浏览器缓存污染防御策略
2018-05-21戴成瑞
戴成瑞,陈 伟
(南京邮电大学 计算机学院,南京 210023)
0 引言
浏览器缓存可以节约网络资源加速浏览,浏览器在用户磁盘上对最近请求过的资源进行缓存,当访问者再次请求这个页面时,浏览器就可以从本地磁盘调用该缓存资源,这样就可以加速页面的阅览。
浏览器缓存[1]主要包括Web缓存和HTML5应用程序缓存[2]。一般网络上的资源都是默认利用Web缓存方式进行缓存,随着网络生活的高速发展,人们在使用浏览器上网时会浏览各种各样的资源文件,而这些资源文件又分为静态资源文件和动态资源文件:静态资源文件是指图片、CSS文件等,这些文件在较长的时间内都不会发生变化;而动态资源文件通常是指经常变化的JS文件,当然有些JS文件属于变化较少的,通常这类文件容易遭受缓存污染攻击[3]。
攻击者可以通过中间人攻击、被动抓包等方式污染用户缓存,而传统的缓存污染防御方案仅仅是针对某一具体的攻击行为,本文希望设计一种可以不用关心攻击者采用何种缓存污染攻击方式的防御策略,对将要直接从缓存读取的资源通过特征分析、用户行为分析等多个步骤来判断该资源是否具有被污染的可能性,最终保证用户请求资源的安全性和体验性。
本文首先分析并研究了目前常用的缓存污染攻击方式,然后对传统的缓存污染防御方案进行分析,在指出传统防御方案存在不足的基础上,提出一种无需关心攻击者污染方式的防御方案,能够自适应防御浏览器缓存污染,最后分析了本文所提出的防御方案的局限性,对今后的工作进行展望。
1 相关工作
缓存污染主要是一种污染用户缓存的网络攻击手段[4]。这种缓存可以是域名系统(Domain Name System, DNS)缓存[5]、内容分发网络(Content Delivery Network, CDN)缓存或者说本文所讨论的浏览器缓存,就浏览器缓存污染研究而言,主要包括对污染攻击的方法、防御和危害分析[6]这几个方面。
Vallentin等[7]在介绍中间人攻击的手段来实施缓存污染攻击的同时,还提出了一种被动抓包侦听的方式来实施缓存污染攻击。Jia等[8]在介绍常规的HTTP浏览器缓存污染攻击的同时,介绍了对HTTPS下实施缓存污染攻击的方式,还提出了同源攻击、跨源攻击和浏览器插件攻击三种攻击手段。Vallentin等[6]等对一个真实的网络环境进行了缓存污染攻击,并介绍了如何利用最小的污染成本来实现最大化的攻击范围并定量分析了缓存污染的危害性。因此从上述的研究成果来看,对污染攻击的方法已经有了较为全面的介绍,但是从防御的角度,大都是从用户出发,提出经常清理缓存的建议。本文所介绍的防御策略是一种在用户与服务器之间的一种可调控防御策略,这种策略的最大优势在于不关注用户是否被污染,或者说攻击者使用何种方法进行浏览器缓存污染,简化了缓存污染防御的流程,且能够在安全性和用户体验性之间进行合理的平衡以满足不同用户的使用需求。
从之前研究结果来看,大部分用户都没有定期清理缓存的习惯,甚至处于一个中间人攻击环境[9]也没有一个良好的安全意识,使得各种各样的缓存污染成为可能,而这又往往会成为其他网络攻击的跳板,危害极大[10]。本文所做的研究工作一方面希望能提高人们的安全意识,另一方面提出一种能够抵抗绝大多数的缓存污染攻击的防御策略,既不影响用户正常浏览网页的体验性,又可以提高在复杂网络环境下的安全性。
2 缓存污染攻击
浏览器缓存污染[11]是指在攻击者攻击受害者浏览器期间,返回给浏览器具有潜在威胁的缓存资源,当受害者脱离攻击者攻击环境并再次上网请求资源时,浏览器直接从缓存中读取已被攻击者污染的资源从而受到污染攻击。
