利用深度卷积神经网络提高未知噪声下的语音增强性能
2018-05-15袁文浩孙文珠夏斌欧世峰
袁文浩 孙文珠 夏斌 欧世峰
语音增强是噪声环境下语音信号处理的必要环节[1].传统的基于统计的语音增强方法一般通过假设语音和噪声服从某种分布或者具有某些特性来从含噪语音中估计纯净语音,这些方法对于平稳噪声具有较好的处理效果,但在高度非平稳噪声和低信噪比情况下其处理性能将会急剧恶化[2−5].
近年来,深度学习成为了机器学习领域的研究热点,深度神经网络(Deep neural network,DNN)在图像分类和语音识别领域的成功应用为解决复杂多变噪声环境下的语音增强问题提供了思路.与其他机器学习方法相比,深度神经网络具有更加强大的学习能力,通过使用大量纯净语音和含噪语音样本数据进行模型的训练,能够有效提高语音增强方法对不同噪声的适应能力,相比传统有监督方法具有更强的泛化能力,对没有经过训练的未知噪声也有比较好的处理效果.基于深度神经网络的语音增强方法的有效性已在很多文献中得到证明,文献[6]训练DNN作为一个二值分类器来估计含噪语音的IBM(Ideal binary mask),克服了基于核函数的机器学习方法对大规模数据存在的计算复杂度难题,提高了对未知噪声的适应能力,取得了优于传统方法的语音增强性能.文献[7]采用更加有效的IRM(Ideal ratio mask)代替IBM 作为训练目标,并通过实验证明了相比其他方法,基于深度神经网络的语音增强方法明显提高了增强语音的质量和可懂度.不同于上述方法中使用的基于掩蔽的训练目标,Xu等将纯净语音的对数功率谱(Logarithmic power spectra,LPS)作为训练目标,以含噪语音的对数功率谱作为训练特征,通过训练DNN得到一个高度非线性的回归函数,来建立含噪语音对数功率谱与纯净语音对数功率谱之间的映射关系[8];并在文献[9]中采用Global variance equalization、Dropout training和Noise-aware training三种策略进一步改善该方法,使其在低信噪比、非平稳噪声环境下的语音增强性能相比传统方法有了显著提升.为了在语音增强时充分考虑相位信息,文献[10]提出了复数域的掩蔽目标cIRM(Complex IRM),通过同时估计掩蔽目标的实部和虚部,相比使用其他训练目标进一步提高了语音增强性能.
除了设计不同的训练特征和训练目标,提高未知噪声下语音增强性能的另外一种重要思路是提高训练集中噪声的多样性.文献[9,11]分别采用包含104类和115类噪声的训练集,提高了DNN对未知噪声的处理能力;文献[12−13]更是通过训练包含10000种不同噪声的DNN来提高对未知噪声的泛化能力,主客观实验结果表明采用大数据量的训练集能显著提高未知噪声下的语音可懂度.另外,与直接增加训练集噪声类型数量的方法不同,文献[14]采用对有限种类的噪声施加不同的扰动项的方式来提高噪声特性的多样性,实验结果表明该方法同样能有效提高DNN的泛化能力.
上述基于深度神经网络的语音增强方法尽管在训练目标的设计、训练特征的选择以及训练集的规模上各有不同,但是它们所采用的网络结构均是全连接的DNN.为了进一步提高未知噪声下的语音增强性能,本文考虑使用深度学习的另外一种重要的网络结构—深度卷积神经网络(Deep convolutional neural network,DCNN)来进行语音增强.深度卷积神经网络在图像识别等分类任务上已经取得了巨大成功[15],其在二维图像信号处理上相比DNN表现出了更好的性能.语音和噪声信号在时域的相邻帧和频域的相邻频带之间都具有很强的相关性,因此在基于深度神经网络的语音增强方法中,为了充分考虑时域和频域的上下文关系,一般采用相邻多帧的特征作为网络的输入,这种矩阵形式的输入在时间和频率两个维度上的局部相关性与图像中相邻像素之间的相关性非常类似.如图1和图2所示,假设使用连续5帧的对数功率谱作为网络的输入,当网络结构为全连接的DNN时,由于其输入层只有一个维度,因此要将包含时频结构信息的矩阵转换为向量作为输入;而当网络结构为DCNN时,则可以直接使用矩阵作为输入,不破坏时频结构.可见,得益于DCNN在二维平面上的局部连接特性,使其相比DNN能够更好地表达网络输入在时间和频率两个维度的内在联系,因而在语音增强时能够更充分地利用语音和噪声信号的时频相关性.另外,DCNN通过权值共享极大减少了神经网络需要训练的参数的个数,具有更好的泛化能力,对未训练噪声理论上应该有更好的处理性能.
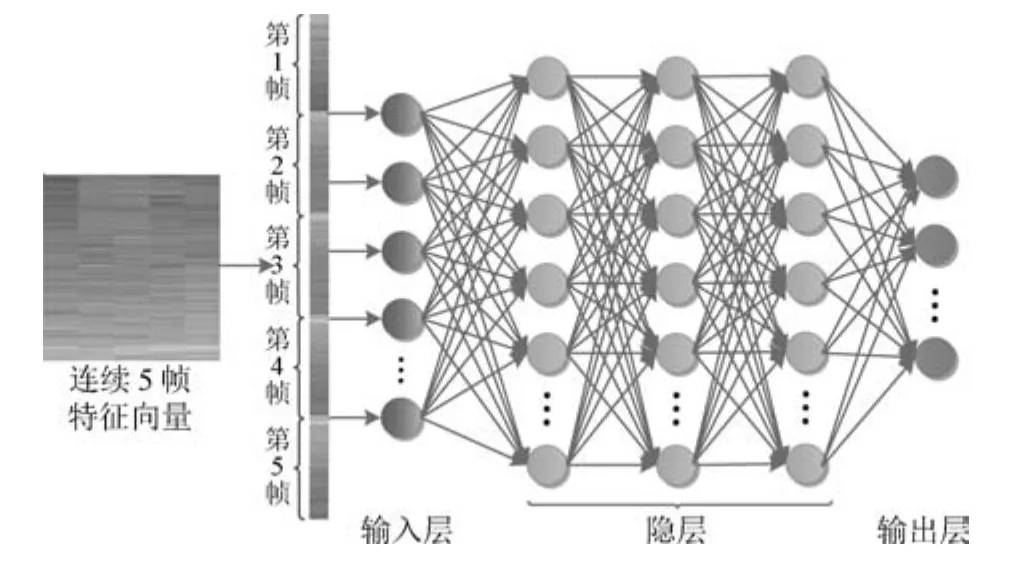
图1 DNN结构示意图Fig.1 Schematic diagram of DNN
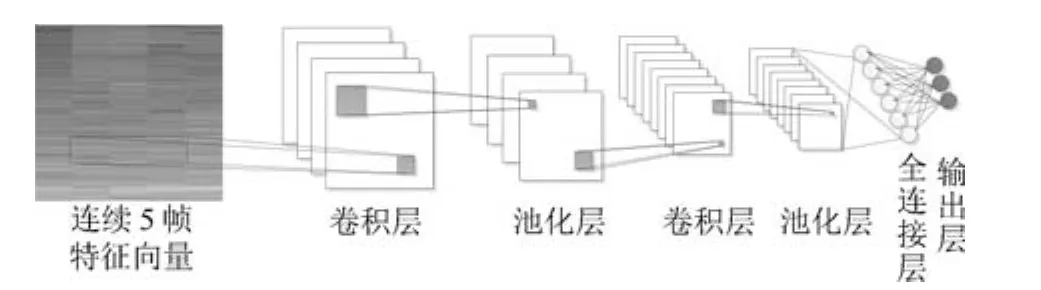
图2 DCNN结构示意图Fig.2 Schematic diagram of DCNN
