基于分类数据的可视化改善方法
2018-04-24李存燕
李存燕
(四川大学计算机学院,成都 610065)
0 引言
分类数据是取值不连贯、没有次序关系的数据,属于统计数据的一种,可以反映事物的类别,例如人属于一种分类数据,可以按照性别分为男、女两类。对分类数据进行预处理,例如排序,聚类等可以改善可视化效果,用来确定相同属性的相似之处和不同属性之间的关系。
可视化技术对大型多维数据集的分析和探索变得越来越重要[1-2]。虽然大量的工作已经解决了数字数据的可视化问题,但是许多领域都需要对大量的分类数据进行可视化。目前,研究者已经针对多个领域的数据进行了可视化技术的研究。例如人口普查数据中的城市名称和本文研究对象网络管理数据中的告警名称、产生告警设备编号等,只是与数值数据不同的是,分类值没有顺序。常用的可视化技术例如散点图和平行坐标图等,分类值需要映射到坐标轴上(例如产生告警设备编号),处理后按照一定规则排序的数据可以极大地提高可视化的质量。
1 排序分类数据的算法
排序分类数据的算法分为三个步骤:
第一步,使分类数据形成自然聚类,这个阶段需要使用领域知识进行分组,例如将接近同样的时间发出相似事件的设备作为一组。这样构造的一个重要含义是使得一个分类值可能属于多个分组。
第二步,给第一步发现的聚类排序。这应该由最小化冲突,或者最大化的解决潜在冲突来完成。这个优化问题能够更进一步的转化为一个图形问题。例如聚类 C1 包含 D1,D3,D4,D5,D6 六个主机,C2 包含D1,D2,D3,D7 四个主机,C3 包含 D1,D4,D5,D8 四个主机,则C1和C2冲突的数量为2(D1,D3),C1和C3冲突的数量为3(D1,D4,D5),C2和C3冲突的数量为 1(D1)。如图1所示,在这张图中,节点代表聚类,权重说明聚类间潜在冲突的数量。聚类排序为了最大化的解决潜在冲突,找到一个路径恰好遍历每个节点并最大化遍历弧的总和,是一样的。这是一个Hamilton[3]路径问题,一个完全NP问题,有很多启发式的算法被用于解决这个问题,我们用一个简单的贪心算法。
第三步,给每个聚类的主机排序。这是直接希望排序相邻聚类的分类值来消除所有两个聚类间的潜在的冲突。
算法的假设条件为:排序分类数据能够改善可视化的效果,以至于能够更好的研究分析大型、复杂的数据。
●算法输入:一个告警数据(Excel)
●算法的主要步骤:
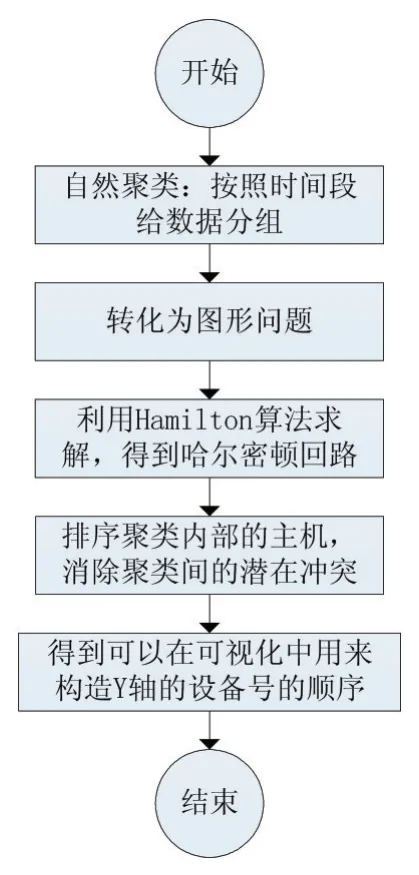
图2 算法流程
●算法输出:用来构造Y轴的设备号的排序
●平行坐标轴排序分类数据的算法主要思想
平行坐标轴排序分类数据的算法的主要思想继承了散点图排序分类数据算法的主要思想。除了第一步不同外,两个算法的思想跟步骤都基本相同。平行坐标轴排序分类数据的第一步是把基于两个值的关联规则聚类成一个属性。例如,A,B主机都发射了相同的事件类型,则A,B主机被聚为一类。这种方法一个主机也可能同时属于多个聚类。
2 可视化
数据的可视化是展示实验结果的最后一步,它负责呈现工作效果、是与客户交流的关键[4]。为了衔接项目组成员在前面所做的工作,我们的任务是寻找合适的可视化工具,借此分别用散点图和平行坐标图来展示原始数据与通过算法分组排序后的数据。
通过调研,发现大部分工具功能缺乏,例如魔方,无法进行平行坐标图的绘制;一部分工具例如raw只能支持在线进行可视化,无法满足可视化要求;一部分工具比如iCharts,是需要脚本语言进行调用,将其嵌入到网站开发代码中。通过比较,选择Tableau和Xdat对实验数据结果进行可视化。Tableau是用于画散点图的工具,十分灵活,可视化图案美观清晰,能够自主调节X轴和Y轴顺序。Xdat是用于画平行坐标图的工具,它是个开源工具,使用简单。缺点是不能自主调节X轴和Y轴顺序。
散点图和平行坐标图的可视化流程如图3所示。
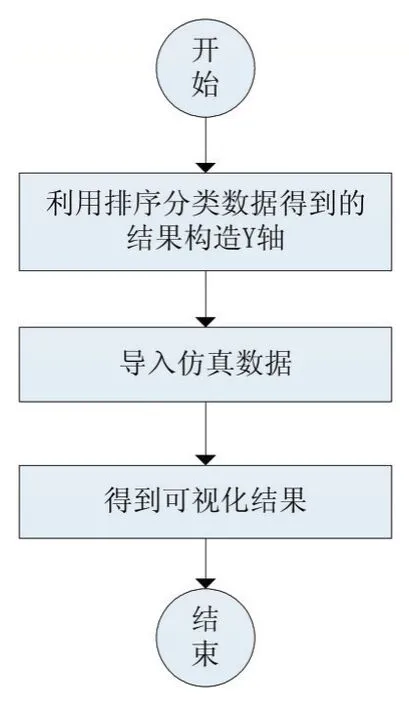
图3 散点图和平行坐标图的可视化流程
3 实验
(1)实验目标
验证排序分类数据改善可视化效果。
(2)实验对象(网络和数据仿真)
实验对象为根据数据描述制造的仿真数据,部分数据如表1所示:

表1 部分仿真数据
(3)实验预期结果
对仿真数据进行排序处理后的可视化效果明显优于未进行排序处理前的可视化效果,①找到某个属性中相同值的分组;②找到不同属性值之间的关系。
(4)实验步骤设计
第一步,构造分类值的自然聚类,实现步骤如下:
每台设备需要配备3人及1台运输切缝用水三轮车,每天切缝80m,折合成本5.75元/m。通过对比分析节省总成本38.88万元,速度快2.5倍。
①读取Excel实验数据
②按照时间段给数据分组,例如6秒内的数据分为一个组
>一共有几个分组(几个节点)
>每个分组里面的主机号(重复的忽略)
>根据节点两两之间重复的主机号,确定权重
关键代码如下:
//获取指定的两个参数之间的权重
③列出每个节点与其他每个节点的权重,输出矩阵
利用Hamilton算法写出程序,将矩阵输入后得到聚类的排序
第三步,给每个聚类内部的主机排序[5],希望可以消除两个聚类间的潜在冲突,实现步骤如下:
h1,h2为自然聚类得到的分组 a1,2为h1,h2中相同主机号的集合
a)对h1-a1,2中的值进行排序,使其序列处于h2中这些对应值之前
b)对h2-a1,2中的绝对值值进行排序,使其序列处于h2中对应值之后
c)在h2-a1,2和h1-a1,2之间选定a1,2的位置
d)用h2-a1,2和h1-a1,2,绝对值循环排列
关键代码如下:


(5)实验中间结果展示
经过编码测试,排序分类数据的结果如下图所示:
第一步,分类值自然聚类的实验结果如图4所示:

图4 分类值得自然聚类结果
第二步,给第一步得到的自然聚类排序的结果如图5所示:
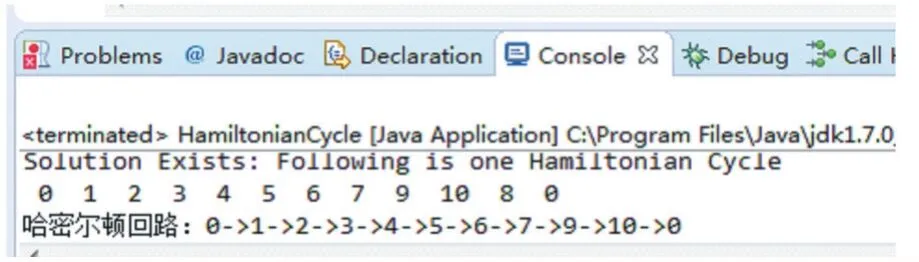
图5 对自然聚类排序的结果
第三步:给每个聚类内部的主机排序的结果如图6所示:
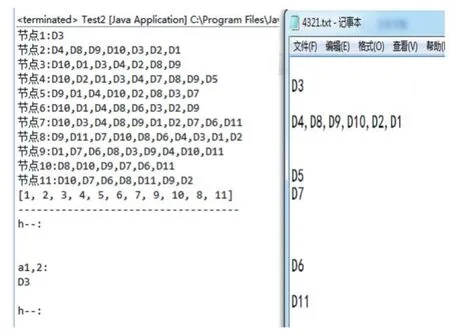
图6 聚类内部的主机排序的结果
(6)可视化效果
对分类数据排好序后,使用画散点图的工具Tab⁃leau,按照分类结果调节Y轴,然后倒入仿真数据得到可视化结果,如下图所示:
●散点图绘制实例如图7和8所示。
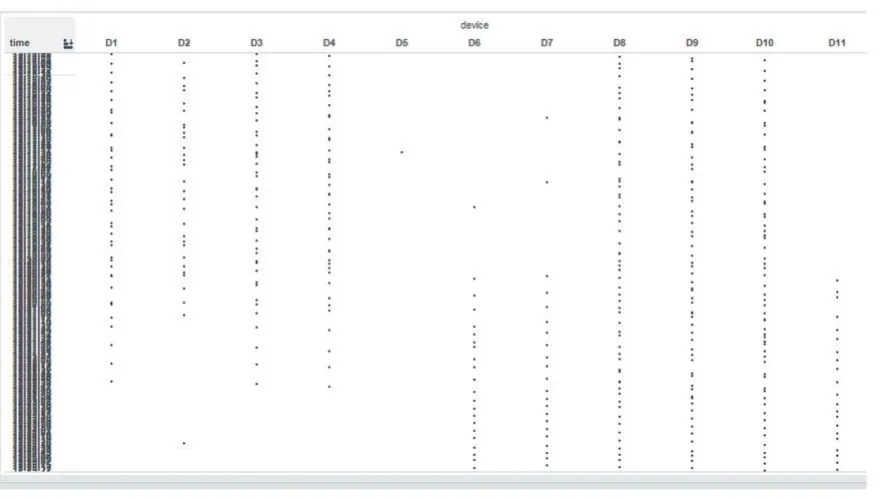
图7 排序前的可视化图
4 可视化结果分析
观察实验得到的排序前后的可视化效果图,发现经过处理后平行坐标轴的可视化效果更佳,达到了预期找到不同属性值之间的关系的效果。从图9处理后的平行坐标轴可视化图可以明显观察到大多数other类的告警都是由设备D1产生的,error7_alarm3到er⁃ror7_alarm48的告警基本都是由设备D9产生的等,该结果可用于告警预测,或者当网络发生告警时进行根因分析、定位等。

图8 排序后的可视化图
●平行坐标轴绘制实例如图9所示:

图9 处理前的可视化图
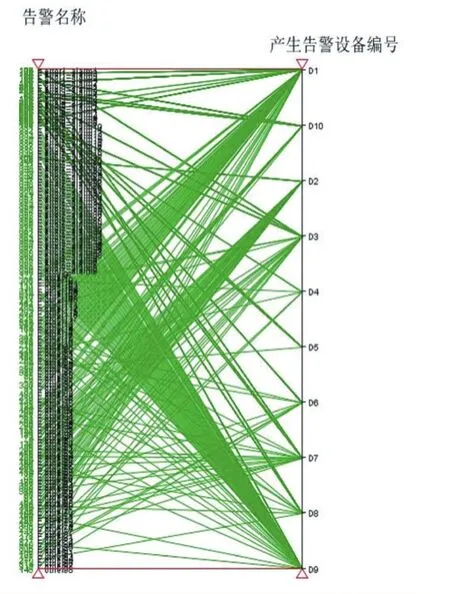
图10 处理后的可视化图
散点图的可视化效果改善不够明显,分析有如下原因:①实验使用的是根据数据描述制造的仿真数据,数据本身相当于经过了预处理后的数据,所示实验结果不理想;②实验数据量太少,改善效果不够明显。下一步考虑采取增大数据量或者采用真实数据等方法,以期获得更优的实验效果。
参考文献:
[1]Ahlberg C,Wistrand E.IVEE:an Information Visualization and Exploration Environment[M].CiteSeer,1995.
[2]Ankerst M,Berchtold S,Keim D A.Similarity Clustering of Dimensions for an Enhanced Visualization of Multidimensional Data[C].Information Visualization,1998.Proceedings.IEEE Symposium on.IEEE,1998:52-60,153.
[3]蔡延光,张新政,钱积新,孙优贤.边赋权森林ω-路划分的 O(n)算法[J].软件学报,2003(05):897-903.
[4]沈汉威,张小龙,陈为,袁晓如,王文成.可视化及可视分析专题前言[J].软件学报,2016,27(05):1059-1060.
[5]Ma S,Hellerstein J L.Ordering Categorical Data to Improve Visualization[J].Proceedings of the IEEE Information Visualization Symposium Late Breaking Hot Topics,1999.
