基于情感分析的商品评价模型构建研究
2018-05-17陈晓玲许钧儒
陈晓玲 褚 汉 许钧儒
(安徽财经大学,安徽 蚌埠 233030)
一、引言
随着网上购物行为的增多,商品评论数量也越来越多,评论数据的可读性与丰富性,使得评论往往成为消费者决定是否购买的标尺。由于评论数据量过于巨大,讨论的主题涉及商品的各个属性,想从大量的商品评论中整理出有用信息,是非常困难的。笔者采用情感分析方法,将海量评论中所蕴含的信息挖掘整理出来——建立基于情感分析的商品评价模型,对特定商品进行评价。
情感分析是2001年在分析股票的留言板上首次出现,作者认为,股票的走势会受到投资者的情感影响,而投资者的情感则可以通过股票留言板中的留言来提取。次年,Turney和Pang[1]分别提出了有监督学习和无监督学习的情感分类研究。
Pang(2002)认为,对文档进行分类时不必对整个文档进行研究,应该将文本分类技术用于文档中含有主观情绪的部分。Abbasi(2008)对提取特征的过程进行了改进,开发了熵加权遗传算法,通过对阿拉伯语与英语的语法句法特征分析,提取特征集,有效提高了学习的准确度,数据的准确识别达到了95%[2],这些属于有监督的机器学习。
无监督学习,也称基于词典的规则匹配,通过对特定语言的语法结构进行分析,制定规则和词典,对语句进行分析。pak(2010)等人对国外流行的推特上的内容进行情感分析表明,利用这种社交平台监控国民舆情具有可操作性,并且发现越来越多的人喜欢在这种平台表达自己情感[3]。
国内关于情感分析的研究较晚。朱嫣岚(2006)认为,词作为文章的基础单元,首先要对词的正负面做研究,进而研究出词义倾向模型。其核心思想在于相同极性的词会经常在一起出现,或者是可以相互替换[4]。张子琼等人在2010年对当时情感分析的状况进行了一个总结,论述了商品评论挖掘的经济价值,对于股票、电影和一些电子商品的商品评论中含有的褒贬义情感与商品的销量成正相关[5]。
随着电子商务的蓬勃发展,消费者迫切需要科学有效的商品评价数据指导消费。如何利用网上海量评论数据,有效地分析得出真实、准确的评价信息,成为信息科学、统计学等领域的研究热点。本文以情感分析理论为基础,侧重分析基于情感分析的商品评价模型的构建,以便对电子商务产品进行评价。
二、基于情感分析的商品评价模型构建
基于情感分析的评价,其评价指标源于大量的评论数据,数据的获取和处理是构建模型的基础。
1.数据的获取
利用python对电商评论数据进行抓取,需要在发链接请求时附带上完善的header信息即可,如图1所示。

图1 请求信息
2.数据的清洗
由于刷单行为越演越烈,数据清洗成为构建商品评价模型的重要一环。数据清洗基于二个规则,第一,每个买家每天最多在一件商品下评论一次,这是为了杜绝同一账号在同一商品下多次刷评论的行为,也是为了删除爬取过程中的重复数据。第二,从评价内容的角度,利用余弦定理,从评价内容中找出相似的文本向量,剔除极度相似的评论。
3.指标体系的建立
本文以手机为例,讨论指标体系的构建。
(1)主题模型
利用LDA(Latent Dirichlet Allocation)主题模型,我们可以从经过清洗的大量数据文本中找出潜在主题——即消费者所关心的商品属性,通过人为的判定这些主题的类别,来确定出商品的评价指标体系。
LDA模型对词语和文章的关系有着这么一种认识,即每一篇文章或者每一段文字都是由一个或者多个主题构成,每一个主题又是由特定的词组合而成。LDA的联合概率公式为:
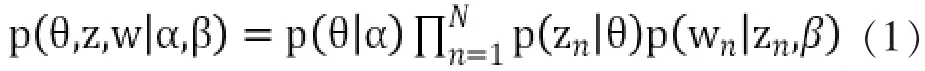
每一篇文章首先从主题分布θ中挑选出一个主题 z(p(θ|α)),同时 z对应着一个词分布 p(zn|θ),从词分布中挑选出N词语,再重新回到主题分布中挑选主题,循环K次就是一篇文章的词分布。α,β是主题分布与词分布的先验分布(狄里克雷分布)的参数。计算后验概率为

似然函数:
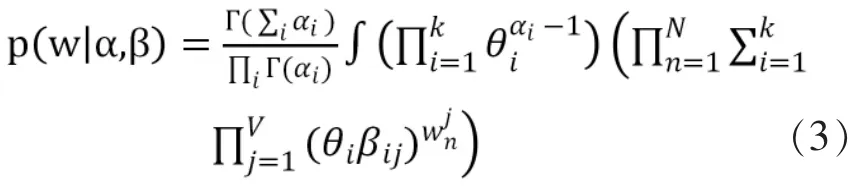
该式中含有的参数α,β是无法直接求解的,只能使用计算机进行大量的样本抽取,对后验分布进行估计。
(2)指标体系
利用主题模型,从大量评论中挑出消费者最关注的商品属性,构成评价指标体系。

