APT木马网络协议逆向自动化分析
2018-05-03潘思远王轶骏
潘思远 王轶骏 薛 质 林 祥
(上海交通大学电子信息与电气工程学院 上海 200240)
0 引 言
随着信息时代的全面到来,互联网规模不断扩大,与社会发展日渐紧密结合。互联网在给社会带来极大便利的同时,也带来了各种各样的安全问题。各种网络攻击与入侵行为层出不穷,其中,近几年来,APT攻击尤其引起信息安全行业从业人员的广泛关注。作为一种精确、高效、隐秘性强的网络攻击方式,APT攻击被广泛应用于针对企业与各级国家机构的各种网络攻击行动中,成为企业与国家信息安全面临的一个重大挑战。
在APT攻击中,攻击者普遍使用远程控制木马作为攻击行动中的远程控制工具,主要用于保持控制、信息窃取等。同时,被选择应用于进行APT攻击的远程控制木马往往是非公开的未知木马,这些木马由于具有未知的动态行为特征与静态特征,从而难以被检测与发现。
对于远程控制木马的检测,业界常用手段包括静态特征检测与动态行为检测。其中,静态特征检测主要指基于特征码的静态特征检测,通过扫描文件系统中的文件,判断其是否具备已知的木马静态特征码,从而完成检测。由于该方法需要对文件系统中的文件进行扫描,必然需要消耗大量的资源,因而一般只适用于特定的少数主机,而难以大量部署。而动态行为检测中又包括本地行为检测与网络行为检测,由于本地行为检测要求主机将所有可执行文件预先在沙盒环境中运行,从而获取可执行文件的行为特征,进行判断,必然也需要消耗大量资源。因此在实际环境中,往往采用部署于中心网络节点的网络行为检测系统,通过对网络数据流的监控,发现内网环境中产生的可疑数据流,从而定位到受到木马感染的主机。
综上,关于APT木马网络行为特征的分析与提取对于APT攻击的检测有着关键的作用。当前,由于APT木马的独特性与复杂性,信息安全从业人员对于APT木马通信行为特征的分析与提取主要采用的还是人工分析的方法。但是,在实际的分析工作中,APT木马为了躲避杀软的分析与检测会衍生出各种相似而又相互不同的变种,这给人工分析带来了大量的困难,使得人工分析将会浪费大量的精力在于变种APT木马上。
未知网络协议逆向技术能够提取出未知网络协议格式,从而应用于网络行为特征的提取上。如张楠[1]将网络协议逆向应用于无线环境下未知协议指纹特征的提取上;张俊娇[2]将协议逆向应用于比特流协议的特征提取上。在此,本文提出一种能够应用于APT木马网络行为特征提取的协议逆向方法,并实现了该方法的原型系统,对若干个木马样本进行测试分析来证明其有效性。
1 国内外研究现状
目前国内外针对APT木马网络协议逆向的研究较少,在未知网络协议逆向方面的研究主要集中在通用网络应用的应用层协议逆向上。目前被提出的未知网络协议逆向的主要方法可以被分为两大类:基于指令序列的污点分析方法与基于报文数据的统计分析方法[3]。
在基于指令序列的污点分析方法中,未知网络协议的协议规范被映射为一组指令序列。通过对报文数据打上标签(污点数据),观察污点数据在指令序列中被处理的流程,从而能够对报文数据进行划分数据域,并能够得到报文数据中的各个数据域的约束关系与实现对数据域的语义分析。基于该方法,Caballero等[4]设计出了Polyglot原型系统,实现了对网络协议的字段划分与属性判断。而Lin等[5]、Comparetii等[6]、Cui等[7]由分别基于该方法提出了自己的改进设计。在国内,应凌云等[8]借鉴Polyglot的思想,设计出了Prama原型系统,Prama引入了API分析的方法,降低了存粹指令级分析的运算复杂度。