改进的HMM模型在特征抽取上的应用
2018-04-25,
,
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010)
0 引言
传统的情感分析方式是基于简单统计的情感倾向分类,Tsou等[1]利用大众对名人的评价语料,全面地统计分析极性元素分布密度和语义强度得到词语的语义倾向。
接着,基于机器学习的文本倾向性研究开始兴起,Pang 等[2-3]利用bag-of-words 技术并且朴素贝叶斯、最大熵、支持向量机(SVM)分类器方法对电影影评进行情感倾向分析;Whitelaw 等[4]提取文本中形容词和修饰语词组作为特征结合词袋技术形成向量空间模型并采用 SVM 对电影影评分类;Turney使用一些固定句法模式来抽取基于词性标注的标签。Taboada[5]提出基于词库的方法,用带有一定倾向和强度的情感词及词组的词典采用集约化方法计算每个文本的情感分值。向量空间模型的假设是特征与特征之间是相互独立的(正交假设),这在实际中难以满足。
为了改善向量空间模型的缺陷,LSA(Latent Semantic Analysis)[6]潜在语义分析的方法被提出了,并且在信息检索方面取得了一定的成功。
随着,计算机计算的存储能力和计算性能不断地提高,深度学习的方法再次进入人们的视野,并成为情感分类研究的热点。RNN具有很强大的抽取文本信息的能力,并且循环神经网络(RNN)在NLP里应用广泛,论文[7]证明了RNN在文本分类和情感分类上效果很好,但是,RNN解决不了长期依赖的问题,LSTM模型能解决任何长度的序列,并且能够捕获长时间的独立性。
随着对word2vec的深入,以及谷歌对word2vec开源以后,在论文[8]中作者运用的是基于word2vec加权的svm算法,作者通过计算每一个文档当中词语的tf-idf作为权值,最后得出一个比较好的结果。在文章[9]中,作者将连续的三个词作为一个嵌入向量对进行输入,通过神经网络模型,最后测评分类结果,在这篇文章中,所有的词汇在空间上相邻,作为一个输入,这样的做法是VSM的扩展,相当于把词对作为一个单元进行处理,忽略了词对之间的关联性。因此,对词对的关联性如果按照论文的处理方式是空间位置的相邻。
1 特征抽取模型的设计
1.1 概率图模型
设X={x1,…,xk,…,xl}表示的是训练集,xk=(xk1),…,xki),…,xkp),其中k∈{1,2,…,l},i∈{1,2,…,p},xk表示的是第k个样本,xki表示的是第k个样本中的第i个观测值,l表示的是训练集的样本容量,p表示的是是组成样本xk的序列长度。
集合S={s1,s2,…,sn}为训练集当中所有的状态集合,集合O={o1,o2,…,om}为观测值的集合(其中m为观测集合的长度,n为状态值的长度)。那么隐马尔科夫模型所涉及概率图模型就如图1。
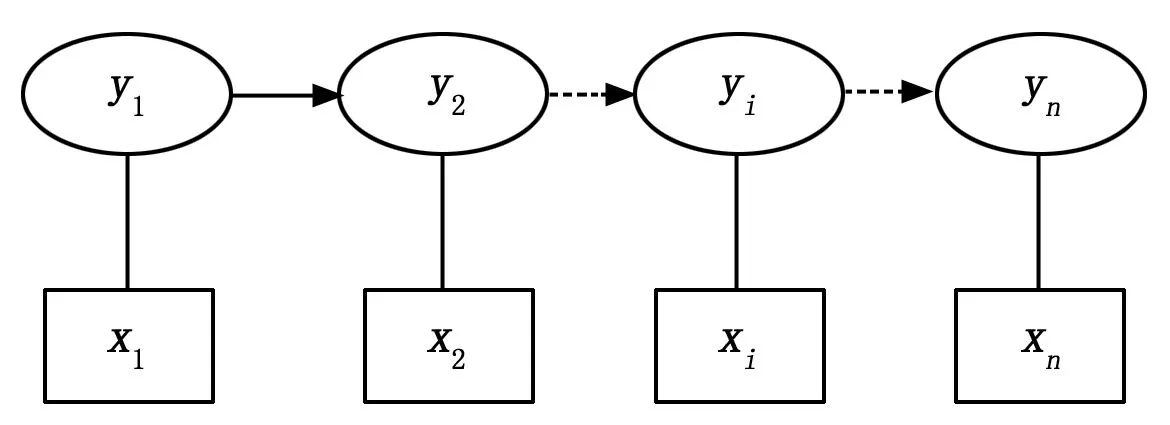