实际上,对于语音信号处理,CNN(Convolutional neural network)以及DCNN已经在语音识别任务中得到成功应用,取得了超越DNN/HMM系统的语音识别性能,证明了其对于语音信号同样具有较好的特征提取能力[16−18],文献[19−23]更是采用极深层的卷积神经网络显著提高了语音识别性能.但是在语音识别任务中,DCNN的最后一层一般采用Softmax来预测状态概率,因此本质上也是一个分类问题;而基于深度神经网络的语音增强方法一般将语音增强归结为回归问题进行解决,因此传统的网络结构并不适合.文献[24]以幅度谱向量作为训练特征和训练目标,采用不包含全连接层的FCNN(Fully convolutional neural network)来进行语音增强,虽然大幅度降低了训练参数的规模,但是相比DNN并没有明显提高增强后语音的质量和可懂度;文献[25]采用CNN对LPS特征进行建模,通过同时学习纯净语音和信噪比,研究了SNR−aware算法对语音增强性能的影响,但是并没有对不同网络结构的语音增强性能进行深入分析.为了提高语音增强性能,特别是未知噪声下的语音增强性能,本文通过对不同网络结构的语音增强性能进行对比与分析,设计针对语音增强问题的合理DCNN网络结构,提出基于深度卷积神经网络的语音增强方法;最后通过实验度量增强语音的质量和可懂度,对方法在未知噪声下的语音增强性能进行客观评价.
1 训练特征与训练目标
假设含噪语音y由纯净语音s和加性噪声d组成,

语音增强的目的就是在已知y的条件下得到s的估计值,假设y,s和在第n帧的短时傅里叶变换(Short-time Fourier transform,STFT)形式分别为Yn,kexp(jαn,k),Sn,kexp(jϕn,k)和其中k=1,2,···,K是频带序号,忽略相位信息,对第n帧的信号而言,STFT域上的语音增强任务就是最小化如下的误差函数
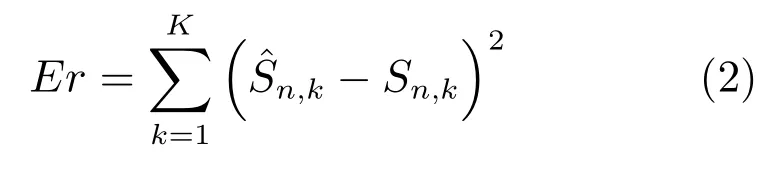
令Sn和分别表示纯净语音第n帧的幅度谱向量及其估计值,该误差函数可以改写为
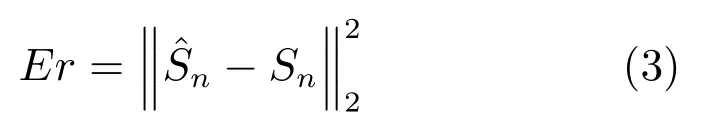
基于深度学习的语音增强的基本思想可以描述为:通过训练网络参数集合θ构造一个高度复杂的非线性函数fθ,使得误差函数

最小,从而得到目标输出

其中

表示第n帧的训练特征,由以第n帧为中心的共(2N+1)帧的含噪语音的幅度谱向量构成,(2N+1)即为输入窗长.
为了构造类似于图像处理DCNN的网络输入,同时在保证时域语音信号重构简单的前提下提高网络性能,我们采用对数运算对Xn和Sn的范围进行缩放,设计如下的训练特征和训练目标

其中,Zn和Tn是幅度谱的变换形式,且其值不小于0,因此称其为非负对数幅度谱(Nonnegative logarithmic amplitude spectra,NLAS).
DCNN采用小批量梯度下降法进行训练,本文使用的损失函数定义为
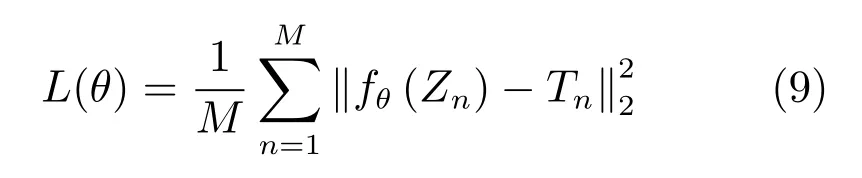
其中,M代表网络训练所采用的Mini-batch的大小.
网络训练完成后,在进行语音增强时,对第n帧的纯净语音sn,使用训练目标的估计值与含噪语音第n帧的相位谱向量αn进行时域信号的重构

n即为增强后的语音信号.
2 网络结构
借鉴在图像识别中使用的典型DCNN的结构,依据本文所采用的训练特征和训练目标,构造如图3所示的DCNN.可见,本文设计的网络结构与典型DCNN的最大不同在于最后几层全连接层的设计,典型DCNN在全连接层后要经过一个Softmax层来计算分类结果,而本文网络则是直接通过全连接层计算目标向量.更深的网络结构、更多的节点数量或滤波器数量能够提高网络的性能,但同时也增加了网络的复杂程度和训练难度,对于本文实验,依据训练集的数据规模,通过权衡网络性能及训练难度之间的关系,我们采用了包含3个卷积层和2个全连接层的网络结构,其中全连接层的节点数量设为1024,卷积层滤波器的个数除第一层为64外,其余设为128.
具体的网络结构设计如下:
1)输入层
网络的输入是多帧非负对数幅度谱向量构成的特征矩阵.
2)卷积层
本文网络包含3个卷积层,第一层采用的卷积滤波器大小为7×7,其余两层的滤波器大小为3×3,步长均设为1×1.
3)Batch normalization层
在每个卷积层和激活函数层之间都有一个Batch normalization层.
4)池化层
3个激活函数层后是3个池化层,均采用Maxpooling,滤波器大小3×3,步长为2×2.
5)全连接层
3个卷积层之后是2个全连接层(Fully connected)和2个激活函数层.
6)输出层
网络的最后一层是129个节点的全连接层,对应129维的目标输出.

