基于条件随机森林的非约束环境自然笑脸检测
2018-05-15罗珍珍陈靓影刘乐元张坤
罗珍珍 陈靓影 刘乐元 张坤
笑脸是人类最常见的面部表情之一,反映了人的心理状态,传递着丰富的情感和意向信息.笑脸检测在用户体验感知[1]、学生心理状态分析[2]、照片增强处理[3]、相机微笑快门[4]等领域有广泛的应用.近年来,国内外的学者在笑脸检测方面开展了大量的研究工作[5−6].随着研究的深入和实际应用要求的提高,笑脸检测的研究热点逐步从约束环境转移到非约束环境[7].非约束环境(Unconstrained environment)是指主体意识想法和行为不受规定约束的环境.在非约束环境下,人的头部姿态、环境光照、背景以及图像分辨率等环境因素不受约束.由于这些不利环境因素的影响,约束环境下的笑脸检测算法通常不能在非约束环境下保持良好的正确率.非约束环境下的笑脸检测在计算机视觉领域仍然是一项富有挑战性的工作[5−6].
依据特征采样方式的不同,可将现有笑脸检测算法粗略分为基于面部运动单元(Action units,AUs)的方法[7−13]和基于内容 (non-AUs)的方法[4,14−22].基于面部运动单元的方法从面部动作编码系统(Facial action coding system,FACS)[8]定义的44个面部运动单元中选取相关的AUs,并以这些AUs为桥梁建立低层人脸特征与表情的关系模型进行笑脸检测.文献[7]和文献[9]分别利用动态贝叶斯网络(Dynamic Bayesian network,DBN)和隐马尔科夫模型(Hidden Markov model,HMM)建立AUs之间以及AUs与表情的概率模型,从图像中同步推理头部运动和表情变化.这两种方法取得了良好的笑脸检测效果,但模型较为复杂,导致计算量庞大.为建立更为高效和简洁的笑脸检测系统,文献[10]将人脸分为眉眼区域和嘴巴区域两部分,采用Gabor小波提取区域特征,并结合K近邻(KNearest neighbor,KNN)与贝叶斯网络(Bayesian network,BN)建立面部运动单元与表情间的概率关系模型.为避免精确检测AUs的困难,文献[12]从特定AUs周围提取图像子块,对每个子块提取Haar特征后采用错误率最小策略从中选出AUs组合特征,在Boosting框架下利用组合特征构造表情分类器.Walecki等[13]提出一种基于潜式条件随机森林(Latent conditional random forests)的视频动态序列编码方法实现人脸运动单元AUs检测和表情识别.虽然AUs具备明确的面部表情划分和定义,便于利用心理学的研究成果选用最有效的AUs来识别不同的表情,但基于面部运动单元的方法对笑脸检测的准确率很大程度上取决于AUs的定位和运动特征的计算精度.此外,对训练数据做AUs标注较为困难是基于面部运动单元方法的另一弱点.
基于内容的方法通常不再分析面部运动单元,而是在对人脸进行对齐(Face registration)后,直接从人脸提取特征并通过机器学习方法建立图像到笑脸表情的映射.Shimada等[14]在提取局部强度直方图(Local intensity histogram,LIH)和中心对称局部二值模式(Center-symmetric local binary pattern,CS-LBP)两种特征后,采用层级式支持向量机(Support vector machine,SVM)进行笑脸分类.该方法对高分辨率正脸图像具备良好的检测效果和效率,但没有考虑头部姿态变化的情况.Whitehill等[4]从互联网上收集了头部水平偏向角为−20°∼+20°的GENKI-4K 数据集,并在该数据集上系统地测试了Gabor、Haar、边缘方向直方图 (Edge orientation histograms,EOH)、LBP等特征搭配SVM、GentleBoost等分类器对笑脸检测的效果.实验结果表明,头部姿态变化对笑脸检测的效果有较大的影响.Shan等[15]使用像素对的灰度差值作为特征,利用AdaBoost算法选择像素对并组合强分类器进行笑脸检测.当使用100对像素对时,该方法在GENKI-4K数据集上可以达到88%的正确率.文献[16]采用极端学习机(Extreme learning machine,ELM)[17],使用灰度值、HOG、LBP、LPQ(Local phase quantization)特征时,在GENKI-4K数据集上分别取得了79.3%、88.2%、85.2% 和85.2% 的正确率.最近,Gao等[18]通过混合HOG31、梯度自相似性(Selfsimilarity of gradients,SSG)[19]和灰度特征,及组合AdaBoost和线性ELM 两种分类器的方式,将GENKI-4K数据集上的笑脸检测正确率提高到了96.1%.就作者查阅的文献来看,目前还只有少量研究者开展任意头部姿态下的笑脸检测工作.例如,文献[20]使用随机森林在视频序列图像上进行任意头部姿态下的表情识别工作,但该工作训练时使用的是非自然状态下采集的3D表情序列训练数据集(BU-3DFE)[23],难以满足大量实际应用的需求.Dapogny等[22]提出一种基于PCRF(Pairwise conditional random forests)的动态序列人脸表情识别方法.但该方法只针对视频序列图像,不适合单帧图像的表情识别.
在任意头部姿态下进行笑脸检测主要面临两方面的困难:1)当前缺少任意头部姿态下的自然笑脸数据集;2)当头部姿态变化范围较大时人脸对齐较为困难,巨大的类内差异会导致难以设计高正确率和高效率的分类器[4].为更好地在任意头部姿态、低分辨率图像上实现自然笑脸的检测,本文对LFW数据集[24]做了头部姿态和笑脸的标注,采集了自然课堂场景下的CCNU-Classroom数据集,并给出一种基于条件随机森林的自然笑脸检测方法.本文的主要贡献:1)以头部姿态作为隐含条件,提出了基于条件随机森林的笑脸检测方法,降低了非约束环境下头部姿态对笑脸检测带来的不利影响.2)在使用随机森林建构笑脸分类器时,给出了一种基于K-Means聚类的决策边界确定方法,提高了笑脸分类器的准确率.3)由分别从嘴巴区域和眉眼区域训练的条件随机森林组成层级式检测器,提高了笑脸检测的准确率.
1 条件随机森林
随机森林[25]是一种采用决策/回归树作为基预测器的集成学习方法.由于能从训练数据中快速学习得到高精度、鲁棒的分类器,随机森林已经成为计算机视觉领域的一个重要工具,在头部姿态估计[26−27]和表情识别[20]等应用方向取得了良好的效果.随机森林直接从训练数据估计目标状态θ的概率分布p(θ|P),其中P为样本.
