基于SOM神经网络的高校图书馆个性化推荐服务系统构建*
2018-05-04刘爱琴李永清
刘爱琴,李永清
0 引言
图书馆个性化服务在高校图书馆建设中意义重大[1]。针对个性化需求,朱晓云认为应当研究用户群需求,进而从数据庞大的资源中提取真正满足用户需求的部分[2];张莉萍则强调知识整合,认为应当着眼用户需要,积极为其提供完善的知识信息服务[3]。不同学者对高校图书馆中如何进行个性化服务的观点趋于多元化。
资源分类不合理、资源检索机制不完善是当前高校图书馆数字化建设面临的一个重要问题。原有机械式的文献分类方法已难以满足现代高校读者的图书使用需求,面对用户的个性化需求,也难以提供一个良好的处理机制和规范。
通过获取用户We b访问数据,对用户行为进行聚类,根据用户需求实现资源的个性化推荐,将有效地提升高校图书馆的服务质量。山西大学图书馆记录了大量学生和老师的访问数据,其中包含用户的I P地址、上网时间、访问时长以及访问资源内容等信息[4]。本文以山西大学图书馆为例,首先借助SOM神经网络对读者We b访问行为进行聚类和优化分析,其中,聚类优化算法分为粗调整和微调整两个优化阶段,以保证聚类效果和聚类速率的提升;其次,基于用户分析输出结果,筛选整合相关数据资源,形成可靠性和可用性更高的关联数据集,并结合语义检索和属性值匹配等技术,构建高校图书馆用户个性化推荐服务系统;最后,验证系统有效性,实现图书馆内部主题推荐、图书推荐和专家推荐三个子系统的协同,并通过用户与文献资源特征的深层次挖掘,识别用户的兴趣点和所在聚类集。
1 神经网络聚类体系构建
1.1 SOM神经网络聚类
在现代智慧图书馆的构建中,用户的个性化资源推荐服务越来越受到重视,数据深层次挖掘在图书馆工作中的比重不断增加,这就要求个性化推荐算法具备及时处理大规模数据、有效处理高维数据、对异常数据值不敏感等特征。同时,相较于其他类型图书馆,高校图书馆用户类型较为单一、访问数据针对性较强,数据集中性和可用性更高。因此,当前在图书馆个性化推荐服务中,研究人员可从不同的方面予以尝试,有针对性地响应用户个性化需求。各类方法的着眼点均在于挖掘数据之间的关联,并将这种关联应用于服务工作。从类型上看,主要分为文献资源关联、用户行为关联、检索词关联三大类。其中,文献资源关联主要是通过关联借阅访问信息来对文献资源属性进行二次挖掘,找出其中深层的关联价值[5];用户行为关联主要是根据读者借阅访问信息来将读者划分集群,根据不同集群进行相似性爱好预测推荐[6];检索词关联主要将现有文献和标题进行深层次解读,根据文献主题[7]、关键词语义相似度匹配度和文献关键词复现率等规则进行推荐[8]。
在现有个性化资源推荐算法中,聚类算法应用最为普遍。聚类是指将对象基于一定特征的相似程度进行分组,实现组内相似度最大,组间相似度最小效果的过程[9]。在数据深层次挖掘中,减少错误率,提高精准度非常重要。本文选取SOM神经网络聚类算法来进行分析。SOM网络[10]基于人工智能神经系统实施聚类,具有无导师自组织学习,无参数、精准化和稳定性强的特点,能够将高维数据映射为一维或者二维数据,在聚类时间和聚类效果上都具有显著优点,主要应用于智慧神经网络构建分析、大数据分析处理和用户个性化服务等领域。该方法的无参数特征能有效规避参数选择导致的聚类结果不客观问题;自组织学习特征能很好地将需要聚类的用户信息进行关系整合,避免人为操作工作量大、分类困难的问题;高校图书馆的数据可用性较高这一特征也有效促进了SOM神经网络聚类效果,可靠性的实现,对研究者和学习者进行学科综合和方法借鉴均有很大意义。本文将用户个人特征信息、用户行为数据、文献数据库数据进行整合,搭建用户的个性化推荐服务系统。
