审计大数据下模糊匹配审计证据获取方法研究∗
2018-04-26林俊方宽
林俊 方宽
(广东电网有限责任公司 广州 510030)
1 引言
审计对象的信息化展使计算机辅助审计成为必然,而数据查询抽样、统计分析等[1]常用方法多是把手工的审计流程计算机化,没有充分利用先进的信息技术,不能提取隐藏的或未知的信息。随着企业业务数据量的增大,被审计数据呈海量增长,已建立起TB甚至PB级的大数据库[1]。巨大的审计数据量,仅靠先验知识和传统经验流程难以充分发挥大数据优势。因此探索适用于审计大数据的新方法来提炼审计证据具有重要的理论和应用价值。
模糊匹配通过对不同数据源中的数据进行相似性比较,能够搜索出不同数据源中相似重复实体[2]。尽管模糊匹配应用较多[3],如Monge[4]等基于模糊匹配对同一数据源中的相似重复记录进行清理,张家俊[5]等在字母和音字转换基础上对维吾尔语人名进行模糊匹配和识别,孙怡帆[6]等利用模糊匹配技术揭示网络内在的社区结构,吴海涛[7]等基于模糊匹配策略实现中文地址编码的自动识别。但模糊匹配直接应用于审计中的研究不常见[8],而在大数据审计环境下,数据源分散,不同企业的被审计数据相关性不大,因而不同数据源不应该出现相似重复的审计数据,但当存在相似数据时,如数据源A与B中低保发放统计数据基本一致时,则很可能是存在舞弊的可疑数据,此时通过模糊匹配技术可以有效地发现这些可疑数据,文献[9]中对基于模糊匹配的审计证据发现进行了初步探讨,但其并未考虑大规模数据对匹配速率的限制。
为充分发挥大数据的优势,提出一种基于外存索引快速模糊匹配的大数据审计证据获取方法,记为 EMI(External Memory Inverted Index,EMI)算法,如图1所示,算法分为大数据源中数据表相似公共字段搜索和公共字段内数据相似性检测两部分,首先针对数据表相似公共字段需要在整个原始审计大数据中搜索的特性,采用基于外存倒排索引快速模糊匹配技术以满足搜索时间和效率的要求,然后在公共字段内进一步对数据进行相似性检测,发现相似重复可疑数据,借助审计人员的延伸调查,最终获取审计证据。实验结果验证了算法在大数据审计证据获取上的有效性。

图1 基于模糊匹配的审计证据获取流程
2 基于改进外存倒排索引的相似公共字段搜索
模糊匹配的核心是有效的相似度计算,编辑距离是指由待匹配字符串变化到目标字符串所需最少的编辑操作次数,广泛应用于文本信息检索领域的相似度计算[10~12]。大数据下对编辑距离的改进大多基于q-gram的内存倒排索引[13],先将数据集转换为q-gram集合,由gram对应的倒排表组成倒排索引,然后经倒排表读取和相似性判断完成模糊匹配过程。但基于内存的倒排索引当面对大规模审计数据时,无法在内存中构建倒排索引。Behm[14]通过在外存储器上建立q-gram倒排索引并在内存中保存索引地址,在倒排表自适应选择基础上实现大数据下字符串的快速相似匹配(记为Behm算法)。