与随机森林不同,条件随机森林[27−28]从训练数据集中学习目标状态θ关于隐含条件ω的条件概率分布p(θ|ω,P).目标状态θ的概率p(θ|P)可由p(θ|ω,P) 积分得到.
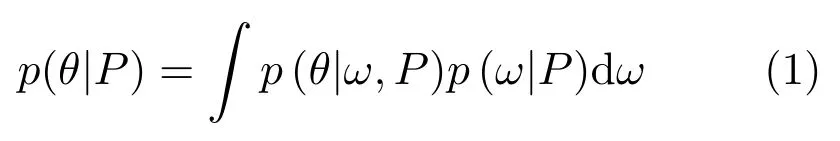
若将隐含条件ω的状态空间划分为若干不相交子集,则式(1)可以写为
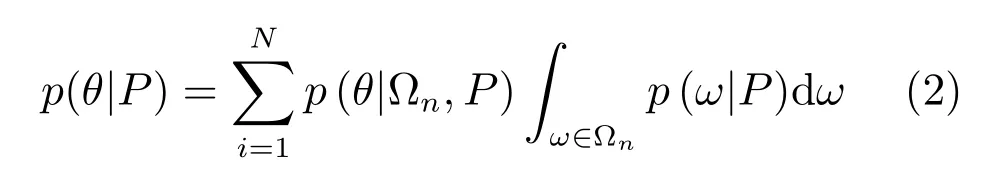
其中,是隐含条件变量ω状态的一个划分.由式(2)可知,为从训练样本估计目标状态θ,可在训练时将训练数据集S按条件状态划分为不相交的若干数据子集然后分别从各数据子集抽取样本训练一组随机森林用于估计条件概率而隐含条件的状态概率p(ω|P)可以从整个数据集S训练得到的随机森林来估计.
若隐含条件ω选取合理,按其状态划分训练数据后,数据子集SΩn的样本类内差异将比整个数据集S的样本类内差异低.数据类内差异的降低使得分类器能更有效和更高效地描述训练数据.因此,条件概率p(θ|Ωn,P)比p(θ|P)能更容易、更准确地从训练数据中学习得到[27−28].文献[27]在面部特征点检测和文献[28]在人体姿态估计的结果表明,在数据类内差异较大的情况下,条件随机森林可大幅提高随机森林的鲁棒性和分类/回归精度.
2 基于条件随机森林的笑脸检测
在非约束环境下,头部姿态的多样性使得人脸在特征空间的类内差异过大,导致建构具备高准确率的笑脸分类器较为困难.为此,本文以头部姿态作为隐含条件来划分数据空间,提出一种基于条件随机森林的笑脸检测方法,如图1所示.
在训练阶段,使用整个训练数据集训练生成用于估计头部姿态的随机森林,记为TH.然后将训练数据集S按头部姿态划分为N个子集,并使用各数据子集分别训练生成一组用于笑脸分类的条件随机森林本文在实现时,按头部的水平偏向角度将训练数据划分为3个子集,即Ω1={−30°≤ω≤+30°},Ω2={ω|−60°≤ω<−30°}∪{ω|+30°<ω≤+60°}及 Ω3={ω|−90°≤ω<−60°}∪{ω|+60°<ω≤+90°}.其中,Ω2和Ω3利用了人脸的水平对称性,将朝向为左的人脸图像作水平镜像后与朝向为右的人脸图像合并,以扩充训练样本.为进一步提高笑脸检测的正确率,分别从嘴巴区域和眉眼区域采样图像子块以同样的方式独立训练两组条件随机森林,记为和
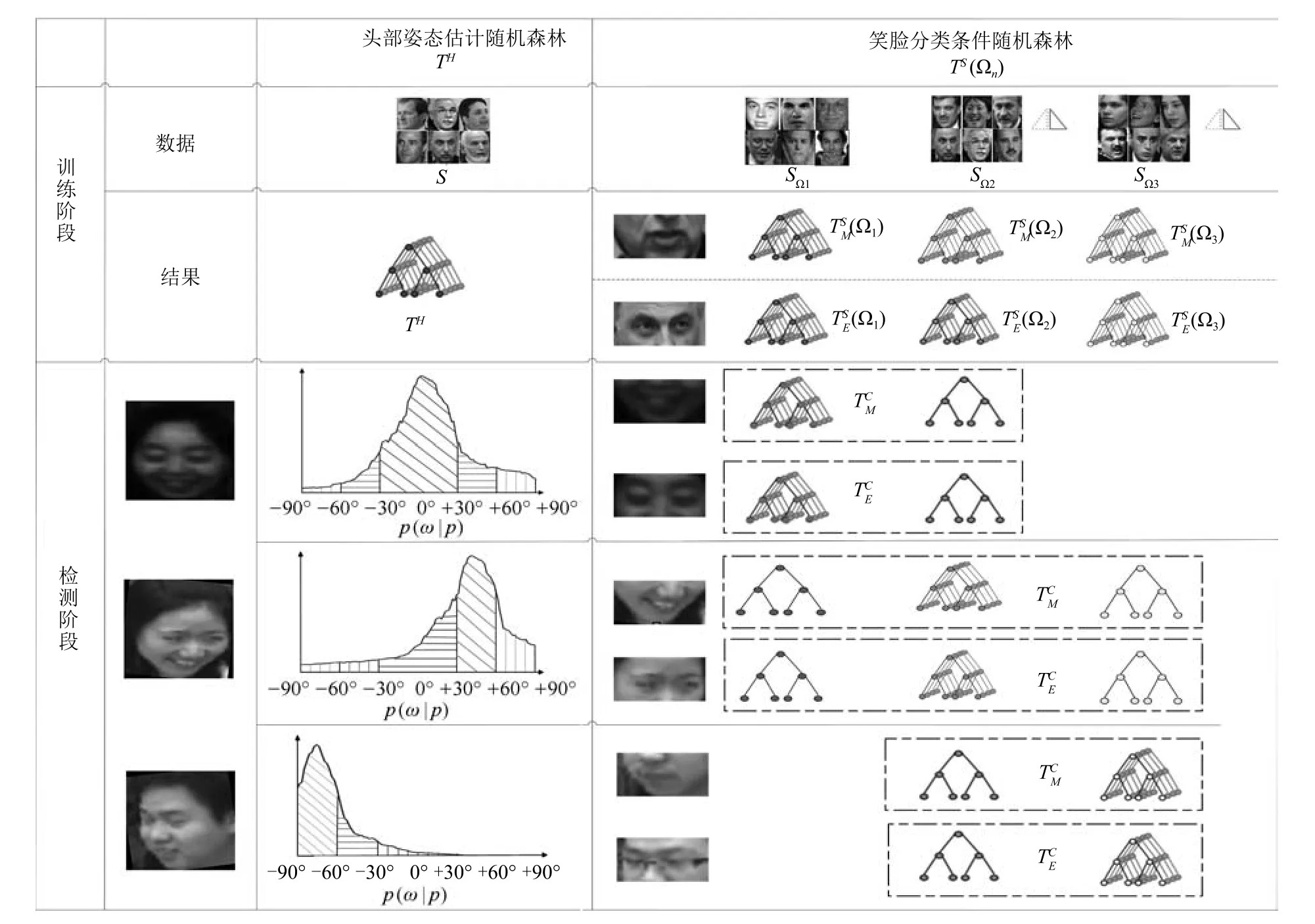
图1 基于条件随机森林的笑脸检测示意图Fig.1 Smile detection based on conditional random forests
在检测阶段,首先利用头部姿态随机森林TH估计出头部姿态;然后根据头部姿态估计结果分别从条件随机森林中随机选取相应数量的决策树动态建构随机森林和最后将检测图像输入得到笑脸检测结果.
