A NOTE ON POWER CALCULATION FOR GENERALIZED CASE-COHORT SAMPLING WITH ACCELERATED FAILURE TIME MODEL
2018-04-02SHIYueyongCAOYongxiuJIAOYulingYUJichang
SHI Yue-yong,CAO Yong-xiu,JIAO Yu-ling,YU Ji-chang
(1.School of Economics and Management,China University of Geosciences,Wuhan 430074,China)(2.School of Statistics and Mathematics,Zhongnan University of Economics and Law,Wuhan 430073,China)(3.Center for Resources and Environmental Economic Research,China University of Geosciences,Wuhan 430074,China)
1 Introduction
In many epidemiological studies,the meaningful results can be obtained through observing thousands of subjects for a long time.Due to the financial limitation or technical difficulties,it needs to develop the cost-effective design for selecting subjects in the underlying cohort to observe their expensive covariates.The case-cohort sampling(Prentice,1986)is a well-known cost-effective design with the response subject to censoring,where the expensive covariates are measured only for a subcohort randomly selected from the cohort and additional failures outside the subcohort.The statistical methods for case-cohort sampling were well studied in the literature(e.g.,Self and Prentice,1988;Chen and Lo,1999;Kulich and Lin,2000;Kong,Cai and Sen,2004;Kong and Cai,2009).
Aforementioned works show the case-cohort sampling is especially useful when the failure rate is low.However,the failure rate may be high in practice.Therefore,it’s unpractical to assemble covariates of all failures due to the fixed budget.Under such situations,the generalized case-cohort(GCC)sampling is proposed,which selects a subset of failures instead of all the failures in the case-cohort design.For example,Chen(2001)proposed the GCC design and studied its statistical properties.Kang and Cai(2009)studied the GCC design with the multivariate failure time.Cao,Yu and Liu(2015)studied the optimal GCC design through the power function of a significant test.The aforementioned works are all under the framework of Cox’s proportional hazards model(Cox,1972).Yu et al.(2014),Cao and Yu(2017)studied the GCC design under the additive hazards model(Lin and Ying,1994).
Both the Cox proportional hazards model and additive hazards model are based on modeling the hazards function.However,it is important to directly model the failure time in some applications.Recently,the accelerated failure time(AFT)model which linearly relates the logarithm of the failure time to the covariates gained more and more attention.Kong and Cai(2009)studied the case-cohort sampling under the AFT model.Chiou,Kang and Yan(2014)proposed a fast algorithm for the AFT model under the case-cohort sampling.Cao et al.(2017)studied the GCC sampling under the AFT model and discussed the optimal subsample allocation by the asymptotic relative efficiency between the proposed estimators and the estimators from the simple random sampling scheme.
In order to design a GCC study in practice,there is an important question for the principal investigators that how to calculate the power function under a fixed budget.To the best of our knowledge,no such consideration is given under the generalized case-cohort design.Therefore,we will fill this gap under the accelerated failure time model in this paper.
The article is organized as follows.In Section 2,we propose the generalized case-cohort sampling,use the smoothed weighted Gehan estimating equation approach to estimate the unknown regression parameters in the accelerated failure time model,and give the corresponding asymptotic properties.In Section 3,we study the power calculation under a fixed budget.In Section 4,we conduct the simulation studies to evaluate the performances of the proposed methods.A real data analysis is analyzed through the proposed method in Section 5.Some concluding remarks are presented in Section 6.
2 Generalized Case–Cohort Sampling and Inference Procedures
2.1 Model

where β0and γ0are unknown regression parameters and ∈is the random error with an unknown distribution function.
2.2 Generalized Case-Cohort Sampling
Suppose the underlying population has n subjects and{Ti,δi,Ze,i,Zc,i,i=1,···,n}are the independent copies of(T,δ,Ze,Zc).In the generalized case-cohort sampling,binary random variable ξidenotes whether or not the i-th subject is selected into the subcohort and the corresponding successful probability is p.Let ηibe the selection indicator for whether or not the j-th subject is selected into supplemental failure samples and the conditional probability P(ηj=1|ξj=0,δj=1)=q.In the GCC sampling,the covariates Zeare only observed on the selected subjects.Hence,the observed data structure is given as follows:

2.3 Inference Procedures
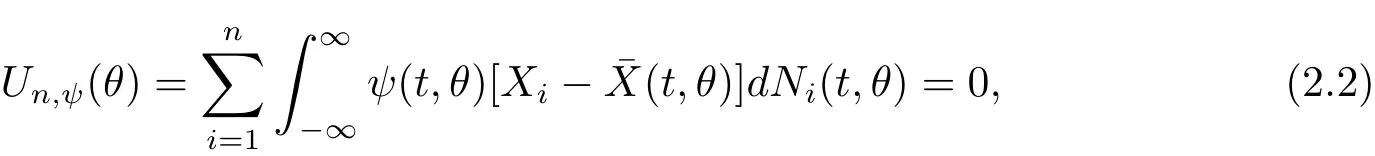
where ψ(·)is a possible data-dependent weight function and(t,θ)=S(1)(t,θ)/S(0)(t,θ)withfor d=0,1.The weight function ψ(t,θ)=1 and S(0)(t,θ)are corresponding to the log-rank and Gehan statistics,respectively.
Unfortunately,in the GCC sampling,the covariates Zeare only observed for selected subject and the distribution of selected supplemental failures is different from the distribution of the underlying population.Therefore,the inverse probability weight method(Horvitz and Thompson,1951)is needed to adjust for the biased sampling mechanism of the GCC sampling
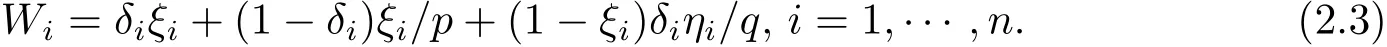
Then,the true regression parameters θ0in model(2.1)can be estimated by solving the following weighted estimating equations
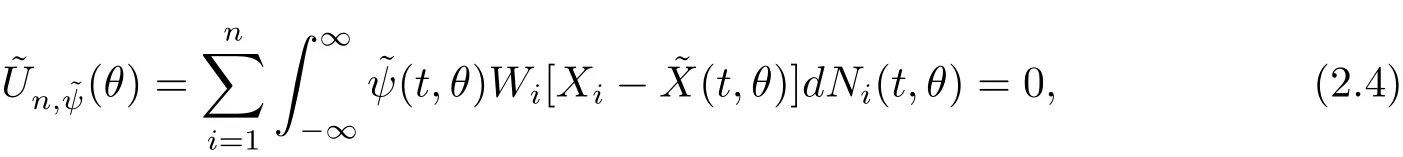
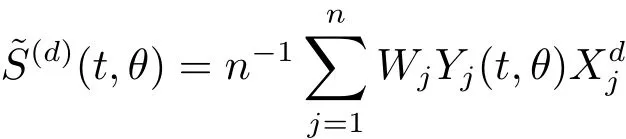
for d=0,1.In this paper,we consider Gehan statistics,Hence,the weighted Gehan estimating equations can be re-written as

which are monotone in each component of θ and letdenote the estimators obtained by solving(2.5).
Due to the fact that the weighted Gehan estimating equations are not continuous,induced smoothing procedure is adopted to smooth the weighted Gehan estimating equations(Brown and Wang,2007;Cao,Yang and Yu,2017).The smoothed weighted Gehan estimating equations can be re-written as
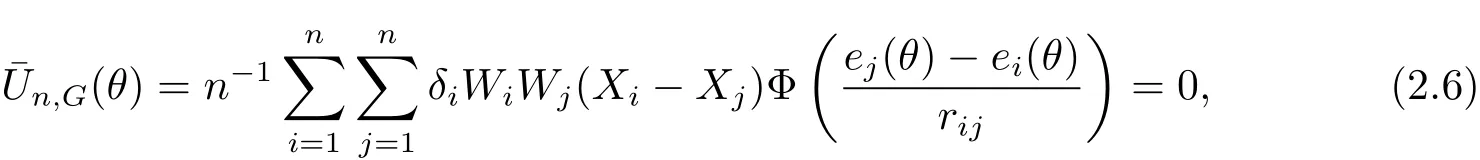
2.4 Asymptotic Properties
In this subsection,we will show the consistency and asymptotic distribution of the.Furthermore,the asymptotic distribution ofis also the same as that of.Define,and λ(·)is the common hazard function of the error term and a⊗2=aa′for a vector a.
Theorem 2.1Under some regular conditions,

