基于深度卷积神经网络的位置识别方法∗
2018-04-26黄于峰刘建国
黄于峰 刘建国
(华中科技大学自动化学院 武汉 430074)
1 引言
近年来随着自动驾驶[1],增强现实[2]等应用领域的兴起,视觉位置识别在计算机视觉、机器人等领域备受关注。视觉位置识别(Visual Place Recog⁃nition)是通过图像来判断两个地点是否处于同一位置,不同于其他识别任务,位置识别最大难点源于环境本身的多变性[3],如日照、气候、人类活动、拍摄视角等,所造成的图像光照强度、外观结构、视点等方面的变化,如图1所示。
目前,视觉位置识别问题主要被当作图像实例检索任务来进行处理,即通过与数据库中的图像进行匹配以返回查询图像的位置。数据库中图像首先利用 SIFT[4]、SURF[5]、ORB[6]、GIST[7]等进行特征提取,由于所生成的特征数量很大,直接用于匹配将非常低效,为加速匹配过程,往往将其与词袋模型(BoW)[8]、VLAD[9]或 Fisher矢量[10]等结合使用,由此生成的特征描述符往往更加紧凑并能被高效地索引[11]。然而,随着视觉位置识别任务对变化环境下的识别率与鲁棒性要求越来越高,基于SIFT、ORB等传统手工特征的位置识别方法越来越无法满足应用要求。

图1 环境变化对位置图像的影响
近年来,卷积神经网络(CNN)作为一种强有力的图像表示方式在目标分类[12]、场景识别[13]、目标检测[14]等多种识别任务中表现出远优于传统手工特征的性能,也逐渐有研究者将CNN用于位置识别中来,并取得了良好的效果[3,15~19]。然而目前所提出的这些方法都存在着一定的缺陷,比如缺少对于相机视点变化的不变性[20],或者说需要针对特定环境进行额外地训练[21],抑或是缺乏对外观变化的鲁棒性[15]。Niko等[18]提出了一种基于 EdgeBox[22]路标检测与CNN特征结合的位置识别方法,该方法不仅具备对于视点及环境变化的鲁棒性,且不需要额外的训练开销,不过该方法需要对所提取的每个路标分别进行CNN特征提取,时间花费非常高,无法满足实时要求,此外该方法得到的特征维度很高且并未采用BOW等方式对特征匹配环节进行优化,因此实用性不高。
本文基于CNN特征提取并结合BOW提出了一种稀疏的特征描述子——BCF(Bag of Convolu⁃tion Features),大大提高了图像检索的速度,同时为了提高其对于变化环境的鲁棒性,构建了一个能够实现快速生成局部感兴趣区域特征词汇的特征映射图,并利用其对检索结果进行二次排序,通过这种方式将全局特征与局部特征进行了联合,在保证实时性的同时也大大提高了识别效果,此外本文提出的方法并不需要针对特定的识别任务进行额外地训练,更加提升了其实用性。
2 BCF特征描述子
BCF特征描述子的构建流程如图2所示。
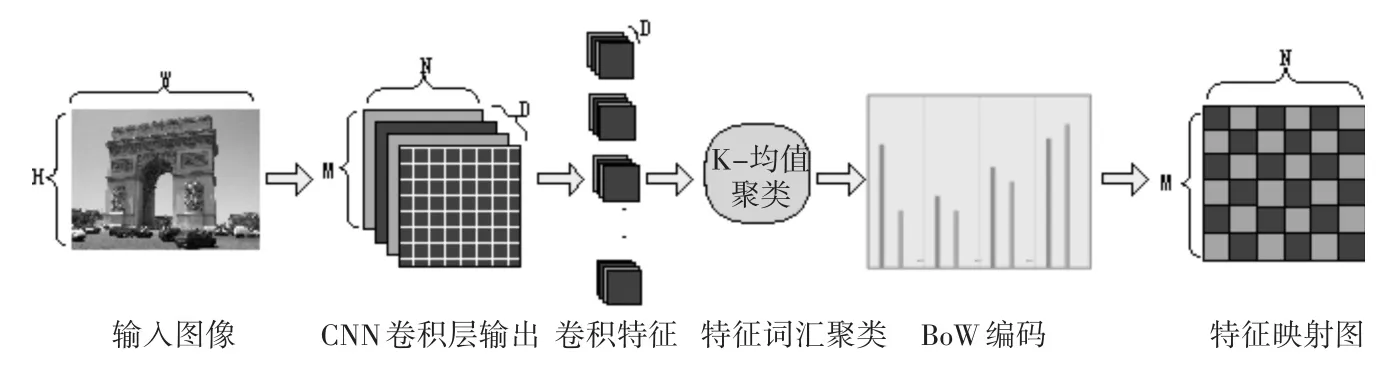
图2 BCF构建流程图
2.1 卷积特征提取
特征提取部分,我们利用预先训练好的CNN网络模型,将某一层的激活响应输出作为特征,为了加快CNN网络的前馈计算过程,我们直接将原始网络中的softmax层和全连接层去掉,通过这种方式不仅能加快特征提取的速度,还能使得CNN网络的输入可以是任意尺寸的图像,因为CNN网络对于输入图像尺寸的要求主要是全连接层带来的[23]。如图2所示,若某一卷积层的输出维度为N×M×D,则可将其看作N×M个D维的局部特征描述子。
