基于一般二阶混合矩的高斯分布估计算法
2018-05-15任志刚梁永胜张爱民庞蓓
任志刚 梁永胜 张爱民 庞蓓
分布估计算法(Estimation of distribution algorithm,EDA)是一类典型的基于模型的进化算法.与基于交叉和变异等遗传操作的其他进化算法相比,EDA具有较强的理论基础,而且可以成功求解大量不同类型的连续和离散优化问题,近年来一直是进化计算领域的研究热点[1−3].
本文重点研究面向连续问题的EDA,这类算法通常采用高斯概率模型(Gaussian probability model,GPM)描述优解的分布.根据对各变量之间相关关系的处理方式,高斯EDA(Gaussian EDA,GEDA)可以分为变量无关的EDA、部分变量相关的EDA、全变量相关的EDA,其代表性算法分别为PBILc(Population based incremental learning)[1]和UMDAc(Univariate marginal distribution algorithm)[1,4]、EGNA(Estimation of Gaussian networks algorithm)[4−5]、EMNAg(Estimation of multivariate normal density algorithm)[1].
GPM为EDA的理论分析提供了诸多方便,但同时也有一些不足,其中最显著的一点是,直接由常用的极大似然估计(Maximum likelihood estimation,MLE)计算出的变量方差会快速减小,导致算法的探索能力急剧下降.已有研究通过保持各方差值至少为1[6]、将估计出的方差固定地放大一定倍数[7]、利用协方差矩阵(Covariance matrix,CM)的特征值修改方差[8]以及根据采样解的改进情况自适应地调整方差[9−10]等策略来弥补这一不足.其中,Bosman等学者提出的自适应方差缩放策略影响最为广泛[10].他们建议当算法在远离均值的位置找到更优解时增大方差,而当算法在连续多次迭代内找不到更优解时减小方差.除方差快速减小这一不利因素之外,与CM相对应的概率密度椭球体(Probability density ellipsoid,PDE)的长轴还倾向于与目标函数的改进方向相垂直,这会大大降低GEDA的搜索效率[11−12].Cai等学者首次发现了这一现象,并将其与方差收缩问题合并处理,提出了基于概率分布交叉熵的自适应方差缩放策略[11].Bosman等学者则提出了预期均值偏移策略,该策略尝试采用两组分别以预估均值和偏移均值为中心的较优解来估计CM,从而改变PDE长轴的方向[12].将该策略与前期提出的自适应方差缩放策略相结合后,Bosman等学者构建了一种称为AMaLGaM的有效EDA[13].
除上述研究之外,文献[14−16]分别通过引入混沌变异算子、正则化技术、多群体–多模型方法来增强GPM 对不同问题的适应性;文献[17−19]则放弃GPM,分别采用直方图模型、粒子滤波、Copula函数来估计优解的概率分布;文献[20]在直方图模型的基础上,进一步利用局部搜索技术提升EDA的优化性能;文献[21]则尝试采用有监督学习方法估计优解的条件概率分布,并借助Gibbs采样技术提高搜索效率.这些研究工作在改进EDA性能的同时,也将算法模型复杂化,并引入了较多难以设置的自由参数.
本文在分析传统GEDA性能弱化原因的基础上,提出一种简单高效的GEDA.该算法在每次迭代中首先根据选择出的优秀样本预估出一加权均值,然后显式地利用预估均值的目标函数值将其偏移至一个更有希望的解区域中,最后根据所选优秀样本关于偏移后均值的二阶混合矩来估计CM.这一简单操作可以在不增大算法计算量的前提下,自适应地调整PDE的位置、大小和长轴方向,使之尽可能与当前解区域的结构特征相契合,从而提高算法的搜索效率.根据CM 的计算方式,本文将所提算法命名为基于一般二阶混合矩的高斯分布估计算法(General-second-order-mixed-moment based GEDA,GSM-GEDA).
1 基本分布估计算法
作为一种基于模型的进化算法,EDA假设待解决问题的优解服从某种概率分布,并利用根据当前群体中的较优解估计出的概率分布来产生下一代群体,从而驱动算法进化.基本EDA的步骤如下:
步骤1.设置算法参数,初始化群体.
步骤2.根据目标函数评价当前群体中各个解的质量.
步骤3.根据选择规则选出优秀样本集合.
步骤4.根据优秀样本集估计概率分布模型.
步骤5.根据概率分布模型进行采样,构建新群体.
步骤6.更新获得的最优解并判断是否满足终止条件.若满足,则输出最优结果;否则,转至步骤2.
连续型EDA通常采用GPM描述优解的分布.对于n维的随机列向量x,GPM的联合概率密度函数可以表示为

其中,µ和C分别表示x的均值和CM.在每次迭代中,GEDA通常根据截断选择规则选出优秀样本集S,并采用MLE来估计µ和C:

EMNAg算法采用式(1)∼(3)所示的GPM及参数估计方法来综合描述所有变量之间的相关关系.文献[22]的研究表明,诸如EGNA等基于高斯图的、部分变量相关的EDA可以纳入到全变量相关的EDA框架之下.UMDAc和PBILc则通过忽略各变量间的相关关系,换取了具有较少参数的对角型CM.
上述三类GEDA针对各类型问题的求解性能虽有不同,但它们都采用MLE估计概率分布参数,由此具有两个共性特点:1)各变量的方差会随着算法迭代而快速减小[6,7,9−11];2)与CM 相对应的PDE的长轴倾向于与目标函数的改进方向相垂直[11−13].图1给出了该现象的示意图,造成该现象的主要原因是,GEDA在每次迭代中选出的优秀样本主要分布在由目标函数等值线切割原PDE所形成的半椭球体内.该半椭球体的长轴平行于目标函数等值线;相应地,根据半椭球体内的优秀样本以及MLE新估计出的PDE的长轴也平行于目标函数等值线,即倾向于与目标函数的改进方向相垂直.另一方面,该半椭球体内靠近原PDE中心的样本较多,而远离原PDE中心的样本较少,那么根据这些样本新估计出的PDE自然会发生收缩现象.传统GEDA的这种特性大大降低了算法的搜索效率,导致算法即使在斜坡型解区域中也可能早熟收敛[9].
2 基于一般二阶混合矩的高斯分布估计算法(GSM-GEDA)
在GEDA中,PDE的位置、大小和长轴方向分别决定了算法的搜索中心、范围和主要搜索方向.我们期望PDE位于易于发现更优解的解区域中,其大小能够根据当前解区域的结构特征自适应地变化,其长轴方向与目标函数的改进方向相一致.GSMGEDA通过修改均值和CM的估计方法来实现这一目的.

图1 传统GEDA中PDE的变化示意图Fig.1 Schematic for the change of PDE of traditional GEDA
2.1 均值估计方法
在每次迭代中,为了尽可能获得一个有前途的搜索中心,GSM-GEDA根据如下两个步骤估计均值:
1)采用加权样本预估均值.由式(2)估计出的均值实际上是优秀样本的算术平均,如果对较优样本赋予较大权重则有利于改进所估计均值的质量.具体地,GSM-GEDA首先根据下式为GPM预估出一均值:

其中,S(i)表示集合S中第i个最优解.由式(4)可知,S(i)的权重与其排序的对数值成反比;排序越靠前,其权重越大.数值测试表明,在大多数情况下都优于.
2)沿目标函数的改进方向偏移预估均值.具体为:


其中,t表示第t次迭代中偏移后的均值;表示当前预估均值t与上次迭代中偏移后均值之间的差异,它反映了算法的进化方向;f(·)表示需要极小化的目标函数.通过显式地比较与可以获得f(·)的一个改进方向.若优于式(6)尝试沿的方向将偏移至其目的是发挥算法的搜索惯性,提高搜索效率,其中的ηf称为前向偏移系数;最终能被接受的前提条件是相反地,若t差于式(6)则尝试沿的反方向将偏移至其目的是及时修正算法的进化方向,使其与目标函数的改进方向相一致,其中ηb称为反向偏移系数;也仅在优于的情况下才会被最终接受.当进行反向偏移时,一个合理的设置是允许最远偏移至因此0<ηb≤1;另一方面,大量测试表明,当ηf≥1时,可以前向偏移至一理想位置.综合以上两个因素,一般可以设置ηb=1/ηf.第2.2节将理论分析ηf对算法性能的影响;第3.1节将实验测试ηf对算法最终求解质量的影响,并给出取值方案.
2.2 协方差矩阵估计方法
GEDA根据优秀样本估计CM 的本质目的并不是准确获得样本自身的分布特征,而是希望利用这些样本为下一次迭代确定一个合理的搜索范围和方向.由第1节的分析可知,与式(3)所示估计相对应的PDE的大小和长轴方向是不理想的.另一方面,由概率论中关于矩的知识可知,随机向量的CM 即为它的二阶混合中心矩.那么在样本不变的前提下,改变矩中心是调整PDE大小和长轴方向的一个简单方法.对于GSM-GEDA来说,一个自然选择是采用偏移后的均值代替式(3)中的MLE均值,即:
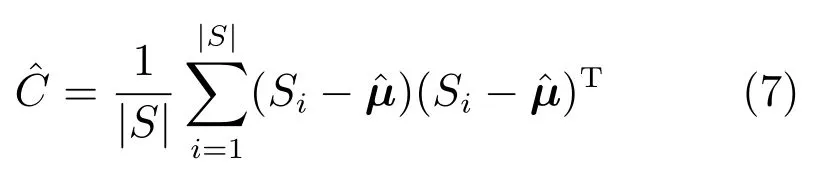
上式表示对以偏移后的均值这一一般位置为中心的二阶混合矩的估计.
由式(5)和(6)可知,不差于;由式(4)可知,通常优于;相应地,一般会优于.那么,代表了目标函数的一个改进方向.与式(3)所示估计相比,式(7)给出的估计可以随的改变而自适应地调整PDE的大小(体积),并且可以使PDE的长轴方向趋近于目标函数的改进方向().为此给出以下定理和推论:
定理1.对于选定的优秀样本,若那么由所确定的PDE的体积不小于由确定的PDE的体积.
证明.由高斯分布的性质可知,PDE的各个轴的方向分别与CM的各特征向量相一致,而各半轴长度ad(d=1,2,···,n)由CM 的相应特征值λd确定:另一方面,由文献[23]可知,PDE的体积与各半轴长度的乘积成正比.记的特征值分别为那么定理1成立的充要条件是,当为证明这一点,对做如下变化:

很明显,矩阵的秩1修正[24].文献[25]中的引理1.4对秩1修正后对角型矩阵的特征多项式进行了讨论,根据该引理可以推得也即的特征多项式:


其中,I表示相应阶数的单位阵.令式(10)中的λ=0,可得:

推论1.对于选定的优秀样本,若且样本数量大于问题维数(即|S|>n),那么由所确定的PDE的体积将大于由所确定的PDE的体积.

推论2.对于选定的优秀样本,到的马氏距离越大,那么由所确定的PDE的体积越大.
证明.重新考虑式(11):证.

由上式可知,越大,越大.由此得
注1.推论1从理论上给出了保证由所确定的PDE的体积大于由所确定的PDE的体积的充要条件.由上文分析可知,GSM-GEDA在每次迭代中采用的通常不等于且优于;另一方面,GSM-GEDA及传统GEDA通常都设置群体规模远大于问题维数,那么从中选出的优秀样本的数量一般都满足|S|>n.由此可知,GSM-GEDA能够使推论1成立.这意味着,对于相同的选定样本,GSM-GEDA的探索能力强于传统GEDA.
注 2.推论2告诉我们,若要增强GSMGEDA 的探索能力,只需增大从到的马氏距离也即增大对于选定的优秀样本,是固定的.若要增大要求增大的各分量d(d=1,2,···,n),即在矩阵的各特征向量上的投影.根据式(6)可知,在优秀样本选定的情况下,通过调整偏移系数ηf可以改变位置,进而调整的大小.ηf越大,倾向于增大,那么GSM-GEDA的探索能力会相应增强.
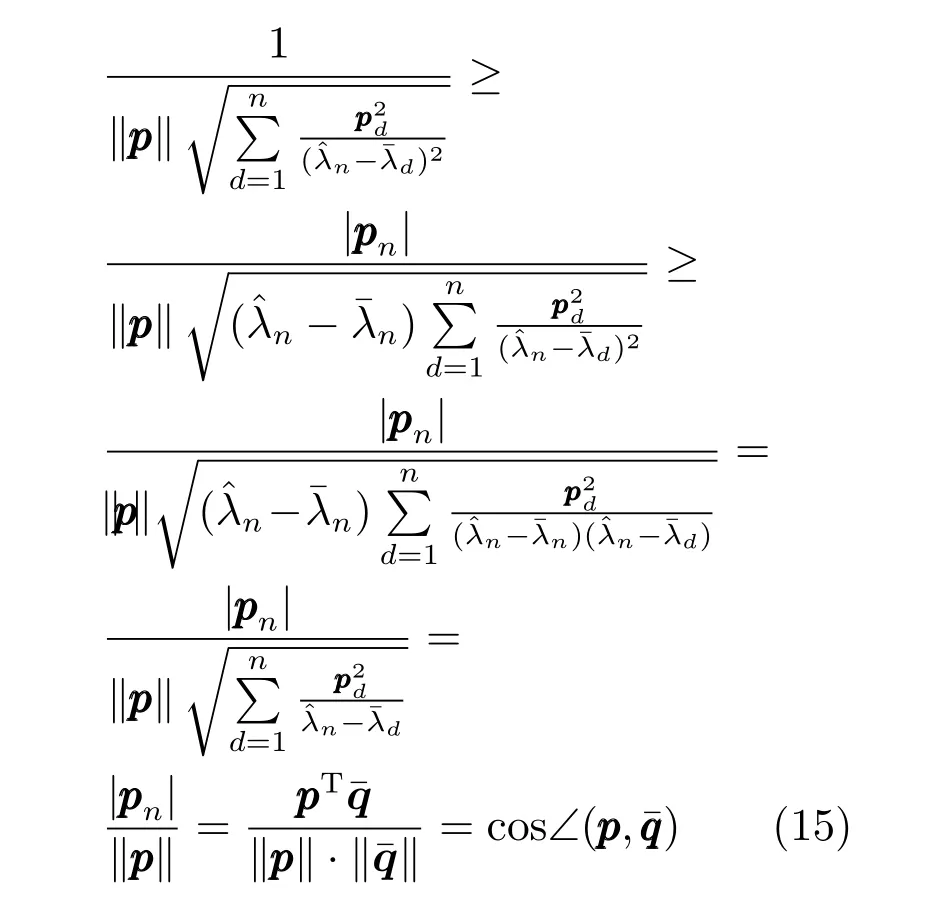
定理2.对于选定的优秀样本,若,那么与由所确定的PDE长轴之间的夹角不大于其与由所确定的PDE长轴之间的夹角.