图1 概率图模型
图1表示的是训练集中任意一个序列对应的状态和观测值之间的关系。从上面的概率图模型中我们可以看出三个基本的变量,状态集,观测矩阵,状态转移矩阵。因此对于隐马尔科夫模型,我们定义三个最基本的矩阵和向量。状态转移矩阵A=[aij] (其中i,j∈{1,2,…,n}),B=[bij],其中i∈{1,2,…,n},j∈{1,2,…,m}。设π=[π1,π2,…,πn]^T表示状态向量,用来表示每个状态的权重。
其中对于以上的aij=P{S=sj|S=si}表示从si状态转移到sj状态的一步转移概率,A表示的是一步转移概率矩阵,bij=P{S=si|O=oj}表示观测值对应的某一个状态的概率值。πi=P{S=si}表示某一个状态对应状态概率。
而对于训练集要获得上面三个参数Φ=(A,B,π)。针对自然语言的特殊要求,在构建模型之前,我们定义一种运算如公式(1):
α⊗β=λ
(1)
在公式(1)中α、β、λ都是n维向量,对于它们的任意分量都有λi=αi×βi。
计算某一个观测值对应的状态表示值用公式(2)进行计算:
γ=AT·β⊗π
(2)
这里A表示的是状态转移矩阵,β表示某观测矩阵B中的某一个观测值对应的观测向量,π表示的是状态向量。
1.2 获取HMM的三要素的方法
在实验过程中,按照Baum-Welch算法对构成中文的语料库进行训练。获得隐马尔科夫模型的三要素Φ=(A,B,π),根据哈工大语言云得到结果,其中的隐含变量是词对的语义标注,观测向量是观测词汇,可以获得马尔科夫模型的初始化,随后,根据Baum-Welch或者EM算法进行迭代获得马尔科夫模型的三要素,其流程如图2所示。
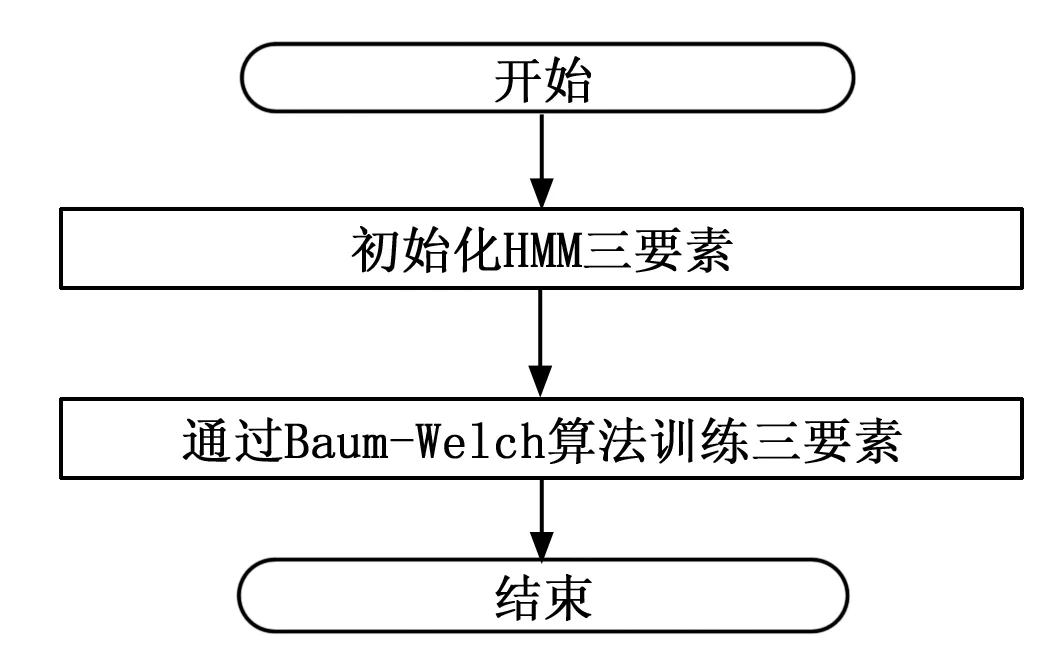
图2 HMM训练过程
1.3 MHMM表示词对向量
根据马尔科夫链的一步转移概率,可以很清楚的知道某一个词对出现的概率。状态矩阵表示的是一步转移概率,而词汇的观测矩阵表示的词对在每个状态下的观测概率。因此,用公式(2)表示的是词对在语义特征上的抽取概率和。接下来用马尔科夫链的性质,说明算法的合理性。
定义1:转移概率在离散序列马尔科夫链{Xn}中,其具有有限或者无限的状态S={s1,s2,…,sn},假设x=x(tn)表示序列t=tn时的状态,则条件转移矩阵表示的是在所有的观测序列当中从上一步转移到下一个状态的概率统计值,用其对应的频率来估计。即是说转移概率矩阵为P=[pij]=P{x(tn+1)=sj|x(tn)=si},其中sj,si∈S。
定义2:观测向量表示的是,在整个观测当中,某一个观测值o在某一个状态上的概率值。假设观测向量用β表示,β是一个m维的向量。其中假设:
β={b1,b2,…bi,…,bm}
其中:对于bi的解释表示如下。
bi=P{S=si|O=o}
上式表示的是某一个观测词对在si状态下的概率。
