基于FPGA的粗粒度可重构系统拓扑网络结构开发
2018-05-18史再峰周佳慧陈可鑫
庞 科,史再峰,周佳慧,陈可鑫
(1.天津大学计算机科学与技术学院,天津 30072;2. 天津大学微电子学院,天津 300072)
大数据时代的到来使得嵌入式多媒体领域对高速计算性能的需求不断提升,与此同时,传统的计算体系架构无法同时满足该领域对计算性能和灵活性的需求.兼备了通用处理器的功能多变性和专用集成电路的处理高效性的可重构计算能够有效地加速多媒体应用的处理,同时还具有低功耗和由于有限非重复性工程(non-recurring engineering,NRE)费用导致的低成本等优点,填补了通用处理器与专用集成电路之间的空白[1-2].作为动态可配置体系,可重构计算可以针对不同的应用,在“硅实现”后重新定义其计算功能.这一特征使得可重构处理器在有着高计算密度和高度灵活性的多媒体应用领域具有广阔的应用前景.
目前,各种各样的可重构体系架构相继被研究者提出[3-8].与目前最流行的可重构加速器现场可编程门阵列(field-programmable gate arrays,FPGAs)相比,CGRA由于其粗粒度和简化的数据路径,在性能和功耗效率方面具有明显的优势[8].CGRA可以与实现复杂特定应用的功能单元集成,从而实现各种不同的应用.
典型的 CGRA有 4个主要的结构参数:可重构阵列单元尺寸、单元间互连拓扑网络结构、本地存储结构以及可重构单元的配置法.其中,拓扑结构为不同应用实现提供了灵活而有效地映射方式,并对系统的性能、面积和功耗有着不可忽略的影响.一方面,灵活的互连拓扑网络结构可以简化可重构单元间复杂而频繁的数据交互,降低不同应用在 CGRA系统上映射的复杂度,为可重构单元提供权衡而精准的分布及互连,从而改善系统性能,有效地减少面积、降低功耗;另一方面,对系统互连拓扑网络结构有着很大依赖性的资源占用率也对系统的功耗有着巨大的影响.在45,nm CMOS工艺下,动态可配置嵌入式系统架构的互连功耗占到总功耗的50%,~60%[9].
目前已经被研究者提出的互连拓扑网络结构已有几十种,主要分为静态拓扑结构和动态拓扑结构[7,,10]两种.其中,绝大多数是静态拓扑,如网格型拓扑(mesh)和环形拓扑(Torus)[6,,11-13].与动态拓扑结构相比,尽管基于 mesh架构的静态拓扑会加大资源和面积的开销,但它执行简单且无延迟,使得静态拓扑在绝大多数的 CGRA架构中被采用.每一种拓扑结构都有其优势和不足.针对于某一种特定的应用,哪种拓扑结构更优很难一概而论.因此,在CGRA应用系统设计中,对系统的互连拓扑网络结构进行评估和开发也就变得格外重要.因此,在 CGRA系统开发中,应仔细地衡量时序、面积以及功耗,从而为不同的应用选择最适宜的互连拓扑网络结构.
在 CGRA的设计空间开发研究领域,一些关于CGRA系统及其互连拓扑网络结构开发的研究已经在进行.被报道的大多数设计空间开发平台都是基于动态可重构嵌入式系统架构的[12-13],这一架构目前被作为 CGRA系统架构的主流架构模板.基于这一模板,文献[13]提出了进行可重构单元开发的开发平台.文献[14-15]则提出了 CGRA的互连功耗模型.文献[16]针对粗粒度可重构计算在重构粒度、可重构性记忆互连网络等方面进行了硬件开发,并对功耗及可扩展性等相关特性展开讨论.
在以上这些文献中,对 CGRA系统及互连拓扑网络结构的开发都只是进行了软件仿真.与软件仿真相比,基于 FPGA的硬件验证平台可以为多核系统的开发提供更合理、更准确的途径,可以以更快的速度为设计者提供更可靠的验证结果[17].
本文提出了一种基于 FPGA的粗粒度可重构系统架构的硬件验证平台及相应的互连拓扑网络结构开发流程.根据该流程,设计者可以基于 FPGA开发板自动地搭建一个可重构出具有不同拓扑网络互连的 CGRA系统,并在此基础上,根据不同应用的特性,对不同的互连拓扑网络结构及其配置方法进行性能验证和开发.通过将验证结果与设计要求进行对比,设计者可以迅速确定针对特定应用的最适宜的互连拓扑网络结构.该开发流程可适用于同构或异构的CGRA系统架构及任何静态拓扑结构.
1 基于FPGA的CGRA系统硬件验证平台
1.1 平台系统架构
本文所提出的 CGRA硬件验证平台主要是基于Morphosys系统架构建立的.与典型的 CGRA系统[18]一样,该平台系统包括一个主控制器、一个可重构单元阵列、阵列控制单元(又称为阵列控制器)和两个片上共享存储单元.可重构单元(reconfigurable cell,RC)按照一定的互连拓扑网络结构彼此互连在一起,如图 1所示.主控制器将配置包和初始数据发送给验证平台.根据配置包中的配置信息,验证平台可自动实现特定的应用并为设计者提供准确的验证结果.
1.1.1 可重构单元RC
在所搭建的 CGRA系统硬件平台中,每一个可重构单元都由一个算术逻辑单元(ALU)、一个移位器、两个多路选择器、一个输出寄存器、一个寄存器阵列及一个配置存储器构成,如图2所示.