将n代入式(10)可知:

进一步有

即由此可知,若定理2成立.
注3.在上述证明过程中,对于情况1可以推得依然分别是的特征值、特征向量;仅当较小,对其他特征值的调整幅度较小,使得仍为的主特征值时,才有对于情况2,仅当即时,才有因此,在绝大部分情况下,由于PDE的长轴,即CM的主特征向量决定了GEDA的主要搜索方向,那么定理2意味着,在采用作为CM的估计之后,GEDA的主要搜索方向更靠近目标函数的改进方向,因此更容易找到较优解.
2.3 GSM-GEDA的步骤
GSM-GEDA在基本EDA的框架之下,采用GPM描述优解的分布,并采用了一种新的GPM参数估计方法,其具体步骤如下:
步骤1.设置算法参数,包括群体规模m、优秀样本比例系数τ以及前向偏移系数ηf;记迭代次数t=1,并采用伪均匀分布随机生成m个解,初始化群体Mt.
步骤2.根据目标函数f(·)评价Mt中各个解的质量.
步骤3.根据截断选择规则,从Mt中选出前个优解,赋予优秀样本集St.
步骤4.根据优秀样本集St估计概率分布参数:1)根据式(4)计算加权的预估均值t;2)根据式(5)和(6)对t进行偏移,获得最终的估计均值t;3)根据式(7)估计协方差矩阵t.
步骤5.根据高斯概率模型新生成m−2个解,并记由这些解构成的集合为采用精英策略更新群体
步骤6.更新t=t+1,判断是否满足终止条件.若满足,则输出最优结果;否则,转至步骤2.
其中,步骤5采用常用的精英策略将当前群体中的最优个体保留到下一代群体中.此外,经过显式评价后的t也可以看作一个完整的解样本,并且其解质量通常较高,因此也将它保留到下一代群体中.
GSM-GEDA与传统GEDA的区别主要体现在步骤4中的概率分布参数估计方法.从式 (4)∼(7)可以看出,新提出的均值、CM 估计方法的计算时间复杂度分别为 O(τmn)=O(mn)、O(τmn2)=O(mn2),这与常用的 MLE的计算复杂度相同.这意味着GSM-GEDA可以以相同的计算复杂度获得具有更好理论性质的GPM,即可以避免PDE快速收缩,从而保证算法具有适度的探索能力;并且可以使PDE的长轴方向趋近于目标函数的改进方向,进而提高算法的搜索效率.
3 实验与分析
为了评估GSM-GEDA的性能,采用IEEE CEC 2005标准函数库[27]中的前14个函数对其进行了测试.其中,f1∼f5是单模函数,f6∼f12是基本的多模函数,f13∼f14是扩展的多模函数.这些函数大多都经过了旋转、偏移操作,分别使得各变量之间相互关联、最优解偏离搜索中心,从而保证函数的优化难度.在实验中,所有函数的维数都设置为30,每个函数在每种算法上独立测试25次,每次测试均以完成300000次目标函数评价作为终止条件,并采用所获优解与实际最优解之间的差值(函数误差值)在25次测试中的均值和标准差来衡量算法性能.
3.1 参数影响及其设置
GSM-GEDA一共包括3个参数,即群体规模m、优秀样本比例系数τ以及前向偏移系数ηf.对于m和τ这两个常规参数,文献中已进行了较多研究[1,13],本文将其设置为常规值m=1200、τ=0.35.本节重点考察新参数ηf对GSM-GEDA的性能的影响.由第2节可知,ηf决定了预估均值eµ的偏移程度,从而改变PDE的中心位置、大小和长轴方向,最终影响GSM-GEDA的性能.
图2以函数f2、f10为例,给出了当ηf以0.25为间隔从0.5增大到3.5时,GSM-GEDA的性能变化情况.从图中可以看出,当ηf在0.5∼3.5这么一个较大的范围内变化时,GSM-GEDA的性能变化并不剧烈.特别地,对于f2,GSM-GEDA求得的解总是非常接近最优解.这说明GSM-GEDA的优化性能关于ηf的鲁棒性较强.另一方面,在不考虑随机因素的情况下,GSM-GEDA的性能总是随着ηf的增大先变好后变差.对于f2这一单模函数,当ηf≈1.0时,GSM-GEDA取得较优结果;对于多模函数f10,当ηf≈2.75时,GSM-GEDA的表现较好.实验表明,上述结论基本上也适用于其他测试函数.对于待优化的一般黑箱函数,并没有先验信息确定其为单模还是多模.为兼顾两类函数的求解质量,我们建议在1.0∼2.75之间为ηf取值;本文选取ηf=2.0.

