一种基于CLB内部共享线网的高效的通用打包方法
2018-05-15来金梅
杨 钊,杨 萌,来金梅
(复旦大学 专用集成电路与系统国家重点实验室,上海 201203)
现代的现场可编程逻辑门阵列(Field Programmable Gate Array, FPGA)是由可编程逻辑块(Configurable Logic Block, CLB)、知识产权核(Intellectual Property Core, IP Core)、输入输出单元(Input/Output, I/O)和可编程互联等组成.FPGA具有电路可重配置、开发周期短、可靠性高、成本低等优点,因此广泛应用于民用通信、自动控制和信息处理等诸多领域.FPGA的计算机辅助设计(Computer Aided Design, CAD)工具流程主要包括逻辑综合、打包、布局、布线,其中打包是将逻辑综合后的网表映射到FPGA的逻辑单元中,这对布局和布线后的网表在时序、面积等方面的结果有很大的影响.
CLB是FPGA芯片中数量最多,使用最广泛的逻辑单元,它可以用于实现逻辑函数也可以用于存储数据.随着市场需求和技术的发展,CLB的功能越来越丰富,同时CLB内部的连线结构也越来越复杂,这对和CLB内部结构紧密相关的打包工具提出了更大的挑战: 如何处理复杂多变的连线结构.针对这样的挑战,文献[1]提出为逻辑块能够实现的所有电路建立模型,然后在用户网表中匹配和这些模型一致的电路并完成映射.但是该方法也存在问题: 在打包过程中,很难实现根据特定的优化目标比如面积或者时序决定打包的结果.开源CAD工具VTR[2-3]的打包阶段[4]也很好地迎接了这个挑战,它能够有效地处理逻辑块内部各种复杂的连线结构,同时避开了文献[1]中的问题,但是也引入了新的问题: 运行时间显著增长.这是因为为了能够处理逻辑块内部各种复杂的连线结构,打包阶段[4]的算法预留了很大的灵活性,同时采用耗费时间的连线合法性检查来确保映射结果在连线方面的正确性.
针对打包阶段[4]运行时间长的问题,本文中提出了一种适用范围广泛的减少运行时间的方法,该方法优先判断CLB内部的共享线网处的映射是否合法,从而避免不必要的连线合法性检查,达到减少整体运行时间的目的.把该方法集成到最新的VTR7.0[2]的打包阶段中,实验结果表明打包在运行时间方面实现了1.83倍的加速,同时输出结果在时序面积等方面的质量保持不变.
1 前期工作
和文献[4]一样,我们将用户网表中具有逻辑功能的最小单元称为atom,将FPGA中逻辑块内部具有逻辑功能的物理单元称为primitive.打包工具的功能是将atom映射到primitive上,并保证映射结果在连线结构上合法和优化时序面积等多个目标.为了能够处理逻辑块内部日益复杂的连线结构,文献[4]在已有工作[1]的基础上提出了一种能够适应FPGA上各种逻辑块内部结构的打包方法—AAPack,该方法集成在早期版本的VTR[3]的打包阶段中.AAPack打包方法采用贪婪算法和迭代方式将用户网表中的atom一个一个地映射到逻辑块内部的primitive上,同时利用和文献[5]中一致的方法确保每次映射的结果在逻辑块内部连线上是合法的,即采用pathfinder算法检查每次映射结果在连线上的合法性.但是,依赖于pathfinder算法的连线合法性检查使打包工具产生了新的问题: 运行速度相比以前的打包工具T-VPack[6]慢了至少两个数量级[7].为了解决运行速度慢引发的运行时间长的问题,文献[7]提出3种提高AAPack打包方法运行速度的方法: 首先是考虑连线结构的pin计数方法(Interconnect-aware Pin Counting): 在把atom映射到primitive的过程中,利用简单的统计pin数量的方法代替复杂的pathfinder算法,快速判断出不合法的映射结果,但是该方法只能判断出部分不合法的映射;其次是投机打包方法(Speculative Packing),在逻辑块没有满时,只采用pin计数方法确保映射结果在连线方面的合法性,在逻辑块满后,才采用pathfinder算法进行逻辑块整体的连线合法性检查;最后是预打包(Pre-packing),通过预先将固定打包在一起的atom标记为一个整体,以减少处理的网表的规模.这3种方法都已经集成到新版本的VTR7.0[2]中.实验数据[7]显示这些方法使AAPack打包方法的运行速度提升12倍,同时使打包结果在布局布线后的最小通道宽度减少20%和关键路径延时减少6%.然而,AAPack打包方法运行时间依然较长,还有必要继续考虑减少其运行时间.