用马尔科夫链的知识,很容易知道在整个马尔科夫过程中,条件转移概率用的是n个状态,而每个状态对应的概率为bi,那么一次词对向量对应的每个状态的输出就是:
P=ATβ
(3)
如果再乘以每个状态对应的权重,上面是用π来表示的,那么就可以看成是这个词汇对在出现的每个对应的权重概率值。在公式(3)中,这个权重用π表示,这里的π表示的是每个状态在训练集中对应的状态的概率。
而且根据马尔科夫链的一步转移矩阵,以及在每个状态下的概率分布,很容易算出这个观测变量在每个状态下的概率。因此,用这个方法来表示一个语义词对,具有一定的科学性。
2 算法有效性验证
2.1 数据获取与预处理
本文的数据集通过网络爬虫,采集了豆瓣的影评数据,对采集的数据进行后续处理:第一部是将整个数据集进行过滤,把影评数据里面重复的字段删除;第二部是将单个测评数据当中连续几个重复的词条进行过滤;第三,去除里面的停顿词。第四部是将评分替换成差评和好评,标准是低于6分的判定是差评,高于6分的判定是好评。
对中文分词,从分词效果上来看,哈工大的自然语言处理工具的作用效果更好,分词的正确率较高,而且,本文考虑了隐含变量的运用,因此,在进行数据预处理的时候,选择了哈工大词云的语义角色标注。
在哈工大的词云上,根据词对的语义特征,将语义标注分成了:施事关系,当事关系,等等大约100种关系,而这种关系可以用这样的一个序列表示(x1,x2,…,xn,r)其中xi表示的是某一个词语,前面的x1至xn表示的是在语义标注里面存在的词汇,r表示这n个词语之间的语义关系。
2.2 特征抽取
2.2.1 RNN
RNN是循环神经网络,它的结构单元如图3所示。
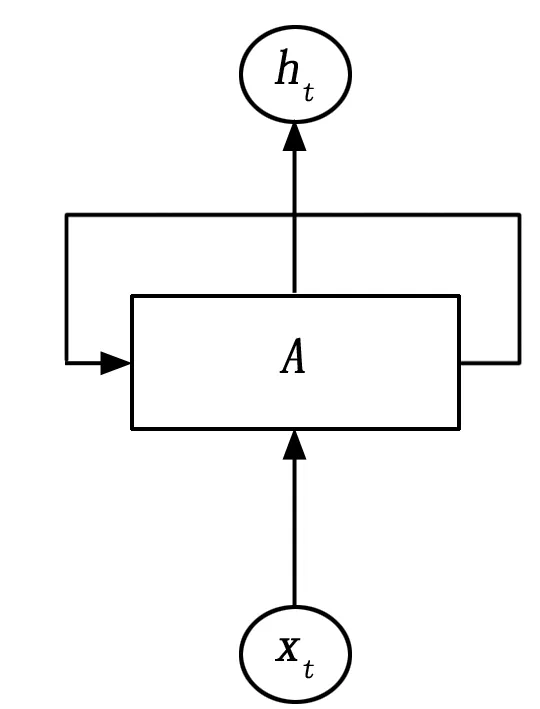
图3 RNN单元
RNN的计算过程如下,假设输入序列是:
其中xt表示的是一个n维的向量。
xt=[x1,x2,…,xn]
记忆单元的初始值为:
C=[c1,c2,…,cn]
RNN的激活函数为线性激活函数,输入权值矩阵为win,输出权值矩阵为wout。根据前向算法,很容易得到的下面的算法:
(4)
式中,[x1,Ci-1]中表示将两个向量拼接在一起。那么输出就为:
oi=wout·Ci
(5)
2.2.2 LSTM
同样的道理,LSTM单元如图4所示。
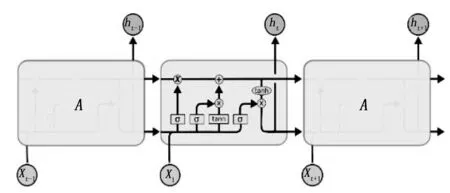
图4 LSTM结构示意图
可以从图中看出LSTM由:输入门、输出门和遗忘门,三个门进行控制其输出以及在细胞单元里面的输入值和输出值的变化,而且这三个门的权重值都是通过LSTM本身学到的。
按照上面的要求,可以得到如下的步骤(以下的σ(·)表示的是sigmoid函数):
第一步:决定单元状态保留的信息,是通过遗忘门来实现的。对应的是图中的ft,其计算如下:
ft=σ(wf·[xt,ht-1]+bf)
(6)
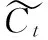