图2 GSM-GEDA的性能随ηf的变化情况Fig.2 The performance variation of GSM-GEDA with regard to ηf
3.2 均值−协方差矩阵估计方法的有效性分析
第2节理论证明了新提出的均值–协方差矩阵估计方法可以增大PDE的体积,使PDE的长轴方向趋近于目标函数的改进方向,本节将通过数值实验验证这一点.实验设置如下:在GSM-GEDA的每次迭代中,除了根据式(4)∼(7)所示的新方法估计CM 之外,还利用相同的优秀样本,根据式(2)∼(3)所示的传统MLE方法估计CM,从而满足定理1和2的限定条件.为描述方便,将这种依附于GSM-GEDA但采用传统估计方法的算法称为quasi-GSM-GEDA.此外,还将EMNAg[1]作为对比算法.除参数估计方法之外,EMNAg的其他设置与GSM-GEDA完全相同.
图3和4以函数f2、f10为例,分别给出了各算法的PDE的长轴长度、长轴与目标函数改进方向之间的夹角余弦(简记为cos(A1))随迭代次数的变化情况.从图3中可以看出,GSM-GEDA和quasi-GSM-GEDA的PDE的长轴长度都随迭代次数的增大而逐渐减小,但前者的长度始终不小于后者,该现象在前期迭代过程中尤为明显.实际上,上述结论对于PDE的其他轴也是成立的,这与定理1所述内容一致.从图4中可以看出,GSM-GEDA的cos(A1)值始终不小于quasi-GSM-GEDA的相应值,这说明GSM-GEDA的PDE的长轴与之间的夹角不大于quasi-GSM-GEDA的相应夹角,这与定理2所述内容一致.

图3 长轴长度随迭代次数的变化情况Fig.3 The variation of long axis length with regard to iteration times
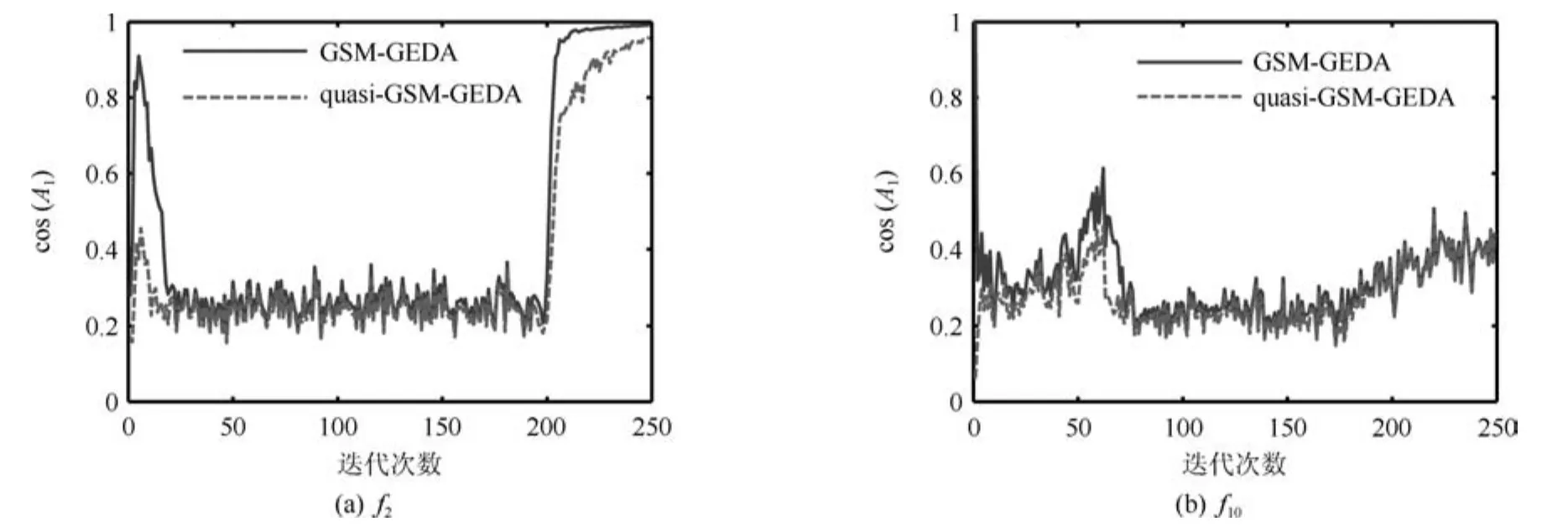
图4 长轴与目标函数改进方向之间的夹角余弦随迭代次数的变化情况Fig.4The variation of the cosine value of the angle between long axis and with regard to iteration times

