Faster R-CNN模型在车辆检测中的应用
2018-05-21张鹤鹤
王 林,张鹤鹤
(西安理工大学 自动化与信息工程学院,西安 710048)
0 引言
车辆检测是智能交通系统中一个不可或缺的重要环节,它能够为道路交通控制、高速公路管理和紧急事件管理等诸多后续交通环节提供强有力的信息支撑,因此得到了研究者的广泛关注。传统的基于机器学习的车辆检测方法通过方向梯度直方图(Histogram Of Gradients, HOG)[1]和尺度不变特征转换(Scale-Invariant Feature Transform, SIFT)[2]等方法对车辆进行特征提取,并将其提取到的特征输入至支持向量机(Support Vector Machine, SVM)[3]、迭代器(AdaBoost)[4]等分类器进行车辆检测。这类方法本质上使用的是人为设计和制造的特征作为图像表征的工具,需要研究人员具有相当坚实的专业知识和大量的经验,设计过程较为主观,缺乏理论的指导,不但耗费时间精力,而且最终得到的特征也是参差不齐,难以适应天气和光线等条件的变化,泛化能力差。随着交通环境的日趋复杂,采用人工设计特征的手段进行车辆检测越来越难以胜任。而深度学习的出现就解决了这一问题,深度学习中的卷积神经网络对几何变换、形变和光照等具有一定程度的不变性[5],并且可以灵活地在训练数据的驱动下根据不同的需求任务自动地去学习有用的特征来帮助算法完成检测和识别的任务。相比人工设计的特征,对目标具有更强的表达能力。
近年来,随着深度学习的快速发展,基于深度卷积神经网络的目标检测方法得到广泛应用。文献[6]中Girshick等提出了基于区域卷积神经网络(Regions with Convolutional Neural Network features, R-CNN)的目标检测方法,解决了如何用少量的标注数据训练出高质量模型的问题,成为了目前目标检测领域的主流方法,但是效率低、占用内存大。随后,Ross和微软亚洲研究院的研究者陆续提出了改进的R-CNN方法:文献[7]中首次引入空间金字塔池化层,放宽了对输入图片尺寸的限制,提高了检测准确率;文献[8]中提出了Fast R-CNN模型,规避了R-CNN中冗余的特征提取操作,采用自适应尺度池化对整个网络进行优化从而提高了深层网络检测识别的准确率,但是利用选择性搜索算法提取候选区域,耗时较多,无法满足实时应用需求;文献[9]中通过构建精巧的区域建议网络(Region Proposal Network, RPN)取代时间开销大的选择性搜索方法,提出了Faster R-CNN模型,解决了计算区域建议时间开销大的瓶颈问题,使实时检测识别成为可能,并在2015年ImageNet比赛中在VOC 2007和 VOC 2012数据集上实现了最高的目标检测准确率。
综上所述,Faster R-CNN模型将目标检测的4个基本步骤(候选区域生成、特征提取、分类、位置精修)统一到一个深度神经网络框架之内,能够在训练数据的驱动下自动提取目标的特征,既对位移、尺度和光照等具有一定程度的不变性,又能保证理想的检测率,基本实现实时检测,可克服现有基于机器学习的车辆检测方法的不足。然而若直接将该模型应用于实际场景中的车辆检测,将会出现以下两大弊端:1)远近不同场景中车辆尺寸差异较大,可能无法检测出远处场景中较小的车辆;2)数据集中一般目标区域比背景区域小很多,负样本空间大,训练时收敛困难。
因此本文以Faster R-CNN为基础模型,结合多尺度训练和难负样本挖掘策略,利用KITTI数据集训练深度神经网络模型,并进行合理的参数调节,把车辆检测问题转换为车辆的二分类问题,解决了光照、目标尺度和图像质量等因素的影响,训练时负样本空间大的问题,进一步提高了车辆检测的效率和精确度。
1 改进的Faster R-CNN的车辆检测方法
