基于语音信号的发音器官运动估计方法综述
2018-05-07汪洋李绍彬边洁蕊
汪洋,李绍彬,边洁蕊
(中国传媒大学 信息工程学院,北京100024)
1 引言
基于语音信号的发音器官运动估计,又称语音反转(Speech Inversion),是根据说话人语音推断嘴唇、下颌、面部肌肉、舌头等发音器官运动过程的技术,综合了语音信号处理、生理语音学、计算机视觉、图形学等多学科前沿知识,在语言教学、发音矫正、医学、影视动画制作等方面有着广阔的应用前景。
语音信号的发音器官运动估计技术,近年来受到了各领域研究者的广泛关注,近期的研究趋向于综合考虑语音现象、声学现象等多维度特征对估计结果的影响,将语音规则和信号处理的前沿技术结合起来解决发音器官运动估计问题,取到了较多研究成果。
本文主要对基于单元选择模型和回归模型的方法进行介绍。
2 单元选择模型法
单元选择模型(Unit Selection Model)又称码本模型(Codebook Model),该模型先将用于估计的目标语音切分为若干语音单元,再从预先建立的码本库中选择出与各语音单元相匹配的运动数据,将选择的运动数据按照目标语音顺序排列成序列,最后应用重采样、内插平滑等拼接合成算法生成运动轨迹。
码本库建设是单元选择模型的关键。码本库建设首先进行参测实验,参测实验同步记录了说话人的发音器官运动数据和语音信号。运动捕捉、医学成像、电磁发音记录(Electromagnetic Articulometer,EMA)等技术被广泛应用于发音器官的运动观测。语音规律复杂,同一个音素在不同的语音环境中会有不同的发音表现,码本库丰富程度将直接影响最终运动呈现逼真程度。
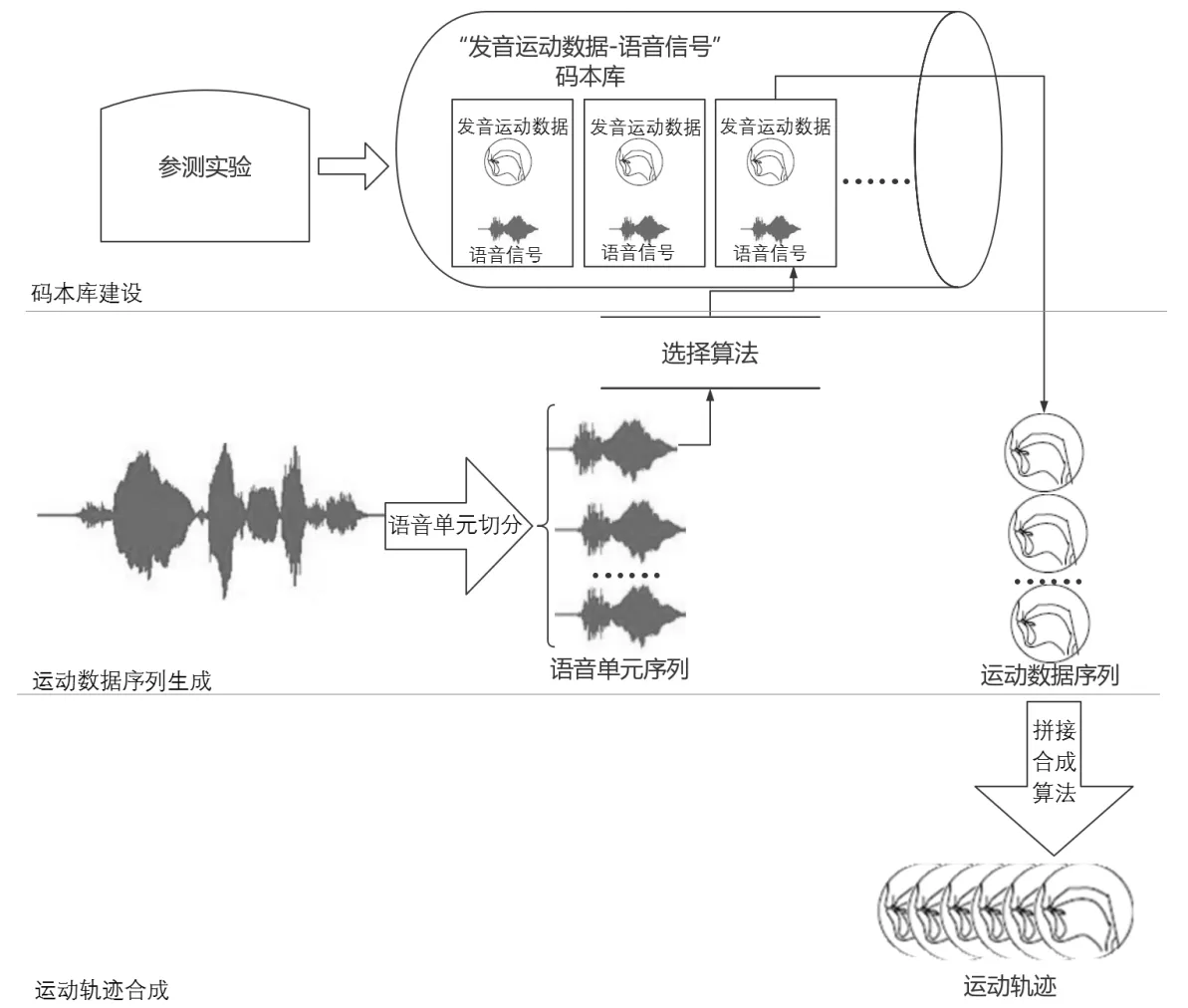
图1 单元选择模型
Yu等人[8]为了解决语音反转过程中估算声道长度问题,利用聚类方法设计了一个“声学参数-运动数据”码本库。还有许多研究者做了码本库的建设与研究[3-7]。
运动数据序列生成是单元选择模型的核心,主要包括语音单元切分和选择算法设计两项技术。
Minnis等人[6]设计了一种基于3D运动数据捕捉的单元选择方法。与传统的根据语言先验知识将语音划分为音素或音节的做法不同,这种方法是根据码本库中音素上下文环境和目标音素上下文环境的一致性来确定语音单元的。研究者将语音单元定义为“可变长语音段”,在选择算法实现过程中确定语音单元的划分。Cao等人[7]也提出了类似方法,所设计的系统会在所有可能的候选语音段中选择最长的语音段,这样做的目的是最小化目标语音所分割的段数。
Suzuki等人[4]建立的码本库中记录了语音信号的谱段(Spectrum Segments)信息,提出了一种发音参数路径平滑程度的计算方法,利用谱段距离和路径平滑程度两个约束条件来完成输入语音和码本库中的参数匹配。在之后的研究[9]中利用隐马尔可夫模型(Hidden Markov Model,HMM)统计声学特征与发音器官运动参数关系。Wei等人[10]采用深度自编码算法建立了一种深度神经网络框架来研究元音的声学特征和舌头的超声波图像间的一一映射。Edge等人[5]根据音素在不同上下文环境中发音表现不同,提出动态音素(Dynamic Phonemes)的概念,并基于此改进了单元选择算法。研究者计算码本库中每个音素单元之间的转移概率;再将给定的目标语音切分成音素单元,利用维特比算法(Viterbi Algorithm)从码本库中找出最有可能的音素序列。