就目前的研究工作而言,国内外对缓存污染攻击方式有了较为全面的研究,最常用的攻击模式就是利用中间人攻击[12],替换服务器返回给受害者的资源文件,不仅将返回数据包头部中的缓存时间设置成很长的时间,还在返回数据包的内容里加上攻击者想要在受害者机器上执行的代码,常用的攻击模式如图1所示。
Vallentin等[7]还提出了一种不使用中间人攻击的方式进行缓存污染攻击,只需监听无线网络并利用重定向技术即可,虽然同样处于服务器和受害者中间,但是攻击者通过监听网络中的数据帧,并自行构造响应数据帧来干扰受害者,使受害者浏览器缓存了攻击者想要污染的内容。

图1 常用缓存污染攻击图 Fig. 1 Common cache pollution attack
之前讨论的攻击都是针对HTTP下的缓存污染[8],因为在HTTP下通信双方是没有加密的,很容易搭建一个中间人攻击环境,而Jia等[8]介绍了一种HTTPS下实施缓存污染攻击的方法,其中在HTTPS下能实施缓存污染攻击最主要的原因在于,对于大部分用户,在面对浏览器提示某个网站证书有误,确认是否继续访问时,他们仍然会点击继续访问。他们提出了同源攻击、跨源攻击和浏览器插件攻击三种手段来进行HTTPS下的缓存污染攻击。
针对缓存污染防御方面,正如前面篇幅所述,HTTPS本身是可以抵御一定的浏览器缓存污染的,推荐站点尽可能使用HTTPS协议进行通信,但用户缺乏安全意识的话HTTPS也不是那么可靠,这种情况下推荐使用HTTP严格传输协议(HTTP Strict Transport Security, HSTS),只要用户第一次访问了合法的站点,浏览器在很长的时间里都只能用HTTPS访问该站点,可以较好地防御流量劫持。然而面对这样的防御手段,攻击者仍然可以通过跨源攻击的方式实施缓存污染攻击:当用户访问网站1时,攻击者故意加载网站2的资源,这个攻击手段的意义在于网站1若是某个新闻网站(不涉及用户敏感信息),而网站2是某个在线银行网站(具有敏感信息),即使浏览器弹出证书不可信的提示,但是用户仍然会以较大概率点击继续访问,然而背后加载的却是网站2的资源。
Jia等[8]还提出一种同源策略,因为对于某个JS资源A也许会被不同网站调用,浏览器可以记录是向网站1请求的资源A还是向网站2请求的资源A,这样可以防止跨源缓存污染攻击。这种防御方式的弱点在于攻击者可以采用浏览器插件攻击,因为部分浏览器插件通常也含有一些脚本文件,污染浏览器插件的意义在于插件是属于浏览器的,不管访问哪个网站,都会触发缓存污染攻击。
其实对于浏览器来说,如果发现某个服务器证书不可信,那么就不要缓存该服务器下的资源。对于用户来说,最简单直接的缓存污染攻击防御策略就是不要访问不受信任的网站,并且养成定期清理缓存的好习惯,增强安全意识。
因此,在已有的一些缓存污染应对方法出现的情况下,本文开展研究的目的是上述介绍的任何浏览器缓存污染防御方式都无法应对多种多样的网络攻击,防御中间人攻击带来的缓存污染,攻击者仍可以使用被动抓包、流量注入等方式达到目的,很难找到一个应对多种攻击模式的防御策略,而这真正的问题在于大部分研究仅仅关注如何防止用户缓存被污染,而忽视了缓存污染攻击的触发条件即用户下次请求资源时直接读取被污染的缓存。因此本文研究的核心是即使用户缓存被污染,也能通过一些手段将其检测并恢复出来,这样防御策略可以直接跳过判断用户此时是否遭受同源攻击、跨源攻击、流量注入等缓存污染攻击的步骤,从而用单一的防御策略应对多种多样的攻击模式。
无论是用何种方式污染了受害者浏览器下的缓存[13],当受害者脱离了攻击者搭建的攻击环境,由于受害者计算机中的缓存资源已经被污染,仍然会面临着潜在的威胁;而这种威胁是未知的,如果用户不及时清除自己的缓存,这样的威胁也许会持续一个月,甚至更久,而且往往缓存污染攻击可以当作很多网络攻击的跳板来作出更具有侵害性的行为[14]。因此,提出一种流程简单但能应对多种缓存污染攻击方式的防御方案具有重要的实际意义。