Faster R-CNN模型以卷积神经网络框架caffe(convolutional architecture for fast feature embedding)为基础,主要由两个模块构成:RPN候选框提取模块和Fast R-CNN目标(车辆)检测模块,模型框图如图1所示。RPN是全卷积神经网络,用于提取高质量的候选框,即预先找出图中车辆可能出现的位置;Fast R-CNN基于RPN提取的候选框来检测并识别候选框中的车辆。
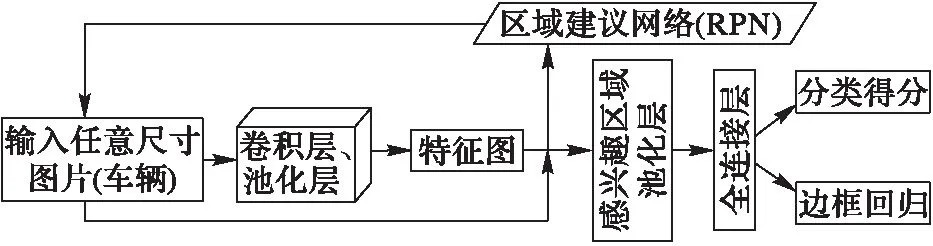
图1 Faster R-CNN模型框图 Fig. 1 Framework of Faster R-CNN model
1.1 区域建议网络
通过在ImageNet预训练模型ZF最后一层卷积特征图之后添加一个卷积层和两个并行的全连接层来构建RPN。RPN[9]以原始图像所提取出的卷积特征图矩阵作为输入,输出一系列的矩形候选框以及该矩形候选区域是否为目标的分数,RPN的结构示意图如图2所示。
RPN中采用了滑动窗口机制,在卷积神经网络最后一个共享卷积层的特征图上增加一个小的滑动窗口,该滑动窗口与输入特征图n×n大小的空间是全连接的,每一个滑动窗口都映射成一个低维的短向量,将该向量输入到两个并行的全连接网络层,一个网络层负责输出滑动窗口区域内的特征属于图像背景还是目标,另一个网络层负责输出该区域位置的回归坐标值。当n×n的滑动窗口在卷积特征图矩阵上滑动时,滑动的每个位置都在原始图像对应k个不同的锚框(人为假定的在原始图像中的候选区域),因此一个全连接层输出2×k维向量,对应k个锚框目标和背景的分数,另一个全连接层输出4×k维向量,表示k个锚框对应于真实目标框的变换参数。每一个锚框都以当前滑动窗口的中心为中心,并分别对应一种尺度和长宽比。本文预设了4种尺度(642、1282、2562、5122)和4种长宽比(1∶1、1∶2、1.5∶1、2∶1),这样在每一个位置就有16个锚框,使得RPN提取的候选框更加准确;同时对生成的候选框采用非极大值抑制法(Non-Maximum Suppression, NMS)选取300个得分较高的候选框。
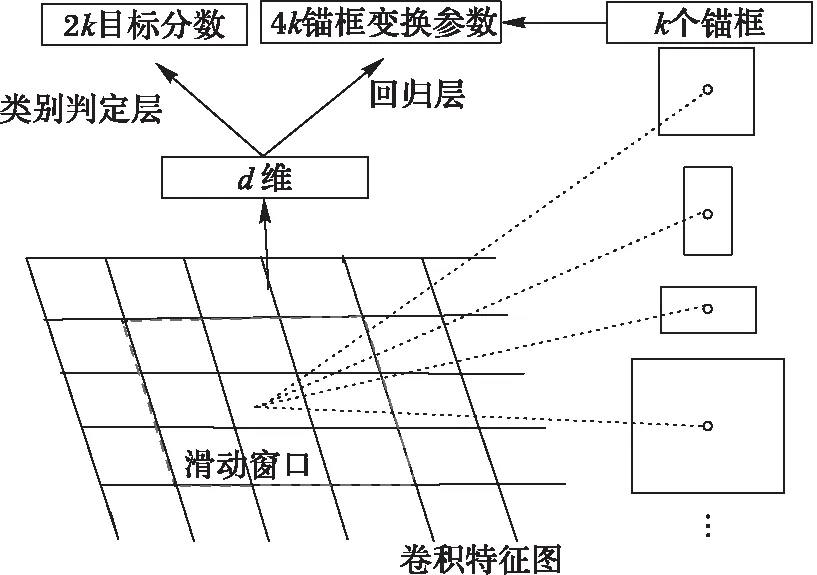
图2 RPN结构 Fig. 2 Framework of region proposal network
损失函数如下。
为了训练区域建议网络(RPN),给每一个候选框都分配一个二进制的标签(目标/非目标)。本文中给以下两类候选框分配正标签:
1)与某个真实的区域包围盒有最大交并比(Intersection-over-Union, IoU)(即两个区域的交集面积与并集面积之比)值。
2)与任意真实区域包围盒的IoU值大于0.7的候选框。
为所有与真实区域包围盒的IoU值低于0.3的候选框分配负标签。遵循文献[9]中的多任务损失,最小化损失函数对网络进行微调。对一个图像的损失函数定义为:
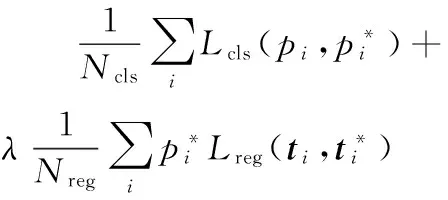
(1)
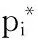
(2)
对于回归损失,定义为:
(3)
其中smoothL1(x)为:
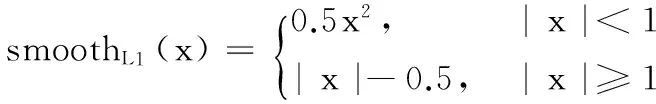
(4)
对于回归,采用4个坐标的参数:
(5)
其中:(x,y)为预测的包围盒的中心坐标;(xa,ya)为候选框的坐标;(x*,y*)为真实区域包围盒的坐标;w和h分别为包围盒的宽和高;Ncls和Nreg为归一化参数,实验中设为256和2 400;λ为平衡因子,实验中设为10。
1.2 Faster R-CNN模型的改进
Faster R-CNN将原始图像和RPN提取出来的候选框同时送入Fast R-CNN检测网络。训练时,首先将带有标注的数据集输入网络中,对输入图像进行5层卷积网络的特征提取,之后将候选区域映射到该共享的特征图中,获取相应的特征信息,通过感兴趣区域(Region of Interest, RoI)池化层对该特征进行池化操作,得到一个7×7的区域特征池化图,并通过全连接层得到一个4 096维的特征向量,该向量就是卷积神经网络所提取出的每个候选框的最终特征。最后,将此特征向量分别输入到Softmax分类与包围盒回归中,可预测候选区域属于每个类别的概率(得分)和目标对象包围盒的更合适的位置。