图3 本文DCNN的结构框图Fig.3 Structure diagram of the proposed DCNN
3 实验与结果分析
3.1 实验配置
实验所用的纯净语音全部来自TIMIT语音数据库[26],所用的噪声包含俄亥俄州立大学Perception and Neurodynamics实验室的100类噪声[27],以及文献[11]中的15类噪声.语音和噪声信号的采样频率均转换为8kHz,短时傅里叶变换的帧长为32ms(256点),帧移为16ms(128点),相应的非负对数幅度谱特征向量和训练目标的维度为129.训练集由100000段含噪语音(约80小时)构成,使用TIMIT语音库的Training集的4620段纯净语音和115类噪声按照−5dB、0dB、5dB、10dB和15dB五种不同的信噪比合成得到.每段含噪语音的具体合成方法如下:每次从4620段纯净语音中随机选取1段,并从115类噪声中随机选取1类,然后将该类噪声的随机截取片段按照从5种信噪比中随机选取的1种混入语音中.测试集采用TIMIT语音库的Core test集的192段语音合成,噪声数据采用来自Noisex92噪声库的与训练集噪声完全不同的4类未知噪声[28],分别是Factory2、Buccaneer1、Destroyer engine、HF channel噪声.对于每一类噪声,将192段语音分别按照−5dB、0dB和5dB的全局信噪比与该类噪声的随机截取片段进行混合,4类噪声合成的测试集总共包含2304(192×3×4)段含噪语音.
本文通过对增强语音进行客观评价来比较不同方法的语音增强性能,主要采用PESQ(Perceptual evaluation of speech quality)作为指标来评价增强语音的质量[29],并采用STOI(Short time objective intelligibility)作为指标来评价增强语音的可懂度[30].PESQ即语音质量感知评估是ITU-T(国际电信联盟电信标准化部)推荐的语音质量评估指标,其得分范围为−0.5∼4.5,越高的得分表示越高的语音质量.STOI即短时客观可懂度,则主要衡量语音的可懂度,其得分范围为0∼1,越高的得分表示语音具有越好的可懂度.
下面通过一系列实验对本文提出的DCNN的语音增强性能以及可能影响网络性能的关键因素进行分析.
3.2 DNN与DCNN的比较
为了验证本文所提出的DCNN在语音增强中的有效性,我们将其与DNN进行比较.作为对比的DNN具有5个隐层,每个隐层有1024个节点,激活函数为ReLU;为了防止过拟合,提高泛化能力,每个隐层后面均伴有一个Dropout层,Dropout的比例为0.2.DNN和DCNN均采用式(7)定义的非负对数幅度谱作为训练目标,并采用式(8)定义的训练特征作为网络的输入;其中,对于DCNN,为了适应其网络结构,输入窗长设为15帧;对于DNN,为了更好地进行对比,其输入窗长分别设为与文献[9]相同的11帧(DNN_11F),以及与DCNN相同的15帧(DNN_15F).mini-batch的大小均为128,冲量因子均设为0.9,迭代次数均为20.本文的所有网络均使用微软的Cognitive Toolkit进行训练[31].
首先通过比较DNN和DCNN的训练误差和测试误差来分析两种网络的性能,图4给出了不同训练阶段所对应的训练集和测试集的均方误差,可见,两种DNN在训练集和测试集上的均方误差(MSE)都十分接近,这表明两种DNN具有相似的语音增强性能;而DCNN在训练集和测试集上的均方误差都要明显小于两种DNN,表明DCNN具有更好的语音增强性能.
为了进一步比较DNN和DCNN的语音增强性能,我们对测试集含噪语音通过三种方法进行增强后得到的增强语音的平均语音质量和可懂度进行比较,表1和表2分别给出了在4类不同噪声和3种不同信噪比下增强语音的平均PESQ和STOI得分,并给出了未处理的含噪语音的平均PESQ和STOI得分作为对比.可见,通过采用多类噪声进行训练,对于4种未经训练的噪声类型,两种方法均能有效提升语音质量和可懂度,并且在两种不同的指标中,DCNN在不同噪声类型和不同信噪比条件下均取得了优于两种DNN的结果.

表1 三种方法的平均PESQ得分Table 1 The average PESQ score for three methods
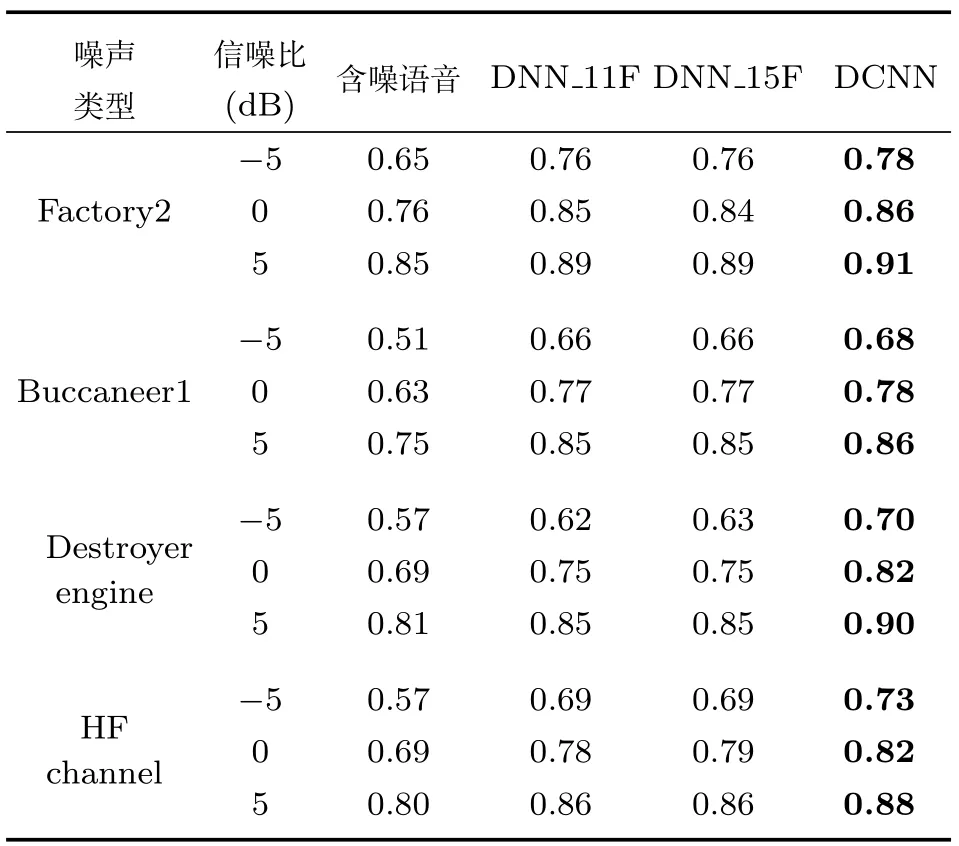
表2 三种方法的平均STOI得分Table 2 The average STOI score for three methods
另外,我们还在表3给出了含噪语音和增强语音的分段信噪比(Segmental SNR,SegSNR),分段信噪比同样是衡量语音质量的重要指标,它比全局信噪比更接近实际的语音质量;分段信噪比越大,代表主观的语音质量越好.与PESQ和STOI指标下的结果一致,采用DCNN增强后的语音取得了最佳的分段信噪比.值得注意的是,两种DNN在三种指标下都取得了非常相近的结果,这与文献[9]的描述是一致的.