运动轨迹合成是单元选择模型的难点。为了实现运动数据单元间自然逼真的平滑过渡,许多研究者做了大量工作。
Edge等人[5]将序列重新采样和回放产生动画,整个过程中没有内插或对帧进行处理,最终的动画仅是来自各码本中动画帧的重新排序。江辰等人[11]采用Sigmoid函数算法完成了序列间的内插和平滑。Cohen和Massaro提出的Cohen-Massaro协同发音模型[13]在此类问题中有优异表现,被广泛引用。Klir等人[15]提出了模糊逻辑(Fuzzy Logic)算法,利用数学工具优化了合成过程。
单元选择模型中建立码本库是非常繁琐复杂的工作,需要有经验的语言工作者进行大量的参测实验,遴选样本,并人工切分和标记单元。近年来,自动标记工具的出现大大减轻了研究者的工作量,但还需要人工核对勘误。单元选择模型只适用于单一语种,更换语种时需要重新建立码本库。另外单元选择模型在不同受测者中的泛化能力较差,因为每个说话人有不同的发音习惯和方言口音,码本库很难涵盖所有语音现象。
3 回归模型法
回归模型(Regression Model)应用合适的回归算法建立模型,使用大规模数据集训练模型,使得模型可以较好地“理解”语音声学特征与运动数据间的拟合关系。
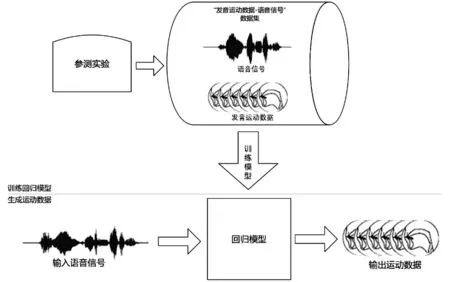
图2 回归模型
大多数回归模型忽略语音的语法规律,仅仅寻找声学特征与运动信息之间的映射关系。
Zelezny等人[16]为了拟合声音和模型动画关键帧上唇部、下颌标定点位置关系,建立了一个4状态、由左向右的HMM,再利用Cohen-Massaro协同发音模型[13]在关键帧间进行插值,完成标记点的平滑运动。HMM常被用于处理该类问题[17-19]。
Naraghi等人[20]建立了双链隐马尔可夫模型(Parallel Hidden Markov Model)实现了基于语音信号的唇部动画合成,还提出了一种形变算法用于动画的平滑处理。
Wielgat等人[21]利用动态时间规整(Dynamic Time Warping,DWT)算法实现语音信号和EMA数据的拟合,并且证明了在小数据集条件下,该方法比HMM表现更佳。
Malcangi等人[22]建立人工神经网络(Artificial Neural Network,ANN)来拟合关键帧上运动值,并利用模糊逻辑算法[13]做内插,平滑运动轨迹。Luo等人[14]利用深度信念网络(Deep Belief Network,DBN)实现语音反转,提取语音的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)及其衍生参数与EMA数据匹配。
Li[23]等人提出了一种方向相对位移(Directional Relative Displacement,DRD)特征提取方法来处理唇部、下颌和舌头的EMA运动数据。研究者在空间建立坐标系,提出了一组由嘴唇宽度、上下唇距离和各个EMA传感器方向相对位移等11个标准化参数构成的特征集合,再利用HMM寻找声音特征和特征集合的回归关系。