3 浏览器缓存污染防御方案
无论采取何种方式进行缓存污染攻击,攻击者的目的都是一样的:污染用户的缓存[15]。因此本文所讨论的防御方案并不关注防御攻击本身,而是在于及时检测出被污染的缓存并进行恢复。即使用户的缓存被污染,当用户在后续的访问中,我们能及时检测到被污染的资源使之重新加载成正确的资源,同时又能保证未被污染的缓存资源能够顺利从用户浏览器缓存中读取,总的来说,本文所讨论的防御方案是在保证用户正常浏览网页的情况下,既不影响到用户体验性,又能实现安全的保障。
本文所讨论的防御端处于用户与服务器之间,该防御策略理想化的实验结果就是一方面将所有未被污染的缓存资源直接作读取缓存处理;另一方面使所有被污染的缓存资源都能够被防御脚本检测出来,并且重新向服务器请求真实的资源返回给用户。
因此本文所设计的防御策略总体思路就是在用户请求缓存资源时,逐步根据缓存资源特征判断该资源是否是未被污染的:一旦在判断过程中认为该资源是未被污染的就作直接读取缓存处理;当经过所有的判断该资源仍无法决定,就认为该资源是被污染的,需要重新向服务器请求该资源。这么做的目的在于尽快地判断出该资源是否应该直接读取缓存,从而最大限度上减小防御策略判断过程中带来的时间消耗。
整个判断策略过程是一个从粗略到细致的过程,刚开始的判断仅仅是分析该资源是否要从缓存中读取,不读缓存的资源就相当于从服务器重新请求资源。真正具有潜在威胁的是准备读取缓存的资源,针对这部分资源,该防御策略通过用户的行为特征和资源本身的通用度进一步决策出是否被污染;对于仍无法判断的资源需要进行最后的哈希验证,这是检测资源是否被污染最为有效也是最耗时的方法,一旦验证不成功就拒绝该资源并向服务器重新加载新的资源。3.1~3.7节将阐述具体的防御策略。
3.1 随机数判断
如果用户请求的统一资源定位符(Uniform Resource Locator, URL)后面含有随机数,那么代表该资源是直接向服务器请求最新的资源,无需进行后续的判断,防御端不作处理,因为这样请求的资源一定是服务器上真实的资源,不存在被污染的可能性。
3.2 请求响应延时判断
如果用户请求的资源URL后面没有包含随机数,那么该资源是有可能受到污染的,因此这里需要计算用户请求该资源的时间和服务器返回的时间差:如果该时间差超过了某个阈值Te,则认为该资源之前是没有被缓存到用户浏览器上,自然也不需要重新申请该资源;如果该时间插值小于该阈值,则此资源需要进一步判断是否被污染。
这里的阈值Te可以在防御端启动时进行初始化检测,因为对于不同的网络环境,这个阈值Te是不一致的,同时,用户在上网的过程中,也有可能面临网速的变化,因此防御端对于阈值Te的检测是周期性的。
3.3 资源代表性判断
进入此步骤的资源由于请求返回时间差小于阈值Te,因此都是将要直接读取用户浏览器缓存的。这里为了进一步优化用户的体验性,需要定义并计算资源代表性值C,因为对于大部分的缓存污染攻击模式,攻击者利用中间人攻击的手段不满足仅仅污染用户请求的资源,而是使用预加载通用资源至用户端的方式,导致用户缓存资源虽然没有被大面积污染,但是却能以很高的概率被触发。因此攻击者使用的通用资源必然是具有代表性的,所以当用户请求的资源是处于不常访问的或者说之前根本没有访问的,那么我们大概率推测该资源是没有被污染的,可以直接返回给用户。
此时定义资源代表性值C,该值由用户行为值U与Alexa[16]统计值A累加得出。其中:用户行为值U是根据用户上网的习惯所给出的评价值,范围是[0,1];Alexa统计值A是根据Alexa网站统计排名所给出的值,范围同样是[0,1]。当资源代表性值C小于阈值Tc时,那么认为该资源是非通用资源,不容易成为攻击者攻击的目标,这些资源直接返回给用户;当C大于阈值Tc时,将交由下一步判断。