为获取更好的匹配效率,在Behm算法基础上通过引入地址参数和非对称搜索模式,减少外存中倒排表的读取数量,待匹配的候选结果中元素数,从而减少匹配阶段的编辑距离计算代价,提高相似度计算效率。
2.1 q-gram倒排索引
给定数据集∑,s∈∑,设字符α,β∉∑,则在s前后各加上q-1个α和β,则新字符串中长度为q的子串组成s的q-gram集Gs(s),如图2所示,将拥有相同q-gram子串的ID按出现顺序保存到该子串对应的列表中,即为该子串的倒排表,而所有倒排表组成∑的倒排索引。
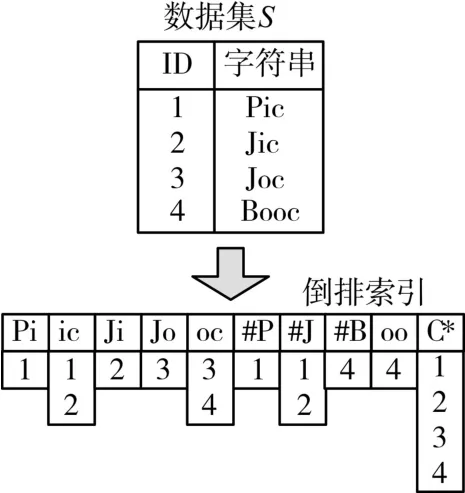
图2 数据集及其外存索引
2.2 EMI外存倒排索引结构构建
EMI倒排索引结构由内存Gram树和外存索引组成,如图3所示。Gram树每个叶节点保存一个q-gram及该q-gram对应的倒排表在外存中的存储地址。
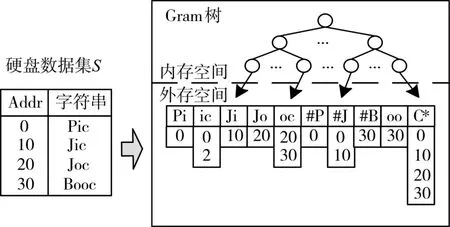
图3 EMI外存索引结构
为提高匹配效率,EMI算法在索引结构中加入长度和位置参数,以减少参与匹配的候选q-gram倒排表数,即在计算字符串s的q-gram集合Gs(s)时,在每个元素中加入s的长度和q-gram的位置,
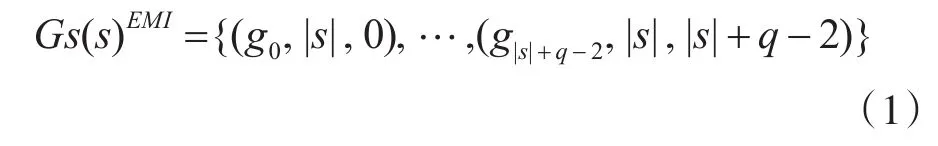
式中,gi为字符串s的第i个q-gram,(0≤i≤|s|+q-2)。
由于位置参数加入剔除,字符相似、长度和位置相邻的q-gram可以同时读取到内存中,因此,EMI索引结构将这样的倒排表存储在相邻的外存磁盘中,可以将整个外存储块同时读入内。
与Behm倒排索引方式不同,SMI倒排表中直接存放相关字符串数据的存储地址,而不是其ID,这样避免了Behm需要在内存中开辟维护ID到磁盘地址映射的额外开销,而导致在大规模的数据集时,内存的额外消耗量随数据量急剧增加。EMI倒排表采用8B的字符串地址而不是4B的ID,在增加磁盘空间的微小代价下,极大节省大数据下的内存开销,使更多的内存用于后续的字符串模糊匹配处理。
EMI索引中长度分段参数llen和位置分段参数lpos代替原字符串的长度和位置计算,从而将长度和位置相邻的q-gram进行整合,进一步减少倒排表个数及Gram树占用的内存。例如,当取llen=lpos=20 时 ,(ic,35,30)节 点 被 整 合 到(ic,35/20,30/20)=(ic,1,1)中。