it=σ(wi·[xt,ht-1])+bi
(7)
(8)
第三步:更新记忆状态,对应图中的Ct,其计算过程如下。
(9)
第四步:最后输出Ot和ht,它们的计算过程如下:
Ot=σ(wo·[xt,ht-1])
(10)
ht=ot×tanh·(Ct)
(11)
运用LSTM神经单元的多个层次对输入序列进行迭代会产生很多个输出,然后在实验过程中取出序列的最后一个输出作为句子向量。
2.2.3 句子特征抽取方式
进行特征抽取以前,通过哈工大语言云对原始数据进行语义分析,并将训练数据存储为json数据,作为训练数据,然后根据里面的词对训练HMM的精确参数(A,B,π),其中A表示状态矩阵,B表示观测矩阵,π表示状态向量。训练HMM的过程如2.2介绍的那样。在进行特征抽取的时候采用的是MHMM模型,用改进的隐马尔科夫模型对一个语义词对进行表示。并且按照MHMM模型,获得句子当中出现的某一个词对出现的特征按照如图5所示的过程去进行词对特征抽取,并将其输入到LSTM神经元中,并且将最后的输出作为句子特征向量。
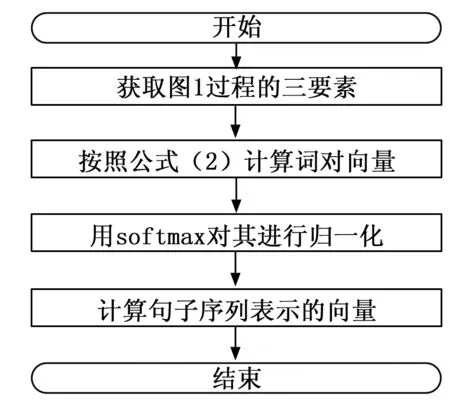
图5 词对向量的训练过程
考虑到整个过程当中,每个词对形成的词对向量存在一定的稀疏性,因此,在对整个数据输入到LSTM之前,运用softmax函数对数据进行归一化处理。
接下来,将特征抽取以后的每个词对向量组成的序列,放入LSTM单元当中,用动态RNN对输入的词对序列迭代处理,神经单元的最后一个输出向量作为评论样本表示的特征向量。
2.3 情感分类模型建立
在构建模型之前,对模型输入的词对或者词汇进行了预训练,获得句子向量,然后根据句子向量和类别标签产生分类训练器。在实验过程中,建立了如下的分类器模型:
1)基于word2vec的SVM:先将所有的词汇用word2vec进行训练产生了词向量,对每一条评论分词产生的序列进行遍历获得词汇向量后,用每个分量的其平均值表示句子向量,用这个句子向量输入到SVM中进行模型训练。
2)标准的LSTM算法:通过word2vec对词汇进行训练以后,把词汇按照分词顺序进行排列并按照这个词序在word2vec的模型中找到对应的向量,输入到LSTM的神经元中,获得其句子的向量,最后按照这个向量进行3000次的迭代产生,使用交叉熵作为优化器,采用随机梯度下降法进行优化求得最优值。
3)基于词对的LSTM算法:通过word2vec对词汇进行训练以后,将三个在语序上相邻的词汇放在一起,求其平均值,然后将这些平均值作为输入,输入至LSTM单元中进行计算,其训练器的优化过程同上。
4)基于MHMM的LSTM算法:通过3.2.3的过程进行特征抽取,然后输入到LSTM的输入单元中,其优化过程和迭代过程同上。
5)基于随机向量的LSTM算法:对词向量的初始化采用的是随机向量,输入到LSTM单元当中,其训练和优化的过程与第二种方式基本相同。