2 CLB内部结构
2.1 CLB内部结构和趋势
在CLB内部结构逐渐复杂的过程中,为了同时获得输入多的查找表(Look Up Table, LUT)在延时方面的优势和输入少的LUT在面积方面的优势,引入了可拆分查找表(Fracturable Look Up Table, F-LUT)[8].F-LUT有2种配置模式,即可以用于实现1个输入多的LUT,也可以用于实现2个输入少的LUT.图1(a)是包含F-LUT的CLB的结构示意图,它由crossbar和1组可拆分逻辑单元(Fracturable Logic Element, F-LE)构成,同时图1(b)表示的是F-LE的内部结构,它由1个F-LUT和2个可以被旁路的触发器(Flip Flop, FF)构成.Crossbar提供局部的连接关系,连接F-LE的输出反馈和CLB的输入到F-LE的输入.
图2显示了图1(b)中F-LUT的2种配置模式: 图2(a)表示的是配置为1个6-LUT,用到6个输入和1个输出O6;图2(b)表示的是配置为2个5-LUT,用到5个共享的输入和2个输出O5、O6.在打包的过程中可以根据需要配置F-LUT为哪一种模式.
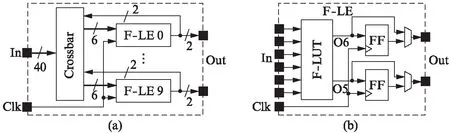
图1 CLB结构示意图Fig.1 Diagram of CLB architecture

图2 F-LUT的2种配置模式Fig.2 Two modes of F-LUT
目前,F-LUT结构被广泛应用于商业FPGA中,比如Xilinx的Virtex5,Virtex6,Virtex7,Altera公司的Stratix Ⅳ,Stratix Ⅴ.可以看出,在FPGA硬件结构逐渐复杂的趋势中,F-LUT因其独有的特点和优势受到商业FPGA的青睐.
2.2 CLB内部的共享线网
CLB内部的连线结构有多种特点,但是这里我们只讲解和减少运行时间相关的特点—共享线网.随着CLB的内部结构越来越复杂,特别是F-LUT的引入,共享线网特征变得越来越明显,如图2(b)中的2个5-LUT共享5条线网.在打包过程中,为了减少打包结果用到的CLB的数量,会尽可能将F-LUT配置为图2(b)的共享线网的模式,这使得CLB内部的连线结构复杂化,大大增加了打包工具处理过程中映射不合法的概率.
3 利用共享线网减少运行时间的方法

图3 将atom打包到CLB部分的伪代码Fig.3 Pseudo code of packing atom to CLB
检查映射结果在CLB内部连线结构上是否合法是打包工具中很重要的一步,同时也是很耗费时间的一步[7].然而,CLB内部共享线网的存在大大增加了打包过程中映射不合法的概率,使得连线合法性检查失败的次数大大增加,增加了打包工具的运行时间.于是,我们从共享线网自身的特点出发,考虑减少打包运行时间的方法.如果CLB内部整体的连线合法性检查通过,则映射在局部共享线网的地方连线是合法的;反过来,如果映射在局部共享线网的地方连线是不合法的,则整体的连线合法性检查必定会失败.于是,我们考虑利用共享线网快速判断出不合法的映射,从而避免检查结果是失败的连线合法性检查,达到减少连线合法性检查次数的目的,进而减少打包工具整体的运行时间.