2.1 条件随机森林的训练
条件随机森林和中的每棵决策树采用相同的方法独立训练得到.为构建每棵决策树从相应的数据子集SΩn中随机选取图像构成训练数据集,然后从每张训练图像的特定区域(眉眼区域或嘴巴区域)随机提取一系列图像子块{Pi=(θi,Ii)},其中θi∈{−1,+1}为类别标签 (笑/非笑),为一系列从图像子块上提取的特征集合.本文在实现时采用了原始灰度值,Gabor和局部二值模式(LBP)等三种特征构成特征集合.
2.1.1 二值测试
决策树的生成是一个通过二值测试不断将树节点分裂成两个子节点的迭代过程.本文定义二值测试函数ψ(P;R1,R2,f,τ)为
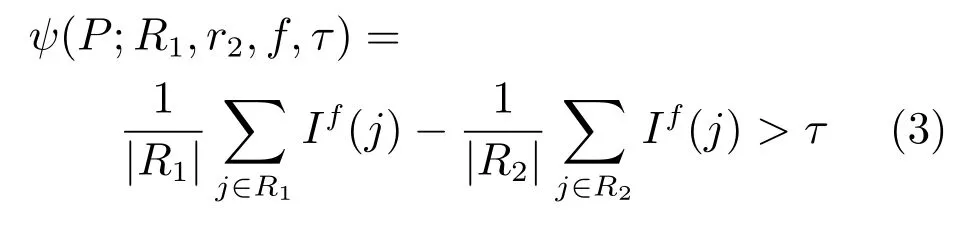
其中,R1和R2分别表示从图像子块P里随机选取的两个矩形区域,|R1|和|R2|表示矩形区域内像素的数量,If(f∈{1,2,···,F})表示随机选取的特征通道,τ为阈值.
2.1.2 不确定性测度
不确定性测度引导各节点从二值测试候选库中选择最优的二值测试,以保证能不断将当前节点分裂为不确定性降低的两个子节点.在本文中,不确定性测度定义为当前节点上图像子块的信息熵.
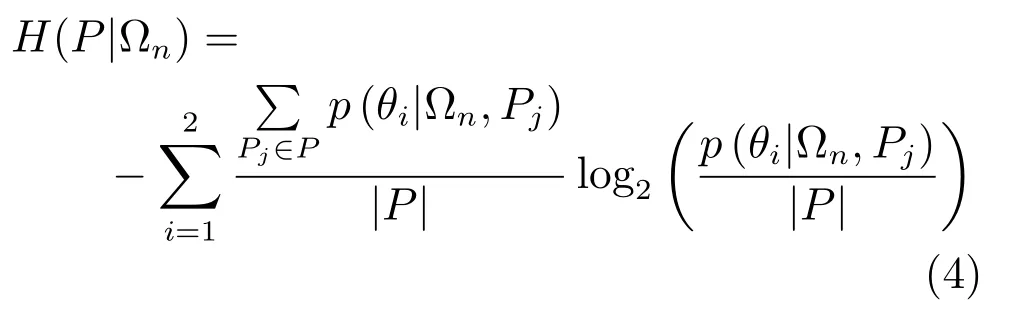
其中,P={Pj}为当前节点上所有的图像子块的集合,|·|表示集的势,p(θi|Ωn,Pj)为当前节点上头部姿态为ω∈Ωn的图像子块属于θi表情(笑/非笑)的概率.
2.1.3 树的生成步骤
条件随机森林中的每棵树独立训练生成,步骤如下:
步骤1.生成候选二值测试集Ψ={ϕk}.对于每个ϕk,其参数R1,R2,f,τ均随机生成.
步骤2.使用候选二值测试集中的每一个ϕk,将当前节点上的图像子块集P分裂为两个子集PL(ϕk)和PR(ϕk),并计算分裂后的信息增益(IG).
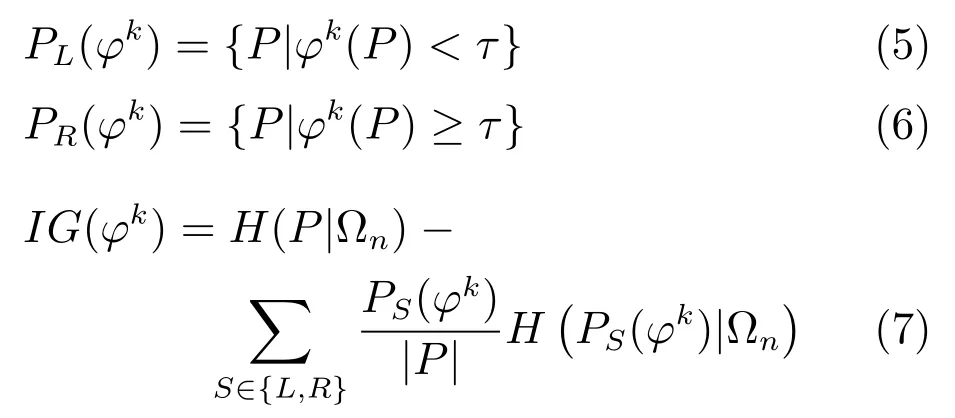
步骤3.选择使得信息增益最大的二值测试ϕ∗=argmax(IG(ϕk))将当前节点分裂为两个子节点.
步骤4.当随机树生长到最大深度或当前节点的信息增益(IG)小于阈值时,停止随机树的生长并生成叶子节点,到达叶子节点l的图像子块集记为l(P),同时将p(θ|Ωn,l(P))存储于该叶子节点上.否则返回步骤2,继续迭代分裂.