2.4 MHMM用于情感分类
基于MHMM的LSTM实验做法是将评论集通过训练马尔科夫模型的三要素,得到每个单词对的词向量,将它们LSTM的一个输入,再将序列按照顺序逐个输入到LSTM神经元中,其处理结构如图6所示。
图6 基于MHMM的LSTM情感分类图
输入层:经过LTP产生的语义词对。
MHMM:经过MHMM对产生的词对进行处理,得到每个词对在语义上产生的概率分布,然后用softmax进行归一化处理,产生的输出。
Z:经过MHMM产生的输出,经过归一化处理,用来训练神经网络。
LSTM:LSTM用来作为特征提取的一个工具,每个序列都会产生一个对应的输出。
Softmax层:用softmax层作为分类的依据。
根据以上的说明,MHMM用于LSTM模型的情感分类算法如算法1所示。
算法1:
输入:无标签的数据D,训练集D-train,测试集D-test
输出:测试集的情感标签
1)将训练集和测试集中的数据进行预处理
2)获取隐马尔科夫参数(A,B,π),并且用来得到词汇对的向量表示
3)初始化LSTM-RNN的参数,训练模型
4)For Sentences s in D-train:
a)对于s中的每个词汇,找到其对应的词向量,放入输入层
b)通过LSTM-RNN产生输出,用输出的最后一个向量作为softmax的输入。
c)通过softmax层产生分类的依据
d)通过反向传播调节参数获得最后的模型
End for
5)导出模型,用于测试集的情感分类
6)For Sentences s in D-test:
a)对于s中的每个词汇,找到其对应的词对向量,放入输入层
b)通过LSTM-RNN产生输出,用输出的最后一个向量作为softmax输入。
c)通过softmax层产生分类
End for
3 实验结果分析
3.1 实验测评参数的定义
本文采用正确率,召回率和f-measure对分类产生的结果进行测评,在进行测评之前首先对几个符号进行定义:
TP:通过分类算法,将原本的正类预测成为正类的数目;
FN:通过分类算法,将原本的正类预测成为负类的数目;
TN:通过分类算法,将原本的负类预测成为负类的数目;
FP:通过分类算法,将原本的负类预测成为正类的数目;
那么,可以定义以下的公式进行分类的测评。
正确率:
(11)
召回率:
(12)
f-measure:
(13)
3.2 实验结果及实验结论
3.2.1 训练阶段
在爬取的豆瓣影评数据集中抽取四万条左右的评论数据,经过哈工大词云进行语义角色标注,获得词对表示的语义标签,把词对作为观测矩阵、把语义标签作为潜在的隐含特征,通过训练HMM的三要素获得了词对的表示,并且将这些语义用来训练HMM模型。对这四万多条的数据进行统计其评论情感极性见表1。
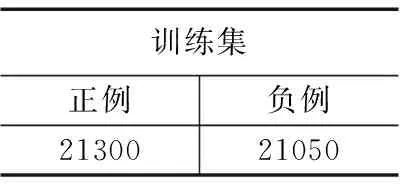
表1 训练集情感极性统计结果表