表3 三种方法的平均SegSNRTable 3 The average SegSNR for three methods
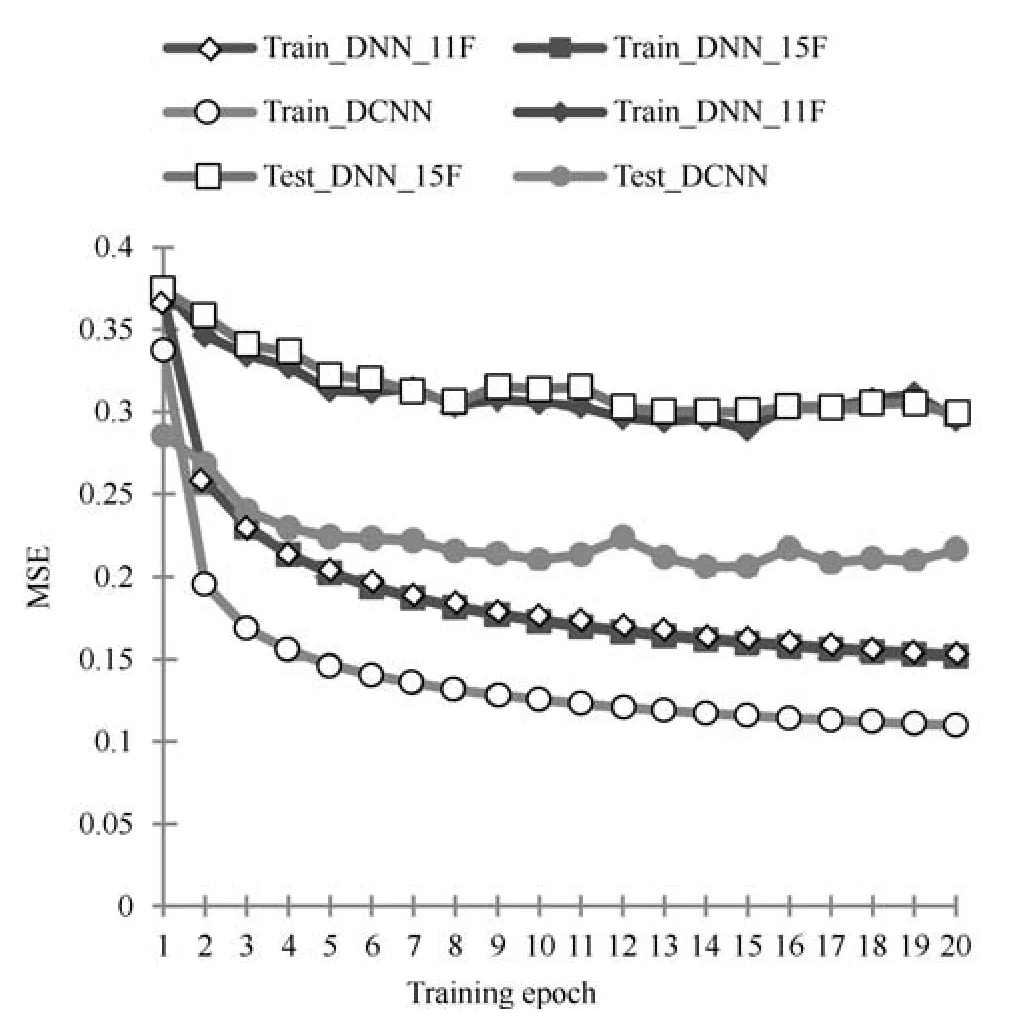
图4 两种网络的训练误差和测试误差Fig.4 Training error and testing error of two networks
为了更加直观地比较两种方法的语音增强性能,我们分别采用三种方法对一段含有Factory2噪声信噪比为−5dB的含噪语音进行语音增强,然后比较其增强语音的语谱图.图5(a)和(b)分别给出了含噪语音与其相应的纯净语音的语谱图,图5(c)∼(e)则分别给出了采用DNN_11F、DNN_15F以及DCNN增强后语音的语谱图.可以看到,DCNN增强后语音的残留噪声成分更少,语音的纯净度更高,其语谱图与纯净语音的语谱图更加接近.
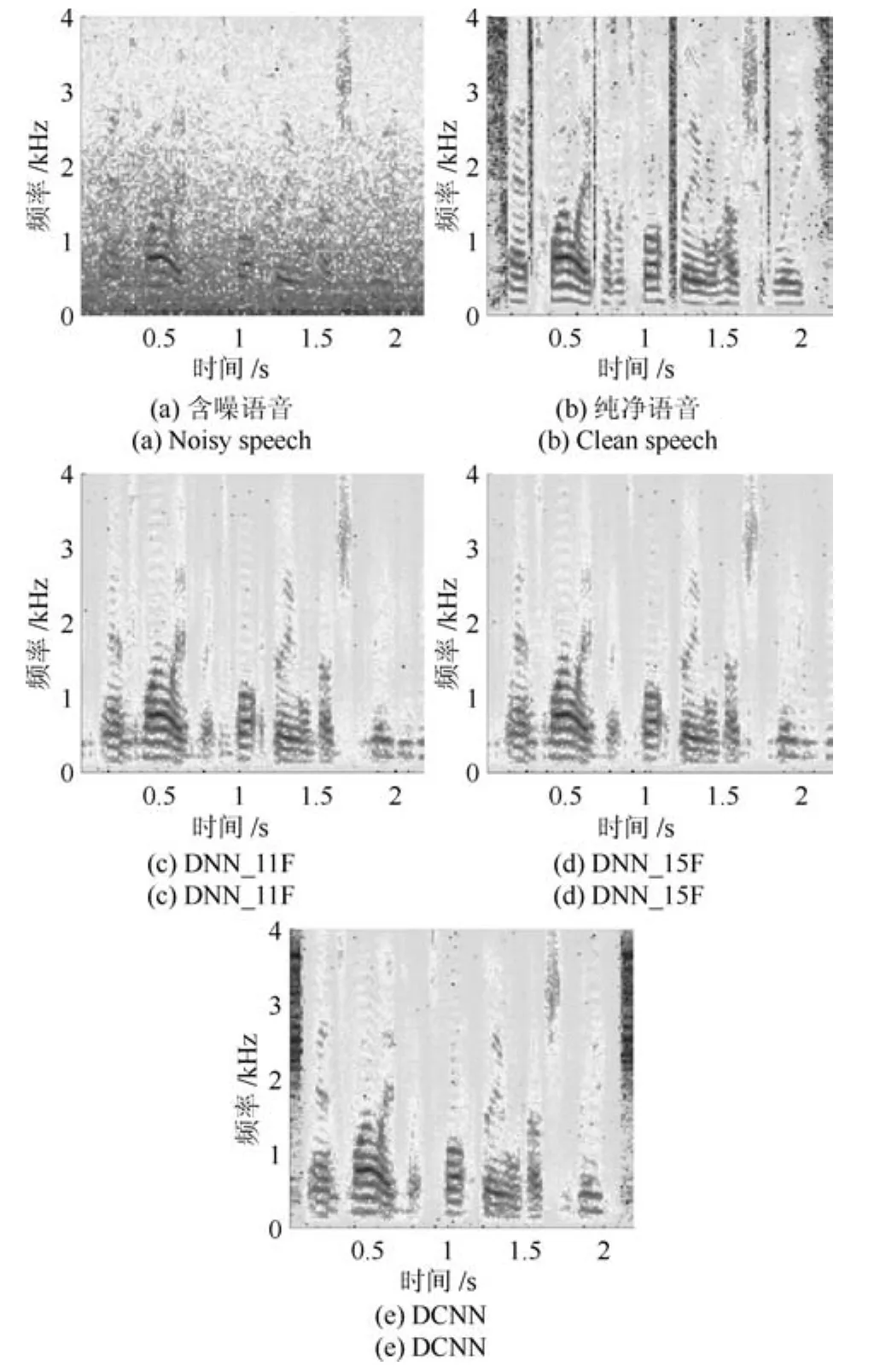
图5 −5dB的Factory2噪声下的增强语音语谱图示例Fig.5 An example of spectrogram of enhanced speech under Factory2 noise at−5dB SNR
3.3 卷积层数量的影响
对于图像和语音这种具有局部强相关性的信号,卷积层具有很好的特征提取能力,但是由于语音增强是一个回归问题,网络的最后输出对应的是纯净语音的功率谱,所以还需要通过全连接层来进行数据的拟合.在本文使用的网络结构中,不同的卷积层和全连接层的数量会带来网络性能的差别,图6给出了不同网络配置下增强后语音的平均PESQ得分提升和平均STOI得分提升.可见,当网络包含3个卷积层和2个全连接层时,在3种不同的信噪比下两种指标都得到了最高的提升值,表明该网络结构具有最好的语音增强性能.
3.4 池化层的影响