2.2 特征映射图构建与BoW编码
BoW模型[24]通过构建一个视觉词典并将特征矢量映射到距离其最近的类别中心,来对图像特征进行编码。我们采用K-均值算法来对数据集中提取出的所有特征向量进行聚类以生成词典。至此由卷积层输出的每一个局部CNN特征矢量都会被分配给词典中的某一个词语,通过这种方式就可以生成一个由局部CNN特征到视觉词语的特征映射图,所得到的二维分配图尺寸为N×M,显然,特征映射图可以看作原始图像的一个更为紧凑的表示,它将原始图像上尺寸为的矩形区域映射为了特征映射图上的一个点,其中W和H分别为原图的宽和高。通过特征映射图,我们可以快速地生成原始图像上任意区域的BOW矢量,这就为全局特征与局部特征的结合使用提供了可能。
3 基于BCF的位置识别
在输入图像进行BCF特征提取之后,接下来就应该进行检索与匹配,即将输入图像的BCF特征与数据集中的BCF特征矢量进行比对,根据距离排序返回结果。根据输入的不同,我们将搜索方式分成了两种:全局搜索与局部搜索。全局搜索以整幅图像的BCF特征矢量作为输入,而局部搜索则只是将感兴趣区域的BCF矢量用于搜索。整个搜索过程主要由初步搜索与局部重排名两步组成。
3.1 初步搜索
利用全局搜索策略得到一个初步的结果排名。计算查询图像的全局BCF特征矢量与数据库中图像的全局BCF矢量的距离,在此我们选择余弦相似度作为距离度量方式[18]:
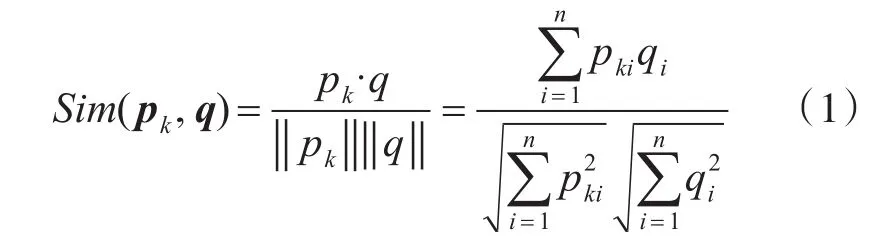
其中,q=(q1,q2,…,qn)为查询图像的 n维BCF 特征矢量,pk=(pk1,pk2,…,pkn)为数据库中第k幅图像的BCF特征矢量。
然后根据距离度量对数据库中的图像进行排序得到初步结果。为了加快搜索的速度,我们采用了逆索引技术[24]并使用GPU来加速稀疏矩阵的乘法计算。
3.2 局部重排名
在初步搜索之后,我们将排名前K的图像挑选出来作为候选集,然后对它们进行局部搜索,根据搜索结果进行重排名,得到最终的查询结果。首先,我们对查询图像进行感兴趣区域提取,提取方式可以自定义,如 EdgeBox[22]、FAST[25]等,在本文中,出于时效性考虑,我们只是采用了一种简单的基于滑动窗的区域提取策略。然后将得到的感兴趣区域经过一定地尺度变换对应到特征映射图上的相应区域,由此可迅速得到感兴趣区域的BCF特征矢量。在实际操作中,我们可以直接在特征映射图上进行滑动窗口提取,分别在查询图像与候选图像的特征映射图的相同位置上,提取了n个宽高为的窗口,其中W和H分别为特征映射图的宽与高,然后计算查询图像Q与候选图像Ck的重排名分数:
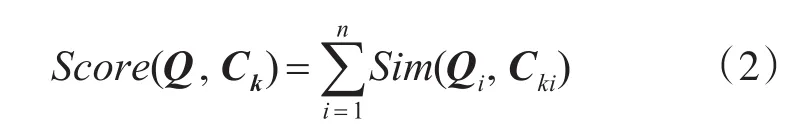
其中,Qi和Cki分别为查询图像和候选图像的第i个窗口区域的BCF特征矢量。
根据重排名分数对候选集中的图像进行二次排名,得到最终的查询结果。
4 实验结果与分析
4.1 网络层及网络结构的影响