徐涌等[11]在进行Web用户聚类时采用了标准的Kohonen神经网络方法,但该方法聚类速度慢,难以应用于规模较大的数据分析;段隆振等[12]基于标准的Kohonen神经网络算法,将数据调整分为粗调整和微调整并采用不同的函数形式来实现整体模型的优化训练。本文借助分阶段聚类思想,选取了2016年10月-2017年1月的用户Web访问相关数据进行模型优化,将聚类分为粗调整优化和微调整优化两个阶段,以提升聚类速率和聚类效果。在解决用户多兴趣度问题上,本文通过构建多个聚类中心,选取从2016年10月-2017年1月的用户访问数据进行仿真,仿真结果显示,该模型能够很好地选择向用户推荐多样化资源的比率,提升用户个性化推荐服务的精准度和体验效果。
1.2 数据选取和预处理
实现个性化推荐服务与用户兴趣需求相结合,需要对大量有价值的数据信息进行筛选和挖掘,构建评价指标体系。本文分别选取山西大学经济与管理学院、文学院、物理电子工程学院和环境与资源学院相关研究人员和学生的We b访问数据,分别代表交叉学科、文科、工科和理科4门学科,进行指标筛选分析和推荐预测。聚类指标选取上,主要选取以下指标进行分析。
(1)用户访问时长和专注度。用户访问时长和专注度可以间接反映用户对所选资源的满意度和采纳程度;专注度是衡量用户对推荐结果满意度的一项重要指标。
(2)关键词所属类别。用户检索的关键词存在不规范性,人机交互时需要对关键词进行相应分类处理,根据关键词所属类别进行初步分析,这对聚类效果以及后续个性化推荐意义重大。
(3)资源访问偏好。山西大学图书馆现有资源根据资源形态,可以分为纸质和电子资源两类;根据资源类别,主要可以分为图书、期刊、报纸、新闻、视频、课件、论文。
(4)资源筛选偏好。主要包括年代、出版社、作者、研究领域等。
(5)阅读方式。主要包括下载、借阅、在线阅读。由于部分用户检索后仅在图书馆直接查阅纸质资料,无法进行跟踪,因此暂时不考虑这类指标。
本文采用原始SOM神经网络框架,将网络划分为输入和输出两个层次。输入层输入从用户We b访问数据中提取的指标,每一指标对应一个输入层神经元;输出层为竞争层,根据用户输入数据进行竞争输出,为输入数据选择其所属类别。模型中,一维输入层和二维输出层的所有神经元间存在纵向全权连接,输入层中各个神经元相互独立,不存在权连接;在输出层中,为更好地进行模型训练,部分神经元间通过横向权连接来实现反馈调整,以提升模型训练的精准度和速度。
1.2.1 算法模型
模型优化过程中,通过自组织特征神经网络算法并结合模糊数学中隶属度相关概念,将这个算法学习过程分为三步。第一步,粗调整学习运算,通过计算来确定输出层中对应的获胜神经元坐标,实现初步聚类;第二步,提升聚类速度,在邻域缩小的过程中本文首先采用指数函数作为邻域函数;第三步,微调整学习运算,将获胜神经元进行进一步的集中优化,以获取更为精准的聚类关键点。在这一过程中,需要对较为集中的连接神经元间的权值进行优化调整,以解决聚类精准度低、学习速率相对较慢的问题。在邻域函数权值优化调整中,不断采用线性递减函数,直至最终模型训练优化完成。
x1,x2,…,xm表示输入层的m维输入向量,记为为模型纵向全连接时的权值向量,记做其中,j=1,2,…,n,为n个输出层向量对应的神经元。
1.2.2 获胜神经元的选取
模型的竞争优化过程,实质是通过计算输入向量和全连接权值向量间的相似性来进行筛选优化。常见可用性较高的度量输入向量和权值向量之间相似程度的计算方法为欧式距离法和余弦法[13]。一般选择输入向量和权值向量相似度最高即欧式距离值最小的输出层神经元作为获胜神经元,获胜神经元比其他输出层神经元享有更高程度的优化,并依据相应规则进行权值处理。本文具体选取步骤如下:
第一,计算网络模型中输入向量和对应输出层全连接权值向量间距离,采用公式:

其中j=1,2,…,n;dj表示输入向量x和第j个输出层神经元对应的权值向量wj之间的距离。
第二,在选择获胜神经元时,首先需要将X、Wj(j=1,2,…,n),全部进行归一化,得到
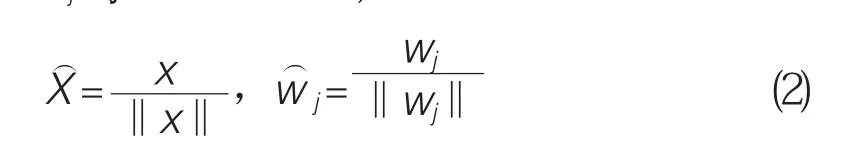
接下来计算并对比输入向量和权值向量之间的相近程度,即计算并选取间距离最小值对应的输出层神经元,设获胜神经元权值向量为

1.2.3 学习率和邻域调整
权值调整阶段,激活邻域所属范围内的全部神经元,学习率调整函数采用线性递减函数,聚类难以达到预期效果。本文在粗调整优化阶段采用指数函数进行初始学习率调整,迅速实现神经元的初步聚类;在微调整优化阶段采用线性递减函数对学习率进一步调整,能够很好地保证聚类效果的准确性。在学习率调整时,初始阶段设置较大的邻域能够保证初始输入神经元有更大的影响效果,提升收敛速度;随着学习率调整的进行,邻域需要逐步保证聚类的稳定性,故需要缩减邻域尺寸。学习率调整采用如下公式:

其中,β0是初始学习率;βt为经过t次迭代后的学习率;T为常数,作用为使得经过t次迭代后学习率缩减到0。
常用指数衰减法来迭代调整邻域尺寸:

其中,σt是经过t次迭代后的邻域宽度,σ0为初始邻域宽度;T为常数,作用为使得经过t次迭代后指数函数缩减到0。
根据邻域函数进行权值向量调整时,借助墨西哥草帽模型,利用各个输出层神经元c和获胜神经元j间的欧式距离来锁定范围并调整对应强度:
1.2.4 模型优化
第一,输入获取到的、经过预处理的优化学习样本并输出优化学习中经调整的权值向量矩阵,该权值向量矩阵能够准确地对输入的测试样本进行聚类。
第二,权值向量初始化。模型优化时,必须进行全连接权值向量初始化,即为权值向量wij赋予初值,wij的值线性无关。在优化学习过程中,通过MATLAB软件为权值向量赋予初始随机值。
第三,优化学习向量输入。输入新向量X=[x1(t),x2(t),…,xm(t)]T。其中,t表示优化学习次数,初始值为0,定义学习优化总次数为T。
第四,借助公式(1)计算第t次的X和输出层各神经元之间对应权值向量的欧式距离,并计算及选取获胜神经元j*。
第五,选择优胜邻域。以获胜神经元j*作为中心,根据优化次数t来确定优化邻域半径。初始邻域范围Sj*(0)最大,随着优化次数的增加,邻域范围Sj*(t)逐步收缩。本文采用指数衰减法来缩减邻域范围。
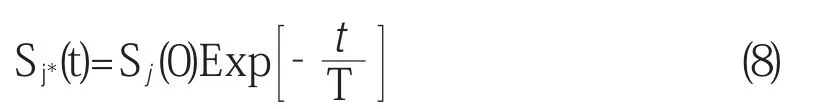
第六,权值优化学习调整。权值优化调整采用权值调整函数:

其中,βt表示第t次优化的学习率,当为粗调整时采用公式(4),微调整时采用公式(5);hij(t)为第t次优化学习时竞争层神经元i所应当调整的邻域程度。对应地,调整后的权向量为:

不断重复以上步骤,当达到MATLAB设置的初始优化学习次数后,学习结束。存储并导出全部全连接权系数,模型优化结束。
1.2.5 模型应用
针对模型优化结果,在试验应用时,需要遵循以下的步骤:第一,向量归一化,即将输入向量和权连接向量进行归一化调整,见公式11和公式12,以保证向量之间欧式距离计算比较时的科学性和可用性;第二,选取一个输入向量并计算该向量与所有连接权值向量之间所对应的欧式距离;第三,计算比较得出输出层获胜神经元,即该输入向量所属的聚类类别点。

1.3 实验结果
本实验模型优化结合标准Kohonen算法优势,在此基础上进行改进,在粗调整阶段采用指数函数,微调整阶段采用线性函数,借助墨西哥草帽函数思想来调整邻域强度,提升收敛效果和可靠性。通过对前期搜集数据进行分析优化,形成可进行用户行为聚类的代表性神经网络系统。本文算法在Intel(R)Core(TM)i5/4G RAM/windows 10/MATLAB R2016a机器上进行12000次粗调整优化和5000次微调整优化,并进行了样本仿真。从2016年10月-2017年1月的用户访问数据中随机抽取800条数据进行聚类仿真。由于维度限制和神经元权值向量分散度高,最终聚类结果以示意图形式给出,对应的用户行为聚类点在输出层的体现如图1所示。图1中4个红色虚线框分别表示4个不同学科的聚类集合,根据实际用户访问量和访问记录,可知图1中①-④分别代表物理电子工程学院、文学院、环境与资源学院和经济与管理学院。聚类结果显示不同学科聚类范围存在明显差异,部分存在交叉现象,即不同学科之间存在较为明显的研究兴趣界限,又存在学科交叉关系。