以上的原型系统针对网络协议的分析都是基于明文协议的,而当前越来越多的网络协议基于安全考虑采用了加密传输,Wang等[9]研究发现OpenSSL库中许多加解密算法的解密指令集与明文协议的解析指令有着明显的区别。同时又考虑到加密网络协议的解密阶段与协议报文解析阶段一般是相互独立的,设计出了一套针对加密未知网络协议逆向的原型系统ReFormat。近几年,还有王庆亮[10]的通过动态污点扩散逻辑树的方法,王军[11]的基于EDSM的二进制协议状态机逆向以及高君丰等[12]的污点回溯逆向方法等。
而基于报文数据的统计分析方法则是利用同一协议的报文间存在相同的协议规范约束,从而天然具备相似的字符集与语法特性。因此在大量的同一网络协议的报文数据中的统计规律必然会体现出该网络协议的协议特征。国外的Protocol Information Project中结合生物信息学DNA序列研究中的多序列比对算法,来提取同一网络协议的大量数据报文中的公共序列,从而进行协议的逆向分析。多序列比对算法对于定长的协议数据域有较好的效果,但对于变长数据域则可能导致错位等分析误差,为了改善该问题,Cui等[13]设计出了Discoverer原型系统。该原型系统采用基于Token的序列比对算法,从而避免了变长序列比对的情况。因此,该系统的协议逆向结果取决于协议报文数据中的Token的识别与划分。除基于序列比对的方法以外,Zhang等[14]通过应用NLP(Natural Language Processing)中的断词和短语识别技术来进行协议字段识别,并设计出了ProWord原型系统。Bossert等[15]设计出了Netzob原型系统,加入了对协议报文数据的基于上下文的语义分析方法,而上下文数据主要来源于Sikuri与Cuckoo的采集。近两年,国内的还有罗建祯等[16]的基于极大似然概率的协议关键词长度确定方法,孟凡治等[17]的基于概率比对的协议逆向方法以及何超等[18]的基于Seq Cluster的未知协议聚类分析等。
2 APT木马网络协议逆向自动化技术理论基础
对于APT木马,一般难以获取其控制端样本,木马分析人员所能够获取到的只有受控端样本甚至只有木马的部分通信数据包。因此,对于APT木马的网络协议逆向基本上只能够基于数据报文的统计分析。下面将对一些应用于APT木马网络协议逆向分析的算法进行介绍。
2.1 多序列比对算法
多序列比对MSA(Multiple Sequence Alignment)算法最早应用于生物信息学领域,用于比对多条DNA序列,实现序列对齐,寻找最佳匹配模式。多序列比对有多种实现的算法,在此,主要介绍Needleman-Wunsch算法[19]。
考虑较为简单的两条序列的比对,Needleman-Wunsch算法允许两条序列中不同或相同的元素比对,也允许序列中的元素与间隙进行比对,并且赋予这三种比对相应的权值。简单地,可以选择相同元素的比对权值为1,其他比对方式权值为0。对于长度分别为m、n的序列M、N,构造mn大小的二维表map,行对应M序列,列对应N长序列,如果M[i]与N[j]相等,它们比对贡献map[i][j]权值1,否则贡献0。而map[i][j]的总权值表示从M[0:i]到N[0:j]的最高权值比对的权值,并填入map表中。因此,可以从左上角开始按一下规则填充表。
map[i][j]=max(map[i-1][j],map[i][j-1],map[i-1][j-1]-1)M[i]=N[j]
(1)
map[i][j]=max(map[i-1][j],map[i][j-1])