通过存储在配置存储器里的配置字可以对可重构单元进行配置,实现系统功能和互连的重构.在每个内核执行之初,配置存储器将配置字发送到每一个可重构单元RC的配置寄存器.一旦拓扑互连网络被重构,可重构单元之间则由按照一定规则连接的路由器阵列来进行数据交互.
1)基本计算单元
ALU单元包括一个乘法器、一个加法器和一个减法器.所有计算单元的输入和输出数据宽度均为32,bit.ALU单元可执行 4种运算:乘法、加法、减法以及数据转移(数据直接从输入端传输到输出端,不做其他处理).利用数据转移这一操作,2个RC之间可以不直接互连而是通过其他的 RC作介质获得之前内核的输出.
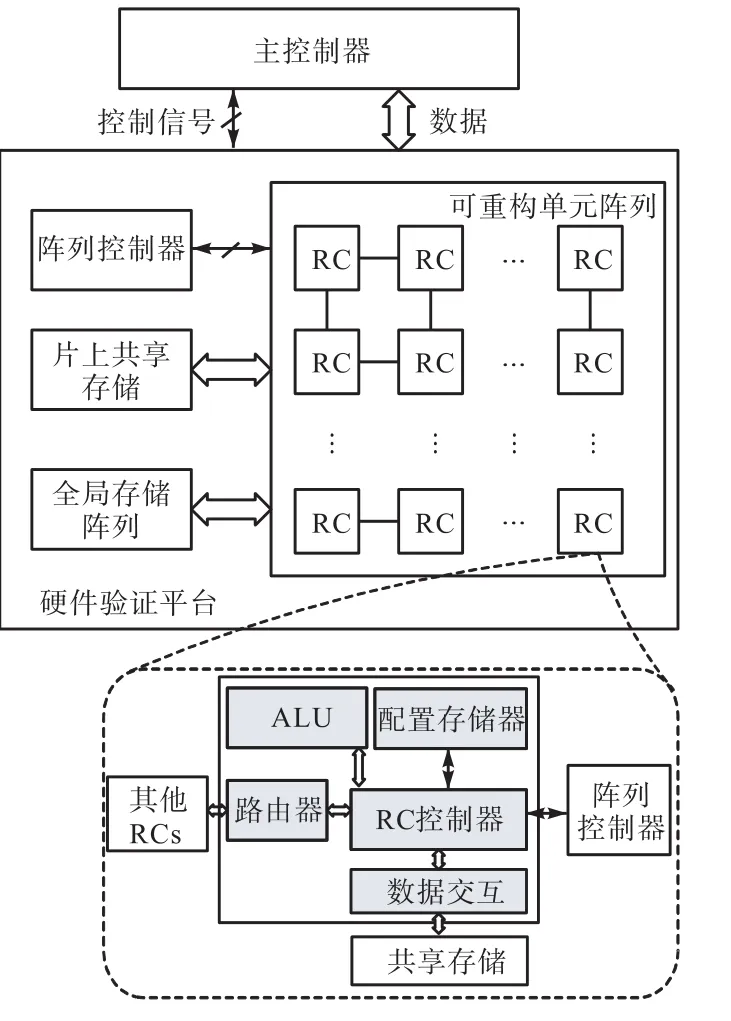
图1 基于 FPGA的粗粒度可重构系统验证平台基本架构Fig.1 Basic structure of CGRA emulation platform based on FPGA
ALU中的移位寄存器可实现数学逻辑左移和逻辑右移两种操作.
2个多路选择器可以根据配置字中的控制位为ALU从多个输入源中选出所需的输入数据.2个多路选择器的输入源有 4个:①该 RC本身的输出;②该RC的寄存器阵列;③其他RC;④外部片上共享存储.在所提出的验证平台系统中,这 2个多路选择器各有一个共享存储输入.如果多路选择器的当前输入来自共享存储,则该RC会发出请求信号并等待应答.

图2 可重构单元RC的基本结构Fig.2 Basic structure of reconfigurable cell RC
2)配置寄存器
配置寄存器主要是用来存储每一个可重构单元RC的配置字.与Morphosys中每一个RC都有一个配置存储器不同,所提出的平台中,可重构阵列中的每一个 RC都配有一个配置寄存器.通过配置寄存器,RC可以更快速地获取配置字.其中,寄存器最低2位[1∶0]是ALU配置位,说明了当前ALU单元需执行的功能;位[9∶2]和[17∶10]分别是输入 1和输入2配置位,用来控制2个多路选择器的选择,即为ALU单元选择两个输入变量;位[26∶18]表示的是输出配置位,用来控制输出结果的去向;[32∶27]描述的是移位寄存器配置位,用来控制当前移位寄存器的执行.配置字的具体描述如表1所示.