Max-pooling的直接作用是通过选取特征的局部最大值达到降低特征维度的目的.在含噪语音功率谱的相邻时频单元中,局部最大值一般含有语音成分,而局部最小值一般为噪声成分,传统的基于最小统计的噪声估计方法正是基于此原则.因此,池化层的存在将对时频单元起到一定的筛选作用,能够通过筛掉局部较小值达到抑制噪声成分的目的.
为了检验池化层对于网络性能的影响,我们将卷积层的步长设为2,并去掉池化层,训练得到不含池化层的网络模型.图7给出了不同信噪比下包含池化层(Max-pooling)和不含池化层(No pooling)的网络增强后语音的平均PESQ得分提升和平均STOI得分提升,综合分析两种指标可知,在较低信噪比的−5dB和0dB两种情况下,包含池化层的网络的语音增强性能略好于不含池化层的网络.
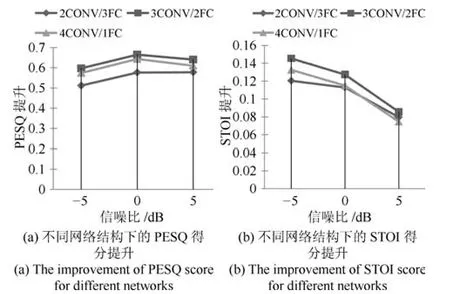
图6 卷积层数量对网络性能的影响Fig.6 The in fluence of the number of convolutional layers on the network performance
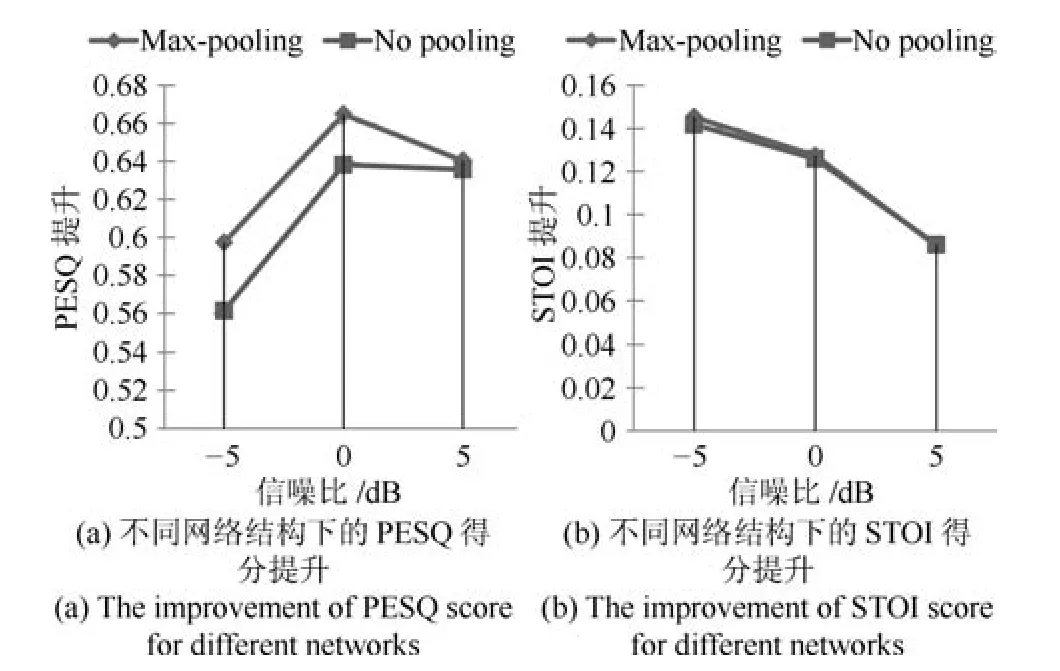
图7 池化层对网络性能的影响Fig.7 The in fluence of the pooling layers on the network performance
通过对比两种网络增强后语音的语谱图来进一步观察池化层的影响,图8(a)和图8(b)分别给出了一段含有−5dB的HF channel噪声的含噪语音与其相应的纯净语音的语谱图,图8(c)和图8(d)则分别给出了采用包含池化层和不含池化层的网络增强后语音的语谱图.由图8可见,与上述分析一致,包含池化层的网络增强后语音的残留噪声明显少于不含池化层网络增强后语音,表明Max-pooling的存在确实能带来更好的噪声抑制效果.