为了使得Faster R-CNN模型能够更好地应用于车辆检测中,本文在训练的过程中加入了多尺度训练和难负样本挖掘策略来增强模型的性能。
1.2.1 多尺度训练
在实际场景中,远处和近处的车辆目标尺寸差异较大。原始的Faster R-CNN模型使用的是单一尺度的图片进行训练,对图像中的较远目标会出现漏检的情况。本文采用多尺度训练,将每张图像设置了3种尺度(600、850、1 100),每张图像随机选择三种尺度之一输入进网络进行训练,因此训练出的模型将能够在各种尺寸范围内学习特征。通过实验证明使用多尺度训练能够让参与训练的目标大小分布更加均衡,从而使得训练出来的模型对目标大小具有一定的鲁棒性。
1.2.2 难度样本挖掘
Faster R-CNN模型在训练过程中有一个很大的问题,整张图里面目标的区域要比背景的区域小很多,负样本空间大。如果直接把这样极度不均衡的数据拿去训练模型的话,模型可能会倾向于把所有的样本分为负样本,导致训练时难以收敛。文献[10-11]中所用的难负样本挖掘策略可以有效地解决这个问题。本文在训练阶段加入难负样本挖掘策略,将第一次训练时在负样本原图(没有目标)上进行目标检测时收集所有检测到的矩形框,然后用这个初始模型错误分类的负样本形成一个难负样本集,将此难负样本集加入到训练集中重新训练新的模型。训练时将输出的得分高于0.7并且与任意真实区域包围盒的IoU值小于0.5的候选框作为难负样本。实验证明难负样本挖掘策略可以增强算法的判别能力,提高检测的精确度。
1.3 模型训练与检测过程
模型训练和测试的流程如图3所示。在模型训练阶段主要进行数据处理、参数调优等过程;在模型测试阶段,主要利用测试样本对训练所得的模型的有效性进行检验。
具体的训练过程如下:
1)获取KITTI数据集,将KITTI数据集转换成VOC2007数据集格式。
2)采用ZF模型作为卷积特征提取模型,利用处理好的数据集对模型进行训练。
3)使用相同的数据集测试初步训练好的模型来产生难负样本。
4)将这些难负样本加入到训练集中,对网络再次训练,增强模型的类别判定能力。
5)通过式(1)对网络模型进行微调,得到最终的检测模型。在这个阶段加入多尺度训练策略,使得参与训练的目标大小更加均衡,从而提高模型的性能。
在整个训练阶段,采用文献[9]中交替训练两个网络的方式来进行训练,使得区域建议网络(RPN)和目标检测网络(Fast R-CNN)共享卷积层特征,构成一个统一深度卷积神经网络,从而提高了计算效率,达到实时检测的效果。
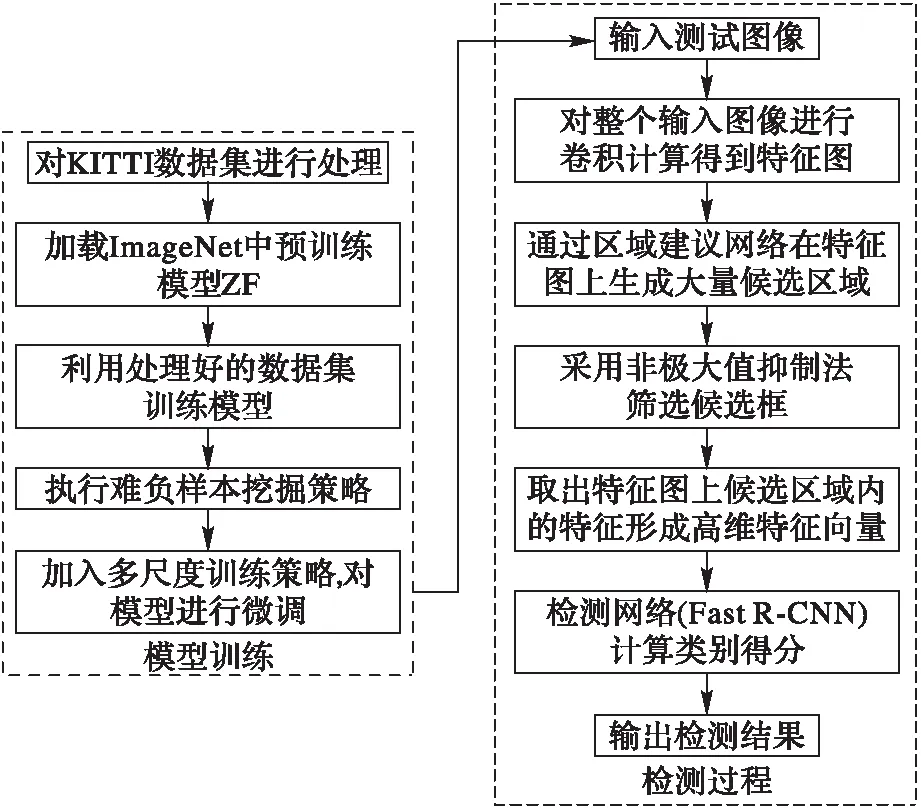
图3 模型训练与检测的流程 Fig. 3 Flow chart of model training and testing
2 实验分析
2.1 数据集
本文训练的原始数据集为KITTI数据集[12],该数据集包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多包含15辆车,还有各种程度的遮挡与截断。实验中选取了5 000张图像,并根据实验需求将其转化为VOC2007数据集格式进行训练。另外采集了300张实际场景中不同条件下的图像(各种背景和各种光线)对训练好的模型进行测试,验证本文所用方法的有效性。
2.2 实验结果及分析
为评估本文算法在解决车辆检测问题时的有效性,本文使用召回率(recall)和精确度(precision)来衡量模型的性能[13]。召回率与精确度的取值范围均在[0,1],计算公式如式(6)和式(7)所示:
recall=TP/(TP+FN)
(6)
precision=TP/(TP+FP)
(7)