EMI外存索引的构建采用文献[15]方法,首先,计算集合∑中每个的Gs(s)EMI,并将s的磁盘地址写入到Gs(s)EMI对应的倒排表中,如果数据量过大,内存缓冲区被占满,则将生成的Gram树写入磁盘临时文件(大数据时,通常需要临时文件的帮助)中,重复构建直到处理完∑中所有元素。其次,将每个g∈Gs(s)EMI对应的临时文件中的倒排表按生成顺序进行合并,生成最终倒排索引,同时将最终倒排表地址插入到Gram树节点。
2.3 审计数据公共字段模糊匹配
EMI倒排索引模糊匹配,采用非对称的搜索模式(子程序2)读取倒排表。但非对称模式需要满足其待匹配字符串的s0的匹配子集GsSel(s)必须在位置上没有重叠部分[16],即目标函数J0最小,J0减少了保留下来的候选结果数[17]。
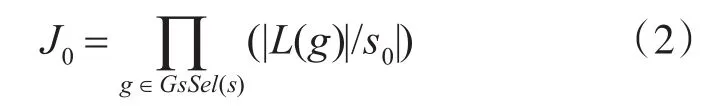
式中|L(g)|为g∈Gs0(s)对应的倒排表长度,并且对于给定的任意 g1,g2∈GsSel(s),有 |P(g1)-P(g2)|≥q,P(g)为g的位置信息。子程序1描述了s0的子集GsSel(s)选择过程。
子程序1在计算子集时,采用递归方法:当Gs(s)EMI在Ps、Pe之间元素数少于q时,算法以代价最小的作为返回值(行④⑤),但当Ps、Pe之间元素数多于q时,则递归的通过式(3)计算子集。

表1 子程序1非对称模式gram子集选择方法Gs0_Sel(s)伪代码
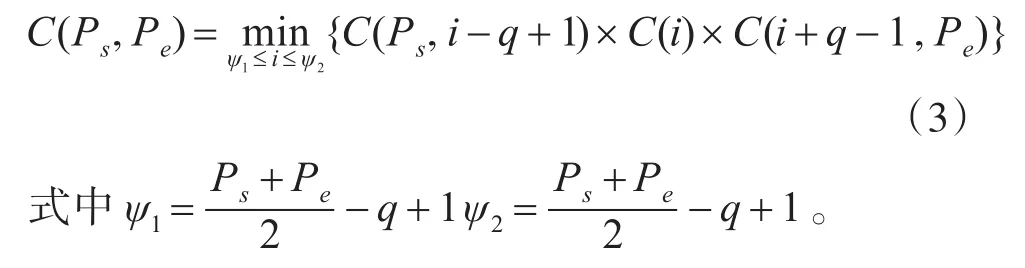
程序中需要对新加入的元素需判断其对后续模糊匹配性能是否有利。设候选集中待评价的一个gram的代价为Cverify,新读取的倒排表L长度为|L|,代价为CL,当前Lini中计算为τ的倒排表数为nτ,由于所有元素被选为下一个候选集元素的概率是一致的,则读取L后,需剔除的Lini中倒排表数为n=nτ×(1- | L | |S|)由此导致在模糊匹配阶段,结果集的代价降低C=n×Cverify而读取L的代价为
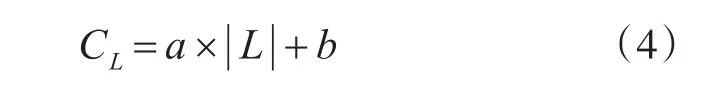
式中a为磁盘数据传输速率,b为数据读取速度,通过数据测得a=10-4,b=10。在性能判断过程中,一次随机I/O读取代价为5ms~10ms,因此,如果C>CL,则读入L。
子程序2实现了基于非对称模式的快速模糊匹配,在提取到s0的子集GsSel(s)后,由于当某个地址在前L个倒排表中出现T次,则其在L-T+1个倒排表中至少出现过一次,因此提取前 p个元素的倒排表作为最小候选集Lini;同时统计Lini中元素出现次数。然后读入下一个元素对应的倒排表,并判断其对匹配性能是否有利,如果有利,则合并到Lini中,在该过程中判断并剔除Lini中现出次数过少的元素,因为这些元素与s0共享的gram不足以满足相似度关系[14],故而不是匹配结果。最后,对Lini中元素地址对应字符串进行相似性验证,从而返回满足预定阈值的模糊匹配结果。

