一种新的基于DTW的孤立词语音识别算法
2018-04-13周炳良邓立新洪民江
周炳良,邓立新,洪民江
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
语音识别即让机器接收、识别和理解语音信号,能够“听懂”会话中的语音语义并执行人类意图。常用的识别方法包括动态时间规整(DTW)、隐马尔可夫模型(HMM)和人工神经网络(ANN)等。在孤立词语音识别中,动态时间规整是最简单有效的方法。DTW算法基于动态规划(DP)的思想,能够较好地解决孤立词识别时说话速度不均匀的难题。相较于传统的语音线性伸缩匹配的方法,DTW方法有效提高了孤立词语音识别系统的识别率,因此在特定场合下得到了较好的应用。
近年来,为了提高孤立词语音识别系统的效率,使其广泛适用于市场和各类服务领域,科研人员提出了许多新的基于DTW的语音识别算法。
文献[1]提出了基于音节个数的高效动态时间规整算法(SEDTW),该算法利用彝语语音信号音节个数从1个到7个不等的特点,预先检测出彝语语音信号中的音节个数,并将其只与含有相同音节个数的模板进行最优匹配,减少了系统的计算开销,提高了系统的识别效率。但该算法利用双门限检测法分辨语音信号的各个音节,对门限阈值精度要求很高,一旦阈值设置不准确,系统识别效率将大幅降低,且该算法只适用于彝语语音信号识别,适用率较低。
文献[2]提出了改善局部路径限制的DTW算法,该算法改善了局部路径节点前进的范围,有利于解决测试语音特征矢量与模板矢量均匀变化剧烈的匹配问题,加快了两矢量匹配的过程。但该算法增加了系统局部路径搜索的复杂度和内存消耗,且不利于解决两矢量均匀变化平缓的匹配过程。
文献[3]提出了增设参考模板阈值的DTW算法,该算法在进行测试语音特征矢量与模板矢量匹配时,一旦计算出部分失真度大于预先增设的模板阈值,将终止对该模板继续运算,转入对其他模板继续匹配运算。由于是中途停止对模板的匹配运算,因此可以节省部分计算开销,提高了系统的识别效率。该算法的识别效率优于文献[2]的算法,但是算法必须要为每一个模板找到一个合理的阈值,否则将无法减少系统的运算量,甚至大幅度降低系统的识别率。
在识别阶段,传统的DTW算法在测试语音特征矢量与所有参考模板矢量之间进行的是全长度最优路径匹配,一旦系统的参考模板数量较大,系统的计算量和内存消耗将加剧,从而严重影响识别系统的效率。针对上述问题,提出了一种加快DTW模板匹配的改进算法:预先对提取得到的测试语音特征矢量进行部分长度截取,并将得到的部分特征矢量与模板矢量进行最优路径匹配,排除掉匹配度较小的部分模板。如此快速反复进行语音部分匹配和模板排除,直至模板数量唯一。通过实验对该算法的识别效率进行了验证。
1 DTW算法的基本原理
DTW技术是一种把时间规整和距离测度计算结合起来的非线性规整技术,通过不断地计算测试语音特征矢量和模板特征矢量的距离来搜索两者之间的最优时间规整(最优匹配路径),保证它们之间存在最大的声学相似特性。假设待测语音共有N帧矢量,参考模板共有M帧矢量,分别记为T和R,且N≠M,则动态时间规整就是要找一个时间规整函数m=w(n),将测试语音特征矢量的时间轴n非线性地映射到模板的时间轴m上,并使函数w满足式(1):

(1)
其中,d[T(n),R(w(n))]是第n帧矢量T(n)和第m=w(n)帧模板矢量R(m)之间的距离测度;D是处于最优时间规整情况下两矢量的累积距离[4]。