在GPU@3.90 GHz,8 GB内存,64位Windows 7的计算机系统下进行了相应的实验,并对结果进行了详细的分析。实验分为4个部分:
1)对比相同场景下两种算法的检测效果。
利用KITTI数据集对原始的Faster R-CNN和改进后的Faster R-CNN进行训练,并从测试集中选取100张图像(包含232辆车)进行测试,两种算法的召回率、精确度如表1所示。检测效果如图4所示。

表1 相同场景下两种算法的检测效果Tab. 1 Detection results of two algorithms under same scene

图4 两种算法的检测效果对比图 Fig. 4 Comparison of detection results by two algorithms
图4中(a)、(b)分别为两种模型的检测效果图,图中目标车辆处显示的是该目标的类别名和置信度。从图4以及表1的数据对比可以看出通过多尺度训练和难负样本挖掘策略改进后的Faster R-CNN模型的召回率、精确度均优于原始的Faster R-CNN模型。相比原始的Faster R-CNN模型,在保证时间性能的情况下召回率提升了约6%,精确度提升了约8%,并且框图相对完整,能够检测图中各种尺寸的车辆目标。
2)采用不同方法检测单张相同图片的时间对比。
利用YOLO[14](You Only Look Once)、SSD[15](Single Shot MultiBox Detector)、RFCN[16](Region-based Fully Convolutional Network)和原Faster R-CNN以及本文方法对测试集中的图像进行检测,检测的精确度和检测速率如表2所示。
YOLO将整个检测问题转化为一个回归问题,网络结构简单,检测速度较高,但是相比表2中的同类方法精确度较低。SSD结合了YOLO和Faster R-CNN方法,使检测精确度得到了提高。RFCN使用Faster R-CNN架构,但只含有卷积网络,减少了计算量,和Faster R-CNN相比提高了检测速率。本文在Faster R-CNN基础上结合了多尺度训练和难负样本挖掘策略提高了精确度。从表2可以看出,本文方法在检测速率方面稍劣于其他方法,但是在保证基本实现实时检测的情况下,检测精确度相比其他方法有很大的优势。综合考虑本文的方法是一个有效的车辆检测方法。
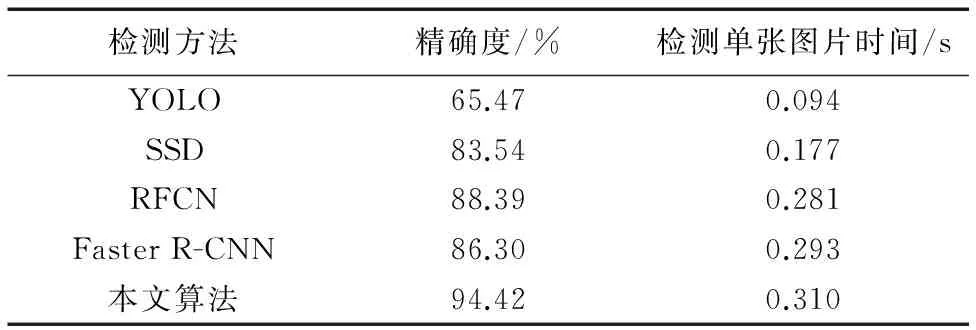
表2 不同方法处理相同图片的时间对比Tab. 2 Time comparison of different methods dealing with same picture
3)采用不同策略训练网络时的检测效果。
为了进一步验证所提方法中使用不同策略的有效性,本文分别使用不同的策略对网络进行训练与测试。采用的策略以及训练之后的检测结果见表3所示。

表3 采用不同策略训练网络的检测效果Tab. 3 Detection results of using different strategies to train network
对比表3中策略1和2发现锚框数量的增加使得检测精度提升了约1个百分点。这是由于原始的Faster R-CNN在RPN网络中设置9个锚框,对于区域面积较小的地方容易出现漏检的情况,如图3中的(a)与(c)。本文通过添加一种尺度(642)和一种长宽比(1.5∶1),将锚框的数量增加到16,使得模型可以检测更多的小目标。对比策略2和3发现使用难负样本挖掘策略使得模型的判别能力增强,检测精度提升了约2个百分点。对比策略2和4发现由于使用了多尺度训练策略,使得模型对目标大小具有一定的鲁棒性,从而提升了模型的检测精度。实验证明采用多尺度训练和难负样本挖掘策略训练模型可以有效地提高模型的检测精度以及召回率。
4)不同场景下改进的Faster R-CNN检测效果。
从300张测试数据中挑选了50张不同场景下的图像来测试改进的Faster R-CNN的性能,其检测结果图如5所示。