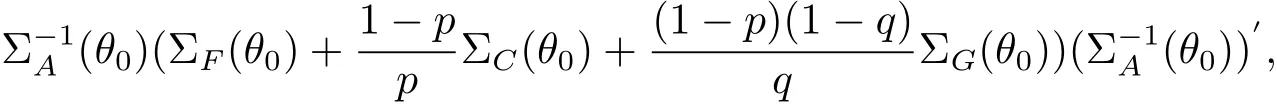
where the matrix ΣA(θ0)is the limit of

with

The regularity conditions and the proof of Theorem 2.1 can be founded in[15].
3 Power Calculation
In this section,we consider the power calculation for GCC sampling with a fixed budget.In order to simplify the notations,letBdenote the fixed budget,Ccdenote the unit price to measure the observed failure time,censoring indicator and cheap covariates{Ti,δi,Zc,i},and Cedenote the unit price to measure expensive covariates Ze,i.Hence,
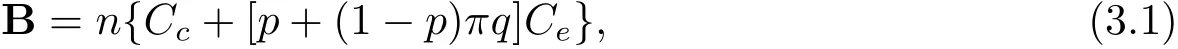
where π =P(δ=1).In practice,n,B,Ccand Ceare known, π can be estimated by,which is equal to p+(1 − p)πq fixed.Let ρv=p+(1 − p)πq,which is the proportion of the validation data set in the missing data literature,where all the data is completely observed.
We consider the following significant test

where k is a non-zero d1-dimensional constant.Letdenote the proposed estimator of β0and α denote the type I error,respectively.From Theorem 2.1,the reject region of the test(3.2)at the significant level α is
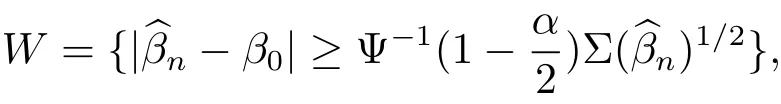
where


When we calculate the power function,due to constrain(3.1),we need to consider the following optimization problem through the Lagrange multiplier argument

where ‖·‖1denote the L1norm.Because the power function is positive,the optimal solution(p∗,q∗)can be easy to obtain and the corresponding power is Power(p∗,q∗).
4 Simulation Study
In this section,the simulation studies are conducted to evaluate the finite sample performances of the proposed method.We generate the failure time from the accelerated failure time model