实际上,DTW算法本质就是搜索测试语音特征矢量与模板矢量的最优匹配路径并求出两者之间最小累积距离D。现实应用中,由于说话人对同一语音的发音速率相差一般不超过2倍,为了满足这一实际特性,搜索最优匹配路径时,应该将最优匹配路径全局(任意节点与起点或止点的连线)限制在两边斜率分别为1/2和2的平行四边形中[5-6],如图1所示,且止点(N,M)满足式(2):
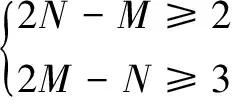
(2)

图1 最优路径全局限制示意图
同时对其局部路径(任意节点与前续节点的连线)也应加以限制,确保搜索路径中节点的前续节点在一定范围内,典型的一种局部路径限制方式[7-8]如图2所示。
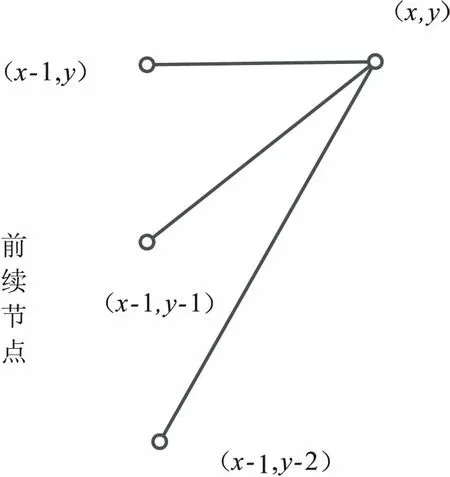
图2 最优路径局部限制示意图
为了找到满足最小测度距离D的最优匹配路径,DTW算法采用逆序决策过程,即节点的前续节点决定该节点的最小累积距离。假设路径的任意节点(x,y),搜寻出所有其可能的前续节点,并选择其中累积距离最小节点作为前续节点,则到达该点路径的最小累积距离计算公式为:
D(x,y)=d(T(x),R(y))+min{D(x-1,y),
D(x-1,y-1),D(x-1,y-2)}
(3)
式中节点满足图2的局部路径限制方式,且测试语音特征矢量作为横轴,模板矢量作为纵轴。这样从起点(1,1)开始搜索路径,利用式(2)反复递推后续节点的最小累积距离,经过N步后到止点(N,M)结束,即两矢量全长度最优路径匹配,则D(N,M)为测试语音特征矢量与模板矢量的最小累积距离。
传统孤立词识别系统基于上述DTW算法,分别搜索出测试语音特征矢量与所有库模板矢量的最优匹配路径并计算出两者的最小累积距离D,然后选择其中D最小的模板所表示的语音作为判别结果[8-9],具体算法流程如图3所示。

图3 传统全长度匹配流程
2 DTW算法的改进
由上一节知道,传统孤立词语音识别时,需要将测试语音特征矢量与所有的库模板都进行全长度最优路径匹配。如果孤立词语音库模板量较大,系统的计算量将急剧上升,严重影响系统的识别效率。这个现象在一词多模板的非特定人识别系统中尤其突出。
2.1 改进思路
假设测试语音特征矢量表示的是实际孤立词V,则与模板库中其他孤立词模板相比,它的起始部分长度与模板库中同样表示孤立词V的模板的起始部分长度之间匹配失真度相对较小。反之,如果将测试语音特征矢量V的起始部分长度与所有库模板矢量进行最优路径匹配,那么只需要保留部分匹配失真度相对较小的库模板矢量就可以将表示孤立词V的模板矢量保留下来。由于匹配过程中只需要测试语音特征矢量的起始部分长度进行匹配运算,便可以排除匹配失真度较大的部分模板,因此系统减少了部分计算量。
综合以上想法,提出了测试语音特征矢量与库模板矢量部分长度最优路径匹配的DTW算法,具体思路如下:先截取提取得到的测试语音特征矢量的起始部分长度(百分比),并从起点(1,1)开始搜索它们与各个模板矢量的最优匹配路径,采用松弛端点检测[10]的方法找到最优匹配路径的止点并求出各自的最小累积距离D,即找出各模板矢量与截取语音特征矢量匹配度最大的起始部分长度并求出相应的D,然后选择D相对较小的部分模板进行保留,排除D相对较大的模板。如此循环,采用这种方法对剩余的模板进行部分长度匹配和排除,直至剩余模板数量唯一,该算法流程如图4所示。