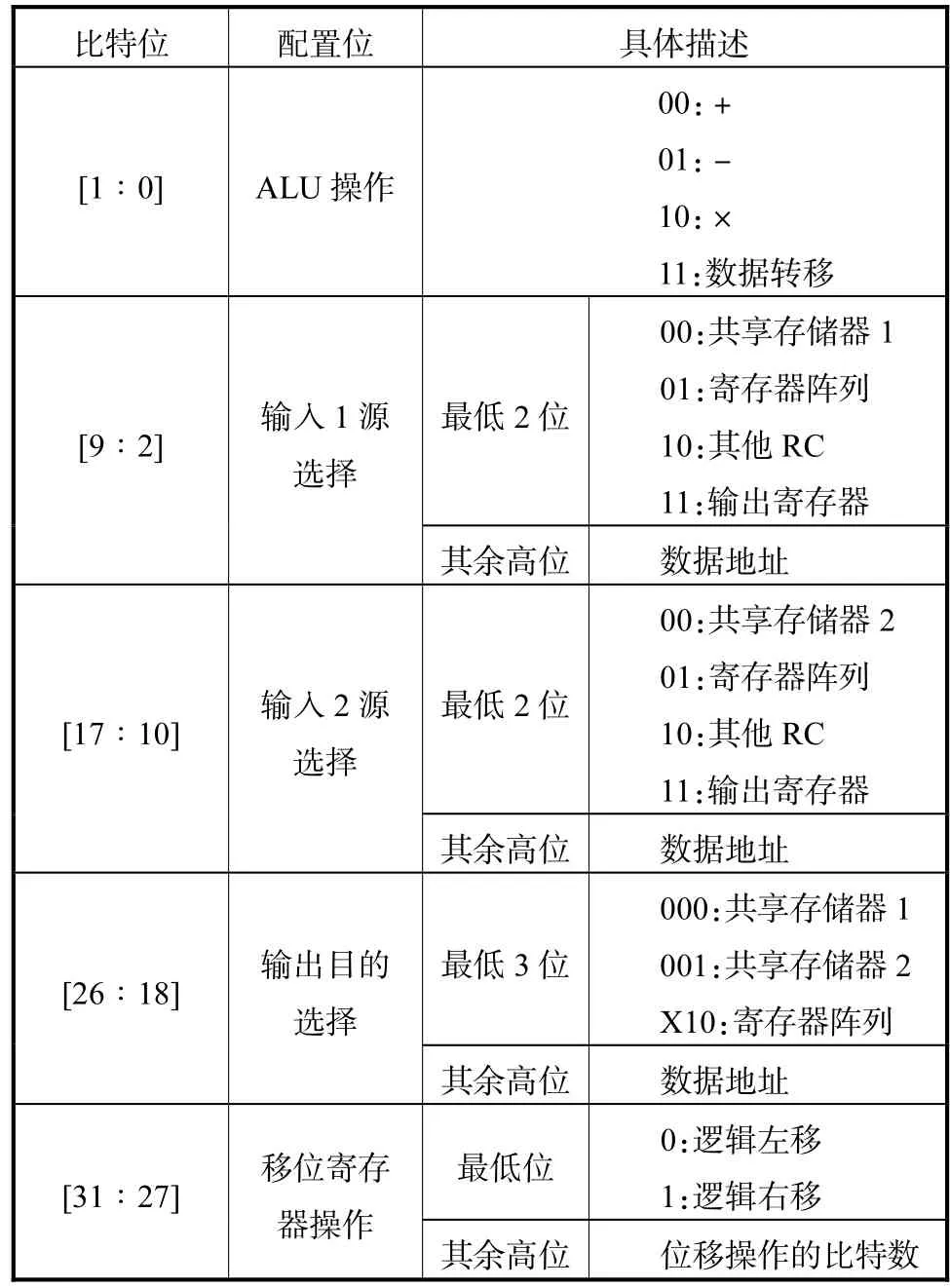
表1 可重构单元配置字的具体描述Tab.1 Detailed description of the context word of reconfigurable cell
3)路由器单元
可重构单元中的路由器单元结构如图3所示.
每一个路由器都由 5个多路选择器(MUX)构成,而每个多路选择器则根据配置字中对应控制位来选择输入.在路由单元中,共有 5个输入和输出端口,这 5个端口分别与 RC本身(P)以及与它互连的4个相邻 RC 单元(上 U、下 D、左 L以及右 R)相连.多路选择器可以选择任何一个输入直接输出.路由单元对应的配置字由10,bit二进制数字构成,设计者可通过配置字对互连网络的拓扑结构进行配置重构.

图3 路由器单元基本结构Fig.3 Basic structure of router cell
1.1.2 可重构阵列控制单元及片上共享存储
在 CGRA验证平台中,可重构单元阵列有一个控制单元,它主要用来同步阵列中所有的可重构单元.该控制单元可以发送“开始”信号并接受“结束”信号,从而同步调用整个可重构阵列.
在所提出的 CGRA验证平台系统中,共有 2个片上共享存储器来保存初始数据、中间结果以及最终结果.在每一个共享存储器中,都有一个仲裁装置根据预设的优先级来对来自整个可重构阵列的请求进行应答.在该验证平台上,可重构单元 RC_1~RC_16,其预设的优先级逐次递减.可重构单元的请求可以是读请求也可以是写请求.当所有的请求都是来自同一地址(即同一个 RC)的读请求,仲裁器则会对数据进行帧传送处理.
1.2 互连拓扑网络结构
CGRA的模块化特性使得该应用系统的参数化架构可以从一个模板构造而来.该模板就是互连拓扑网络结构(简称拓扑结构).本文所提出的硬件验证平台以几种经典拓扑结构为模板,在此基础上构建不同的CGRA系统架构.
1.2.1 网格型拓扑和环形拓扑
网格型拓扑和环形拓扑在片上网络和可重构处理架构中都是最经典的拓扑结构.如图 4(a)所示,二维网格型拓扑(2D mesh)因其结构简单、易实现而被广泛采用.在 mesh拓扑结构的基础上,环形拓扑(Torus)在边缘 RC之间添加互连以形成环形网格结构,如图4(b)所示.