为了验证本文提出的方法并不依赖于特定的网络结构,我们选择了Caffe[26]预先训练好的两种不同的网络模型,AlexNet[12]和 VGG16[27]网络模型,在相同数据集上进行对比实验。同时为了验证本文的方法并不需要针对特定的识别任务进行专门地训练,我们选用了AlexNet-Places365网络模型进行实验,该模型与AlexNet具有相同的网络结构,但它是在Places365[13]场景识别数据集上训练得到的。深度卷积神经网络往往具有多个卷积层,不同卷积层输出也不同,因此在本实验中我们对每种网络结构都选用了三个不同的卷积层输出来构造BCF特征,以展示不同网络层对于识别结果的影响,对于AlexNet和AlexNet-Places365网络,我们选用了其conv3,conv4及conv5层的输出,对于VGG16网络模型,我们选择了其conv5_1,conv5_2及conv5_3的输出。我们抽取了不同卷积层输出进行可视化,效果示例如图3所示。
由图3可以看出,不同网络卷积层输出有较大差别,且同一卷积层内部层间输出也存在很大差异,其实这也解释了为什么CNN网络能够表现出比传统手工特征更为强劲的表现,相对于手工特征来说,CNN网络实质是一个高度非线性的模型,它内在地集成了多个不同的滤波器各自进行卷积运算,因此能在各个层次上提取出不同位置的不同特征。我们在Gardens Point Campus数据集[18]上进行了实验,实验结果如图4所示。
我们采用了从候选集中挑选出前N个候选结果时的正确率来作为评判标准。从实验结果可看出,虽然识别效果上VGG16要稍好于AlexNet-Places365 和 AlexNet,而 AlexNet-Plac⁃es365的识别效果要略好于AlexNet,但这种优势并不明显,vgg16的平均识别正确率只比AlexNet-Places365高出了3.05%,而经过特定训练的AlexNet-Places365模型的平均识别正确率仅仅比通用的AlexNet网络模型高出了0.42%。由此可以说明,本文的方法并不依赖于特定的网络模型,也无须针对特定识别任务进行专门的训练。

图3 卷积层输出可视化
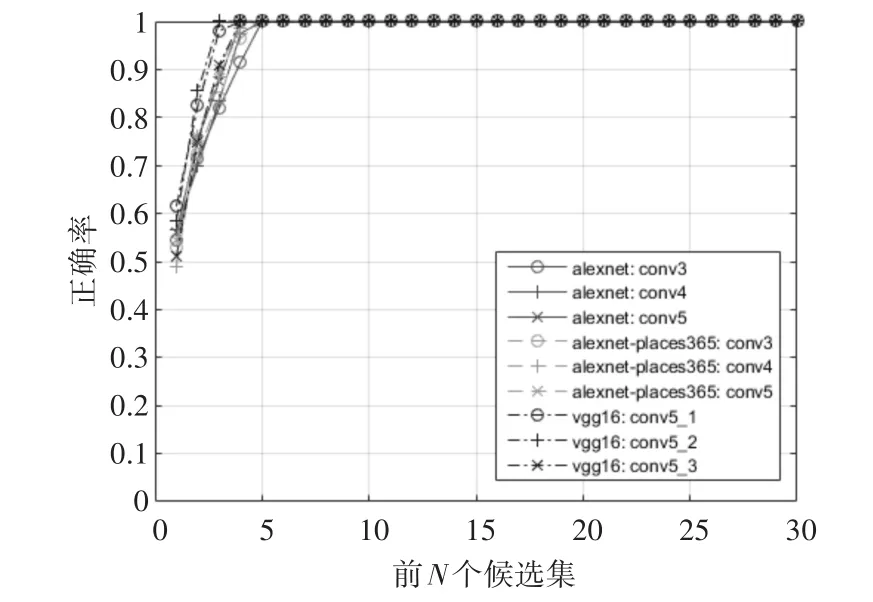
图4 不同网络及网络层的实验结果
4.2 与传统手工特征进行对比
我们将本文所提的基于CNN特征提取的位置识别方法与基于传统手工特征的方法进行对比,以验证CNN特征在位置识别任务上具有优势。在此我们选择了SURF和ORB这两种具有代表性的手工特征,并采用与CNN特征相同的BoW集成策略在相同数据集上进行实验。SURF和ORB直接使用了OpenCV的实现。CNN特征我们选用了AlexNet的conv5层输出,AlexNet-Places365的conv5层输出,以及VGG16的conv5_1层输出。实验主机配置为Intel Core i5-6500 CPU@3.20GHz x 4,GPU为NVIDIA GeForce GTX 1050。
首先,我们在 Gardens Point Campus数据集[18]上进行了实验,该数据集中图片主要包含了一定的视点变化,并含有轻微的外观变化和行人等动态环境的影响因素,如图5所示。

图5 Gardens Point Campus数据集样例图
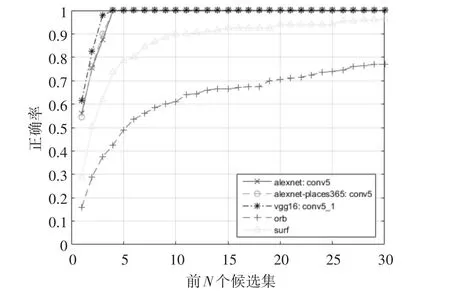
图6 Gardens Point Campus数据集实验结果