2.2 头部姿态估计
Du等[29−30]采用新的类 Haar特征和 AdaBoost进行人脸姿态的分类.Liu等[26]采用Gabor,sobel和灰度强度等特征,结合随机森林进行人脸姿态估计.本文采用与文献[26−27]类似的随机森林来估计头部姿态的水平偏向角ω.在训练生成头部姿态随机森林(TH)模型时,采用如下不确定性测度:
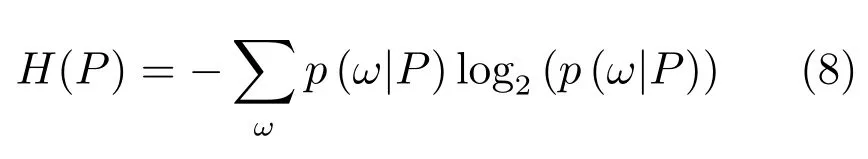
头部姿态以高斯模型的方式存储于随机森林TH的每个叶子节点l上.

其中,表示叶子节点l上图像子块代表的头部姿态均值和方差.
2.3 基于条件随机森林的笑脸分类器
在头部姿态ω∈Ωn的条件下,图像子块P属于表情θ(笑/非笑)的概率p(θ|Ωn,P)由随机森林中的所有树投票得到.
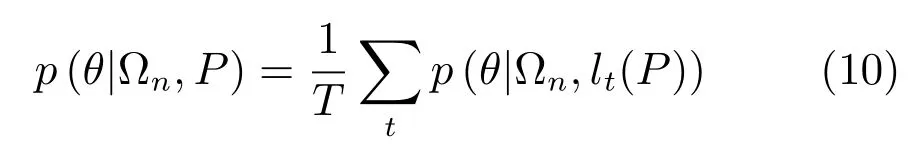
其中,T为树的数量,lt表示第t棵树上图像子块P达到的叶子节点.
在头部姿态未知的情况下,图像子块P属于表情θ(笑/非笑)的概率p(θ|P)为

由式(11)和式(12)可知,在笑脸分类时,首先根据头部姿态估计的结果从条件随机森林和中分别随机选取kn棵决策树动态构建随机森林然后由中各决策树投票得出测试图像子块P的表情θ(笑/非笑)概率p(θ|P).
从图像Ii中密集采样M个图像子块输入随机森林估计得到各个图像子块Pm属于笑脸表情的概率p(θ=+1|Pm).最终判决图像Ii属于笑脸表情的分类器为
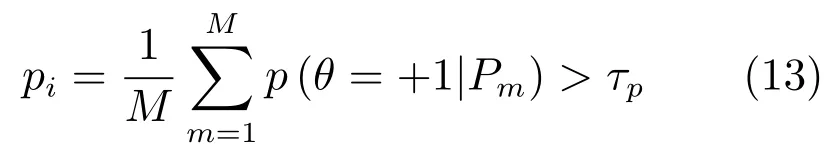
其中,τp为分类器的决策边界(即分类阈值).
2.4 基于K-Means聚类的决策边界
分类器(13)的决策边界τp从训练样本得到.常用的方法是使训练时的分类错误率最小,例如使用决策桩(Stump)[31]算法,求出分类器的决策边界τp.但由于只考虑了分类错误率,没有考虑数据在决策空间的分布,使得训练误差最小并不能保证测试时的效果达到最佳,而且还可能带来过拟合的问题.文献[26,28]采用的高斯投票法虽然考虑了数据在决策空间的分布,但要求数据在决策空间服从高斯分布.因此,本文提出一种基于K-Means聚类的决策边界法.
将训练数据子集SΩn中的所有图像Ii(Ii∈SΩn)通过条件随机森林或估计其属于笑脸的概率{p1,p2,p3,···},并将{p1,p2,p3,···}作为输入数据进行K-Means聚类以求取分类器(13)的决策边界.算法步骤为:
步骤1.初始化聚类中心:c0=min{p1,p2,p3,···},c1=max{p1,p2,p3,···}.
步骤2.计算各个数据pi到聚类中心c0和c1的距离,并将各个数据归类到距离较近的聚类中心所在的类.归类后的两类数据集合分别记为
步骤3.计算各类均值作为新的聚类中心.
步骤4.重复步骤2和步骤3,直到聚类中心不再变化.
步骤5.输出聚类结果C0和C1.
由条件随机森林的训练样本得到的决策边界由两类中离各自聚类中心最远的点共同决定,即
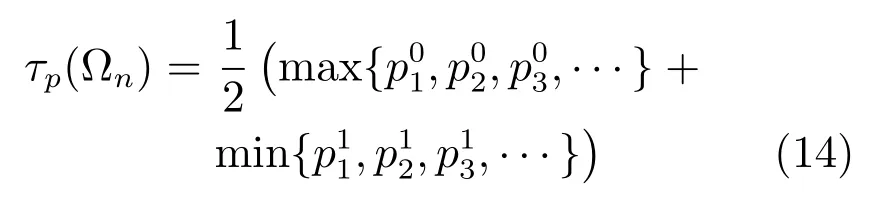
检测时,分类器(13)的决策边界为
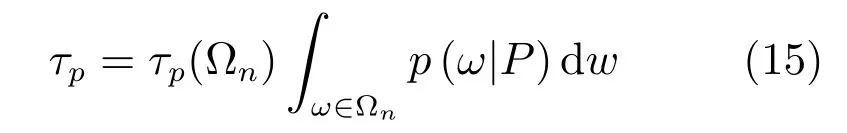
2.5 层级式笑脸检测
本文分别从嘴巴和眉眼区域采集图像子块训练两组条件随机森林构建层级式结构进行笑脸检测,流程如图2所示.
1)测试图像通过文献[32]的方法检测人脸,根据人脸几何位置关系提取嘴巴和眼睛区域.
2)从人脸区域密集采样图像子块输入头部估计随机森林TH估计头部姿态.
3)根据头部姿态估计的结果,按第2.3节方法,从条件随机森林中选取相应数量的决策树动态建构随机森林判决测试图像是否笑脸表情.若结果为笑脸,即判定该测试图像为笑脸表情.
4)若判决为非笑脸,则再次从建构随机森林作进一步的判决.
采用这种层级式的检测结构,一方面可以提高笑脸检测的准确率,另一方面由于图像子块从小部分人脸区域采集,提高了算法的运算效率.此外,采用层级式的检测结构,在大部分情况下仅使用一个分类器就能对笑脸做出判断,能够进一步减少计算量.