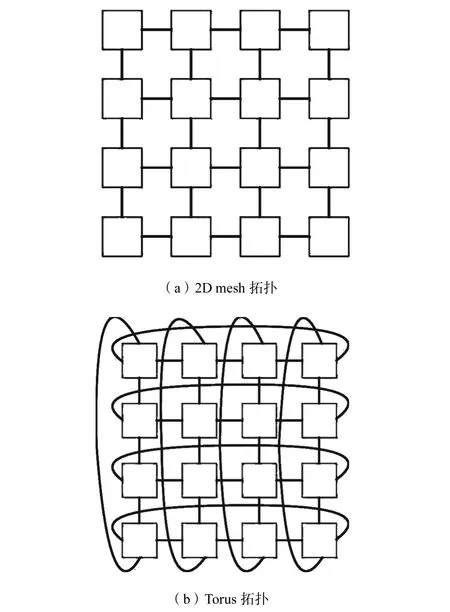
图4 2D mesh和Torus拓扑结构Fig.4 2D mesh and Torus interconnection network topology
1.2.2 完全行列互连网络拓扑(CRC)
图 5所示的完全行列互连网络拓扑结构是一个具有4行4列可重构互连拓扑阵列,每一个RC都可以与同行和同列的其他 RC直接交互数据.与 2D mesh和 Torus拓扑结构相比,这一拓扑结构可以更好地满足密集计算型算法的要求,但同时也要消耗更多的面积和功耗.

图5 完全行列互连网络拓扑结构Fig.5 Complete row and column interconnection network topology
1.2.3 完全行列及对角互连网络拓扑(CRCD)
这一拓扑结构为可重构阵列提供了完全的行、列及对角互连,从最大程度上保证了位于同行或同列或对角位置的RC之间进行直接数据交互.图6给出了一个 4×4完全行列及对角互连可重构阵列,每一个RC都与周围10个相邻RC互连.与前面介绍的3种拓扑结构相比,该拓扑结构丰富的互连资源使得应用在可重构阵列上的映射更加简单.
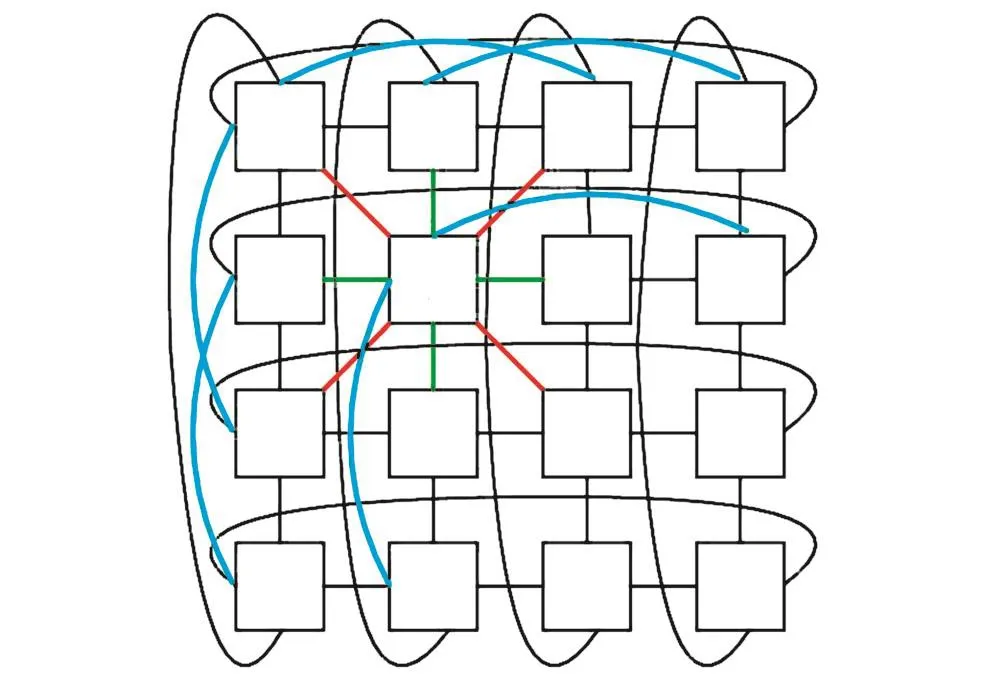
图6 完全行列及对角互连网络拓扑结构Fig.6 Complete row,column and diagonal interconnection network topology
1.2.4 完全路由互连网络拓扑(CRIN)
在这种拓扑结构中,每2个RC之间都可以通过一个路由器进行互连,如图 7所示.该拓扑结构借助路由器之间的灵活互连,可在减少互连线路的前提下实现整个阵列的全互连.这一拓扑结构,在大大降低了互连复杂度的同时保证了阵列全互连的高效性.

图7 完全路由互连网络拓扑结构Fig.7 Complete router interconnection network topology
目前,CGRA系统架构中可以进行完全互连的方法有很多,例如,与 FPGA类似的数据总线、多级互连网络、片上网络和可重构互连拓扑网络结构.其中,在数据总线、多级互连网络和片上网络上进行数据传输时都可能会出现数据通路拥塞,设计者必须仔细考察整个系统的传输延迟和功耗.与前三者相比,可重构互连拓扑网络结构可以确保数据传输的准确性,并精准地控制传输延迟,因此,本文采用可重构互连拓扑网络结构作为整个系统的互连结构.