图3~图5是我们减少运行时间方法的伪代码.图3是将名字为c的atom映射到名字为B的CLB中的函数模块的伪代码,我们在AAPack[4]中对应函数模块的基础上添加了利用共享线网减少运行时间的方法.具体添加2个函数模块: 在进行CLB整体的连线合法性检查(图3第4行)前,添加判断映射在局部共享线网处的连线是否合法的函数模块(图3第3行);更新primitive约束的函数模块(图3第7行).图4是更新primitive约束的函数模块的详细伪代码,图5是判断共享线网的地方连线是否合法的详细伪代码.

图4 更新primitive约束部分的伪代码Fig.4 Pseudo code of updating constrains of primitive

图5 Primitive的约束满足性判断部分的伪代码Fig.5 Pseudo code of satisfing constraints of primitive
利用共享线网特点减少运行时间的方法分为两部分: 第一部分,更新primitive的约束,每一条约束都记录着一条被共享的线网的信息.刚创建好的CLB内部的primitive约束为零,当尝试把一个atom映射到primitive上而连线合法性检查失败时,我们就认为该primitive与其他primitive共享的线网已经被占用,我们把与该线网相关的信息记录下来保存在primitive上,作为primitive的约束信息.图4展示了更新名字为p的primitive约束信息的详细过程,先清空p的全部约束信息,然后遍历p的输入输出pin,把和其他primitive共享并且已经被先打包的atom占用的线网信息记录下来作为一条约束.另外,当primitive的多个pin在逻辑上等效时,需要将多个pin上的net信息记录在一条约束中考虑,比如LUT的输入pin.第二部分,判断是否满足约束.当把atom映射到含有约束的primitive上时,优先判断atom是否满足primitive的约束,如果不满足约束,则意味着映射在连线结构上将会不合法,就不必进行随后的连线合法性检查;如果满足约束,则映射在连线结构上可能合法也可能不合法,还需要进行后面的连线合法性检查.判断的具体过程如图5的伪代码所示,遍历名字为p的primitive的每一条约束,根据约束记录的线网的信息恢复共享线网的地方,然后判断该名字为c的atom需要的线网资源是否超过了该处线网能够提供的资源,若超过了则不满足,若没有超过则满足.
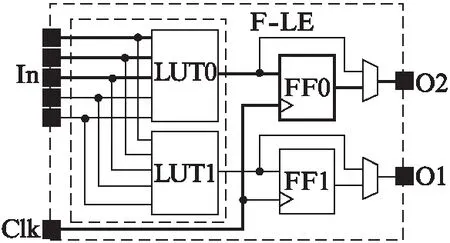
图6 部分打包的F-LEFig.6 Partial packed F-LE
举例说明,图6表示CLB中一个已经完成部分打包的F-LE,F-LE中的F-LUT配置为2个5-LUT类别的primitive,分别是LUT0和LUT1.图中粗线表示已经完成打包的primitive和被占用的线网资源.然后把LUT类别的atom映射到LUT1上并且进行CLB内部的连线合法性检查,如果检查失败,我们就把连线合法性检查过程中与LUT1有关的信息保存在LUT1上,包括LUT1与LUT0共享的且已经被占用的3条线网的实际名字、3条线网与LUT1相连的pin的名字.当下一次尝试把新的LUT类别的atom打包到LUT1上时,我们根据前面保存的线网信息恢复共享线网的位置,优先判断新的LUT能否满足该处线网资源的限制(即LUT1中剩余的未占用的线网能否满足atom的输入需要的线网数),如果满足,则进入随后针对整个CLB的连线合法性检查,如果不满足,意味着共享线网地方的连线将不合法,则不用再进行随后的整个CLB的连线合法性检查,从而减少连线合法性检查的次数,进而减少整体的运行时间.
4 实验数据与结果
本节测试了利用共享线网减少运行时间方法对打包工具运行时间和布局布线后输出结果质量的影响.我们采用的测试平台是VTR7.0[2,9].我们把在VTR7.0上集成了利用共享线网减少运行时间的打包算法称为S-AAPack,把VTR7.0中原本的打包算法称为AAPack7.0.为了简化处理过程,在建立primitive的约束时,我们只考虑了与输入pin共享的线网,没有考虑与输出pin共享的线网.
