基于社交实值条件的拓扑神经网络推荐算法
2018-05-02洪联系
杨 璐,洪联系
(集美大学 诚毅学院,福建 厦门 361021)
随着信息时代的到来,信息过载问题越发突出,个性化推荐系统在这个信息化背景下应运而生,成为广大学者和业界的研究热点。虽然现阶段社交网络的数据分析结果能有效地影响商业机制,但个性化推荐技术在速度和准确度上仍有进一步提高的空间。
推荐系统这个概念在1990年被提出,它最初的用意是让数以万计的网络用户拥有更多的选择,更高效地从信息网络中发现更切合自己兴趣的事物。1992年,PARC Tapestry System提出了一种类似集体智慧的算法——协同过滤算法,并且证明了如何运用用户已知的个人信息及其他们的浏览点击等习惯中做出个性化分析。麻省理工大学于1995年研发的Ringo System便是运用协同过滤自动从网络提取数据的音乐推荐系统。随后,更多推荐算法陆续被提出,从信息过滤的角度可以概括为:协同过滤推荐(Collaborative Filtering Recommendation)[1-3],基于内容的推荐(Content-based Recommendation)[4],基于知识的推荐(Knowledge-based Recommendation)[5],混合推荐(Hybrid Recommendation)[6-7],随着移动设备的普及,又出现了基于地理位置的推荐(Mobile Recommendation)[8-9]。
21世纪以来,推荐系统的研究与应用在各大电子商务和社交网络中得到广泛应用,其中以A-mazon、Facebook、Twitter最为著名,有研究表明,Amazon有35%的营业额来自于自身的推荐系统。当前,有越来越多的社交网站开始研究大数据环境下的推荐系统[10-11],而从推荐系统出现至今已过去几十年,目标便是研发更快,准确率更高的算法,提高用户体验度和商业转化率。
推荐系统发展到现在,在硬件方面主要面临的问题是内存消耗,但更为严峻的挑战是针对不同类型的数据结构和需求,研究员们需改进出更为适合的算法。过去几年中,社交网络和商业化网站都存在一个“冷启动”问题,即新用户或新商品和网络中其他人或物的关系如何定义。对于内存消耗问题,本文针对实验中使用的集群数据集给出的解决办法是只选择计算目标用户所在集群里其他所有用户与之的相似度来推断其爱好,该思路针对反向传播神经网络算法可大大减小其计算量,且实验证明该计算结果拥有更高的准确度。
1 系统框架
如今社交网络已经成为人们生活中不可或缺的一部分,越来越多的人更倾向于在线交友和购物,那么当一个用户进入一个成熟的社交网络并做出一切操作指令后,该系统便会根据用户的选择和操作习惯进行分析而后给出用户的倾向性分析结果,即社交网络的推荐系统。一个完整的社交网络系统,需要精确实时地对所提出的推荐算法进行实现和评价。本文提出的推荐框架,以及该框架如何和预测算法结合,算法及系统框架如图1所示。
本社交网络推荐系统框架主要由三部分构成:用户数据预处理层、推荐生成层和效用评价层,整个实验过程将真实地模拟社交网络的推荐。

图1 在线社交网络推荐系统的基本框架
用户数据预处理层:算法分析所用数据集采集自Flixter网站,包括用户信息、用户行为日志(即用户在此网站内所产生的评分信息)和用户之间的友好关系。海量数据下,缓解数据的稀疏性是数据预处理主要面对的问题。数据量越大推荐算法的处理速度越慢,而且往往不能得到好的推荐结果,针对推荐质量问题,该框架设计了这一层级。