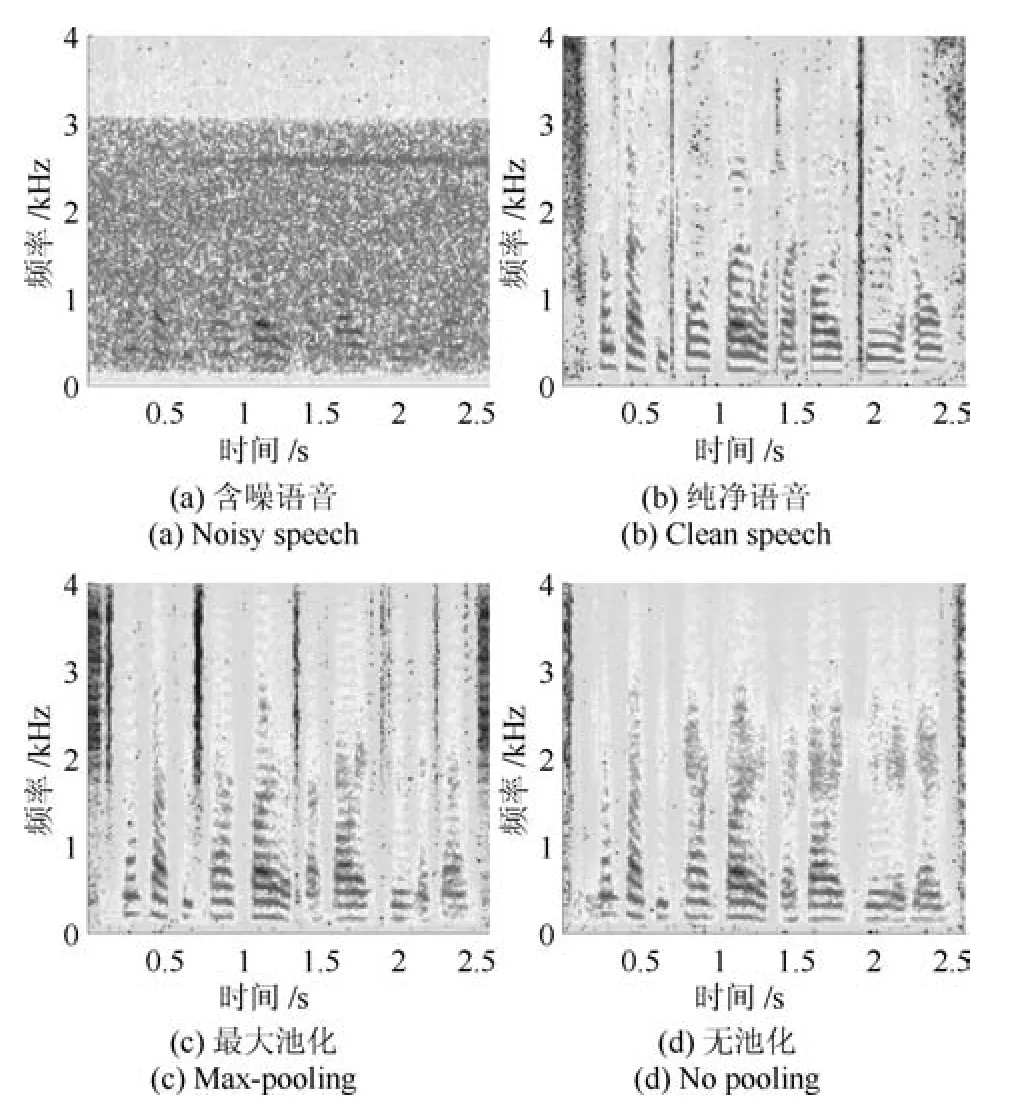
图8 −5dB的HF channel噪声下的增强语音语谱图示例Fig.8 An example of spectrogram of enhanced speech under HF channel noise at−5dB SNR
3.5 Batch normalization层的影响
Batch normalization是深度卷积神经网络中的常用技术,Batch normalization层的引入往往可以加快收敛过程,提升训练速度,并能防止过拟合.为了检验Batch normalization层对本文网络结构的影响,我们去掉网络中的Batch normalization层,训练得到不含Batch normalization层的网络模型.图9给出了不同信噪比下包含Batch normalization层(BN)和不含Batch normalization层(No BN)的网络增强后语音的平均PESQ得分提升和平均STOI得分提升,在两种指标下,不包含Batch normalization层的网络模型都略好于包含Batch normalization层的网络模型,表明Batch normalization层的引入并没有提升本文网络结构的语音增强性能.可见,对于本文相对简单的网络结构,Batch normalization并没有明显的作用,可以去掉.
3.6 LPS与NLAS的比较
下面通过实验对文献[9]采用的LPS与本文采用的NLAS两种特征进行比较,分别采用DNN和DCNN对两种特征进行训练.其中,训练LPS的DNN(LPS-DNN)与训练NLAS的DNN(NLASDNN)均为与前文相似的包含5个隐层的DNN,需要注意的是两种DNN采用的激活函数是Sigmoid函数,因为在我们的实验中,当训练特征为LPS时,如果采用ReLU作为激活函数,会造成训练过程不收敛;训练LPS的DCNN(LPS-DCNN)与前文的NLAS-DCNN结构一致.图10分别给出了4种测试集噪声在不同信噪比下采用4种方法增强后语音的平均PESQ和STOI得分.可见,在相同特征下,DCNN的语音增强性能明显好于DNN;在相同的网络结构下,采用NLAS特征训练得到的网络模型在3种不同信噪比下都取得了较好的语音可懂度,并且在低信噪比(−5dB)下取得了较好的语音质量,表明NLAS特征能够更好地保留含噪语音中的语音成分,更加适用于低信噪比下的语音增强.