3 实验及结果分析
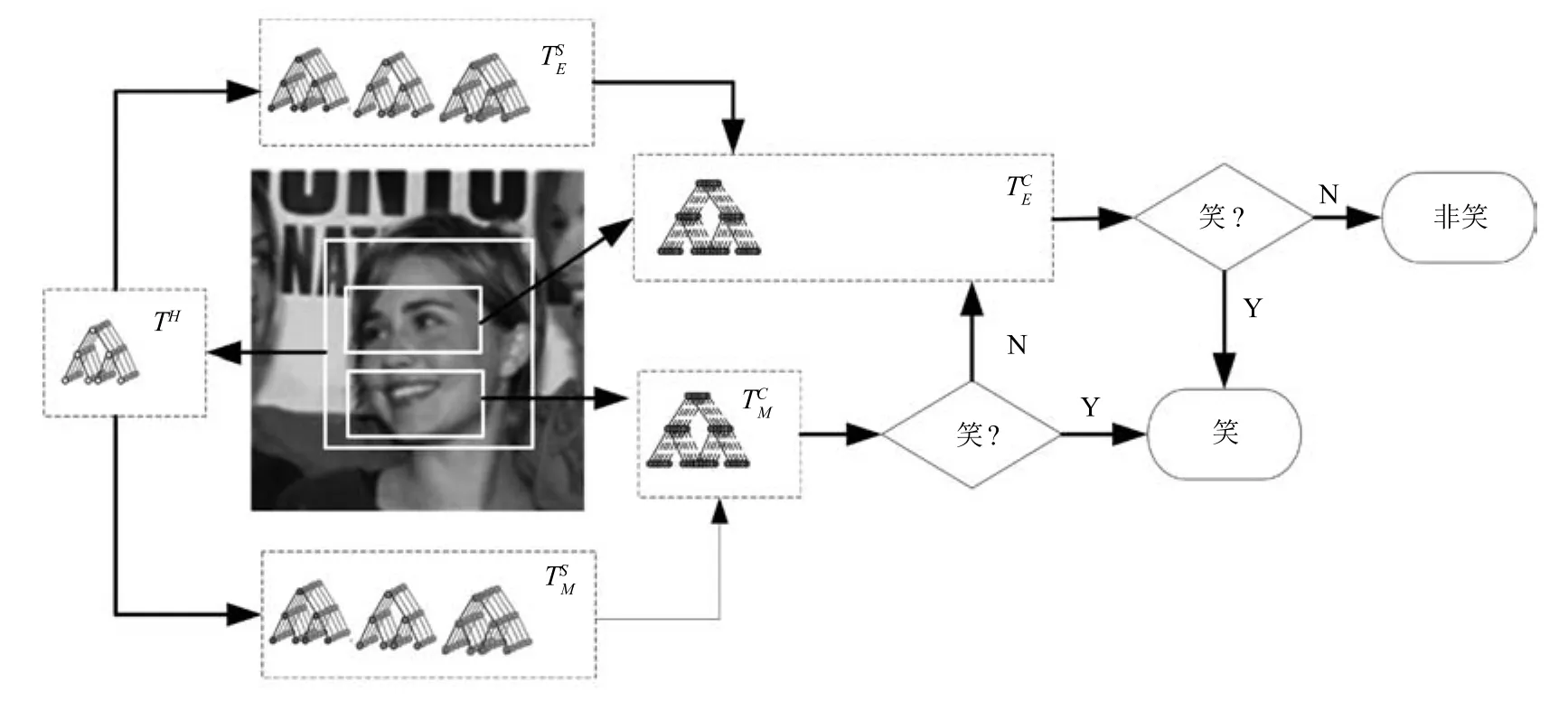
图2 层级式笑脸检测流程图Fig.2 The flowchart of the proposed smile detection method
为了评估本文方法的有效性,分别在GENKI-4K数据集[4]、LFW 数据集[24]和自备教室数据集(CCNU-Classroom)上进行了实验.GENKI-4K和LFW数据集均为从互联网收集的自然状态下拍摄的人脸图像,包含不同种族、个体、性别、光照条件、分辨率和表情等因素.GENKI-4K数据集由4000张图像组成,其头部水平偏向角范围为−20°∼+20°.LFW 数据集包含13233张人脸图像,其头部水平偏向角范围为 −90°∼+90°.CCNUClassroom数据集包含345张在自然课堂场景下采集的图像,每张图像包含8∼12个学生.CCNUClassroom数据集同样包含不同头部姿态、光照变化和低分辨率等因素.实验前,分别让5名专家对LFW和CCNU-Classroom数据集中的每个人脸做了头部姿态和笑(+1)/非笑(−1)的人工标注,然后取占优的人工标注作为客观标注(Ground truth).
3.1 训练
在训练头部姿态估计随机森林TH时,设置树的数量为60,树的最大深度为15,二值测试候选库的大小为2000.随机森林TH的训练数据集为从LFW数据集中随机选取的2000张图像.选取训练图像后,抠取人脸区域并归一化为125像素×125像素,然后从每个人脸区域上随机采样200个大小为30像素×30像素的图像子块用于训练.
在训练笑脸分类条件随机森林和时,设置树的最大深度为15,二值测试候选库的大小为1500.从LFW 数据集中随机选取5518张正脸(水平偏向角为−30°∼+30°)图像用于训练和1883张微侧脸 (水平偏向角为 −60°∼−30° 及 +30°∼+60°)用于训练4507张侧脸图像(水平偏向角为 −90°∼−60° 及 +60°∼+90°) 用于训练为进行对比实验,除和外,从整个人脸区域采样图像子块训练了一组条件随机森林,记为训练时,人脸区域归一化为125像素×125像素;嘴巴区域归一化为120像素×60像素,图像子块的大小为30像素×15像素,且从每张图像上采样的图像子块个数为150;眉眼区域归一化为120像素×40像素,图像子块的大小为30像素×10像素,且从每张图像上采样的图像子块个数为100.实验发现,在所有训练参数中,树的数量对笑脸分类准确率的影响最大.图3为在各训练数据子集上树的数量与笑脸分类准确率关系曲线.随着树的数量的增加,笑脸分类的准确率也随之上升,最终趋于平稳.因此,在后续实验中笑脸分类随机森林树的数量统一取为40.
3.2 实验结果及分析
测试集包括GENKI-4K数据集的4000张图像、LFW 数据集中未参与训练的2000张图像和CCNU-Classroom 数据集的345张图像(约3500个人脸).本文方法在三个数据集上的部分实验结果如图4所示.实验结果表明:
1)本文方法能有效处理非约束环境下包含头部姿态多样性、低分辨率和光照变化等多种挑战因素的自然笑脸检测问题.