where Zefollows a standard normal distribution,Zcfollows a Bernoulli distribution with a successful probability of 0.5,the regression parameters β0=0 and γ0=0.5,and the error term∈follows a standard normal distribution or a standard extreme value distribution,which will result a log-norm distribution or a Weibull distribution for the failure time,respectively.The censoring time is generated from the uniform distribution over the interval[0,c],where c is chosen to yield around 80%censoring rate,respectively.
We consider the following test at the significant level α being 0.05:
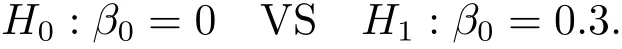
The size of the underlying population is n=600.We investigate different scenarios for sampling probabilities(p,q)under constraint(3.1),which is equal to ρvbeing fixed.For each configuration,we generate 1000 simulated data sets.The results of the simulation studies are summarized in Figure 1.From Figure 1,we can obtain following results
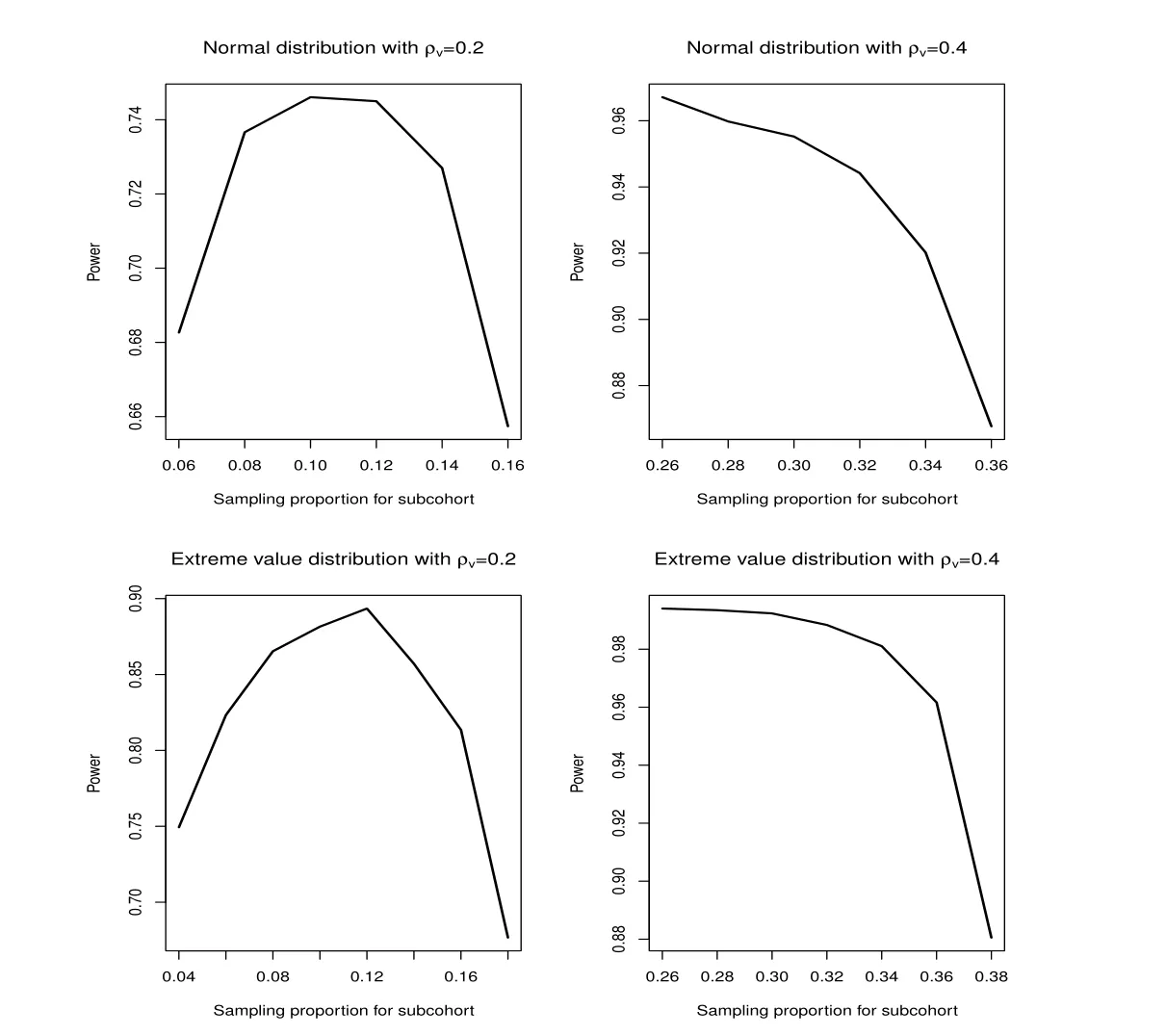
Figure 1:Power function with fixed ρvand different sampling probability p
(I)When the error term follows the standard normal distribution,the powers are 0.746 and 0.967 with ρvbeing 0.200 and 0.400,respectively,and the corresponding sampling probability(p,q)are(0.100,0.556)and(0.260,0.946),respectively.
(II)When the error term follows the extreme value distribution,the powers are 0.893 and 0.994 with ρvbeing 0.200 and 0.400,respectively,and the corresponding sampling probability(p,q)are(0.120,0.455)and(0.260,0.946),respectively.
5 National Wilm’s Tumor Study Group
The national Wilm’s tumor study group(NWTSG)is a cancer research which was conducted to improve the survival of children with Wilms’tumor by evaluating the relationship between the time to tumor relapse and the tumor histology(Green et al.,1998).However,the tumor histology is difficult and expensive to measure.According to the cell type,the tumor histology can be classified into two categories,named as favorable and unfavorable.Let the variable histol denote the category of the tumor histology.We also consider other covariates including the patient age,the disease stages and the study group.
We consider the accelerated failure time model
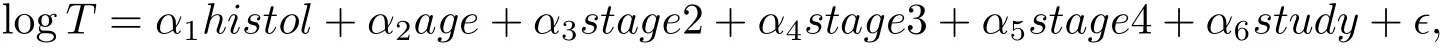
where the covariates stage2,stage3,stage4 indicate the disease stages and the variable study indicates the study group.There are 4028 subjects in the full cohort and 571 subjects subject to tumor relapse.We randomly selected a subcohort by p=0.166 and select a subset of the failures outside subcohort through q=0.400.We compare the proposed estimatorwith,which is based on the simple random sampling design with the same sample size as GCC design.The results are summarized in Table 1.