M[i]≠N[j]
(2)
在填充完成后,从矩阵右下角开始回溯,从而获取最优比对序列。
2.2 聚类算法
聚类算法主要可以划分为以K-means[20]算法为代表的划分方法和以BIRCH算法[21]和DBSCAN算法[22]为代表的层次方法两种。在这里主要介绍凝聚型层次聚类算法的思想:
凝聚型层次聚类的思想是将每个对象看做一个独立的簇,通过不断的合并操作,将不同的簇合并成一个新的簇,直到达到了某个目标条件。聚类的步骤如下:
1) 将每个对象看做一个簇,并计算两两间的距离;
2) 合并距离最小的两个簇;
3) 计算新簇与其他簇间的距离;
4) 判断是否达到目标条件,达到则聚类完成,否则回到步骤2)。
3 APT木马网络协议自动化逆向分析方案设计
为了实现对APT木马网络协议的自动化逆向分析,整个设计方案可以划分为两个阶段:一个阶段是APT木马通信数据和上下文信息的采集,另一个阶段是基于APT木马通信数据和上下文信息的协议逆向分析。
结合两个阶段,完整的分析流程原理结构如图1所示。
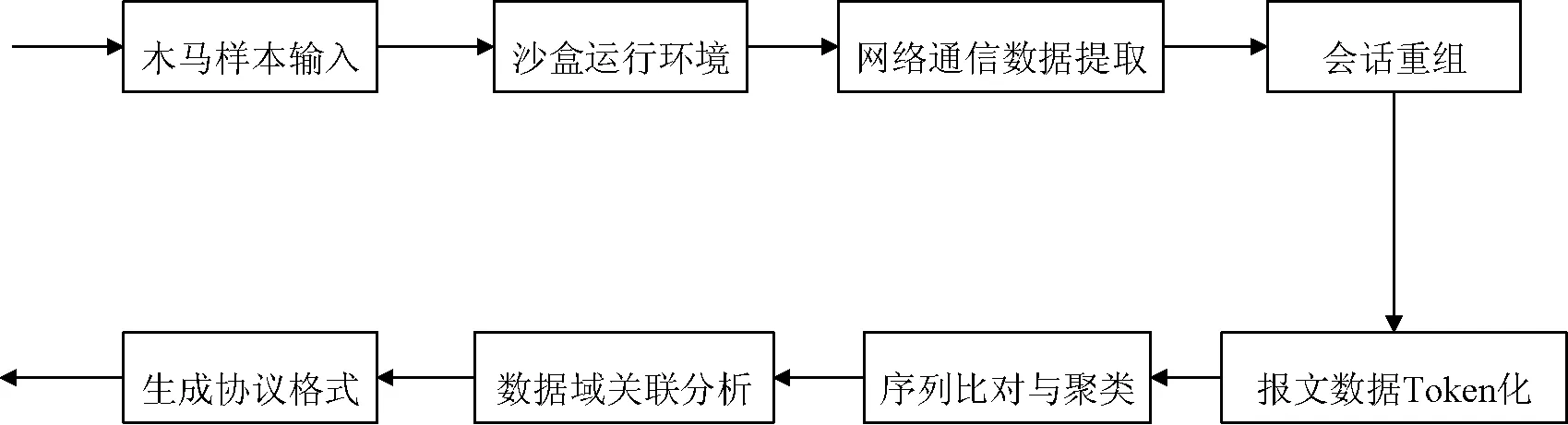
图1 分析流程原理结构图
3.1 APT木马通信报文数据及上下文信息采集
对于通信数据和上下文信息的采集,主要的方法是动态分析。在沙盒环境中运行APT木马样本,通过将网卡设置为混杂模式来监听网卡,从而采集APT木马样本的通信数据。而上下文信息主要指的是沙盒环境的上下文信息,包括操作系统信息、用户信息和网络环境信息等。该信息能够直接通过沙盒环境获得。沙盒环境逻辑结构如图2所示。

图2 沙盒环境结构图
3.1.1 Cuckoo沙盒
对于沙盒环境,采用的是作为一款开源的沙盒软件——Cuckoo[23]。Cuckoo是一款专门应用于恶意代码分析领域的沙盒,不仅能够对恶意代码进行静态分析,以提取PE头中的信息和字符信息,它还能够记录恶意代码对API的调用和恶意代码文件释放操作,截取网络流量数据以及进行一定程度的内存分析。在这里,由于只需要获取网络数据,因此对于一些不必要的功能做了一些裁剪,以提升性能。
为了使得对于恶意代码样本的分析不被攻击者所察觉,沙盒环境必须部署在封闭的网络环境中,这样恶意代码样本就不能够实现与攻击者控制端进行通信,同时,也需要采集恶意代码与控制端进行通信的网络流量数据。对于这个问题,可以通过采用以下两个方案来进行处理:
1) 在沙盒所在封闭网络环境中部署一台内部DNS服务器,对于任意的DNS查询都返回一个指定的内网地址。同时在内网环境中搭建一些常用的应用服务器来模拟真实网络环境,支持的协议包括HTTP/HTTPS、SMTP/SMTPS、POP/POP3、FTP/FTPS、TFTP、DNS等,这使得沙盒能够捕获到一些使用了某些常见网络协议作为隧道的恶意代码流量。对于这些模拟的网络环境,采用INetSim[24]来统一进行搭建。
2) 如果恶意代码直接使用IP地址来与控制端进行通信,那么方案1中基于DNS服务的方案就会失效。因此,通过Iptables来进行端口映射来实现将恶意代码与外网IP的连接映射到内网指定IP制定端口上的连接,使得恶意代码发起的TCP连接能够建立,同时又不能实际与外网进行通信,并且对恶意代码透明。
3.1.2 数据流重组
