共享汽车智能调度专家系统的研究
2018-05-03周鹏飞
周鹏飞 乔 佳 李 良
1(北京亿华通科技股份有限公司 北京 100192) 2(国家信息中心 北京 100045)
0 引 言
共享汽车租赁的概念起源于美国,最早是从传统的汽车短租业务切分出时间模块更短的分时租赁业务。随后部分汽车厂和创业公司也通通冲进这个领域,经过十数年的发展,以网点取还、自由取还、B2C模式为主的几大模式也已发展成熟。而在国内,经营模式与国外别无二致。由于在国内各大城市,分时汽车租赁网点大多位于城市核心位置或人口聚集地,网点内的汽车停车位的停车费用都较为高昂,而客户用车习惯往往具有聚集效应。这势必导致部分网点内车位数量不足和车辆停车费用过高的问题,同时有些网点则又出现车辆不足的情况。这种因异地还车服务导致共享汽车分布不合理的现象急需解决。目前主要解决方案是通过运营人员手动发起车辆调度,人工发起调度存在时效性差、缺乏有效预测等缺点。随着业务的不断扩大,当前调度方式显然不能满足业务发展需求。车辆智能调度系统ISS(Intelligent Scheduling System)能为汽车共享业务中出现的问题提供有效的解决方案。本文将基于真实运营数据,通过数据挖掘技术来进行ISS的研究与设计。
1 共享汽车智能调度专家系统简介
专家系统[1]ES也称为基于知识的系统,是人工智能学科最重要和最活跃的一个分支,是计算机应用的一个新领域。它实现了人工智能从理论研究走向实际应用,从一般思维方法探讨转入专门知识运用的重大突破,它重点强调知识在人类智能活动中的重要地位。简单地说,ES是一个在某一特定领域中,以人类专家水平处理困难问题的计算机程序系统。
共享汽车智能调度系统则是在专家系统的指导下的具体实现,它是基于知识的数据挖掘系统,通过数据挖掘和训练形成知识库和预测模型[2]。最终通过预测模型来对车辆调度时间、地点进行预测。
2 共享汽车智能调度专家系统的设计
2.1 知识库设计
共享汽车智能调度专家系统知识的来源主要有共享汽车运营数据、调度的书籍、相关论文文献、调度现场的调查以及与现场调度人员交谈所获得的经验知识。
在共享汽车运营调度中,主要是通过将客户主动发起的用车需求传递给运营保障人员,再由保障人员发起车辆调度。因此系统车辆调度数据都是用户真实需求,也就是说相关车辆调度是有效的。对知识库的管理都是依托关系型数据库管理系统(RDBMS)实现[3]。RDBMS中不仅存放了前述的所有调度领域的专家知识,也存放了与共享汽车运营及管理有关的所有数据信息,是执行调度推理的基础。
在知识库中,存储了针对所有问题类型的调度案例。每个案例的固有变量有网点标示、调度日期、调度时段、是否为节假日、调度次数,知识库中还包含用户历史催车数据,结合二者,实现规则推理。
首先将历史调度案例进行数据预处理,系统按地域、季节、节假日、小时段和网点五个纬度进行分类统计,并形成案例知识库,历史调度案例知识表如表1所示。

表1 历史调度知识结构表
其次,将历史用户催车表进行数据预处理,系统按地域、季节、节假日、小时段和网点五个纬度进行分类统计,并形成案例知识库,历史用户催车知识表如表2所示。

表2 历史用户催车知识结构表
两个知识表具有相同特征,因此二者具有相同表结构。并且,二者的数据值上在统计学上也具有相似性,究其原因,表1数据是表2数据的结果。
2.2 数据挖掘方法
本系统数据挖掘[4]算法采用随机森林决策树算法。随机森林[5-7]是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看这个样本应该属于哪一类(对于分类算法),然后看哪一类被选择最多,就预测这个样本为那一类。随机森林大致过程如下:
1) 从样本集中有放回随机采样选出n个样本;
2) 从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树(一般是CART,也可以是别的或混合);
3) 重复以上两步m次,即生成m棵决策树,形成随机森林;
4) 对于新数据,经过每棵树决策,最后投票确认分到哪一类。
建立决策树的目标就是把数据集按对应的类标签进行分类。最理想的情况是,通过特征的选择能把不同类别的数据集贴上对应类标签。特征选择的目标使得分类后的数据集比较纯。如何衡量一个数据集纯度,这里就需要引入数据纯度函数。下面将介绍两种表示数据纯度的函数。
信息熵[8]表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,分类后的数据集信息熵会比分类前的小,其差值表示为信息增益。信息增益可以衡量某个特征对分类结果的影响大小。
假设在样本数据集D中,混有c种类别的数据。构建决策树时,根据给定的样本数据集选择某个特征值作为树的节点。在数据集中,可以计算出该数据中的信息熵:
(1)
式中:D表示训练数据集,c表示数据类别数,pi表示类别i样本数量占所有样本的比例。对应数据集D,选择特征A作为决策树判断节点时,在特征A作用后的信息熵的为Info(D),计算如下:
(2)
式中:k表示样本D被分为k个部分。信息增益表示数据集D在特征A的作用后,其信息熵减少的值。公式如下:
Gain(A)=Info(D)-InfoA(D)
(3)
对于决策树节点最合适的特征选择,就是Gain(A)值最大的特征。
本系统采用开源数据挖掘软件WEKA(全名是怀卡托智能分析环境,Waikato Environment for Knowledge Analysis)进行数据挖掘和规则推理。首先对用户催车历史数据进行挖掘。
输入WEKA命令:
java weka.classifiers.trees.RandomForest -K 0 -M 1.0 -V 0.001 -S 1 -t /export_592_u.arff -d /export_592_urf.model
WEKA输出结果:
=== Stratified cross-validation ===
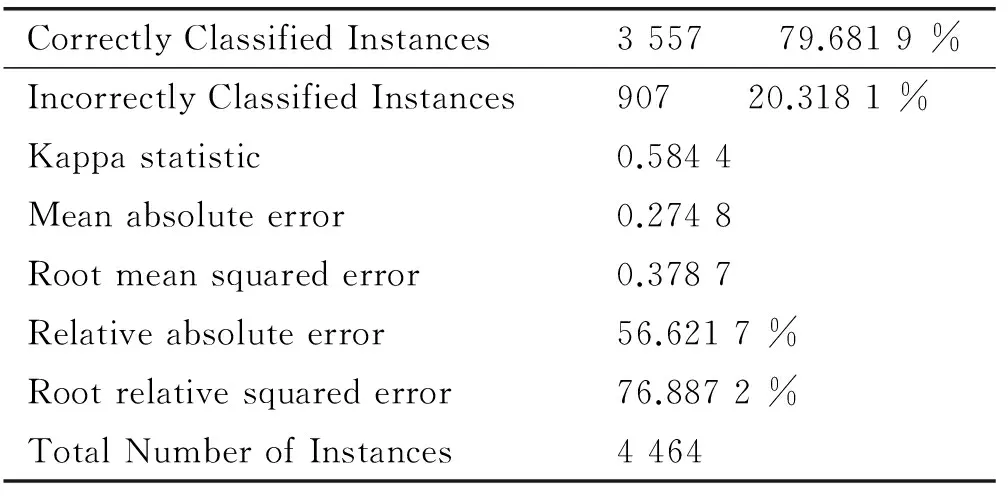
CorrectlyClassifiedInstances3557 79.6819%IncorrectlyClassifiedInstances907 20.3181%Kappastatistic0.5844Meanabsoluteerror0.2748Rootmeansquarederror0.3787Relativeabsoluteerror56.6217%Rootrelativesquarederror76.8872%TotalNumberofInstances4464
=== Detailed Accuracy By Class ===