Table 1:Analysis results for NWTSG
From Table 1,both the two methods con fi rm that tumor histology is significant to the cancer relapse.The proposed method shows the age is significant to cancer relapse which is different from the result from.
6 Concluding Remarks
In this paper,we study the power calculation for the generalized case-cohort(GCC)design under the accelerated failure time model.Due to the biased sampling mechanism of GCC,the weighted Gehan estimating equations are adopted to estimate the regression coefficients.The induced smoothing procedure is introduced to overcome the discontinuous of the smoothed weighted Gehan estimating equation,which could lead to continuously differentiable estimating equations and can be solved by the standard numerical methods.The simulation studies are conducted to evaluate the finite sample performances of the proposed method and we also analyze a real data set from national Wilm’s tumor study group.
In this paper,we consider the covariates which are time-invariant.Next,we will consider power calculation in the accelerated failure time model under the GCC design with timedependent covariates.Finally,it will be interesting to evaluate the performance of stratified sampling in the subcohort to enhance the efficiency.Study along this directions is currently under way.
[1]Prentice R L.A case-cohort design for epidemiologic cohort studies and disease prevention trials[J].Biometrika,1986,73(1):1–11.
[2]Self S G,Prentice R L.Asymptotic distribution theory and efficiency results for case-cohort studies[J].Ann.Stat.,1988,16(1):64–81.
[3]Chen K,Lo S H.Case-cohort and case-control analysis with Cox’s model[J].Biometrika,1999,86(4):755–764.
[4]Kulich M,Lin D Y.Additive hazards regression with covariate measurement error[J].J.Amer.Stat.Assoc.,2000,95(449):238–248.
[5]Kong L,Cai J,Sen P K.Weighted estimating equations for semiparametric transformation models with censored data from a case-cohort design[J].Biometrika,2004,91(2):305–319.
[8]Kong L,Cai J.Case-cohort analysis with accelerated failure time model[J].Biometrics,2009,65(1):135–142.
[7]Chen K.Generalized case-cohort sampling[J].J.R.Stat.Soc.Ser.B Stat.Meth.,2001,63(4):791–809.
[8]Kang S,Cai J.Marginal hazards model for case-cohort studies with multiple disease outcomes[J].Biometrika,2009,96(4):887–901.
[9]Cao Y X,Yu J C,Liu Y Y.Optimal generalized case-cohort analysis with Cox’s proportional hazards model[J].Acta Math.Appl.Sin.Engl.Ser.,2015,31(3):841–854.
[10]Cox D R.Regression models and life-tables(with discussion)[J].J.R.Stat.Soc.Ser.B Stat.Meth.,1972,34(2):187-220.
[11]Yu J C,Shi Y Y,Yang Q L,Liu Y Y.Additive hazards regression under generalized case-cohort sampling[J].Acta Math.Sin.Engl.Ser.,2014,30(2):251–260.
[12]Cao Y,Yu J.Optimal generalized case-cohort sampling design under the additive hazard model[J].Comm.Statist.The.Meth.,2017,46(9):4484–4493.
[13]Lin D,Ying Z.Semiparametric analysis of additive hazards model[J].Biometrika,1994,81(1):61–71.
[14]Chiou S H,Kang S,Yan J.Fast accelerated failure time modeling for case-cohort data[J].Stat.Comput.,2014,24(4):559–568.
[15]Cao Y,Yang Q,Yu J.Optimal generalized case-cohort analysis with accelerated failure time model[J].J.Korean Stat.Soc.,2017,46(2):298–307.
[16]Horvitz D G,Thompson D J.A generalization of sampling without replacement from a finite universe[J].J.Amer.Stat.Assoc.,1952,47(260):663–685.
[17]Brown B M,Wang Y G.Induced smoothing for rank regression with censored survival times[J].Stat.Med.,2007,26:828–836.