并且将这些特征输入到LSTM-RNN模型中,并且抽取最后的一个词汇特征作为神经网络的输入,再进行分类,在训练的时候,选择的优化器是交叉熵,使用随机梯度下降法进行学习,其学习率设置为0.0001,在训练模型的时候,每次用于训练模型的评论集的batch大小设置为512条,经过大约2千万次的训练,各个模型-算法正确率见表2。
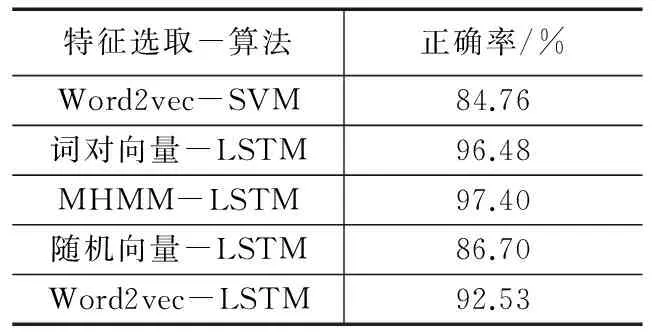
表2 数据集情感极性统计结果表
从表中,可以很容易得出的是,运用MHMM进行特征抽取的效果比词对向量进行特征抽取的效果要高1个百分点,用词对向量进行特征抽取比标准的word2vec进行词向量的表示要11个高百分点,因此MHMM的在特征的抽取上有较好的作用效果。
3.2.2 测试阶段
通过对测试集的情感极性分析获得了数据统计情况见表3。
表3 测试集情感极性统计结果表
通过对数据的测试,获取了的测评数据包括:模型的正确率,模型的召回率和模型的f-score,其详细情况见表4。
从表4中可以看出来,使用三个模型进行特征抽取的时候,MHMM的正确率比词对向量高出1个百分点,比标准的word2vec进行特征抽取词向量的模型高0.04百分点。召回率最大的是运用word2vec进行特征抽取的模型,其比词对向量高2个百分点,比MHMM-LSTM词向量进行特征抽取3个高百分点。f-score值最高的是使用word2vec进行特征抽取的,其比其他两个模型高出的百分点依次是:1.5个百分点和1.4个百分点。
运用MHMM产生的词向量和空间相邻的词语产生的词向
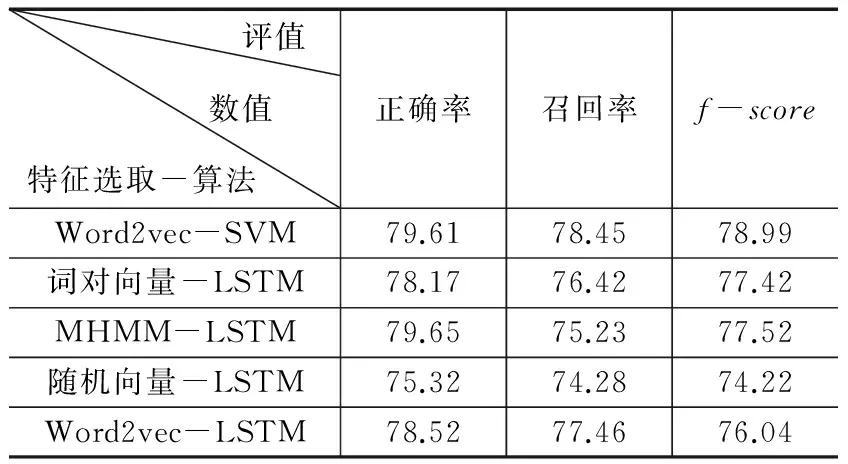
表4 模型测试 %
量作为LSTM-RNN细胞的输入,进行情感分类,通过多轮迭代产生,对其正确率、召回率和f-score进行评估,实验结果表明了通过MHMM进行预训练产生的词对向量,用于LSTM-RNN分类器中,其性能优于空间相邻的词对向量,而词对向量的性能优于word2vec。
综上观之,运用MHMM进行特征抽取,进行情感分类的作用效果较好。
参考文献:
[1] Tsou B K Y, Yuen R W M, Kwong O Y, et al.Polarity classification of celebrity coverage in the Chinese press[A].Proc.of International Conference on Intelligence Analysis[C]. 2005.
[2] Pang B, Lee L, Vaithyanathan S. Thumbs up?: Sentiment classification using machine learning techniques[A].Proc of the ACL Conference on Empirical Methods in Natural Language Processing[C].Association for Computational Linguistics, 2002:79-86.