由图6可以看出,在应对具有视点变化的位置识别时,基于CNN特征的方法表现优于SURF和ORB,其平均识别正确率比SURF高出了11.17%,比ORB高出了35.02%。ORB特征是一种二值特征,其设计时在精度和速度上进行了折中,因此是一种速度极快(在本实验环境中,其平均查询时间约为0.05s,而基于CNN特征和SURF特征的方法平均查询时间在0.1s左右)但精度稍逊一筹的特征描述子。
Gardens Point Campus数据集中图片所存在的变化并不大,识别较为简单。为了体现CNN特征在复杂环境变化下的优势,我们在难度更大的Al⁃derley Day/Night数据集[20]上进行了实验,该数据集是对同一条路线,在天晴的白天和下雨的夜晚分别进行拍摄,因此存在光照、视点、外观及动态环境等多种变化因素的影响,大大增加了位置识别的难度,数据集图片示例如图7所示。
由图8可以看出,在应对包含较大的光照、外观、动态环境、视点等变化环境下的位置识别时,基于CNN特征的方法表现出明显的优势,其平均识别正确率比SURF高出了46.61%,比ORB高出了55.41%。由于我们只是简单地采用了基于OpenCV的SURF和ORB实现,并没有采用一些额外地优化手段,因此基于SURF和ORB的方法性能上还有一定的提升空间。不过由于我们将CNN特征、SURF及ORB,集成了相同的位置识别算法框架,因此更加能够说明CNN特征在应对光照、外观结构、动态环境、视点等环境变化因素上具有更好的鲁棒性。

图7 Alderley Day/Night数据集图片示例

图8 Alderley Day/Night数据集实验结果
5 结语
本文提出了一种基于深度卷积神经网络特征与词袋模型结合的视觉位置识别框架。该方法无需针对特定位置识别任务进行专门地训练,且可更换识别算法框架中的任意模块,通用性强,实用性高。通过在具有挑战性的公开数据集上进行测试,该方法取得了比基于SURF、ORB等传统手工特征的位置识别方法更好的识别效果,并对视点变化、光照变化、外观变化以及动态环境等复杂影响因素具备更好的鲁棒性。本文中只是采用了最简单的局部区域提取策略用于局部重排名,在接下来,我们将研究采用更加有效的局部区域提取策略来进一步提高识别效果。
[1]Mcmanus C,Churchill W,Maddern W,et al.Shady deal⁃ings:Robust,long-term visual localisation using illumi⁃nation invariance[C]//IEEE International Conference on Robotics and Automation,2014:901-906.
[2]Middelberg S,Sattler T,Untzelmann O,et al.Scalable 6-DOF Localization on Mobile Devices[C]//European Conference on Computer Vision,2014:268-283.
[3]Lowry S,Sunderhauf N,Newman P,et al.Visual Place Recognition:A Survey[J].IEEE Transactions on Robot⁃ics,2015,32(1):1-19.