图1 不同学院输入向量神经元聚类
2 个性化推荐服务系统构建与分析
2.1 系统构建
基于SOM神经网络的模型优化训练结果,构建基于高校图书馆的个性化推荐服务系统,见图2。聚类结果揭示用户多种We b访问数据的隐含规律,个性化推荐中需进一步将这一结果与用户和图书馆现有资源实现整合连接。系统架构包括3个部分:数据层、网络层、应用层。其中,数据层主要完成各类数据的整合操作,并将相应算法进行封装,为网络层数据调用和计算提供支持[14]。Web访问数据便于用户查看历史访问记录;用户特征信息库将用户相关信息整合,进而对用户进行身份识别;聚类结果数据描述将SOM神经网络聚类算法结果进行计算机语言表述,和资源库一起为实现资源检索和个性化推荐提供支持,提升实体信息服务的匹配效率和准确性[15]。网络层是连接数据层和应用层的桥梁,将用户检索数据进行匹配,借助相应算法从数据层读取筛选结果。同时数据层还进行相关算法和数据库修正操作,以满足用户需求。应用层实现相关资源推荐的可视化交互服务:将用户输入数据传输到网络层进行相应计算,并将计算结果以可视化语言输出,为用户提供个性化资源推荐服务;同时搜集用户访问Web相关数据,后续向下层传输,便于网络层进行数据调整,保证系统可靠性。整个个性化推荐服务过程由数据层、网络层和应用层协调配合完成,具体流程如图3所示。
2.2 服务实现
基于现有系统,个性化推荐服务需要数据层、网络层和应用层的有效配合。用户个性化需求提出后,系统需要根据用户需求及时作出响应。通过前期数据挖掘,揭示用户兴趣点、阅读爱好和研究方向三大个性特征,以及学科关联、知识关联和资源关联三大主要群体特征。针对读者提供的个性化推荐服务中,系统主要进行以下操作:(1)已有信息检索。用户登录系统时,系统自动读取用户历史记录和过去We b访问聚类数据。向用户推荐相关资源,同时读取用户搜索关键词,与现有用户特征信息进行匹配,对文献资源库进行检索并输出结果,推荐结果根据用户个性化需求进行排序。(2)知识关联展示。根据集群内不同用户访问情况,根据知识关联程度向用户展示关联资源,方便用户获取。(3)用户信息更新。根据用户使用推荐吻合度和用户满意度,设定阈值,对用户兴趣点和聚类集群进行改进和重塑,提升用户体验。

图2 高校图书馆个性化推荐服务系统架构

图3 个性化推荐服务实现流程图
个性化推荐服务系统建设中,SOM神经网络聚类算法起着决定性作用。此外,系统应用中需要结合现有最新计算机相关技术,以达到系统最优利用效果。比如,采用SILK语言进行语义搜索中的属性值匹配计算,通过RDF来链接和描述实体之间的相互关系,并将检索结果进行输出。
本系统在应用中,将不同的学科进行弱分类,在区别各个学科之间边界的同时也重视各个学科之间的关联关系,降低跨学科知识借鉴和交流壁垒,突出用户兴趣点和研究方向。系统弱化检索阈值,对用户多兴趣点问题进行自动协调,提高系统查准率的同时,避免资源推荐冗余现象,提升了总体服务质量。
2.3 有效性验证
原有系统中,图书馆根据资源分类进行推荐服务时,由于研究热点中存在学科交叉现象,分类明确但实施困难。在基于SOM神经网络聚类算法的个性化推荐服务中,将推荐方案细分为主题推荐、专家推荐和图书推荐3个子系统。这3种推荐依托于用户兴趣点,分别提供热点资源和专题文献等一系列服务,基于读者不同类型的需要提供有差异的精准推荐。
选取2016年10月初至2017年1月中旬109天的用户访问数据进行分析。在基于SOM神经网络聚类算法的个性化推荐服务中,为减少人为因素影响,系统基于原始管理类研究热点数据,进行数据整合,并按照SOM神经网络聚类算法进行自动聚类,向用户推荐输出结果。用户输入检索关键词后,系统自动识别并使用新的推荐算法进行计算。原有系统推荐算法仅考虑用户输入关键词的词义匹配,精确度较低。在新系统个性化推荐算法中,系统会首先识别用户身份,从用户原始We b访问数据聚类集群中进行对比分析。如果分析结果符合用户所属聚类集群,则根据用户集群中相似性语义关键词和用户过去兴趣点进行双重匹配,为用户输出推荐结果;如果分析结果不符合用户所属聚类集群,则直接借助现有关键词进行语义分析和聚类,并根据用户需求所属类别进行推荐,同时存储用户访问效果数据,以备后续调整修正。在山西大学图书馆用户Web访问数据研究中,将用户数据按照关联数据集进行集群化存储,以便在用户检索时能够及时找到对应所属集群进行推荐,也能够根据集群用户访问效果及时对整体系统的推荐效果进行修正。通过系统前期运营分析,得出这段时期内的系统运作情形,如图4所示。