这里的阈值Tc同样可调控:如果想要追求更大的安全性,阈值Tc应该设置足够地小,让更多的资源进行下一步的判断;如果想要更好的用户体验,可以提高阈值Tc。
3.4 哈希验证
不论攻击者利用什么手段污染了用户的某个资源,该资源与服务器上原始资源的哈希值是不同的。基于此,考虑到防御端无需占用太大的空间,防御端事先以键值对的形式存储好常用的资源名所对应的该资源内容的哈希值,同时可以搭建一个防御端服务器存储更多这样的键值对便于查询。进入到该步骤下的资源,如果所计算返回资源的哈希值和防御端中已存放对应的哈希值一致,直接返回给用户;如果不一致,说明该资源被污染,防御端重新向服务器请求最新的资源给用户;如果没有查询到,访问防御端服务器查询并进行同样的操作。当服务器端也查询不到时,直接向服务器请求真正的资源返回给用户,因为即使该资源是未被污染的,重新向服务器请求真正资源并计算哈希值比对也是没有意义的,所以这里直接当作被污染的资源处理。
3.5 众包策略
这里值得注意的是,真正的资源文件也是会变化的,当远程服务器的资源文件发生变化,而防御端还没即时更新,此时检测哈希值必然是不一致的,防御策略会将这样的资源当作污染资源处理,因此,当防御端所监测的用户群在某个时间开始,针对某个资源的哈希值出现大量的不一致且这些计算的哈希值都为同一值时,将进行自适应的调整,以保证防御端能够存放着不断更新的键值对。
当然,众包策略需要大量用户参与才能保证众包的可靠性,例如当防御系统充当校园网管角色时,大量校园用户与远程服务器的交互会使系统不断处于一个自动更新的状态,而当只有少量用户参与,该防御系统并不能做到有效的快速更新,更多依赖的是系统本身定期向各个服务器来获取最新的数据。
3.6 相关假设
在用户依赖这样的防御策略情况下,需要保证当防御脚本检测出污染资源时向服务器请求的最新资源是未被污染的。如果用户已经脱离攻击环境,显然向服务器重新请求资源是安全的;而用户仍若处于中间人攻击这样环境,此时很难利用该防御策略抵御缓存污染攻击,因为就算服务器返回的资源是未被污染的,攻击者仍可以采用中间人的方式替换资源。这里涉及到的关键问题在于中间人攻击的防御,并不在本文讨论的范畴。本文所介绍的防御策略就是让资源可以被缓存污染,但是在下次触发缓存污染时能够有效检测并恢复。
3.7 防御策略算法
本文所介绍的防御端是处于用户与服务器之间,换句话说,它既可以充当某个校园网管的角色进行缓存污染保护,也可以运行在用户机上针对具体的用户进行防护。为了便于进行实验和结果分析,将中间人代理方式构建在用户机上,当用户在浏览器设置里添加Node.js所监听的端口以及代理服务器地址(这里就是127.0.0.1),那么之后这样的一个简单的代理首先能够接收客户端的转发请求,并且根据客户端请求向真正目标服务器发起请求,最后再将真正的服务器响应内容转发给客户端。
在搭建了这样一个中间人代理之后,按照上一章节所介绍的防御策略设计相应的算法实现。其中对于资源代表性判断算法,由于涉及到两种不同范围的值的运算,所以需要对数据作归一化处理,对于用户行为值U,采集用户的历史浏览纪录并按照访问次数大小排序如下所示:
[x1:u1],[x2:u2],…,[xn:un]
xi(i=1,2,…,n)代表资源名,无论用户使用HTTP协议还是HTTPS(SSL/TLS)协议,提取用户在一段时间内请求的资源名,作为用户行为值判断的样本。ui(i=1,2,…,n)代表资源xi的访问次数,总共有n对这样的数据,其中u1≥u2≥…≥un,因此如果对于资源xj,那么归一化的计算公式为:
针对u1=un这种情况,无需使用归一化对用户行为值进行处理,因为该条件代表用户历史浏览记录中不同资源的请求次数都是一致的,此时用户行为值U是无意义的参数,无法判断该资源在历史记录中的流行程度。因此只需考虑另一种判断因素也就是Alexa统计值A,本文参考的是Alexa网站流量全球综合排名[16],这是一种更具有普适意义的系数,与上述数据不同的是,这里按照如下方式采集数据:
[y1:m],[y2:m-1],…,[ym:1]
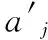
最后根据系数W按如下公式计算c:
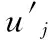
随着时间的推移,用户行为值U与Alexa[16]统计值A都会发生变化,虽然一些变量在初始化的时候生成,但是在后续的防御过程中会周期性地检查以确保防御端处于一个不断更新的状态。考虑到上一时刻的ci-1仍然对当前时刻的ci具有一定的影响,一个合理的计算公式为:
ci=t*ci-1+(1-t)*ci
t是上一时刻的ci-1对当前时刻的ci的影响因子,处于0~1,通过这样不断的迭代,c会不断地根据上一时刻更新到这一时刻从而与阈值Tc相比较。这些变量和值如表1所示。
4 实验及结果
4.1 缓存污染攻击模拟实验
本文基于Node.js模拟中间人攻击的方式,对用户进行缓存污染攻击模拟实验。
4.1.1 搭建环境
用户处于一个中间人攻击环境[17]或者连上攻击者创建的无线网络接入点。这一步主要是为了构建一个网络攻击环境,本文具体采用Node.js中的express框架,监听本机的8080端口。实验进行时,用户将浏览器的代理服务器设置成127.0.0.1,同时代理端口设置为8080,接下来用户通过浏览器发出的请求都会被监听脚本捕获。
4.1.2 选取待污染的资源
在这一部分的实验中,尽可能地模拟攻击者的行为,从攻击者的角度出发,如何选取合适的资源来污染是这一步的关键。首先创建一个URL的列表文件,上面列举着一些常用的网站域名,再基于PhatomJS模拟请求这些网站,根据网站返回资源信息,去提取出带污染的资源URL。具体的选取规则依赖于HTTP头部特征,本文根据资源头部信息里的缓存时间、缓存过期时间、上次修改时间和是否具有ETag标志这四个特征判断这个资源是不是容易被污染的。即使用户进行刷新操作,浏览器也不会向服务器请求完整的资源,而是询问服务器该资源是否被修改过,若没有修改过,那浏览器仍然从缓存中读取该资源,因此选取这些待污染的资源能有效避免用户刷新页面导致缓存污染攻击失败的问题。
4.1.3 实施缓存污染
用户正常浏览网页,当攻击脚本监听到用户在访问HTTP的网站时,尝试预加载上述待污染的资源,利用发送带随机数的URL请求真正的资源并加上模拟攻击代码,那么上述选取的待污染资源内容其实都被篡改,即在保证显示原有页面的情况下弹出一个模拟攻击窗口,同时设置资源的缓存时间为31 536 000 s以及其他的头部信息。
4.2 实验结果分析
此时用户的浏览器缓存里会被强行缓存了攻击者设置好的资源,这些资源往往具有很高的通用性,也许用户这一时刻并不会打开,但是这些资源都被设置了很长的缓存时间,并且这些资源在服务器上距离上次修改也隔了很长的时间,大概率推测将来的一段时间也不会频繁地变动,因此即使用户脱离攻击环境,只要之后没有清空缓存,那么该资源很容易被触发,一旦请求了该资源,浏览器会从缓存中直接读取,而缓存已经被污染,所以用户将会执行攻击者的代码。