1.3 可重构单元阵列配置
针对某一特定应用,所提出的 CGRA系统硬件验证平台可根据配置信息自动地插入所需的验证模块及模块间的拓扑互连网络,生成基于某一互连拓扑网络结构的 CGRA验证系统.不同的应用所需的验证模块及所生成的互连拓扑网络结构也是截然不同的.设计者可以根据应用的特性及设计的要求对验证系统进行配置重构,根据来自主控制器的配置信息,可重构阵列可在不同的拓扑互连下执行不同的计算功能,进而实现相应的特定应用.因此,对于不同的应用而言,由设计者提供的配置信息也是至关重要的.
每一个内核都对应着应用某一个阶段的实现.在每一个内核执行期间,不同的 RC在同一机器周期内执行不同的运算,而每一个机器周期执行结束,系统都会对所有的 RC进行同步,以防止数据交互错误的发生,如图8所示.
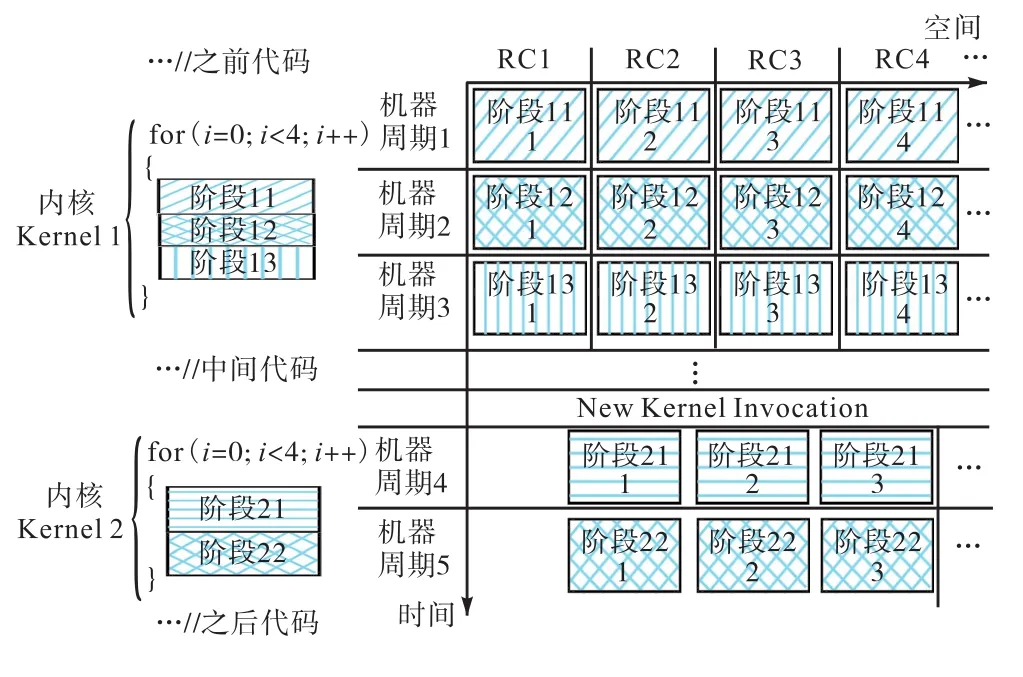
图8 可重构阵列的配置和执行周期Fig.8 Configuration and execution period of reconfigurable cell array
综上所述,本文所提出的基于 FPGA的 CGRA系统硬件验证平台可以为评估 CGRA应用系统提供可靠而高效的验证平台.在此基础上,设计者可以针对不同的特定应用,对不同的互连拓扑网络结构进行验证评估,从而挑选出最符合设计需求的最适宜的CGRA应用系统互连拓扑网络结构.
2 CGRA互连拓扑网络架构开发流程
在第 1节中,本文详细介绍了基于 FPGA的CGRA系统硬件验证平台的基本架构.基于该硬件验证平台,本文进一步提出了一个 CGRA系统互连拓扑网络结构的开发流程.
如图9所示,在互连拓扑网络结构开发的第1阶段,设计者需要通过分析特定应用的特性生成该应用的数据流程图(data flow graph,DFG).根据所产生的DFG,设计者可以选择一个或多个拓扑结构作为备选的拓扑结构,逐一产生对应的应用映射方案,并将所产生的应用映射方案以配置信息的方式输入 CGRA系统硬件验证平台.输入的应用映射方案将为验证平台提供可重构单元之间的互连信息及各个 RC相应的配置信息.
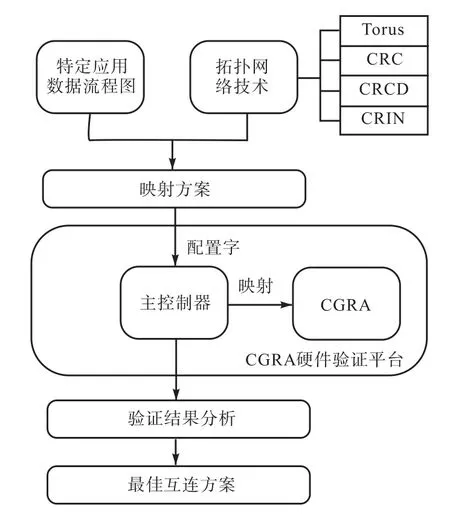
图9 CGRA互连拓扑网络结构开发流程Fig.9 Network topology exploration flow of CGRA based on emulation platform
在开发的第 2阶段,根据输入的配置信息,该验证平台将自动重构可重构单元之间的互连关系,生成所需要的互连拓扑网络,并将指令字发送给所有的可重构单元,从而构建出所需的CGRA系统架构,以实现所需的特定应用.