2)本文方法具备良好的鲁棒性.在一个数据集上训练的算法应用于其他独立采集的数据集仍能保持良好的性能.
3.2.1 不同笑脸检测算法的比较
进行了两组对比实验:1)在GENKI-4K数据集上进行,对比在头部姿态变化范围较小情况下的笑脸检测效果;2)在LFW和CCNU-Classroom数据集上进行,对比在头部姿态变化范围较大情况下的笑脸检测效果.
将本文方法与Shan[15]和An等[16]在GENKI-4K数据集上进行对比实验.文献[15]采用像素对灰度差值作为特征,使用AdaBoost分类器.文献[16]分别采用了LBP和HOG特征,使用线性判别式分析 (Linear discriminant analysis,LDA)、SVM 和ELM三种分类器.对比结果如表1所示,本文方法优于文献[15−16].在头部姿态变化范围较小的情况下,本文方法在使用灰度、Gabor和LBP三种特征时取得了91.14%的准确率,在仅使用灰度或LBP特征时的准确率分别为88.36%和86.99%.

图3 决策树的数量与笑脸分类准确率的关系Fig.3 The accuracies for different numbers of trees in CRF
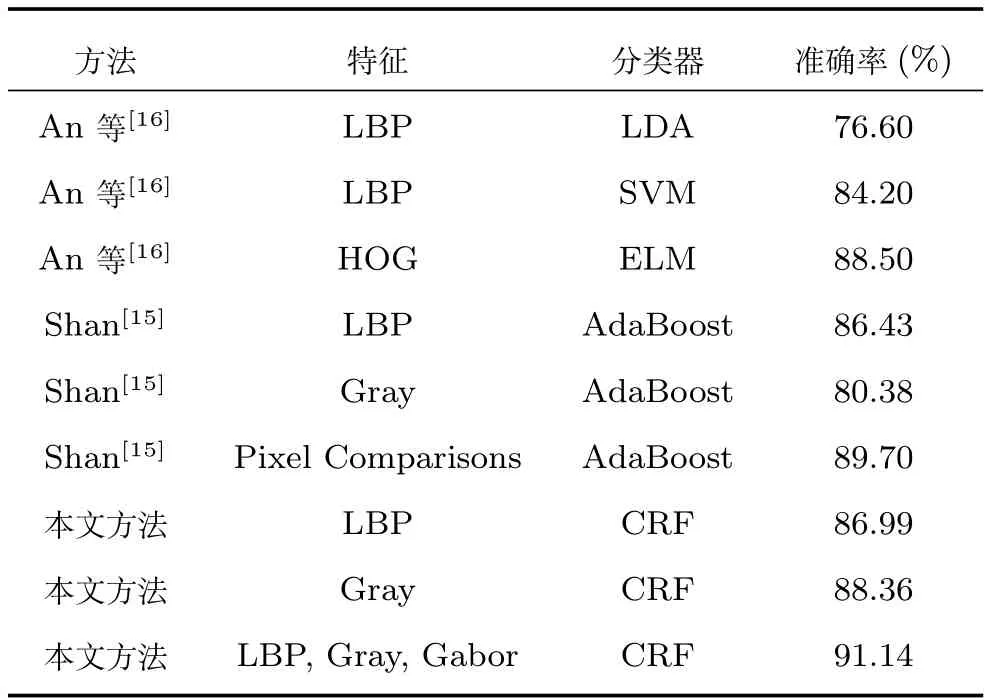
表1 本文方法与文献[15−16]在GENKI-4K数据集上的比较Table 1 The proposed approach compared with[15−16]on GENKI-4K dataset
为了验证各种笑脸检测方法在头部姿态变化较大情况下的性能,将本文方法、基于支持向量机(SVM)和基于随机森林(Random forest,RF)、基于AdaBoost的笑脸检测方法分别在LFW 和CCNU-Classroom两个数据集上进行对比实验.实验过程中,本文方法严格按照图2流程进行.SVM采用libSVM[33],RF采用文献[27]的代码实现,AdaBoost采用文献[15]的方法实现.实验时,将人脸区域归一化为125像素×125像素,并将从人脸上抠取的眉眼区域或嘴巴区域分别归一化为120像素×40像素和120像素×60像素.为了比较的公平性,四种方法均采用原始灰度值、Gabor和LBP三种特征,其中CRF和RF及AdaBoost在每次分裂或每次训练弱分类器时随机从三种特征选择一种特征.在训练SVM时将从原图像上取得的灰度值、Gabor和LBP特征连接成一个长向量(29万维),然后采用主成分分析法(Principal component analysis,PCA)将其压缩为5000维(保留99.9%的能量).四种方法均从嘴巴和眉眼区域采集图像块,并训练两个分类器组成层级式结构进行笑脸检测.在LFW和CCNU-Classroom数据集上头部姿态估计统计结果见表2,四种笑脸检测算法的实验结果见表3(见本页下方).

图4 本文方法的笑脸检测结果Fig.4 The exemplar results of the proposed smile detection method
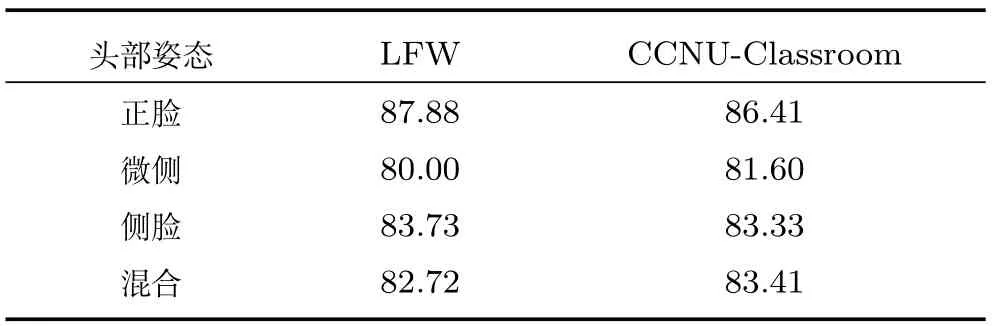
表2 头部姿态估计在LFW和CCNU-Classroom数据集上的准确率(%)Table 2 Accuracies of head pose estimation on LFW and CCNU-Classroom datasets(%)
由于本文方法将整个数据集按头部姿态划分为3个数据子集,降低了各个数据子集内样本的内类差异,使得分类器能更有效和更高效地描述训练数据.本文方法在LFW和CCNU-Classroom数据集上分别取得了90.73%和85.17%的准确率,优于基于SVM、AdaBoost和RF的方法.此外,本文的笑脸检测方法的准确率略微高于头部姿态估计后的准确率,说明虽然头部姿态估计的错误会在一定程度上影响笑脸的检测,但由于进行头部姿态划分后在各姿态条件下笑脸检测性能的极大提升,以及各姿态条件下的笑脸检测器对姿态估计错误的笑脸有一定的鲁棒性,因此整体上提高了笑脸检测的性能.