推荐生成层:分为线下训练、线上推荐两个步骤,线下训练主要用到反向传播神经网络和Sim-Rank++拓扑模型,而线上推荐即推荐生成层。首先随机选取采集数据的绝大部分用于学习,即使用反向传播神经网络和SimRank++进行离线训练,并在原算法上增加权值进行改进。SimRank++算法主要针对的是用户友好关系数据表,反向传播神经网络则主要针对用户行为日志表进行分析。根据用户的个人信息和评分时间,该模型加入了两个主要权值变量,以改进推荐效果。在此层作者将会搭建一个虚拟的社交网站作为可视化界面显示预测结果,即用户登录进作者模拟出来的社交网站中,点击不同按钮,根据已有数据进行分析,预测结果会直接在该社交网站上呈现给当前用户。同时也将在数据库中导入线下用算法训练后的数据,简单和直观地看到预测评分。
效用评价层:系统推荐结果将与文中提到的部分传统算法在精确性上进行比较并用平均绝对误差(MAE)和均方根误差(RMSE)对其进行评价。
2 算法描述及关键技术
所有推荐系统都会遇到“冷启动”问题,即面对新注册的用户,系统对新用户的行为习惯未知,便不能有效做出推荐。此时系统便可运用仅有的用户信息进行分析,对此用欧几里距离算法:

来计算用户之间的“距离”。其中,p和q分别代表不同的两个用户,n为用户个性化属性个数。从上述距离中便可分析出在用户个人信息的基础上的相似度SED,从而解决冷启动问题,同时也可将其作为老用户之间相似度计算的一项指标。
推荐模型将使用反向传播神经网络结合SimRank++算法,不但可以降低神经网络中神经元的个数从而加快数据处理速度,与此同时还可提高推荐精度。在这个大数据时代,社交网络数据集中70%都是缺失数据,如果单一依靠评分或者用户关联度作为聚类条件,会由于数据的稀疏导致分析结果的准确度降低。该算法第一步运用SiamRank++寻找目标用户的最近邻居,再用反向传播神经网络分析目标用户与其的相似度,从而做出预测,最大程度上减少无用的数据分析提高预测准确度。与此同时结合数据集特点,运用个人信息和评价时间戳作为权值拟合算法,解决“冷启动”和用户动态兴趣爱好的变化问题。
2.1 SimRank++算法
SimRank是一种基于随机步伐的相似度算法[12],也是一种基于图的拓扑结构信息来衡量任意两个对象间相似程度的模型。核心思想为:如果两个对象和被与其相似的对象所引用(即它们有相似的入邻边结构),那么这两个对象也相似。通过临近相似规则,它可以很简洁地定义出用户之间关系。两个用户之间相似度越高,相应的Ssimrank(a,b)值则越低。标准SimRank算法如式(2):
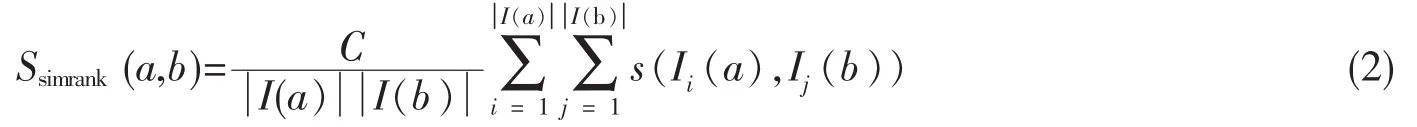
其中C为一个常数,取值在0到1之间,且具体大小要在实验过程中通过反复计算才能定值。a和b表示两个关联用户,Ii(a)和Ij(b))分别为与用户a,b为好友的所有用户集合。若a,b为任意两个不相关用户,且之间没有任何关联的其他用户,则无法定义出a,b两者间的相似度,即s(a,b)=0。所以式(1)可以得到一个临界条件:Ii(a)= Ø或 Ij(b)= Ø 时,Ssimrank(a,b)=0。
式子(1)的缺陷在于一定的迭代计算后,所有用户的相似度结果将会得到同一个值;便有了改进算法SimRank++(以下简称SR++),即增加一个权重值w。

E(a)∩E(b)为用户a和b的共同好友数,该值和权重W为正比关系。加上权重W后进行迭代以得到最终相似度,多次实验后表明当迭代次数在6次之后便可得到一个稳定的结果。综上所述,本文所提出的用户间相似度算法可归结为下:
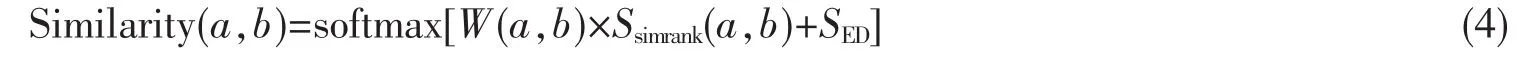
SED是根据用户个人信息用欧几里距离算法计算出来的用户相似度。从最终相似度值找到目标用户的最近邻居,然后选取相似度最高的前20个相似用户和已关联用户作为反向传播神经网络的输入层来预测目标用户对未评分项的得分。
2.2 反向传播神经网络及其改进应用
神经网络[13-14]等机器学习[15]算法应用于大数据是人工智能领域中一个成功应用,它能够满足人们从大量数据中挖掘出隐含的、未知的、有潜在价值的信息和知识的要求。目前,数据挖掘在市场营销、银行、制造业、保险业、计算机安全、医药、交通和电信等领域已经有许多成功案例。
反向传播神经网络(Back Propagation Algorithm,BP)是一种基于神经网络的机器学习,包括输入、隐藏和输出共三层,遵循

其中j是隐藏层的个数,i是输入层的个数,k是输出值,R(10)是0到10之间的任意数。并且本文所提出的评分预测模型将在传统BP网络中加入时间戳作为权值来为评分的有效性进行排序,整个网络训练流程如图2所示。

图2 基于时间戳的BP网络模型
在现实中有一个值得注意的问题就是人的兴趣是会随着时间的推移而发生改变,所以用户对于项目的兴趣度便不能单纯地依靠评分来推断。本文将给每个评分一个取值范围在0至1之间的权值w,而这个权值的判断方法就是基于项目的评价时间。通过上述内容,用户对于项目的评分将依靠权值w进行预处理,同时找到缺失数据和剔除离群值。接着根据图2所示的BP神经网络进行训练,得到稳定的网络结构后,对目标用户未评价的项目进行预测,预测得分高的将作为推荐结果。BP神经网络训练过程如下所示:
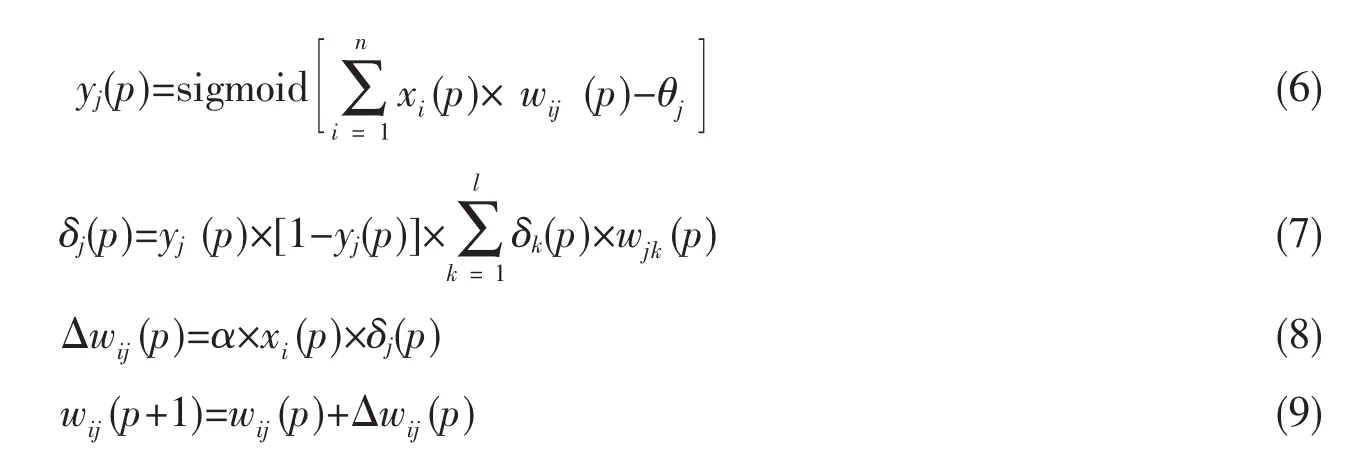
以上为输入层到隐藏层的计算过程,激活函数使用Logistic Function。其中p为迭代次数,yj(p)为隐藏层输出,xi(p)为输入值,wij(p)为权值向量,δk(p)为误差梯度,α为学习率,θj为精度控制参数。而后采用试错法求解得到合适的隐藏层节点数量。
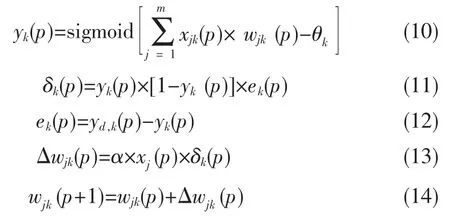
式(10~14)为隐藏层到输出层的计算公式,其计算过程类似输入层到隐藏层,ek(p)为误差信号,其它符号含义同式(6~9)。上述整个SR++_BP模型可大大降低整个评分矩阵的稀疏度,训练-预测过程如图3所示。

图3 SR++_BP模型的训练测试集/过程
图3是整个算法模型的训练测试过程,u6i6单元格的值即为需要预测的项,表格上半部分相当于训练集,其中IN是输入向量,OUT部分是真实输出。对图3的数据集进行训练得到稳定的网络结构后,输入[u6:1,5,1,2,3],可得到 u6对 i6的评分。
3 实验结果及分析
通过实验验证文中所提出算法的性能,实验采用Flixter数据集,过程需要用到数据集中3个表,包括用户对电影的评分,用户好友关系和用户个人信息。要证明算法对结果的影响,就要在实验中建立科学客观的推荐效果评价体系,不仅可以用来比较衡量各推荐系统的优劣,还可以在运算过程中指导相关参数的选择,避免大量重复而无效的计算。对数据多次随机分割交叉学习,把训练结果和随机选取的样本数据进行对比,以构建一套综合评价体系,客观评价算法的推荐效果。
3.1 数据集统计分析