CGRA系统互连拓扑网络结构开发的最后一个阶段是针对不同的拓扑互连策略,对所生产的CGRA应用系统架构进行性能评估.其中,时序性能评估的指标是各个 RC的执行机器周期.与此同时,根据不同的互连方案,实现该应用系统所需的 FPGA资源也将被统计出来,对基于不同拓扑结构的 CGRA系统 FPGA资源占用率进行对比.基于各个拓扑互连策略的系统功耗主要由两部分组成:RC的瞬态功耗和系统的互连动态功耗.
不同的特定应用有着不同的设计要求.基于CGRA系统硬件验证平台的互连拓扑网络结构开发流程可以为 CGRA系统的不同拓扑互连策略提供准确而快速的性能分析.通过对比所分析的结果,设计者可以选出最适宜的 CGRA互连拓扑网络结构以满足特定应用的特殊要求.
3 实验和分析
本文进行了两组实验来验证所提出的基于FPGA的 CGRA系统硬件验证平台及对应的互连拓扑网络结构开发流程.第 1组实验主要是对比第1.2节中所介绍的拓扑结构的 FPGA资源占用率,通过在所提出的验证平台上实时重构不同的互连拓扑网络结构并对系统的资源占有率进行对比,可以有效地验证所提出的 CGRA系统硬件验证平台的高效性.第 2组实验是在验证平台的基础上,对所提出的CGRA互连拓扑网络结构开发流程进行验证评估.针对不同应用,对不同互连拓扑网络结构的性能进行有针对性的评估,从而验证该开发流程的有效性和可靠性.
在本文中,CGRA系统硬件验证平台是基于Xilinx Virtex 5 ML506 FPGA开发板而实现的.所选择的可重构阵列为最具代表性的 4×4阵列.验证平台的系统主时钟为 66,MHz,最大有限带宽可达到62.94,MByte/s.虽然所实现的 CGRA应用系统均为同构架构,但该硬件验证平台的开发理念及互连拓扑网络结构的开发流程均可适用于异构 CGRA系统的设计开发.
3.1 不同拓扑结构的FPGA资源占用率评估
在这组实验中,基于CGRA系统硬件验证平台,将对 4种拓扑结构进行资源占用率的评估.这 4种拓扑结构分别是环形拓扑结构(Torus)、完全行列互连网络拓扑结构(CRC)、完全行列及对角互连网络拓扑结构(CRCD)和完全路由互连网络拓扑结构(CRIN).这 4种拓扑结构目前被广泛应用于经典的CGRA系统架构中,因此本实验中采用这4种拓扑结构进行评估.
图10描绘了采用这4种拓扑结构作为互连拓扑网络结构的 CGRA系统所占用的 FPGA资源,主要包括所占用的查找表(LUT)、寄存器(register)、块存储器(block RAM)、占用的片(occupied slice)、输入输出端口(bonded IOB)、缓存器(BUFG)、数字信号处理器(DSP48Es)以及边界扫描链(BSCAN)等的数量.

图10 不同拓扑结构的FPGA资源占用率评估Fig.10 Occupancy rate evaluation of FPGA resources for different network topologies
在图 11中,进一步分析了不同拓扑结构下所占用的查找表 LUT和寄存器的数量.从图中可以看出,查找表的占用率随着互连线的增多而增加.在基于 2D mesh结构的前 3种拓扑结构中,查找表的占用率随着互连线的增加几乎呈线性增长.在CRIN拓扑结构中,查找表的数量只比 Torus拓扑结构略有增加,这主要是因为CRIN拓扑结构中的路由器之间的连线与 Torus拓扑结构基本相等,增加的连线主要在路由器的内部.在图 11中,前 3种拓扑结构所占用的寄存器数量基本相同,而CRIN由于在路由器内部包含了配置字寄存器而使得其寄存器的占用率远远高于前3种拓扑结构.

图11 不同拓扑结构所占用的查找表和寄存器数量Fig.11 Amount of LUTs and registers for different network topologies
通过第 1组实验,可以很容易看出,不同拓扑结构对于 FPGA资源的占用是截然不同的,相对来说,结构越简单的拓扑结构其所占用的资源也越少,但同时,它所能提供的互连方式也就越有限制.
3.2 基于CGRA系统硬件验证平台的实际应用评估
在本组实验中,两个实际应用被选中来进一步验证所提出的 CGRA系统硬件验证平台和对应互连拓扑网络结构开发流程.这两个应用分别是 4×4蝶形余弦变化(4×4,DCT)和 32点快速傅里叶变换(32-point FFT).这两个应用都是图像处理中最经典的测试基准应用,可以为验证平台及其开发流程的评估提供有效而可靠的评估结果.
按照所提出的互连拓扑网络结构开发流程,首先需要生成应用的数据流程图DFG.基于DCT和FFT的蝶形映射图,图12和图13分别给出了这两个应用的基于可重构阵列的数据配置执行流程图(应用映射图).其中,由于所采用的是 4×4可重构阵列,因此32点 FFT的前16点先被配置执行,然后余下的 16点可利用片上共享存储所保留的中间结果以同样的方式再进行配置执行.在本文中,DCT和 FFT均采用定点运算来实现,从而加快系统的执行速度并降低系统的实现难度,因此需要采用移位运算来实现其小数部分的计算.当需要在两个非互连的RC之间进行数据交换,中间的可重构单元可采用“数据转移”操作将数据不做任何处理而进行传输.