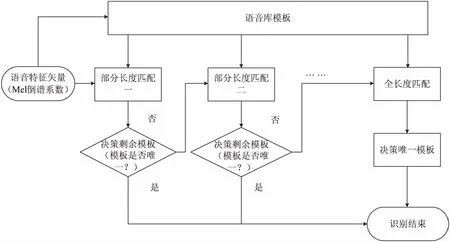
图4 部分长度匹配流程
2.2 准备工作
改进的DTW算法中测试语音特征矢量的截取方式和模板矢量保留方式需要预先设置,具体方法如下:每次截取的语音特征矢量都从起点开始,长度逐次增加。由于每次截取的测试语音特征矢量表示的语音可能与多个模板矢量起始部分表示的语音相同,所以每次部分长度匹配后保留的剩余模板一般大于1个(最后一次除外)。假设系统中有2个库模板矢量,分别表示语音“三”和“四”,它们的语音在起始端有相同的部分:‘s’。如果截取的语音特征矢量表示的语音在‘s’范围内,一旦系统只保留一个模板,就有可能错判。为了保证部分长度匹配算法的识别率,每次部分长度匹配后采用如下方法估计保留模板个数:假设库模板总数为l,截取所有库模板矢量的起始部分,截取长度(百分比)与此次截取测试语音长度(百分比)一致,并将截取的各个模板矢量的起始部分表示为语音,则语音总数为l。选择其中一个截取语音,统计出库模板表示的语音中首部包含该语音的总数,记为该语音与库模板语音的相似数c1。同理,分别为其他截取语音统计出相似数,记为c2c3…cl。比较所有相似数并取其中最大值cmax,则cmax与l的比值就是该次部分长度匹配后保留模板的百分比。
2.3 改进算法的步骤
改进DTW算法的步骤如下所述:
(1)将训练模板存入内存,总数记为c,同时进行识别阶段预设工作:设置测试语音特征矢量的截取方式,包括截取次数m和各次截取长度a1,a2,…,am(百分比);设置各次最优路径匹配后训练模板的保留个数b1,b2,…,bm-1(百分比且最后一次取一个模板,bm可忽略);
(2)输入测试语音信号,经过语音信号预处理(预加重、分帧加窗和端点检测)之后,提取出测试语音特征矢量;
(3)利用式(2)的条件排除部分训练模板,保留满足条件的训练模板;
(4)设某一保留训练模板矢量与测试语音特征矢量的帧匹配失真度矩阵为d和累积失真度矩阵为D=Realmax,其中d和D的大小均为N*M且横向表示待测语音帧,纵向表示训练模板帧。计算该训练模板矢量第一帧与测试语音特征矢量第一帧的失真度(欧氏距离),并保存到d(1,1)和D(1,1)中。同理,计算所有保留训练模板矢量第一帧与测试语音特征矢量第一帧的失真度(欧氏距离),并分别保存到各自的帧失真度矩阵与累积失真度矩阵相同的位置;
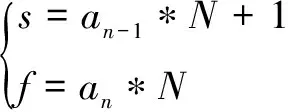
(6)计算搜索到的训练模板矢量帧与待测语音s~f帧之间的帧失真度(欧氏距离),并利用式(3)递推相交帧的累积失真度,分别保存到d与D相应的位置;
(7)找出累积失真度矩阵f列中最小的值,记为该训练模板矢量的最优部分匹配失真度Dmin;
(8)重复步骤5~7,计算并找出所有保留训练模板矢量的最优部分匹配失真度Dmin。将保留的训练模板矢量按照各自的Dmin从小到大排序,并保留前c*bn(四舍五入取整)个模板;
(9)判决c*bn1?若是,则转入步骤10执行;若否,则转入步骤11执行;
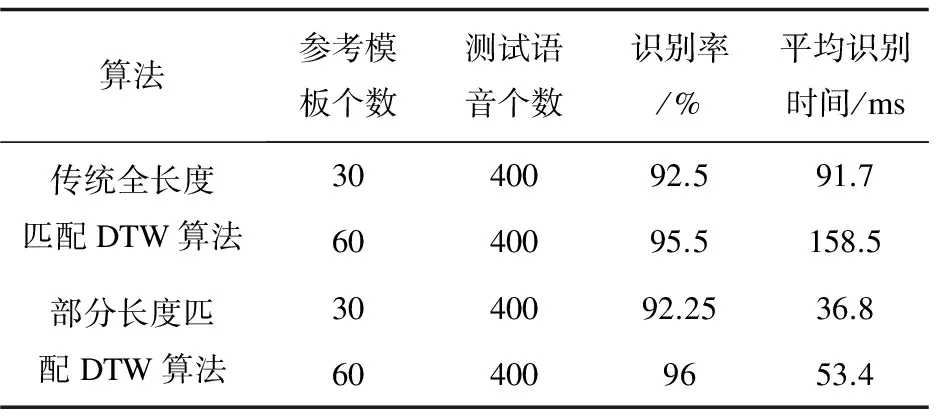
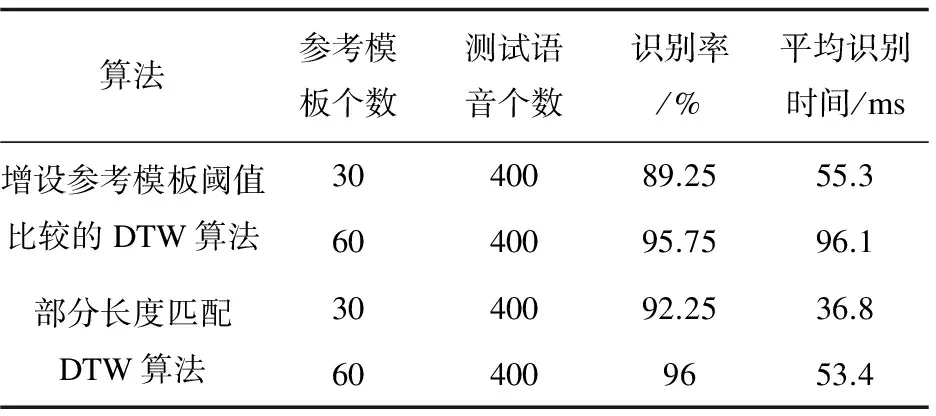