观察图5可以看出改进的Faster R-CNN对于流量较大、光线较强并且存在车辆重叠的场景如图5中的(e),光线较差的场景如图5中的(a)、(b)、(c)与(d),目标尺寸差距大的场景如图5中的(c)、(d)与(f),背景环境复杂且目标较为模糊的场景如图5中的(a)、(b)与(f)均具有较好的检测效果。实验结果表明本文所使用的方法能够适用于不同场景下的车辆目标检测,精确度和实时性均满足实际要求。
3 结语
本文结合多尺度训练和负样本挖掘策略改进了目前在目标检测领域最先进的Faster R-CNN 方法,通过KITTI数据集对深层模型训练,进行合理的参数调节,将复杂环境下的车辆检测问题转换为易于实现的车辆二分类问题。实验证明,该方法能够自动提取车辆的特征,训练出的模型对不同清晰度、不同车流量、不同遮挡程度和不同目标大小的场景均具有很好的鲁棒性,运行效率上每幅图像处理速度在毫秒级别,但是模型训练过程对硬件设备有较高要求,有待进一步改进。

图5 不同场景下车辆检测效果 Fig. 5 Vehicle detection results under different scenes
参考文献(References)
[1] NEGRI P, CLADY X, HANIF S M, et al. A cascade of boosted generative and discriminative classifiers for vehicle detection [J]. Eurasip Journal on Advances in Signal Processing, 2008, 2008: Article No. 136.
[2] MA X, GRIMSON W E L. Edge-based rich representation for vehicle classification [C]// Proceedings of the 2005 10th IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2005: 1185-1192.
[3] TEOH S S, BRAUNL T. Symmetry-based monocular vehicle detection system [J]. Machine Vision & Applications, 2012, 23(5):831-842.
[4] CAO X, WU C, YAN P, et al. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos [C]// Proceedings of the 2011 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2011: 2421-2424.
[5] 何灼彬.基于卷积深度置信网络的歌手识别[D].广州:华南理工大学,2015:38-48.(HE Z B. Singer identification based on convolution deep belief networks [D]. Guangzhou: South China University of Technology, 2015: 38-48.)
[6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 580-587.
[7] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(9):1904-1916.
[8] GIRSHICK R. Fast R-CNN [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1440-1448.