在分析实验结果之前需要定义污染样本的命中率和正常样本的误判率。命中率是用来衡量该防御脚本的安全性,命中率越高说明有更多的污染样本被防御脚本检测出来,用户通过直接加载缓存的方式请求资源而触发缓存污染的概率也就越低,因此实验的目标就是要将防御脚本的命中率接近100%;误判率指的是防御脚本将正常样本检测为污染样本的概率,误判率越高说明防御脚本会让用户重新加载本应该直接读取缓存的正常资源,因此必然会带来时间上的多余消耗,从而影响到了用户体验性。对于个人用户而言,也许重新加载资源所带来的多余延时影响并不大,为了保证不漏判任何的污染样本,必然要对用户体验性方面做出牺牲,换句话说就是在处理难以判断的样本时尽量当作污染样本处理,来换取足够高的安全性,因为攻击者往往利用缓存污染作为跳板实施网络攻击,触发缓存污染的危害是难以预估的;而对于校园网管的角色来说,往往会处理许多用户的大量请求,需要权衡安全性和用户体验性,而该防御策略在两者之间可以通过参数调控的。
采用预加载的形式使用户浏览器缓存了攻击者想要缓存的资源共1 000条,接着让用户脱离攻击环境并运行本文所介绍的防御端脚本,当用户请求其中100条被污染的资源和100条正常的资源,统计该防御策略在松弛条件和严格条件下能实现多少的命中率和误判率,同时与不开启浏览器缓存污染防御脚本和将所有资源都重新加载进行比较,最后统计上述四种方案的请求响应延时,实验结果如表2所示。
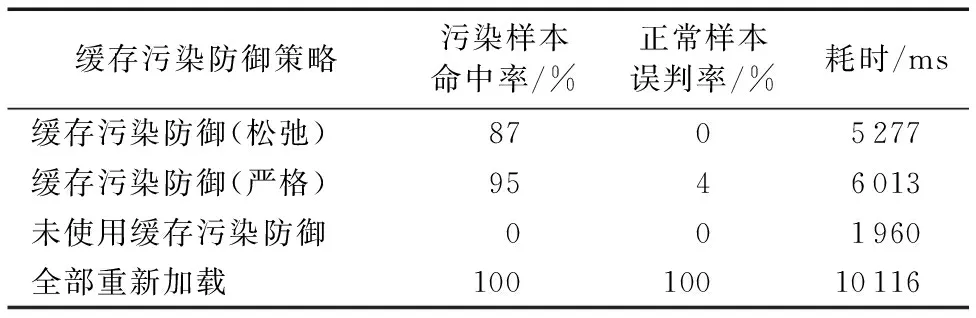
表2 实验结果Tab. 2 Experimental results
由表2所示,很容易理解未使用防御策略和全部重新加载在污染样本命中率和正常样本误判率的表现,而另外的两种是采用不同程度的缓存污染防御策略,相比而言,严格的防御策略下很多资源的URL交由哈希验证处理,因此会存在部分查询不到导致误判率增加,同时耗时相对于松弛条件略有增加。
不难看出利用缓存污染防御策略相对于未使用防御策略的,能保持一个较好的安全性,同时还可以在可调控的范围内以较低的请求响应延时进行工作。
4.3 缓存污染防御策略的优势
首先缓存污染防御是一个处于用户和服务器之间的防御手段,不受Web开发者、服务器、浏览器限制。传统的浏览器缓存污染防御措施主要防止用户遭受污染攻击,Jia等[8]在介绍同源缓存污染攻击手段时提出了利用HTTPS来防止中间人缓存污染攻击,然而攻击者仍可以利用跨源的缓存污染攻击来削弱HTTPS的安全性,随后便提出一种同源策略来应对跨源攻击,即使这样,攻击者仍可以采用污染浏览器插件脚本的方式来实施污染攻击,因为浏览器插件是属于浏览器本身的而非某个网站,只要污染了插件访问任何网站都会遭受攻击。当用户设法采取各种各样的措施来防止中间人这种方式的缓存污染攻击时,攻击者仍可以采用Vallentin等[7]所介绍的流量注入方式污染用户的缓存。
由此发现,攻击者的攻击模式是多样的,而传统的防御措施仅仅是考虑了如何防御用户被污染,一旦新攻击方式出现,那么传统的防御方案就会失效,而本文提出的防御策略不关注缓存污染攻击的方式,即使用户遭受了污染攻击,在后续的请求流量过程中该防御策略仍能检测并恢复正确的资源文件。
在用户体验、服务器带宽和安全性之间提出了一种可调控的平衡方案。防御方案中使用了用户历史行为进行辅助判断以便提高响应速率。防御方案中的响应时间阈值、资源代表性值都可以通过当前网络环境进行动态判断,以增强实用性。本方案不关注资源是否被污染,或者说攻击者使用何种方法进行Web缓存污染[18],简化了缓存污染防御的流程,将防御重心放在用户的整个请求过程,既保证了安全性,又不影响用户的体验性,同时还不增加服务器端的压力。
5 今后的工作
本文所介绍的防御端是处于用户与服务器之间,并且假设此时用户已经脱离了攻击环境,这是为了保证防御端向服务器端请求资源是未被污染的,如果攻击者处于防御端和服务器之间,这样的防御策略很有可能失效了,因此,接下来的工作是在这样的环境下进行一种实时的防护,尤其是当用户从一个常规的IP地址突变到了一个非常规的IP地址,例如咖啡厅、快餐店等布置的公共网络,该防御系统需要进入一个更高的安全检测级别[20],对于敏感的URL可以考虑在请求头部加上不缓存的模式,防止攻击者乘虚而入。