Tobing等人[29]提出了一种潜在轨迹高斯混合模型(Latent Trajectory Gaussian Mixture Model,LT-GMM)来处运动数据估计问题。传统的基于GMM的最大释然法,在训练阶段最优化GMM时会利用“语音信号-运动数据”数据集中的静态和动态特征,但在估计运动轨迹时只会利用静态特征,因为训练时和数据估计时所利用的特征空间不一致,GMM在这类问题中表现不佳,许多研究者在GMM的基础上再利用动态特征和静态特征的约束关系来优化帧间关联[24-28],但这种方法繁琐麻烦。Patrick设计的模型利用最大期望算法优化参数,解决了特征空间不一致问题,并利用实验证明了LT-GMM在处理运动轨迹估计时优于传统方法。
近年来,一些研究者受选择模型的启发,将音素标定等方法应用于回归模型,目的是增加模型的先验知识,提高准确率。
Tamura等人[30]将语音划分到音节层级,利用一个4状态、由左向右的HMM研究各个音节和简单几何特征之间的关系。Taylor等人[31]利用带有音素标签的语音作为输入,采用一种改进的动态外观模型(Active Appearance Models,AAM)[32]跟踪唇部运动,并确定视频上的单元长度,训练HMM生成与音素对应的可变长动态唇部运动数据单元。Kuhnke等人[33]提出了一种基于音素标签和声学特征的新方法来构建语音特征集,并利用一种通用的随机森林方法[34]测试了语音特征集和3D网格序列间的回归关系。
回归模型是一个计算机自己从大量语料中学习规律的过程,尽管有改进算法也应用了语音规则,但往往研究者也很难说清楚计算机在做拟合过程中应用了哪些语音规律。近年来深度学习算法被广泛应用,在此类问题中也有较好表现,但是深度学习算法需要的数据量异常巨大。回归模型对语种的依赖程度较低。
4 总结
本文介绍了基于语音信号的发音器官运动估计技术的研究现状,重点阐述了基于单元选择模型和回归模型的方法。
单元选择模型对特定语种的语音规律和特定人的发音习惯依赖性高,在不同语种和不同发音口音人群中的泛化能力较差。模型中,码本库丰富程度将直接影响最终运动呈现逼真程度,但是大型码本库建设是极其繁重的工作。
回归模型主要寻找声学特征和运动轨迹之间的拟合关系,对语种和说话人口音依赖性较低,回归模型通常需要大量的训练数据。近年来,研究者利用将语音规律和回归算法结合的方法设计模型,取得了较好效果。
基于语音信号的发音器官运动估计技术近年来虽然取得了较大进展,但是仍然有许多问题需要解决,如:如何将语音规则和回归算法更好结合?如何设计出利用较小数据集训练的精巧模型?如何提高运动轨迹合成的精度和真实程度?这些问题将是今后的研究重点。
[1]M Schroeder.A brief history of synthetic speech[C].Speech Communication,1993,13(1):231-237.
[2]T Dutoit.An introduction to text-to-speech synthesis[M].Netherlands:Kluwer Academic,1997.
[3]P Meyer,J Schroeter,M M Sondhi.Design and evaluation of optimal cepstral lifters for accessing articulatory codebooks[C].IEEE Trans ASSP,1991,39(7):1493-1502.
