改进的基于半监督稀疏自编码IM流量识别模型的研究与比较
2018-05-11王姣,蒋言
王 姣 ,蒋 言
(1.南京烽火星空通信发展有限公司IAO江苏南京210019;2.武汉邮电科学研究院湖北武汉430074)
近年来,随着移动互联网浪潮的井喷,科技得以快速发展的同时,一些不良的协议,应用以及网站给互联网安全带来了很大的挑战,例如最常见的的Ddos攻击;除了恶意流量的攻击之外,流量爆炸问题也越来越严重,根据思科Visual Networking Index(VNI)全球移动数据流量预测报告(2015-2020)中显示,自2000年首款智能手机上市以来,移动用户的数量同往期相比已经达到五倍的增长量。报告中显示,到2020年,全球的上网总数将达55亿,几乎是人口数据的70%。随着电子设备成本的不断下降、移动互联网的全面大规模覆盖和社交媒体的广泛普及,各种类型的数据流量将在未来五年内快速大规模的增长。所以对互联网的控制和管理中,对流量的识别显得尤为重要[1]。
在业内,应用流量识别也是一个相对很热门的话题和项目,国内的许多大公司如360,科来,腾讯阿里等都在这个课题投入大量的精力加以研究,对于现在的互联网公司而言,流量识别确实是一个很实用也很前景的方向,他们意识到网络分析在很多方面可以满足多种需求,流量的准确识别不但能洞悉整个互联网的运行情况,还能针对具体需求对用户进行大数据进行分析和行为透视。在业务层面上,不仅可以预防各种攻击断网事件,还可以保证互联网的高效运行。另外,随着加密流量和应用的不断涌现,这些不利因素将都会对流量识别的准确性产生重大的挑战。
本文首先分析了目前的流量识别方法及其存在的问题,并针对IM数据这一特定流量,结合报文特征,考虑目前工具的配置以及数据的复杂度,提出了基于SAE(spare auto-encoder)的离线数据的识别模型。想要对互联网运行状况有一个良好的把握,网络流量识别技术是进行流量测量与分析的基础,但是目前在识别技术上并既没有标准的数据集,也没有一个标准的测试程序和算法,针对这一问题,也将在本文中进行一个初步的探讨。
1 互联网流量识别概述
最初的应用流量识别,目的是想对P2P应用进行准确的分类和识别[2-17]。P2P应用特殊的非客户端服务器文件传输模式,给流媒体、文件共享等领域带来便捷的同时,加剧了互联网的拥塞和不安全性。为了使互联网的运行更加健壮,流量的有效识别就显得很有必要,在前期的研究中,很多流量识别是通过提取数据报文的五元组特性进行的识别,如端口或者IP。随着网络的逐渐复杂,流量识别往DPIDPI(deap packet inspection)深度数据包检测的方向发展[3],这一重大转变,主要是由于后期的应用改变传统的认知模式,使得固定端口的识别方法大面积失效导致的。同时,大数据概念的广泛推广,数据挖掘、模糊统计技术也不断的改进和发展,相当多的机器学习分类算法等非常规手段在流量识别的问题上有很明显的效果。很多学者在这方面投入了大量的研究工作。
通过对往期的各种P2P流量分类技术的调查研究[9],将各种流量检测技术归纳如下。
1.1 基于IP地址的P2P流量识别
这一方法灵感来源于因特网的一项核心服务DNS,它方便人们不用记住机器能够读取的IP串,而通过域名的方式就可以进行服务器访问。而恰巧数据报文中能够直接获取到报文的源IP目的IP。可以通过对应关系,解析出对应的host,从而进行流量识别,但是要获得一份完整的全球映射关系表并不容易,同时实时性较差,由此可见,这种识别方法比较局限,应用范围比较狭窄。
1.2 基于端口的P2P识别
这里的端口是指TCP/IP模型的传输层端口,即TCP或UDP端口。这种方法也是十分的简洁和方便,通过对应两者之间的对应关系就可以实现流量的分类。但是问题与第一种类似,很多当前的协议并不使用固定端口,为了绕开防火墙的封堵,进而选择动态的使用端口,这也包括一些知名的服务。
1.3 基于统一资源定位符的过滤方法
该方法多用于BT的识别控制,这种方法是通过识别URL中的关键字从而进行过滤,这个明显存在很大的局限性,因为很多应用厂商可以改变扩展名或者通过FTP的方式进行规避。
1.4 基于流统计特性的识别
这种方法是通过总结各个应用流量传输的特点进行特征识别,例如P2P流量的数据量大,节点之间数据交换频繁,最突出的特点是不分时段性和长时间持续传播,其他的流量例如网站类,均是突发的,数据一般都不是上行的。可以通过分析和构建各个维度特征,采用一般的分类算法或模型就可以进行识别,朴素贝叶斯就曾经被使用过,但是这个方法的缺点也是很明显的,前期需要大量的人工干预,另外,在准确度上面极大的取决于维度的选择。即使特征选择恰当,相对其他方法准确度仍然比较低。值得一提的是,该方法的可移植性很好。
1.5 基于深度数据包扫描的识别
深度数据包检测技术DPI摈弃传统挖掘对应关系的简单方法,而是对数据报文的深度解析工作着手,从而判定是何种应用。这种方法的精度度算是很高的,它是充分关联报文的载荷进行的识别。但是对于加密性的报文,识别精度会明显下降,可移植性也很差,新的应用出现了,要重新进行训练和识别。
1.6 基于DNS查询日志的P2P节点检测
除了对截获到的数据包报文进行分析外,也有学者对P2P节点所具有的特性入手,结合源IP地址对P2P流量进行识别检测。已经有学者对这个方法进行了实验并取得成功。但是该方法的可用性很差,推广上面难以进行。
2 基于SAE的IM流量识别
目前的应用流量识别中,对即时通信类的流量识别讨论较少,其他比如游戏类、网站类应用更加没有,但是随着当前这些应用的极大丰富,对进一步分析用户行为,创造优质的网络环境,这种类型的应用识别就显得非常关键。下面将对IM的流量数据如QQ、微信等进行识别分类问题进行研究。
2.1 Sparse AutoEncoder稀疏自动编码算法
Deep Learning最简单的一种方法是利用人工神经网络的特点,假设其输出与输入是相同的,然后通过大量的训练和参数的调整,就得到了输入I的几种不同表示。其中每一层中的权重都是不尽相同的。而自动编码器就是一种尽可能复现输入信号的神经网络,从而有效的挖掘数据中隐含的特征。