众包策略依赖大量用户的参与,如何判断用户量已经达到了可以开启众包策略进行实时更新的条件是接下来需要考虑的问题,但同时这样的策略也容易遭受女巫攻击,攻击者可以伪造大量的节点共同请求污染的资源导致防御系统产生错误的更新而带来安全隐患,因此接下来需要对访问防御端服务器的用户进行验证。以校园网管的角色来说,学生可以按照自己唯一的学号去生成相应的数字证书,从而限制非法用户伪造大量节点的请求。
同时,接下来的工作还应包括对用户行为的详细分析与预测,因为对于不同的用户来说,他们的访问习惯也是不同的,因此在他们的浏览器缓存中应该存放着体现各自上网习惯的信息,所以,要想实现更高的污染样本命中率和更低的正常样本误判率需要将本文已经进行的工作与用户行为分析[21]工作相结合。
6 结语
本文提出一种在用户与服务器之间的缓存污染防御策略,通过随机数判断、请求相应延时判断、资源代表性判断、哈希验证和众包策略这五个步骤,即使用户缓存已经遭受污染,也能在后续的请求资源过程中检测出污染资源并进行恢复。与传统的缓存污染防御方案相比,本文提出的防御策略并不关注攻击者通过何种手段污染用户缓存,并且在变化的网络环境中能够进行自适应更新,使防御方案时刻保持着实用性与稳定性。
面对用户行为的多样性和防御策略环境的限制,接下来的工作需要对不同网络环境和不同用户群采用不同的防御策略,因为单一的标准往往不能适用于多种变化的环境和人群,设计不同的防御策略以便在今后工作中保证用户安全性的同时仍然保持着良好的用户体验性。
参考文献(References)
[1] 汤红波,郑林浩,葛国栋,等.CCN中基于节点状态模型的缓存污染攻击检测算法[J].通信学报,2016,37(9):1-9.(TANG H B, ZHENG L H, GE G D, et al. Detection algorithm for cache pollution attacks based on node state model in content centric networking [J]. Journal on Communications, 2016, 37(9): 1-9.)
[2] 贾岩,王鹤,吕少卿,等.HTML5应用程序缓存中毒攻击研究[J].通信学报,2016,37(10):149-157.(JIA Y, WANG H, LYU S Q, et al. Research on HTML5 application cache poison attack [J]. Journal on Communications, 2016, 37(10): 149-157.)
[3] LI M. Persistent JavaScript poisoning in Web browser’s cache [EB/OL]. (2015- 12- 12) [2017- 07- 14]. http://www.cs.tufts.edu/comp/116/archive/fall2015/mli.pdf.
[4] KLEIN A. Web cache poisoning attacks [M]// Encyclopedia of Cryptography and Security. Boston, MA: Springer, 2011: 1373-1373.
[5] HAY R, SHARABANI A. Protection against cache poisoning: U.S. Patent 8,806,133[P]. 2014- 08- 12.