表2 子程序2:基于外存索引的字符串模糊匹配
3 段内数据匹配
搜索到相似公共字段后,还需要对其具体内容进一步模糊匹配,以最终判断两数据源是否为相似可疑数据,其数据模糊匹配采用如下策略。
1)字符型数据匹配
字符型数据采用编辑距离算法进行相似度计算。同时采用表1的编辑距离与相似度对应关系,对整数型编辑距离进行折算,表3中关系也可根据数据具体分析进行调整。
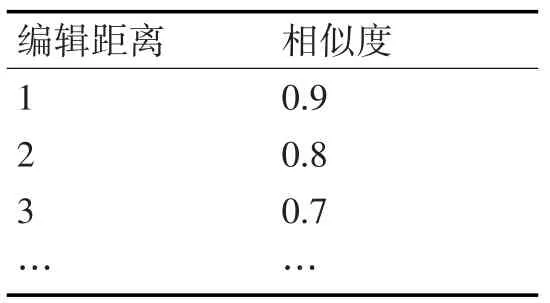
表3 编辑距离与相似度对应关系表
2)布尔型数据匹配
如果布尔型数据相等,则相似度取0,反之相似度取1。
3)数值型数据匹配
数值型数据,采用式(5)方法计算相似度:

4 实验验证
实验首先在title、author数据集上与Behm算法进行性能比较,其次将算法就用于实测数据,验证大数据审计证据获取的有效性。实验计算机配置为:intel core I-2540M CPU,主频为 2.6GHz,7200转/s机械硬盘,页为8KB。Title中字符数为2078174,而Author中字符串数1122253。从中各随机选择100个字符串作为待模糊匹配字符串,编辑距离阈值分别为 θtitle={1,2,4,8,16}和 θauthor={1,2,4,8}每次测试后清空磁盘缓存。
4.1 算法匹配性能比较
采用4种方法进行实验比较:原始Behm算法、在Behm算法中加入非对称gram模式(记为Behm-N),EMI索引结构但未采用非对称gram模式(记为EMI-N)以及本文算法。
图4和图5所示为算法相关参数结果,取50次重复实验的平均值,图4可见,两个数据集上相同条件下,Behm-N与EMI算法分别比Behn和EMI-N算法读取的倒排表数要少,这主要因为非对称模式通过Gs0_Sel(s)程序自适应地从Gs(s)EMI集中选择一部分相关gram,从而减少倒排表的读取个数,说明非对称模式能有效减少倒排表读取数。图5(a)实验结果可见,EMI算法生成的候选集元素数最小,EMI-N算法次之,主要是因为EMI算法增加了位置参数,通过位置参数的约束,仅保留满足位置要求的gram,图5(b)author数据集实验结果进一步验证了位置参数的有效性。
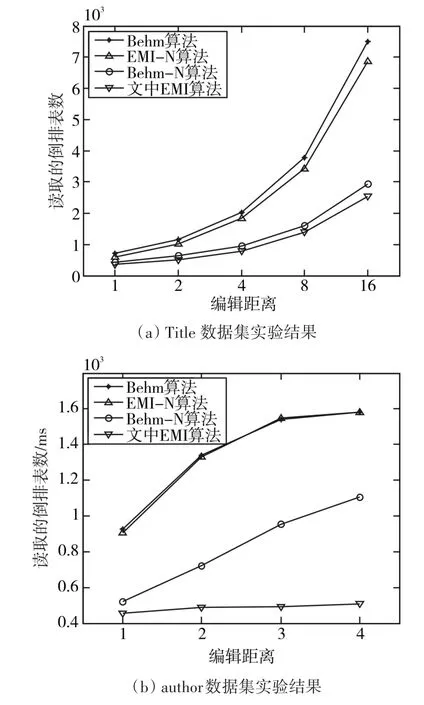
图4 算法读取倒排表数比较结果
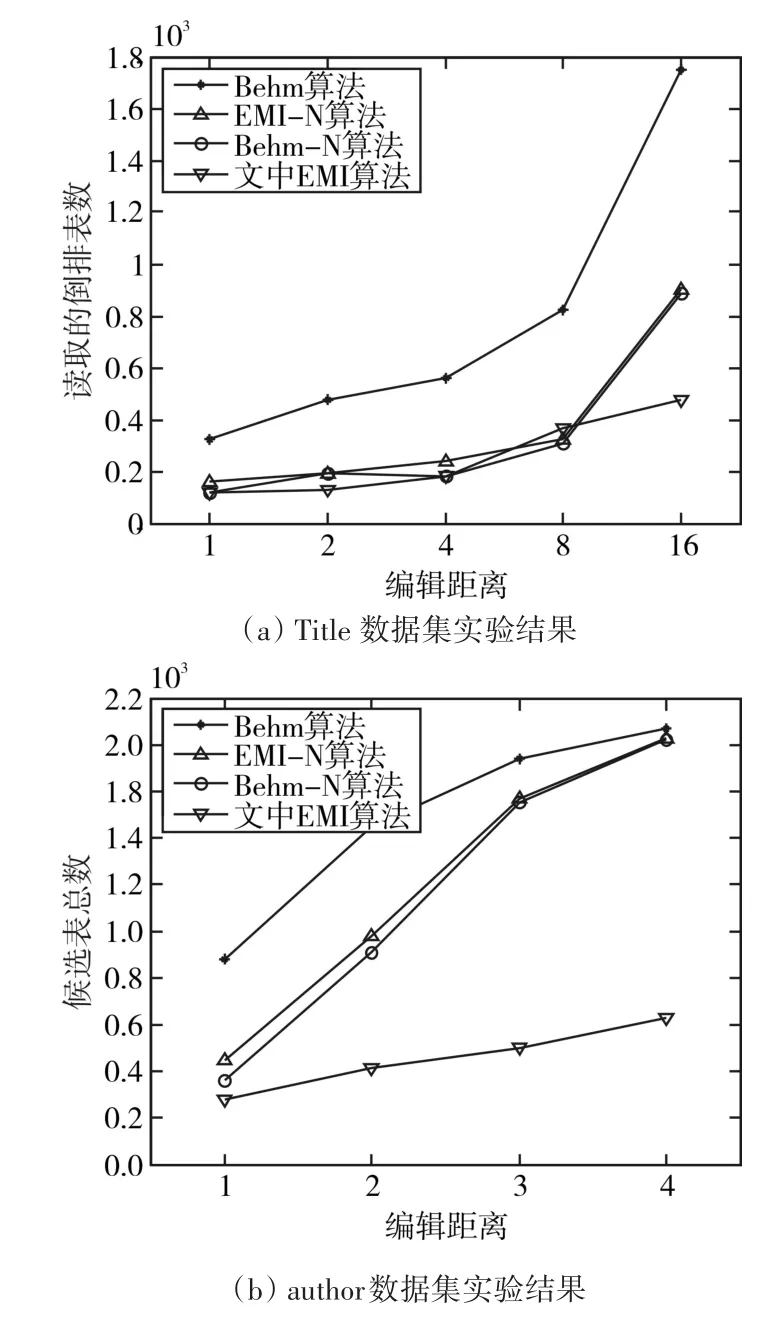
图5 算法生成候选集元素数比较结果