实验所采用的Flixter数据集包含好友关系和电影评分,共有147,612个用户对48,794部电影进行评分。首先对数据进行预处理,剔除没有好友关系的数据,再随机分离出数据集中3000个用户对5406部电影的评分(其中包括用户个人信息和好友关系网络)进行实验。被选中的数据中,部分将作为训练数据,剩下的作为测试数据,用来和算法预测的结果进行对比,以考究预测结果和期望之间的重合度从而得到推荐准确度。推荐模型数据结构图4所示。
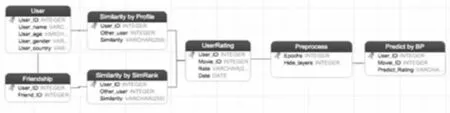
图4 推荐模型数据结构
根据推荐模型数据结构可发现数据集主体由3部分构成:(1)用户信息 (User);(2)好友关系(Friendship);(3)用户对电影的评分(UserMovieRating)。首先根据用户信息和用户好友关系得到用户之间的相似度,其次根据这个相似度选取要进行训练的评分数据,再次根据项目的评分时间进行最后一轮筛选得到最终要纳入训练的数据,训练出稳定的网络结构后便可进行项目评分预测,得到推荐结果。
3.2 评分函数
将使用推荐准确度作为评价指标,而使用评分函数的目的是用函数的形式来评价实验所搭建的模型对于数据集的挖掘分析及推荐有效程度。目前,绝大多数的推荐系统都是使用预测准确度来评价推荐算法的性能,本质是比较推荐结果和实际值之间的相似度。常用度量方法有平均绝对误差(MAE)和根均方差(RMSE)。
MAE计算预测评分与用户实际评分之间的平均绝对误差值,其计算公式如式(15)所示;RMSE计算用户实际评分和预测评分之间的根均方误差,它的计算公式如式(16)所示。
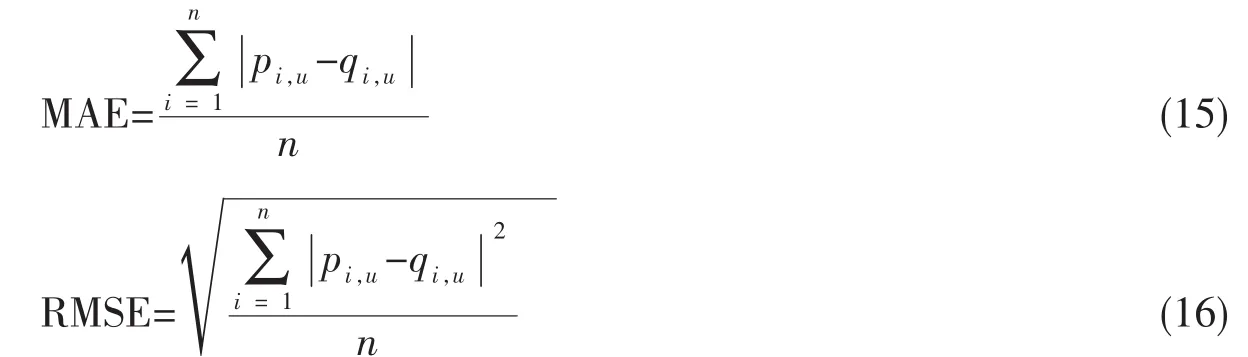
其中:n表示测试集数据个数;pi,u表示用户i对电影u的实际评分;qi,u表示用户i对电影u的预测评分。推荐算法的准确度是所有用户预测评分和用户实际评分的差均分和根均方误差。而后者在求和之前对误差值进行平方,所以其对RMSE的影响比MAE更大。
3.3 推荐界面和结果
为了直观地看出预测结果,首先搭建了一个虚拟的社交网络系统。它实现了用户注册、登录、推荐和预测功能,只需点击不同按钮即可得到所要结果。同时也解决了文中所提出的“冷启动”问题,接下来的好友推荐功能和项目预测评分也都实现在线计算,并且不会耗用过多内存和运行时间。
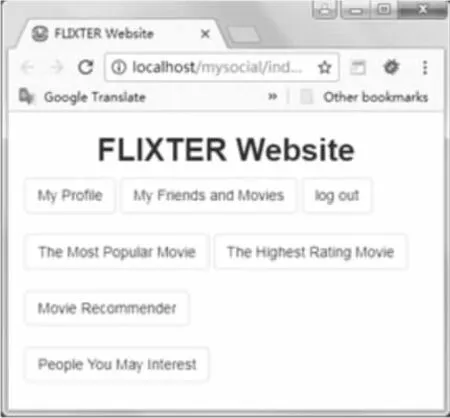
图5 推荐界面
图5简单地展示了社交推荐界面,证明了文中提出算法实际应用的可行性。当用户登录入该网站后,界面上会显示出七个按钮。点击用户配置文件(My Profile)按钮可查看当前登录用户的个人信息,同时可从中找出用户基于个人偏好的相似性,也可在用户未对任何项目进行评分时解决系统“冷启动”问题。点击电影(Movie Recommender)和好友(People You May Interest)推荐按钮,通过已置入网站的推荐算法(本文所提出的)则可得到预测和推荐结果。其余按钮实现的是社交网站基本需求和基于某一条件下对原始数据的排序,仅仅是用来做数据展示的功能。
3.4 Flixter数据集实验结果及分析
使用评分函数计算后的结果将在基于同一个数据集的基础上,和传统推荐算法进行比较。本实验将评分数据中的60%、70%、80%、90%作为训练数据集,相应的剩下部分数据集作为测试数据,实验结果如图6~7所示。
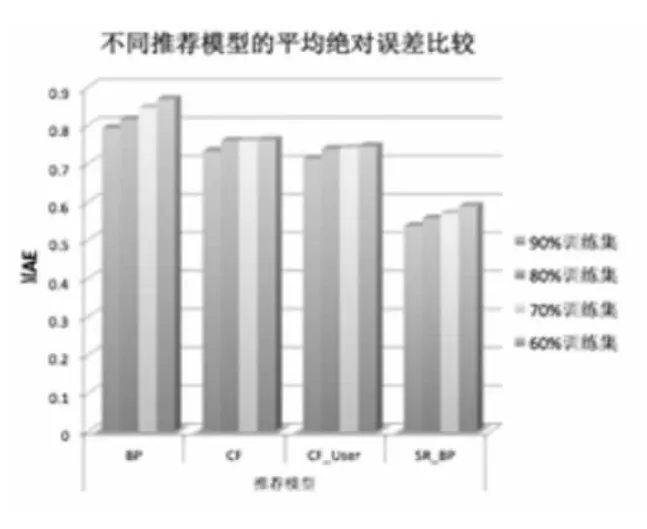
图6 预测精度MAE值
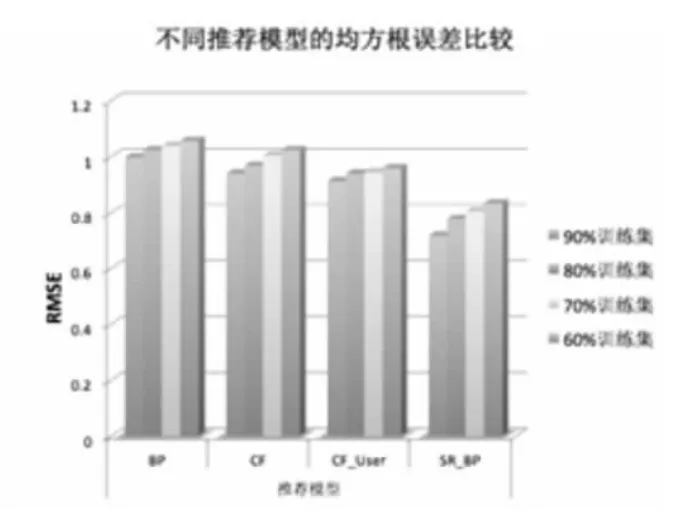