对于从沙盒环境中提出到的网络流量数据,是以pcap包的形式存在的,为了实现对pcap包内的网络数据进行分析,就必须进行数据流重组(特指TCP包)。由于在封闭网络环境中并没有真实的恶意代码的控制端,使得恶意代码与控制端的会话都没有正确的响应格式。因此,在协议逆向分析中,一个会话只有恶意代码发送的数据是有意义的。对于数据流重组,通过TCP连接三次握手过程来识别流的开始,并根据两个特征来标记流的结束,一个是TCP协议的四次挥手过程,另一个是时间超时。前面提到只有恶意代码发送的数据才有分析的意义,因此在流重组的步骤中只需要对恶意代码发送的数据包进行操作,而忽视其他的响应包,从而提高效率。
3.2 基于报文数据与上下文的协议自动化逆向
对于从pcap包中提取出来的会话,从逻辑上可以被划分为RAT受控端的上线会话。为了方便,在此称该会话中受控端发送到控制端的数据为上线包报文数据。对于上线包报文数据的处理,包括三个阶段:1) 报文数据的Token化;2) 报文数据Token模式匹配、聚类与协议格式提取;3) 协议内部数据域关联分析与语义分析。
3.3 报文数据Token化
由于报文数据本身具备变长数据域,直接使用报文数据来进行模式匹配必然会因为变长数据域而影响匹配结果。因此对于报文数据先进行Token化处理,目的是使得变长数据域被划分到同一个Token内,从而模式匹配的匹配单元被限定到Token之间。
Token化的方式有两种,一种是通过沙盒本身的上下文信息,如IP地址、主机名、操作系统信息等,对于这些上下文信息,在报文数据中查找它们的各种常用编码的结果,如大小数端、ASCII、UTF-16、Base64等。一旦查找到上述的上下文信息,就能将该数据域归为一个Token,并打上一个语义标签。
而对于其他的数据域,把它们归类为字符型数据域Token或者二进制数据域Token。对于字符型数据域,意味着它本身的数据是合法的ASCII字符或者UTF-16字符等常见编码的字符,并且为了避免误将二进制数据域的数据误判断为字符型数据,添加了长度的限制,必须连续四个字符以上的数据域才能被判断为字符型数据域。遵循上述原则,首先在报文数据中查找所有满足字符型数据域条件的数据,并将连续的该类数据归类为同一个数据域Token。然后根据相应的编码中的常见分隔符,如空格、换行符等作为分割,分隔得到多个字符型Token。对于剩下的数据域,将其归为二进制Token,每个Token包含一个字节的数据。
如图3所示,一个Token包含Type、Property、Semantics和Messages。Type表示Token类型(字符型或二进制型);Property表示Token属性,包括是否常量,长度是否定长;Semantics表示Token的语义;Messages表示Token对应的数据域的数据集合。
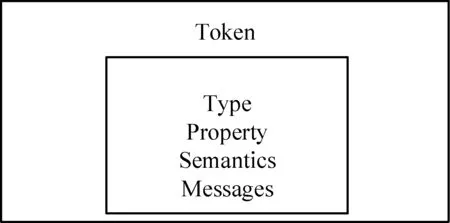
图3 Token结构图
3.4 报文数据模式匹配、聚类与协议格式提取
在上一步骤中,已经将所有的报文数据Token,每条报文数据都由一个Token的序列表示。后续将以报文数据的Token序列的匹配度作为聚类的相似度的依据。对于两个Token,如果判断它们完全相同,需要满足下面的两个条件:
1) 两个Token为同一个类型的Token;
2) 如果Token本身被打上了语义的标签,那么该语义标签必须相同,否则两个Token所包含的数据必须相同。
而对于同一个类型的两个Token,如果都没有打上语义的标签,则通过Token所包含的数据的长度来计算它们的之间的匹配度。
根据Needleman-Wunsch算法,能够很轻松地构造出两个Token序列匹配的匹配表,记为map,再以此计算Token序列的匹配度。但是从直观上看,对于两个不同的Token进行匹配和一个Token与空进行匹配的容忍度应该是不同的,所以需要对Needleman-Wunsch算法的匹配方式的权值进行一定的修改。