表1 指标体系表
4.情感单元的抽取
情感单元包含两部分信息,情感的主体和情感。情感单元的抽取目的是将杂乱的评论变为规范的问卷式数据,一段评论可能包含多个情感单元,笔者只抽取每段评论中与最终评价指标息息相关的情感单元。
情感单元中的情感主体利用一些筛选规则即可以很快判定情感。从可实现性与高效的角度,笔者将每一条规则定为四个部分[关键词、联合词1、联合词2、互斥词]。 例如[(容量),(电),(…),(内存、存储、空间)],这样一条简单的规则,已经可以将电池容量这个主体抽取出来了,经过反复测试,笔者建立了90余条规则用于抽取情感主体。
情感单元中的情感抽取则是根据三部分决定的,情感词(褒贬义词)、程度词和转意词,如表2所示:

表2 词性标注
每一个褒贬义词都有自己的褒贬义得分,褒义词正分,贬义词负分,程度词0.8至2分,转意词-1分,每一句计算公式为:

最终的情感分还需要进行规范:

最终的抽取结果如表3所示:

表3 评论情感单元提取表
5.情感词典的扩充
尽管与前几年相比,大学新生的英语水平有了明显提高,但仍有相当一部分学生的英语水平并不足以满足ESP课程的要求。如果学习者没有一定的英语基础,ESP教学因增加了专业内容,且教学目标并不仅仅是对语言技能的训练,从而将加重这些学生的学习负担,他们会丧失英语学习的兴趣。因而,现阶段在我国高校大面积推广ESP取代EGP显然过于冒进。一个普遍接受的做法是在学习者通过大学英语四级考试以后再开展ESP教学,这样教学效果将大大提高。目前,可以在学生入学英语水平普遍较高的院校进行试点ESP取代EGP,以为下一步改革积累经验。
情感词典是帮助确定情感强弱与翻转的词典,本文使用的基础词典是hownet情感词典。“这部手机好”和“这部手机很好“这两句话都是褒义,但是“很”这个程度词就让后一句的褒义要大于前一句。由于,Hownet词典没有基于特定方向,像发烫、黑屏、卡机、自动关机这类过于专业化的词汇没有出现在词典中,需要根据研究方向进行扩充和修改词典。笔者将利用Apriori和word2vec模型对评论进行处理,找出和研究主体相关的词,再人工筛选出合适的词加入词典。利用非监督的机器学习找出行业相关的词,再人工筛选,能够有效提高词典的扩充效率与准确率。
6.评论的有效度模型
在商品的评价中,贴合消费者思维模式的评论是高质量的评论,笔者希望评论的质量越高对模型最终结果影响越大,因此,在建立商品评价模型前,就需要先建立评论的有效度模型。
在爬取的评论数据中,除了有每一条评论的文本内容,还含有一些其他信息,比如买家的昵称、等级、评论的点赞数量、回复数量和评价时间,这些信息可以代表问卷质量,表4为评论的附带信息。
表4 买家相关信息
指标都是效益型指标,我们利用熵值法确定权重,熵值法的核心公式:
计算第i个评论第j项指标的占比
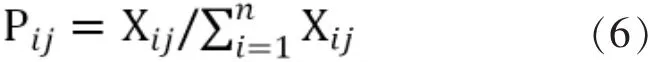
计算评论的第j项指标熵


7.商品评价模型
在选取评价模型时考虑了共性和个性两个要求:共性,评价模型将海量评论的信息总结出规律,同时又尽可能的保留更多的信息。个性,商品的同一属性可能不同的人的评价是不一样的,所以希望在最终评价时可以针对不同类型的客户,给予不同的评价结果。
模糊关系矩阵R可以解决共性问题,不仅从评论中提取出有效的信息,最终的信息是根据评论信息计算该商品属性对于非常满意、满意、一般、不太满意和非常不满意五个消费者态度的隶属度,这样的隶属度矩阵富含更多的信息。
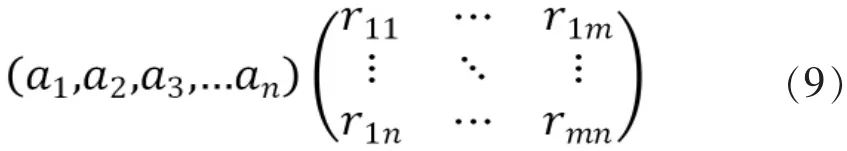
权数与关系矩阵分别代表了个性与共性,笔者很难断定两者的重要性,所以笔者更倾向选择算子值得注意的是模糊关系矩阵的构造不同于一般的计算公式,矩阵的计算与前文评论的有效度是密不可分的:
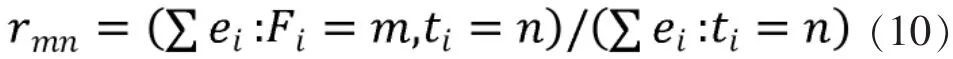
每条评论有以下几个指标,见表5

表5 隶属度指标
评价模型的构建逻辑见图2。

图2 评价模型构建逻辑
三、结论
笔者通过爬虫技术从电商网站获取评论数据,利用情感分析技术将不规则的评论数据转变成规范的问卷样式,再利用模糊数学方法建立商品评价模型,整个流程省时省力。评论数据作为评价模型的源数据,包含了非常重要的消费者体验信息,模型评价结果贴合消费者感受。研究表明,利用评价结果帮助消费者挑选商品是可行的,当拥有大量手机的模糊矩阵后,就可以在更大范围内帮助不同消费者挑选商品。