图4 个性化推荐服务系统之间的协同
在推荐吻合度计算时,根据用户检索访问时长、方式(下载、在线浏览)计算有效访问数值,之后计算推荐吻合效果。在初始阶段,3种推荐数据都会有较大的波动,不同的系统发展情况有较大的差异。随着系统数据的完善和计算结果的更新,整体系统的稳定性逐渐提升,推荐吻合度也整体呈现上升趋势。由于不同学院不同时间段参与的用户人数不均衡和用户专业性不同,使得各学院用户采纳的波动情况和效果有较大差别。从整体上看,整个系统在后期均出现图书推荐、主题推荐和专家推荐3个子系统之间的协同趋势。
2.4 系统应用
本系统对用户兴趣行为采用开放式运行机制,以有效避免学科交叉和学科综合导致的推荐不准确的问题出现;同时,通过设定阈值和定期进行数据更新的方式,对SOM神经网络聚类结果进行调整,有效规避了由于用户兴趣转移而导致的信息迷航问题。

图5 学科团队建设挖掘示意图
[1]刘恩涛,李国俊,邱小花,等.MOOCs对高校图书馆的影响研究[J].图书馆杂志,2014(2):67-71.
[2]朱晓云.Web数据挖掘与个性化信息服务中用户研究[J].情报杂志,2004(2):34-35.
[3]张莉萍.论图书馆个性化服务中用户信息的Web数据挖掘[J].情报资料工作,2007(2):101-103,93.
[4]欧阳烽.Web数据挖掘与高校数字图书馆个性化服务[J].现代情报,2008(1):103-104,107.
[5]张文华,胡春,胡光林,等.基于图书馆流通数据的聚类分析研究[J].农业图书情报学刊,2010(10):109-111,130.
[6]杨昌顺.聚类分析在图书馆读者群体细分中的研究和应用[J].贵州师范学院学报,2012(6):11-17.
[7]章成志,张庆国,师庆辉.基于主题聚类的主题数字图书馆构建[J].中国图书馆学报,2008(6):64-69.
[8]刘敏,马秀峰.基于共词聚类分析的数字图书馆热点研究[J].农业图书情报学刊,2017(4):67-71.
[9]Thamaraiselvi,G,Kaliammal,A.Data Mining:Concepts and Techniques[J].SRELS Journal of Information Management,2004,41 (4):339-348.
[10]张德丰.MATLAB神经网络应用技术[M].北京:机械工业出版社,2012:50.
[11]徐涌,陈恩红,王煦法.基于神经网络的Web用户行为聚类分析[J].小型微型计算机系统,2001(6):699-702.
[12]段隆振,朱敏,王靓明.基于双Kohonen神经网络的Web用户访问模式挖掘算法[J].计算机工程与科学,2009 (9):95-98.
[13]柳胜国.数字图书馆个性化服务与Web日志挖掘数据预处理技术[J].现代情报,2007(7):65-67.
[14]D Hienert,BZapilko,P Schaer,et al.Vizgr: Linking Datain Visualizations[M]//Web Information Systemsand Technologies.Berlin:Springer,2017:177-191.
[15]高劲松,周习曼,梁艳琪.面向关联数据的实体链接发现方法研究[J].中国图书馆学报,2016(6):85-101.