3.2.2 不同图像子块采样方式的比较
为比较不同图像子块采样方式的差异,在LFW数据集上采用四种子采样方式进行实验.
1)从整个人脸区域随机采样图像子块,然后仅使用条件随机森林动态构建随机森林进行笑脸检测;
2)仅从嘴巴区域随机采样图像子块,然后使用条件随机森林动态构建随机森林进行笑脸检测;
3)仅从眉眼区域随机采样图像子块,然后使用条件随机森林动态构建随机森林进行笑脸检测;

表3 不同笑脸检测算法在LFW和CCNU-Classroom数据集上的准确率(%)Table 3 Comparisons of accuracies of different smile detection algorithms on LFW and CCNU-Classroom datasets(%)
4)从嘴巴和眉眼区域随机采样图像子块,然后按图2流程使用条件随机森林和动态构建随机森林组成层级式结构进行笑脸检测.
为避免其他因素的影响,实验过程中头部姿态直接采用客观标注,决策边界统一采用本文提出的K-Means聚类法确定.采用四种图像子块采样方式对应的笑脸检测准确率见表4,从嘴巴和眉眼区域随机采样图像子块组成层级式分类器取得的效果最好.
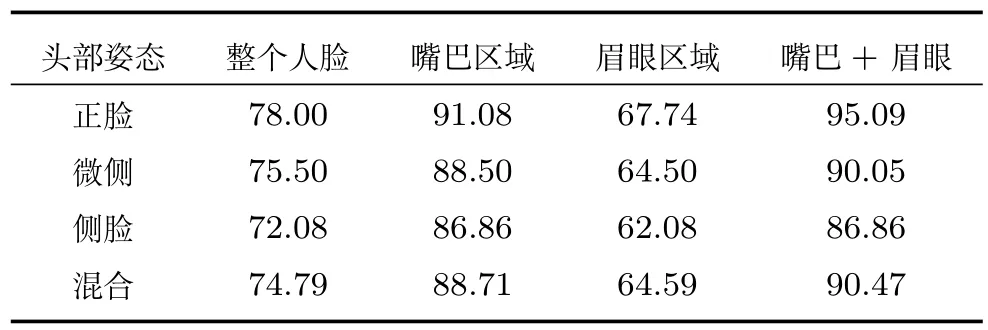
表4 不同图像子块采样方式在LFW数据集上的笑脸检测准确率(%)Table 4 Accuracies of smile detection with different image sub-regions on LFW dataset(%)
3.2.3 不同嘴巴和眼睛区域定位方法的比较
为比较不同嘴巴和眼睛区域的定位方法对笑脸检测的影响,分别使用人脸几何位置关系粗略确定嘴巴、眉眼区域和文献[27]提出的人脸特征点定位方法来精确确定嘴巴区域和眉眼区域,在LFW 数据集上进行实验.为避免其他因素的干扰,实验时头部姿态直接采用客观标注.采用两种嘴巴和眉眼区域的定位方法对应的笑脸检测准确率见表5.精确定位嘴巴区域和眉眼区域可以进一步提升本文方法的笑脸检测准确率.但精确定位方法会带来更多的计算量.与使用粗略定位相比,使用精确定位在LFW数据集上进行笑脸检测每幅图像的平均耗时增加19ms.
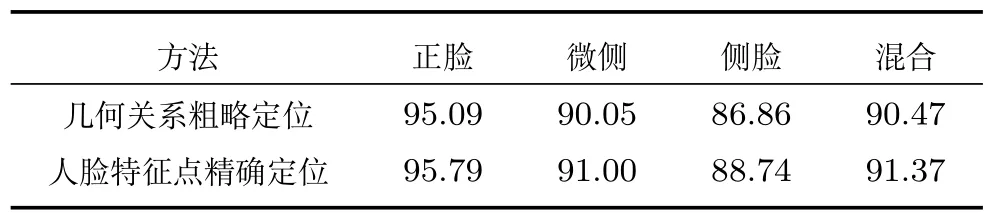
表5 不同嘴巴和眉眼区域定位方法的笑脸检测准确率(%)Table 5 Accuracies of smile detection using different approaches to locate eyes and mouth regions(%)

表6 使用不同决策边界方法对应的笑脸检测准确率(%)Table 6 Accuracies of smile detection using different decision boundary methods(%)
3.2.4 不同决策边界确定方法的比较
为比较不同决策边界方法的优劣,分别使用本文提出的K-Means聚类、高斯投票[26−27]和决策桩[31]三种分类决策边界确定方法,在LFW数据集和CCNU-Classroom数据集上进行实验.为避免其他因素的干扰,实验时头部姿态直接采用客观标注,图像子块从嘴巴区域和眉眼区域采集,并按图2流程进行笑脸检测.采用三种决策边界确定方法对应的笑脸检测准确率见表6.本文提出的K-Means聚类法取得了最好的效果,高斯投票法次之,决策桩的效果最差.
4 结论
本文提出一种基于条件随机森林的自然笑脸检测方法.以头部姿态作为隐含条件划分数据空间,构建了基于条件随机森林的笑脸检测模型,降低了数据的内类差异,因此有效抑制了非约束环境下头部姿态多样性对笑脸检测带来的不利影响.提出了一种基于K-Means的分类边界决策方法.相比随机森林算法常用的平均值法或多高斯法等投票方法,基于K-Means的分类边界法考虑了数据在决策空间的分布,因此具备更高的笑脸分类准确率.同时,分别从嘴巴区域和眉眼区域采集图像子块训练两组条件随机森林构成层级式结构进行笑脸检测,提高了准确率.实验结果表明,本文方法对非约束环境下的自然笑脸检测具备较好的准确性和鲁棒性.在未来的工作中,将尝试结合基于AUs的方法来自动选取对笑脸检测最有效的区域,以进一步提高笑脸检测的准确率.