对于Token序列ts1和ts2有:
map[i][j]= max(map[i-1][j-1]+
s(ts1[i],ts2[j]),map[i-1]+
d,map[j-1]+d)
(3)
(4)
当两个Token相同时贡献权值1,当两个Token不等时贡献权值e(t1,t2),当Token与空匹配时贡献权值d。对于计算得到的map的最右下角的值map[maxts1][maxts2]可以用于表示两个Token序列的匹配度,对该值进行归一化,得到map[maxts1][maxts2]/
max(maxts1,maxts2)作为最终的两个Token序列的匹配度。
(5)
在聚类过程中,采用的是凝聚型层次聚类的方法。在初始状态时,称一条数据消息为一个message,在经过Token化后得到一个message对应的Token序列,一个簇包含一条Token序列。在聚类中过程中,通过Token序列的模式匹配计算簇与簇间的两两的匹配度,并对匹配度最高的两个簇进行合并,从而生成一个新的簇。因此,对两个簇进行合并的过程就是将两个Token序列进行合并的过程。由于通过Token序列的模式匹配,就能够得到两条Token序列对齐后的两条对齐序列,如图4所示。
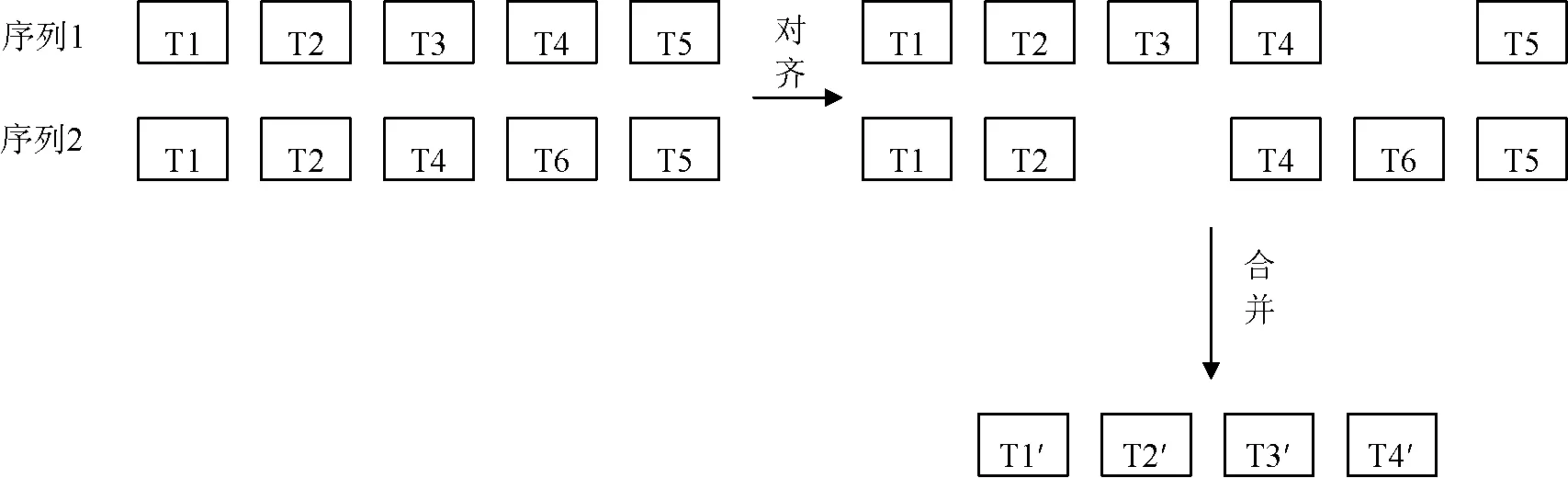
图4 Token序列对齐与合并
此时,对两个簇的合并就是对两条对齐后的Token序列的合并。以图4的对齐后的Token序列为例,合并的目标为得到一个新的Token序列:T1’、T2’、T3’、T4’。
Token的合并,分为上下对齐的Token的合并,与左右相邻的Token的合并两种。对于上下对齐的Token,直接将各自对应的message集合进行合并,保持其他的Token属性不变生成合并后的新Token。而对于左右相邻的Token的合并,首先合并它们对应的message集合,通过message的拼接得到集合大小与原来一致的新message集合。此外,如果是左合并则保持左侧Token的其余属性,如果是右合并则保持右侧Token的其余属性。并且通过计算左右合并对新的匹配Token序列整体的匹配度的大小来决定采用的合并方式。
对于两个对齐的Token,以图4中对齐的T1为例,序列1与序列2的两个T1合并得到新Token序列中的T1’。对于与间隙对齐的Token,意味着该Token很可能是Token化时的过度划分,因此该Token应该与相邻的Token合并。以图4中序列1的T3为例,T3依左合并和右合并两种不同的合并方式,影响到的是合并后的序列中的T2’和T3’。因此有两种情况,T2与T3合并,即T3的左合并,再与上下对齐的序列2的T2合并得到T2’,或T3与T4合并,即T3的右合并,再与上下对齐的序列2的T4合并得到T3’。在该情况下,T2’由两个对齐的两个T2上下合并得到。
最后,通过设定一个匹配度阈值,当任意两个簇间的匹配度低于该阈值时,聚类结束。剩下的每一个簇包含一个Token序列,各表示一种协议格式,而每种协议格式中的Token则表示一个数据域。
3.5 协议内部数据域关联分析与语义分析
在该部分的处理中,目标是将前面聚类后,初步得到的协议格式进一步进行分析,从而分析得到包括协议数据域的更多的信息,以及多个数据域间的关系,进而推断部分数据域的语义。