从实验结果整体来看,文中EMI算法通过位置参数和非对称Gram模式的引入,从读取倒排表数和生成的候选集两个方面减少了数据量,一方面减少了读取外存数据产生的消耗,另一方面也减少后续字符模糊匹配的时间和内存开销,从而为提高整个字符模糊匹配的效率奠定基础,以满足审计大数据处理速率的要求。
4.2 时间比较
与4.1节实验一相似,本节在Title和Author数据集上,测试使用实验一中的四种算法进行字符串模糊匹配的运行时间比较,实验结果如图6所示,算法依然对每个字符串运行50并计算其平均值。
从图中可以看出,随编辑距离的增大,四种算法的运行时间逐渐增大,而三种比较算法的运行时间增加急剧,EMI算法增加的时间并不明显,主要是因为文中算法通过位置参数和非对称模式的使用,使得在外存倒排表读取时仅读取与当前字符模糊匹配相关性最大且位于位置约束范围内的倒排表,从而使外存倒排表数及生成的候选集增长得到较好的控制(见图4、5所示),使总体模糊匹配时间变化不大。
从图6(a)匹配时间比较结果可以看出,Behm运行时间最长,而EMI算法运行时间最小,在编辑距离较小时,为Behm算法时间的50%左右,而在编辑距离较大时,仅为其20%~30%,而图6(b)所示Author集下,EMI算法在各个编辑距离下为Behm算法运行时间的35%左右,实验结果验证EMI算法在处理大数据模糊匹配上的运行时间优势。

图6 字符串模糊匹配运行时间比较
4.3 真实审计数据匹配实验分析
为了定量分析文中方法的审计风险,以查全率R(Recall)和查准率P(Precision)为评价依据,通过网络爬行技术选取2008-2017年度1079家沪市上市公司在互联网公开的财报数据作为研究样本,对数据进行预处理后,形成有效实例数为175690条,以“营业利润增长率”和“税务登记号”作为模糊匹配的公共字段,实验结果如图7所示。

从图中可以看出,设置不同的公共字段阈值,数据的模糊匹配结果不同,当阈值较低时,查出的相似数据较全,但准确率较低会;而当阈值较高时,查出的相似数据会有遗漏,但准确率较高;
当采用较高的查全率时,公共字段搜索的较全,审计风险相对较少,但此时需要审计人员更多参与分析确认,降低了审计的效率,而当查准率较高时,相应的审计风险也增加。
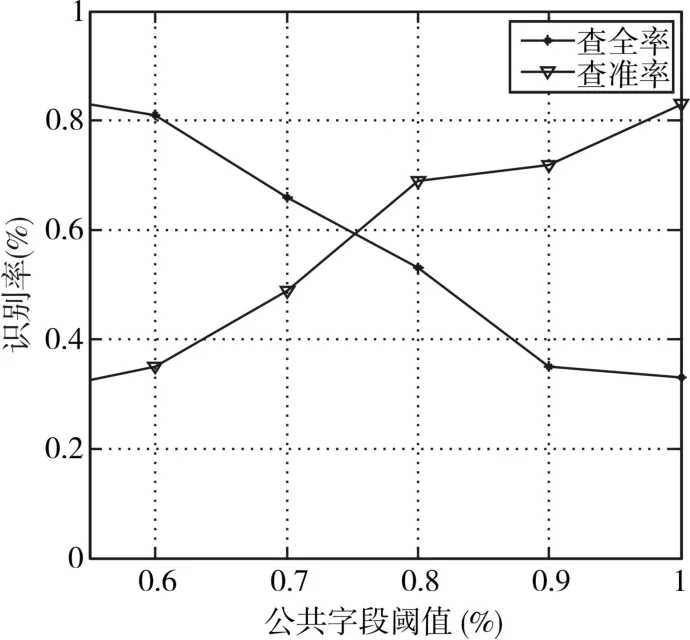
图7 不同公共字段阈值对应查全率与查准率
因此在实际数据审计处理时,审计人员应根据风险水平所需的查全率和查准率,设置合理的公共字段阈值,以控制审计检查风险。通常情况下,可以设置一个高阈值和一个低阈值,高阈值下,高查准率可以快速确定可疑审计证据,然后通过低阈值扩大搜索范围,控制审计风险。