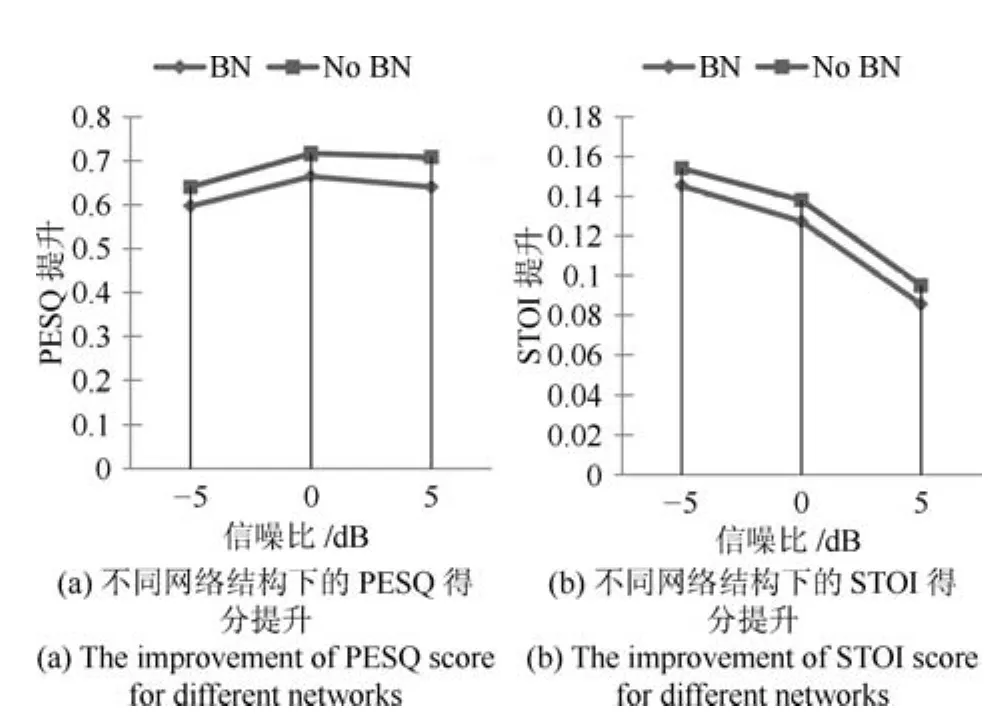
图9 Batch normalization层对网络性能的影响Fig.9 The in fluence of the batch normalization layers on the network performance
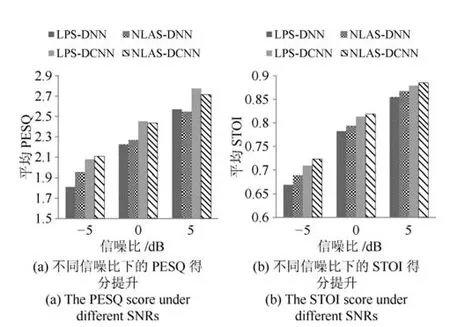
图10 两种特征训练得到的DNN和DCNN的性能比较Fig.10 The performance comparisons for DNN and DCNN trained using two kinds of feature
3.7 与其他方法的比较
为了进一步验证本文DCNN的语音增强性能,将其与LSTM(Long-short term memory)以及文献[24]中的FCNN进行比较.其中LSTM包含5个隐层,Cell维度为256;FCNN包含16个卷积层,每层滤波器的个数分别为:10,12,14,15,19,21,23,25,23,21,19,15,14,12,10,1.图11分别给出了各种方法增强后语音的平均PESQ、平均STOI和平均SegSNR,同时给出DNN对应的结果作为对比.通过综合分析3种指标可知,DCNN取得了最佳的语音增强性能,LSTM次之,FCNN略好于DNN.
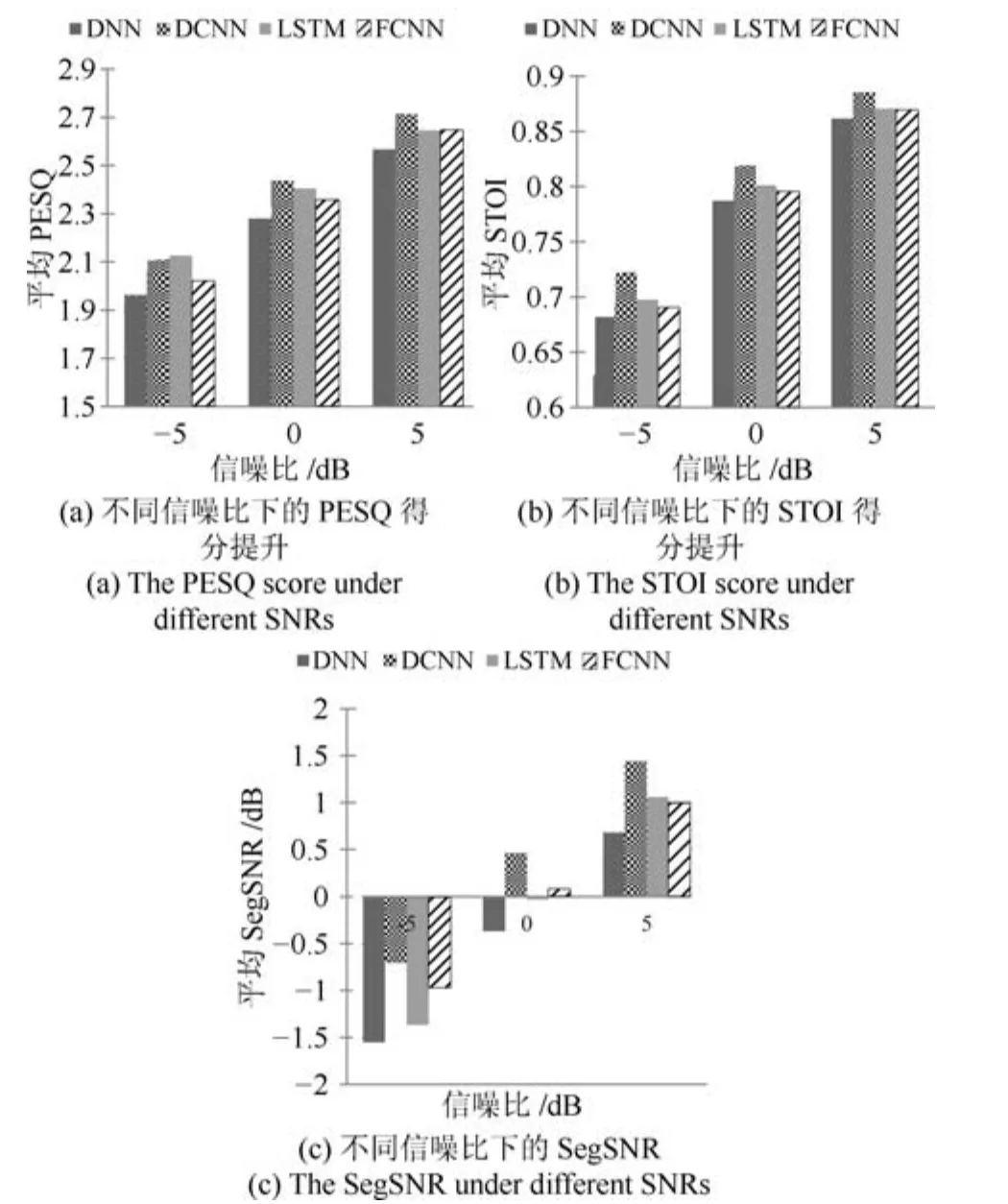
图11 两种特征训练得到的DNN和DCNN的性能比较Fig.11 The performance comparisons for DNN and DCNN trained using two kinds of feature
4 结论
为了进一步提高未知噪声下的语音增强性能,考虑DCNN相比DNN具有更好的局部特征表达能力,能够更好地利用语音和噪声信号的时频相关性,本文采用深度卷积神经网络建立回归模型来表达含噪语音和纯净语音之间的复杂非线性关系.通过使用非负对数幅度谱作为训练特征和训练目标,设计与训练了不同结构的DCNN并对其语音增强性能进行了比较,得到了适合于语音增强问题的合理网络结构,提出了基于深度卷积神经网络的语音增强方法.实验结果表明,在与DNN及其他方法的对比中,本文提出的DCNN在测试集上取得了更小的误差,表现出了更好的噪声抑制能力,在各类噪声和各种信噪比条件下都显著提升了增强后语音的语音质量和可懂度,进一步提高了未知噪声下的语音增强性能.