[4]S Suzuki,T Okadome,M Honda.Determination of articulatory positions from speech acoustics by applying dynamic articulatory constraints[C].Proceedings of Int Conf Spoken Language Processing,1998.
[5]J D Edge,A Hilton.Visual speech synthesis from 3d video[C].European Conference Visual Media Production,2006,174-179.
[6]S Minnis,A P Breen.Modeling visual coarticulation in synthetic talking heads using a lip motion unit inventory with concatenative synthesis[C].International Conference on Spoken Language Processing,2000,759-762.
[7]Y Cao,P Faloutsos,E Kohler,F Pighin.Real-time speech motion synthesis from recorded motions[C].ACM SIGGRAPH/Eurographics symposium on Computer animation,2004,345-353.
[8]Z L Yu,S C Zeng.Acoustic-to-articulatory mapping codebook constraint for determining vocal-tract length for inverse speech problem and articulatory synthesis[C].5th international conference on signal processing proceedings,2000,827-830.
[9]S Hiroya,M Honda.Estimation of articulatory movements from speech acoustics using an HMM-based speech production model[J].IEEE Trans Speech Audio Process,2004,12(2):175-185.
[10]J Wei,Q Fang,X Zheng,W Lu,Y He,J Dang.Mapping ultrasound-based articulatory images and vowel sounds with deep neural network framework[J].Multimed Tools Appl,2016,(75):5223-5245.
[11]江辰,於俊,罗常伟,李睿,汪增福.基于生理舌头模型的语音可视化系统[J].中国图象图形学报,2015,20(9):1237-1246.
[12]W Mattheyses,W Verhelst.Audiovisual speech synthesis:an overview of the state-of-the-art[C].Speech Communication,2014,(66):182-217.