从图中可以看出,对于实验中的真实审计数据,当公共字段阈值取75%时,可以取得查全率和查准率的较好折中,为此采用65%和80%两个阈值进行模糊匹配审计证据获取,此时,可得到39家存在相似重复可疑数据的公司,进一步通过证监会、上交所等机构公开的处罚信息对实验聚类疑点小簇进行验证,发现在发现的39家可疑公司中,不少收到了上海交易所、证监会等的整改通知甚至是行政处罚,从而验证了本文算法对审计数据疑点发现的有效性。
结合三组实验可以看出,文中基于模糊匹配的大数据审计方法在保证审计数据获取有效性的基础上,减少了数据处理的运行时间,提高了数据处理的效率,保证了大数据下审计的速率要求。另外,经模糊匹配发现的疑点公司并不都存在问题,其结果表明这些公司出现问题的概率更高,但最终的疑点确认需要审计人员完成。
5 结语
文中针对大数据审计面临的运行效率和审计证据有效获取问题,在分析得到不同数据源中的相似重新审计数据可能为舞弊数据基础上,提出一种基于模糊匹配的审计证据获取方法,首先通过引入位置参数和非对称查询模式改进外存倒排索引结构,自适应地选择待匹配数据,以控制数据读取量,实现审计大数据公共字段的快速模糊匹配,保证了算法在大数据下的运行效率,其次在公共字段匹配基础上,对字段内数据进一步进行相似性判断,从而发现相似审计舞弊数据,获得审计证据。实验结果表明,算法在保证审计证据有效获取的基础上,减少了数据处理的运行时间,提高了数据处理的效率,满足审计大数据下审计证据获取的要求。
[1]张晓伟,谢强,陈伟.基于划分和孤立点检测的审计证据获取研究[J].计算机应用研究,2009,26(7):2495-2498.ZHANG Xiaowei,XIE Qiang,CHEN Wei,Study on Au⁃dit Evidence Gathering based on Partition and Outlier De⁃tection[J].Application Research of Computers.2009,26(7):2495-2498.
[2]李艳玲,颜永红.中文口语理解中关键语义类模糊匹配方法研究[J].小型微型计算机系统,2014,35(9):2182-2186.LI Yanling,YAN Yonghong.Research for Fuzzy Matching Algorithm of Key Semantic Class in Chinese Spoken lan⁃guage Understanding[J].Journal of Chinese Computer Systems,2014,35(9):2182-2186.
[3]张娜,张剑.一个快速的字符串模式匹配改进算法[J].微电子学与计算机,2007,24(4):102-105.