图1 AutoEncoder原理图
算法的原理如图2所示,将输入信号I放入一个encoder编码器中,就可以得到一个code,这个code就是输入I的另外一种表述。再讲前面产生的code输入到另外的解码器中(decoder),如果输出的这个信息O与之前的输入信号I之间的偏差值最小,那么就可以说明,这个code是可靠的。所以,我们就可以通过逐步调整encoder和decoder的参数,当重构误差最小时,可以得出结论:输入信号I可以被code唯一表示。经过这样逐层训练。输入信号I可以被逐层得到的code唯一表示,而输入信号的特征I就会变得非常明显。这里误差的来源就是直接重构后的信号O与原输入I的绝对值。同时可以说明,输入信号可以被有效的还原了。如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0),这就是Sparse AutoEncoder法。如图2所示。

图2 Sparse AutoEncoder示意图
稀疏自编码其实就是限制每次得到的code尽量稀疏。也就是让特征尽量独立,从而输入I可以被有效的表达出来。这个概念类似于线性代数中的基,即O=a1*Φ1+a2*Φ2+…+an*Φn,Φi是基,ai是系数,我们可以得到这样一个优化问题:

稀疏自编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。
2.2 IM流量识别模型
结合数据实际情况,识别IM流量模型如图3所示,该识别模型主要包含4大模块。

图3 识别模块流程图
2.2.1 数据采集
通过PC端抓取手机端的APP报文数据,以抓取QQ报文为例,具体步骤如下:
St1:在 pc端建立虚拟 wifi;
St2:将手机连接该虚拟wifi,并开启wireshark,wireshark选择虚拟wifi对应的网卡;
St3:在wireshark的过滤框中,输入相应的过滤条件,并执行该条件;
St4:当没有新的QQ报文数据产生时,停止抓取,将过滤出的QQ报文数据导出为纯文本格式。

图4 wireshark抓数据包截图
这里进行识别模型的数据集是通过pc端的软件wireshark进行手动抓包得到的,不仅需要进行人工干预多次上下线、发送多次消息、建立多次视频和语音通信等动作来进行丰富的报文集抓取,不仅获取数据速度慢,并且在报文的获取中还要严格控制减少其他杂质报文的产生,避免过滤条件的复杂化。而前期的研究中使用的ckan等数据集,研究者均是从中直接获取再用来模型识别,已知存在的数据集,不仅存在数据集老旧的问题,并且数据集内容单一,以P2P流量占多,一些新型的应用流量都需要人为的获取并降噪。而数据的质量对模型的选择和调参都及其重要,如果能构建一个分布式的,能在各个应用服务器的分光口进行定期数据采集,对研究界将会产生及其重要的影响和作用。
2.2.2 数据处理
预处理包括格式整理、MAC层数据剔除、五元组数据提取、传输层有效净载荷提取、数据规范化处理。首先对wireshark保存的txt文件里无效内容进行替换;报文前14个字节为MAC层数据,对于传输层、应用层协议识别均无用处,故剔除。
报文第24个字节为传输层协议代码:

表1 协议代码
其中数据报文都以TCP、UDP为主,剩余夹杂ICMP协议。这里提取五元组主要是对TCP和UDP报文进行的,对于ICMP只提取源IP和目的IP以及自身协议代码。报文第27~30个字节是源IP、第31~34个字节是目的IP。对于TCP和UDP,报文第35~36个字节是源端口,第37~38个字节是目的端口。
分别根据TCP、UDP、ICMP数据包结构,提取各自的有效净载荷:
1)TCP:对于TCP数据我们以一次会话报文为基本单位,提取每次会话重组后报文的第55个字节到最后所有数据载荷;
2)UDP:对于UDP数据,我们以每条报文为基本单位,提取每条报文的第43个字节到最后所有数据载荷;
3)ICMP:与UDP类似,提取第71个字节到最后所有数据载荷。
IM数据流量识别主要是对应用层协议的头部(或尾部)进行识别,内容相关性不大。因此,在构建模型时,只提取数据前固定若干个字节(或数据尾部固定若干个字节)作为特征数据。假设应用层协议头部长度一般不会大于MTU。选择截取了数据净载荷的前1 460个字节作为后面的训练数据(默认MTU-20-20)。
为提高模型的收敛速度,进而提高模型的准确度,将1 460个字节数据各自除以255(归一化处理)。SAE是一种无监督学习方法,为了进一步精度的提升和明显的分类效果,将训练数据进行标签化,对各个IM应用类型进行了如下编码。

表2 APP应用类别One-hot编码
2.2.3 特征提取与决策
流量识别选择SAE(sparse auto-encoder)构建识别模型,隐含层神经元都采用函数作为激励函数。因为AutoEncoder是学习并获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号,但是该模型并不能用来分类数据。为了实现分类,所以最后一层选择添加一层logistic回归层进行分类识别。
依据人工经验并根据调试结果进行调整,拟定SAE的隐含层个数以及各层神经元个数为:[1460-730-200-50-10-1]。

图5 SAE算法流程图
构建SAE时,首次是以误差二范数作为损失函数,即模型训练问题转化为如下的最优化问题:
W*,B*=训练时,我们首先将有标签的报文数据进行6∶1∶3(训练集∶验证集∶测试集)分割,经过多次调整,训练参数如下:
learning_rate_ae=0.05 #AE预训练学习速率
learning_rate_refine=0.05 #反向微调学习速率
training_epochs_ae=5000 #AE预训练批次
training_epochs_refine=5000 #反向微调训练批次
mini_batch_ae=1000 #AE随机选择训练数据大小
mini_batch_refine=1000 #反向微调随机选择训练数据大小时,且添加了五元组中协议代码(TCP0x06、UDP0x11、ICMP0x01)作为一个特征维度,训练好后的SAE对训练集、测试集和验证集进行测试,得到如下结果:

表3 结果表
3 Apriori特征提取算法与SAE算法的比较
在各类特征提取的算法中,最大频繁项集算法也是一种,它偏向于的寻找特征之间的关联,从而找出最合适的频繁项,同样也可以用到识别和提取中。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,下面对这两种算法的优劣进行初步的讨论方便后面的人的研究。
所谓最大频繁项集,就是交集不为空的最大项集。