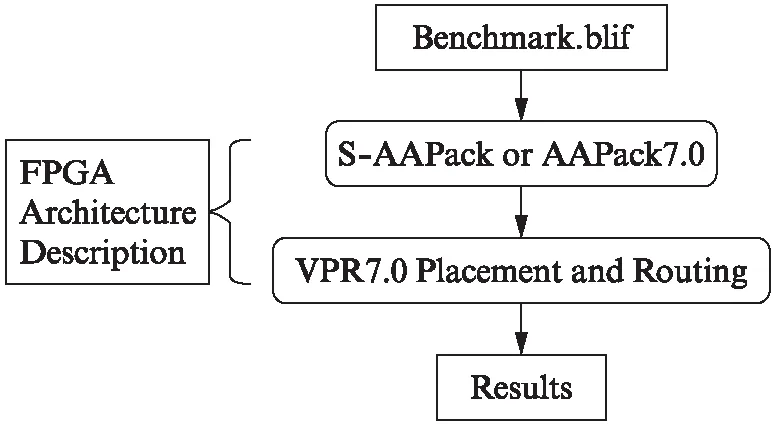
图7 测试所用CAD流程Fig.7 The experimental CAD flow
4.1 实验的建立
我们采用的CAD流程如图7所示.该流程的输入文件包括逻辑综合后的blif格式的测试例子和FPGA的硬件结构描述文件.先采用S-AAPack或者AAPack7.0完成打包,然后采用VPR7.0的布局和布线工具完成布局和布线,最后统计打包阶段的运行时间和布线后输出结果中与面积、延时相关的信息.VPR7.0的设置都采用默认值[10].
我们采用了和文献[7]一致的测试例子和FPGA结构描述文件,这些测试例子和文件可以在VTR7.0[2,9]的工程中获得.这些测试例子来自于一系列不同的应用场景包括计算机视觉、医疗、数学等,同时其规模覆盖范围广泛.FPGA硬件结构文件的名字是k6_frac_N10_frac_chain_mem32K_40nm,包含的CLB是从Altera Stratix Ⅳ[11]FPGA简化而来.CLB内部的具体结构如图1和图2所示.
测试采用的计算机是Intel i7-4790k处理器,运行频率为4.00GHz.每个处理器包含4核,有4×256KB的二级缓存.机器上共有16GB的内存.
4.2 实验数据和比较
我们统计的数据包括打包阶段的运行时间、打包输出结果中和最终面积紧密相关的CLB数量,及布局布线后输出结果的最小通道宽度、逻辑块间需要布线的线网数量、与时序相关的关键路径延时.
表1展示的是用测试CAD流程获得的19个测试例子的数据结果,这些例子的运行时间从零点几秒到上百秒,占用CLB的数量从几十到上千个,显示了测试例子的规模变化范围广.表2展示的是AAPack7.0的测试结果与S-AAPack的测试结果的比值(RAAPack7.0/S-AAPack).可以看出,在打包阶段的运行时间方面,S-AAPack比AAPack7.0快1.83倍,而在CLB数量、通道宽度、外部线网数量和关键路径延时方面,S-AAPack和AAPack7.0的比值为1.00,说明两者保持一致.我们进一步用自动化程序比对了19个测试例子用两种方法处理后输出的网表文件,发现两者是一致的,这说明在功能方面S-AAPack处理后的结果也和AAPack7.0处理后的结果保持一致.表2反映的结果是符合预期的,因为利用共享线网减少运行时间的方法,只是快速判断出不合法的映射,避免进行耗费时间的连线合法性检查,这并不影响打包过程中atom到primitive的映射过程,进而不改变打包的输出结果,最后也不改变布局布线后网表在面积、时序等方面的结果.总结下来,利用共享线网减少运行时间的方法具有优越性: 只减少打包工具的运行时间,不改变打包工具的输出结果.