图5 长轴与最速下降方向之间的夹角余弦随迭代次数的变化情况Fig.5 The variation of the cosine value of the angle between long axis and the steepest descent direction with regard to iteration times
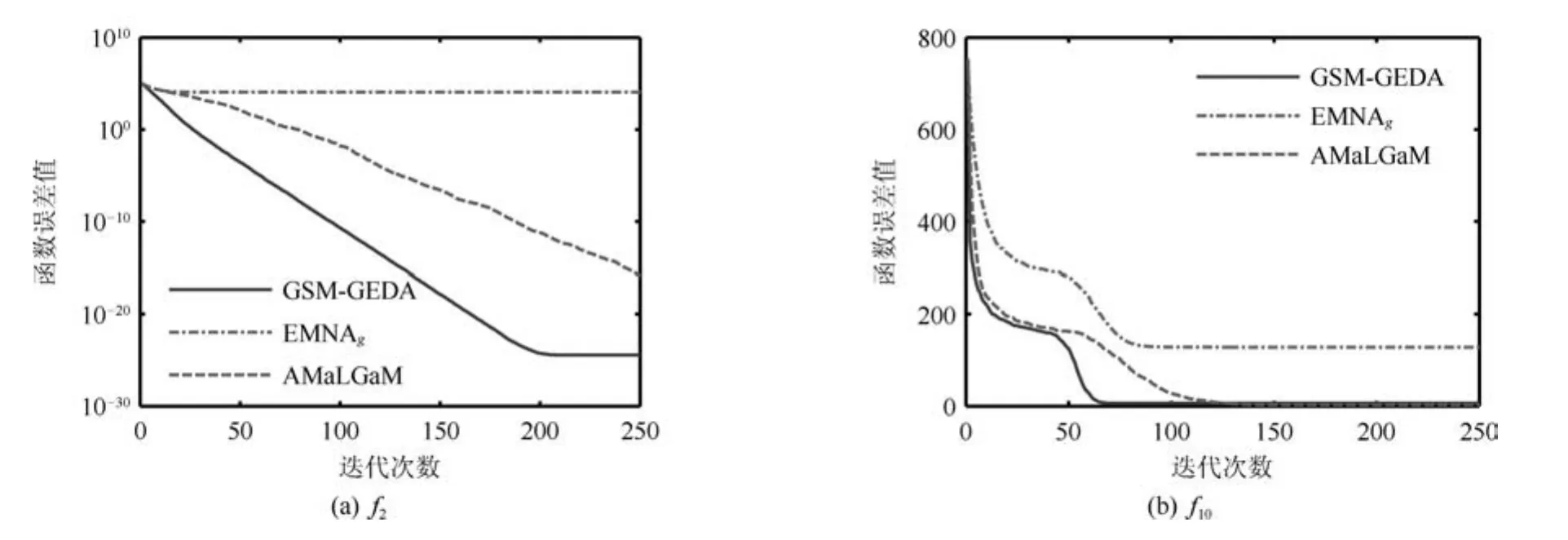
图6 函数误差值随迭代次数的变化情况Fig.6 The variation of the function error value with regard to iteration times
从图3中还可以看出,与EMNAg相比,GSMGEDA的PDE的长轴长度在前期迭代过程中保持了较大值,这有利于算法进行探索性搜索;在中后期迭代过程中,GSM-GEDA的PDE的长轴收缩到一个较小的尺度范围内,这有利于算法进行精细搜索.为了进一步说明GSM-GEDA与EMNAg的性能差异,图5和6分别给出了两算法的PDE的长轴与目标函数的最速下降方向(即从PDE的中心指向最优解的方向)之间的夹角余弦(简记为cos(A2))、所求得的最小函数误差值随迭代次数的变化情况.从图5中可以看出,对于f2这一单模函数,GSMGEDA的cos(A2)值始终大于EMNAg的相应值,说明GSM-GEDA能够探测到较好的搜索方向.从图6中可以看出,GSM-GEDA在经过大概200次迭代后基本上获得了f2的最优解;EMNAg在经过大概15次迭代后便早熟收敛,无法获得理想解.对于多模函数f10,GSM-GEDA在中前期迭代过程中的cos(A2)值也大于EMNAg的相应值,尽管两算法都陷入了局部优解,但GSM-GEDA获得的终解远优于EMNAg.
图6还给出了AMaLGaM[13]获得的最小函数误差值的进化情况.AMaLGaM利用预期均值偏移策略和自适应方差缩放策略改进了传统GEDA,是当前性能最为优越的EDA之一.从图6中可以看出,AMaLGaM和GSM-GEDA在不同程度上消弱了EMNAg的早熟收敛问题.在给定的目标函数评价次数内,GSM-GEDA求得的f2、f10的终解分别优于、接近于AMaLGaM所得结果,其收敛速度也快于AMaLGaM.
3.3 与其他算法的比较
为了综合衡量GSM-GEDA的性能,将其与 6种已有算法进行了比较,包括 EMNAg[1]、AMaLGaM[13]、 CMA-ES[28]、 CLPSO[29]、CoBiDE[30]以及MPEDE[31].选择这6种算法作为对比算法的原因在于:EMNAg和AMaLGaM分别是传统GEDA和先进GEDA的典型代表,可以为衡量GSM-GEDA的性能提供基准;CMAES、CLPSO、CoBiDE分别是进化策略算法、粒子群算法、差分进化算法的代表算法,并被多次用作对比算法,而且CoBiDE中的交叉算子也涉及了CM的估计问题;MPEDE是一种新近提出的差分进化算法,一定程度上反映了当前函数智能优化方面的发展水平.
为了保证比较的公平性,EMNAg、AMaLGaM以及GSM-GEDA的参数m、τ取为相同值,AMaLGaM 也选用全变量相关的GPM 模型;AMaLGaM的其余参数以及其他4种算法的参数均按照相应的原文献进行取值.表1给出了各算法最终所获优解的函数误差值在25次独立测试中的均值和标准差,表中还采用了下式所示的Cohen′sd效应量[32]衡量GSM-GEDA与其他6种算法之间的性能差异:

其中,分别表示样本集a的均值、标准差、样本数量.通常当|d|<0.2时,认为两样本集的均值差异较小[32],这里意味着两个被测算法的性能无显著差异,在表1中用符号“≈”标识.反过来,若根据效应量判断出某算法显著优于或差于GSM-GEDA,则在表1中分别用符号“+”、“−”来标识.
从表1中可以看出,对于单模函数f1∼f5,GSM-GEDA的性能比较理想.尽管针对f1、f2的优化结果差于差分进化算法,但其获得的解也已充分接近最优解.对于基本的多模函数f6∼f12,GSM-GEDA在3个函数上的性能优于其他所有算法;特别地,它可以获得f7、f11的最优解.对于f6、f9,3种EDA的表现都不太理想;对于f8,所有被测算法的性能差异不大;对于f10,GSM-GEDA的表现仅次于AMaLGaM,优于其他5种算法.对于扩展的多模函数,GSM-GEDA在f13上的表现与CoBiDE接近,仅次于CLPSO;在f14上的表现优于其他所有算法.根据表1最后一行的统计结果可知,GSM-GEDA 分别在14、9、12、9、9、9个函数上的性能显著优于EMNAg、AMaLGaM、CMAES、CLPSO、CoBiDE、MPEDE,表现出良好的全局寻优能力.