考虑到存在无关噪点数据的影响,首先需要剔除包含message数量较小的协议格式。对于剩下的协议格式中的Token包含的message进行分析,判断该数据域是否是常量数据域。如果Token包含的所有message都完全相同,那么认为该Token是一个常量的Token,否则,认为该Token为变量的Token。对于被判断为变量的Token,再根据它所包含的message的长度是否全部相同,来判断该Token是否是定长的。
对于所有被判断为变量的Token,如果一个Token的语义为另一个或另一些Token的长度或者偏移,那么该Token所包含的message与相对应的一个或多个Token的message间必然存在线性关系。通过检查各个Token中的message是否存在线性关系,就能够发现包含长度或偏移的语义的Token,从而扩充上一部分分析结果中的协议格式所包含的信息。
最终,对于相邻的被判断为常量的Token进行合并,在经过该部分处理后,得到最终提取的协议格式。
4 测试与分析
为了测试上文中描述的协议逆向方法,使用C++开发了相应的自动化分析原型系统,并对若干款远程控制木马软件的数个样本进行分析后,发现均能够得到可观的分析结果。下面分别以文本类型协议的njRAT和二进制类型协议的gh0st为例,使用通过上文介绍的方法开发的原型系统分析通信协议,并与开源的分析未知网络协议的软件netzob的分析结果进行对比。
4.1 文本型通信协议RAT软件——njRAT
njRAT是一款流行于中东地区的APT攻击中的一款RAT软件,它采用基于TCP协议的文本型自定义应用层协议进行与控制端的通信。在测试中,将若干个njRAT的样本经过沙盒提取其发送到控制端的上线数据包,由于沙盒运行于封闭内网环境中,因此捕获到的pcap包中的流量只包含njRAT的上线会话。经过原型系统的自动化分析后,得到了两种协议格式,如表1-表2所示。
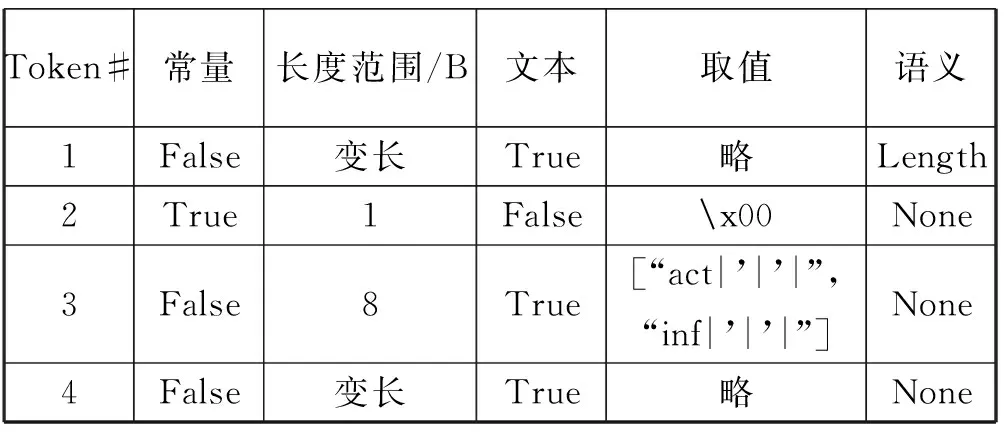
表2 njRAT通信协议格式二
从表1、表2的结果看,协议格式的提取结果是较为理想的。结合两张表,可以发现njRAT的通信协议满足的一个基本协议格式可以分为四块数据域:[Length][x00] [格式区分符] [其他数据]。格式区分符指的是能够根据其取值而决定协议格式中某一个或多个数据域内部格式的数据域,如HTTP协议中的GET、POST等方法。容易发现,两张表中前三个Token的协议格式是高度一致的,它们分别表示前三个数据域,第四块数据域的内部协议格式则是由第三块数据域的取值决定,如两张表中第二块数据域的取值有三种:“x00inf|’|’|”、“x00ll|’|’|”以及“x00act|’|’|”。
同时,从上面的结果也能够发现一点缺陷,在表1的协议格式中,可以注意到Token11与Token12存在Token的过度划分的现象,并且从取值可知,该两个Token表示的是njRAT样本运行环境的操作系统信息。对于该问题,可以对分析结果经过少量的人工辅助进行调整。
4.2 二进制型通信协议RAT软件——Gh0st
Gh0st是一款在国内比较流行的开源的RAT软件,它采用了基于TCP协议的二进制型自定义应用层协议与控制端通信。经过原型系统自动化分析,得到的通信协议如表3所示。
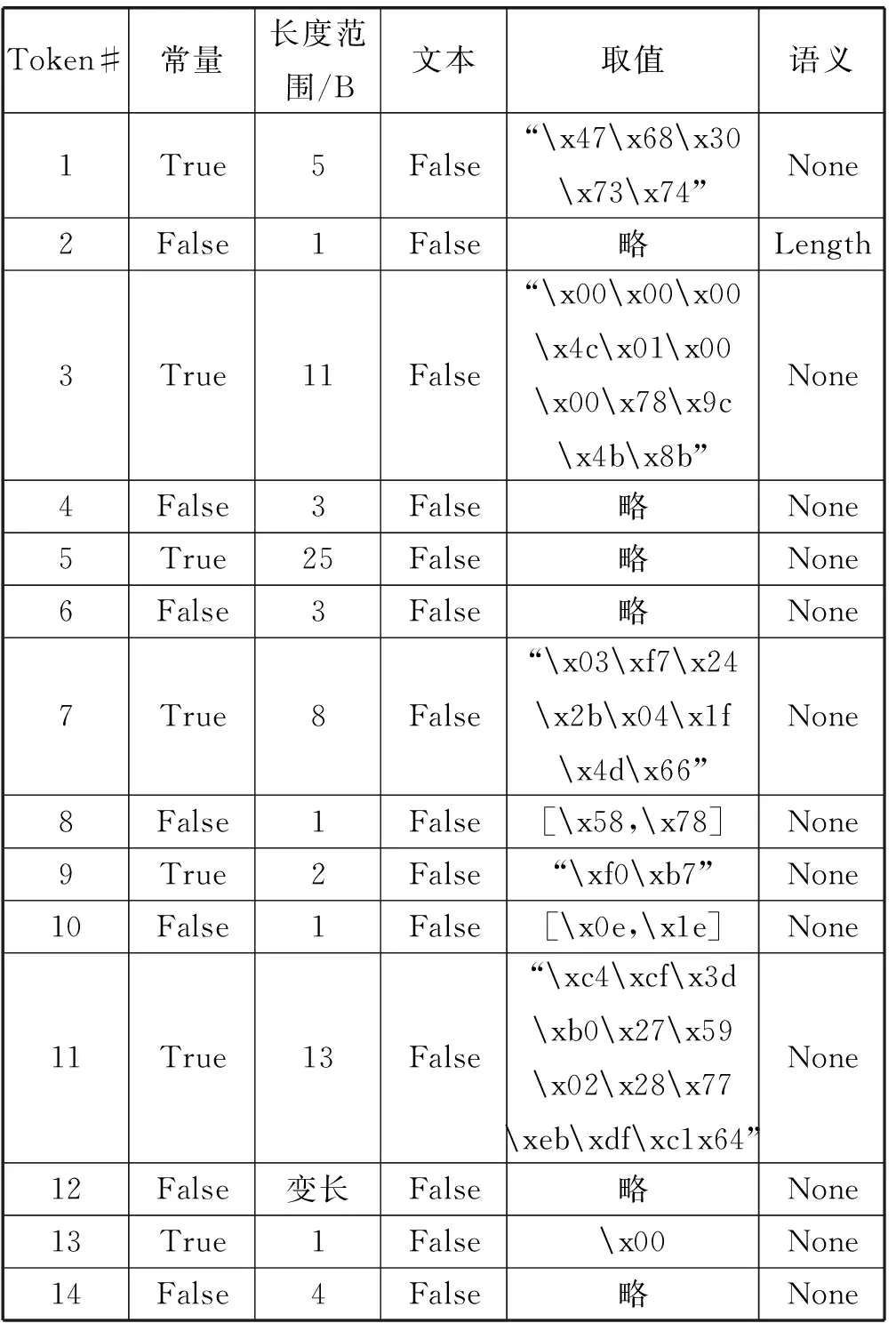
表3 Gh0st通信协议格式
从表3的结果看,Gh0st的通信协议整体可分为三个部分。第一部分包含Token1,它的内容恰好是“Gh0st”的Ascii码。第二部分是Token2,我们的原型系统将它的语义标记为Length,它的值等于整条通信消息的大小。第三部分是剩下的Token,它们都是不与沙盒环境提取的上下文信息匹配的二进制数据,这是由于数据压缩加密后的结果。这也是二进制型协议的一个特点,它们往往经过压缩加密,以至于难以发现其语义。但是由于使用的算法导致也具备一定的协议特征,如通信协议的倒数第五个字节固定为x00。