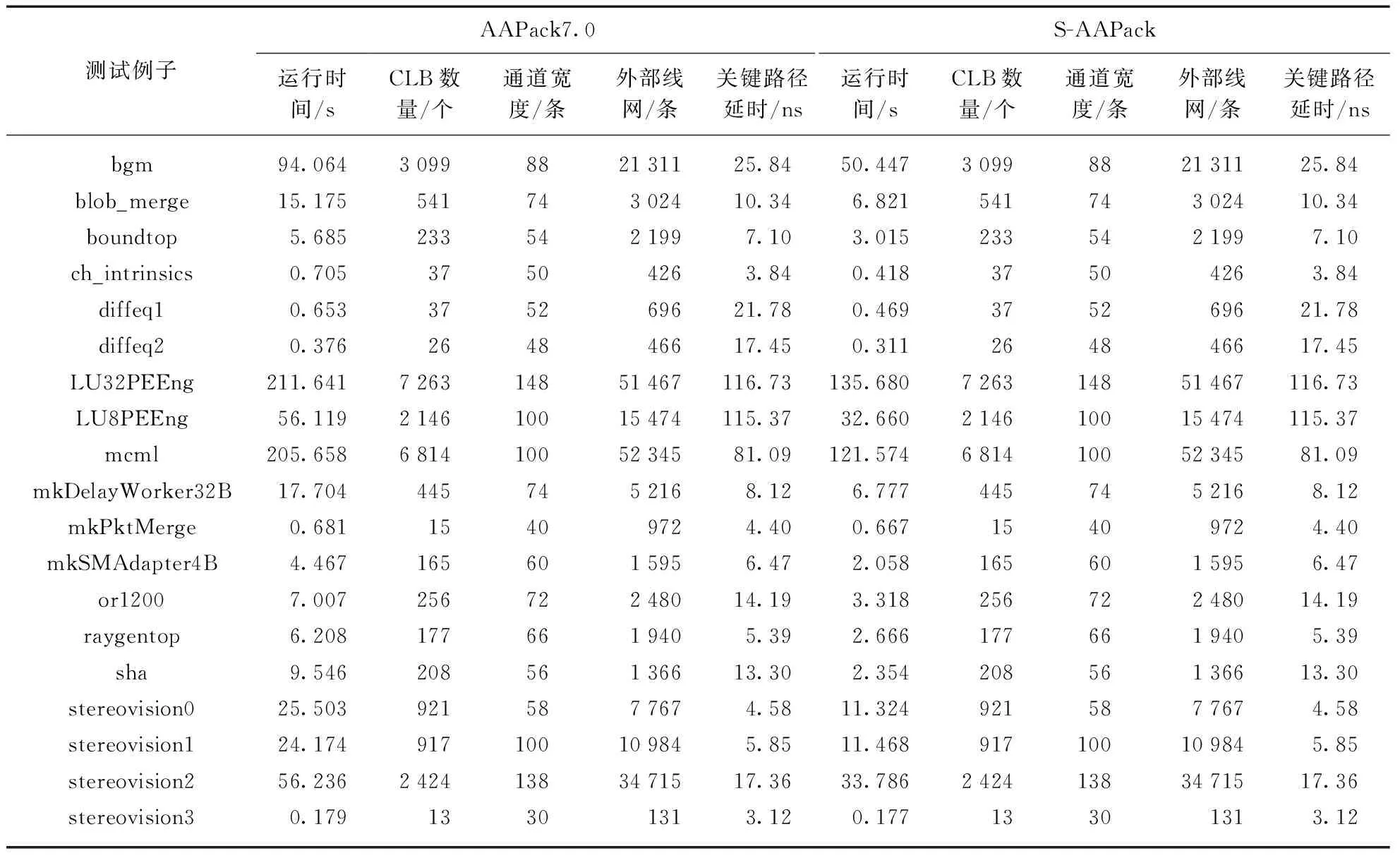
表1 采用S-AAPack或者AAPack7.0的CAD流程的19个测试例子的数据结果
从表2中,我们还可看出测试例子的加速比波动较大,从几乎没有加速的1.01(测试例子stereovision3)到大幅加速的4.05(测试例子sha).这是因为利用共享线网减少运行时间方法的加速比和连线合法性检查失败的次数与整个检查次数中的比例紧密相关: 占的比例越大,减少的运行时间越多,加速比也就越大.在极端情况下,如果测试例子简单连线合法性检查失败次数所占的比例接近于零,则加速比有可能小于1.00,这是因为更新约束和约束满足判断花费的时间有可能超过连线合法性检查失败所花费的时间,例子stereovision3已经比较接近这种情况了.而在实际情况中由于电路功能多、结构复杂,连线合法性检查失败次数所占的比例往往较高,此时加速的效果明显.