References
1 Sénéchal T,Turcot J,el Kaliouby R.Smile or smirk?Automatic detection of spontaneous asymmetric smiles to understand viewer experience.In:Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition(FG).Shanghai,China:IEEE,2013.1−8
2 Chen J Y,Luo N,Liu Y Y,Liu L Y,Zhang K,Kolodziej J.A hybrid intelligence-aided approach to affect-sensitive e-learning.Computing,2016,98(1−2):215−233
3 Shah R,Kwatra V.All smiles:automatic photo enhancement by facial expression analysis.In: Proceedings of the 9th European Conference on Visual Media Production(CVMP).London,UK:ACM,2012.1−10
4 Whitehill J,Littlewort G,Fasel I,Bartlett M,Movellan J.Toward practical smile detection.IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(11):2106−2111
5 Sariyanidi E,Gunes H,Cavallaro A.Automatic analysis of facial affect:a survey of registration,representation,and recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(6):1113−1133
6 Sun Xiao,Pan Ting,Ren Fu-Ji.Facial expression recognition using ROI-KNN deep convolutional neural networks.Acta Automatica Sinica,2016,42(6):883−891(孙晓,潘汀,任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报,2016,42(6):883−891)
7 Tong Y,Chen J X,Ji Q.A uni fied probabilistic framework for spontaneous facial action modeling and understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(2):258−273
8 Vick S J,Waller B M,Parr L A,Pasqualini M C S,Bard K.A cross-species comparison of facial morphology and movement in humans and chimpanzees using the facial action coding system(FACS).Journal of Nonverbal Behavior,2007,31(1):1−20
9 Valstar M,Pantic M.Fully automatic recognition of the temporal phases of facial actions.IEEE Transactions on Systems,Man,and Cybernetics,Part B(Cybernetics),2012,42(1):28−43
10 Xie Lun,Lu Ya-Nan,Jiang Bo,Sun Tie,Wang Zhi-Liang.Expression automatic recognition based on facial action units and expression relationship model.Transactions of Beijing Institute of Technology,2016,36(2):163−169(解仑,卢亚楠,姜波,孙铁,王志良.基于人脸运动单元及表情关系模型的自动表情识别.北京理工大学学报,2016,36(2):163−169)
11 Wang Lei,Zou Bei-Ji,Peng Xiao-Ning.Tunneled latent variables method for facial action unit tracking.Acta Automatica Sinica,2009,35(2):198−201(王磊,邹北骥,彭小宁.针对表情动作单元跟踪的隧道隐变量法.自动化学报,2009,35(2):198−201)
12 Yang P,Liu Q S,Metaxas D N.Exploring facial expressions with compositional features.In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).San Francisco,CA,USA:IEEE,2010.2638−2644
13 Walecki R,Rudovic O,Pavlovic V,Pantic M.Variablestate latent conditional random fields for facial expression recognition and action unit detection.In:Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition(FG).Ljubljana,Slovenia:IEEE,2015.1−8
14 Shimada K,Matsukawa T,NoguchiY,Kurita T.Appearance-based smile intensity estimation by cascaded support vector machines.In:Proceedings of the 2010 Revised Selected Papers,Part I Asian Conference on Computer Vision(ACCV).Queenstown,New Zealand:Springer,2010.277−286
15 Shan C F.Smile detection by boosting pixel differences.IEEE Transactions on Image Processing,2012,21(1):431−436
16 An L,Yang S F,Bhanu B.Efficient smile detection by extreme learning machine.Neurocomputing,2015,149:354−363
17 Huang G B,Zhou H M,Ding X J,Zhang R.Extreme learning machine for regression and multiclass classi fication.IEEE Transactions on Systems,Man,and Cybernetics,Part B(Cybernetics),2012,42(2):513−529
18 Gao Y,Liu H,Wu P P,Wang C.A new descriptor of gradients self-similarity for smile detection in unconstrained scenarios.Neurocomputing,2016,174:1077−1086
19 Liu H,Gao Y,Wu P.Smile detection in unconstrained scenarios using self-similarity of gradients features.In:Proceedings of the 2014 IEEE International Conference on Image Processing(ICIP).Paris,France:IEEE,2014.1455−1459
20 El Meguid M K A,Levine M D.Fully automated recognition of spontaneous facial expressions in videos using random forest classi fiers.IEEE Transactions on Affective Computing,2014,5(2):141−154
21 Liu Shuai-Shi,Tian Yan-Tao,Wan Chuan.Facial expression recognition method based on gabor multi-orientation features fusion and block histogram.Acta Automatica Sinica,2011,37(12):1455−1463(刘帅师,田彦涛,万川.基于Gabor多方向特征融合与分块直方图的人脸表情识别方法.自动化学报,2011,37(12):1455−1463)
22 Dapogny A,Bailly K,Dubuisson S.Pairwise conditional random forests for facial expression recognition.In:Proceedings of the 2015 IEEE International Conference on Computer Vision(ICCV).Santiago,USA:IEEE,2015,3783−3791
23 Yin L J,Wei X Z,Sun Y,Wang J,Rosato M J.A 3D facial expression database for facial behavior research.In:Proceedings of the 7th IEEE International Conference on Automatic Face and Gesture Recognition.Southampton,Britain:IEEE,2006.211−216
24 Huang G B,Mattar M,Berg T,Learned-Miller E.Labeled faces in the wild:a database for studying face recognition in unconstrained environments.Technical Report,University of Massachusetts,USA,2007.
25 Breiman L.Random forests.Machine Learning,2001,45(1):5−32
26 Liu Y Y,Chen J Y,Su Z M,Luo Z Z,Luo N,Liu L Y,Zhang K.Robust head pose estimation using Dirichlet-tree distribution enhanced random forests.Neurocomputing,2015,173:42−53
27 Sun M,Kohli P,Shotton J.Conditional regression forests for human pose estimation.In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Providence,RI,USA:IEEE,2012.3394−3401
28 Dantone M,Gall J,Fanelli G,Van Gool L.Real-time facial feature detection using conditional regression forests.In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Providence,RI,USA,2012.2578−2585
29 Du S Y,Zheng N N,You Q B,Wu Y,Yuan M J,Wu J J.Rotated Haar-Like features for face detection with in-plane rotation.In:Proceedings of the 12th International Conference,Virtual Systems and Multimedia(VSMM).Xi0an,China:Springer,2006.128−137
30 Du S Y,Liu J,Liu Y H,Zhang X T,Xue J R.Precise glasses detection algorithm for face with in-plane rotation.Multimedia Systems,2017,23(3):293−302
31 Wayne I,Langley P.Induction of one-level decision trees.In:Proceedings of the 9th International Workshop on Machine Learning.San Francisco,CA,USA:Morgan Kaufmann,1992.233−240
32 Viola P,Jones M J.Robust real-time face detection.International Journal of Computer Vision,2004,57(2):137−154
33 Chang C C,Lin C J.Trainingv-support vector classi fiers:theory and algorithms.Neural Computation,2001,13(9):2119−2147