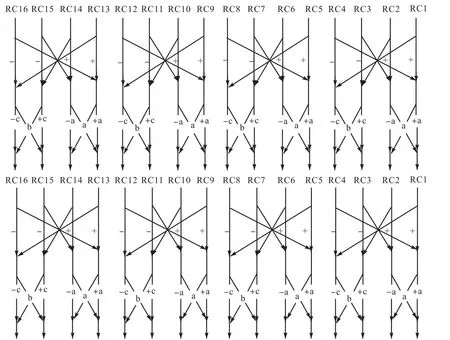
图12 4×4,DCT蝶形映射图Fig.12 Butterfly mapping graph of 4×4,DCT

图13 32点FFT蝶形映射图Fig.13 Butterfly mapping graph of 32-point FFT
图14描绘了DDT和FFT在基于不同互连拓扑网络结构的 CGRA应用系统上进行实现而所需的执行机器周期数.从图中可以看到,对DCT而言,不同的拓扑结构其所需的执行机器周期几乎相等.这是由于 DCT的数据交互只存在于相邻的 4个 RC之间.因此,对于这 4种拓扑结构,其数据交互的途径基本相同,所导致的执行机器周期也基本相同.与DCT不同,FFT的执行需要在同行或同列的 RC之间进行数据交互.在这种情况下,CRC、CRCD和CRIN拓扑结构都可以有效地在同行以及同列的 RC之间进行直接的数据交互,所以其执行机器周期明显少于Torus拓扑结构.

图14 不同拓扑结构下 4×4,DCT和 32点 FFT的执行机器周期Fig.14 Number of machine cycles for 4×4,DCT and 32-point FFT with different network topologies
图 15描绘了这两个应用在 CGRA应用系统上实现所消耗的系统功耗.系统功耗的评估结果是采用 Xilinx ISE 13.4中的 XPower工具进行统计评估的.该工具主要是提取构建系统架构的逻辑单元的功耗而并不考虑互连功耗,因此,由 XPower提供的系统功耗并不完全准确.
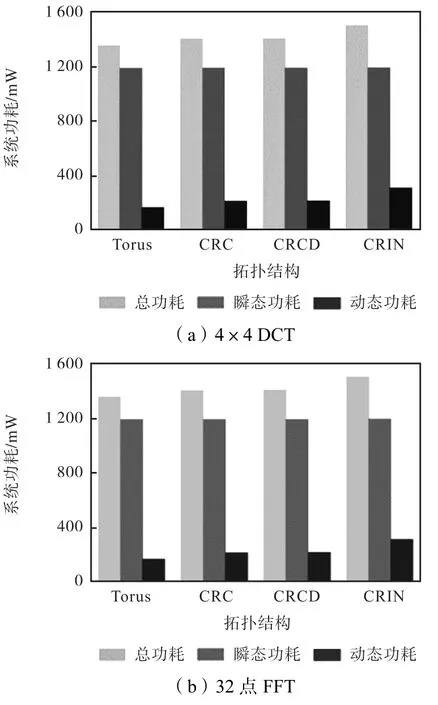
图15 不同拓扑结构下4×4,DCT和32点FFT的系统功耗Fig.15 Energy consumption for 4×4,DCT and 32-point FFT with different network topologies
但是,从图 15中可以看到,瞬态功耗在不同拓扑结构之间的变化很小,因此,从一定程度上来说,由 XPower所产生的功耗报告可以反映出不同拓扑结构所带来的系统功耗的变化,进而可以为设计者提供系统架构设计的参考.对于系统架构中互连网络的资源占用率和功耗的评估,设计者可以通过互连线的数量对不同工艺下的不同拓扑结构进行理论分析.表2列出了不同拓扑结构下所需的互连线数目.

表2 不同拓扑结构互连线的数量Tab.2 Numbers of interconnecting lines for different network topologies
根据第 2组实验的评估结果,可以看出,对于具有较小中间数据依赖性的应用(如 DCT),或是对于那些对系统性能要求不高但对系统面积和功耗有着较高要求的应用而言,环形拓扑(Torus)结构被推荐来进行CGRA实现.与之相反,对于那些有着较强数据依赖性或是较严格的时序限制要求的应用而言,当它们在 CGRA系统上进行实现时,完全行列互连网络拓扑结构(CRC)或是完全路由互连网络拓扑结构(CRIN)都是很好的选择.
然而,对于特定应用而言,并不是只有一种拓扑结构可以使其 CGRA应用系统在不同的应用场合下均获得最佳的系统性能.根据特定应用的不同特性和不同性能要求,其最适宜的拓扑结构往往是不同的.利用所提出的互连拓扑网络结构开发流程,设计者可以针对不同应用,在基于 FPGA的 CGRA系统硬件验证平台上对系统的互连策略进行开发,通过衡量整个系统的性能要求,选择出该应用最适宜的互连拓扑网络结构.这样的开发辅助工具,将帮助设计者为特定应用快速地开发出最适宜的拓扑互连策略.
4 结 语
本文探讨了粗粒度可重构体系架构 CGRA设计中的一个重要问题:针对特定应用如何开发出最适宜的系统拓扑互连策略.本文提出了一个基于 FPGA的 CGRA系统硬件验证平台及对应的系统互连拓扑网络结构开发流程.所提出的验证平台和开发流程可以有效地帮助设计者在最短的时间内为特定应用找到最适宜的拓扑互连策略.