4.3 与netzob的对比分析
目前针对RAT未知网络协议逆向的开源工具很少,而netzob是能够应用于RAT未知网络协议逆向的一款半自动化工具。在此,使用netzob对相同的数据集进行分析,下面分别介绍njRAT与Gh0st的分析结果。
通过netzob对njRAT进行分析,只能得到一条协议格式,得到的协议格式如下:[2或3字节变长数据域] [x00] [2或3字节变长数据域] [|’|’|] [变长数据域] [|’|’| 或空]。从netzob对同样的数据集的分析可以看到,分析的结果与本文采用的方法分析得到的结果(表1和表2)有一定的相似性,比较明显的区别在于最后的两个数据域。事实上,njRAT的部分数据域使用了Base64编码,这也是netzob的分析结果中出现的数据域的原因,其实这是一个过渡的划分,而该问题并没有出现在本文所采用的分析方法上。同时,netzob的分析不能给出任何语义的结果。
同样对Gh0st使用netzob进行分析,得到的协议格式如下:[5字节常量数据域] [1字节定长数据域] [11字节常量数据域] [3字节定长数据域] [25字节常量数据域] [3字节定长数据域] [8字节常量数据域] [1字节数据域] [2字节常量数据域] [1字节数据域] [13字节常量数据域] [变长数据域] [1字节常量数据域] [变长数据域] [1字节常量数据域] [变长数据域] [1字节常量数据域] [变长数据域]。可以发现使用netzob分析的协议格式的前半部分与本文分析方法的到的协议格式的前半部分(表3中Token1到Token11)完全一致。但是,后面的差别较大,特别是netzob的分析结果中包含大量的一字节数据域和变长数据域。特别是netzob分析得到的变长数据域中的数据长度的差距极大,甚至出现了同一数据域中最短的数据只有几字节而最长的有数十字节的情况,而这样的情况对于RAT软件的通信协议是不合理的,其实是一种过渡的划分。并且,netzob的分析结果不包含任何语义的结果。
从整体上看,本文所诉的协议逆向方法对比netzob有着以下的优点:
1) 通过沙盒上下文提供语义分析的依据,对于文本型的协议有明显优势。
2) 相对不容易出现数据域的过度划分。
3) 当同一款RAT软件的通信协议中出现多种协议格式时,能够得到更细致的协议格式。
4) netzob的分析过程需要更多的人工参与(源于它图形化界面的操作),而用本文方法开发的原型系统只要提供通信数据包路径即可完成自动化分析。
5 结 语
对于未知网络协议的逆向,国内外研究人员结合多序列比对、聚类分析等方法提出了各种分析方法。本文结合过去研究人员提出的方法的优点,通过Token化来优化序列比对中变长数据域的比对,并通过沙盒环境的上下文信息来初步划分Token,通过聚类来对Token化进行优化以避免Token的过度划分,形成一种针对木马通信协议逆向的分析方法。虽然通过本文所阐述的方法能够达到了预期的协议逆向的目标,但也依然具有缺陷。如Token过度划分依然存在与语义分析依然不够精确的问题。因此,下一步的研究工作将着眼于提高Token划分与语义分析的精度,从而得到更为准确的协议逆向结果。
[1] 张楠.无线网络环境下未知协议指纹特征识别与分析[D].电子科技大学,2014.