原始Apriori算法是通过判断各项集的频次是否大于最小支持度来选择第一层频繁项集M的。如图6所示,通常选出来的第一层频繁项集有两种情况:高度耦合和低耦合。高耦合即第一层频繁项集中大部分项集甚至所有项集在大于最小支持度的情况下,存在交集;而低耦合则是少数项集甚至两两交集为空。
由于原始Apriori算法是由下至上、由个体项集逐次排列组合生成新的频繁项集,因此在高耦合的情况下,Apriori算法需要多次逐层迭代,且每次迭代复杂度成指数级增长。在时间复杂度上一般要比SAE要大,SAE隐含层的层数是可选并且有限的,但是Apriori算法存在一个未知循环,当最新的项集支持度超过阈值而下一层的支持度小于阈值才会停止。但是从空间复杂度上来看,从算法概念上来看是类似的。她们都是属于层次递进的,高层表达由底层表达的组合而成。但是每种算法的优劣也是多方面的,应用场景不同,算法的优势表现也是不同的。而项目的应用场景是网络流量在线实时识别方面,所以要尽量选择实时性更好,并且这里并不需要深入探讨数据特征的关联性问题,所以在这一方面,稀疏自编码对IM流量识别模型构建更实用。
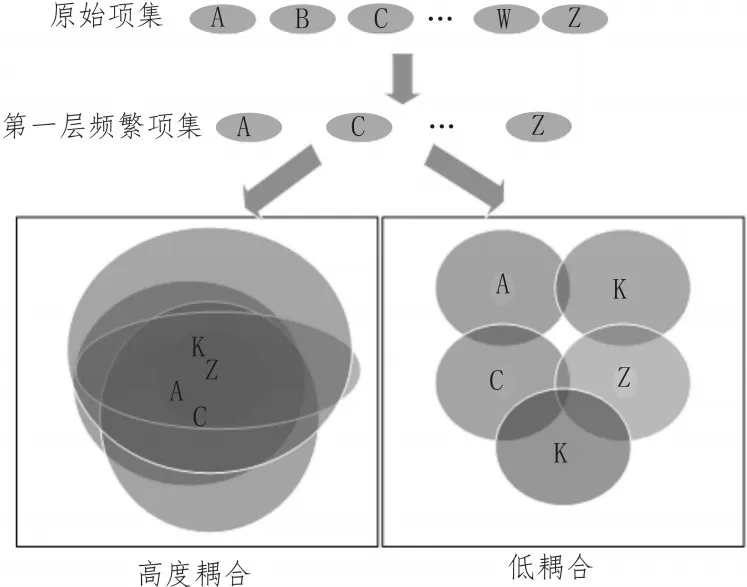
图6 耦合度示意图
4 结束语
随着每天新增应用的增多,所带来的类别也越来越多。在实时应用流量识别的问题上,精度是很重要的,到底是每个应用训练一个模型还是训练一个综合的识别模型的选择很重要,从机器的角度,综合缓存堆栈等影响偏向于后者,但是如果新增的和已有的某一应用很相似,而新增的应用之前并没有被机器学习到,会大大影响识别的正确率,目前业内解决被认错方案就是利用关联的方法把它找出来,通过神经网络每天对模型进行优化,不需要重新训练。另外可以考虑提高识别门限,将特征模糊的数据给过滤掉或先去处一些垃圾数据,这样可以有效的解决这种问题,就是会丢失部分数据。未来的识别模型中,是否可以尝试将应用行为进行粒度细分,例如根据平台(Android、IOS、Windows、Mac OS、Linux等等)、动作(上线、下线、心跳包、更新、IM数据等)、数据(文本、语音、图片、视频)来建立一个综合的识别将是我们需要考虑的方向,从而真正的实现人工智能。
参考文献:
[1]李鹏,刘悦.一种基于行为特征和SVM的P2P流量识别模型[J].开封大学学报,2010,24(3):79-84.
[2]喻东阳,陈宏伟,杨庄.基于信任抽样的P2P流量识别[J].湖北工业大学学报,2013,28(4):24-26.
[3]王炜,程东年,马海龙.基于趋势感知协议指纹的Skype加密流量识别算法[J].计算机应用研究,2015,32(1):183-186.
[4]孙瑜玲,林勤花.基于遗传神经网络的P2P流量识别系统[J].现代电子技术,2015,38(17):117-120.
[5]王春枝,张会丽,叶志伟.基于混沌粒子群算法和小波SVM的P2P流量识别方法[J].计算机科学,2015,42(10):117-121.
[6]张伟,刘清.基于传输层会话行为统计特征的恶意流量识别[J].小型微型计算机系统,2015,36(5):959-963.
[7]刘三民,孙知信.一种新的P2P流量识别模型[J].小型微型计算机系统,2015,36(6):1235-1239.
[8]邢玉凤,毛艳琼.基于有督导机器学习的网络流量识别系统[J].现代电子技术,2015,38(21):109-112.
[9]鲁刚,张宏莉,叶麟.P2P流量识别[J].软件学报,2011,22(6):1281-1298.
[10]刘三民,孙知信,刘余霞.基于K均值集成和SVM的P2P流量识别研究[J].计算机科学,2012,39(4):46-48.
[11]于明,朱超.利用半监督近邻传播聚类算法实现P2P流量识别[J].哈尔滨工程大学学报,2013,35(5):653-657.
[12]谭骏,陈兴署,杜敏,等.基于自适应BP神经网络的网络流量识别[J].算法电子科技学报,2012,41(4):580-585.
[13]HOU Ya-jun.P2P Network traffic identification based on random forest algorithm[J].Journal of Networks,2014,9(9):29-35.
[14]LIU Yan.Analysis of P2P traffic identification methods[J].Journal of Emerging Trends in Computing and Information Sciences,2013,4(5):490-493.
[15]赵晶晶.基于数据挖掘的P2P流量识别算法研究与实现[D].北京:北京邮电大学,2009.
[16]张峰.基于机器学习的VoIP流量识别技术研究[D].武汉:华中科技大学,2013.
[17]彭立志.基于机器学习的流量识别关键技术研究[D].哈尔滨:哈尔滨工业大学,2015.