[9] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[10] SUN X, WU P, HOI S C H. Face detection using deep learning: an improved faster RCNN approach [EB/OL]. [2017- 03- 01]. http://xueshu.baidu.com/s?wd=paperuri%3A%28526a86e5697d1f0c149d60d8ba856dd5%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Farxiv.org%2Fpdf%2F1701.08289&ie=utf-8&sc_us=9408430938623955412.
[11] SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region-based object detectors with online hard example mining [C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 761-769.
[12] FAN Q, BROWN L, SMITH J. A closer look at faster R-CNN for vehicle detection [C]// Proceedings of the 2016 Intelligent Vehicles Symposium. Piscataway, NJ: IEEE, 2016: 124-129.
[13] 钟晓明,余贵珍,马亚龙,等.基于快速区域卷积神经网络的交通标志识别算法研究[C]//中国汽车工程学会年会论文集.北京:中国汽车工程学会,2016:2033-2036.(ZHONG X M, YU G Z, MA Y L, et al. Research on traffic sign recognition algorithm based on faster R-CNN [C]// Proceedings of the 2016 Annual Conference of Society of Automotive Engineers of China. Beijing: SAE-China, 2016: 2033-2036.)
[14] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 779-788.
[15] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Berlin: Springer, 2016: 21-37.
[16] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [EB/OL]. [2017- 04- 21]. http://pdfs.semanticscholar.org/a8f2/4fcc1eb0354ffd91f0e3031f5c4dc3e02dd6.pdf.
This work is partially supported by Shaanxi Province Science and Technology Key Project (2017ZDCXL-GY- 05- 03).
WANGLin, born in 1962, Ph. D., professor. His research interests include wireless sensor network, community detection of complex network, big data, data mining.
ZHANGHehe, born in 1991, M. S. candidate. Her research interests include big data, deep learning.