(10)判决n (11)将步骤8中已排序的训练模板矢量中的第一个训练模板矢量表示的语音判决为测试语音,结束。 假设孤立词语音识别系统中有N个模板,平均测试语音提取参数的时间为t0,识别时间为t1,则全长度匹配需要的时间为N*(t0+t1)。在保证系统识别率基本不变的情况下,部分长度匹配需要的时间粗略计算如式(4): (4) 其中,a1,a2,…,am逐次增加且b1,b2,…,bm-1逐次减小。由式(4)可得,T的值始终小于N*(t0+t1)。当a1与b1取值很小时,系统采用部分长度匹配算法所需的识别时间接近N*(t0+t1*(a1+b1-a1*b1)),远小于采用全长度匹配算法所需的时间N*(t0+t1)。 为了检验上述部分长度匹配DTW算法在降低系统识别时间方面的有效性,进行了两组仿真实验:比较部分长度匹配DTW算法与传统全长度匹配DTW算法,以及部分长度匹配DTW算法与文献[3]中增设参考模板阈值的DTW算法。实验中语音数据采自于28位男生,12位女生,内容包括0~9十个汉语发音的数字。其中每个人对各个数字重复发音2次,总共800组数据。由于实验数据来自于非特定人,实验采用聚类的方法训练模板[11-13],即对每个数字所有人的第一遍发音(40组数据)进行聚类训练出3个或6个模板,10个数字共30个或60个模板。其中语音参数采用36维Mel系数(12维Mel系数+12维一阶差分参数+12维二阶差分参数)[14-17]。语音采样频率为16 kHz,预加重系数μ=0.937 5。采用汉明窗进行分帧,帧长256个样点,帧移80个样点。 实验中部分长度匹配DTW算法采用将测试语音特征矢量依次截取3部分(10%,70%,100%)的方式进行匹配,同时每次匹配后保留部分模板(20%,10%)作为下次部分匹配的参考模板,截取过程中矢量长度或模板个数的小数部分四舍五入取整。仿真结果如表1和表2所示。 从表1中的数据可以看出,在保证系统识别率基本不变的情况下,采用部分长度匹配算法的识别时间大约是传统全长度匹配DTW算法的1/3,大幅降低了孤立词语音识别系统的识别时间。 从表2可以看出,相较于采用增设参考模板阈值的DTW算法,采用部分长度匹配DTW算法的识别时间也有明显降低。而且采用部分长度匹配DTW算法避免了增设参考模板阈值的DTW算法额外设立合理阈值的问题,减少了识别系统的额外工作量。 表1 部分长度匹配算法与传统DTW算法的识别性能比较 表2 部分长度匹配算法与文献[3]中DTW算法的识别性能比较 为了提高孤立词语音识别系统的识别效率,提出了测试语音特征矢量与模板矢量部分长度最优路径匹配的算法。在算法中,每一次进行部分长度匹配时只需截取一段测试语音特征矢量与剩余的模板矢量进行匹配,便可以大量排除匹配失真度较大的模板。仿真结果表明,与传统DTW算法相比,该算法在保证系统识别精度基本不变的情况下,减少了系统的工作运算量,有效降低了系统的识别时间。 参考文献: [1] 余 炜,周 娅,万代立,等.基于改进DTW的彝语孤立词识别研究[J].昆明理工大学学报:自然科学版,2014,39(5):47-53. [2] ZHANG Z,TAVENARD R,BAILLY A,et al.Dynamic time warping under limited warping path length[J].Information Sciences,2017,393:91-107. [3] 张宝峰.