[4]Monge A E.Matching algorithm within a duplicate detec⁃tion system[J].IEEE Data Engineering Bulletin.2000,23(4):14-20.
[5]热合木·马合木提,于斯音·于苏普,张家俊,等.基于模糊匹配与音字转换的维吾尔语人名识别[J].清华大学学报(自然科学版),2017,57(2):188-196.Abdurahim Mahmoud,Hussein Yusuf,ZHANG Jiajun,et al.Name recognition in the Uyghur language based on Fuzzy Matching and Syllable-character Conversion[J].Journal of Tsinghua University(Science and Technology),2017,57(2):188-196.
[6]孙怡帆,李赛.基于相似度的微博社交网络的社区发现方法[J].计算机研究与发展,2014,51(12):2797-2807.SUN Yifan,LI Sai.Similarity based Community Detection in Social Network of Miroblog[J].journal of Computer Re⁃search and development.2014,51(12):2797-2807.
[7]吴海涛,俞立,张贵军.基于模糊匹配策略的城市中文地址编码系统[J].计算机工程,2011,37(2):194-199.WU Haitao,YU Li,ZHANG Guijun.Chinese City geocod⁃ing System Based on Fuzzy Matching Strategy[J].Comput⁃er Engineering,2011,37(2):194-199.
[8]陈伟,刘思峰,邱广华.计算机审计中数据处理新方法探讨[J].审计与经济研究,2006,21(1):37-39.CHEN Wei,LIU Sifeng,QIU Guanghua.New Approaches to Data Processing Used in IT Audit[J].Audit&Enono⁃my Research,2006,21(1):37-39.
[9]陈伟.大数据环境下基于模糊匹配的审计方法[J].中国注册会计师,2016(11):84-88.CHEN Wei.Audit Method Research based on Fuzzy Matching in Large Data Environment[J].Chinese Certi⁃fied Public Accountants,2016(11):84-88.
[10]秦佳,杨建峰,薛彬,等.基于向量相似度匹配准则的图像配准与拼接[J].微电子学与计算机,2013,30(6):22-25.QIN Jia,YANG Jianfeng,Xue Bin,et al.Image Regis⁃tration and Mosaic based on Vector Similarity Matching Principle[J].Microelectronics&Computer,2013,30(6):22-25.
[11]赵亚慧.基于编辑距离的中文机构名简称检索方法研究[J].内蒙古科技与经济,2010(7):69-70.ZHAO Yahui.Study on Retrieval Method of Chinese In⁃stitutional Name Abbreviations based on Edit Distance[J].Inner Mongolia Science Technology and Economy,2010(7):69-70.
[12]姜华,韩安琪,王美佳,等.基于改进编辑距离的字符串相似度求解算法[J].计算机工程,2014,40(1):222-227.JIANG Hua,HAN Anqi,WANG Meijia,et al.Solution Algorithm of String Similarity based on improved Leven⁃shtein Distance[J].Computer Engineering,2014,40(1):222-227.
[13]孙德才,王晓霞.一种支持多种子近似串匹配的q-gram索引[J].计算机科学,2014,41(9):279-284.SUN Decai,WANG Xiaoxia.Q-gram Index for Approxi⁃mate String Matching with Multi-seeds[J].Computer Science,2014,41(9):279-284.
[14]Behm A,Li chen,et al.answering approximate string queries on large data sets using external memory[C]//IEEE International Conference on Data Engineering.2011,83(1):888-899.
[15]Zobel,Moffat A.Inverted files for text search engines[J].ACM Computer Survey,2006,38(2):6-20.
[16]刘慧婷,黄厚柱,刘志中,等.基于分割的字符串相似性查找算法[J/OL].计算机科学与探索,2016:1-17.LIU Huiting,HUANG Houzhu,LIU Zhizhong,et al.Partition based Algorithms for String Similarity Search[J].Journal of Frontiers of Computer Science and Tech⁃nology,2016:1-17.
[17]王金宝,高宏,李建中,等.外存中高效的字符串相似性查询处理[J].计算机研究与发展,2015,52(3)738-748.WANG Jinbao,GAO Hong,LI Jianzhong,et al.Process⁃ing String Similarity Search in External Memory Efficient⁃ly[J].Journal of Computer Research and Development,2015,52(3)738-748.