References
1 Loizou P C.Speech Enhancement:Theory and Practice.Florida:CRC Press,2013.
2 Ephraim Y,Malah D.Speech enhancement using a minimum mean-square error log-spectral amplitude estimator.IEEE Transactions on Acoustics,Speech,and Signal Processing,1985,33(2):443−445
3 Cohen I.Noise spectrum estimation in adverse environments:Improved minima controlled recursive averaging.IEEE Transactions on speech and audio processing,2003,11(5):466−475
4 Mohammadiha N,Smaragdis P,Leijon A.Supervised and unsupervised speech enhancement using nonnegative matrix factorization.IEEE Transactions on Audio,Speech,and Language Processing,2013,21(10):2140−2151
5 Liu Wen-Ju,Nie Shuai,Liang Shan,Zhang Xue-Liang.Deep learning based speech separation technology and its developments.Acta Automatica Sinica,2016,42(6):819−833(刘文举,聂帅,梁山,张学良.基于深度学习语音分离技术的研究现状与进展.自动化学报,2016,42(6):819−833)
6 Wang Y X,Wang D L.Towards scaling up classi ficationbased speech separation.IEEE Transactions on Audio,Speech,and Language Processing,2013,21(7):1381−1390
7 Wang Y X,Narayanan A,Wang D L.On training targets for supervised speech separation.IEEE Transactions on Audio,Speech,and Language Processing,2014,22(12):1849−1858
8 Xu Y,Du J,Dai L R,Lee C H.An experimental study on speech enhancement based on deep neural networks.IEEE Signal Processing Letters,2014,21(1):65−68
9 Xu Y,Du J,Dai L R,Lee C H.A regression approach to speech enhancement based on deep neural networks.IEEE/ACM Transactions on Audio,Speech,and Language Processing,2015,23(1):7−19
10 Williamson D S,Wang Y X,Wang D L.Complex ratio masking for monaural speech separation.IEEE/ACM Transactions on Audio,Speech,and Language Processing,2016,24(3):483−492
11 Xu Y,Du J,Huang Z,Dai L R,Lee C H.Multi-objective learning and mask-based post-processing for deep neural network based speech enhancement.In:Proceedings of the 16th Annual Conference of the International Speech Communication Association.Dresden,Germany:ISCA,2015.1508−1512
12 Wang Y X,Chen J T,Wang D L.Deep Neural Network Based Supervised Speech Segregation Generalizes to Novel Noises Through Large-scale Training,Technical Report OSU-CISRC-3/15-TR02,Department of Computer Science and Engineering,The Ohio State University,Columbus,Ohio,USA,2015
13 Chen J T,Wang Y X,Yoho S E,Wang D L,Healy E W.Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises.The Journal of the Acoustical Society of America,2016,139(5):2604−2612
14 Chen J T,Wang Y X,Wang D L.Noise perturbation for supervised speech separation.Speech Communication,2016,78:1−10
15 Krizhevsky A,Sutskever I,Hinton G E.ImageNet classi fication with deep convolutional neural networks.In:Proceedings of the International Conference on Neural Information Processing Systems.Nevada,USA:Curran Associates Inc.2012.1097−1105
16 Abdel-Hamid O,Mohamed A,Jiang H,Penn G.Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition.In:Proceedings of the 2012 IEEE International Conference on Acoustics,Speech and Signal Processing.Kyoto,Japan:IEEE,2012.4277−4280
17 Abdel-Hamid O,Deng L,Yu D.Exploring convolutional neural network structures and optimization techniques for speech recognition.In:Proceedings of the 14th Annual Conference of the International Speech Communication Association.Lyon,France:ISCA,2013.3366−3370
18 Sainath T N,Kingsbury B,Saon G,Soltau H,Mohamed A R,Dahl G,Ramabhadran B.Deep convolutional neural networks for large-scale speech tasks.Neural Networks,2015,64:39−48
19 Qian Y M,Bi M X,Tan T,Yu K.Very deep convolutional neural networks for noise robust speech recognition.IEEE/ACM Transactions on Audio,Speech and Language Processing,2016,24(12):2263−2276
20 Bi M X,Qian Y M,Yu K.Very deep convolutional neural networks for LVCSR.In:Proceedings of the 16th Annual Conference of the International Speech Communication Association.Dresden,Germany:ISCA,2015.3259−3263
21 Qian Y,Woodland P C.Very deep convolutional neural networks for robust speech recognition.In:Proceedings of the 2016 IEEE Spoken Language Technology Workshop.San Juan,Puerto Rico:IEEE,2016.481−488
22 Sercu T,Puhrsch C,Kingsbury B,LeCun Y.Very deep multilingual convolutional neural networks for LVCSR.In:Proceedings of the 2016 IEEE International Conference on Acoustics,Speech and Signal Processing.Shanghai,China:IEEE,2016.4955−4959
23 Sercu T,Goel V.Advances in very deep convolutional neural networks for LVCSR.In:Proceedings of the 16th Annual Conference of the International Speech Communication Association.California,USA:ISCA,2016.3429−3433
24 Park S R,Lee J.A fully convolutional neural network for speech enhancement.arXiv:1609.07132,2016.
25 Fu S W,Tsao Y,Lu X.SNR-Aware convolutional neural network modeling for speech enhancement.In:Proceedings of the 17th Annual Conference of the International Speech Communication Association.San Francisco,USA:ISCA,2016.8−12
26 Garofolo J S,Lamel L F,Fisher W M,Fiscus J G,Pallett D S,Dahlgren N L,Zue V.TIMIT acoustic-phonetic continuous speech corpus.Linguistic Data Consortium,Philadelphia,1993.
27 Hu G N.100 nonspeech sounds[online],available:http://web.cse.ohio-state.edu/pnl/corpus/HuNonspeech/HuCorpus.html,April 20,2004
28 Varga A,Steeneken Herman J M.Assessment for automatic speech recognition:II.NOISEX-92:a database and an experiment to study the effect of additive noise on speech recognition systems.Speech Communication,1993,12(3):247−251
29 Beerends J G,Rix A W,Hollier M P,Hekstra A P.Perceptual evaluation of speech quality(PESQ)—a new method for speech quality assessment of telephone networks and codecs.In:Proceedings of the 2001 IEEE International Conference on Acoustics,Speech and Signal Processing.Utah,USA:IEEE,2001.749−752
30 Taal C H,Hendriks R C,Heusdens R,Jensen J.An algorithm for intelligibility prediction of time-frequency weightednoisyspeech.IEEETransactionsonAudio,Speech,and Language Processing,2011,19(7):2125−2136
31 Yu D,Eversole A,Seltzer M L,Yao K S,Huang Z H,Guenter B,Kuchaiev O,Zhang Y,Seide F,Wang H M,Droppo J,Zweig G,Rossbach C,Currey J,Gao J,May A,Peng B L,Stolcke A,Slaney M.An Introduction to Computational Networks and the Computational Network Toolkit,Technical Report,Tech.Rep.MSR,Microsoft Research,2014.