[3] Pang B, Lee L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales[A].Pro. of the 43rd Annual Meeting on Association for Computation Linguistics[C].Association for Computational Linguistics,2005:115-124.
[4] WhtitelawC,GargN,ArgamonS.Using appraisal groups for sentiment analysis[A].Proc of 14th ACM International Conference on Information and Knowledge Management 2005:625-631.
[5] Taboada M, Brooke J, Tofiloski M, et al. Lexicon-based methods for sentiment analysis[J]. Computational Linguistics, 2011, 37(2): 267-307.
[6] Nigam,McCallumA,ThrunS,et al.Learning to classify text from labeled and unlabeled documents[A].Proceedings of the 15th National /10thConferenceon Artificial Intelligence/Innovative Applications of Artificial Intelligence [C].Menlo Park,CA,USA:AAAI Press,1998:792-799.
[7] Lee Y.Dernoncourt:sequential short-text classification with recurrent and convolutional neural networks(2016).arXiv preprint:2016.
[8] 李 锐,张 谦,刘嘉勇.基于加权word2vec的微博情感分析[J].通信技术,2017(3):502-506.
[9] ChiLu et al,A P-LSTM Neural Networksfor Sentiment Classification[J].Jinho Kim .KyuseokLongbing Cao Jae-Gil Lee XueminLin.Yang-Sae moon(eds):105-110.