WeightedAvgTPRate0.8090.7800.797FPRate0.2200.1910.208Precision0.8390.7430.799Recall0.8090.780.797F-Measure0.8230.7610.797MCC0.5850.5850.585ROCArea0.8700.8700.870PRCArea0.9130.7800.858Class不需要需要
=== Confusion Matrix ===

ab<--classifiedas2115500|a=不需要4071442|b=需要
从输出结果可以看出,Correctly Classified Instances值为79.681 9%,表示这个模型的准确度有79.681 9%。根据输出模型export_592.model文件即可对新数据进行预测。
输入WEKA命令:
java weka.classifiers.trees.RandomForest -p 2 -l /export_592_urf.model -T /export_592_test.arff
WEKA输出结果:
=== Predictions on test data ===

actualpredictederrorprediction(WEEK_OF_DAY)2:需要2:需要0.631(星期五)2:需要2:需要0.882(星期五)2:需要2:需要0.851(星期五)1:不需要2:需要+0.561(星期一)2:需要2:需要0.719(星期一)1:不需要1:不需要0.802(星期五)2:需要2:需要0.874(星期一)2:需要2:需要0.83(星期一)1:不需要2:需要+0.848(星期一)1:不需要1:不需要0.684(星期五)2:需要2:需要0.88(星期一)
从预测结果来看,预测正确率接近于80%,后期发起调度时根据系统当时状态再进行调度有效性判定即可实现智能调度的高准确性。
3 共享汽车智能调度专家系统的实现
以Eclipse进行专家系统的开发,采用JDBC实现具体的数据查询、匹配。采用关系型数据库管理软件(RDBMS)Oracle实现对系统知识库的管理和操作,数据挖掘采用WEKA开源数据挖掘组件。系统的主程序设计流程如图1所示。

图1 共享汽车智能调度专家系统程序流程图
4 结 语
本文探讨了共享汽车智能调度专家系统知识表示方法以及相应的数据挖掘方法。通过随机森林算法实现了历史数据的有效挖掘,实现了调度知识的获取、知识的表达和知识库的建立。通过数据训练得到训练模型,再由训练模型对各网点或区域进行各时段调度预测。最后系统结合网点或区域的当前状态对预测结果进行判定决定是否发起调度。系统采用Java语言进行开发,借助WEKA开源数据挖掘组件进行数据挖掘。共享汽车智能调度专家系统为B2C运营模式下的共享汽车运营公司提供了一个调度平台,解决了人工发起调度存在时效性差、缺乏有效预测等问题,对提高企业运营效率具有重要的意义。
[1] Buchanan B G,Barstow D,Bechtal R,et al.Constructing an expert system[J].Building expert systems,1983,50:127-167.
[2] Chandrasekaran B.Generic tasks in knowledge-based reasoning:High-level building blocks for expert system design[J].IEEE expert,1986,1(3):23-30.
[3] 刘全坤,王匀,王雷刚,等.基于关系型数据库的专家系统结构模型及实现技术[J].中国机械工程,2001,12(5):545-547.
[4] 钟晓,马少平,张钹,等.数据挖掘综述[J].模式识别与人工智能,2001,14(1):48-55.
[5] 姚登举,杨静,詹晓娟.基于随机森林的特征选择算法[J].吉林大学学报(工),2014,44(1):137-141.
[6] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[7] Liaw A,Wiener M.Classification and regression by randomForest[J].R news,2002,2(3):18-22.
[8] 刘小虎,李生.决策树的优化算法[J].软件学报,1998,9(10):797-800.