图7 预测精度RMSE值
图6和图7中,横坐标表示不同推荐算法;纵坐标前者为评价指标MAE的值,后者为评价指标RMSE的值。从两图中可发现随着训练数据集比例增加,推荐效果越来越好,并且无论训练集比例占比多少,可发现本文提出的SR++_BP模型取得了最好的推荐效果,说明了该模型利用用户社交关系和其个性化属性信息有助于提高推荐精度。反映了好友信任关系是值得信赖的,可以得出结论:SR++_BP模型在对用户未评分项目上的预测效果高于BP、CF和CF_User算法模型,并且有效地解决了数据稀疏性问题。
4 结束语
当前用户评分数据在绝大多数数据集中都存在严重的数据稀疏性问题,若只使用单一的BP模型将大大影响训练效果。其次,从数据中获取用户短时期内的偏好,捕捉用户偏好的动态变化,是当前推荐系统的热点和难点,本文通过调整评分数据在基于评价时间上的权值以改变输出,便能很好地追踪用户的兴趣变化。而在基于BP和SimRank++模型的社交网络中,挖掘用户社交活动的特征信息及其与社交关系的关联性,利用协同过滤和临近相似规则,从大量数据中定义人与人之间、人与物之间的关系,是本文研究的主要目的。文中所提出的算法针对不同社交网络数据特点,可有效反馈推荐结果,真正意义上为用户缓解“信息”问题,同时也和传统推荐算法进行比较,用评分函数来证明其学术和商业价值,也望未来在训练速度和推荐效率上有更好的改进。
参考文献:
[1]CHEN D,XU D.A Collaborative Filtering recommendation based on user profile weight and time weight[C]//International Conference on Computational Intelligence and Software Engineering.IEEE,2009:1-4.
[2]ZHANG Q Q,YE N.Collaborative filtering algorithm adapting to changes over dynamic time[J].International Proceedings of Computer Science & Information Tech,2012:27.
[3]CANNY J.Collaborative filtering with privacy via factor analysis[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM, 2002:238-245.
[4]RUTH G,XAVIER A.Weighted content based methods for recommending connections in online social networks[C].Proceedings of the 2nd ACM RecSys'10 Workshop on Recommender Systems and the Social Web ,2010:74-77
[5]BOURAGA S,JURETA I,FAULKNER S,et al.Knowledge based recommendation systems:a survey[J].International Journal of Intelligent Information Technologies,2014,10(2):1-19.