[4]Lowe D G.Distinctive Image Features from Scale-Invari⁃ant Keypoints[J].International Journal of Computer Vi⁃sion,2004,60(2):91-110.
[5]Bay H,Tuytelaars T,Gool L V.SURF:Speeded Up Ro⁃bust Features[J].Computer Vision&Image Understand⁃ing.2006,110(3):404-417.
[6]Rublee E,Rabaud V,Konolige K,et al.ORB:An effi⁃cient alternative to SIFT or SURF[C]//IEEE International Conference on Computer Vision,2011:2564-2571.
[7]Oliva A,Torralba A.Chapter 2 Building the gist of a scene:the role of global image features in recognition[J].Progress in Brain Research,2006,155(2):23-36.
[8]Philbin J,Chum O,Isard M,et al.Object retrieval with large vocabularies and fast spatial matching[C]//IEEE Conference on Computer Vision and Pattern Recognition,2007:1-8.
[9]Arandjelovic R,Zisserman A.All About VLAD[C]//IEEE Conference on Computer Vision and Pattern Recog⁃nition,2013:1578-1585.
[10]Perronnin F,Liu Y,Sanchez J,et al.Large-scale image retrieval with compressed Fisher vectors[C]//IEEE Con⁃ference on Computer Vision and Pattern Recognition,2010:3384-3391.
[11]Jegou H,Douze M,Schmid C.Product quantization for nearest neighbor search[J].IEEE Transactions on Pat⁃tern Analysis&Machine Intelligence,2011,33(1):117-128.
[12]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classi⁃fication with deep convolutional neural networks[C]//In⁃ternational Conference on Neural Information Processing Systems,2012:1097-1105.
[13]Zhou B,Garcia A L,Xiao J,et al.Learning Deep Fea⁃tures for Scene Recognition using Places Database[J].Advances in Neural Information Processing Systems,2015,1:487-495.
[14]Ren S,He K,Girshick R,et al.Faster R-CNN:To⁃wards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2016(99):1-9.
[15]Gomezojeda R,Lopezantequera M,Petkov N,et al.Training a Convolutional Neural Network for Appear⁃ance-Invariant Place Recognition[J].Computer Sci⁃ence,2015:1-9.
[16]Neubert P,Protzel P.Local region detector+CNN based landmarks for practical place recognition in changing en⁃vironments[C]//European Conference on Mobile Robots,2015:1-6.
[17]Sunderhauf N,Shirazi S,Dayoub F,et al.On the perfor⁃mance of ConvNet features for place recognition[C]//IEEE International Conference on Intelligent Robots and Systems,2015:4297-4304.
[18]Sünderhauf N,Shirazi S,Jacobson A,et al.Place Rec⁃ognition With ConvNet Landmarks:Viewpoint-Robust,Condition-Robust,Training-Free[C]//qIn Proceedings of Robotics:Science and Systems XII,2015:296-296.
[19]Chen Z,Lam O,Jacobson A,et al.Convolutional Neu⁃ral Network-based Place Recognition[J].Computer Sci⁃ence,2014:1-9.
[20]Milford M,Scheirer W,Vig E,et al.Condition-invari⁃ant,top-down visual place recognition[C]//IEEE Inter⁃national Conference on Robotics and Automation,2014:5571-5577.
[21]Mcmanus C,Upcroft B,Newmann P.Scene Signatures:Localised and Point-less Features for Localisation[C]//Robotics:Science and Systems,2014.
[22]Zitnick C L,Dollar P.Edge Boxes:Locating Object Pro⁃posals from Edges[C]//European Conference on Comput⁃er Vision2014:391-405.
[23]He K,Zhang X,Ren S,et al.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2014,37(9):1904-1916.
[24]Galvez-Lopez D,Tardos J D.Bags of Binary Words for Fast Place Recognition in Image Sequences[J].Robotics IEEE Transactions on,2012,28(5):1188-1197.
[25] Rosten E,Drummond T.Machine Learning for High-Speed Corner Detection[C]//European Conference on Computer Vision,2006:430-443.
[26]Jia Y,Shelhamer E,Donahue J,et al.Caffe:Convolu⁃tional Architecture for Fast Feature Embedding[C]//ACM International Conference on Multimedia,2014:675-678.
[27]Simonyan K,Zisserman A.Very Deep Convolutional Net⁃works for Large-Scale Image Recognition[J].Computer Science,2015:1-14.