[2] 张俊娇.比特流协议分析与特征识别技术研究[D].电子科技大学,2016.
[3] 刘渊,张春瑞,孟凡治,等.基于网络数据的协议逆向工程研究进展[J].计算机工程与设计,2015(11):2915-2920.
[4] Caballero J,Yin H,Liang Z,et al.Polyglot:automatic extraction of protocol message format using dynamic binary analysis[C]//ACM Conference on Computer and Communications Security,CCS 2007,Alexandria,Virginia,Usa,October.DBLP,2007:317-329.
[5] Lin Z,Jiang X,Xu D,et al.Automatic Protocol Format Reverse Engineering through Context-Aware Monitored Execution[C]//Proceedings of the Network and Distributed System Security Symposium,NDSS 2008,San Diego,California,USA,10th February-13th February 2008.
[6] Comparetti P M,Wondracek G,Kruegel C,et al.Prospex:Protocol Specification Extraction[C]//IEEE Symposium on Security and Privacy.IEEE Computer Society,2009:110-125.
[7] Cui W,Peinado M,Chen K,et al.Tupni:automatic reverse engineering of input formats[C]//ACM Conference on Computer and Communications Security.ACM,2008:391-402.
[8] 应凌云,杨轶,冯登国,等.恶意软件网络协议的语法和行为语义分析方法[J].软件学报,2011,22(7):1676-1689.
[9] Wang Z,Jiang X,Cui W,et al.ReFormat:Automatic Reverse Engineering of Encrypted Messages[C]//Computer Security-ESORICS 2009,European Symposium on Research in Computer Security,Saint-Malo,France,September 21-23,2009.Proceedings.DBLP,2009:200-215.
[10] 王庆亮.未知协议逆向分析关键技术研究[D].北方工业大学,2015.
[11] 王军.基于EDSM的二进制协议状态机逆向[D].哈尔滨工业大学,2016.
[12] 高君丰,张岳峰,罗森林,等.网络编码协议污点回溯逆向分析方法研究[J].信息网络安全,2017(1):68-76.
[13] Cui W D,Kannan J,Wang H J.Discoverer:Automatic protocol reverse engineering from network traces[C]//SS’07 Proceedings of 16th USENIX Security Symposium.2007:14.
[14] Zhang Z,Zhang Z,Lee P P C,et al.ProWord:An unsupervised approach to protocol feature word extraction[C]//INFOCOM,2014 Proceedings IEEE.IEEE,2014:1393-1401.
[15] Bossert G,Hiet G.Towards automated protocol reverse engineering using semantic information[C]//ACM Symposium on Information,Computer and Communications Security.ACM,2014:51-62.
[16] 罗建桢,余顺争,蔡君.基于最大似然概率的协议关键词长度确定方法[J].通信学报,2016,37(6):119-128.
[17] 孟凡治,李桐,刘渊,等.基于概率比对的通信协议格式逆向分析方法[J].计算机工程与设计,2016,37(9):2337-2341.
[18] 何超,刘方,曾曦.针对未知协议消息序列的聚类分析实现[J].通信技术,2017,50(2):277-286.
[19] Needleman S B,Wunsch C D.A general method applicable to the search for similarities in the amino acid sequence of two proteins[J].Journal of Molecular Biology,1970,48(3):443.
[20] Hartigan J A,Wong M A.A K-means clustering algorithm[J].Applied Statistics,1979,28(1):100-108.
[21] Zhang T,Ramakrishnan R,Livny M.BIRCH:an efficient data clustering method for very large databases[C]//ACM SIGMOD International Conference on Management of Data.ACM,1996:103-114.
[22] Ester M,Kriegel H P,Xu X.A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]//International Conference on Knowledge Discovery and Data Mining.AAAI Press,1996:226-231.
[23] Guarnieri C,Schloesser M,Bremer J,et al.Cuckoo sandbox-open source automated malware analysis[R].Black Hat USA,2013.
[24] Hungenberg T,Eckert M.INetSim[EB/OL].[2017-6-20].http://www.inetsim.org.