基于 FPGA开发板,所建立的 CGRA系统通过主控制器输入的配置信息重构系统的互连拓扑网络结构,搭建出可对不同互连拓扑网络结构进行验证评估的硬件验证平台.在此平台基础上,利用所提出的互连拓扑网络结构开发流程,根据 CGRA系统配置参数、应用配置信息以及不同拓扑互连策略,设计者可生成不同的系统互连方案.将所得到的系统互连方案在验证平台上进行验证评估并对验证结果进行分析,设计者便可根据设计需求找出最适宜于当前设计需求的拓扑互连策略.实验表明,基于 FPGA的CGRA系统硬件验证平台及相应的互连拓扑网络结构开发流程可以有效地帮助设计者开发出满足特定应用设计需求的最适宜的拓扑互连策略.
在本文中,所提出的应用平台仅仅可重构实现最经典的 4种拓扑结构.在今后的工作中,将进一步开发更多不同的拓扑互连策略使之更准确地适用于更多不同的应用,从而使得所提出的 CGRA系统硬件验证平台可适用于所有的拓扑结构.此外,该平台还可以添加可配置的功能,使设计者可以为特定应用定制特殊的互连拓扑网络结构.
:
[1] Cervero T,López S,Callicó G M,et al. Survey of reconfigurable architectures for multimedia applications[C]//Proceedings of SPIE,VLSI Circuits and Systems IV. Dresden,Germany,2009:363-381.
[2] Dutta H,Kissler D,Hannig F,et al. A holistic approach for tightly coupled reconfigurable parallel processors[J].Microprocessors & Microsystems,2009,33(1):53-62.
[3] Rossi D,Campi F,Spolzino S,et al. A heterogeneous digital signal processor for dynamically reconfigurable computing[J].IEEE Journal of Solid-State Circuits,2010,45(8):1615-1626.
[4] Shan Gao,Kihara T,Shimizu S,et al. A novel traffic engineering method using on-chip diorama network on dynamically reconfigurable processor DAPDNA-2[C]//International Conference on High Performance Switching and Routing. Paris,France,2009:1-6.
[5] Mei B,Sutter B D,Aa T V,et al. Implementation of acoarse-grained reconfigurable media processor for AVC decoder[J].Journal of Signal Processing Systems for Signal Image & Video Technology,2008,51(3):225-243.
[6] Vahid F,Stitt G,Lysecky R. Warp processing:Dynamic translation of binaries to FPGA circuits[J].Computer,2008,41(7):40-46.
[7] Singh H,Lee M H,Lu G,et al. MorphoSys:An integrated reconfigurable system for data-parallel and computation-intensive applications[J].IEEE Transactions on Computers,2000,49(5):465-481.
[8] Atak O,Atalar A. BilRC:An execution triggered coarse grained reconfigurable architecture[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2013,21(7):1285-1298.
[9] Ansaloni G,Bonzini P,Pozzi L. Heterogeneous coarse-grained processing elements:A template architecture for embedded processing acceleration[C]//Proceedings of the Conference on Design,Automation and Test in Europe.Nice,France,2009:542-547.
[10] Marco L,Stefania P,Pasquale C,et al. A new reconfigurable coarse-grain architecture for multimedia applications[C]//2nd NASA/ESA Conference on Adaptive Hardware and Systems. Edinburgh,UK,2007:119-126.
[11] Liang C,Huang X. SmartCell:A power-efficient reconfigurable architecture for data streaming applications[C]//IEEE Workshop on Signal Processing Systems.Washington,USA,2008:257-262.
[12] Bouwens F,Berekovic M,Kanstein A,et al. Architectural exploration of the ADRES coarse-grained reconfigurable array[C]//ARC2007:Reconfigurable Comput-ing:Architectures,Tools and Applications.Mangaratiba,Brazil,2007:1-13.
[13] Bouwens F,Berekovic M,de Sutter B,et al. Architecture enhancements for the ADRES coarse-grained reconfigurable array[C]//Proceedings of High Performance Embedded Architectures and Compilers,HiPEAC2008.Göteborg,Sweden,2008:66-81.
[14] Lambrechts A,Raghavan P,Jayapala M,et al. Energy-aware interconnect optimization for a coarse grained reconfigurable processor[C]//21st International Conference on VLSI Design. Hyderabad,India,2008:201-207.
[15] Palkovic M,Hartmann M,Allam O,et al. Time-space energy consumption modeling of dynamic reconfigurable coarse-grain array processor datapath for wireless applications[C]//2010IEEE Workshop on Signal Processing Systems(SIPS). San Francisco,CA,USA,2010:134-139.
[16] Zain-ul-Abdin,Svensson B. Evolution in architectures and programming methodologies of coarse-grained reconfigurable computing[J].Microprocessors & Microsystems,2009,33(3):161-178.
[17] Liu Yangfan,Liu Peng,Jiang Yingtao. Building a multi-FPGA-based emulation frame-work to support networks-on-chip design and verification[J].International Journal of Electronics-INT J Electron,2010,97(10):1241-1262.
[18] Taylor M B. Is dark silicon useful?:Harnessing the four horsemen of the coming dark silicon apocalypse[C]//Proceeding49th Design Automation Conference. San Francisco,CA,USA,2012:1131-1136.
