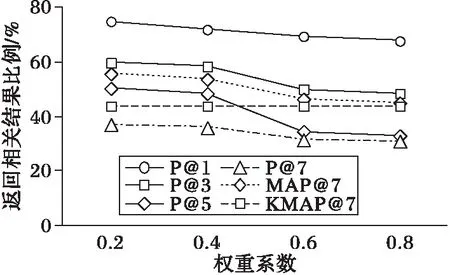
图6 不同权重系数结果对比 Fig. 6 Comparison of the results of different weight coefficients 表6 MRR实验结果 Tab. 6 Experiment results of MRR

权重本文方法Krugle权重本文方法Krugle0.20.750.600.60.6900.600.40.720.600.80.6730.60
通过图6可以看出不是注释权重越大,搜索效率提升越明显。当权重系数为0.8时,本文方法的搜索效率与Krugle就相差不多了(图中MAP@7与KMAP@7的趋势)。这说明,注释这一代码特征确实可以帮助提升搜索效率,但是,过大的权重也会增加查询语句中对查询不起主要作用的关键词的搜索得分,从而会在一定程度上限制搜索准确度的提升。所以本文在默认权重为0.4情况下得到效率提升将近10%,在0.2权重下提升大于10%。而表6的实验数据表明本文搜索方法在MRR的度量上是优于Krugle的,即在使用本文方法搜索的返回结果序列中,针对15条查询语句的第一个相关结果的综合位置比Krugle得到的结果靠前,说明在搜索中加入注释这一代码特征并考虑权重可以提升代码搜索准确度。在MAP@K与MRR度量标准下的实验对比结果说明本文方法是有效的。
6 结语
在基于关键字的源代码搜索研究中,本文在对单一代码特征识别与匹配的基础上,考虑其他代码特征对搜索结果的影响,增加了对注释的匹配和方法签名的重构,并且考虑了多个代码特征的权重问题。通过与已有代码搜索引擎的实验结果进行对比,多个代码特征在不同权重影响下提升了代码搜索准确度。
本文在方法签名的重构中没有考虑类名、包名的权重问题,在匹配重构后的方法签名时类名、包名与方法名在搜索过程中的贡献度是相同的,但是开发人员在编码过程中,往往在命名方法名与类名时会加以区分,这就会导致重构后的方法签名中方法名与类名、包名对搜索的贡献度是不一样的,所以在匹配方法签名时会影响搜索结果的准确度。后续可以对评分机制作出改进,如考虑对类名和包名赋予不同的权重,以期进一步提高代码搜索的准确度。
参考文献(References)
[1] Github. Github [DB/OL]. [2017- 01- 02]. https://github.com.
[2] Open Source China. OSChina [DB/OL]. [2017- 01- 02]. https://www.oschina.net.
[3] Microsoft. CodePlex [DB/OL]. [2017- 01- 02]. https://www.codeplex.com.
[4] 吕飞.基于搜索的代码推荐技术研究[D].上海:上海交通大学,2015.(LYU F. Research on search based code recommendation techniques [D]. Shanghai: Shanghai Jiao Tong University, 2015.)
[5] HILL E, POLLOCK L, VIJAY-SHANKER K. Improving source code search with natural language phrasal representations of method signatures [C] // Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering. Piscataway, NJ: IEEE, 2011: 524-527.
[7] ISHIHARA T, HOTTA K, HIGO Y, et al. Reusing reused code [C]// Proceedings of the 2013 20th Working Conference on Reverse Engineering. Washington, DC: IEEE Computer Society, 2013: 457-461.
[8] 林泽琦,赵俊峰,谢冰.一种基于图数据库的代码结构解析与搜索方法[J].计算机研究与发展,2016,53(3):531-540.(LIN Z Q, ZHAO J F, XIE B. A graph database based method for parsing and searching code structure [J]. Journal of Computer Research and Development, 2016, 53(3): 531-540.)
[9] 刘石,李合,王啸吟,等.基于语法与语义分析的代码搜索结果优化[J].计算机科学,2009,36(8):165-168.(LIU S, LI H, WANG X Y, et al. Enhancement of code search results using syntax and semantic analysis [J]. Computer Science, 2009, 36(8): 165-168.)
[10] HAIDUC S, ROSA G D, BAVOTA G, et al. Query quality prediction and reformulation for source code search: the Refoqus tool [C]// Proceedings of the 2013 35th International Conference on Software Engineering. Washington, DC: IEEE Computer Society, 2013: 1307-1310.
[11] PORTER M F. An algorithm for suffix stripping [J]. Program, 1980, 14(3): 130-137.
[12] ASWANI KUMAR C, RADVANSKY M, ANNAPURNA J. Analysis of a vector space model, latent semantic indexing and formal concept analysis for information retrieval [J]. Cybernetics and Information Technologies, 2016, 12(1): 34-48.
[13] 陈春玲,陈琳,熊晶,等.基于Simhash算法的重复数据删除技术的研究与改进[J].南京邮电大学学报(自然科学版),2016,36(3):85-91.(CHEN C L, CHEN L, XIONG J, et al. Research and improvement of data de-duplication based on Simhash algorithm [J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2016, 36(3): 85-91.)
[14] BAJRACHARYA S K, OSSHER J, LOPES C V. Leveraging usage similarity for effective retrieval of examples in code repositories [C]// FSE ’10: Proceedings of the 18th ACM SIGSOFT International Symposium on Foundations of Software Engineering. New York: ACM, 2010: 157-166.
LIZhen, born in 1992, M. S. candidate. His research interests include open source search.
NIUJun, born in 1976, Ph. D., associate professor. His research interests include service computing, open source search.
WANGKui, born in 1988, M. S. candidate. His research interests include open source search.
XINYuanyuan, born in 1993, M. S. candidate. Her research interests include open source search.