表2 AAPack7.0算法结果与S-AAPack算法结果的比值

(续表)
5 小 结
本文提出了一种利用FPGA中CLB内部的共享线网减少打包阶段运行时间的方法,该方法利用共享线网快速判断出不合法的映射,从而避免整体的连线合法性检查,达到减少运行时间的目的;该方法减少的运行时间和连线合法性检查失败的次数与整个检查次数中的比例紧密相关,比例越高,运行时间减少越明显.测试例子的数据显示,与最新的VTR7.0[2]相比,该方法实现了打包阶段1.83倍的加速,同时保持其输出结果在面积、时序等方面的性能不变.
参考文献:
[1] NI G, TONG J, LAI J. A new FPGA packing algorithm based on the modeling method for logic block [C]∥2005 6th International Conference on ASIC. Antwerp, Belgium: IEEE Press, 2005,2: 877-880.
[2] LUU J, GOEDERS J, WAINBERG M, et al. VTR 7.0: Next generation architecture and CAD system for FPGAs [J].ACMTransactionsonReconfigurableTechnologyandSystems(TRETS), 2014,7(2): 6.
[3] ROSE J, LUU J, YU C W, et al. The VTR project: Architecture and CAD for FPGAs from verilog to routing [C]∥Proceedings of the ACM/SIGDA international symposium on Field Programmable Gate Arrays. Monterey, California, USA: ACM, 2012: 77-86.
[4] LUU J, ANDERSON J H, ROSE J S. Architecture description and packing for logic blocks with hierarchy, modes and complex interconnect [C]∥Proceedings of the 19th ACM/SIGDA international symposium on field programmable gate arrays. Monterey, California, USA: ACM, 2011: 227-236.
[5] SHARMA A, HAUCK S, EBELING C. Architecture-adaptive routability-driven placement for FPGAs [C]∥International Conference on Field Programmable Logic and Applications, 2005. Tampere, Finland: IEEE Press, 2005: 427-432.
[6] MARQUARDT A S, BETZ V, ROSE J. Using cluster-based logic blocks and timing-driven packing to improve FPGA speed and density [C]∥Proceedings of the 1999 ACM/SIGDA seventh international symposium on Field programmable gate arrays. Monterey, CA, USA: ACM, 1999: 37-46.
[7] LUU J, ROSE J, ANDERSON J. Towards interconnect-adaptive packing for FPGAs [C]∥Proceedings of the 2014 ACM/SIGDA international symposium on Field-programmable gate arrays. Monterey, CA, USA: ACM, 2014: 21-30.
[8] HUTTON M, SCHLEICHER J, LEWIS D, et al. Improving FPGA performance and area using an adaptive logic module [C]∥International Conference on Field Programmable Logic and Applications. Antwerp, Belgium: Springer Berlin Heidelberg, 2004: 135-144.
[9] LUU J, GOEDERS J, WAINBERG M, et al. Verilog-to-Routing 7.0[EB/OL]. https:∥github.com/verilog-to-routing/vtr-verilog-to-routing, 2016.
[10] LUU J, GOEDERS J, LIU T, et al. VPR User’s Manual.http:∥venividiwiki.ee.virginia.edu/mediawiki/images/61601/VPR_User_Manual_6.0.pdf,2013.
[11] Altera Corporation. Stratix Ⅳ Device Family Overview[EB/OL]. http:∥www.altera.com/literature/hb/stratix-iv/stx4_siv51001.pdf, November 2009.