[6]GARCIA R.Hybrid methods for recommending connections in online social networks[D].UPF,2010.
[7]JOEL P L,NUNO L,MARIA N M,et al.A hybrid recommendation approach for a tourism system[J].Expert Systems with Applications,2013,40(9):3532-3550.
[8]AUAD T,MENDES L,STROELE V,et al.Improving the user experience on mobile apps through data mining[C]//IEEE, International Conference on Computer Supported Cooperative Work in Design.IEEE,2016:158-163.
[9]TUUKKA R,KRISTER H,et al.SMAETMUSEUM:a mobile recommender system for the web of data web semantics:science[J].Services and Agents on the World Wide Web,2013,20(2):50-67.
[10]JIA W H,MICHELINE K,JIAN P.Data mining:concepts and techniques[M].3rd Edition.Morgan Kaufmann:2012.
[11]DIETMAR J,SIMON F.Recommendation-based modeling support for data mining processes [C]//ACM Conference on Recommender Systems.ACM,2014:337-340.
[12]JEH G,WIDOM J.SimRank:a measure of structural-context similarity[C]//Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2002:538-543.
[13]SCHOLKOPFB,PLATTJ,HOFMANNT.Modelinghumanmotionwsingbinarylatentvariables [C]//InternationalConference onNeuralInformationProcessingSystems.MITPress,2006:1345-1352.
[14]WELLING M,ROSEN Z,HINTON M.Exponential family harmoniums with an application to information retrieval[C]//International Conference on Neural Information Processing Systems.MIT Press, 2004:1481-1488.
[15]CARREIRA P,HINTON M.On Contrastive Divergence Learning[J].Proceedings of Artificial Intelligence & Statistics,2005.