基于DSP的语音识别算法研究与实现[D].兰州:兰州理工大学,2011. [4] 陈泉坤.基于DSP5509A的DTW语音识别系统设计与实现[D].成都:电子科技大学,2012. [5] 吴佳龙,李 坤,刘 中.孤立词语音识别算法研究与设计[J].电子科技,2015,28(2):22-25. [6] 陈立万.基于语音识别系统中DTW算法改进技术研究[J].微计算机信息,2006,22(2-2):267-269. [7] 朱淑琴,赵 瑛.DTW语音识别算法研究与分析[J].微计算机信息,2012,28(5):150-151. [8] 廖振东.基于DTW的孤立词语音识别系统研究[D].昆明:云南大学,2015. [9] 苏 昊,王 民,李 宝.一种改进的DTW语音识别系统[J].中国西部科技,2011,10(1):38-39. [10] 文 翰,黄国顺.语音识别中DTW算法改进研究[J].微计算机信息,2010,26(7-1):195-197. [11] ABDULLA W H,CHOW D,SIN G.Cross-words reference template for DTW-based speech recognition systems[C]//Tencon conference on convergent technologies for the Asia-pacific Region.[s.l.]:[s.n.],2003:1576-1579. [12] 封伶刚,王秀萍.一种新的基于LBG和DTW的模板训练算法[J].计算机工程与应用,2005,41(26):85-88. [13] 李 燕,陶定元,林 乐.基于DTW模型补偿的伪装语音说话人识别研究[J].计算机技术与发展,2017,27(1):93-96. [14] 甄 斌,吴玺宏,刘志敏,等.语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报:自然科学版,2001,37(3):371-378. [15] DHINGRA S D,NIJHAWAN G,PANDIT P.Isolated speech recognition using MFCC And DTW[J].International Journal of Advanced Research in Electrical Electronics & Instrumentation Engineering,2013,2(8):4085-4092. [16] LIMKARA M,RAOB R,SAGVEKARC V.Isolated digit recognition using MFCC And DTW[J].International Journal of Advanced Electrical & Electronics Engineering,2012,1(1):59-64. [17] MUDA L,BEGAM M,ELAMVAZUTHI I.Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques[J].Journal of Computing,2010,2(3):138-143.2.4 改进算法的识别性能评估
3 实验结果及分析
4 结束语