[13]M M Cohen,D W Massaro.Models and Techniques in Computer Animation[M].Springer-Verlag,1993,139-156.
[14]R Luo,Q Fang,J Wei.Acoustic VR in the mouth:A real-time speech-driven visual tongue system[J].Virtual Reality,IEEE,2017,112-121.
[15]G Klir,B Yuan.Fuzzy sets and fuzzy logic[M].Prentice Hall,1995.
[16]M Zelezny,Z Krnoul,P Cisar,J Matousek.Design,implementation and evaluation of the czech realistic audio-visual speech synthesis[J].Signal Processing,2006,86(12):3657-3673.
[17]S Hiroya,M Honda.Estimation of articulatory movements from speech acoustics using an HMM based speech production model[J].IEEE Trans SAP,2004,12(2):175-185.
[18]K Richmond.Advances in Nonlinear Speech Processing Lecture Notes in Computer Science[J].Trajectory Mixture Density Networks,2007,4885:263-272.
[19]T Hueber,A Ben,G Bailly,P Badin,F Eliséi.Cross-speaker Acoustic-to-Articulatory Inversion using Phone-based Trajectory HMM for Pronunciation Training[C].Proceedings of Interspeech,2012.
[20]Z Naraghi,M Jamzad.Speech driven lips animation for the Farsi language[C].International Symposium on Artificial Intelligence and Signal Processing,2015,201-205.
[21]R Wielgat,A Lorenc.Speech inversion by dynamic time warping method[C].International Conference on Signals and Electronic Systems,2016,81-84.
[22]M Malcangi.Text-driven avatars based on artificial neural networks and fuzzy logic[J].International journal of computers,2010,4(2):61-69.
[23]H Li,M H Yang,J H Tao.Speaker-independent lips and tongue visualization of vowels[C].Proceedings of ICASSP,2013,8106-8110.
[24]H Zen,K Tokuda,T Kitamura.Reformulating the HMM as a trajectory model by imposing explicit relationship between static and dynamic feature vector sequences[J].Computer Speech and Language,2007,21(1):760-764.
[25]T Toda,S Young.Trajectory training considering global variance for HMM-based speech synthesis[C].Proc ICCASP,2009,4025-4028.
[26]S Takamichi,T Toda,A W Black,S Nakamura.Modulation spectrum-constrained rajectory training algorithm for GMMbased voice conversion[C].Proc ICCASP,2015,4859-4863.
[27]C W Luo,J Yu,X Li,Z F Wang.Real Time Speech-Driven Facial Animation Using Gaussian Mixture Models[C].International Conference on Multimedia and Expo Workshops,2014,1-6.
[28]C W Luo,J Yu,Z F Wang.Synthesizing Real-Time Speech-Driven Facial Animation[C].International Conference on Acoustics,Speech and Signal Processing,2014,4568-4572.
[29]P L Tobing,H K Toda,H Kameoka,S Nakamur.Acoustic-to-Articulatory Inversion Mapping based on Latent Trajectory Gaussian Mixture Model[C].Inter Speech,2016,8(12):953-957.
[30]M Tamura,T Masuko,T Kobayashi,K Tokuda.Visual speech synthesis based on parameter generation from hmm:Speech-driven and text-and-speech-driven approaches[C].International Conference on Auditory-Visual Speech Processing,1998,221-226.
[31]S Taylor,M Mahler,B Theobald,I Matthews.Dynamic units of visual speech[C].ACM/ Eurographics Symposium on Computer Animation,2012,275-284.
[32]I Matthews,S Baker.Active appearance models revisited[J].International Journal of Computer Vision,2004,60(2):135-164.
[33]F Kuhnke,J Ostermann.Visual speech synthesis form 3D mesh sequences driven by combined speech features[C].Proceeding of the IEEE International Conference on Multimedia and Expo,2017,1075-1080.
[34]T Kim,Y S Yue,S Taylor,I Matthews.A Decision Tree Framework for Spatiotemporal Sequence Prediction[C].Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2015,577-586.