[6] VALLENTIN M, BEN-DAVID Y. Quantifying persistent browser cache poisoning [EB/OL]. (2010- 04- 21) [2017- 07- 04]. http://matthias.vallentin.net/course-work/cs294-50-s10.pdf.
[7] VALLENTIN M, BEN-DAVID Y. Persistent browser cache poisoning [EB/OL]. [2017- 07- 20]. https://people.eecs.berkeley.edu/~yahel/papers/Browser-Cache-Poisoning.Song.Spring10.attack-project.pdf.
[8] JIA Y, CHEN Y, DONG X, et al. Man-in-the-browser-cache: persisting HTTPS attacks via browser cache poisoning [J]. Computers & Security, 2015, 55: 62-80.
[9] KUPPAN L. Attacking with HTML5 [EB/OL]. [2017- 04- 01]. https://www.techylib.com/en/view/victorious/attacking_with_html5.
[10] 方慧鹏,应凌云,苏璞睿,等.移动智能终端的SSL实现安全性分析[J].计算机应用与软件,2015,32(7):272-276.(FANG H P, YING L Y, SU P R, et al. Securiy analysis on SSL implementation of smart mobile terminals [J]. Computer Applications and Software, 2015, 32(7): 272-276.)
[11] JOHNS M, LEKIES S, STOCK B. Eradicating DNS rebinding with the extended same-origin policy [C]//SEC ’13: Proceedings of the 22nd USENIX Conference on Security. Berkeley, CA: USENIX Association, 2013: 621-636.
[12] SALTZMAN R, SHARABANI A. Active man in the middle attacks [EB/OL]. [2017- 03- 03]. http://www.security-science.com/pdf/active-man-in-the-middle.pdf.
[13] JIA Y, DONG X, LIANG Z, et al. I know where you’ve been: Geo-inference attacks via the browser cache [J]. IEEE Internet Computing, 2015, 19(1): 44-53.
[14] LEKIES S, JOHNS M. Lightweight integrity protection for Web storage-driven content caching [EB/OL]. [2017- 04- 11]. http://www.w2spconf.com/2012/papers/w2sp12-final8.pdf.
[15] KARAPANOS N, CAPKUN S. On the effective prevention of TLS man-in-the-middle attacks in Web applications [C]// Proceedings of the 23rd USENIX Conference on Security Symposium. Berkeley, CA: USENIX Association, 2014: 671-686.
[16] ALEXA.CN. Alexa [DB/OL] (2017) [2017- 08- 01]. http://www.alexa.cn/siterank/.
[17] 黎松,段海新,李星.域间路由中间人攻击的实时检测系统[J].清华大学学报(自然科学版),2015,55(11):1229-1234.(LI S, DUAN H X, LI X. Real-time system for detecting inter-domain routing man-in-the-middle attacks [J]. Journal of Tsinghua University (Science and Technology), 2015, 55(11): 1229-1234.)
[18] CLARK J, van OORSCHOT P C. SoK: SSL and HTTPS: Revisiting past challenges and evaluating certificate trust model enhancements [C]// Proceedings of 2013 IEEE Symposium on Security and Privacy. Washington, DC: IEEE Computer Society, 2013: 511-525.
[19] PRANDINI M, RAMILLI M, CERRONI W, et al. Splitting the HTTPS stream to attack secure Web connections [J]. IEEE Security and Privacy, 2010, 8(6): 80-84.
[20] 汪定,马春光,翁臣,等.强健安全网络中的中间人攻击研究[J].计算机应用,2012,32(1):42-44.(WANG D, MA C G, WENG C, et al. Research of man-in-the-middle attack in robust security network [J]. Journal of Computer Applications, 2012, 32(1): 42-44.)
[21] NAYAK G N, SAMADDAR S G. Different flavours of man-in-the-middle attack, consequences and feasible solutions [C]// Proceedings of the 2010 3rd IEEE International Conference on Computer Science and Information Technology. Piscataway, NJ: IEEE, 2010, 5: 491-495.
This work is partially supported by the National Natural Science Foundation of China (61602258).
DAIChengrui, born in 1993,M.S. candidate. His research interests include network security, operating system security.
CHENWei, born in 1979, Ph. D., professor. His research interests include network security, privacy protection.