表1 7种算法最终求得的函数误差值的均值和标准差Table 1 The mean and standard deviation of the function error values obtained by 7 algorithms
4 结论
概率密度椭球体(PDE)的位置、大小和长轴方向是影响高斯分布估计算法(GEDA)性能的关键.本文在分析传统GEDA性能弱化原因的基础上,提出了一种基于一般二阶混合矩的高斯分布估计算法(GSM-GEDA).该算法以沿目标函数改进方向偏移后的加权均值作为协方差矩阵(二阶混合中心矩)的矩中心,一方面将PDE引导至一个更有希望的解区域;另一方面可以自适应地增大PDE的大小,并使PDE的长轴方向趋近于目标函数的改进方向.理论分析和数值实验均证明了上述结论的正确性.此外,在14个标准函数上的数值测试还表明,GSM-GEDA的求解质量优于现有的GEDA以及其他一些先进的进化算法.下一步工作将研究设计更为系统化的均值偏移策略,并在实际的复杂优化问题中检验GSM-GEDA的有效性.
References
1 Larranaga P,Lozano J A.Estimation of Distribution Algorithms:A New Tool for Evolutionary Computation.New York,USA:Springer,2001.57−100
2 Hauschild M,Pelikan M.An introduction and survey of estimation of distribution algorithms.Swarm and Evolutionary Computation,2011,1(3):111−128
3 Wang Sheng-Yao,Wang Ling,Fang Chen,Xu Ye.Advances in estimation of distribution algorithms.Control and Deci-sion,2012,27(7):961−966,974(王圣尧,王凌,方晨,许烨.分布估计算法研究进展.控制与决策,2012,27(7):961−966,974)
4 Larraaga P,Etxeberria R,Lozano J A,Pe˜na J M.Optimization in continuous domains by learning and simulation of Gaussian networks.In:Proceedings of 2000 Genetic and Evolutionary Computation Conference.Las Vegas,USA:Morgan Kaufmann,2000.201−204
5 Lu Q,Yao X.Clustering and learning Gaussian distribution for continuous optimization.IEEE Transactions on Systems,Man,and Cybernetics,Part C:(Applications and Reviews),2005,35(2):195−204
6 Yuan B,Gallagher M.On the importance of diversity maintenance in estimation of distribution algorithms.In:Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation.New York,USA:ACM,2005.719−726
7 Pošk P.Preventing premature convergence in a simple EDA via global step size setting.Parallel Problem Solving from Nature—PPSN X.Lecture Notes in Computer Science.Berlin,Heidelberg,Germany:Springer-Verlag,2008:.549−558
8 Dong W S,Yao X.Uni fied Eigen analysis on multivariate Gaussian based estimation of distribution algorithms.Information Sciences,2008,178(15):3000−3023
9 Ocenasek J,Kern S,Hansen N,Koumoutsakos P.A mixed bayesian optimization algorithm with variance adaptation.Parallel Problem Solving from Nature—PPSN VIII.Lecture Notes in Computer Science.,Berlin,Heidelberg,Germany:Springer-Verlag,2004.352−361
10 Bosman P A N,Grahl J,Rothlauf F.SDR:a better trigger for adaptive variance scaling in normal EDAs.In:Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation.New York,USA:ACM,2007.492−499
11 Cai Y P,Sun X M,Xu H,Jia P F.Cross entropy and adaptive variance scaling in continuous EDA.In:Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation.New York,USA:ACM,2007.609−616
12 Bosman P A N,Grahl J,Thierens D.Enhancing the performance of maximum-likelihood Gaussian EDAs using anticipated mean shift.Parallel Problem Solving from Nature—PPSN X.Lecture Notes in Computer Science.Berlin,Heidelberg,Germany:Springer-Verlag,2008:.133−143
13 Bosman P A N,Grahl J,Thierens D.Benchmarking parameter-free AMaLGaM on functions with and without noise.Evolutionary Computation,2013,21(3):445−469
14 Cheng Yu-Hu,Wang Xue-Song,Hao Ming-Lin.An estimation of distribution algorithm with diversity preservation.Acta Electronica Sinica,2010,38(3):591−597(程玉虎,王雪松,郝名林.一种多样性保持的分布估计算法.电子学报,2010,38(3):591−597)
15 Karshenas H,Santana R,Bielza C,Larra˜naga P.Regularized continuous estimation of distribution algorithms.Applied Soft Computing,2013,13(5):2412−2432
16 Yang P,Tang K,Lu X F.Improving estimation of distribution algorithm on multi-modal problems by detecting promising areas.IEEE Transactions on Cybernetics,2015,45(8):1438−1449
17 Ding N,Zhou S D,Sun Z Q.Histogram-based estimation of distribution algorithm:a competent method for continuous optimization.Journal of Computer Science and Technology,2008,23(1):35−43
18 Zhang Jian-Hua,Zeng Jian-Chao.Estimation of distribution algorithm based on sequential importance sampling particle filters.Acta Electronica Sinica,2010,38(12):2929−2932(张建华,曾建潮.基于序贯重点采样粒子滤波的分布估计算法.电子学报,2010,38(12):2929−2932)
19 Wang Li-Fang,Zeng Jian-Chao,Hong Yi.Estimation of distribution algorithm modeling and sampling by means of Copula.Control and Decision,2011,26(9):1333−1337,1342(王丽芳,曾建潮,洪毅.利用Copula函数估计概率模型并采样的分布估计算法.控制与决策,2011,26(9):1333−1337,1342)
20 Zhou A M,Sun J Y,Zhang Q F.An estimation of distribution algorithm with cheap and expensive local search.IEEE Transactions on Evolutionary Computation,2015,19(6):807−822)
21 Zhang Fang,Lu Hua-Xiang.General stochastic model for algorithm of distribution estimation with conditional probabilities and Gibbs sampling.Control Theory&Applications,2013,30(3):307−315(张放,鲁华祥.利用条件概率和Gibbs抽样技术为分布估计算法构造通用概率模型.控制理论与应用,2013,30(3):307−315)
22 Zhong Wei-Cai,Liu Jing,Liu Fang,Jiao Li-Cheng.Estimation of distribution algorithm based on generic Gaussian networks.Journal of Electronics and Information Technology,2005,27(3):467−470(钟伟才,刘静,刘芳,焦李成.建立在一般结构Gauss网络上的分布估计算法.电子与信息学报,2005,27(3):467−470)
23 Zhao Hong.Areas(Volumes)ofn-dimension ellipsoid by quadratic curve(surface)enclosed.Mathematics in Practice and Theory,2013,43(10):279−282(赵虹.n元椭球面的判定及所围椭球体的体积.数学的实践与认识,2013,43(10):279−282)
24 Bunch J R,Nielsen C P,Sorensen D C.Rank-one modi fication of the symmetric eigenproblem.Numerische Mathematik,1978,31(1):31−48
25 Yin Qing-Xiang.The inverse problem of rank-1 modi fication of real symmetric matrices.Journal of Nantong Institute of Technology(Natural Science),2003,2(4):11−14(殷庆祥.实对称矩阵的秩1修正的特征反问题.南通工学院学报(自然科学版),2003,2(4):11−14)
26 Xie Ping-Min,Chen Tu-Hao.The positive de finiteness of the covariance matrix of continuous sample.Acta Scientiarum Naturalium Universitatis Sunyatseni,1990,29(1):102−104(谢平民,陈图豪.连续型样本协差阵的正定性.中山大学学报(自然科学版),1990,29(1):102−104)
27 Suganthan P N,Hansen N,Liang J J,Deb K,Chen Y P,Auger A,Tiwari S.Problem De finitions and Evaluation Criteria for the CEC 2005 Special Session on Real Parameter Optimization,Technical Report,Nanyang Technological University,Singapore,2005.
28 Hansen N,Ostermeier A.Completely derandomized selfadaptation in evolution strategies.Evolutionary Computation,2001,9(2):159−195
29 Liang J J,Qin A K,Suganthan P N,Baskar S.Comprehensive learning particle swarm optimizer for global optimization of multimodal functions.IEEE Transactions on Evolutionary Computation,2006,10(3):281−295
30 Wang Y,Li H X,Huang T W,Li L.Differential evolution based on covariance matrix learning and bimodal distribution parameter setting.Applied Soft Computing,2014,18:232−247
31 Wu G H,Mallipeddi R,Suganthan P N,Wang R,Chen H K.Differential evolution with multi-population based ensemble of mutation strategies.Information Sciences,2016,329:329−345
32 Cohen J.Statistical Power Analysis for the Behavioral Sciences(Second Edition).Hillsdale,NJ:Lawrence Erlbaum Associates,1988.
